
Lernpfad
Llama-Grundlagen
4 Std.
DeepSeek-R1 ist aufgrund seiner optimierten Leistung, der erweiterten Vektorsuchfunktionen und der Flexibilität in verschiedenen Umgebungen - von lokalen Installationen bis hin zu skalierbaren Einsätzen - ideal für RAG-basierte Systeme geeignet. Hier sind einige Gründe, warum sie effektiv ist:
Unser Demoprojekt konzentriert sich auf den Aufbau eines RAG-Chatbots mit DeepSeek-R1 und Gradio.
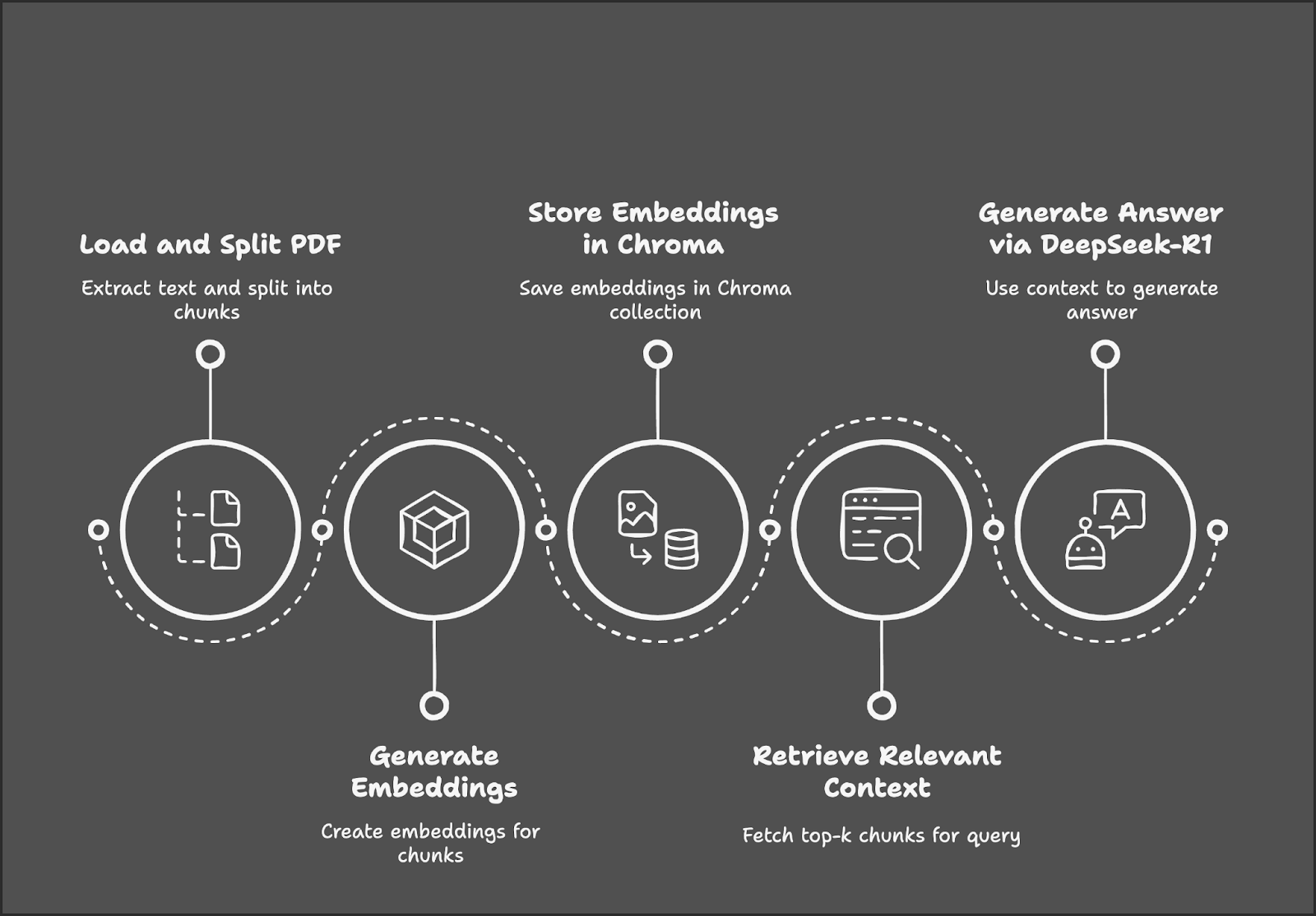
Der Prozess beginnt mit dem Laden und Zerlegen einer PDF-Datei in Textabschnitte, gefolgt von der Erzeugung von Einbettungen für diese Abschnitte. Diese Einbettungen werden in einer Chroma-Datenbank gespeichert, um sie effizient abrufen zu können. Wenn ein Nutzer eine Anfrage stellt, ruft das System die relevantesten Textabschnitte ab und verwendet DeepSeek-R1, um eine Antwort auf der Grundlage des abgerufenen Kontexts zu generieren.
Bevor wir beginnen, müssen wir sicherstellen, dass wir die folgenden Tools und Bibliotheken installiert haben:
Führe die folgenden Befehle aus, um die notwendigen Abhängigkeiten zu installieren:
!pip install langchain chromadb gradio ollama pymypdf
!pip install -U langchain-communitySobald die oben genannten Abhängigkeiten installiert sind, führst du die folgenden Importbefehle aus:
import ollama
import re
import gradio as gr
from concurrent.futures import ThreadPoolExecutor
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyMuPDFLoader
from langchain_community.embeddings import OllamaEmbeddings
from chromadb.config import Settings
from chromadb import Client
from langchain.vectorstores import ChromaWir werden LangChains PyMuPDFLoader nutzen, um den Text aus der PDF-Version des Buches Foundations of LLMs von Tong Xiao und Jingbo Zhu zu extrahieren - es ist ein mathematiklastiges Buch, was bedeutet, dass unser Chatbot in der Lage sein sollte, die Mathematik hinter LLMs gut zu erklären. Du kannst das Buch auf arXiv finden.
# Load the document using PyMuPDFLoader
loader = PyMuPDFLoader("/path/to/Foundations_of_llms.pdf")
documents = loader.load()Sobald das Dokument geladen ist, können wir damit beginnen, den Text für die weitere Verarbeitung in Abschnitte zu unterteilen.
Wir teilen den extrahierten Text in kleinere, sich überschneidende Abschnitte auf, um den Kontext besser wiederzufinden. Du kannst die Größe des Chunks und die Überlappung der Chunks in der Funktion RecursiveCharacterTextSpilitter() je nach deinem System variieren.
# Split the document into smaller chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
chunks = text_splitter.split_documents(documents)Jetzt haben wir die extrahierten Textabschnitte, die in Einbettungen umgewandelt werden können.
Wir verwenden Ollama Embeddings, die auf DeepSeek-R1 basieren, um die Dokumenteneinbettungen zu erzeugen. Je nach Größe des Dokuments kann die Erstellung der Einbettung einige Zeit in Anspruch nehmen, daher ist es besser, sie zu parallelisieren, um die Verarbeitung zu beschleunigen.
Hinweis: model="deepseek-r1" berücksichtigt standardmäßig das 7B-Parameter-Modell. Du kannst ihn je nach Bedarf in 8B, 14B, 32B, 70B oder 671B ändern. Ersetze X im folgenden Modellnamen durch die Modellgröße: model="deepseek-r1:X"
# Initialize Ollama embeddings using DeepSeek-R1
embedding_function = OllamaEmbeddings(model="deepseek-r1")
# Parallelize embedding generation
def generate_embedding(chunk):
return embedding_function.embed_query(chunk.page_content)
with ThreadPoolExecutor() as executor:
embeddings = list(executor.map(generate_embedding, chunks))Die obige Funktion initialisiert DeepSeek-R1 über Ollama, um hochdimensionale semantische Einbettungen zu generieren, die später für die ähnlichheitsorientierte Dokumentensuche verwendet werden.
Die Funktion generate_embedding() nimmt den Text eines Dokumentenstücks und erzeugt dessen Einbettung. Schließlich wendet ThreadPoolExecutor() generate_embedding() auf jeden Chunk gleichzeitig an und sammelt die Einbettungen in einer Liste, um sie schneller zu verarbeiten als bei der sequentiellen Ausführung.
Wir speichern die Einbettungen und die entsprechenden Textabschnitte in einer leistungsstarken Vektordatenbank, Chroma.
# Initialize Chroma client and create/reset the collection
client = Client(Settings())
client.delete_collection(name="foundations_of_llms") # Delete existing collection (if any)
collection = client.create_collection(name="foundations_of_llms")
# Add documents and embeddings to Chroma
for idx, chunk in enumerate(chunks):
collection.add(
documents=[chunk.page_content],
metadatas=[{'id': idx}],
embeddings=[embeddings[idx]],
ids=[str(idx)] # Ensure IDs are strings
)Wir beginnen mit den folgenden Schritten, um Einbettungen zu speichern:
Client(Settings()) initialisiert den Chroma-Client, um den Vektorspeicher zu verwalten. client.delete_collection(), um Fehler zu vermeiden. Zum Schluss erstellst du mit client.create_collection() eine neue Sammlung, in der du die Dokumentenstücke und ihre Einbettungen speicherst.collection.add():chunk.page_content){'id': idx}), um den Chunk zu referenzierenAuf diese Weise wird sichergestellt, dass jedes Dokument korrekt indiziert wird, um eine effiziente vektorbasierte Suche zu ermöglichen.
Wir initialisieren den Chroma-Retriever und stellen sicher, dass er die gleichen DeepSeek-R1-Einbettungen für Abfragen verwendet.
# Initialize retriever using Ollama embeddings for queries
retriever = Chroma(collection_name="foundations_of_llms", client=client, embedding_function=embedding_function).as_retriever()Der Chroma-Retriever verbindet sich mit der Sammlung "foundations_of_llms" und verwendet DeepSeek-R1-Einbettungen über Ollama, um Benutzeranfragen einzubetten. Es findet die relevantesten Dokumententeile auf der Basis von Vektorähnlichkeit für kontextbezogene Antworten.
Als Nächstes suchen wir die wichtigsten Textabschnitte heraus und formatieren sie für DeepSeek-R1, um Antworten zu generieren.
def retrieve_context(question):
# Retrieve relevant documents
results = retriever.invoke(question)
# Combine the retrieved content
context = "\n\n".join([doc.page_content for doc in results])
return contextDie Funktion retrieve_context bettet die Benutzerabfrage mit DeepSeek-R1 ein und ruft die wichtigsten relevanten Dokumentenstücke über den Chroma Retriever ab. Dann kombiniert es den Inhalt der abgerufenen Chunks zu einem einzigen Kontextstring für die weitere Verarbeitung.
Jetzt haben wir die Frage und den gesuchten Kontext. Als Nächstes schickst du sie über Ollama an DeepSeek-R1, um unsere endgültige Antwort zu erhalten.
def query_deepseek(question, context):
# Format the input prompt
formatted_prompt = f"Question: {question}\n\nContext: {context}"
# Query DeepSeek-R1 using Ollama
response = embedding_function.chat(
model="deepseek-r1",
messages=[{'role': 'user', 'content': formatted_prompt}]
)
# Clean and return the response
response_content = response['message']['content']
final_answer = re.sub(r'<think>.*?</think>', '', response_content, flags=re.DOTALL).strip()
return final_answerUm die endgültige Antwort zu erhalten, kombinieren wir zunächst die Frage des Nutzers und den ermittelten Kontext zu einer strukturierten Aufforderung. Sende diese Aufforderung dann über Ollama an das DeepSeek-R1-Modell, um eine Antwort zu erhalten. Um die endgültige Ausgabe vorzeigbar zu machen, entfernen wir unnötige Tags und geben die endgültige Antwort zurück.
Wir haben unsere RAG-Pipeline eingerichtet. Jetzt werden wir Gradio nutzen, um eine interaktive Schnittstelle zu schaffen, über die Nutzer Fragen zur Wissensbasis stellen können (in diesem Fall zu den Grundlagen des LLM).
def ask_question(question):
# Retrieve context and generate an answer using RAG
context = retrieve_context(question)
answer = query_deepseek(question, context)
return answer
# Set up the Gradio interface
interface = gr.Interface(
fn=ask_question,
inputs="text",
outputs="text",
title="RAG Chatbot: Foundations of LLMs",
description="Ask any question about the Foundations of LLMs book. Powered by DeepSeek-R1."
)
interface.launch()Die Funktion ask_question() ruft mithilfe des Chroma-Retrievers den relevanten Kontext ab und generiert die endgültige Antwort über DeepSeek-R1. Die Gradio-Benutzeroberfläche, die mit gr.Interface() erstellt wurde, ermöglicht es den Nutzern, interaktiv Fragen zu stellen und kontextgenaue, fundierte Antworten zu erhalten.
Herzlichen Glückwunsch! Du hast jetzt einen lokal laufenden Chatbot, mit dem du über alles diskutieren kannst, was mit LLMs zu tun hat.
Die obige Demo zeigt eine sehr einfache Implementierung von RAG, die weiter optimiert werden kann, um effizienter zu werden. Hier sind ein paar Dinge zum Ausprobieren:
chunk_size und chunk_overlap an, um ein Gleichgewicht zwischen Leistung und Abrufqualität herzustellen.In diesem Tutorial haben wir einen RAG-basierten lokalen Chatbot gebaut, der DeepSeek-R1 und Chroma für das Retrieval nutzt und auf der Grundlage einer großen Wissensdatenbank genaue, kontextreiche Antworten auf Fragen gibt.
Um mehr über DeepSeek zu erfahren, empfehle ich diese Blogs:
Lerne KI mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
