
Kurs
Entwickeln von LLM-Anwendungen mit LangChain
3 Std.
46.3K
In diesem Tutorial lernst du, wie du das Gemma 2-Modell anhand des Patient-Arzt-Gesprächsdatensatzes fein abstimmst. Wir werden das Modell auch in das GGUF-Format konvertieren, damit es lokal auf dem Laptop offline verwendet werden kann.
Wir werden Gemma 2 und seine Verbesserungen gegenüber früheren Generationen kennenlernen, bevor wir das Gemma 2-Modell anhand des Patient-Arzt-Konversionsdatensatzes feinabstimmen. Dann fügen wir den gespeicherten Adapter mit dem Basismodell zusammen, schieben das vollständige Modell zum Hugging Face Hub und verwenden einen Hugging Face Space, um das Modell zu konvertieren und zu quantisieren. Schließlich laden wir das quantisierte Modell herunter und verwenden es lokal mit der Jan-Anwendung.

Bild vom Autor
Gemma 2 ist die neueste Version in der Gemma-Familie der offenen großen Sprachmodelle (LLMs) von Google. Es steht Forschern und Entwicklern in zwei Größen, 9 Milliarden (9B) und 27 Milliarden (27B) Parameter, unter einer kommerziell günstigen Lizenz zur Verfügung. Das bedeutet, dass du es auf deinem privaten Datensatz feinabstimmen und das feinabgestimmte Modell ohne Einschränkungen in der Produktion einsetzen kannst.
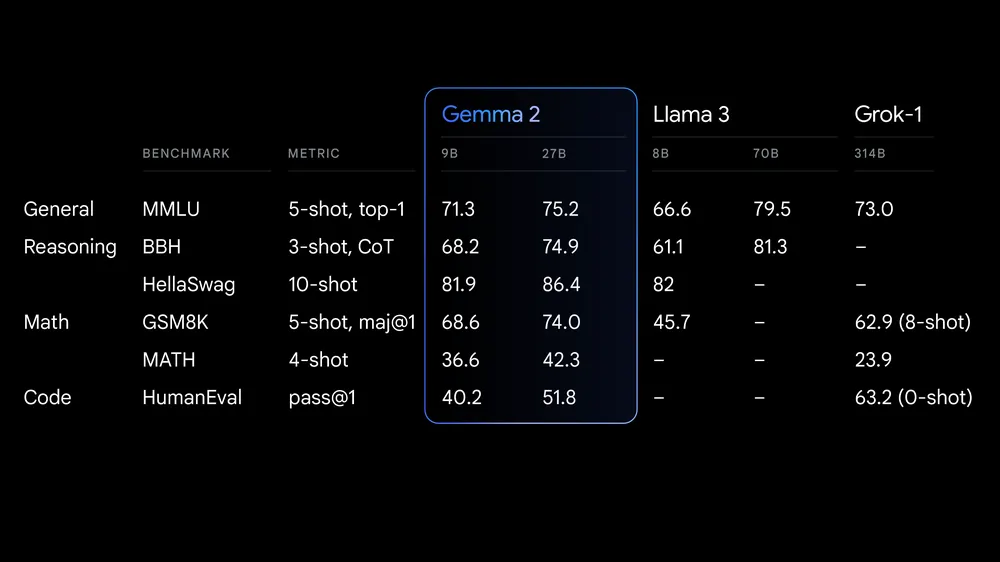
Quelle: Google launches Gemma 2
Gemma 2 bietet deutliche Verbesserungen in Bezug auf Leistung und Inferenz-Effizienz. Die neu gestaltete Architektur sorgt für blitzschnelle Inferenzen auf verschiedenen Hardwarekonfigurationen und eine nahtlose Integration mit wichtigen KI-Frameworks wie Hugging Face Transformers, JAX, PyTorch und TensorFlow.
Gemma 2 enthält außerdem robuste Sicherheitsmaßnahmen und Werkzeuge für den ethischen KI-Einsatz. Es übertrifft das Llama 3 und Groq-1 in verschiedenen Benchmarks und verfügt über eine verbesserte Keras 3-Integration für nahtlose Feinabstimmung und Modellinferenz.
Wenn du mehr über die erste Generation der Gemma-Modelle erfahren möchtest, ist unser Tutorial Fine Tuning Google Gemma eine gute Ressource : Verbesserung der LLMs mit maßgeschneiderten Anweisungen. Diese Ressource bietet eine umfassende Anleitung zur Feinabstimmung von Gemma-Modellen, wie z. B. Gemma 7b-it, für bestimmte Datensätze und Aufgaben.
In diesem Abschnitt werden wir das Modell herunterladen, es in 4-Bit-Quantisierung laden und dann die Inferenz auf einer GPU ausführen.
%%capture
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U accelerate
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)Hinweis: Das Modell Gemma 2 9B-It ist groß und selbst mit 16 GB GPU-Speicher können wir nicht das gesamte Modell laden. Deshalb laden wir das Modell in 4-Bit Quantisierung.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig, AutoConfig
modelName = "google/gemma-2-9b-it"
bnbConfig = BitsAndBytesConfig(
load_in_4bit = True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
tokenizer = AutoTokenizer.from_pretrained(modelName)
model = AutoModelForCausalLM.from_pretrained(
modelName,
device_map = "auto",
quantization_config=bnbConfig
)from IPython.display import Markdown, display
system = "You are a skilled software architect who consistently creates system designs for various applications."
user = "Design a system with the ASCII diagram for the customer support application."
prompt = f"System: {system} \n User: {user} \n AI: "
inputs = tokenizer(prompt, return_tensors='pt', padding=True, truncation=True).to("cuda")
outputs = model.generate(**inputs, max_length=500, num_return_sequences=1)
text = tokenizer.decode(outputs[0], skip_special_tokens=True)
Markdown(text.split("AI:")[1])Wie wir sehen können, hat das Modell Gemma 2 gute Arbeit geleistet.
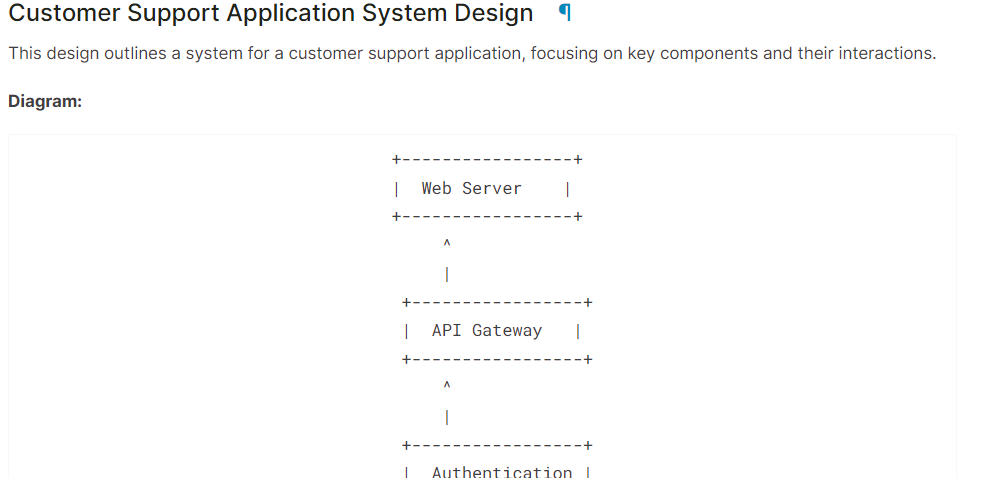
Wenn du Probleme hast, den obigen Code auszuführen, schau bitte im Kaggle Notebook nach: Gemma 2 Einfache Inferenz auf der GPU.
In diesem Abschnitt werden wir das Gemma 2 9B-It Modell mit dem Gesundheitswesen-Datensatzder aus Gesprächen zwischen Patienten und Ärzten besteht. Wir laden das Modell und den Tokenizer, laden den Datensatz, konvertieren den Datensatz, richten das Modell mit Hilfe von Trainingsargumenten ein und verfolgen die Leistung des Modells mit Hilfe der Weights and Biases API.
Wenn du verstehen willst, wie die Feinabstimmungstheorie funktioniert, lies unseren Leitfaden, Einleitender Leitfaden zum Fine-Tuning LLMs.
Installiere die notwendigen Python-Pakete, um das Modell zu laden, zu verfeinern und auf dem medizinischen Datensatz auszuwerten.
%%capture
%pip install -U transformers
%pip install -U datasets
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes
%pip install -U wandbLade die notwendigen Python-Pakete und die Funktionen.
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
HfArgumentParser,
TrainingArguments,
pipeline,
logging,
)
from peft import (
LoraConfig,
PeftModel,
prepare_model_for_kbit_training,
get_peft_model,
)
import os, torch, wandb
from datasets import load_dataset
from trl import SFTTrainer, setup_chat_formatMelde dich bei Hugging Face CLI mit dem API-Schlüssel an, den wir mit den Kaggle Secrets gespeichert haben.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)
Lade den API-Schlüssel für Gewichte und Verzerrungen aus den Kaggle-Geheimnissen, um das Projekt für die Verfolgung der Modellleistung zu starten.
wb_token = user_secrets.get_secret("wandb")
wandb.login(key=wb_token)
run = wandb.init(
project='Fine-tune Gemma-2-9b-it on HealthCare Dataset',
job_type="training",
anonymous="allow"
)Einstellen der Modell- und Datensatz-ID, damit wir sie vom Hugging Face Hub laden können. Außerdem müssen wir den Namen des feinabgestimmten Modells festlegen, um ein Modell-Repository auf Hugging Face zu erstellen und das feinabgestimmte Modell zu pushen.
base_model = "google/gemma-2-9b-it"
dataset_name = "lavita/ChatDoctor-HealthCareMagic-100k"
new_model = "Gemma-2-9b-it-chat-doctor"Einstellen des Datentyps und der Aufmerksamkeitsimplementierung auf Basis der GPU.
if torch.cuda.get_device_capability()[0] >= 8:
!pip install -qqq flash-attn
torch_dtype = torch.bfloat16
attn_implementation = "flash_attention_2"
else:
torch_dtype = torch.float16
attn_implementation = "eager"Wir müssen die QLoRA-Konfiguration so erstellen, dass wir das Modell mit 4-Bit-Präzision laden können, um den Speicherbedarf zu verringern und den Feinabstimmungsprozess zu beschleunigen.
# QLoRA config
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch_dtype,
bnb_4bit_use_double_quant=True,
)
Nutze die Modell-URL, die LoRA-Konfiguration und die Aufmerksamkeitsimplementierung, um das Gemma 2 9B-It-Modell und den Tokenizer zu laden.
# Load model
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=bnb_config,
device_map="auto",
attn_implementation=attn_implementation
)
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(base_model, trust_remote_code=True)Erstelle die Python-Funktion, die das Modell verwendet und die Namen aller linearen Module extrahiert.
import bitsandbytes as bnb
def find_all_linear_names(model):
cls = bnb.nn.Linear4bit
lora_module_names = set()
for name, module in model.named_modules():
if isinstance(module, cls):
names = name.split('.')
lora_module_names.add(names[0] if len(names) == 1 else names[-1])
if 'lm_head' in lora_module_names: # needed for 16 bit
lora_module_names.remove('lm_head')
return list(lora_module_names)
modules = find_all_linear_names(model)Die Feinabstimmung des vollständigen Modells wird viel Zeit in Anspruch nehmen. Um den Trainingsprozess zu beschleunigen, erstellen wir die Adapterschicht und fügen sie hinzu, was zu einem schnelleren und speichereffizienteren Prozess führt.
Die Adoptionsschicht wird mithilfe der Zielmodule und des Aufgabentyps erstellt. Als Nächstes richten wir das Chat-Format für das Modell und den Tokenizer ein. Schließlich verbinden wir das Basismodell mit dem Adapter, um ein Parameter Efficient Fine-Tuning (PEFT) Modell zu erstellen.
# LoRA config
peft_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules=modules
)
model, tokenizer = setup_chat_format(model, tokenizer)
model = get_peft_model(model, peft_config)Wir laden nun die lavita/ChatDoctor-HealthCareMagic-100k Datensatz aus dem Hugging Face Hub. Der Datensatz besteht aus drei Spalten:
Nachdem wir den Datensatz geladen haben, mischen wir ihn und wählen 1000 Stichproben aus, um die Trainingszeit noch weiter zu verkürzen. Zum Schluss erstellen wir das Chat-Format mit der Standard-Chat-Vorlage und verwenden sie, um die Spalte "Text" zu erstellen.
#Importing the dataset
dataset = load_dataset(dataset_name, split="all")
dataset = dataset.shuffle(seed=65).select(range(1000)) # Only use 1000 samples for quick demo
def format_chat_template(row):
row_json = [{"role": "system", "content": row["instruction"]},
{"role": "user", "content": row["input"]},
{"role": "assistant", "content": row["output"]}]
row["text"] = tokenizer.apply_chat_template(row_json, tokenize=False)
return row
dataset = dataset.map(
format_chat_template,
num_proc= 4,
)
datasetAusgabe:
Dataset({
features: ['instruction', 'input', 'output', 'text'],
num_rows: 1000
})Sehen wir uns die Spalte "Text" in Zeile 3 an.
dataset['text'][3]Die Spalte "Text" enthält Anweisungen, die Frage des Patienten und die Antwort des Arztes im OpenAI-Stil.

Für die Modellbewertung teilen wir den Datensatz in einen Trainings- und einen Testdatensatz auf.
dataset = dataset.train_test_split(test_size=0.1)Wir legen nun das Trainingsargument und die STF-Parameter fest und starten dann den Trainingsprozess.
Du kannst die verschiedenen Hyperparameter je nach Umgebung, Rechenleistung und Speicherplatz ändern. Die Hyperparameter unten sind für das Kaggle Notebook optimiert. Wenn du also dasselbe mit Google Colab machen willst, solltest du mit Trainingsalgorithmen experimentieren.
# Setting Hyperparamter
training_arguments = TrainingArguments(
output_dir=new_model,
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=2,
optim="paged_adamw_32bit",
num_train_epochs=1,
eval_strategy="steps",
eval_steps=0.2,
logging_steps=1,
warmup_steps=10,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
report_to="wandb"
)
# Setting sft parameters
trainer = SFTTrainer(
model=model,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
peft_config=peft_config,
max_seq_length= 512,
dataset_text_field="text",
tokenizer=tokenizer,
args=training_arguments,
packing= False,
)
model.config.use_cache = False
trainer.train()Die Feinabstimmung des Modells hat fast 25 Minuten gedauert, und wie wir sehen können, hat sich der Trainings- und Validierungsverlust allmählich verringert. Um eine bessere Leistung zu erzielen, solltest du das Modell mindestens drei Epochen lang mit dem gesamten Datensatz feinabstimmen.
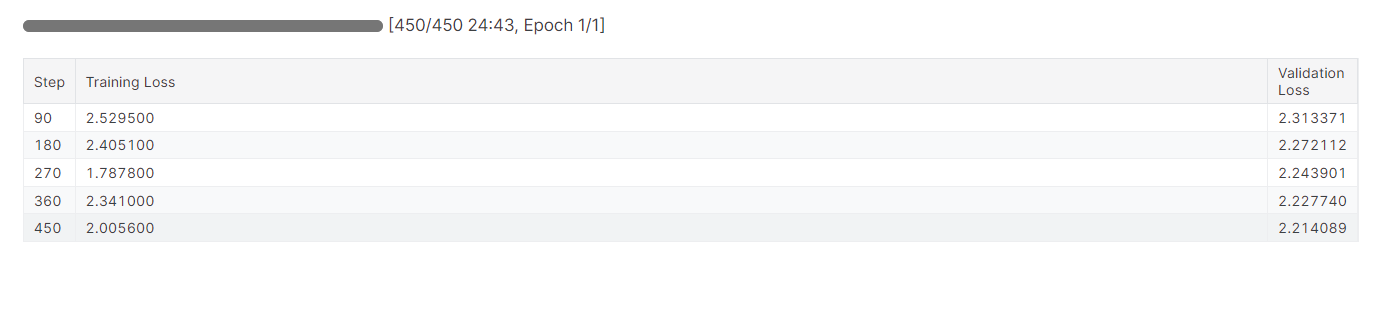 Die Feinabstimmung kann für Anfänger und technisch nicht versierte Personen ein wenig technisch sein. Wenn du nach einer einfacheren Lösung suchst, solltest du dir das Fine-Tuning OpenAI's GPT-4 ansehen: Eine Schritt-für-Schritt-Anleitung tutorial. Es geht um eine einfache Möglichkeit, ein hochmodernes Modell mit Hilfe der OpenAI API zu verfeinern.
Die Feinabstimmung kann für Anfänger und technisch nicht versierte Personen ein wenig technisch sein. Wenn du nach einer einfacheren Lösung suchst, solltest du dir das Fine-Tuning OpenAI's GPT-4 ansehen: Eine Schritt-für-Schritt-Anleitung tutorial. Es geht um eine einfache Möglichkeit, ein hochmodernes Modell mit Hilfe der OpenAI API zu verfeinern.
Wir werden das Experiment "Gewichte und Verzerrungen" beenden und einen Auswertungsbericht erstellen.
wandb.finish()
model.config.use_cache = True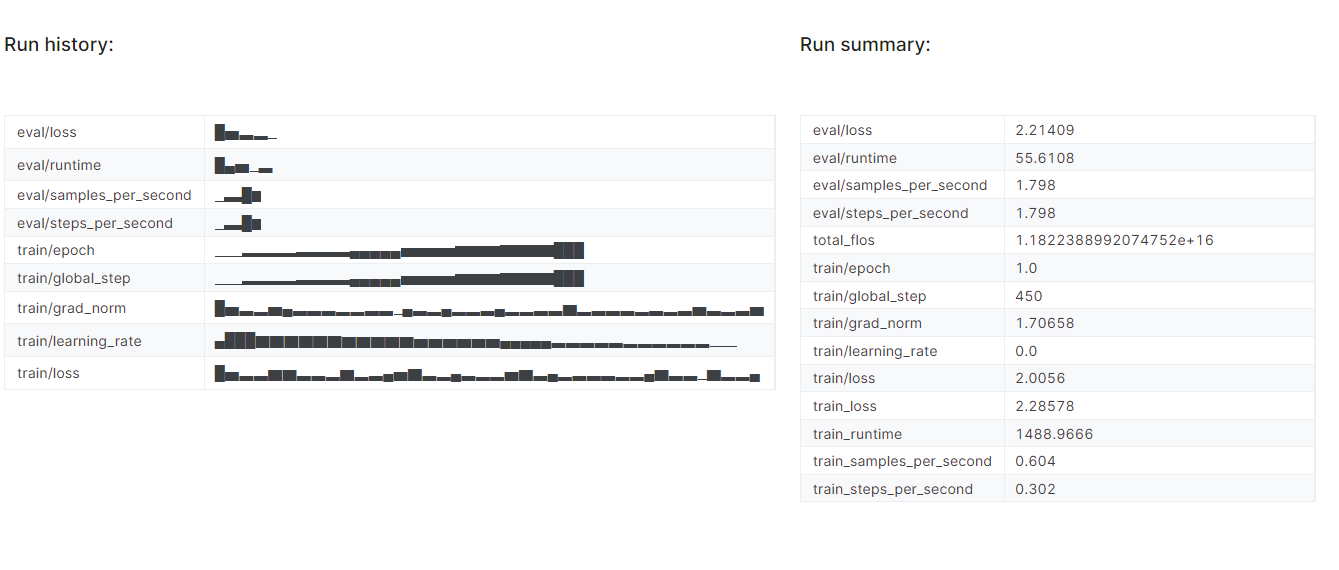
Um den detaillierten Bericht anzuzeigen, gehe zu deinem Weights and Biases-Konto und klicke auf "Fine-tune Gemma-2-9b-it on Healthcare Dataset". Projektname.
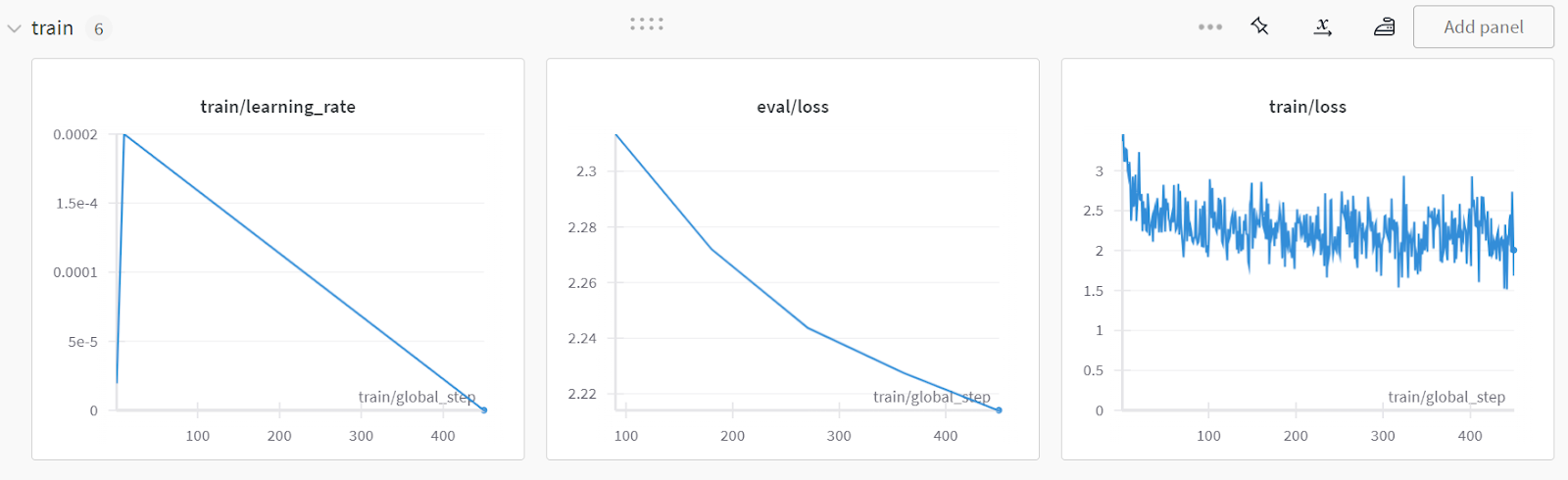
Der Screenshot stammt von wandb.ai
Wir speichern nun den feinabgestimmten Adopter lokal und pushen ihn auch an den Hugging Face Hub.
trainer.model.save_pretrained(new_model)
trainer.model.push_to_hub(new_model, use_temp_dir=False)Um den gespeicherten Adopter in einem anderen Kaggle-Notizbuch zu verwenden, müssen wir das Notizbuch speichern. Das können wir tun, indem wir oben rechts auf "Version speichern" klicken. Danach wählst du "Schnellspeicherung" und "Ausgabe beim Erstellen einer Schnellspeicherung immer speichern" und drückst dann auf "Speichern".
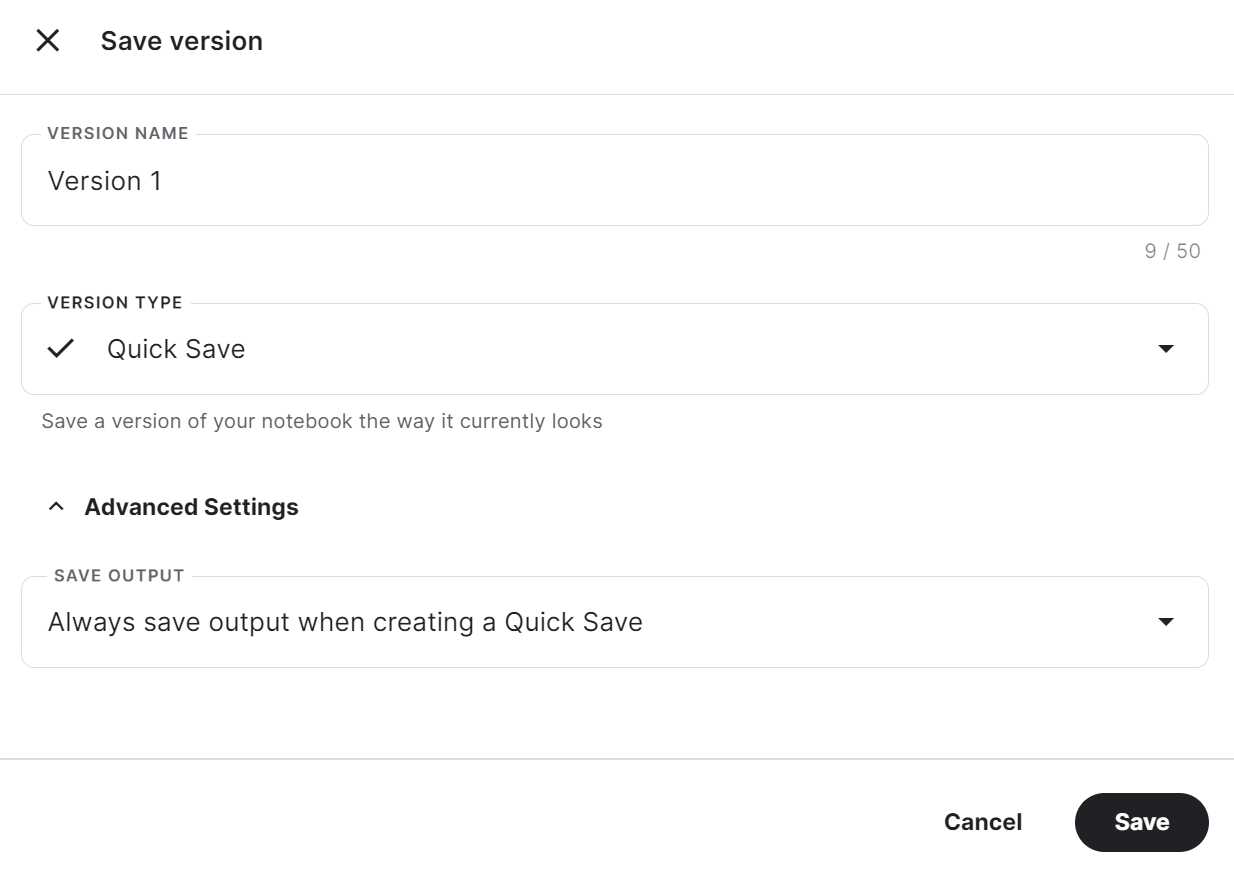
Wenn du Probleme beim Ausführen des Codes hast, klone bitte das Kaggle-Notizbuch und führe es aus. Du musst den API-Schlüssel für Hugging Face und Weights & Biases über die Kaggle Secrets einrichten.
Um herauszufinden, ob Fine-Tuning oder Retrieval-Augmented Generation (RAG) für deinen speziellen Anwendungsfall besser geeignet ist, empfehle ich dir, den RAG vs. Feinabstimmung Blog zu lesen.
Jetzt fügen wir den Adapter mit dem Basismodell zusammen und schieben das vollständige Modell zum Hugging Face Hub.
Erstelle ein neues Kaggle-Notebook mit einer CPU als Beschleuniger und installiere die notwendigen Python-Pakete.
Warum benutzen wir die CPU als Beschleuniger? Wird es nicht zu langsam sein? Ja, aber die GPU-Maschine bei Kaggle stellt uns nur 16 GB GPU-Speicher zur Verfügung, was für ein Modell mit 7 Milliarden Parametern ausreicht, aber nicht für ein Modell mit 9 Milliarden Parametern. Die CPU-Maschine bietet 30 GB, was genug ist, um sowohl das Basismodell als auch den Adapter zu laden.
%%capture
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U accelerate
%pip install -U peft
%pip install -U trlHol dir den API-Schlüssel von den Kaggle Secrets und melde dich bei der Hugging Face CLI an.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)Um auf das gespeicherte Modell zuzugreifen, musst du das gespeicherte Kaggle-Notizbuch importieren. Klicke dazu oben rechts auf die Schaltfläche "Eingabe hinzufügen" und wähle den Reiter "Deine Arbeit". Klicke dann auf den Plus-Button des gespeicherten Notizbuchs, um auf alle darin enthaltenen Dateien zuzugreifen.
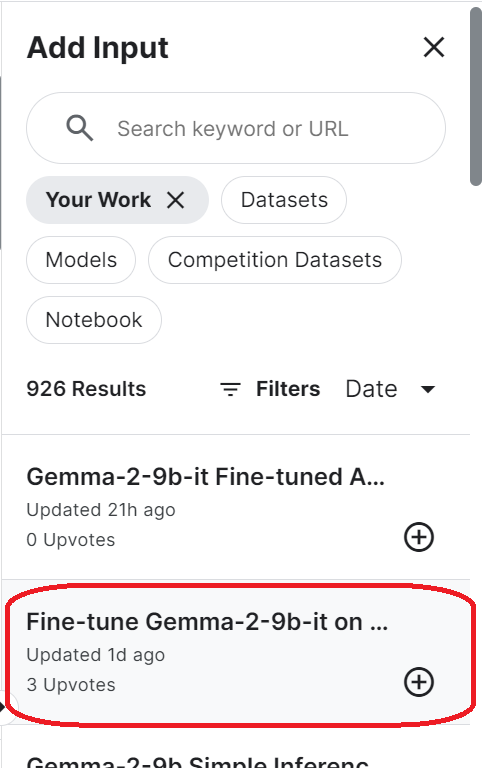
Richte die URL des Basismodells ein, indem du den Namen des Hugging Face-Repository angibst. Außerdem konfigurierst du die URL des Adapters, indem du das lokale Verzeichnis angibst, in dem der Adapter gespeichert ist.
base_model_url = "google/gemma-2-9b-it"
new_model_url = "/kaggle/input/fine-tune-gemma-2-9b-it-on-healthcare-dataset/Gemma-2-9b-it-chat-doctor/"Lade den Tokenizer und das vollständige Modell über die URL des Basismodells. Stelle sicher, dass du das Gerät "cpu" und dtype "float16" einstellst.
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig, pipeline
from peft import PeftModel
import torch
from trl import setup_chat_format
# Reload tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(base_model_url)
base_model_reload= AutoModelForCausalLM.from_pretrained(
base_model_url,
low_cpu_mem_usage=True,
return_dict=True,
torch_dtype=torch.float16,
device_map="cpu",
)Setze das Chatformat auf das neu geladene Basismodell und kombiniere es mit dem Adopter. Am Ende laden wir den Adopter und fügen ihn mit dem Basismodell zusammen.
Die Funktion merge_and_unload() hilft uns dabei, die Adaptergewichte mit dem Basismodell zu verschmelzen und es als eigenständiges Modell zu verwenden.
base_model_reload, tokenizer = setup_chat_format(base_model_reload, tokenizer)
model = PeftModel.from_pretrained(base_model_reload, new_model_url)
model = model.merge_and_unload()Speichere das vollständige Modell und den Tokenizer lokal.
model.save_pretrained("Gemma-2-9b-it-chat-doctor")
tokenizer.save_pretrained("Gemma-2-9b-it-chat-doctor")Schiebe außerdem alle Modelldateien und den Tokenizer in den Hugging Face Hub.
model.push_to_hub("Gemma-2-9b-it-chat-doctor", use_temp_dir=False)
tokenizer.push_to_hub("Gemma-2-9b-it-chat-doctor", use_temp_dir=False)Du kannst zu deinem Hugging Face Modell-Repository gehen und alle Dateien ansehen.
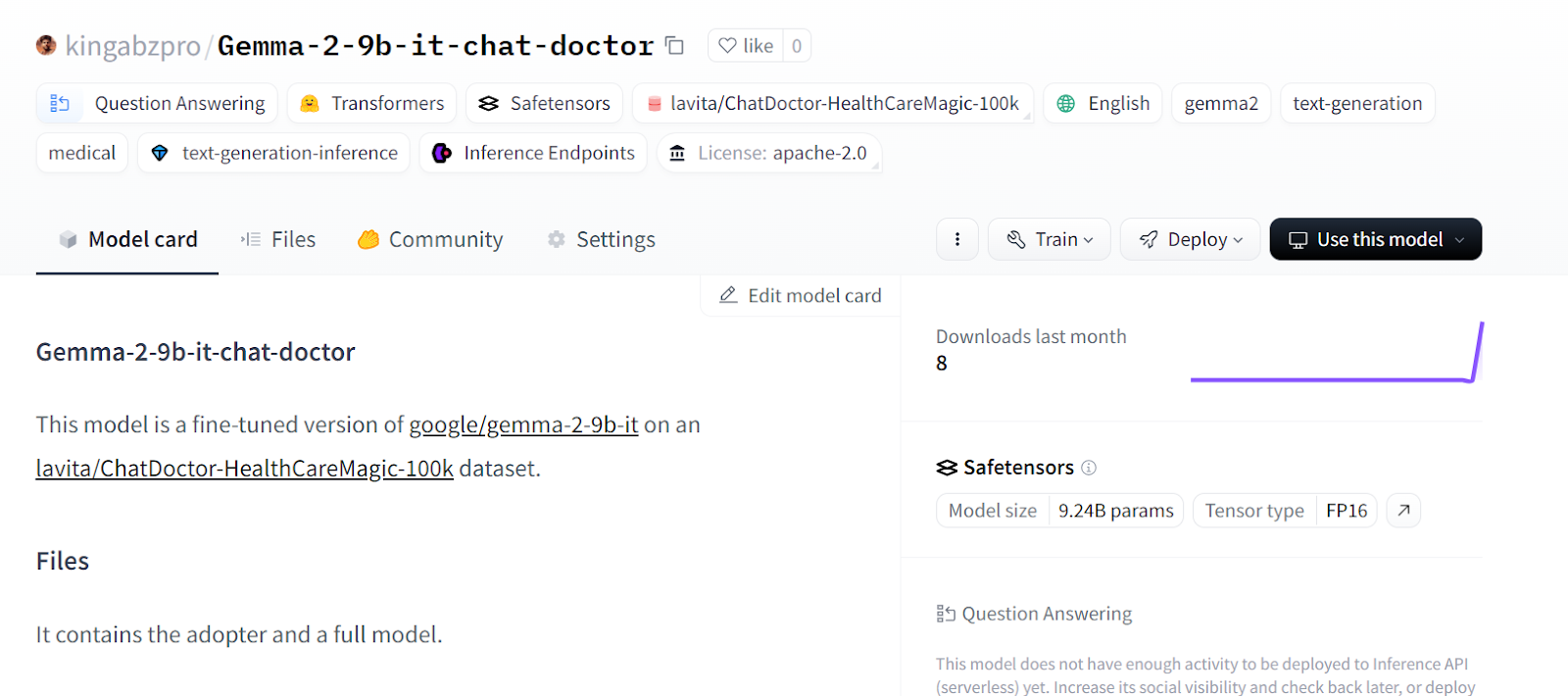
Quelle: kingabzpro/Gemma-2-9b-it-chat-doctor - Hugging Face
Wenn du Probleme beim Zusammenführen von Modellen mit der CPU hast, sieh dir bitte das Kaggle Notizbuch.
Mit der GGUF My Repo Hugging Face Space ist die Modellkonvertierung und Quantisierung einfach und schnell geworden. Alles, was du tun musst, ist dich einzuloggen und die Modell-ID anzugeben.
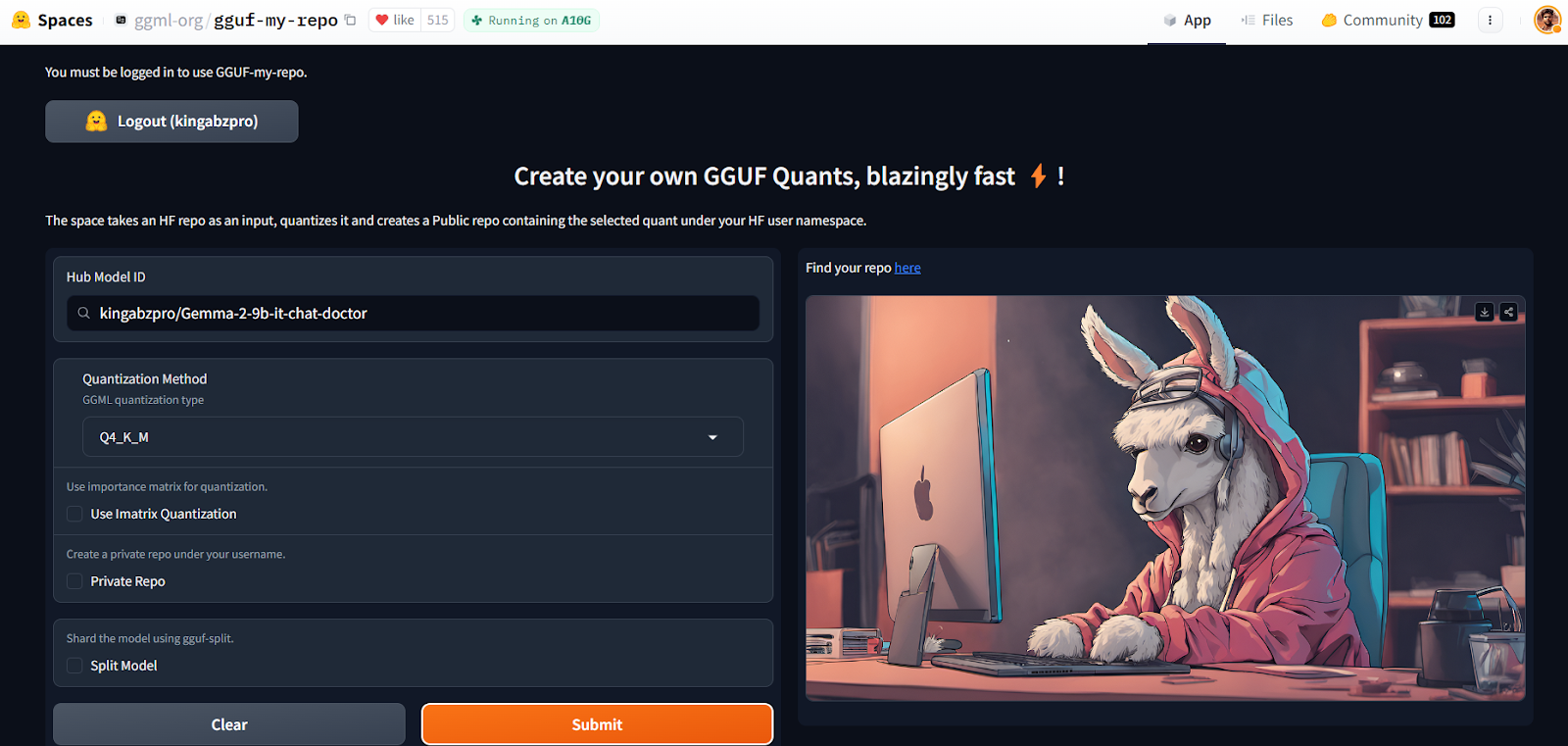
Quelle: GGUF My Repo - a Hugging Face Space by ggml-org
Es erstellt für dich ein neues Modell-Repository mit einer quantisierten Modelldatei, die du später herunterladen kannst, um sie lokal zu verwenden. So einfach ist das.
Die Theorie hinter der Quantisierung kannst du in unserem Artikel Quantisierung für große Sprachmodelle (LLMs) nachlesen : Reduziere die Größe von KI-Modellen auf effiziente Weise.
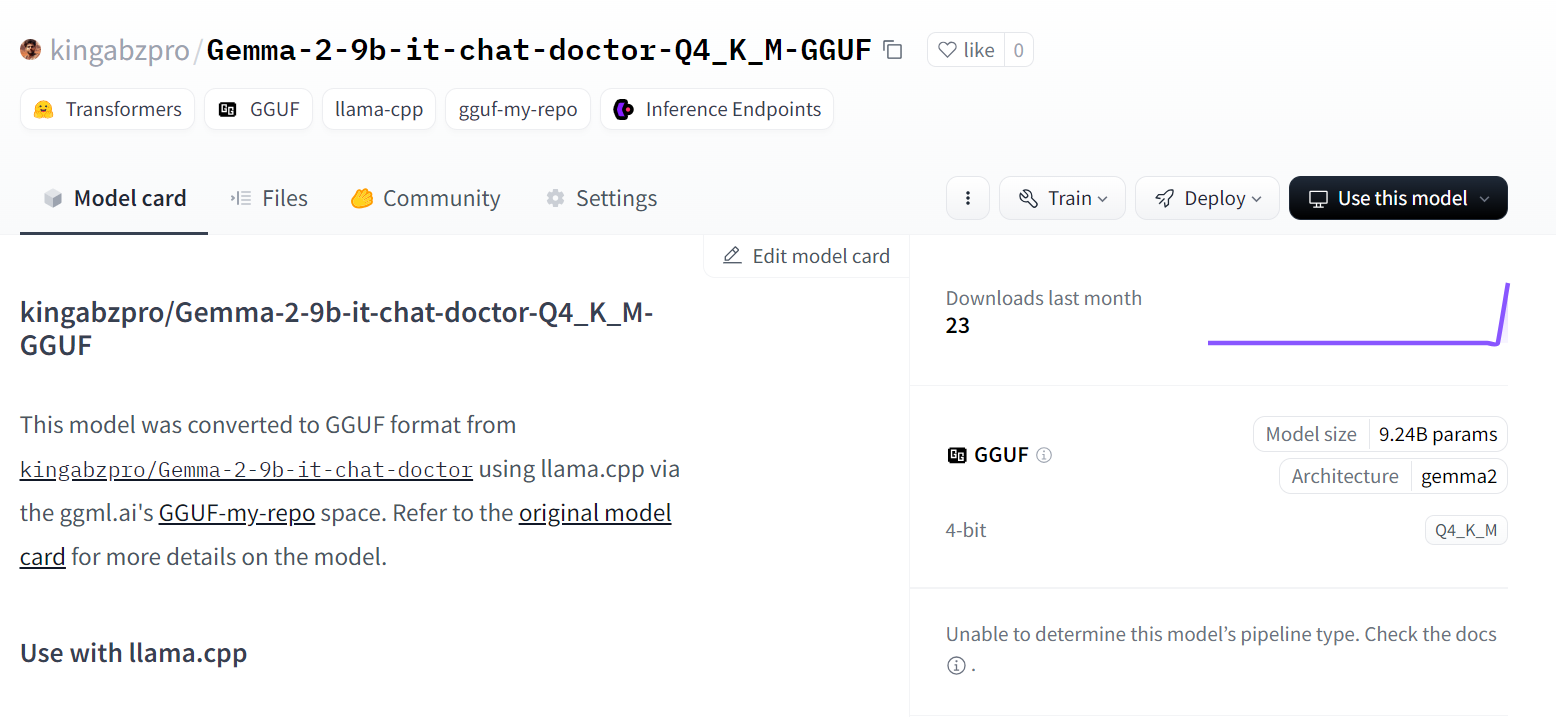
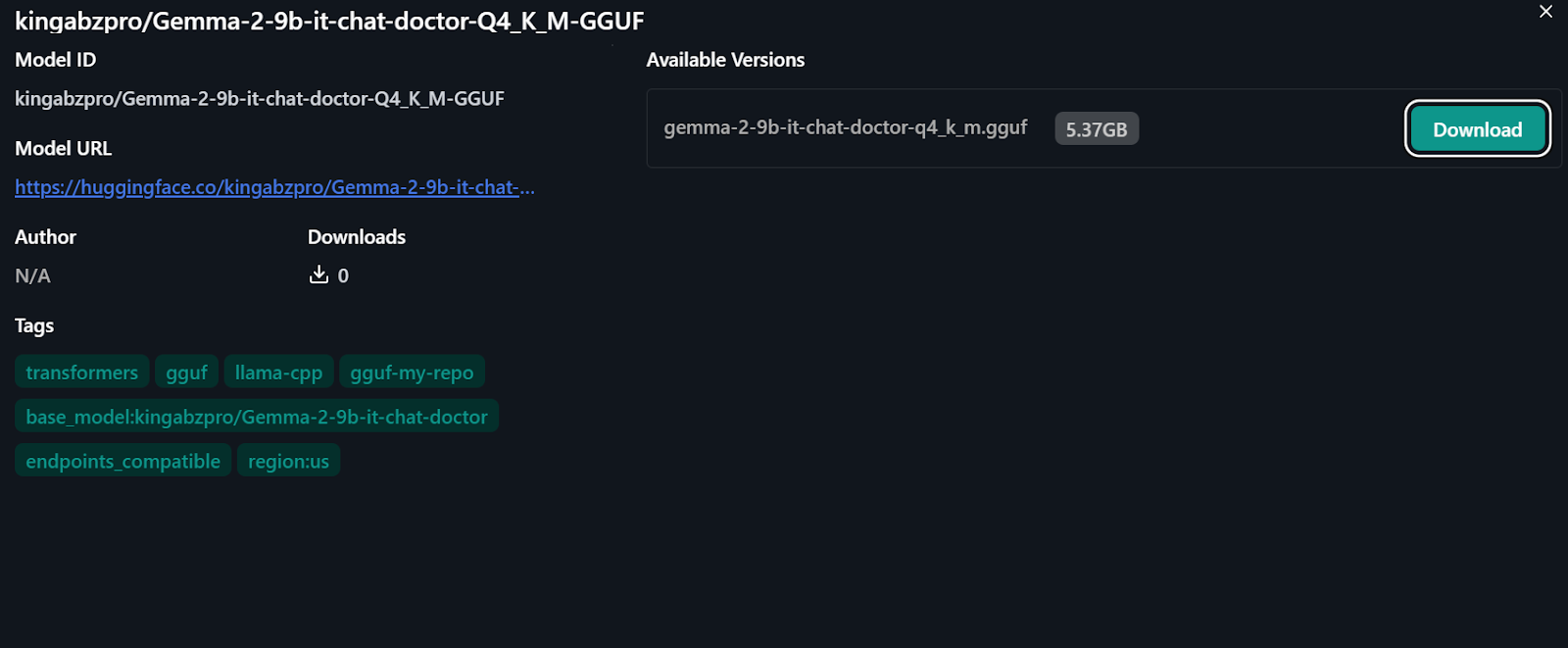
Source: kingabzpro/Gemma-2-9b-it-chat-doctor-Q4_K_M-GGUF · Hugging Face
Wenn du dir aber die Hände schmutzig machen und llama.cpp-Skripte selbst ausführen willst, dann solltest du dir die Feinabstimmung von Llama 3 und seine lokale Verwendung Tutorial ansehen.
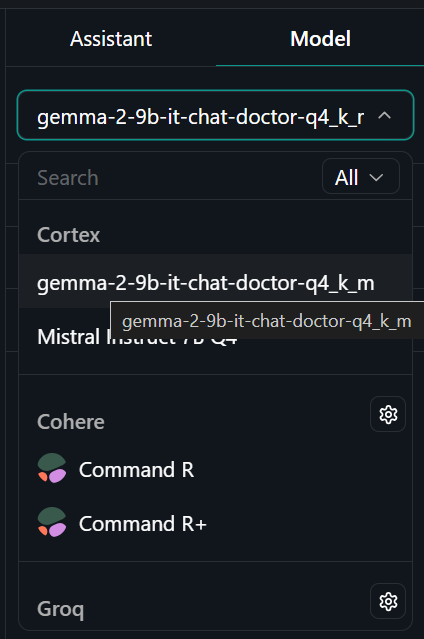
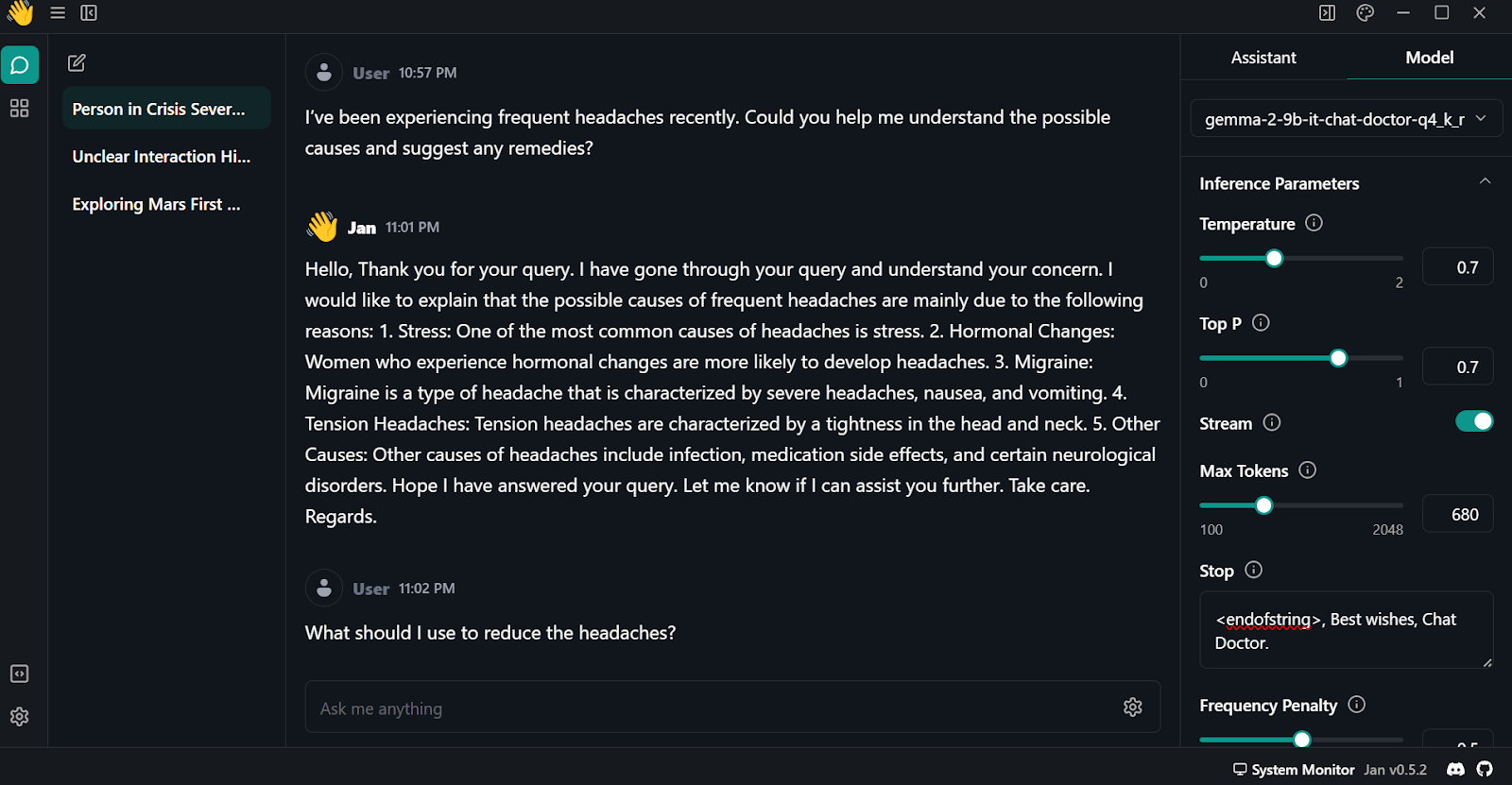
Um das quantisierte Modell lokal zu verwenden:
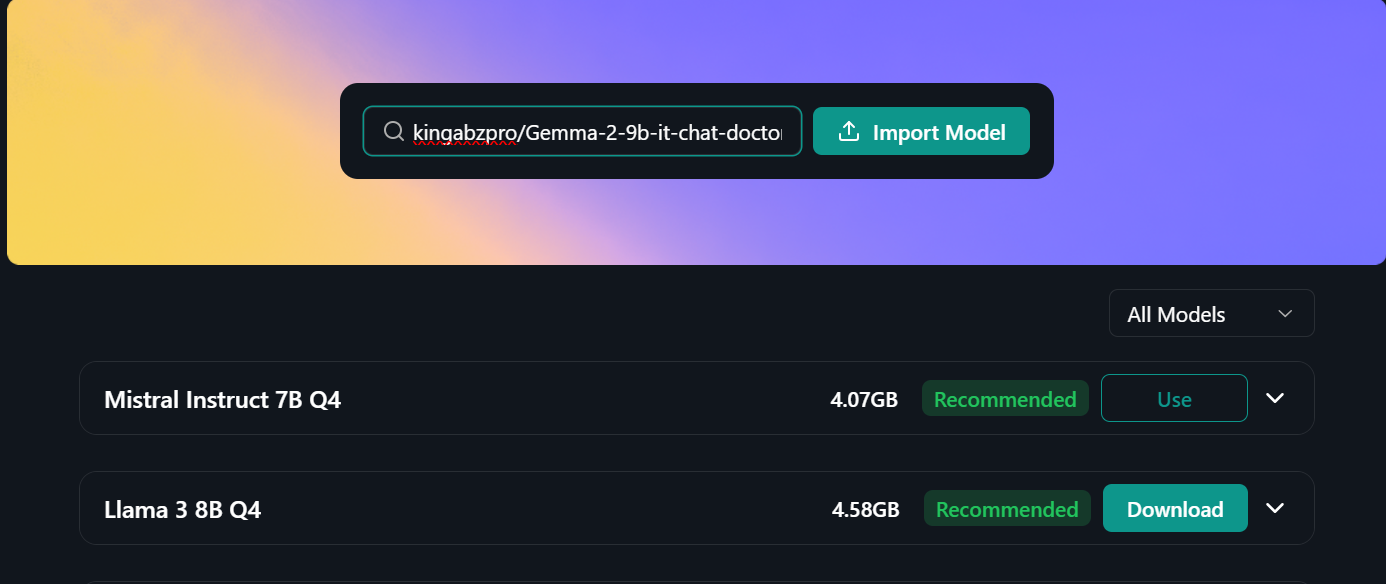
Gemma 2 ist ein großartiges Modell, das noch besser werden kann, wenn du das Keras-3-Framework für verteiltes Fine-Tuning und Modellinferenz verwendest. Du bekommst eine schnellere Trainings- und Inferenzzeit im Vergleich zur Verwendung des Transformers-Frameworks.
Im Folgenden erfährst du, wie du das Gemma-Modell fein abstimmst und die Modellinferenz mit Keras 3 durchführst Fine-Tune and Run Inference on Google's Gemma Model with TPU Tutorial.
In diesem Lernprogramm haben wir etwas über Gemma 2-Modelle gelernt und wie man mit der Transformer-Bibliothek auf sie zugreift. Wir haben auch gelernt, das Modell anhand von Patienten-Arzt-Gesprächen fein abzustimmen, die angenommenen Daten mit dem Basismodell zusammenzuführen, das vollständige Modell in den Hugging Face Hub zu übertragen, das Modell mit Hilfe des Hugging Face Space zu konvertieren und zu quantisieren und das Modell mit Hilfe der Jan-Anwendung lokal auf den Laptop herunterzuladen und auszuführen.
Es ist ein lustiges Projekt, das KI-Enthusiasten ausprobieren sollten. Dies wird ihre Fähigkeit verbessern, Probleme zu beheben, die bei der Feinabstimmung großer Sprachmodelle auftreten. Die größten Herausforderungen sind oft der begrenzte Speicher und die begrenzte Rechenleistung sowie die Minimierung von Verlusten.
Du kannst auch lernen, deine eigenen LLMs mit PyTorch und Hugging Face zu entwickeln, und zwar in der Entwickeln großer Sprachmodelle Kurs auf DataCamp.
Top LLM-Kurse
Kurs
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
