
Track
Llama Fundamentals
4 hr
DeepSeek-R1 is an ideal fit for RAG-based systems due to its optimized performance, advanced vector search capabilities, and flexibility across different environments, from local setups to scalable deployments. Here are some reasons why it’s effective:
Our demo project focuses on building a RAG chatbot using DeepSeek-R1 and Gradio.
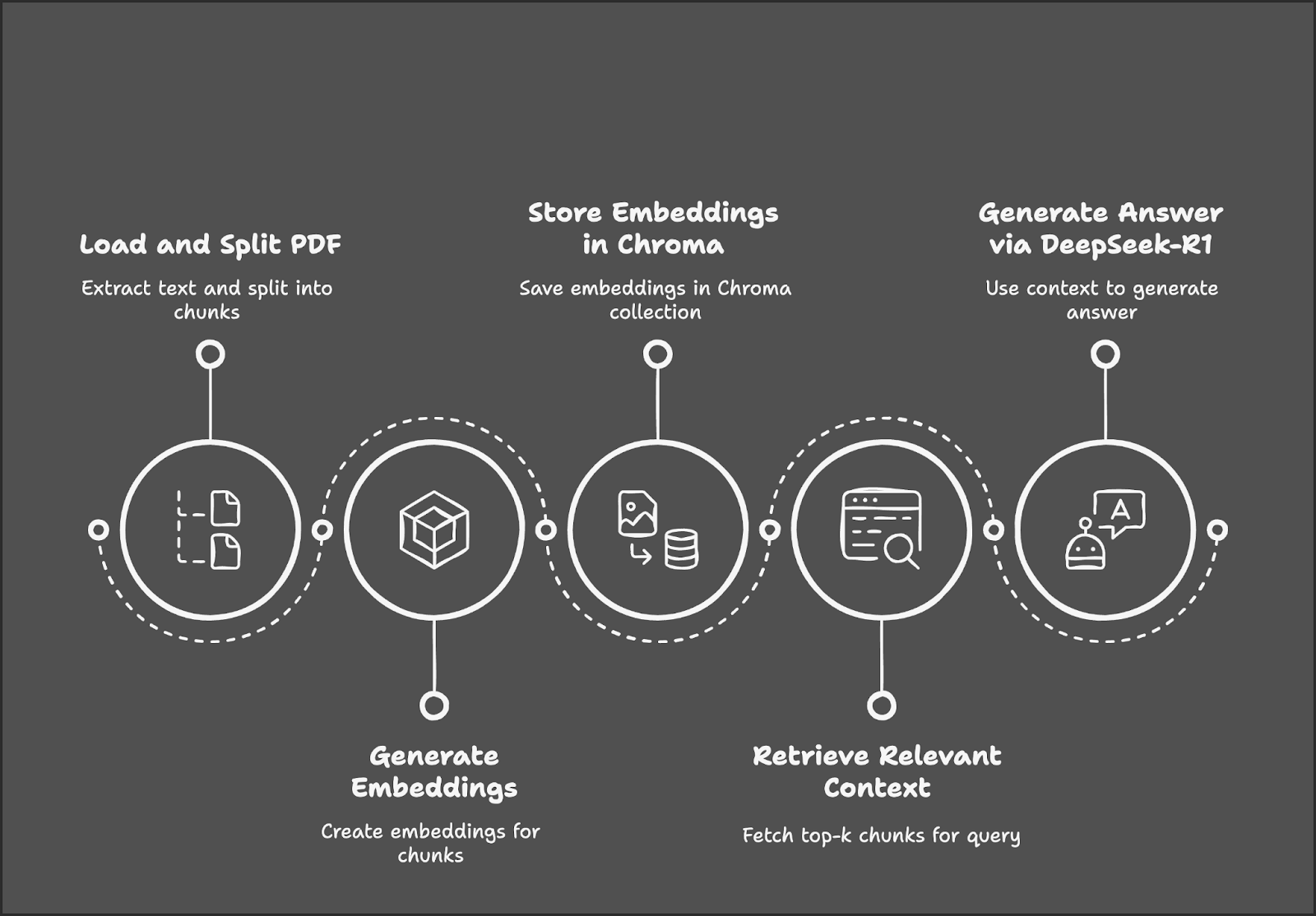
The process begins with loading and splitting a PDF into text chunks, followed by generating embeddings for those chunks. These embeddings are stored in a Chroma database for efficient retrieval. When a user submits a query, the system retrieves the most relevant text chunks and uses DeepSeek-R1 to generate an answer based on the retrieved context.
Before we start, let’s ensure that we have the following tools and libraries installed:
Run the following commands to install the necessary dependencies:
!pip install langchain chromadb gradio ollama pymypdf
!pip install -U langchain-communityOnce the above dependencies are installed, run the following import commands:
import ollama
import re
import gradio as gr
from concurrent.futures import ThreadPoolExecutor
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyMuPDFLoader
from langchain_community.embeddings import OllamaEmbeddings
from chromadb.config import Settings
from chromadb import Client
from langchain.vectorstores import ChromaWe will use LangChain’s PyMuPDFLoader to extract the text from the PDF version of the book Foundations of LLMs by Tong Xiao and Jingbo Zhu—this is a math-heavy book, which means our chatbot should be able to explain well the math behind LLMs. You can find the book on arXiv.
# Load the document using PyMuPDFLoader
loader = PyMuPDFLoader("/path/to/Foundations_of_llms.pdf")
documents = loader.load()Once the document is loaded, we can start dividing the text into chunks for further processing.
We’ll split the extracted text into smaller, overlapping chunks for better context retrieval. You can vary the size of chunk and chunk overlap as per your system within the RecursiveCharacterTextSpilitter() function.
# Split the document into smaller chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
chunks = text_splitter.split_documents(documents)Now, we have the chunks of extracted text which are ready to be converted into embeddings.
We’ll use Ollama Embeddings based on DeepSeek-R1 to generate the document embeddings. Depending on the size of the document, embedding generation can take time, so it's preferable to parallelize it for faster processing.
Note: model="deepseek-r1" by default considers the 7B parameter model. You can change it as required to 8B, 14B, 32B, 70B, or 671B. Replace X in the following model name with model size: model="deepseek-r1:X"
# Initialize Ollama embeddings using DeepSeek-R1
embedding_function = OllamaEmbeddings(model="deepseek-r1")
# Parallelize embedding generation
def generate_embedding(chunk):
return embedding_function.embed_query(chunk.page_content)
with ThreadPoolExecutor() as executor:
embeddings = list(executor.map(generate_embedding, chunks))The above function initializes DeepSeek-R1 via Ollama to generate high-dimensional semantic embeddings, which will later be used for similarity-based document retrieval.
The generate_embedding() function takes a document chunk’s text and generates its embedding. Finally, ThreadPoolExecutor() applies generate_embedding() to each chunk concurrently, collecting embeddings into a list for faster processing compared to sequential execution.
We’ll store the embeddings and corresponding text chunks in a high-performance vector database, Chroma.
# Initialize Chroma client and create/reset the collection
client = Client(Settings())
client.delete_collection(name="foundations_of_llms") # Delete existing collection (if any)
collection = client.create_collection(name="foundations_of_llms")
# Add documents and embeddings to Chroma
for idx, chunk in enumerate(chunks):
collection.add(
documents=[chunk.page_content],
metadatas=[{'id': idx}],
embeddings=[embeddings[idx]],
ids=[str(idx)] # Ensure IDs are strings
)We start by following these steps to store embeddings:
Client(Settings()) initializes the Chroma client to manage the vector store. client.delete_collection() to avoid running into errors. Finally, use client.create_collection() to create a new collection to store the document chunks and their embeddings.collection.add() stores:chunk.page_content){'id': idx}) to reference the chunkThis setup ensures that each document chunk is indexed correctly for efficient vector-based retrieval.
We’ll initialize the Chroma retriever, ensuring it uses the same DeepSeek-R1 embeddings for queries.
# Initialize retriever using Ollama embeddings for queries
retriever = Chroma(collection_name="foundations_of_llms", client=client, embedding_function=embedding_function).as_retriever()The Chroma retriever connects to the "foundations_of_llms" collection and uses DeepSeek-R1 embeddings via Ollama to embed user queries. It retrieves the most relevant document chunks based on vector similarity for context-aware responses.
Next, we’ll retrieve the most relevant chunks of text and format them for DeepSeek-R1 to generate answers.
def retrieve_context(question):
# Retrieve relevant documents
results = retriever.invoke(question)
# Combine the retrieved content
context = "\n\n".join([doc.page_content for doc in results])
return contextThe retrieve_context function embeds the user query using DeepSeek-R1 and retrieves the top relevant document chunks via the Chroma retriever. It then combines the content of the retrieved chunks into a single context string for further processing.
Now, we have the question and retrieved context. Next, send it to DeepSeek-R1 via Ollama for our final answer.
def query_deepseek(question, context):
# Format the input prompt
formatted_prompt = f"Question: {question}\n\nContext: {context}"
# Query DeepSeek-R1 using Ollama
response = embedding_function.chat(
model="deepseek-r1",
messages=[{'role': 'user', 'content': formatted_prompt}]
)
# Clean and return the response
response_content = response['message']['content']
final_answer = re.sub(r'<think>.*?</think>', '', response_content, flags=re.DOTALL).strip()
return final_answerTo get the final answer, we start with combining user question and retrieved context into a structured prompt. Then send this prompt to the DeepSeek-R1 model via Ollama to receive a response. To make the final output presentable, we remove unnecessary tags and return the final answer.
We have our RAG pipeline in place. Now, we’ll use Gradio to create an interactive interface for users to ask questions related to its knowledge base (Foundations of LLMs in this case).
def ask_question(question):
# Retrieve context and generate an answer using RAG
context = retrieve_context(question)
answer = query_deepseek(question, context)
return answer
# Set up the Gradio interface
interface = gr.Interface(
fn=ask_question,
inputs="text",
outputs="text",
title="RAG Chatbot: Foundations of LLMs",
description="Ask any question about the Foundations of LLMs book. Powered by DeepSeek-R1."
)
interface.launch()The ask_question() function retrieves relevant context using the Chroma retriever and generates the final answer via DeepSeek-R1. The Gradio interface, built with gr.Interface(), enables users to ask questions interactively and receive contextually accurate, grounded answers.
Congrats! You now have a locally running chatbot ready to discuss anything related to LLMs.
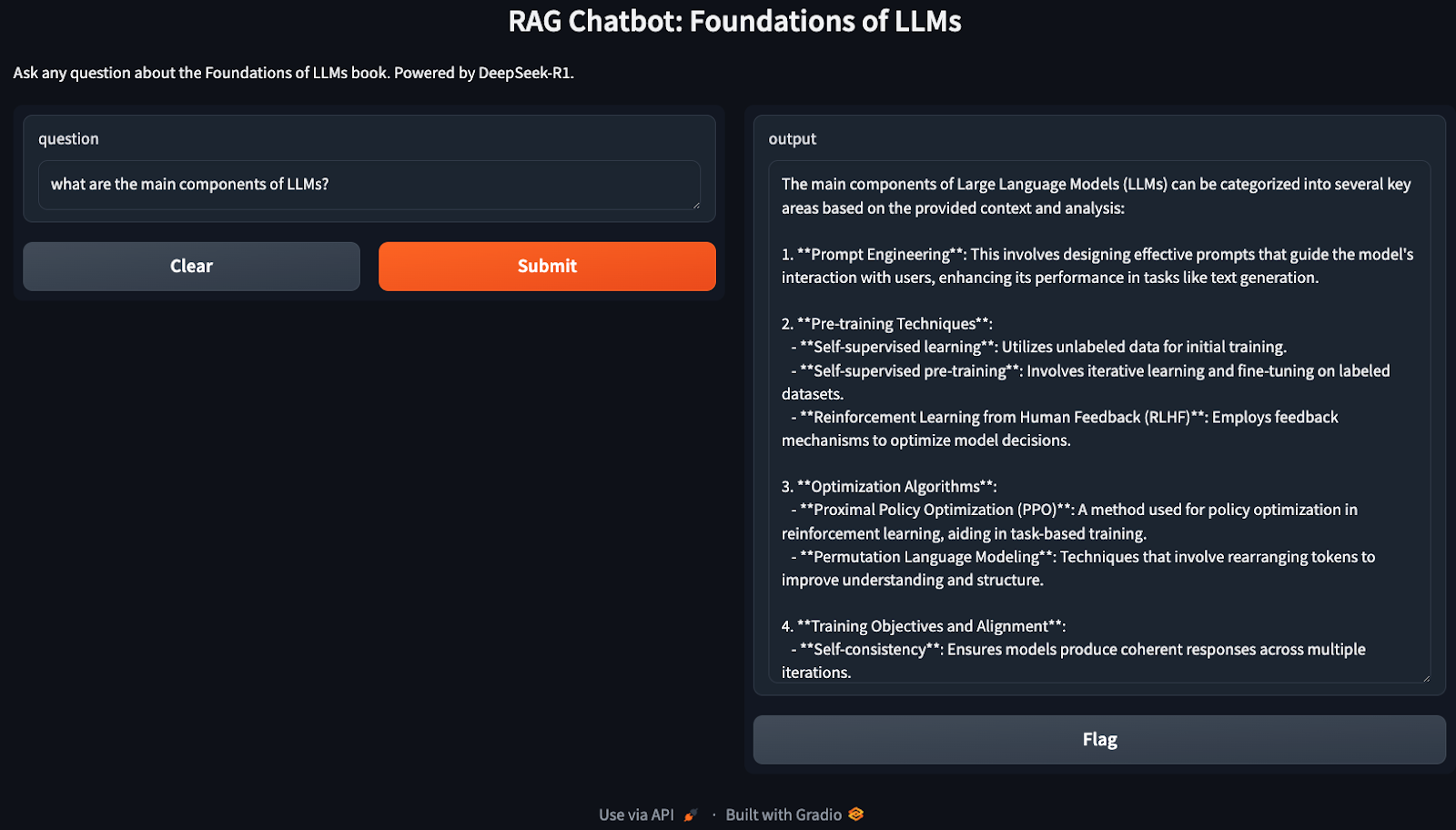
The above demo covers a very basic implementation of RAG, which can be optimized further for efficiency. Here are a few things to try:
chunk_size and chunk_overlap parameters to balance performance and retrieval quality.In this tutorial, we built a RAG-based local chatbot using DeepSeek-R1 and Chroma for retrieval, which ensures accurate, contextually rich answers to questions based on a large knowledge base.
To learn more about DeepSeek, I recommend these blogs:
Learn AI with these courses!
Track
Course
Course
Tutorial
Aashi Dutt
Tutorial
Aashi Dutt
Tutorial
Ryan Ong
Tutorial
Aashi Dutt
Tutorial
Ryan Ong
code-along
Dan Becker
