
Cours
Développement d'applications LLM avec LangChain
3 h
46.2K
Dans ce tutoriel, nous allons apprendre à affiner le modèle Gemma 2 sur l'ensemble de données de conversations entre un patient et un médecin. Nous convertirons également le modèle au format GGUF afin qu'il puisse être utilisé localement sur l'ordinateur portable hors ligne.
Nous découvrirons Gemma 2 et ses améliorations par rapport aux générations précédentes avant d'affiner le modèle Gemma 2 sur l'ensemble de données de conversion patient-médecin. Nous fusionnerons ensuite l'adaptateur sauvegardé avec le modèle de base, pousserons le modèle complet vers le Hugging Face Hub et utiliserons un Hugging Face Space pour convertir et quantifier le modèle. Enfin, nous téléchargerons le modèle quantifié et l'utiliserons localement avec l'application Jan.

Image par l'auteur
Gemma 2 est la dernière version de la famille Gemma de modèles linguistiques ouverts (LLM) de Google. Il est mis à la disposition des chercheurs et des développeurs en deux tailles, 9 milliards (9B) et 27 milliards (27B) de paramètres, dans le cadre d'une licence commerciale. Cela signifie que vous pouvez l'affiner sur votre ensemble de données privé et déployer le modèle affiné en production sans aucune restriction.
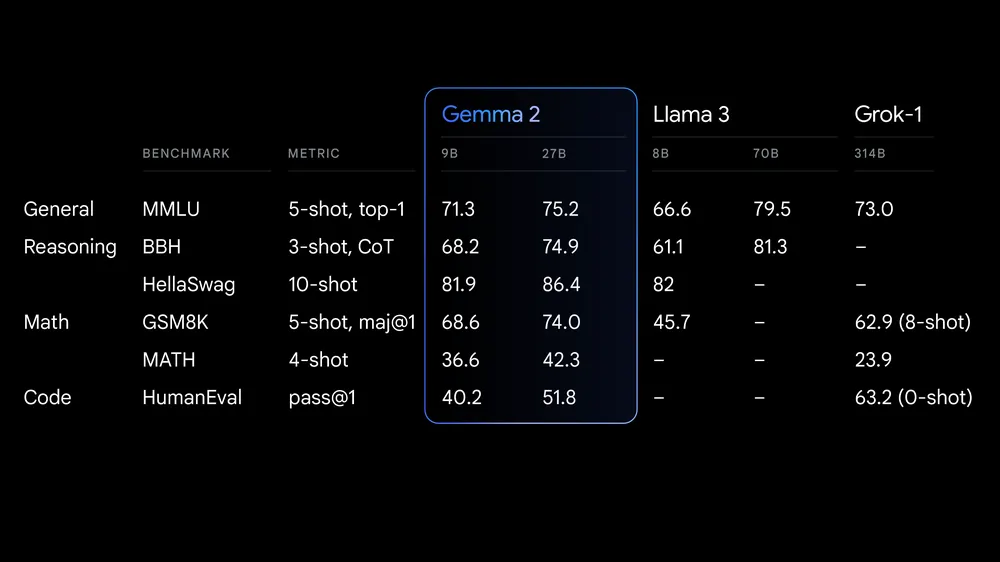
Source : Google lance Gemma 2
Gemma 2 offre des avancées significatives en termes de performance et d'efficacité d'inférence. L'architecture remaniée garantit une inférence ultra-rapide sur différentes configurations matérielles et une intégration transparente avec les principaux frameworks d'IA tels que Hugging Face TransformersJAX, PyTorch et TensorFlow.
Gemma 2 comprend également des mesures de sécurité et des outils robustes pour un déploiement éthique de l'IA. Il est plus performant que Llama 3 et Groq-1 sur différents benchmarks et est livré avec une intégration améliorée de Keras 3 pour un réglage fin et une inférence de modèle transparents.
Si vous souhaitez en savoir plus sur la première génération de modèles Gemma, notre didacticiel Fine Tuning Google Gemma est une excellente source d'informations : Améliorer les LLM avec des instructions personnalisées. Cette ressource fournit des conseils complets sur la manière d'affiner les modèles Gemma, tels que le Gemma 7b-it, sur des ensembles de données et des tâches spécifiques.
Dans cette section, nous allons télécharger le modèle, le charger avec une quantification sur 4 bits, puis exécuter l'inférence sur un GPU.
%%capture
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U accelerate
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)Note : Le modèle Gemma 2 9B-It est volumineux, et même avec une mémoire GPU de 16 Go, nous ne pouvons pas charger le modèle complet. C'est pourquoi nous chargeons le modèle en quantification 4 bits. quantification de 4 bits.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig, AutoConfig
modelName = "google/gemma-2-9b-it"
bnbConfig = BitsAndBytesConfig(
load_in_4bit = True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
tokenizer = AutoTokenizer.from_pretrained(modelName)
model = AutoModelForCausalLM.from_pretrained(
modelName,
device_map = "auto",
quantization_config=bnbConfig
)from IPython.display import Markdown, display
system = "You are a skilled software architect who consistently creates system designs for various applications."
user = "Design a system with the ASCII diagram for the customer support application."
prompt = f"System: {system} \n User: {user} \n AI: "
inputs = tokenizer(prompt, return_tensors='pt', padding=True, truncation=True).to("cuda")
outputs = model.generate(**inputs, max_length=500, num_return_sequences=1)
text = tokenizer.decode(outputs[0], skip_special_tokens=True)
Markdown(text.split("AI:")[1])Comme on peut le constater, le modèle Gemma 2 a fait un excellent travail.
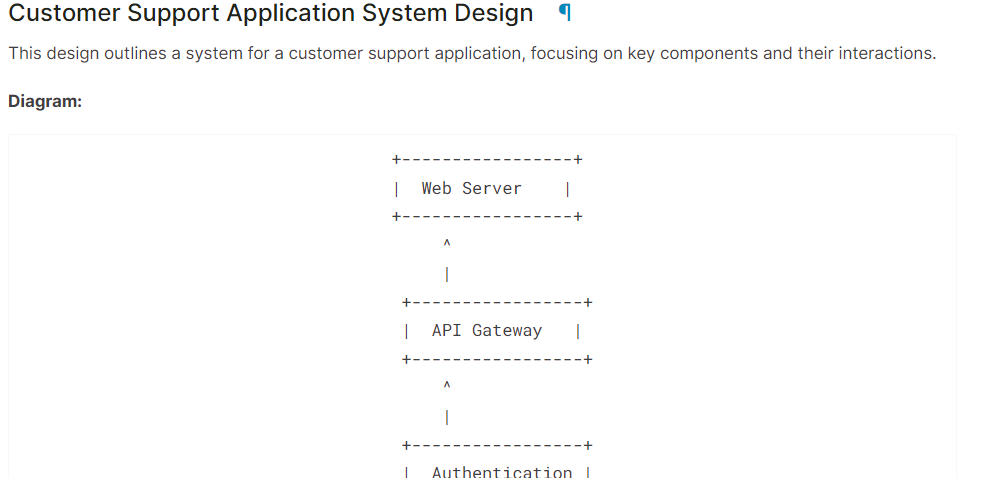
Si vous avez des difficultés à exécuter le code ci-dessus, veuillez vous référer au carnet de notes Kaggle : Gemma 2 Simple Inference on GPU.
Dans cette section, nous allons affiner le modèle Gemma 2 9B-It sur l'ensemble de données de santé. données sur les soins de santéqui consiste en des conversations entre des patients et des médecins. Nous allons charger le modèle et le tokenizer, charger le jeu de données, convertir le jeu de données, configurer le modèle en utilisant des arguments d'entraînement, et suivre les performances du modèle en utilisant l'API Weights and Biases.
Si vous souhaitez comprendre le fonctionnement de la théorie du réglage fin, lisez notre guide, Guide d'introduction aux LLM Fine-Tuning.
Installez les paquets Python nécessaires au chargement, à la mise au point et à l'évaluation du modèle sur le jeu de données médicales.
%%capture
%pip install -U transformers
%pip install -U datasets
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes
%pip install -U wandbChargez les paquets Python nécessaires et les fonctions.
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
HfArgumentParser,
TrainingArguments,
pipeline,
logging,
)
from peft import (
LoraConfig,
PeftModel,
prepare_model_for_kbit_training,
get_peft_model,
)
import os, torch, wandb
from datasets import load_dataset
from trl import SFTTrainer, setup_chat_formatConnectez-vous à Hugging Face CLI en utilisant la clé API que nous avons enregistrée à l'aide des secrets Kaggle.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)
Chargez la clé API Weights and Biases à partir des secrets Kaggle pour lancer le projet de suivi des performances des modèles.
wb_token = user_secrets.get_secret("wandb")
wandb.login(key=wb_token)
run = wandb.init(
project='Fine-tune Gemma-2-9b-it on HealthCare Dataset',
job_type="training",
anonymous="allow"
)Définition de l'ID du modèle et de l'ensemble de données afin que nous puissions les charger à partir du Hugging Face Hub. En outre, nous devons définir le nom du modèle affiné afin de créer un référentiel de modèles sur Hugging Face et de pousser le modèle affiné.
base_model = "google/gemma-2-9b-it"
dataset_name = "lavita/ChatDoctor-HealthCareMagic-100k"
new_model = "Gemma-2-9b-it-chat-doctor"Définition du type de données et mise en œuvre de l'attention basée sur le GPU.
if torch.cuda.get_device_capability()[0] >= 8:
!pip install -qqq flash-attn
torch_dtype = torch.bfloat16
attn_implementation = "flash_attention_2"
else:
torch_dtype = torch.float16
attn_implementation = "eager"Nous devons créer la configuration QLoRA afin de pouvoir charger le modèle avec une précision de 4 bits, ce qui réduit l'utilisation de la mémoire et accélère le processus de réglage fin.
# QLoRA config
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch_dtype,
bnb_4bit_use_double_quant=True,
)
En utilisant l'URL du modèle, la configuration LoRA et l'implémentation de l'attention, chargez le modèle Gemma 2 9B-It et le tokenizer.
# Load model
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=bnb_config,
device_map="auto",
attn_implementation=attn_implementation
)
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(base_model, trust_remote_code=True)Créez la fonction Python qui utilisera le modèle et extraira les noms de tous les modules linéaires.
import bitsandbytes as bnb
def find_all_linear_names(model):
cls = bnb.nn.Linear4bit
lora_module_names = set()
for name, module in model.named_modules():
if isinstance(module, cls):
names = name.split('.')
lora_module_names.add(names[0] if len(names) == 1 else names[-1])
if 'lm_head' in lora_module_names: # needed for 16 bit
lora_module_names.remove('lm_head')
return list(lora_module_names)
modules = find_all_linear_names(model)La mise au point du modèle complet prendra beaucoup de temps. Pour accélérer le processus de formation, nous créerons et attacherons la couche d'adaptation, ce qui permettra d'accélérer le processus et d'économiser de la mémoire.
La couche d'adoption est créée à l'aide des modules cibles et du type de tâche. Ensuite, nous définissons le format du chat pour le modèle et le tokenizer. Enfin, nous rattachons le modèle de base à l'adaptateur pour créer un modèle PEFT (Parameter Efficient Fine-Tuning).
# LoRA config
peft_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules=modules
)
model, tokenizer = setup_chat_format(model, tokenizer)
model = get_peft_model(model, peft_config)Nous allons maintenant charger le fichier lavita/ChatDoctor-HealthCareMagic-100k du hub Hugging Face. L'ensemble de données se compose de trois colonnes :
Après avoir chargé l'ensemble de données, nous le mélangeons et sélectionnons 1000 échantillons pour réduire encore davantage le temps d'apprentissage. Enfin, nous créerons le format du chat à l'aide du modèle de chat par défaut et l'utiliserons pour créer la colonne "texte".
#Importing the dataset
dataset = load_dataset(dataset_name, split="all")
dataset = dataset.shuffle(seed=65).select(range(1000)) # Only use 1000 samples for quick demo
def format_chat_template(row):
row_json = [{"role": "system", "content": row["instruction"]},
{"role": "user", "content": row["input"]},
{"role": "assistant", "content": row["output"]}]
row["text"] = tokenizer.apply_chat_template(row_json, tokenize=False)
return row
dataset = dataset.map(
format_chat_template,
num_proc= 4,
)
datasetSortie :
Dataset({
features: ['instruction', 'input', 'output', 'text'],
num_rows: 1000
})Examinons la colonne "texte" de la ligne 3.
dataset['text'][3]La colonne "texte" contient des instructions, la requête du patient et la réponse du médecin dans le style OpenAI.

Pour l'évaluation du modèle, nous diviserons l'ensemble de données en deux parties, l'une pour la formation et l'autre pour le test.
dataset = dataset.train_test_split(test_size=0.1)Nous allons maintenant définir l'argument de formation et les paramètres STF, puis lancer le processus de formation.
Vous pouvez modifier les différents hyperparamètres en fonction de votre environnement, de votre capacité de calcul et de votre mémoire. Les hyperparamètres ci-dessous sont optimisés pour le carnet Kaggle. Par conséquent, si vous souhaitez faire la même chose sur Google Colab, envisagez d'expérimenter avec des algorithmes de formation.
# Setting Hyperparamter
training_arguments = TrainingArguments(
output_dir=new_model,
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=2,
optim="paged_adamw_32bit",
num_train_epochs=1,
eval_strategy="steps",
eval_steps=0.2,
logging_steps=1,
warmup_steps=10,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
report_to="wandb"
)
# Setting sft parameters
trainer = SFTTrainer(
model=model,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
peft_config=peft_config,
max_seq_length= 512,
dataset_text_field="text",
tokenizer=tokenizer,
args=training_arguments,
packing= False,
)
model.config.use_cache = False
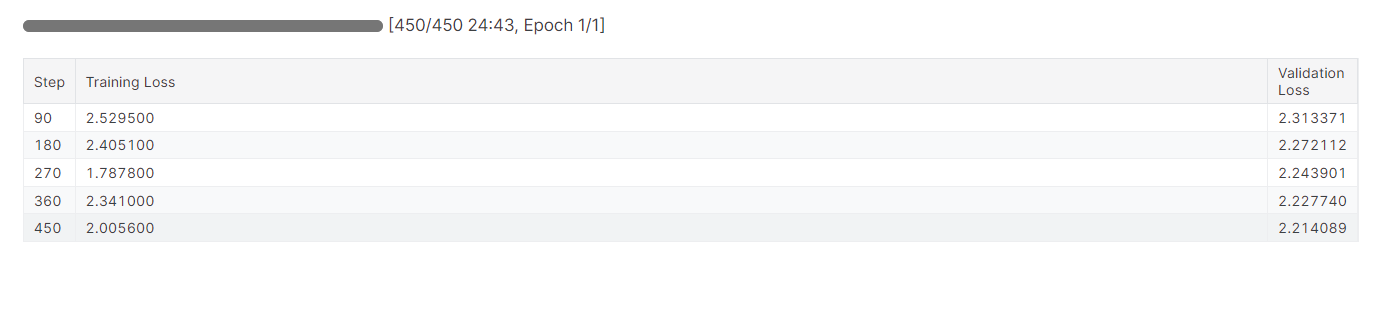
trainer.train()Il a fallu près de 25 minutes pour affiner le modèle et, comme nous pouvons le constater, la perte d'entraînement et de validation a progressivement diminué. Pour améliorer les performances, essayez d'affiner le modèle sur l'ensemble des données pendant au moins trois époques.
 Le réglage fin peut être un peu technique pour les débutants et les personnes non techniques. Si vous recherchez une solution plus simple, vous pouvez consulter le site Fine-Tuning OpenAI's GPT-4 : Un guide étape par étape tutorial. Il présente un moyen simple d'affiner un modèle de pointe à l'aide de l'API OpenAI.
Le réglage fin peut être un peu technique pour les débutants et les personnes non techniques. Si vous recherchez une solution plus simple, vous pouvez consulter le site Fine-Tuning OpenAI's GPT-4 : Un guide étape par étape tutorial. Il présente un moyen simple d'affiner un modèle de pointe à l'aide de l'API OpenAI.
Nous terminerons l'expérience sur les poids et les biais, qui donnera lieu à un rapport d'évaluation.
wandb.finish()
model.config.use_cache = True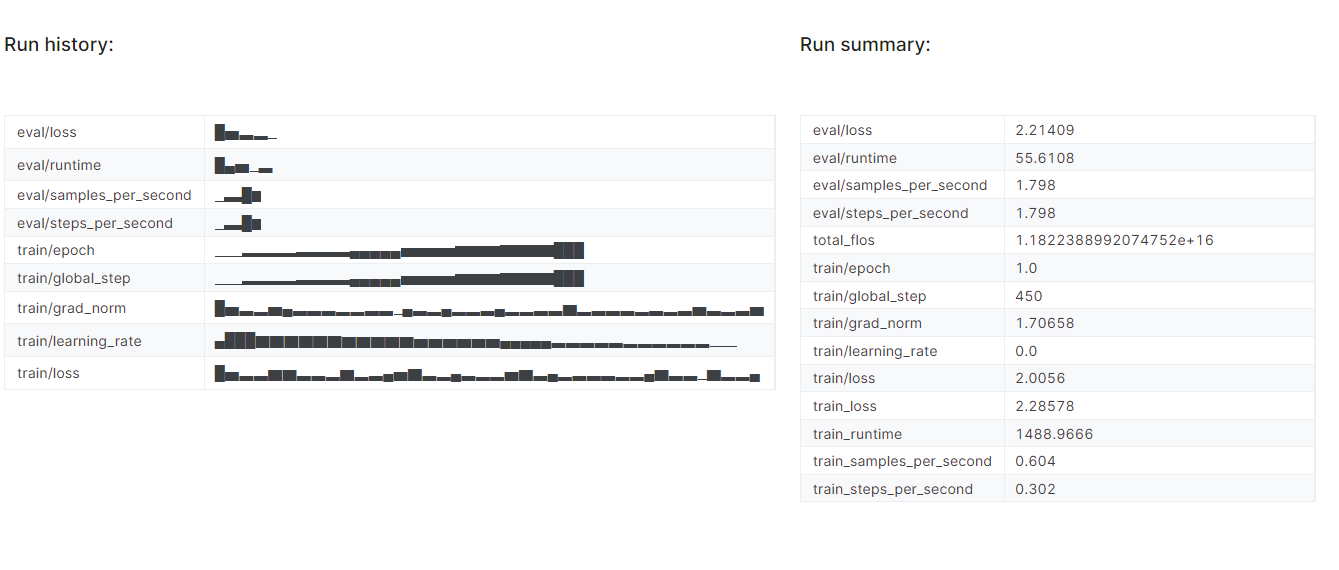
Pour consulter le rapport détaillé, rendez-vous sur votre compte Pondérations et Biais et cliquez sur "Fine-tune Gemma-2-9b-it on Healthcare Dataset" (Ajustement de Gemma-2-9b-it sur des données de santé). nom du projet.
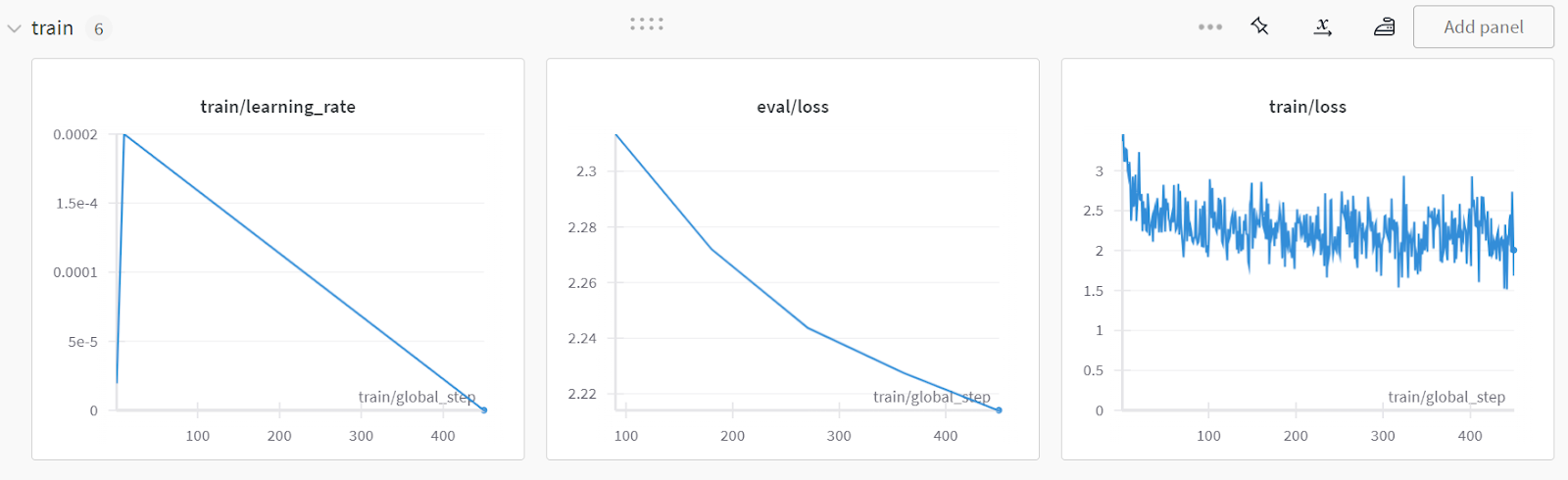
La capture d'écran provient de wandb.ai
Nous allons maintenant enregistrer l'adoptant affiné localement et le pousser également vers le hub de Hugging Face.
trainer.model.save_pretrained(new_model)
trainer.model.push_to_hub(new_model, use_temp_dir=False)Pour utiliser l'adoptant sauvegardé dans un autre carnet Kaggle, nous devons sauvegarder le carnet. Pour ce faire, cliquez sur "Enregistrer la version" en haut à droite. Sélectionnez ensuite "Enregistrement rapide" et "Toujours enregistrer la sortie lors de la création d'un enregistrement rapide", puis cliquez sur le bouton "Enregistrer".
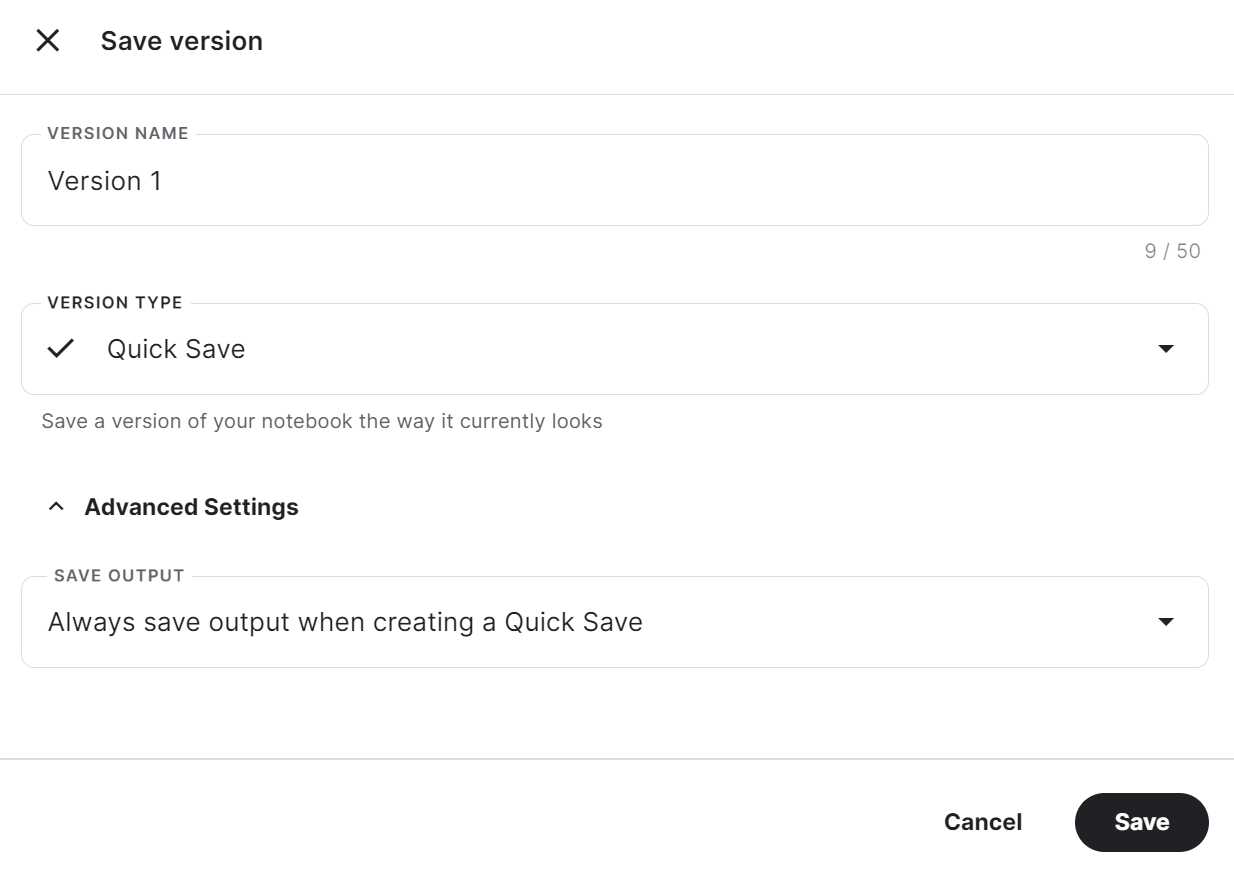
Si vous avez des difficultés à exécuter le code, veuillez cloner le Kaggle Notebook et exécutez-le. Vous devez configurer la clé d'API de Hugging Face et de Weights & Biases à l'aide des secrets Kaggle.
Pour déterminer si le réglage fin ou la génération améliorée par récupération (RAG) est plus adapté à votre cas d'utilisation spécifique, je vous recommande vivement de lire le document suivant RAG vs Fine-Tuning sur le blog.
Nous allons maintenant fusionner l'adaptateur avec le modèle de base et pousser le modèle complet vers le hub de Hugging Face.
Créez un nouveau notebook Python avec un processeur comme accélérateur et installez les paquets Python nécessaires.
Pourquoi utiliser l'unité centrale comme accélérateur ? Ne sera-t-il pas lent ? Oui, mais la machine GPU de Kaggle ne nous fournit que 16 Go de mémoire GPU, ce qui est suffisant pour un modèle à 7 milliards de paramètres, mais pas pour un modèle à 9 milliards de paramètres. L'unité centrale fournit 30 Go, ce qui est suffisant pour charger le modèle de base et l'adaptateur.
%%capture
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U accelerate
%pip install -U peft
%pip install -U trlObtenez la clé API à partir des secrets Kaggle et connectez-vous à la CLI de Hugging Face.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)Pour accéder au modèle sauvegardé, vous devez importer le carnet Kaggle sauvegardé. Pour ce faire, cliquez sur le bouton "Ajouter une contribution" en haut à droite et sélectionnez l'onglet "Votre travail". Ensuite, cliquez sur le bouton plus du carnet enregistré pour accéder à tous les fichiers qu'il contient.
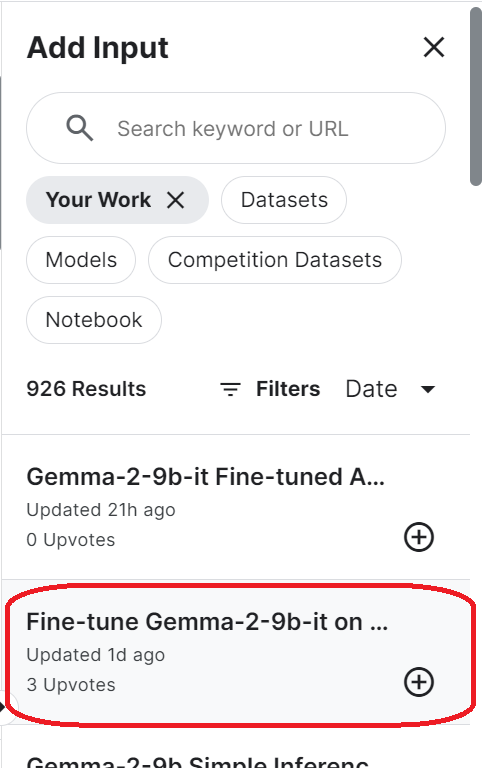
Configurez l'URL du modèle de base en indiquant le nom du référentiel Hugging Face. En outre, configurez l'URL de l'adaptateur en spécifiant le répertoire local dans lequel l'adaptateur est enregistré.
base_model_url = "google/gemma-2-9b-it"
new_model_url = "/kaggle/input/fine-tune-gemma-2-9b-it-on-healthcare-dataset/Gemma-2-9b-it-chat-doctor/"Chargez le tokenizer et le modèle complet en utilisant l'URL du modèle de base. Veillez à définir le périphérique "cpu" et le type "float16".
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig, pipeline
from peft import PeftModel
import torch
from trl import setup_chat_format
# Reload tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(base_model_url)
base_model_reload= AutoModelForCausalLM.from_pretrained(
base_model_url,
low_cpu_mem_usage=True,
return_dict=True,
torch_dtype=torch.float16,
device_map="cpu",
)Définissez le format du chat sur le modèle de base nouvellement chargé et combinez-le avec l'adoptant. Enfin, nous chargerons et fusionnerons l'adoptant avec le modèle de base.
La fonction merge_and_unload() nous aidera à fusionner les poids de l'adaptateur avec le modèle de base et à l'utiliser comme un modèle autonome.
base_model_reload, tokenizer = setup_chat_format(base_model_reload, tokenizer)
model = PeftModel.from_pretrained(base_model_reload, new_model_url)
model = model.merge_and_unload()Enregistrez localement le modèle complet et le tokenizer.
model.save_pretrained("Gemma-2-9b-it-chat-doctor")
tokenizer.save_pretrained("Gemma-2-9b-it-chat-doctor")Poussez également tous les fichiers de modèle et le tokenizer vers le hub Hugging Face.
model.push_to_hub("Gemma-2-9b-it-chat-doctor", use_temp_dir=False)
tokenizer.push_to_hub("Gemma-2-9b-it-chat-doctor", use_temp_dir=False)Vous pouvez vous rendre dans le référentiel de votre modèle Hugging Face et consulter tous les fichiers.
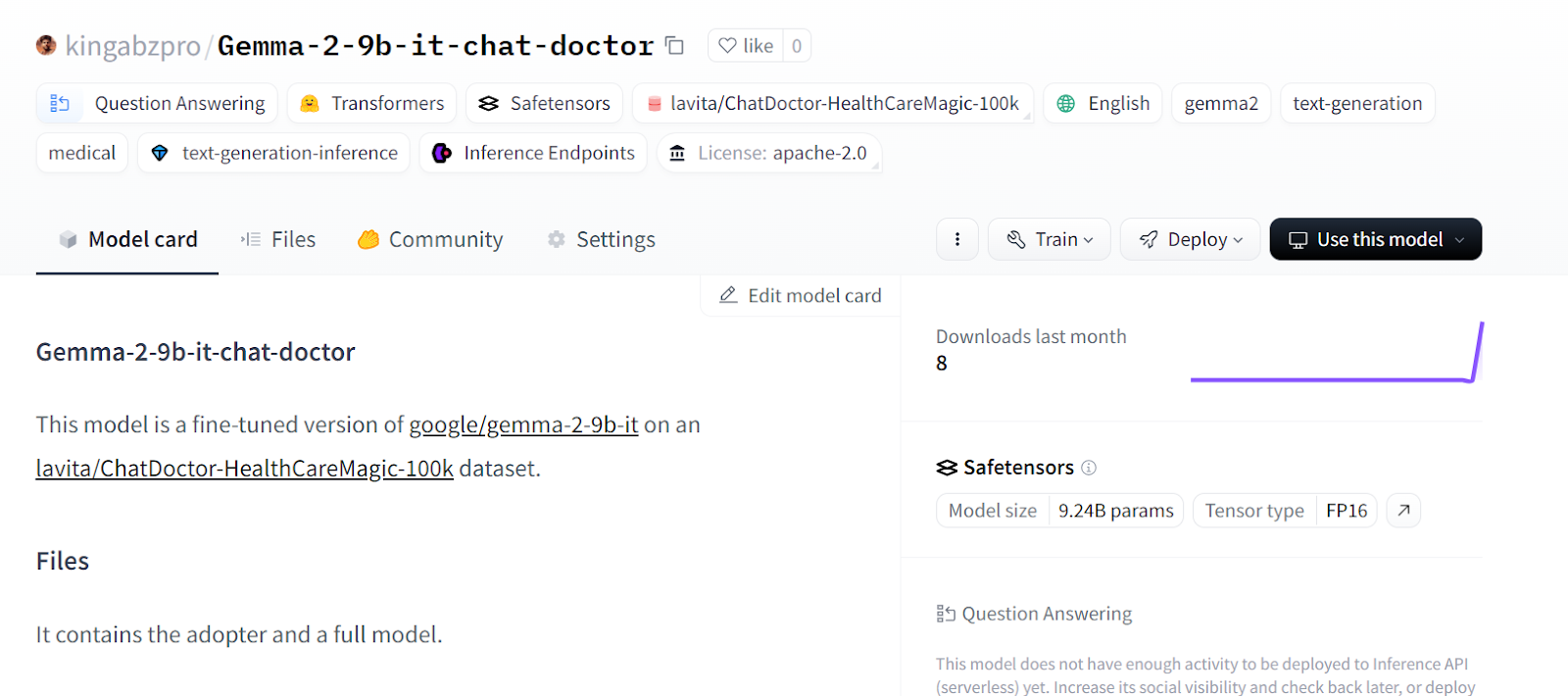
Source : kingabzpro/Gemma-2-9b-it-chat-doctor - Hugging Face
Si vous rencontrez des problèmes pour fusionner des modèles à l'aide du CPU, veuillez vous référer au Carnet de notes Kaggle.
Avec le programme GGUF My Repo Hugging Face, la conversion et la quantification des modèles sont devenues faciles et rapides. Il vous suffit de vous connecter et de fournir l'identifiant du modèle.
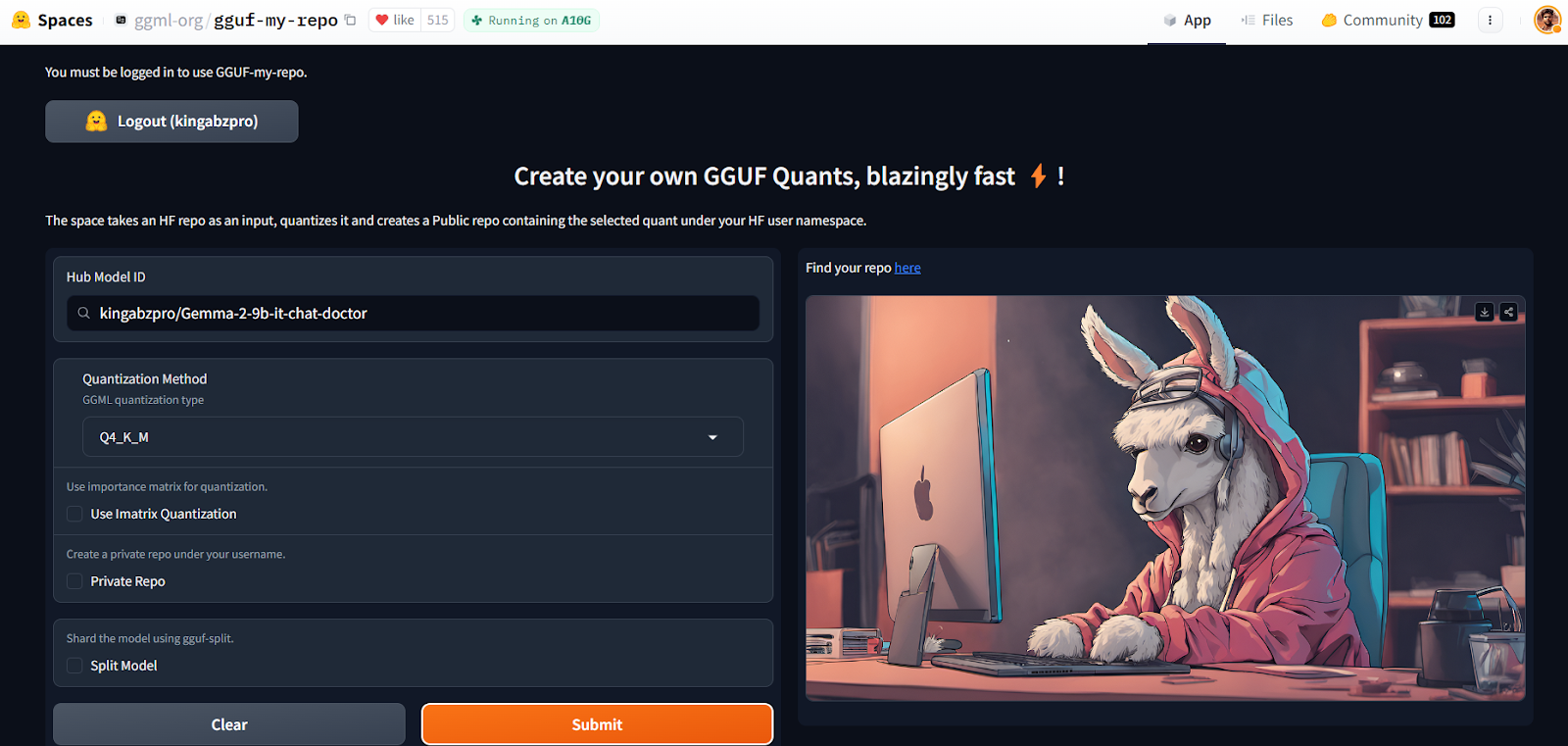
Source : GGUF My Repo - un espace Hugging Face par ggml-org
Il créera pour vous un nouveau dépôt de modèles avec un fichier de modèle quantifié que vous pourrez télécharger ultérieurement pour l'utiliser localement. C'est aussi simple que cela.
Vous pouvez vous familiariser avec la théorie de la quantification en lisant notre article sur Quantization for Large Language Models (LLMs) : Réduire efficacement la taille des modèles d'IA.
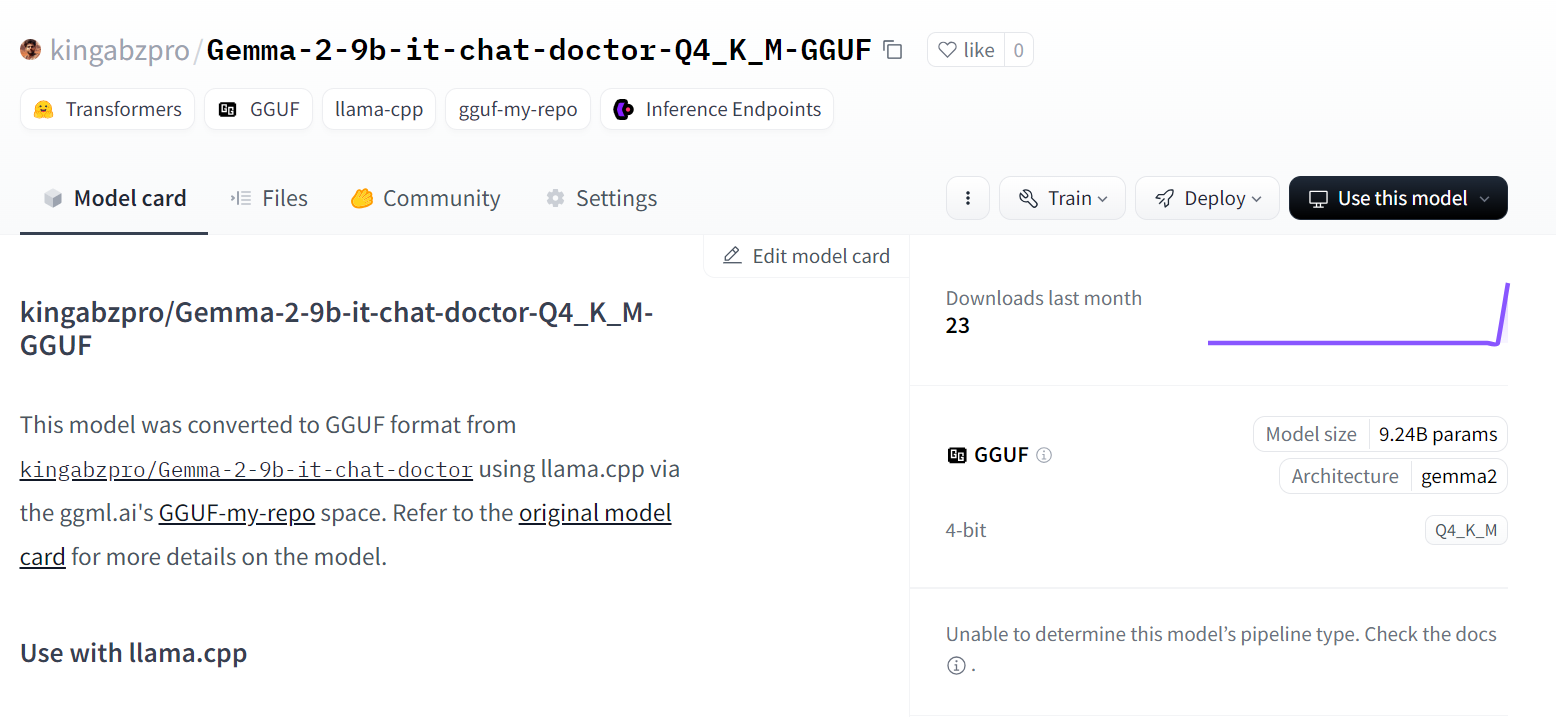
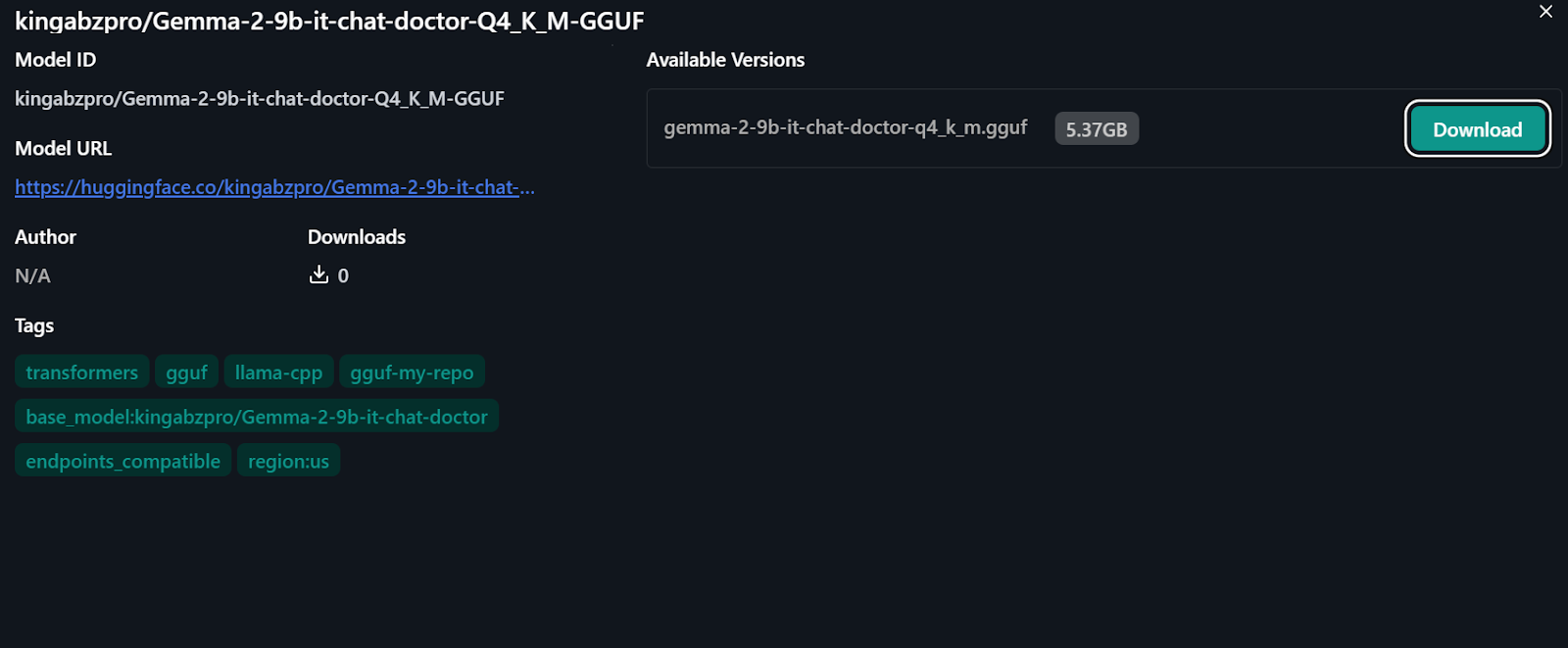
Source : kingabzpro/Gemma-2-9b-it-chat-doctor-Q4_K_M-GGUF - Hugging Face
Mais si vous voulez vous salir les mains et exécuter des scripts llama.cpp par vous-même, alors vous devriez consulter le document suivant Ajuster Llama 3 et l'utiliser localement .
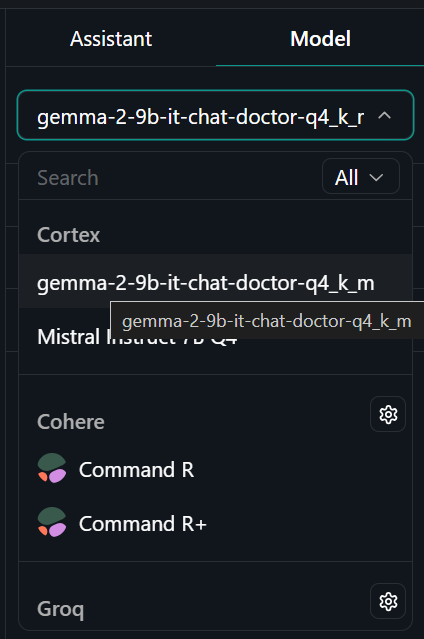
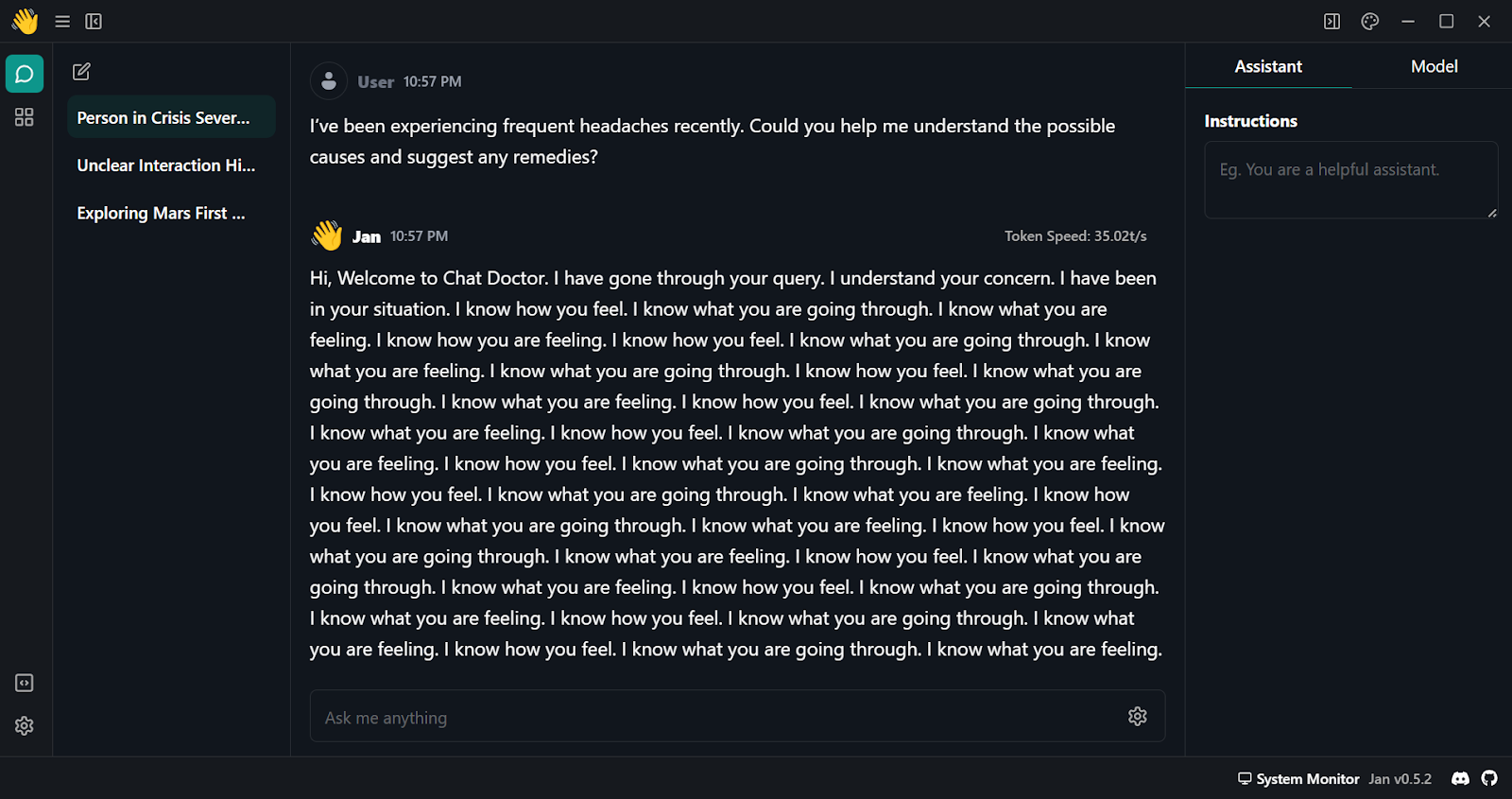
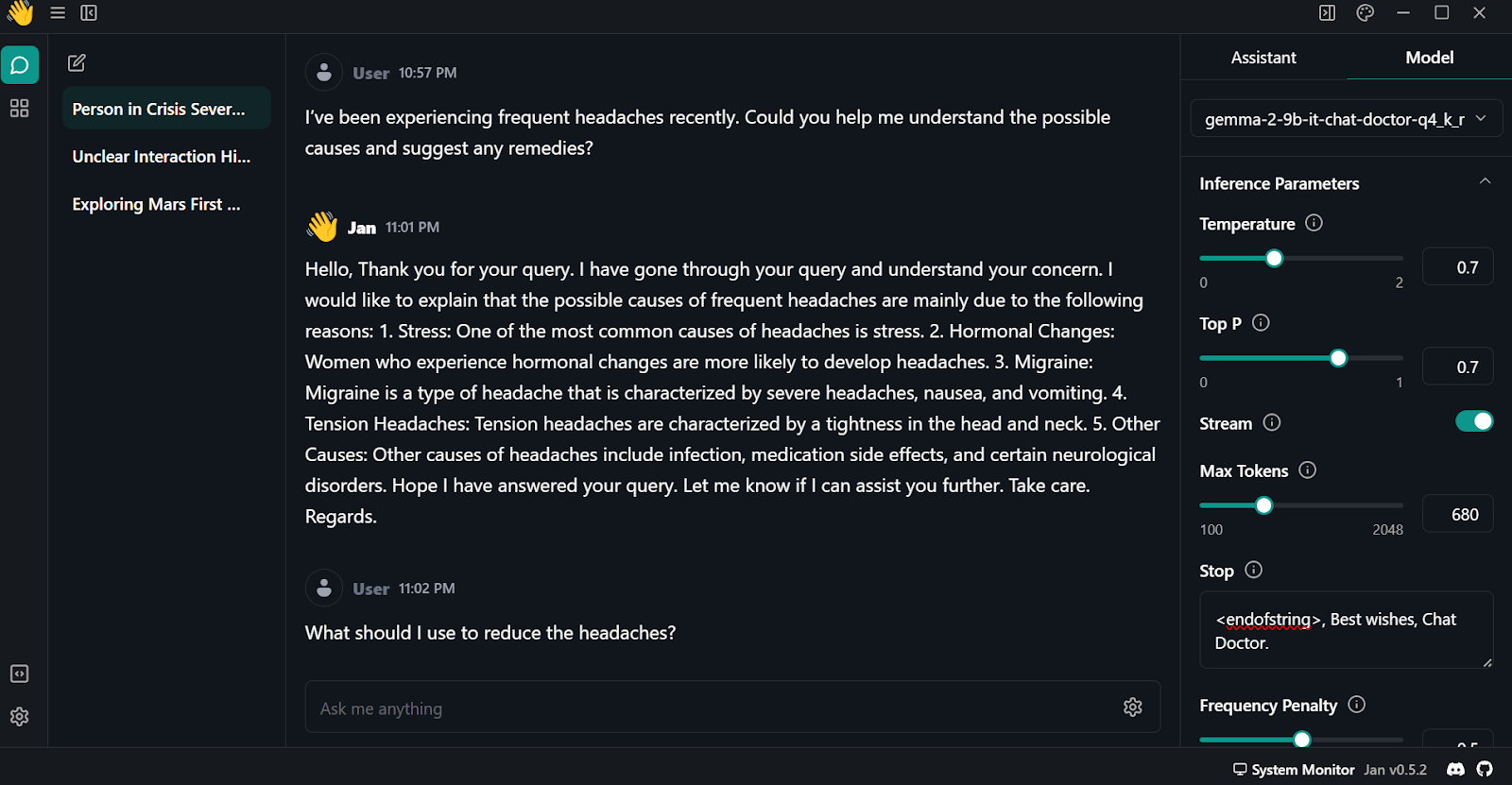
Pour utiliser le modèle quantifié localement :
Gemma 2 est un excellent modèle, et il peut être encore meilleur si vous utilisez le cadre Keras 3 pour le réglage fin distribué et l'inférence de modèle. Vous obtiendrez un temps de formation et d'inférence plus rapide qu'en utilisant le cadre Transformers.
Vous pouvez apprendre à affiner le modèle Gemma et à exécuter l'inférence du modèle à l'aide de Keras 3 en suivant les instructions suivantes Ajuster finement et exécuter l'inférence sur le modèle Gemma de Google avec TPU en suivant le tutoriel.
Dans ce tutoriel, nous avons appris à connaître les modèles Gemma 2 et à y accéder à l'aide de la bibliothèque Transformer. Nous avons également appris à affiner le modèle sur les conversations patient-médecin, à fusionner le modèle adopté avec le modèle de base, à pousser le modèle complet vers le hub Hugging Face, à convertir et quantifier le modèle en utilisant le Hugging Face Space, à télécharger et exécuter le modèle localement sur l'ordinateur portable à l'aide de l'application Jan.
Il s'agit d'un projet amusant que les passionnés d'IA devraient essayer. Cela leur permettra d'améliorer leur capacité à résoudre les problèmes qui surviennent lors de l'ajustement de modèles linguistiques de grande taille. Les principaux défis sont souvent liés aux limitations de mémoire et de calcul, ainsi qu'à la minimisation des pertes.
Vous pouvez également apprendre à développer vos propres LLM avec PyTorch et Hugging Face dans la section Développer de grands modèles de langage sur DataCamp.
Principaux cours de LLM
Cours
Cours
Cours
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
blog
Nathaniel Taylor-Leach
8 min
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach