
Cursus
Les fondamentaux du lama
4 h
DeepSeek-R1 est idéal pour les systèmes basés sur RAG en raison de ses performances optimisées, de ses capacités avancées de recherche vectorielle et de sa flexibilité dans différents environnements, qu'il s'agisse d'installations locales ou de déploiements évolutifs. Voici quelques raisons de son efficacité :
Notre projet de démonstration se concentre sur la construction d'un chatbot RAG en utilisant DeepSeek-R1 et Gradio.
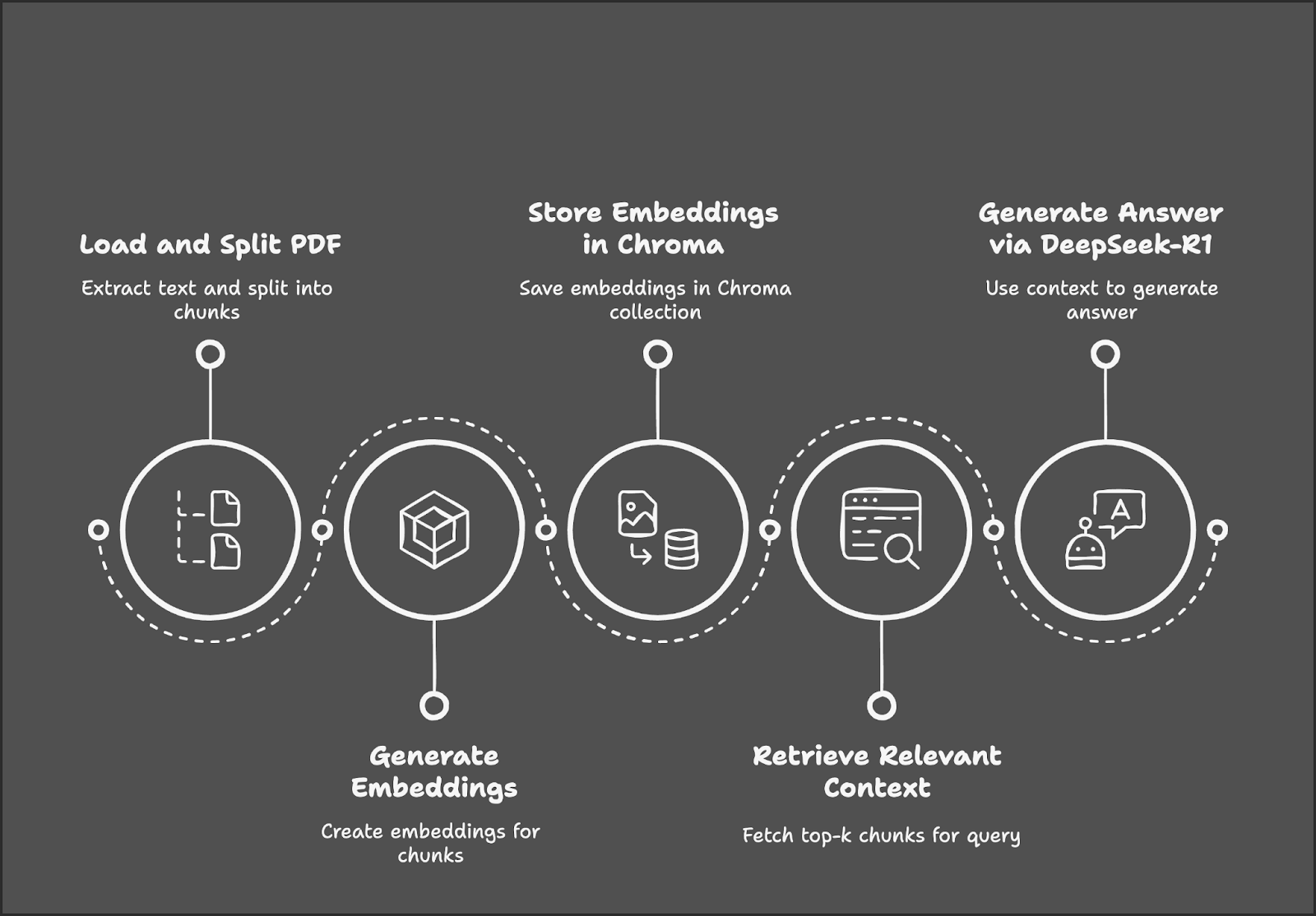
Le processus commence par le chargement et la division d'un PDF en morceaux de texte, suivis de la génération de enchâssements pour ces morceaux. Ces encastrements sont stockés dans une base de données Chroma pour une récupération efficace. Lorsqu'un utilisateur soumet une requête, le système récupère les morceaux de texte les plus pertinents et utilise DeepSeek-R1 pour générer une réponse basée sur le contexte récupéré.
Avant de commencer, nous devons nous assurer que les outils et bibliothèques suivants sont installés :
Exécutez les commandes suivantes pour installer les dépendances nécessaires :
!pip install langchain chromadb gradio ollama pymypdf
!pip install -U langchain-communityUne fois les dépendances ci-dessus installées, exécutez les commandes d'importation suivantes :
import ollama
import re
import gradio as gr
from concurrent.futures import ThreadPoolExecutor
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyMuPDFLoader
from langchain_community.embeddings import OllamaEmbeddings
from chromadb.config import Settings
from chromadb import Client
from langchain.vectorstores import ChromaNous utiliserons le site PyMuPDFLoader de LangChain pour extraire le texte de la version PDF du livre Foundations of LLMs de Tong Xiao et Jingbo Zhu - il s'agit d'un livre à forte teneur en mathématiques, ce qui signifie que notre chatbot devrait être en mesure d'expliquer correctement les mathématiques qui sous-tendent les LLM. Vous pouvez trouver le livre sur arXiv.
# Load the document using PyMuPDFLoader
loader = PyMuPDFLoader("/path/to/Foundations_of_llms.pdf")
documents = loader.load()Une fois le document chargé, nous pouvons commencer à diviser le texte en morceaux pour la suite du traitement.
Nous diviserons le texte extrait en petits morceaux qui se chevauchent afin d'améliorer la récupération du contexte. La fonction RecursiveCharacterTextSpilitter() vous permet de modifier la taille des morceaux et le chevauchement des morceaux en fonction de votre système.
# Split the document into smaller chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
chunks = text_splitter.split_documents(documents)Nous disposons à présent des morceaux de texte extraits, qui sont prêts à être convertis en embeddings.
Nous utiliserons Ollama Embeddings basé sur DeepSeek-R1 pour générer les embeddings de documents. En fonction de la taille du document, la génération de l'incorporation peut prendre du temps, il est donc préférable de la paralléliser pour un traitement plus rapide.
Note : model="deepseek-r1" considère par défaut le modèle de paramètres 7B. Vous pouvez le remplacer par 8B, 14B, 32B, 70B ou 671B. Remplacez X dans le nom du modèle suivant par la taille du modèle : model="deepseek-r1:X"
# Initialize Ollama embeddings using DeepSeek-R1
embedding_function = OllamaEmbeddings(model="deepseek-r1")
# Parallelize embedding generation
def generate_embedding(chunk):
return embedding_function.embed_query(chunk.page_content)
with ThreadPoolExecutor() as executor:
embeddings = list(executor.map(generate_embedding, chunks))La fonction ci-dessus initialise DeepSeek-R1 via Ollama pour générer des encastrements sémantiques de haute dimension, qui seront ensuite utilisés pour la recherche de documents basée sur la similarité.
La fonction generate_embedding() prend le texte d'un morceau de document et génère son intégration. Enfin, ThreadPoolExecutor() applique generate_embedding() à chaque morceau simultanément, en rassemblant les encastrements dans une liste pour un traitement plus rapide par rapport à l'exécution séquentielle.
Nous stockerons les enchâssements et les morceaux de texte correspondants dans une base de données vectorielle très performante, Chroma.
# Initialize Chroma client and create/reset the collection
client = Client(Settings())
client.delete_collection(name="foundations_of_llms") # Delete existing collection (if any)
collection = client.create_collection(name="foundations_of_llms")
# Add documents and embeddings to Chroma
for idx, chunk in enumerate(chunks):
collection.add(
documents=[chunk.page_content],
metadatas=[{'id': idx}],
embeddings=[embeddings[idx]],
ids=[str(idx)] # Ensure IDs are strings
)Nous commençons par suivre les étapes suivantes pour stocker les encastrements :
Client(Settings()) initialise le client Chroma pour gérer le magasin de vecteurs. client.delete_collection() pour éviter les erreurs. Enfin, utilisez client.create_collection() pour créer une nouvelle collection afin de stocker les morceaux de documents et leurs enchâssements.collection.add() stocke :chunk.page_content){'id': idx}) pour référencer le chunkCette configuration garantit que chaque fragment de document est indexé correctement pour une recherche vectorielle efficace.
Nous allons initialiser le récupérateur Chroma, en veillant à ce qu'il utilise les mêmes encastrements DeepSeek-R1 pour les requêtes.
# Initialize retriever using Ollama embeddings for queries
retriever = Chroma(collection_name="foundations_of_llms", client=client, embedding_function=embedding_function).as_retriever()Le récupérateur Chroma se connecte à la collection "foundations_of_llms" et utilise les encastrements DeepSeek-R1 via Ollama pour intégrer les requêtes des utilisateurs. Il récupère les morceaux de documents les plus pertinents sur la base de la similarité des vecteurs pour des réponses tenant compte du contexte.
Ensuite, nous récupérerons les morceaux de texte les plus pertinents et les formaterons pour que DeepSeek-R1 puisse générer des réponses.
def retrieve_context(question):
# Retrieve relevant documents
results = retriever.invoke(question)
# Combine the retrieved content
context = "\n\n".join([doc.page_content for doc in results])
return contextLa fonction retrieve_context intègre la requête de l'utilisateur à l'aide de DeepSeek-R1 et récupère les morceaux de documents les plus pertinents via le récupérateur Chroma. Il combine ensuite le contenu des morceaux récupérés en une seule chaîne de contexte pour la suite du traitement.
Nous disposons à présent de la question et du contexte récupéré. Ensuite, nous l'envoyons à DeepSeek-R1 via Ollama pour obtenir la réponse finale.
def query_deepseek(question, context):
# Format the input prompt
formatted_prompt = f"Question: {question}\n\nContext: {context}"
# Query DeepSeek-R1 using Ollama
response = embedding_function.chat(
model="deepseek-r1",
messages=[{'role': 'user', 'content': formatted_prompt}]
)
# Clean and return the response
response_content = response['message']['content']
final_answer = re.sub(r'<think>.*?</think>', '', response_content, flags=re.DOTALL).strip()
return final_answerPour obtenir la réponse finale, nous commençons par combiner la question de l'utilisateur et le contexte récupéré dans une invite structurée. Envoyez ensuite cette demande au modèle DeepSeek-R1 via Ollama pour recevoir une réponse. Pour rendre le résultat final présentable, nous supprimons les balises inutiles et renvoyons la réponse finale.
Nous avons mis en place notre pipeline RAG. Nous allons maintenant utiliser Gradio pour créer une interface interactive permettant aux utilisateurs de poser des questions relatives à sa base de connaissances (ici, Fondements des LLM).
def ask_question(question):
# Retrieve context and generate an answer using RAG
context = retrieve_context(question)
answer = query_deepseek(question, context)
return answer
# Set up the Gradio interface
interface = gr.Interface(
fn=ask_question,
inputs="text",
outputs="text",
title="RAG Chatbot: Foundations of LLMs",
description="Ask any question about the Foundations of LLMs book. Powered by DeepSeek-R1."
)
interface.launch()La fonction ask_question() récupère le contexte pertinent à l'aide du récupérateur Chroma et génère la réponse finale via DeepSeek-R1. L'interface Gradio, construite avec gr.Interface(), permet aux utilisateurs de poser des questions de manière interactive et de recevoir des réponses contextuelles précises et fondées.
Félicitations ! Vous disposez désormais d'un chatbot local prêt à discuter de tout ce qui concerne les LLM.
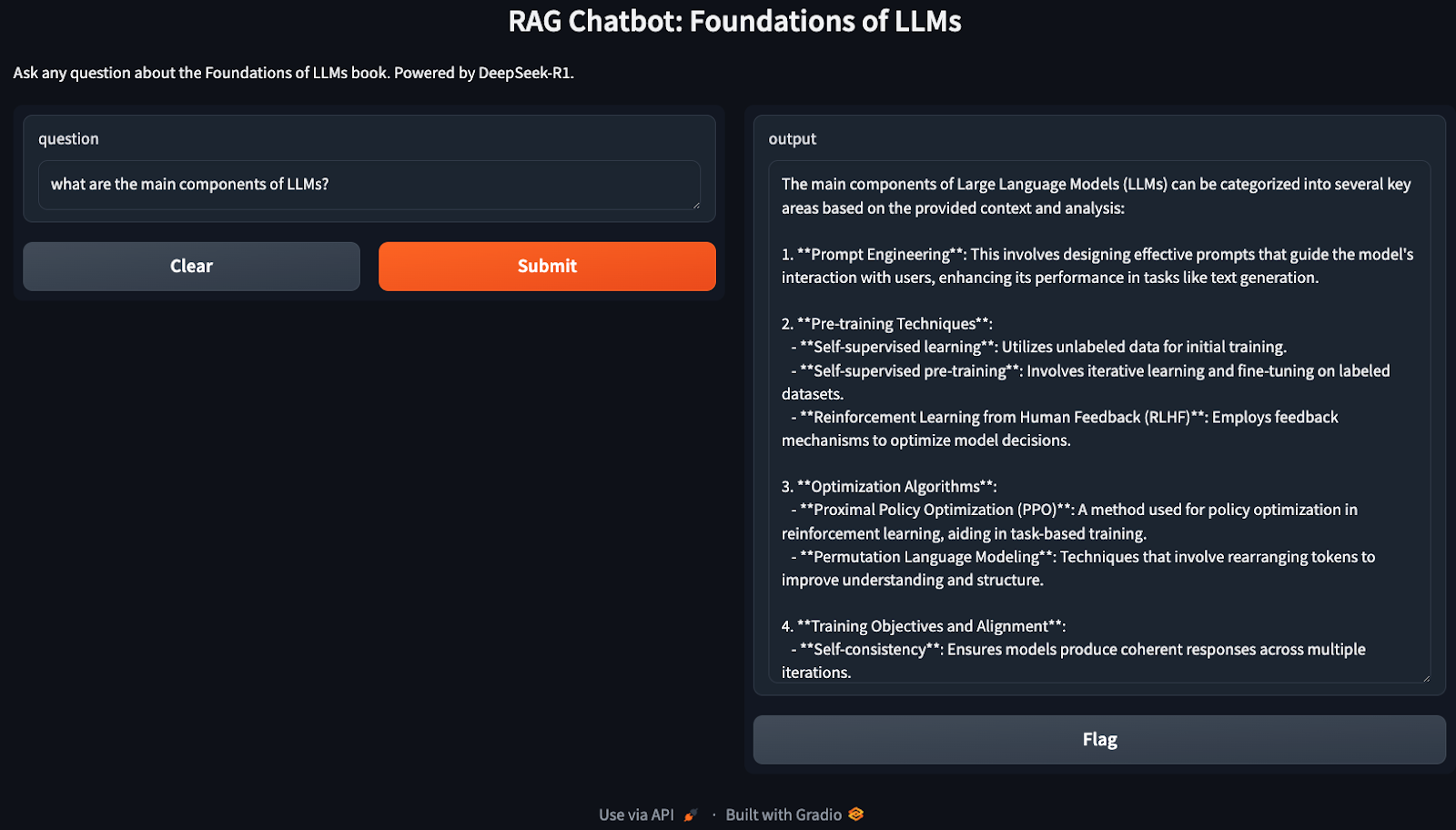
La démonstration ci-dessus couvre une implémentation très basique de RAG, qui peut être optimisée pour plus d'efficacité. Voici quelques exemples à essayer :
chunk_size et chunk_overlap pour équilibrer les performances et la qualité de l'extraction.Dans ce tutoriel, nous avons construit un chatbot local basé sur RAG en utilisant DeepSeek-R1 et Chroma pour la recherche, ce qui garantit des réponses précises et contextuelles aux questions basées sur une large base de connaissances.
Pour en savoir plus sur DeepSeek, je vous recommande ces blogs :
Apprenez l'IA avec ces cours !
Cursus
Cours
Cours