
Course
Foundations of Probability in R
4 hr
42.2K
When a weather analyst predicts a severe storm, they're not just forecasting heavy rain or strong winds independently – they're assessing the probability that both weather conditions will occur together. This scenario illustrates joint probability – the likelihood of two events happening simultaneously.
In this article, we'll explore how joint probability works, examine formulas for both dependent and independent events, work through practical examples, and see how this concept is applied in data science and machine learning. For a handy reference to basic probability definitions and rules, check out DataCamp's Introduction to Probability Rules Cheat Sheet.
Joint probability represents the likelihood of two (or more) events occurring at the same time. Mathematically, we denote this as P(A∩B), which is read as "the probability of A intersection B" or simply "the probability of A and B."
To understand joint probability, we first need to establish some context:
Joint probability differs significantly between independent and dependent events:
We can visualize joint probability using a Venn diagram, where the overlapping region represents the intersection of events—the scenarios where both events occur simultaneously:
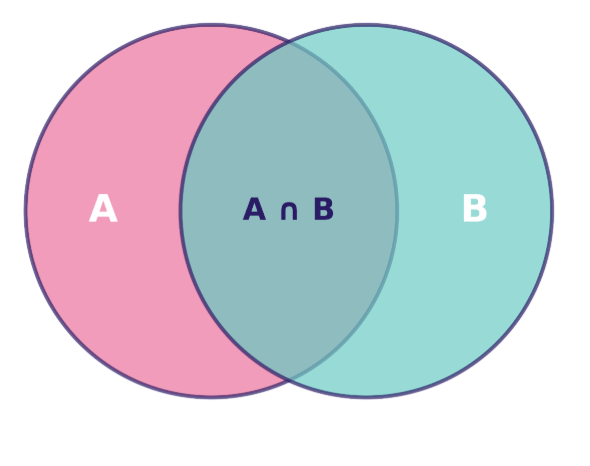
Venn diagram showing the relationship between sets A and B, with their intersection A ∩ B highlighted. Image by Author.
This overlapping region's area, relative to the total sample space, gives us P(A∩B)—the joint probability we're seeking to calculate.
Understanding how to calculate joint probability requires different approaches depending on whether events are independent or dependent. Let's examine both scenarios and explore the rules that govern these calculations.
When two events are independent, calculating their joint probability becomes straightforward. Since neither event influences the other, we can simply multiply their individual probabilities:
P(A∩B) = P(A) × P(B)
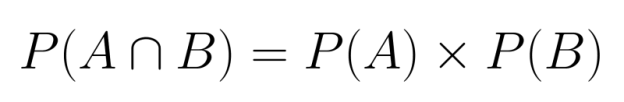
This multiplication rule applies because independence means that knowing one event occurred provides no information about the likelihood of the other event.
Example: Consider flipping two fair coins. The probability of getting heads on the first coin is 1/2, and the probability of getting heads on the second coin is also 1/2. Since these events are independent (the first flip doesn't affect the second), the probability of getting heads on both coins is:

This means there's a 25% chance of flipping two heads in succession.
When events are dependent, we must account for how the first event affects the probability of the second. This requires using conditional probability in our calculation:
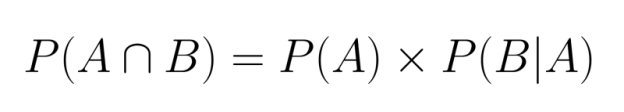
Here, P(B|A) represents the probability of event B occurring given that event A has already occurred.
Example: Imagine drawing two cards from a standard deck without replacement. What's the probability of drawing two aces?
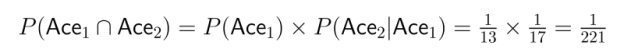
This illustrates how dependence significantly affects the joint probability calculation.
The calculations above demonstrate the multiplication rule of probability. This rule extends to more than two events, allowing us to calculate joint probabilities for multiple events using a chain of conditional probabilities:
![]()
This is known as the chain rule, which provides a systematic way to break down complex joint probabilities into manageable pieces.
Example: Consider the probability of drawing three hearts in succession from a standard deck without replacement:
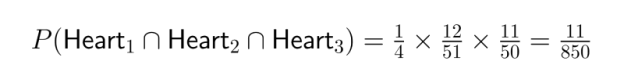
The chain rule becomes particularly valuable in data science when modeling sequences of events or working with multi-stage processes.
To solidify our understanding of joint probability, let's work through some classic examples and explore practical applications that demonstrate how these concepts operate in various contexts.
Imagine rolling two six-sided dice. What's the probability of rolling a 4 on the first die and a 6 on the second die?
Since the outcome of the first die doesn't affect the second die, these are independent events:
This tells us there's approximately a 2.78% chance of this specific combination occurring.
Let's calculate the probability of drawing a red card followed by an Ace from a standard 52-card deck without replacement.
Since we're drawing without replacement, these events are dependent:
To handle this properly, we need to consider both scenarios:
Therefore, the total joint probability is: P(Red card ∩ Ace on second draw) = 24/663 + 1/442 = (24×2 + 3)/1326 = 51/1326 = 1/26
The probability is approximately 3.85%.
Consider a bag containing 5 blue marbles and 3 green marbles. Let's calculate the probability of drawing two blue marbles under two different scenarios.
With replacement:
Without replacement:
This comparison highlights how the dependency created by not replacing the marbles reduces the joint probability.
Joint probability is vital in medical contexts when assessing multiple symptoms or test results. Consider a diagnostic scenario where physicians need to assess patients with symptoms A and B for a specific condition.
Based on historical data:
This joint probability helps physicians assess the likelihood of different conditions. It's worth noting that P(A ∩ B) is not equal to P(A) × P(B) = 0.30 × 0.25 = 0.075, which indicates these symptoms are not independent—knowing a patient has one symptom increases the likelihood they have the other.
Investment analysts often need to evaluate the joint probability of multiple market conditions occurring together. Consider an analyst assessing the risk of both a stock market decline and rising interest rates within the next quarter.
If their models suggest:
The joint probability calculation would be: P(Stock market decline ∩ Rising interest rates) = 0.60 × 0.45 = 0.27
This 27% probability helps quantify portfolio risk and guides hedging strategies to protect against this scenario.
These examples demonstrate how joint probability serves as a powerful tool for quantifying uncertainty in diverse fields, whether analyzing simple games of chance or making complex decisions in medicine and finance.
Joint and conditional probabilities are closely intertwined concepts that allow us to analyze complex scenarios involving multiple events. Understanding their relationship provides powerful tools for probabilistic reasoning.
The relationship between joint and conditional probability is expressed by the formula:
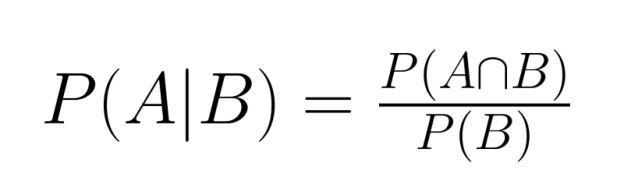
Rearranging this equation, we can express joint probability in terms of conditional probability:
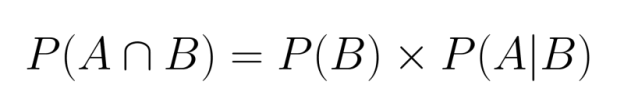
This relationship shows that we can calculate joint probability if we know the marginal probability of one event and the conditional probability of the other given the first.
Similarly, we could also write:
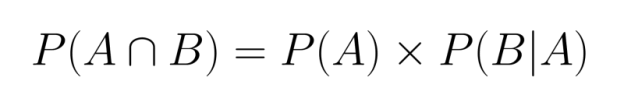
Both formulations are valid and equivalent, demonstrating the symmetrical nature of joint probability.
The relationship between joint and conditional probability is central to Bayes' Theorem, a fundamental tool in probabilistic inference:
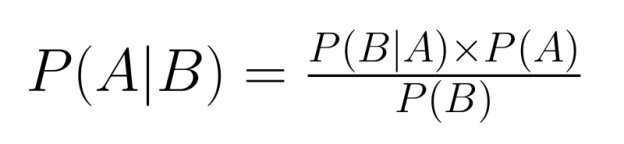
Bayes' Theorem allows us to "reverse" conditional probabilities—if we know P(B|A), we can calculate P(A|B). This proves invaluable when we have information about one conditional relationship but need to reason about the reverse relationship.
For example, medical tests often provide information about P(Positive Test|Disease), but doctors need to determine P(Disease|Positive Test). Bayes' Theorem bridges this gap by incorporating joint probability:
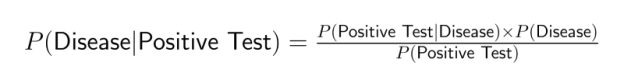
Joint probability forms the foundation for numerous data science techniques and applications. Understanding how multiple events interact helps data scientists build more accurate models and make better predictions in various domains.
Joint probability is fundamental to many classification algorithms, particularly Naive Bayes classifiers. These popular machine learning models calculate the probability of different outcomes based on the presence of multiple features.
The Naive Bayes approach applies Bayes' Theorem with a "naive" assumption that features are conditionally independent. This simplifies joint probability calculations:

Despite this simplifying assumption, Naive Bayes classifiers work remarkably well for:
This approach is computationally efficient and often performs surprisingly well even when the independence assumption doesn't strictly hold.
Joint probability plays a crucial role in fraud detection systems, where multiple risk factors must be evaluated together. Modern fraud detection algorithms analyze combinations of suspicious behaviors to identify potentially fraudulent transactions.
Consider an online payment system that monitors various signals:
While each signal alone might not indicate fraud, specific combinations (their joint occurrence) can significantly increase suspicion. For instance, a large transaction, from a new device, in a foreign country, at an unusual time represents a joint event with potentially high fraud probability.
This joint probability assessment enables more sophisticated risk scoring than evaluating each factor in isolation, reducing both false positives and false negatives.
Joint probability concepts are central to many advanced machine learning models, including:
Bayesian Networks: These graphical models represent variables and their probabilistic relationships. They enable reasoning about complex joint probability distributions by breaking them down into simpler conditional probabilities. Bayesian networks are widely used in:
Hidden Markov Models (HMMs): These sequential models use joint probabilities to model systems where the underlying state is hidden but produces observable outputs. Applications include:
Probabilistic Graphical Models: These encompass a broader class of models that use graph structures to encode complex joint probability distributions. They're essential tools for:
Through these applications, joint probability enables data scientists to build models that capture the complex interdependencies in real-world data, leading to more accurate predictions and better decision-making under uncertainty.
Despite its usefulness, joint probability is often misunderstood or misapplied. Let's examine some common misconceptions and how to avoid them.
One of the most frequent mistakes is confusing P(A∩B) with P(A|B). While they're related, they represent different concepts:
For example, the probability that a person both has diabetes and is over 65 (joint) is different from the probability that a person has diabetes given that they're over 65 (conditional).
This distinction matters in many analytical contexts. For instance, when a data scientist reports that "5% of users both clicked on an ad and made a purchase," this joint probability is very different from "40% of users who clicked on an ad made a purchase," which is a conditional probability.
Another common error is automatically assuming that P(A∩B) = P(A) × P(B) without verifying that events are truly independent. This assumption can lead to significant errors when events are actually dependent.
For example, in market analysis, assuming independence between purchasing product A and product B might lead to incorrect inventory planning if these products are complementary (like printers and ink) or substitutes (like different brands of the same item).
Testing for independence is crucial—if P(A∩B) ≠ P(A) × P(B), the events are dependent, and more careful joint probability calculations are required.
When working with joint probabilities, analysts sometimes focus exclusively on the intersection while ignoring the overall frequency of individual events. This can lead to misleading conclusions about the strength of relationships.
For instance, discovering that 90% of customers who bought products A and B also bought product C might seem impressive. However, if 89% of all customers buy product C regardless, the apparent relationship is much weaker than it initially appeared.
Always compare joint probabilities against relevant marginal probabilities to avoid overstating relationships between events. The lift ratio—the ratio of the joint probability to the product of marginal probabilities—offers a more accurate measure of association:
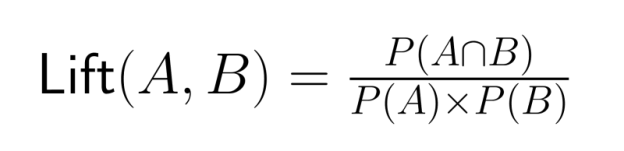
A lift value greater than 1 indicates events occur together more often than would be expected if they were independent.
Understanding these common pitfalls helps data scientists apply joint probability correctly and derive meaningful insights from probabilistic analysis.
As data scientists progress in their careers, they'll encounter more sophisticated applications of joint probability. Let's explore some advanced concepts that build upon the foundations we've established.
When dealing with modern machine learning problems, data scientists often work with dozens or even hundreds of variables simultaneously. In these high-dimensional spaces, calculating and representing joint probabilities becomes challenging.
The number of parameters needed to specify a joint distribution grows exponentially with the number of variables—a phenomenon known as the "curse of dimensionality." For example, a joint distribution of 10 binary variables requires 2¹⁰ - 1 = 1,023 parameters to specify completely.
To manage this complexity, data scientists employ techniques like:
These approaches make high-dimensional joint probability calculations tractable for practical applications in areas like computer vision, genomics, and natural language processing.
Our examples so far have mostly involved discrete events, but joint probability extends naturally to continuous variables through joint probability distributions.
For discrete variables, we work with joint probability mass functions (PMFs), which specify the probability that each combination of random variables takes on specific values:
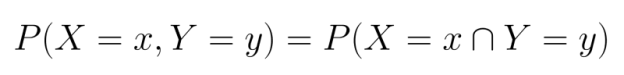
For continuous variables, we use joint probability density functions (PDFs). Unlike PMFs, PDFs don't directly give probabilities but must be integrated over regions to find the probability that the variables fall within those regions:
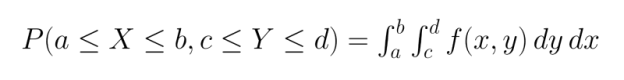
Common joint distributions include:
Understanding these distributions enables more sophisticated modeling of relationships between continuous variables in fields like economics, bioinformatics, and environmental science.
Several software tools and programming languages offer functions and libraries for working with joint probabilities:
Python:
NumPy and SciPy provide functions for multivariate probability distributions
Pandas offers powerful tools for empirical joint probability calculations
Libraries like PyMC3 and PyStan implement Bayesian modeling with joint distributions
R:
Base R includes many multivariate distribution functions
Packages like copula enable modeling complex dependence structures
bnlearn supports Bayesian network analysis
SQL:
GROUP BY clauses with COUNT functions can calculate empirical joint probabilities
Window functions enable more complex probabilistic analysis
Modern databases support statistical functions for probability calculations
These tools make it practical to apply joint probability concepts to large datasets, enabling data scientists to build sophisticated probabilistic models for complex problems.
To deepen your understanding of joint probability and its applications in Bayesian analysis, DataCamp offers several excellent courses:
These courses will help you build on the concepts covered in this article and apply joint probability techniques to solve real-world data science problems.
As we've seen throughout this article, joint probability is a fundamental statistical concept with wide-ranging applications across numerous data science fields. DataCamp's resources, like those shared in the 40+ Python Statistics for Data Science Resources, provide excellent pathways to strengthen your understanding. This comprehensive collection includes specific recommendations for learning probability theory, Bayesian thinking, and other statistical concepts that build upon joint probability.
For those preparing for data science roles, our Top 35 Statistics Interview Questions and Answers guide offers valuable practice with joint probability questions alongside other important statistical concepts. I also think that our Probability Puzzles in R course is a fun option.
Learn with DataCamp
Course
Course
Course
blog
Vinod Chugani
13 min
cheat-sheet
Richie Cotton
Tutorial
Vinod Chugani
Tutorial
Vinod Chugani
Tutorial
Vinod Chugani
Tutorial
DataCamp Team

