
Track
AI Fundamentals
10 hr
Databricks has recently introduced DBRX, its open general-purpose large language model (LLM) built on a mixture-of-experts (MoE) architecture with a fine-grained approach. Instead of using a single neural network for all tasks, the system comprises multiple specialized "expert" networks, each optimized for different types of tasks or data.
This model has performed better than traditional LLMs like GPT-3.5 and Llama 2 because it's faster and more cost-effective. According to tests, DBRX scores 73.7%, which is higher than LLaMa2 (69.8%) in language understanding tasks.
In this article, we’ll discuss its capabilities and how to get started with Databricsk DBRX in more detail.
DBRX uses a transformer-based decoder-only architecture trained using next-token prediction. It employs a fine-grained mixture-of-experts (MoE) architecture. These ‘experts’ refer to specialized agents based on LLMs, enhanced with domain-specific knowledge and reasoning skills.
DBRX has a large number of smaller experts (16 experts in total) and chooses a subset of them (4 experts) for any given input.
Simply put, this fine-grained approach with 65x more possible combinations of experts improves model quality compared to other open MoE models like Mixtral and Grok-1, which have fewer experts and choose fewer experts per input.
Here are some key details about DBRX:
The model was pre-trained on an impressively large dataset, estimated to be twice as effective as previous datasets used by Databricks. A suite of Databricks tools, such as Apache Spark and Databricks notebooks for data processing and Unity Catalog for data governance, was used to train the model.
During its training, curriculum learning was employed, and the data mix was changed to substantially improve model quality. Such strategic alterations in the training data mix optimized the model's ability to handle diverse inputs effectively.
Some of the key technologies used for DBRX’s pretraining include:
Databricks claims its DBRX model is superior to several top open-source models in terms of efficiency and task performance.
Here’s a detailed comparison of how DBRX stacks up against its competitors:
Below, we’ve collated the comparisons into a table, and shown a graph based on some of the results:
|
Model Comparison |
General Knowledge |
Commonsense Reasoning |
Databricks Gauntlet |
Programming Reasoning |
Mathematical Reasoning |
|
DBRX vs LLaMA2-70B |
+9.8% |
+3.1% |
+14% |
+37.9% |
+40.2% |
|
DBRX vs Mixtral Instruct |
+2.3% |
+1.4% |
+6.1% |
+15.3% |
+5.8% |
|
DBRX vs Grok-1 |
+0.7% |
Not available |
Not available |
+6.9% |
+4% |
|
DBRX vs Mixtral Base |
+1.8% |
+2.5% |
+10% |
+29.9% |
Not available |
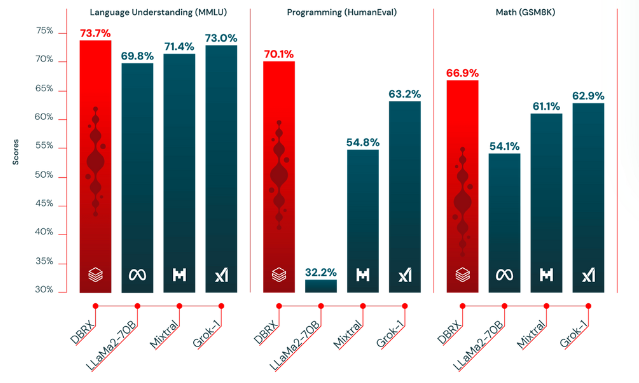
Comparing DBRX’s quality with other open-source LLMs - source
Before accessing DBRX, ensure your system has at least 320GB of memory. Then follow these steps to access DBRX:
transformers librarypip install "transformers>=4.40.0"from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("databricks/dbrx-base", token="hf_YOUR_TOKEN")
model = AutoModelForCausalLM.from_pretrained("databricks/dbrx-base", device_map="auto", torch_dtype=torch.bfloat16, token="hf_YOUR_TOKEN")
# Directing tensors to "cuda" (GPU) for faster computation as GPUs are better at handling parallel tasks.
input_text = "Databricks was founded in "
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
# DBRX accepts a context length of up to 32768 tokens. Here`max_new_tokens` specifies the maximum number of tokens to generate.
outputs = model.generate(**input_ids, max_new_tokens=100)
print(tokenizer.decode(outputs[0]))Want to learn how to use Transformers and Hugging Face? Read our tutorial on using Transformers and Hugging Face.
DRBX can help you with basic content creation and prompt response tasks like any LLM. Here’s what you can do with DBRX:
DBRX can also perform advanced coding-related tasks to help data practitioners or coders:

DBRX responding to simple commands - source
You can fine-tune DBRX with Github’s open-source LLM foundry. However, fine-tuning requires training examples to be formatted as dictionaries:
formatted_example = {'prompt': <prompt_text>, 'response': <response_text>}Prompt: This is the starting question or instruction you give the model.
Response: This is the answer the model is trained to generate.
You can use three different data sets to fine-tune any LLM:
If you want to fine-tune using a dataset from the HuggingFace Hub, and the
dataset has a pre-defined preprocessing function or already follows the
"prompt"/"response" format, you can simply point the dataloader to that dataset.
train_loader:
name: finetuning
dataset:
hf_name: tatsu-lab/alpaca
split: train
...If no preprocessing function is defined, Use preprocessing_fn to specify a custom preprocessing function for the dataloader.
train_loader:
name: finetuning
dataset:
hf_name: mosaicml/doge-facts
preprocessing_fn: my_data.formatting:dogefacts_prep_fn
split: train
...
If you already have a finetuning dataset in your device, define local JSONL files in
the YAML config yamls/finetune/1b_local_data_sft.yaml.
train_loader:
name: finetuning
dataset:
hf_name: json # assuming data files are json formatted
hf_kwargs:
data_dir: /path/to/data/dir/
preprocessing_fn: my.import.path:my_preprocessing_fn
split: train
...
Skip preprocessing_fn if your local data is already in "prompt"/"response" format.
Convert your HuggingFace dataset to MDS format using the
convert_finetuning_dataset.py script.
After converting your HuggingFace dataset to a streaming format, simply adjust your YAML configuration like this.
train_loader:
name: finetuning
dataset:
remote: s3://my-bucket/my-copy-doge-facts
local: /tmp/mds-cache/
split: train
...
If you want to see full parameter finetuning, see the YAML config at
Databricks DBRX uses multiple specialized networks to enhance the model speed and cost-effectiveness. This fine-grained approach allows it to outperform other LLMs in handling complex tasks.
Want to learn more about large language models and how to fine-tune them? Check out these resources:
Continue Your AI Journey Today!
Track
Course
Course
blog
Josep Ferrer
Tutorial
Laiba Siddiqui
Tutorial
Arunn Thevapalan
Tutorial
Allan Ouko
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan

