
Programa
Llama Fundamentals
4 h
DeepSeek-R1 é ideal para sistemas baseados em RAG devido ao seu desempenho otimizado, recursos avançados de pesquisa vetorial e flexibilidade em diferentes ambientes, desde configurações locais até implementações dimensionáveis. Aqui estão alguns motivos pelos quais ele é eficaz:
Nosso projeto de demonstração se concentra na criação de um chatbot RAG usando o DeepSeek-R1 e o Gradio.
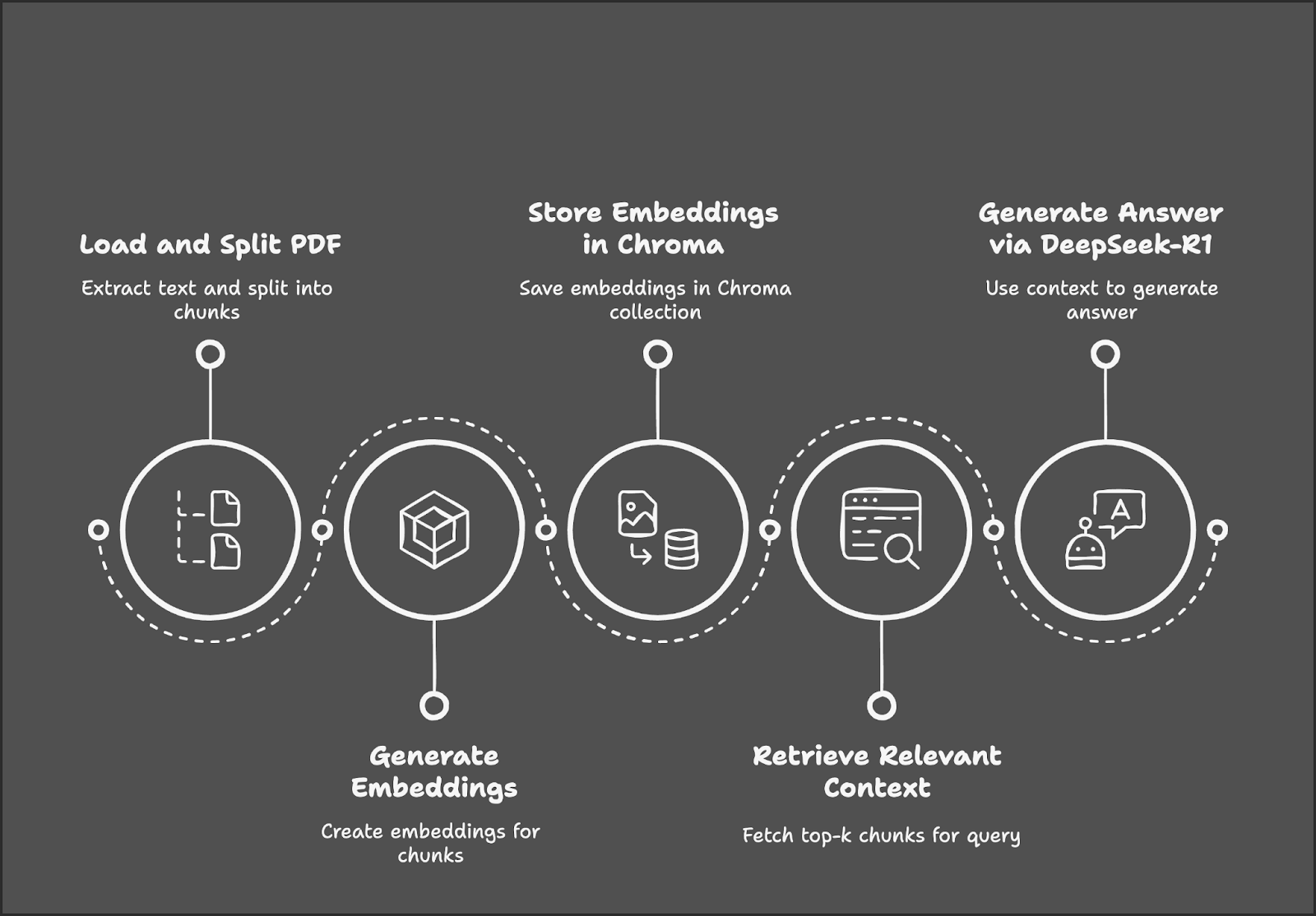
O processo começa com o carregamento e a divisão de um PDF em partes de texto, seguido pela geração de incorporações para esses blocos. Essas incorporações são armazenadas em um banco de dados Chroma para uma recuperação eficiente. Quando um usuário envia uma consulta, o sistema recupera os trechos de texto mais relevantes e usa o DeepSeek-R1 para gerar uma resposta com base no contexto recuperado.
Antes de começarmos, vamos garantir que você tenha as seguintes ferramentas e bibliotecas instaladas:
Execute os seguintes comandos para instalar as dependências necessárias:
!pip install langchain chromadb gradio ollama pymypdf
!pip install -U langchain-communityQuando as dependências acima estiverem instaladas, execute os seguintes comandos de importação:
import ollama
import re
import gradio as gr
from concurrent.futures import ThreadPoolExecutor
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyMuPDFLoader
from langchain_community.embeddings import OllamaEmbeddings
from chromadb.config import Settings
from chromadb import Client
from langchain.vectorstores import ChromaUsaremos o PyMuPDFLoader da LangChain para extrair o texto da versão em PDF do livro Foundations of LLMs (Fundamentos dos LLMs) de Tong Xiao e Jingbo Zhu - esse é um livro com muita matemática, o que significa que nosso chatbot deve ser capaz de explicar bem a matemática por trás dos LLMs. Você pode encontrar o livro no arXiv.
# Load the document using PyMuPDFLoader
loader = PyMuPDFLoader("/path/to/Foundations_of_llms.pdf")
documents = loader.load()Depois que o documento é carregado, podemos começar a dividir o texto em partes para processamento posterior.
Dividiremos o texto extraído em pedaços menores e sobrepostos para melhorar a recuperação do contexto. Você pode variar o tamanho do bloco e a sobreposição do bloco de acordo com seu sistema na função RecursiveCharacterTextSpilitter().
# Split the document into smaller chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
chunks = text_splitter.split_documents(documents)Agora, temos os blocos de texto extraídos que estão prontos para serem convertidos em embeddings.
Usaremos o Ollama Embeddings baseado no DeepSeek-R1 para gerar os embeddings de documentos. Dependendo do tamanho do documento, a geração de incorporação pode ser demorada, portanto, é preferível que você a paralelize para obter um processamento mais rápido.
Observação: por padrão, o site model="deepseek-r1" considera o modelo de parâmetro 7B. Você pode alterá-lo conforme necessário para 8B, 14B, 32B, 70B ou 671B. Substitua o X no nome do modelo a seguir pelo tamanho do modelo: model="deepseek-r1:X"
# Initialize Ollama embeddings using DeepSeek-R1
embedding_function = OllamaEmbeddings(model="deepseek-r1")
# Parallelize embedding generation
def generate_embedding(chunk):
return embedding_function.embed_query(chunk.page_content)
with ThreadPoolExecutor() as executor:
embeddings = list(executor.map(generate_embedding, chunks))A função acima inicializa o DeepSeek-R1 via Ollama para gerar embeddings semânticos de alta dimensão, que serão usados posteriormente para recuperação de documentos com base em similaridade.
A função generate_embedding() pega o texto de um bloco de documento e gera sua incorporação. Por fim, o site ThreadPoolExecutor() aplica o generate_embedding() a cada bloco simultaneamente, coletando embeddings em uma lista para um processamento mais rápido em comparação com a execução sequencial.
Armazenaremos os embeddings e os pedaços de texto correspondentes em um banco de dados vetorial de alto desempenho, o Chroma.
# Initialize Chroma client and create/reset the collection
client = Client(Settings())
client.delete_collection(name="foundations_of_llms") # Delete existing collection (if any)
collection = client.create_collection(name="foundations_of_llms")
# Add documents and embeddings to Chroma
for idx, chunk in enumerate(chunks):
collection.add(
documents=[chunk.page_content],
metadatas=[{'id': idx}],
embeddings=[embeddings[idx]],
ids=[str(idx)] # Ensure IDs are strings
)Começamos seguindo estas etapas para armazenar embeddings:
Client(Settings()) inicializa o cliente Chroma para gerenciar o armazenamento de vetores. client.delete_collection() para evitar erros. Por fim, use client.create_collection() para criar uma nova coleção para armazenar os blocos de documentos e suas incorporações.collection.add() armazena:chunk.page_content){'id': idx}) para fazer referência ao blocoEssa configuração garante que cada bloco de documento seja indexado corretamente para uma recuperação eficiente baseada em vetores.
Inicializaremos o Chroma retriever, garantindo que ele use os mesmos embeddings do DeepSeek-R1 para consultas.
# Initialize retriever using Ollama embeddings for queries
retriever = Chroma(collection_name="foundations_of_llms", client=client, embedding_function=embedding_function).as_retriever()O recuperador Chroma se conecta à coleção "foundations_of_llms" e usa os embeddings do DeepSeek-R1 via Ollama para incorporar as consultas do usuário. Ele recupera os blocos de documentos mais relevantes com base na similaridade de vetores para respostas com reconhecimento de contexto.
Em seguida, recuperaremos os trechos de texto mais relevantes e os formataremos para que o DeepSeek-R1 gere respostas.
def retrieve_context(question):
# Retrieve relevant documents
results = retriever.invoke(question)
# Combine the retrieved content
context = "\n\n".join([doc.page_content for doc in results])
return contextA função retrieve_context incorpora a consulta do usuário usando o DeepSeek-R1 e recupera os principais blocos de documentos relevantes por meio do recuperador Chroma. Em seguida, ele combina o conteúdo dos blocos recuperados em uma única string de contexto para processamento posterior.
Agora, temos a pergunta e o contexto recuperado. Em seguida, envie-o para o DeepSeek-R1 via Ollama para obter a resposta final.
def query_deepseek(question, context):
# Format the input prompt
formatted_prompt = f"Question: {question}\n\nContext: {context}"
# Query DeepSeek-R1 using Ollama
response = embedding_function.chat(
model="deepseek-r1",
messages=[{'role': 'user', 'content': formatted_prompt}]
)
# Clean and return the response
response_content = response['message']['content']
final_answer = re.sub(r'<think>.*?</think>', '', response_content, flags=re.DOTALL).strip()
return final_answerPara obter a resposta final, começamos combinando a pergunta do usuário e o contexto recuperado em um prompt estruturado. Em seguida, envie esse prompt para o modelo DeepSeek-R1 via Ollama para receber uma resposta. Para tornar o resultado final apresentável, removemos as tags desnecessárias e retornamos a resposta final.
Temos nosso pipeline RAG em funcionamento. Agora, usaremos o Gradio para criar uma interface interativa para que os usuários façam perguntas relacionadas à sua base de conhecimento (Foundations of LLMs, neste caso).
def ask_question(question):
# Retrieve context and generate an answer using RAG
context = retrieve_context(question)
answer = query_deepseek(question, context)
return answer
# Set up the Gradio interface
interface = gr.Interface(
fn=ask_question,
inputs="text",
outputs="text",
title="RAG Chatbot: Foundations of LLMs",
description="Ask any question about the Foundations of LLMs book. Powered by DeepSeek-R1."
)
interface.launch()A função ask_question() recupera o contexto relevante usando o Chroma retriever e gera a resposta final por meio do DeepSeek-R1. A interface do Gradio, desenvolvida com o site gr.Interface(), permite que os usuários façam perguntas de forma interativa e recebam respostas contextualmente precisas e fundamentadas.
Parabéns! Agora você tem um chatbot em execução no local, pronto para discutir qualquer coisa relacionada a LLMs.
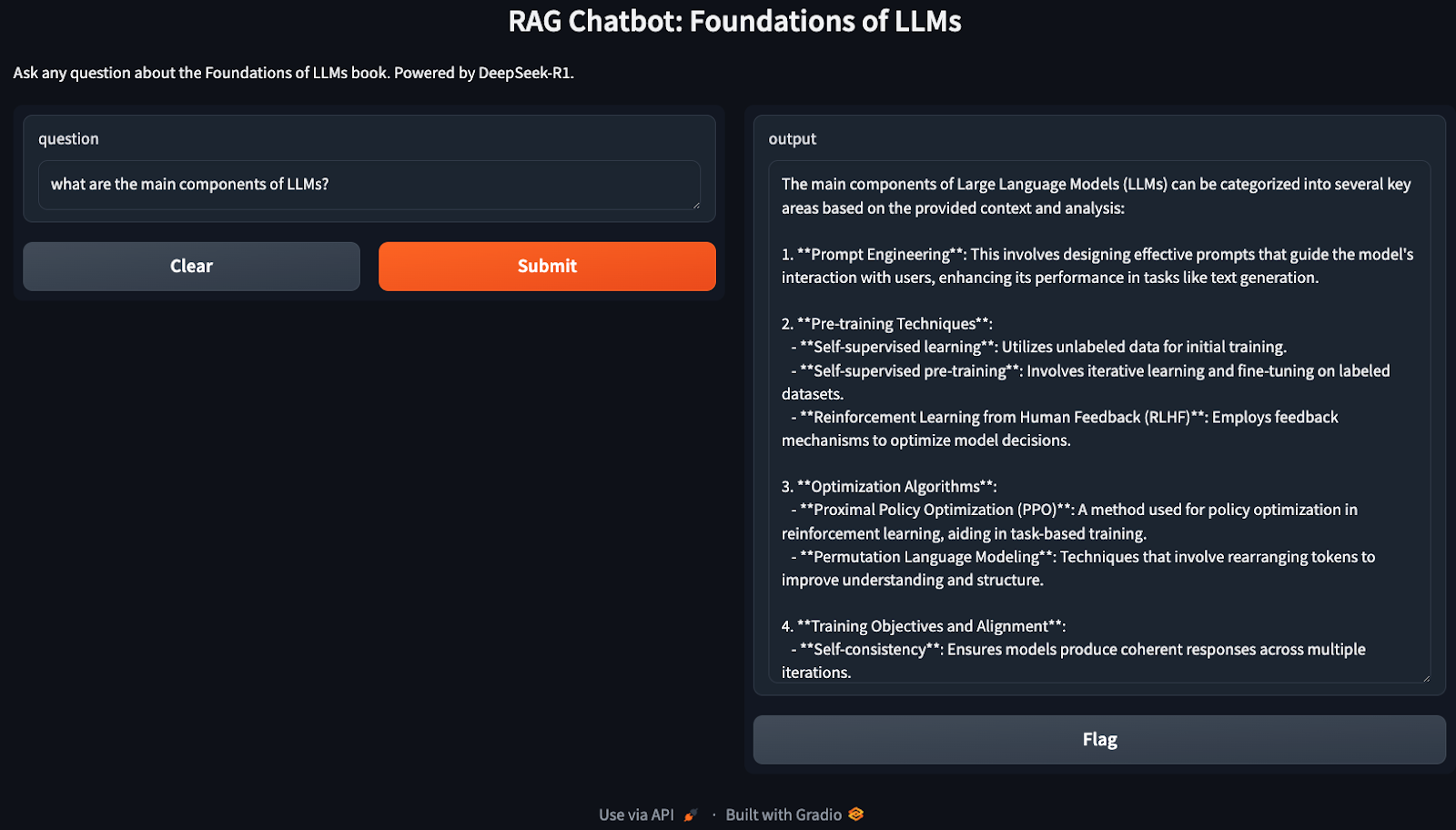
A demonstração acima abrange uma implementação muito básica do RAG, que pode ser otimizada ainda mais para aumentar a eficiência. Aqui estão algumas coisas que você pode experimentar:
chunk_size e chunk_overlap para equilibrar o desempenho e a qualidade da recuperação.Neste tutorial, criamos um chatbot local baseado em RAG usando o DeepSeek-R1 e o Chroma para recuperação, o que garante respostas precisas e contextualmente ricas para perguntas baseadas em uma grande base de conhecimento.
Para saber mais sobre o DeepSeek, recomendo estes blogs:
Aprenda IA com estes cursos!
Programa
Curso
Curso
blog
Javier Canales Luna
14 min
Tutorial
Ryan Ong
Tutorial
Dimitri Didmanidze
Tutorial
Moez Ali
Tutorial
Bex Tuychiev
Tutorial
Abid Ali Awan

