
Curso
Desenvolvimento de aplicativos de LLM com LangChain
3 h
46.3K
Neste tutorial, aprenderemos a fazer o ajuste fino do modelo Gemma 2 no conjunto de dados de conversas entre pacientes e médicos. Também converteremos o modelo no formato GGUF para que ele possa ser usado localmente no laptop off-line.
Aprenderemos sobre o Gemma 2 e seus aprimoramentos em relação às gerações anteriores antes de fazer o ajuste fino do modelo Gemma 2 no conjunto de dados de conversão paciente-médico. Em seguida, mesclaremos o adaptador salvo com o modelo básico, enviaremos o modelo completo para o Hugging Face Hub e usaremos um Hugging Face Space para converter e quantizar o modelo. Por fim, faremos o download do modelo quantizado e o usaremos localmente com o aplicativo Jan.

Imagem do autor
O Gemma 2 é a versão mais recente da família Gemma de modelos abertos de linguagem grande (LLMs) do Google. Ele está disponível para pesquisadores e desenvolvedores em dois tamanhos, 9 bilhões (9B) e 27 bilhões (27B) de parâmetros, sob uma licença comercialmente amigável. Isso significa que você pode fazer o ajuste fino em seu conjunto de dados privado e implementar o modelo ajustado na produção sem nenhuma restrição.
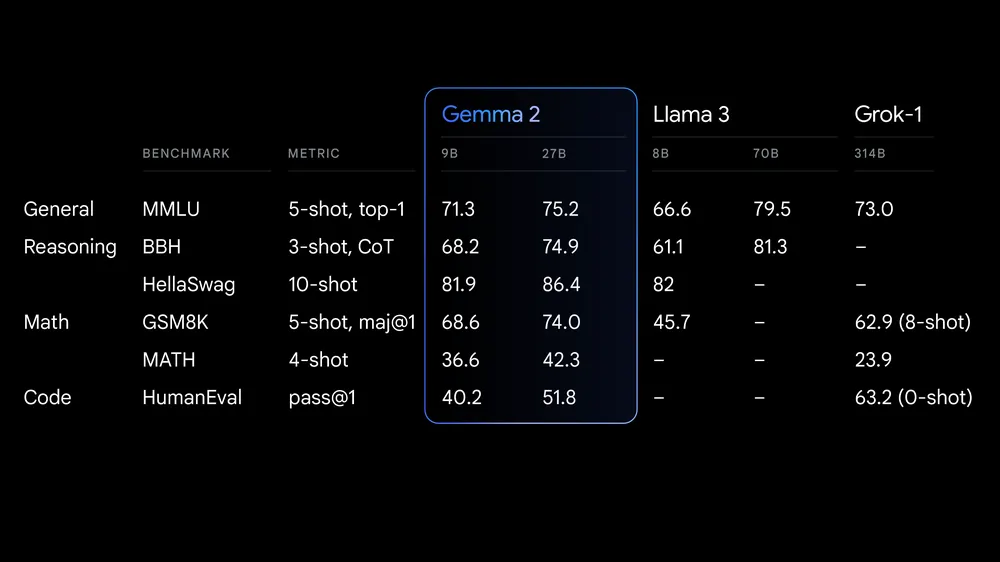
Fonte: Google launches Gemma 2
O Gemma 2 oferece avanços significativos no desempenho e na eficiência da inferência. A arquitetura reprojetada garante uma inferência extremamente rápida em várias configurações de hardware e uma integração perfeita com as principais estruturas de IA, como Hugging Face TransformersJAX, PyTorch e TensorFlow.
O Gemma 2 também inclui medidas e ferramentas de segurança robustas para a implementação ética da IA. Ele supera o desempenho do Llama 3 e o Groq-1 em vários benchmarks e vem com integração aprimorada com o Keras 3 para ajuste fino e inferência de modelos.
Se você quiser saber mais sobre a primeira geração de modelos Gemma, um ótimo recurso é o nosso tutorial, Fine Tuning Google Gemma: Aprimorando os LLMs com instruções personalizadas. Esse recurso fornece orientação abrangente sobre como ajustar os modelos Gemma, como o Gemma 7b-it, em conjuntos de dados e tarefas específicos.
Nesta seção, faremos o download do modelo, o carregaremos em quantização de 4 bits e, em seguida, executaremos a inferência em uma GPU.
%%capture
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U accelerate
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)Observação: O modelo Gemma 2 9B-It é grande e, mesmo com 16 GB de memória GPU, não conseguimos carregar o modelo completo. É por isso que estamos carregando o modelo em quantização de 4 bits quantização de 4 bits.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig, AutoConfig
modelName = "google/gemma-2-9b-it"
bnbConfig = BitsAndBytesConfig(
load_in_4bit = True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
tokenizer = AutoTokenizer.from_pretrained(modelName)
model = AutoModelForCausalLM.from_pretrained(
modelName,
device_map = "auto",
quantization_config=bnbConfig
)from IPython.display import Markdown, display
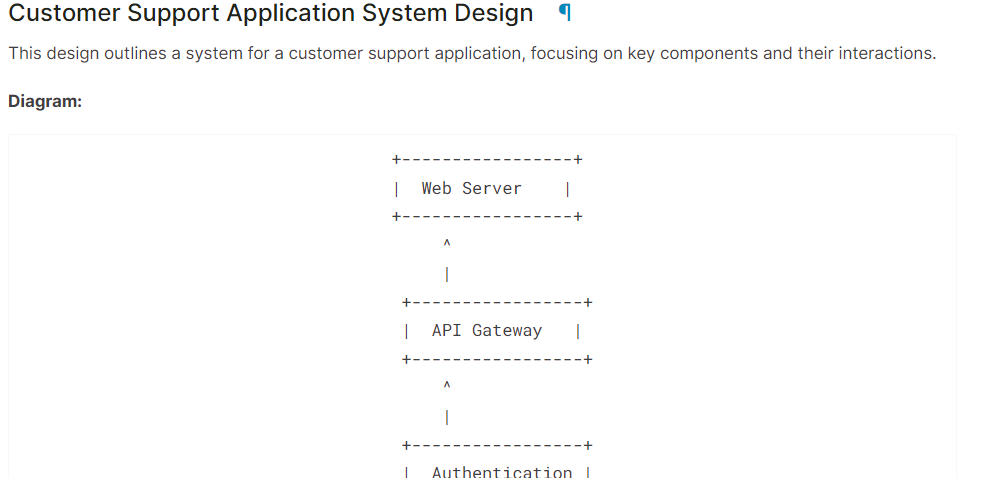
system = "You are a skilled software architect who consistently creates system designs for various applications."
user = "Design a system with the ASCII diagram for the customer support application."
prompt = f"System: {system} \n User: {user} \n AI: "
inputs = tokenizer(prompt, return_tensors='pt', padding=True, truncation=True).to("cuda")
outputs = model.generate(**inputs, max_length=500, num_return_sequences=1)
text = tokenizer.decode(outputs[0], skip_special_tokens=True)
Markdown(text.split("AI:")[1])Como você pode ver, o modelo Gemma 2 fez um ótimo trabalho.
Se você estiver tendo problemas para executar o código acima, consulte o Kaggle Notebook: Gemma 2 Inferência simples na GPU.
Nesta seção, faremos o ajuste fino do modelo Gemma 2 9B-It no conjunto de dados de saúdeque consiste em conversas entre pacientes e médicos. Carregaremos o modelo e o tokenizador, carregaremos o conjunto de dados, converteremos o conjunto de dados, configuraremos o modelo usando argumentos de treinamento e acompanharemos o desempenho do modelo usando a API Weights and Biases.
Se você estiver interessado em entender como funciona a teoria do ajuste fino, leia nosso guia, Um guia introdutório para LLMs de ajuste fino.
Instale os pacotes Python necessários para carregar, ajustar e avaliar o modelo no conjunto de dados médicos.
%%capture
%pip install -U transformers
%pip install -U datasets
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes
%pip install -U wandbCarregue os pacotes Python necessários e as funções.
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
HfArgumentParser,
TrainingArguments,
pipeline,
logging,
)
from peft import (
LoraConfig,
PeftModel,
prepare_model_for_kbit_training,
get_peft_model,
)
import os, torch, wandb
from datasets import load_dataset
from trl import SFTTrainer, setup_chat_formatFaça login no Hugging Face CLI usando a chave de API que salvamos usando o Kaggle Secrets.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)
Carregue a chave da API Weights and Biases dos segredos do Kaggle para iniciar o projeto de rastreamento do desempenho do modelo.
wb_token = user_secrets.get_secret("wandb")
wandb.login(key=wb_token)
run = wandb.init(
project='Fine-tune Gemma-2-9b-it on HealthCare Dataset',
job_type="training",
anonymous="allow"
)Definir o ID do modelo e do conjunto de dados para que você possa carregá-los no Hugging Face Hub. Além disso, precisamos definir o nome do modelo ajustado para criar um repositório de modelos no Hugging Face e enviar o modelo ajustado.
base_model = "google/gemma-2-9b-it"
dataset_name = "lavita/ChatDoctor-HealthCareMagic-100k"
new_model = "Gemma-2-9b-it-chat-doctor"Definir o tipo de dados e a implementação de atenção com base na GPU.
if torch.cuda.get_device_capability()[0] >= 8:
!pip install -qqq flash-attn
torch_dtype = torch.bfloat16
attn_implementation = "flash_attention_2"
else:
torch_dtype = torch.float16
attn_implementation = "eager"Devemos criar a configuração do QLoRA para que possamos carregar o modelo com precisão de 4 bits, reduzindo o uso da memória e acelerando o processo de ajuste fino.
# QLoRA config
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch_dtype,
bnb_4bit_use_double_quant=True,
)
Usando o URL do modelo, a configuração do LoRA e a implementação de atenção, carregue o modelo Gemma 2 9B-It e o tokenizador.
# Load model
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=bnb_config,
device_map="auto",
attn_implementation=attn_implementation
)
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(base_model, trust_remote_code=True)Crie a função Python que usará o modelo e extrairá os nomes de todos os módulos lineares.
import bitsandbytes as bnb
def find_all_linear_names(model):
cls = bnb.nn.Linear4bit
lora_module_names = set()
for name, module in model.named_modules():
if isinstance(module, cls):
names = name.split('.')
lora_module_names.add(names[0] if len(names) == 1 else names[-1])
if 'lm_head' in lora_module_names: # needed for 16 bit
lora_module_names.remove('lm_head')
return list(lora_module_names)
modules = find_all_linear_names(model)O ajuste fino do modelo completo levará muito tempo, portanto, para acelerar o processo de treinamento, criaremos e anexaremos a camada do adaptador, resultando em um processo mais rápido e eficiente em termos de memória.
A camada de adoção é criada usando os módulos de destino e o tipo de tarefa. Em seguida, configuramos o formato de bate-papo para o modelo e o tokenizador. Por fim, anexamos o modelo básico ao adaptador para criar um modelo PEFT (Parameter Efficient Fine-Tuning, ajuste fino eficiente de parâmetros).
# LoRA config
peft_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules=modules
)
model, tokenizer = setup_chat_format(model, tokenizer)
model = get_peft_model(model, peft_config)Agora, carregaremos o arquivo lavita/ChatDoctor-HealthCareMagic-100k do hub Hugging Face. O conjunto de dados consiste em três colunas:
Depois de carregar o conjunto de dados, nós o embaralharemos e selecionaremos 1.000 amostras para reduzir ainda mais o tempo de treinamento. No final, criaremos o formato de bate-papo usando o modelo de bate-papo padrão e o usaremos para criar a coluna "texto".
#Importing the dataset
dataset = load_dataset(dataset_name, split="all")
dataset = dataset.shuffle(seed=65).select(range(1000)) # Only use 1000 samples for quick demo
def format_chat_template(row):
row_json = [{"role": "system", "content": row["instruction"]},
{"role": "user", "content": row["input"]},
{"role": "assistant", "content": row["output"]}]
row["text"] = tokenizer.apply_chat_template(row_json, tokenize=False)
return row
dataset = dataset.map(
format_chat_template,
num_proc= 4,
)
datasetSaída:
Dataset({
features: ['instruction', 'input', 'output', 'text'],
num_rows: 1000
})Vamos analisar a coluna "texto" da linha 3.
dataset['text'][3]A coluna "texto" tem instruções, a consulta do paciente e a resposta do médico no estilo da OpenAI.

Para a avaliação do modelo, dividiremos o conjunto de dados em treinamento e teste.
dataset = dataset.train_test_split(test_size=0.1)Agora, definiremos o argumento de treinamento e os parâmetros do STF e, em seguida, iniciaremos o processo de treinamento.
Você pode alterar os vários hiperparâmetros com base em seu ambiente, computação e memória. Os hiperparâmetros abaixo são otimizados para o Kaggle Notebook. Portanto, se você quiser executar a mesma coisa no Google Colab, considere fazer experiências com algoritmos de treinamento.
# Setting Hyperparamter
training_arguments = TrainingArguments(
output_dir=new_model,
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=2,
optim="paged_adamw_32bit",
num_train_epochs=1,
eval_strategy="steps",
eval_steps=0.2,
logging_steps=1,
warmup_steps=10,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
report_to="wandb"
)
# Setting sft parameters
trainer = SFTTrainer(
model=model,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
peft_config=peft_config,
max_seq_length= 512,
dataset_text_field="text",
tokenizer=tokenizer,
args=training_arguments,
packing= False,
)
model.config.use_cache = False
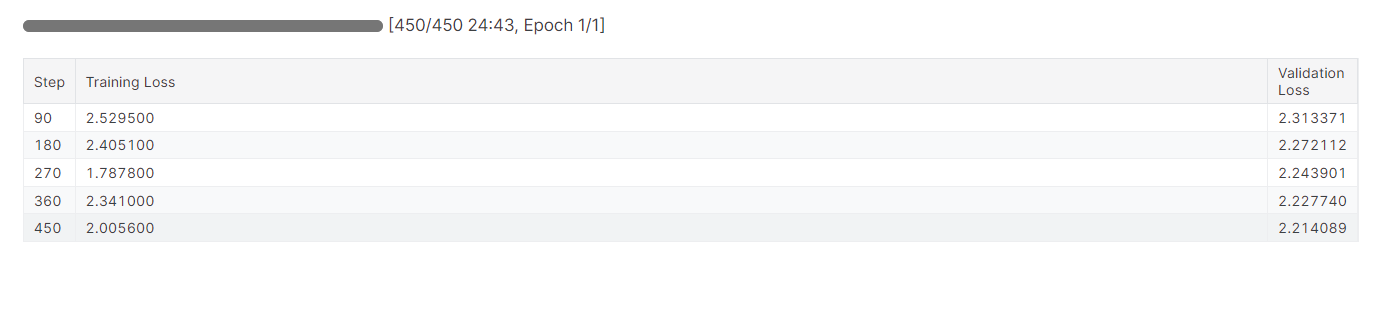
trainer.train()Foram necessários quase 25 minutos para fazer o ajuste fino do modelo e, como podemos ver, a perda de treinamento e validação foi reduzida gradualmente. Para melhorar o desempenho, tente fazer o ajuste fino do modelo no conjunto de dados completo por pelo menos três épocas.
 O ajuste fino pode ser um pouco técnico para iniciantes e pessoas não técnicas. Se estiver procurando uma solução mais simples, você deve conferir o Fine-Tuning OpenAI's GPT-4: A Step-by-Step Guide (Guia passo a passo) tutorial. Ele aborda uma maneira simples de ajustar um modelo de última geração usando a API OpenAI.
O ajuste fino pode ser um pouco técnico para iniciantes e pessoas não técnicas. Se estiver procurando uma solução mais simples, você deve conferir o Fine-Tuning OpenAI's GPT-4: A Step-by-Step Guide (Guia passo a passo) tutorial. Ele aborda uma maneira simples de ajustar um modelo de última geração usando a API OpenAI.
Concluiremos o experimento Weights and Biases, que gerará um relatório de avaliação.
wandb.finish()
model.config.use_cache = True
Para visualizar o relatório detalhado, acesse sua conta do Weights and Biases e clique em "Fine-tune Gemma-2-9b-it on Healthcare Dataset" nome do projeto.
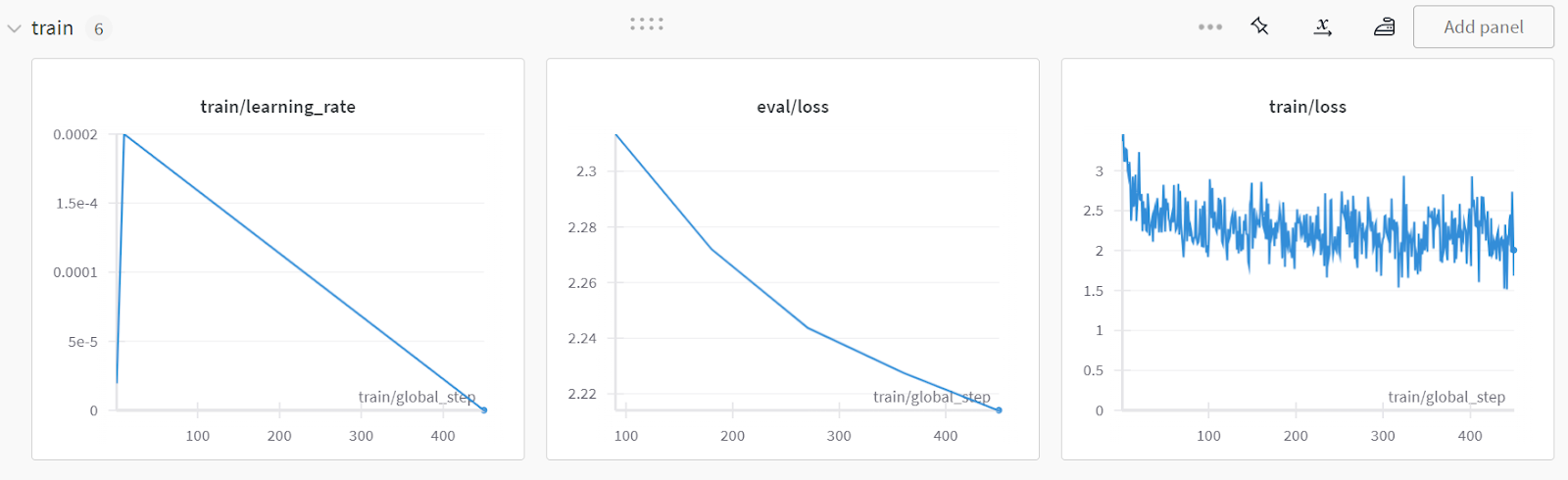
A captura de tela é de wandb.ai
Agora, salvaremos o adotante ajustado localmente e também o enviaremos para o hub do Hugging Face.
trainer.model.save_pretrained(new_model)
trainer.model.push_to_hub(new_model, use_temp_dir=False)Para usar o adotante salvo em outro notebook do Kaggle, é necessário salvar o notebook. Você pode fazer isso clicando em "Save Version" (Salvar versão) no canto superior direito. Depois disso, selecione "Quick Save" (Salvamento rápido) e "Always save output when creating a Quick Save" (Sempre salvar a saída ao criar um salvamento rápido) e, em seguida, pressione o botão "Save" (Salvar).
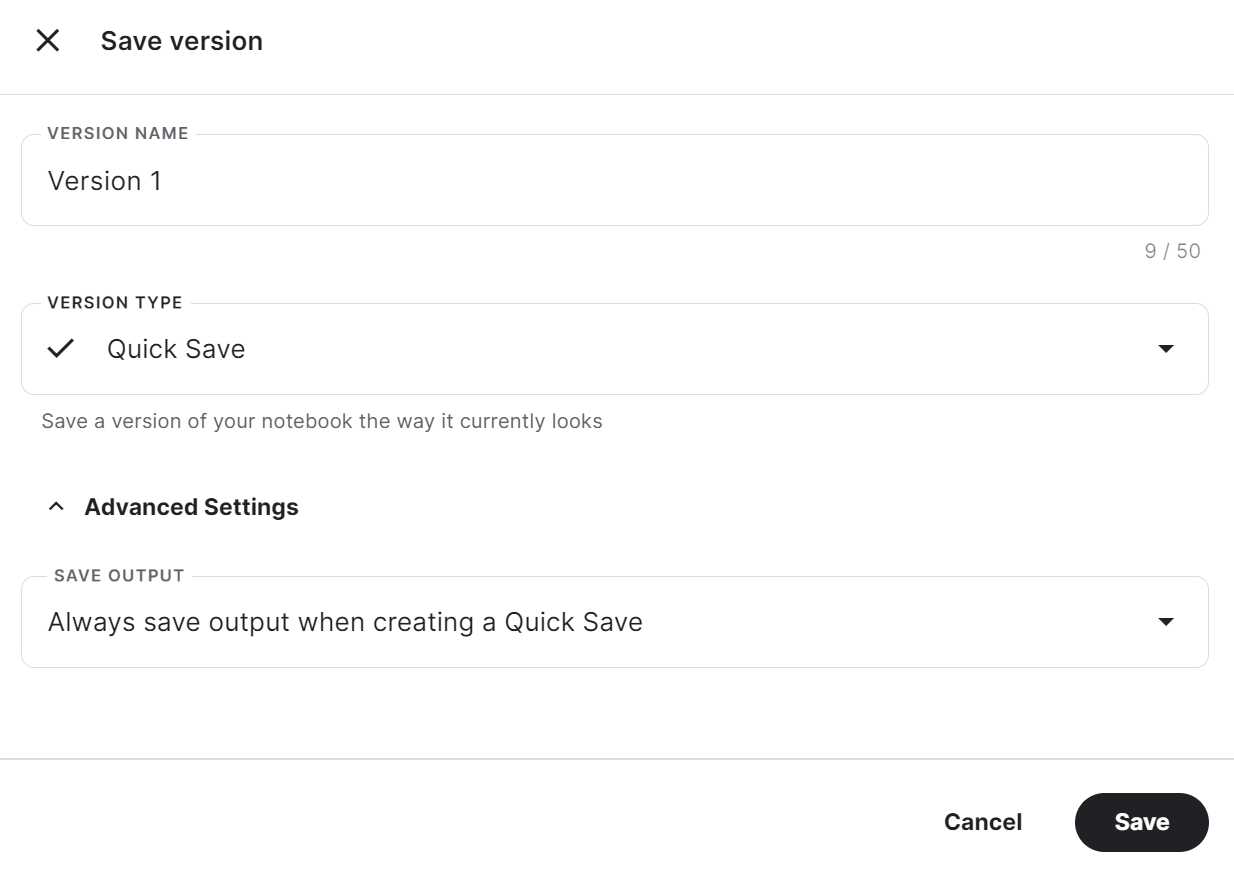
Se você tiver problemas para executar o código, clone o Notebook do Kaggle da Kaggle e execute-o. Você deve configurar a chave da API Hugging Face e Weights & Biases usando o Kaggle Secrets.
Para determinar se o ajuste fino ou o Retrieval-Augmented Generation (RAG) é mais adequado para seu caso de uso específico, recomendo que você leia o artigo RAG versus ajuste fino do blog.
Agora, mesclaremos o adaptador com o modelo básico e enviaremos o modelo completo para o hub Hugging Face.
Crie um novo notebook do Kaggle com uma CPU como acelerador e instale os pacotes Python necessários.
Por que estamos usando a CPU como um acelerador? Não será lento? Sim, mas a máquina de GPU no Kaggle só nos fornece 16 GB de memória de GPU, o que é suficiente para um modelo de 7 bilhões de parâmetros, mas não para um modelo de 9 bilhões de parâmetros. Enquanto isso, a máquina com CPU fornece 30 GB, o que é suficiente para carregar o modelo básico e o adaptador.
%%capture
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U accelerate
%pip install -U peft
%pip install -U trlObtenha a chave de API do Kaggle Secrets e faça login na CLI do Hugging Face.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)Para acessar o modelo salvo, você precisa importar o notebook salvo do Kaggle. Para fazer isso, clique no botão "Add Input" (Adicionar entrada) no canto superior direito e selecione a guia "Your Work" (Seu trabalho). Em seguida, clique no botão de adição do notebook salvo para acessar todos os arquivos que ele contém.
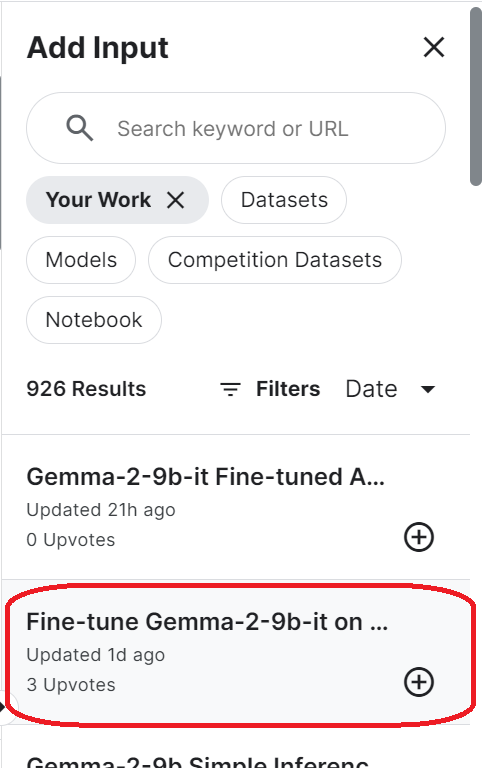
Configure o URL do modelo básico fornecendo o nome do repositório Hugging Face. Além disso, configure o URL do adaptador especificando o diretório local onde o adaptador está salvo.
base_model_url = "google/gemma-2-9b-it"
new_model_url = "/kaggle/input/fine-tune-gemma-2-9b-it-on-healthcare-dataset/Gemma-2-9b-it-chat-doctor/"Carregue o tokenizador e o modelo completo usando o URL do modelo básico. Certifique-se de que você definiu o dispositivo "cpu" e o tipo de dados "float16".
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig, pipeline
from peft import PeftModel
import torch
from trl import setup_chat_format
# Reload tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(base_model_url)
base_model_reload= AutoModelForCausalLM.from_pretrained(
base_model_url,
low_cpu_mem_usage=True,
return_dict=True,
torch_dtype=torch.float16,
device_map="cpu",
)Defina o formato do bate-papo para o modelo básico recém-carregado e combine-o com o adotante. No final, carregaremos e mesclaremos o adotante com o modelo básico.
A função merge_and_unload() nos ajudará a mesclar os pesos do adaptador com o modelo básico e a usá-lo como um modelo autônomo.
base_model_reload, tokenizer = setup_chat_format(base_model_reload, tokenizer)
model = PeftModel.from_pretrained(base_model_reload, new_model_url)
model = model.merge_and_unload()Salve o modelo completo e o tokenizador localmente.
model.save_pretrained("Gemma-2-9b-it-chat-doctor")
tokenizer.save_pretrained("Gemma-2-9b-it-chat-doctor")Além disso, envie todos os arquivos de modelo e o tokenizador para o hub Hugging Face.
model.push_to_hub("Gemma-2-9b-it-chat-doctor", use_temp_dir=False)
tokenizer.push_to_hub("Gemma-2-9b-it-chat-doctor", use_temp_dir=False)Você pode acessar o repositório do modelo Hugging Face e visualizar todos os arquivos.
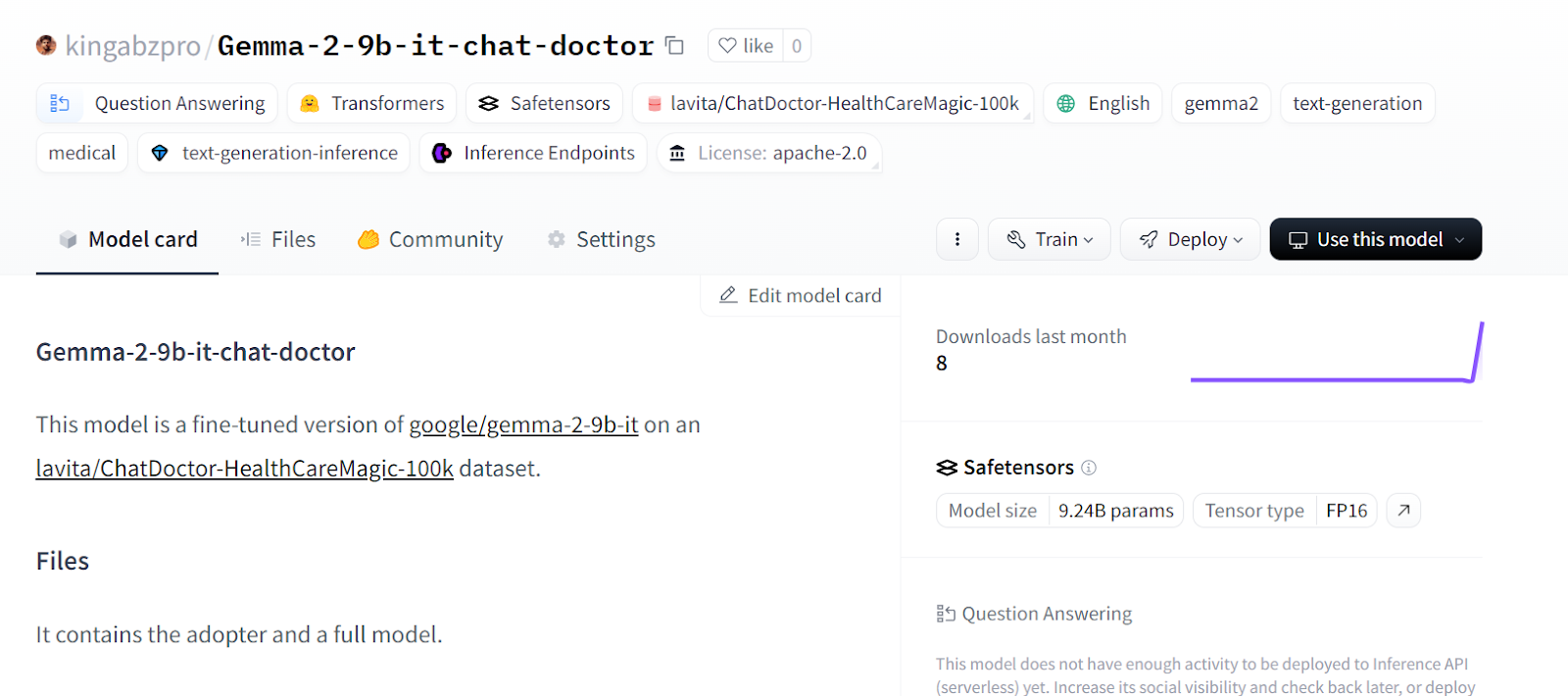
Fonte: kingabzpro/Gemma-2-9b-it-chat-doctor - Hugging Face
Se você estiver enfrentando problemas ao mesclar modelos usando a CPU, consulte o Caderno do Kaggle.
Com o GGUF My Repo Hugging Face Space, a conversão e a quantização de modelos se tornaram fáceis e rápidas. Tudo o que você precisa fazer é fazer login e fornecer a ID do modelo.
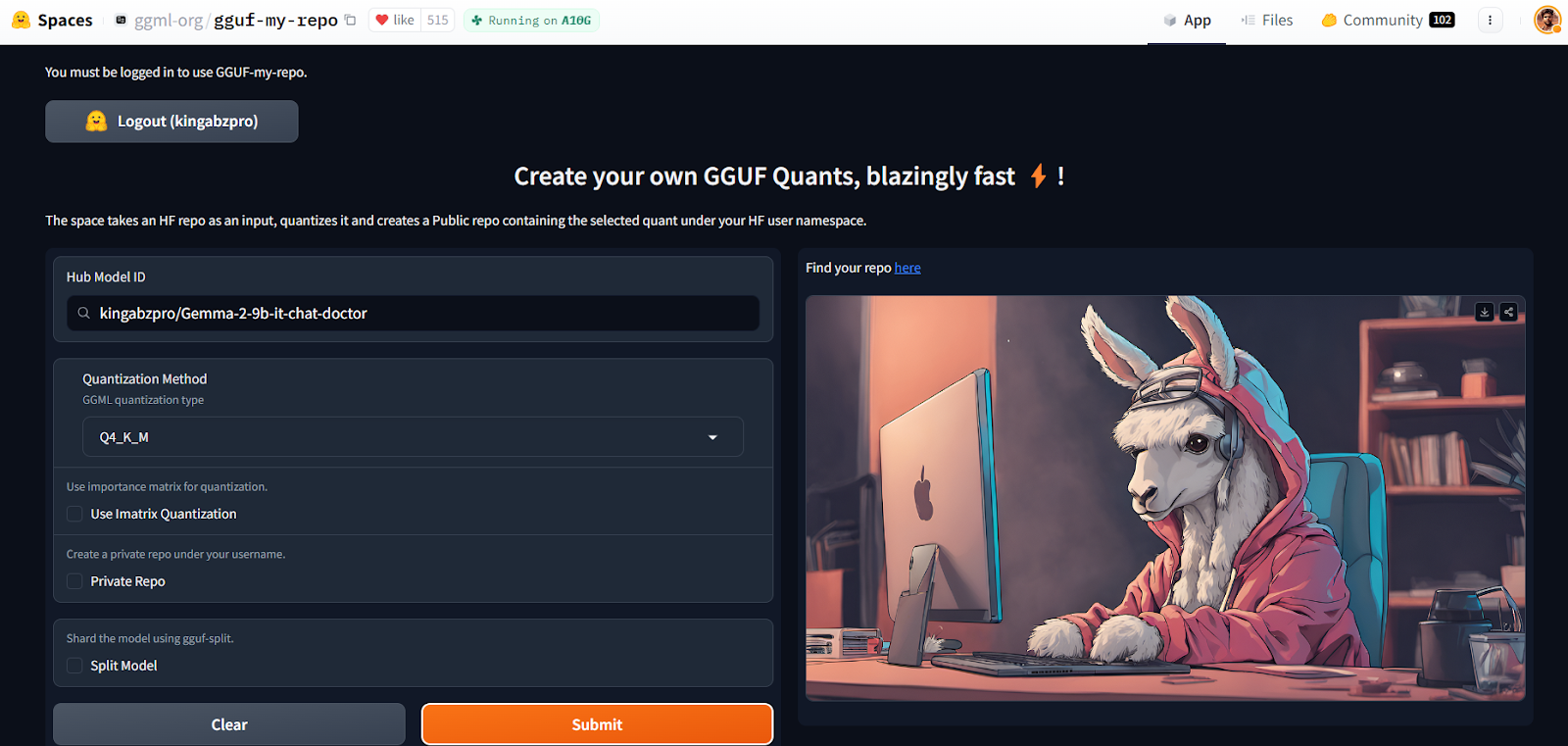
Fonte: GGUF My Repo - um espaço para abraçar o rosto por ggml-org
Ele criará um novo repositório de modelos para você com um arquivo de modelo quantizado que você poderá baixar posteriormente para usá-lo localmente. É simples assim.
Você pode conhecer a teoria por trás da quantização lendo nosso artigo sobre Quantização para modelos de linguagem grandes (LLMs): Reduza o tamanho dos modelos de IA de forma eficiente.
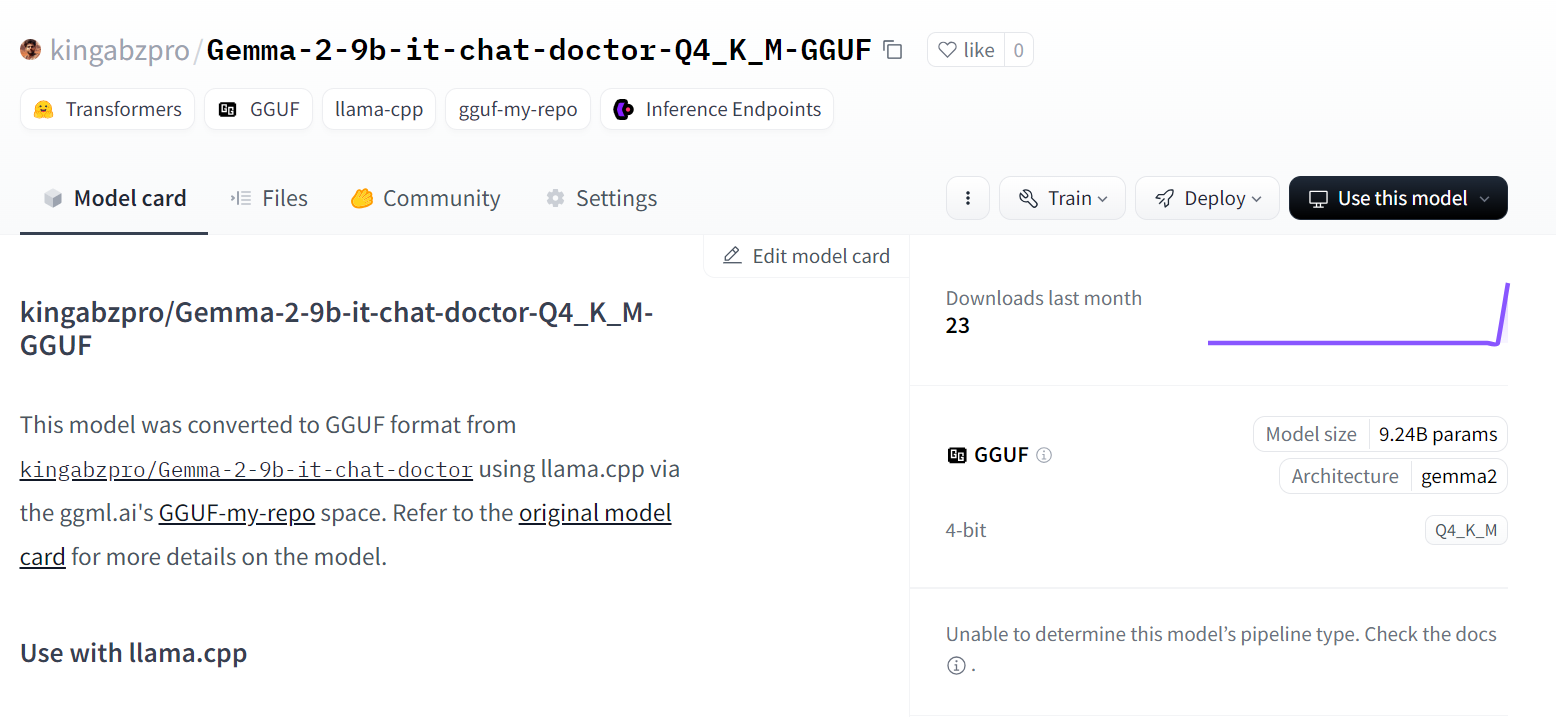
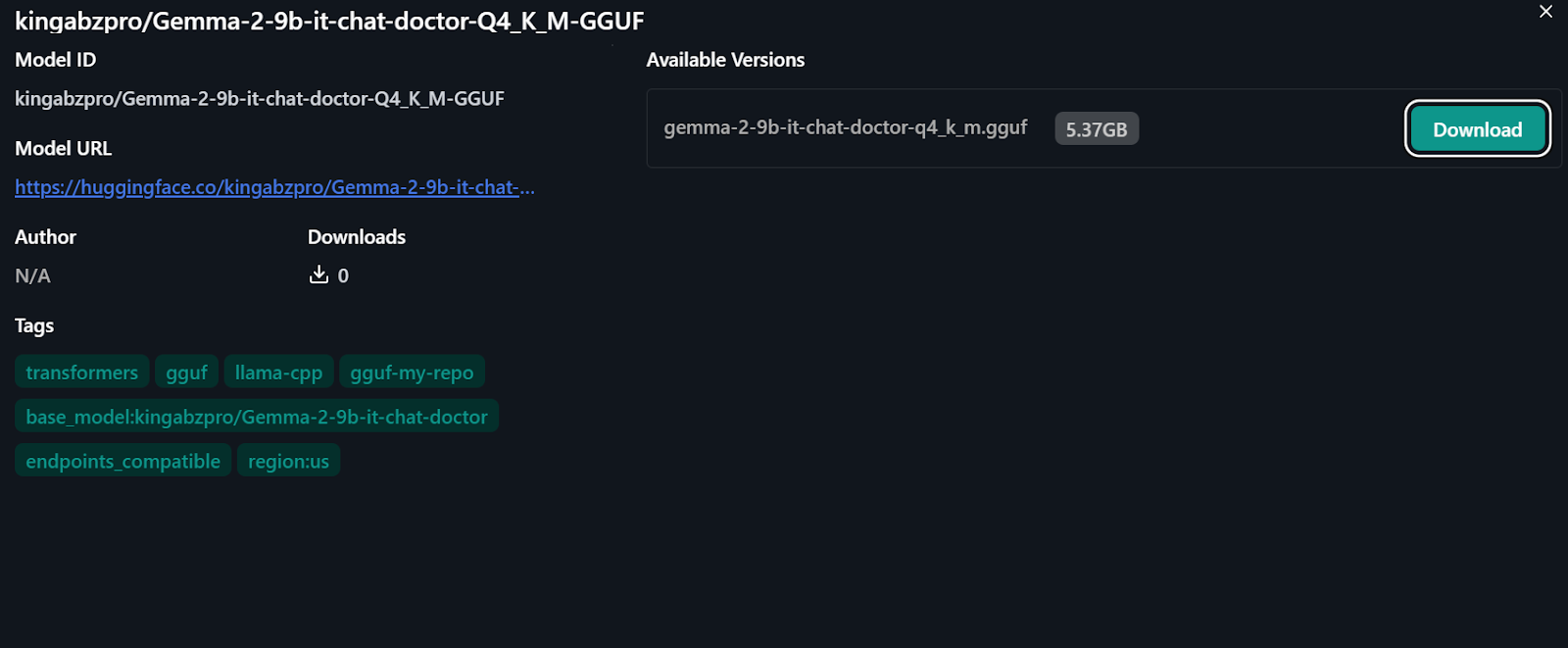
Fonte: kingabzpro/Gemma-2-9b-it-chat-doctor-Q4_K_M-GGUF - Hugging Face
Mas, se você quiser colocar a mão na massa e executar scripts llama.cpp por conta própria, consulte o artigo Como ajustar a Llama 3 e usá-la localmente que você pode ler no tutorial.
Para usar o modelo quantizado localmente:
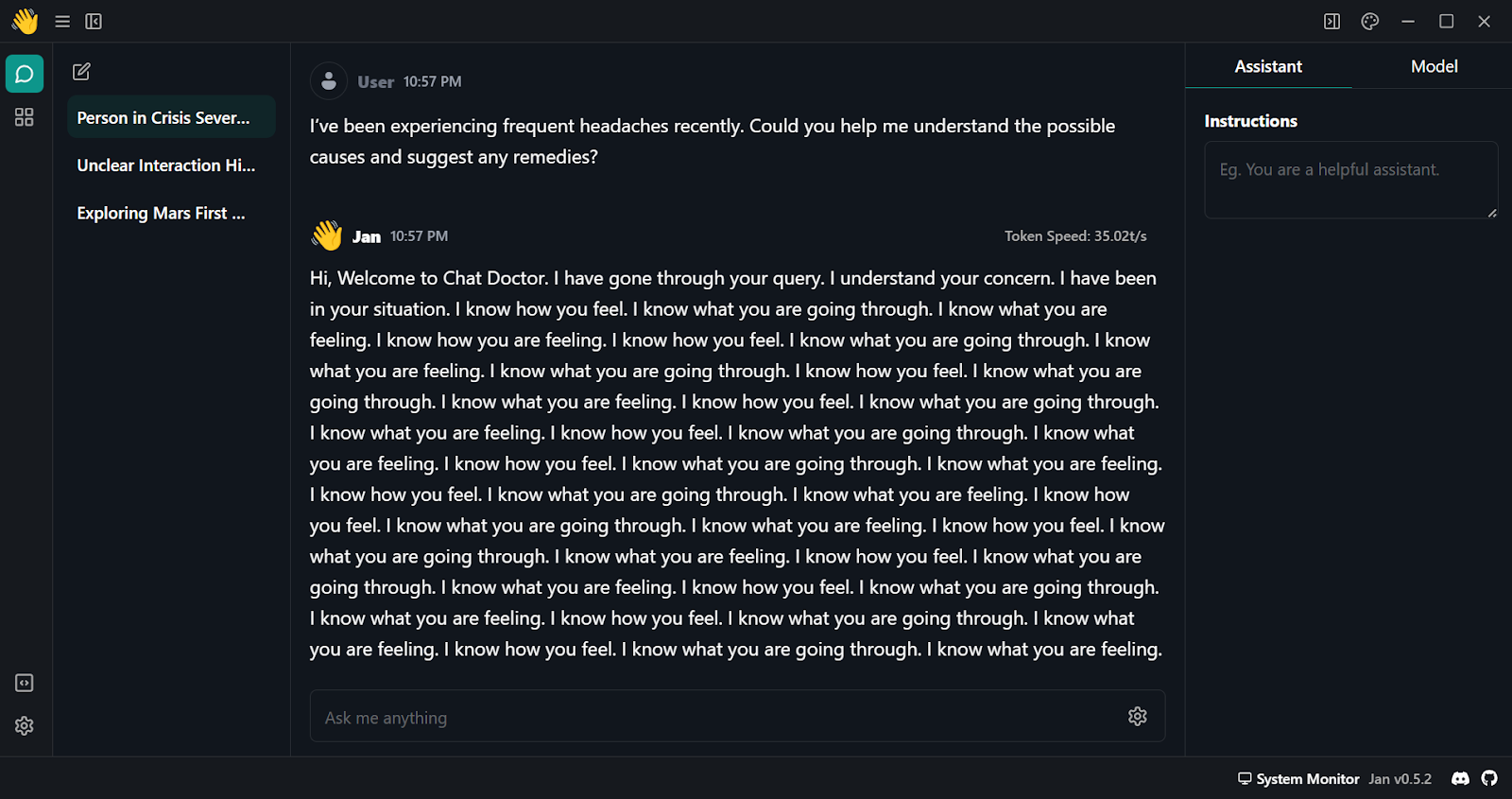
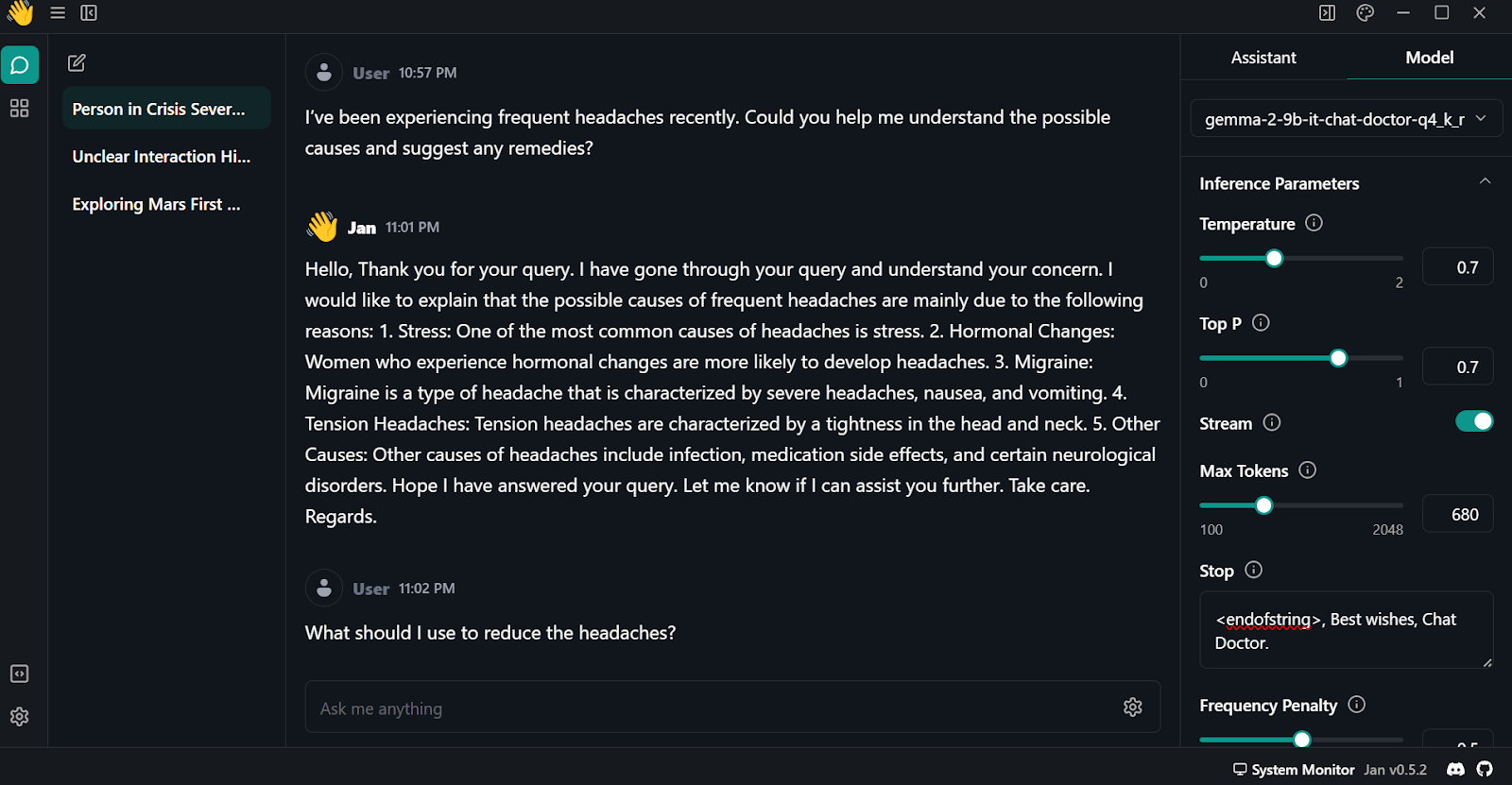
O Gemma 2 é um ótimo modelo e pode ser ainda melhor se você usar a estrutura do Keras 3 para ajuste fino distribuído e inferência de modelo. Você terá um tempo de treinamento e inferência mais rápido em comparação com o uso da estrutura Transformers.
Você pode aprender a fazer o ajuste fino do modelo Gemma e a executar a inferência do modelo usando o Keras 3 da seguinte forma Ajuste fino e execução de inferência no modelo Gemma do Google com TPU do Google.
Neste tutorial, aprendemos sobre os modelos Gemma 2 e como acessá-los usando a biblioteca Transformer. Também aprendemos a ajustar o modelo em conversas entre paciente e médico, mesclar o modelo adotado com o modelo básico, enviar o modelo completo para o hub Hugging Face, converter e quantizar o modelo usando o Hugging Face Space, baixar e executar o modelo localmente no laptop usando o aplicativo Jan.
É um projeto divertido que os entusiastas da IA deveriam experimentar. Isso aumentará sua capacidade de solucionar problemas que surgem durante o ajuste fino de grandes modelos de linguagem. Os principais desafios geralmente envolvem limitações de memória e computação, bem como a minimização de perdas.
Você também pode aprender a desenvolver seus próprios LLMs com PyTorch e Hugging Face no curso Desenvolvendo grandes modelos de linguagem no curso DataCamp.
Principais cursos de LLM
Curso
Curso
Curso
Tutorial
Aashi Dutt
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
Tutorial
Dimitri Didmanidze

