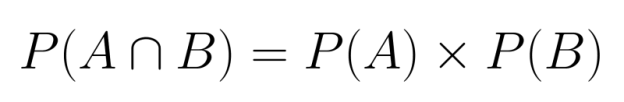

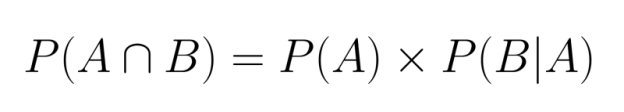
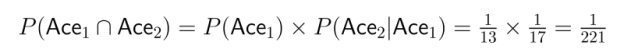
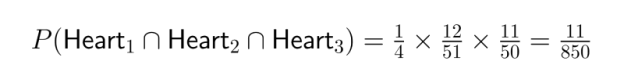
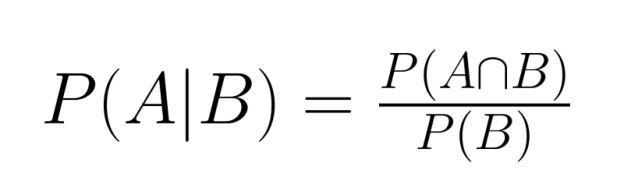
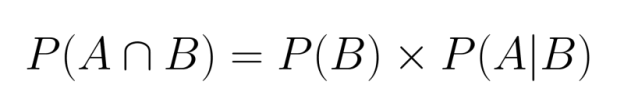
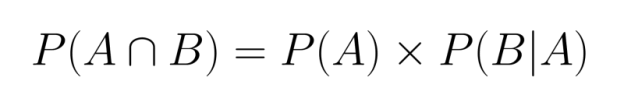
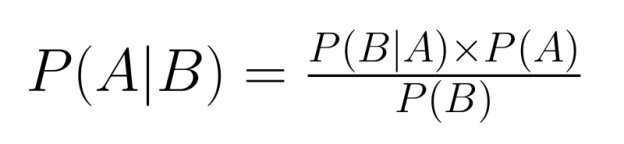
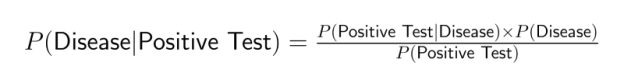

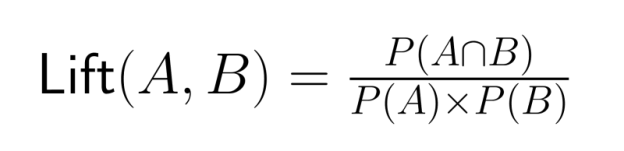
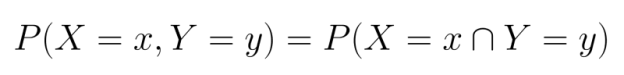
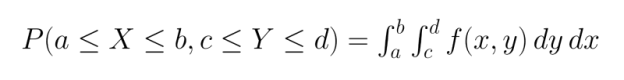
Curso
Fundamentos de probabilidad en R
4 h
42.2K
Cuando un analista meteorológico predice una tormenta severa, no solo está pronosticando lluvias intensas o vientos fuertes de forma independiente, sino que está evaluando la probabilidad de que ambas condiciones meteorológicas se den al mismo tiempo. Este escenario ilustrauna probabilidad conjunta e : la probabilidad de que dos eventos ocurran simultáneamente.
En este artículo, exploraremos cómo funciona la probabilidad conjunta, examinaremos fórmulas para eventos dependientes e independientes, trabajaremos con ejemplos prácticos y veremos cómo se aplica este concepto en la ciencia de datos y machine learning. Para obtener una referencia práctica sobre las definiciones y reglas básicas de probabilidad, consulta DataCamp's Introducción a la hoja de referencia de reglas de probabilidad de DataCamp.
La probabilidad conjunta representa la probabilidad de que dos (o más) eventos ocurran al mismo tiempo. Matemáticamente, lo denotamos como P(A∩B), que se lee como «la probabilidad de A intersección B» o, simplemente, «la probabilidad de A y B».
Para entender la probabilidad conjunta, primero hay que establecer un contexto:
La probabilidad conjunta difiere significativamente entre eventos independientes y dependientes:
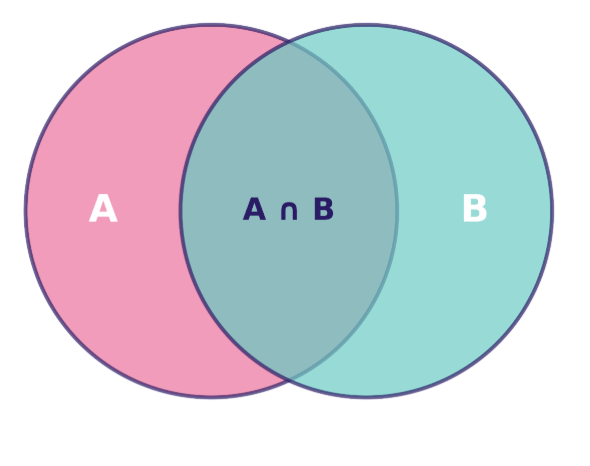
Podemos visualizar la probabilidad conjunta utilizando un diagrama de Venn, en el que la región superpuesta representa la intersección de los eventos, es decir, los escenarios en los que ambos eventos ocurren simultáneamente:
Diagrama de Venn que muestra la relación entre los conjuntos A y B, con su intersección A ∩ B resaltada. Imagen del autor.
El área de esta región superpuesta, en relación con el espacio muestral total, nos da P(A∩B), la probabilidad conjunta que queremos calcular.
Para comprender cómo calcular la probabilidad conjunta, se requieren diferentes enfoques dependiendo de si los eventos son independientes o dependientes. Examinemos ambos escenarios y exploremos las reglas que rigen estos cálculos.
Cuando dos eventos son independientes, calcular su probabilidad conjunta resulta sencillo. Dado que ninguno de los dos eventos influye en el otro, podemos simplemente multiplicar sus probabilidades individuales:
P(A∩B) = P(A) × P(B)
Esta regla de multiplicación se aplica porque la independencia significa que saber que ocurrió un evento no proporciona información sobre la probabilidad de que ocurra el otro evento.
Ejemplo: Considera lanzar dos monedas justas. La probabilidad de que salga cara en la primera moneda es de 1/2, y la probabilidad de que salga cara en la segunda moneda también es de 1/2. Dado que estos eventos son independientes (el primer lanzamiento no afecta al segundo), la probabilidad de obtener cara en ambas monedas es:
Esto significa que hay un 25 % de probabilidades de sacar dos caras seguidas.
Cuando los eventos son dependientes, debemos tener en cuenta cómo el primer evento afecta a la probabilidad del segundo. Esto requiere utilizar la probabilidad condicional en nuestro cálculo:
Aquí, P(B|A) representa la probabilidad de que ocurra el evento B dado que el evento A ya ha ocurrido.
Ejemplo: Imagina que sacas dos cartas de una baraja estándar sin reemplazo. ¿Cuál es la probabilidad de sacar dos ases?
Esto ilustra cómo la dependencia afecta significativamente al cálculo de la probabilidad conjunta.
Los cálculos anteriores demuestran la regla de multiplicación de la probabilidad. Esta regla se extiende a más de dos eventos, lo que nos permite calcular probabilidades conjuntas para múltiples eventos utilizando una cadena de probabilidades condicionales:
Esto se conoce como la regla de la cadena, que proporciona una forma sistemática de descomponer probabilidades conjuntas complejas en partes manejables.
Ejemplo: Considera la probabilidad de sacar tres corazones seguidos de una baraja estándar sin reemplazo:
La regla de la cadena resulta especialmente valiosa en la ciencia de datos a la hora de modelar secuencias de eventos o trabajar con procesos de varias etapas.
Para consolidar nuestra comprensión de la probabilidad conjunta, veamos algunos ejemplos clásicos y exploremos aplicaciones prácticas que demuestran cómo funcionan estos conceptos en diversos contextos.
Imagina que lanzas dos dados de seis caras. ¿Cuál es la probabilidad de sacar un 4 en el primer dado y un 6 en el segundo?
Dado que el resultado del primer lanzamiento no afecta al segundo, se trata de eventos independientes:
Esto nos indica que hay aproximadamente un 2,78 % de probabilidades de que se produzca esta combinación específica.
Calculemos la probabilidad de sacar una carta roja seguida de un as de una baraja estándar de 52 cartas sin reemplazo.
Dado que estamos extrayendo sin reemplazo, estos eventos son dependientes:
Para manejar esto adecuadamente, debemos considerar ambos escenarios:
Por lo tanto, la probabilidad conjunta total es: P(Carta roja ∩ As en la segunda jugada) = 24/663 + 1/442 = (24×2 + 3)/1326 = 51/1326 = 1/26
La probabilidad es de aproximadamente el 3,85 %.
Considera una bolsa que contiene 5 canicas azules y 3 canicas verdes. Calculemos la probabilidad de sacar dos canicas azules en dos escenarios diferentes.
Con sustitución:
Sin reemplazo:
Esta comparación pone de relieve cómo la dependencia creada por no reemplazar las canicas reduce la probabilidad conjunta.
La probabilidad conjunta es fundamental en contextos médicos a la hora de evaluar múltiples síntomas o resultados de pruebas. Considera un escenario diagnóstico en el que los médicos deben evaluar a pacientes con los síntomas A y B para detectar una afección específica.
Basado en datos históricos:
Esta probabilidad conjunta ayuda a los médicos a evaluar la probabilidad de diferentes afecciones. Cabe señalar que P(A ∩ B) no es igual a P(A) × P(B) = 0,30 × 0,25 = 0,075, lo que indica que estos síntomas no son independientes: saber que un paciente tiene un síntoma aumenta la probabilidad de que tenga el otro.
Los analistas de inversiones a menudo necesitan evaluar la probabilidad conjunta de que se den varias condiciones de mercado al mismo tiempo. Considera el caso de un analista que evalúa el riesgo tanto de una caída del mercado bursátil como de un aumento de los tipos de interés en el próximo trimestre.
Si sus modelos sugieren:
El cálculo de la probabilidad conjunta sería: P(Caída del mercado bursátil ∩ Aumento de los tipos de interés) = 0,60 × 0,45 = 0,27
Esta probabilidad del 27 % ayuda a cuantificar el riesgo del portafolio y orienta las estrategias de cobertura para protegerse frente a este escenario.
Estos ejemplos demuestran cómo la probabilidad conjunta constituye una poderosa herramienta para cuantificar la incertidumbre en diversos campos, ya sea para analizar simples juegos de azar o para tomar decisiones complejas en medicina y finanzas.
Las probabilidades conjuntas y condicionales son conceptos estrechamente relacionados que nos permiten analizar escenarios complejos que implican múltiples eventos. Comprender vuestra relación proporciona herramientas poderosas para el razonamiento probabilístico.
La relación entre la probabilidad conjunta y la probabilidad condicional se expresa mediante la fórmula:
P(A|B) = P(A∩B) / P(B)
Reorganizando esta ecuación, podemos expresar la probabilidad conjunta en términos de probabilidad condicional:
Esta relación muestra que podemos calcular la probabilidad conjunta si conocemos la probabilidad marginal de un evento y la probabilidad condicional del otro dado el primero.
Del mismo modo, también podríamos escribir:
Ambas formulaciones son válidas y equivalentes, lo que demuestra la naturaleza simétrica de la probabilidad conjunta.
La relación entre la probabilidad conjunta y la probabilidad condicional es fundamental para el teorema de Bayes, una herramienta básica en la inferencia probabilística:
El teorema de Bayes nos permite «invertir» las probabilidades condicionales: si conocemos P(B|A), podemos calcular P(A|B). Esto resulta muy valioso cuando tenemos información sobre una relación condicional, pero necesitamos razonar sobre la relación inversa.
Por ejemplo, las pruebas médicas suelen proporcionar información sobre P(prueba positiva|enfermedad), pero los médicos necesitan determinar P(enfermedad|prueba positiva). El teorema de Bayes salva esta diferencia incorporando la probabilidad conjunta:
La probabilidad conjunta constituye la base de numerosas técnicas y aplicaciones de la ciencia de datos. Comprender cómo interactúan múltiples eventos ayuda a los científicos de datos a crear modelos más precisos y realizar mejores predicciones en diversos ámbitos.
La probabilidad conjunta es fundamental para muchos algoritmos de clasificación, en particular para los clasificadores Naive Bayes. Estos populares modelos de machine learning calculan la probabilidad de diferentes resultados basándose en la presencia de múltiples características.
El enfoque Naive Bayes aplica el teorema de Bayes con una suposición «ingenua» de que las características son condicionalmente independientes. Esto simplifica los cálculos de probabilidad conjunta:
A pesar de esta simplificación, los clasificadores Naive Bayes funcionan muy bien para:
Este enfoque es computacionalmente eficiente y, a menudo, funciona sorprendentemente bien incluso cuando la hipótesis de independencia no se cumple estrictamente.
La probabilidad conjunta desempeña un papel crucial en los sistemas de detección de fraudes, en los que es necesario evaluar conjuntamente múltiples factores de riesgo. Los algoritmos modernos de detección de fraudes analizan combinaciones de comportamientos sospechosos para identificar transacciones potencialmente fraudulentas.
Considera un sistema de pago en línea que supervisa varias señales:
Aunque cada señal por sí sola puede no indicar fraude, ciertas combinaciones específicas (su aparición conjunta) pueden aumentar significativamente las sospechas. Por ejemplo, una transacción de gran cuantía, realizada desde un dispositivo nuevo, en un país extranjero y a una hora inusual, representa un evento conjunto con una probabilidad de fraude potencialmente alta.
Esta evaluación conjunta de probabilidades permite una puntuación de riesgos más sofisticada que la evaluación aislada de cada factor, lo que reduce tanto los falsos positivos como los falsos negativos.
Los conceptos de probabilidad conjunta son fundamentales para muchos modelos avanzados de machine learning, entre los que se incluyen:
Redes bayesianas: Estos modelos gráficos representan variables y sus relaciones probabilísticas. Permiten razonar sobre distribuciones de probabilidad conjuntas complejas descomponiéndolas en probabilidades condicionales más simples. Las redes bayesianas se utilizan ampliamente en:
Modelos ocultos de Markov (HMM): Estos modelos secuenciales utilizan probabilidades conjuntas para modelar sistemas en los que el estado subyacente está oculto, pero produce resultados observables. Las aplicaciones incluyen:
Modelos gráficos probabilísticos: Estos abarcan una clase más amplia de modelos que utilizan estructuras gráficas para codificar distribuciones de probabilidad conjuntas complejas. Son herramientas esenciales para:
A través de estas aplicaciones, la probabilidad conjunta permite a los científicos de datos crear modelos que capturan las complejas interdependencias de los datos del mundo real, lo que conduce a predicciones más precisas y a una mejor toma de decisiones en situaciones de incertidumbre.
A pesar de su utilidad, la probabilidad conjunta a menudo se malinterpreta o se aplica incorrectamente. Examinemos algunos conceptos erróneos comunes y cómo evitarlos.
Uno de los errores más frecuentes es confundir P(A∩B) con P(A|B). Aunque están relacionados, representan conceptos diferentes:
Por ejemplo, la probabilidad de que una persona tenga diabetes y sea mayor de 65 años (conjunta) es diferente de la probabilidad de que una persona tenga diabetes dado que es mayor de 65 años (condicional).
Esta distinción es importante en muchos contextos analíticos. Por ejemplo, cuando un científico de datos informa que «el 5 % de los usuarios hicieron clic en un anuncio y realizaron una compra», esta probabilidad conjunta es muy diferente de «el 40 % de los usuarios que hicieron clic en un anuncio realizaron una compra», que es una probabilidad condicional.
Otro error común es asumir automáticamente que P(A∩B) = P(A) × P(B) sin verificar que los eventos sean realmente independientes. Esta suposición puede dar lugar a errores significativos cuando los eventos son realmente dependientes.
Por ejemplo, en el análisis de mercado, suponer que la compra del producto A y la del producto B son independientes puede llevar a una planificación incorrecta del inventario si estos productos son complementarios (como impresoras y tinta) o sustitutos (como diferentes marcas del mismo artículo).
Es fundamental comprobar la independencia: si P(A∩B) ≠ P(A) × P(B), los eventos son dependientes y es necesario realizar cálculos de probabilidad conjunta más precisos.
Cuando trabajas con probabilidades conjuntas, a veces os centráis exclusivamente en la intersección, ignorando la frecuencia global de los eventos individuales. Esto puede llevar a conclusiones erróneas sobre la solidez de las relaciones.
Por ejemplo, descubrir que el 90 % de los clientes que compraron los productos A y B también compraron el producto C puede parecer impresionante. Sin embargo, si el 89 % de todos los clientes compran el producto C independientemente, la relación aparente es mucho más débil de lo que parecía inicialmente.
Compara siempre las probabilidades conjuntas con las probabilidades marginales relevantes para evitar exagerar las relaciones entre los eventos. La razón de elevación —la relación entre la probabilidad conjunta y el producto de las probabilidades marginales— ofrece una medida más precisa de la asociación:
Un valor de elevación superior a 1 indica que los eventos ocurren juntos con más frecuencia de lo que cabría esperar si fueran independientes.
Comprender estos errores comunes ayuda a los científicos de datos a aplicar correctamente la probabilidad conjunta y obtener información significativa a partir del análisis probabilístico.
A medida que los científicos de datos avanzan en sus carreras, se encontrarán con aplicaciones más sofisticadas de la probabilidad conjunta. Exploremos algunos conceptos avanzados que se basan en los fundamentos que hemos establecido.
Cuando se enfrentan a problemas modernos de machine learning, los científicos de datos suelen trabajar con docenas o incluso cientos de variables simultáneamente. En estos espacios de alta dimensión, calcular y representar probabilidades conjuntas se convierte en un reto.
El número de parámetros necesarios para especificar una distribución conjunta crece exponencialmente con el número de variables, un fenómeno conocido como «la maldición de la dimensionalidad». Por ejemplo, una distribución conjunta de 10 variables binarias requiere 2¹⁰ - 1 = 1023 parámetros para especificarse por completo.
Para gestionar esta complejidad, los científicos de datos emplean técnicas como:
Estos enfoques facilitan los cálculos de probabilidad conjunta de alta dimensión para aplicaciones prácticas en áreas como la visión artificial, la genómica y el procesamiento del lenguaje natural.
Hasta ahora, nuestros ejemplos han versado principalmente sobre sucesos discretos, pero la probabilidad conjunta se extiende de forma natural a las variables continuas a través de las distribuciones de probabilidad conjunta.
Para variables discretas, trabajamos con funciones de masa de probabilidad conjunta (PMF), que especifican la probabilidad de que cada combinación de variables aleatorias adopte valores específicos:
Para las variables continuas, utilizamos funciones de densidad de probabilidad conjunta (PDF). A diferencia de las PMF, las PDF no proporcionan probabilidades directamente, sino que deben integrarse en regiones para hallar la probabilidad de que las variables se encuentren dentro de esas regiones:
Las distribuciones conjuntas comunes incluyen:
Comprender estas distribuciones permite realizar modelos más sofisticados de las relaciones entre variables continuas en campos como la economía, la bioinformática y las ciencias ambientales.
Varias herramientas de software y lenguajes de programación ofrecen funciones y bibliotecas para trabajar con probabilidades conjuntas:
Python:
R:
SQL:
Estas herramientas permiten aplicar conceptos de probabilidad conjunta a grandes conjuntos de datos, lo que permite a los científicos de datos crear modelos probabilísticos sofisticados para problemas complejos.
Para profundizar en tu comprensión de la probabilidad conjunta y sus aplicaciones en el análisis bayesiano, DataCamp ofrece varios cursos excelentes:
Estos cursos te ayudarán a desarrollar los conceptos tratados en este artículo y a aplicar técnicas de probabilidad conjunta para resolver problemas reales de ciencia de datos.
Como hemos visto a lo largo de este artículo, la probabilidad conjunta es un concepto estadístico fundamental con amplias aplicaciones en numerosos campos de la ciencia de datos. Los recursos de DataCamp, como los que se comparten en los Más de 40 recursos de estadística Python para ciencia de datos, proporcionan excelentes vías para reforzar tu comprensión. Esta completa colección incluye recomendaciones específicas para aprender teoría de la probabilidad, pensamiento bayesiano y otros conceptos estadísticos que se basan en la probabilidad conjunta.
Para aquellos que se preparan para puestos relacionados con la ciencia de datos, nuestras guía con las 35 preguntas y respuestas más frecuentes en entrevistas sobre estadística ofrece una valiosa práctica con preguntas sobre probabilidad conjunta, junto con otros conceptos estadísticos importantes. También creo que nuestros Rompecabezas de probabilidad en R es una opción divertida.
Aprende con DataCamp
Curso
Curso
Curso
blog
Tim Lu
12 min
blog
Matt Crabtree
15 min
blog
Matt Crabtree
10 min
Tutorial
Joanne Xiong
Tutorial
Arunn Thevapalan
Tutorial
Łukasz Deryło


