
programa
Llama Fundamentals
4 h
Se dice que Llama 4 Scout tiene una ventana de contexto masiva de 10 millones de tokens, pero su entrenamiento se limitó a un tamaño máximo de entrada de 256k tokens. Esto significa que el rendimiento puede degradarse con entradas mayores. Para evitarlo, podemos utilizar Llama 4 con una canalización de generación aumentada por recuperación (RAG).
En este tutorial, explicaré paso a paso cómo construir una canalización RAG utilizando el ecosistema LangChain y crear una aplicación web que permita a los usuarios subir documentos y hacer preguntas sobre ellos.
Mantenemos a nuestros lectores al día de lo último en IA enviándoles The Median, nuestro boletín gratuito de los viernes que desglosa las noticias clave de la semana. Suscríbete y mantente alerta en sólo unos minutos a la semana:
Llama 4 viene con una ventana contextual de 10 millones de tokens, lo que significa que podemos alimentarla con 100 libros y recibir respuestas contextuales sobre ellos. Sin embargo, a pesar de esta impresionante característica, hay razones de peso para emparejar Llama 4 con RAG. He aquí por qué:
Aunque Llama 4 admite una ventana de contexto masiva, su entrenamiento se limitó a un tamaño máximo de entrada de 256k tokens. El rendimiento del modelo puede degradarse cuando las entradas se acercan o superan este umbral. RAG mitiga este problema recuperando sólo la información más relevante, asegurándose de que la entrada sigue siendo concisa y centrada.
La RAG permite recuperar información muy relevante de una base de datos vectorialpermitiendo a Llama 4 procesar entradas más pequeñas y específicas. Este enfoque mejora tanto la eficacia como la precisión.
Procesar entradas masivas con la ventana de contexto completa de Llama 4 puede ser costoso computacionalmente. Al utilizar la GAR, sólo se recuperan y procesan los datos más relevantes, lo que reduce significativamente la carga computacional y los costes asociados.
En este tutorial, te explicaré paso a paso cómo construir una sencilla canalización de generación aumentada por recuperación que te permita cargar un archivo .docx y hacer preguntas sobre su contenido.
En primer lugar, tenemos que crear un GroqCloud y guardarla como variable de entorno. A continuación, instalaremos todos los paquetes de Python necesarios para cargar, dividir, vectorizar y recuperar el contexto, así como para generar respuestas.
%%capture
%pip install langchain
%pip install langchain-community
%pip install langchainhub
%pip install langchain-chroma
%pip install langchain-groq
%pip install langchain-huggingface
%pip install unstructured[docx]Configuraremos el objeto modelo utilizando la API de Groq, proporcionándole el nombre del modelo y la clave de la API. Del mismo modo, descargaremos el modelo de incrustación de Cara Abrazada y lo cargaremos como nuestro modelo de incrustación.
from langchain_groq import ChatGroq
from langchain_huggingface import HuggingFaceEmbeddings
llm = ChatGroq(model="meta-llama/llama-4-scout-17b-16e-instruct", api_key=groq_api_key)
embed_model = HuggingFaceEmbeddings(model_name="mixedbread-ai/mxbai-embed-large-v1")Cargaremos el archivo .docx desde la carpeta raíz y lo dividiremos en trozos de 1000 caracteres.
from langchain_community.document_loaders import DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Initialize the text splitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=100,
separators=["\n\n", "\n"]
)
# Load the .docx files
loader = DirectoryLoader("./", glob="*.docx", use_multithreading=True)
documents = loader.load()
# Split the documents into chunks
chunks = text_splitter.split_documents(documents)
# Print the number of chunks
print(len(chunks))29Inicializar el almacén vectorial Chroma y proporciona los trozos de texto a la base de datos vectorial. El texto se convertirá en incrustaciones antes de ser almacenado. Después, realizaremos una búsqueda de similitudes para comprobar si nuestro almacén de vectores está correctamente poblado.
from langchain_chroma import Chroma
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=embed_model,
persist_directory="./Vectordb",
)
query = "What is this tutorial about?"
docs = vectorstore.similarity_search(query)
print(docs[0].page_content)Learn how to Fine-tune Stable Diffusion XL with DreamBooth and LoRA on your personal images.
Let's try another prompt:
Prompt:A continuación, convertiremos nuestro almacén vectorial en un recuperador y crearemos una plantilla de avisos para el conducto RAG.
# Create retriever
retriever = vectorstore.as_retriever()
# Import PromptTemplate
from langchain_core.prompts import PromptTemplate
# Define a clearer, more professional prompt template
template = """You are an expert assistant tasked with answering questions based on the provided documents.
Use only the given context to generate your answer.
If the answer cannot be found in the context, clearly state that you do not know.
Be detailed and precise in your response, but avoid mentioning or referencing the context itself.
Context:
{context}
Question:
{question}
Answer:"""
# Create the PromptTemplate
rag_prompt = PromptTemplate.from_template(template)Por último, crearemos la cadena RAG que proporciona tanto el contexto como la pregunta en la indicación RAG, la pasaremos por el modelo Llama 4 y, a continuación, generaremos una respuesta limpia.
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| rag_prompt
| llm
| StrOutputParser()
)Ahora preguntaremos a la cadena RAG sobre el documento.
from IPython.display import display, Markdown
response = rag_chain.invoke("What this tutorial about?")
Markdown(response)This tutorial is about setting up and using the Janus project, specifically Janus Pro, a multimodal model that can understand images and generate images from text prompts, and building a local solution to use the model privately on a laptop GPU. It covers learning about the Janus Series, setting up the Janus project, building a Docker container to run the model locally, and testing its capabilities with various image and text prompts.Como puedes ver, la respuesta es muy precisa y consciente del contexto. Si tienes algún problema al ejecutar el código anterior, consulta este libro de trabajo de DataLab: Llama 4 RAG pipeline.
En esta sección, transformaremos el código de la tubería RAG anteriormente comentado en una aplicación de chat funcional utilizando el paquete Gradio. Para empezar, necesitas instalar Gradio utilizando el siguiente comando pip:
$ pip install gradioLa aplicación está diseñada para ser sencilla y fácil de usar, y permite a los usuarios cargar un único archivo .docx, varios archivos .docx o un archivo .zip que contenga archivos .docx. A continuación, los usuarios pueden hacer preguntas sobre el contenido de todos los archivos cargados, proporcionando una forma rápida y eficaz de recuperar información.
La aplicación incluye:
Pongámoslo todo junto:
main.py:
# ========== Standard Library ==========
import os
import tempfile
import zipfile
from typing import List, Optional, Tuple, Union
import collections
# ========== Third-Party Libraries ==========
import gradio as gr
from groq import Groq
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import DirectoryLoader, UnstructuredFileLoader
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_groq import ChatGroq
from langchain_huggingface import HuggingFaceEmbeddings
# ========== Configs ==========
TITLE = """<h1 align="center">🗨️🦙 Llama 4 Docx Chatter</h1>"""
AVATAR_IMAGES = (
None,
"./logo.png",
)
# Acceptable file extensions
TEXT_EXTENSIONS = [".docx", ".zip"]
# ========== Models & Clients ==========
GROQ_API_KEY = os.getenv("GROQ_API_KEY")
client = Groq(api_key=GROQ_API_KEY)
llm = ChatGroq(model="meta-llama/llama-4-scout-17b-16e-instruct", api_key=GROQ_API_KEY)
embed_model = HuggingFaceEmbeddings(model_name="mixedbread-ai/mxbai-embed-large-v1")
# ========== Core Components ==========
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=100,
separators=["\n\n", "\n"],
)
rag_template = """You are an expert assistant tasked with answering questions based on the provided documents.
Use only the given context to generate your answer.
If the answer cannot be found in the context, clearly state that you do not know.
Be detailed and precise in your response, but avoid mentioning or referencing the context itself.
Context:
{context}
Question:
{question}
Answer:"""
rag_prompt = PromptTemplate.from_template(rag_template)
# ========== App State ==========
class AppState:
vectorstore: Optional[InMemoryVectorStore] = None
rag_chain = None
state = AppState()
# ========== Utility Functions ==========
def load_documents_from_files(files: List[str]) -> List:
"""Load documents from uploaded files directly without moving."""
all_documents = []
# Temporary directory if ZIP needs extraction
with tempfile.TemporaryDirectory() as temp_dir:
for file_path in files:
ext = os.path.splitext(file_path)[1].lower()
if ext == ".zip":
# Extract ZIP inside temp_dir
with zipfile.ZipFile(file_path, "r") as zip_ref:
zip_ref.extractall(temp_dir)
# Load all docx from extracted zip
loader = DirectoryLoader(
path=temp_dir,
glob="**/*.docx",
use_multithreading=True,
)
docs = loader.load()
all_documents.extend(docs)
elif ext == ".docx":
# Load single docx directly
loader = UnstructuredFileLoader(file_path)
docs = loader.load()
all_documents.extend(docs)
return all_documents
def get_last_user_message(chatbot: List[Union[gr.ChatMessage, dict]]) -> Optional[str]:
"""Get last user prompt."""
for message in reversed(chatbot):
content = (
message.get("content") if isinstance(message, dict) else message.content
)
if (
message.get("role") if isinstance(message, dict) else message.role
) == "user":
return content
return None
# ========== Main Logic ==========
def upload_files(
files: Optional[List[str]], chatbot: List[Union[gr.ChatMessage, dict]]
):
"""Handle file upload - .docx or .zip containing docx."""
if not files:
return chatbot
file_summaries = [] # <-- Collect formatted file/folder info
documents = []
with tempfile.TemporaryDirectory() as temp_dir:
for file_path in files:
filename = os.path.basename(file_path)
ext = os.path.splitext(file_path)[1].lower()
if ext == ".zip":
file_summaries.append(f"📦 **{filename}** (ZIP file) contains:")
try:
with zipfile.ZipFile(file_path, "r") as zip_ref:
zip_ref.extractall(temp_dir)
zip_contents = zip_ref.namelist()
# Group files by folder
folder_map = collections.defaultdict(list)
for item in zip_contents:
if item.endswith("/"):
continue # skip folder entries themselves
folder = os.path.dirname(item)
file_name = os.path.basename(item)
folder_map[folder].append(file_name)
# Format nicely
for folder, files_in_folder in folder_map.items():
if folder:
file_summaries.append(f"📂 {folder}/")
else:
file_summaries.append(f"📄 (root)")
for f in files_in_folder:
file_summaries.append(f" - {f}")
# Load docx files extracted from ZIP
loader = DirectoryLoader(
path=temp_dir,
glob="**/*.docx",
use_multithreading=True,
)
docs = loader.load()
documents.extend(docs)
except zipfile.BadZipFile:
chatbot.append(
gr.ChatMessage(
role="assistant",
content=f"❌ Failed to open ZIP file: {filename}",
)
)
elif ext == ".docx":
file_summaries.append(f"📄 **{filename}**")
loader = UnstructuredFileLoader(file_path)
docs = loader.load()
documents.extend(docs)
else:
file_summaries.append(f"❌ Unsupported file type: {filename}")
if not documents:
chatbot.append(
gr.ChatMessage(
role="assistant", content="No valid .docx files found in upload."
)
)
return chatbot
# Split documents
chunks = text_splitter.split_documents(documents)
if not chunks:
chatbot.append(
gr.ChatMessage(
role="assistant", content="Failed to split documents into chunks."
)
)
return chatbot
# Create Vectorstore
state.vectorstore = InMemoryVectorStore.from_documents(
documents=chunks,
embedding=embed_model,
)
retriever = state.vectorstore.as_retriever()
# Build RAG Chain
state.rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| rag_prompt
| llm
| StrOutputParser()
)
# Final display
chatbot.append(
gr.ChatMessage(
role="assistant",
content="**Uploaded Files:**\n"
+ "\n".join(file_summaries)
+ "\n\n✅ Ready to chat!",
)
)
return chatbot
def user_message(
text_prompt: str, chatbot: List[Union[gr.ChatMessage, dict]]
) -> Tuple[str, List[Union[gr.ChatMessage, dict]]]:
"""Add user's text input to conversation."""
if text_prompt.strip():
chatbot.append(gr.ChatMessage(role="user", content=text_prompt))
return "", chatbot
def process_query(
chatbot: List[Union[gr.ChatMessage, dict]],
) -> List[Union[gr.ChatMessage, dict]]:
"""Process user's query through RAG pipeline."""
prompt = get_last_user_message(chatbot)
if not prompt:
chatbot.append(
gr.ChatMessage(role="assistant", content="Please type a question first.")
)
return chatbot
if state.rag_chain is None:
chatbot.append(
gr.ChatMessage(role="assistant", content="Please upload documents first.")
)
return chatbot
chatbot.append(gr.ChatMessage(role="assistant", content="Thinking..."))
try:
response = state.rag_chain.invoke(prompt)
chatbot[-1].content = response
except Exception as e:
chatbot[-1].content = f"Error: {str(e)}"
return chatbot
def reset_app(
chatbot: List[Union[gr.ChatMessage, dict]],
) -> List[Union[gr.ChatMessage, dict]]:
"""Reset application state."""
state.vectorstore = None
state.rag_chain = None
return [
gr.ChatMessage(
role="assistant", content="App reset! Upload new documents to start."
)
]
# ========== UI Layout ==========
with gr.Blocks(theme=gr.themes.Soft()) as demo:
gr.HTML(TITLE)
chatbot = gr.Chatbot(
label="Llama 4 RAG",
type="messages",
bubble_full_width=False,
avatar_images=AVATAR_IMAGES,
scale=2,
height=350,
)
with gr.Row(equal_height=True):
text_prompt = gr.Textbox(
placeholder="Ask a question...", show_label=False, autofocus=True, scale=28
)
send_button = gr.Button(
value="Send",
variant="primary",
scale=1,
min_width=80,
)
upload_button = gr.UploadButton(
label="Upload",
file_count="multiple",
file_types=TEXT_EXTENSIONS,
scale=1,
min_width=80,
)
reset_button = gr.Button(
value="Reset",
variant="stop",
scale=1,
min_width=80,
)
send_button.click(
fn=user_message,
inputs=[text_prompt, chatbot],
outputs=[text_prompt, chatbot],
queue=False,
).then(fn=process_query, inputs=[chatbot], outputs=[chatbot])
text_prompt.submit(
fn=user_message,
inputs=[text_prompt, chatbot],
outputs=[text_prompt, chatbot],
queue=False,
).then(fn=process_query, inputs=[chatbot], outputs=[chatbot])
upload_button.upload(
fn=upload_files, inputs=[upload_button, chatbot], outputs=[chatbot], queue=False
)
reset_button.click(fn=reset_app, inputs=[chatbot], outputs=[chatbot], queue=False)
demo.queue().launch()Ahora, ejecutaremos la aplicación web y probaremos sus funcionalidades. Para iniciar la aplicación, ejecuta el siguiente comando en el terminal:
$ python main.py Una vez que el servidor web esté en funcionamiento, navega hasta la siguiente URL o cópiala y pégala manualmente en tu navegador para acceder a la interfaz web: http://127.0.0.1:7860
Este es el aspecto de nuestra interfaz de chat:
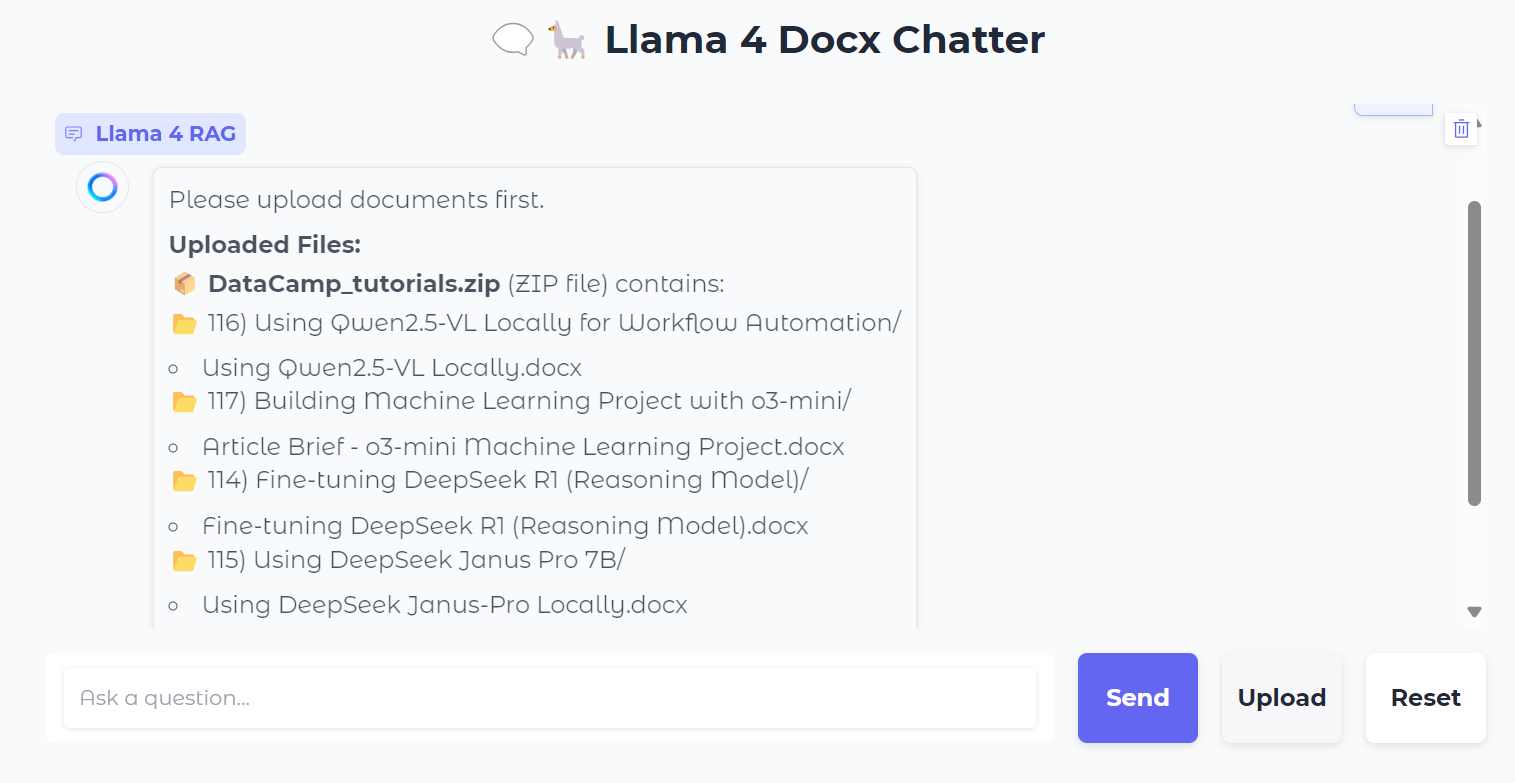
Subiremos un archivo .zip que contiene archivos .docx, y al hacerlo, verás todas las carpetas y archivos dentro del archivo zip.
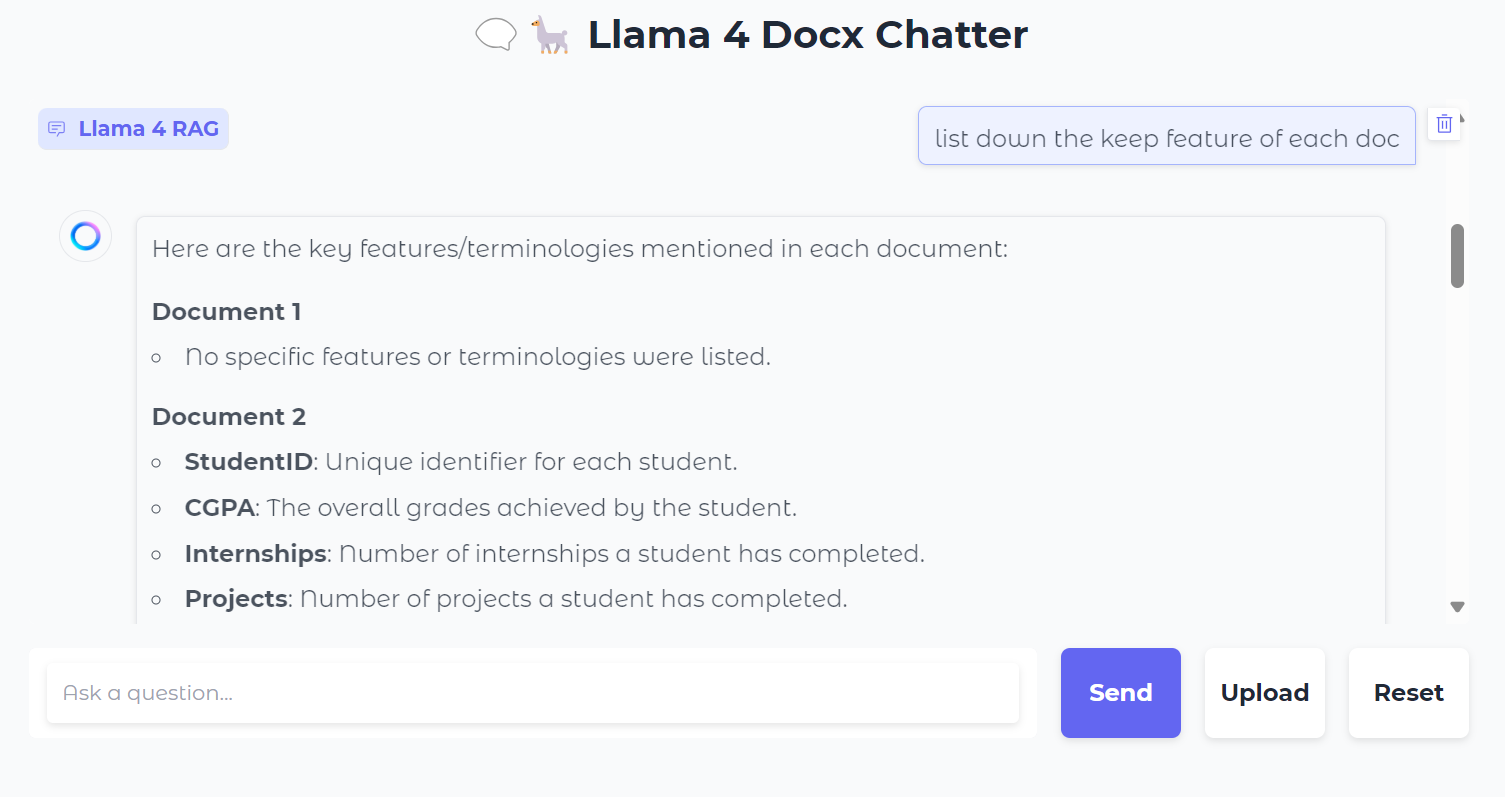
A continuación, podemos hacer preguntas concretas sobre los documentos:
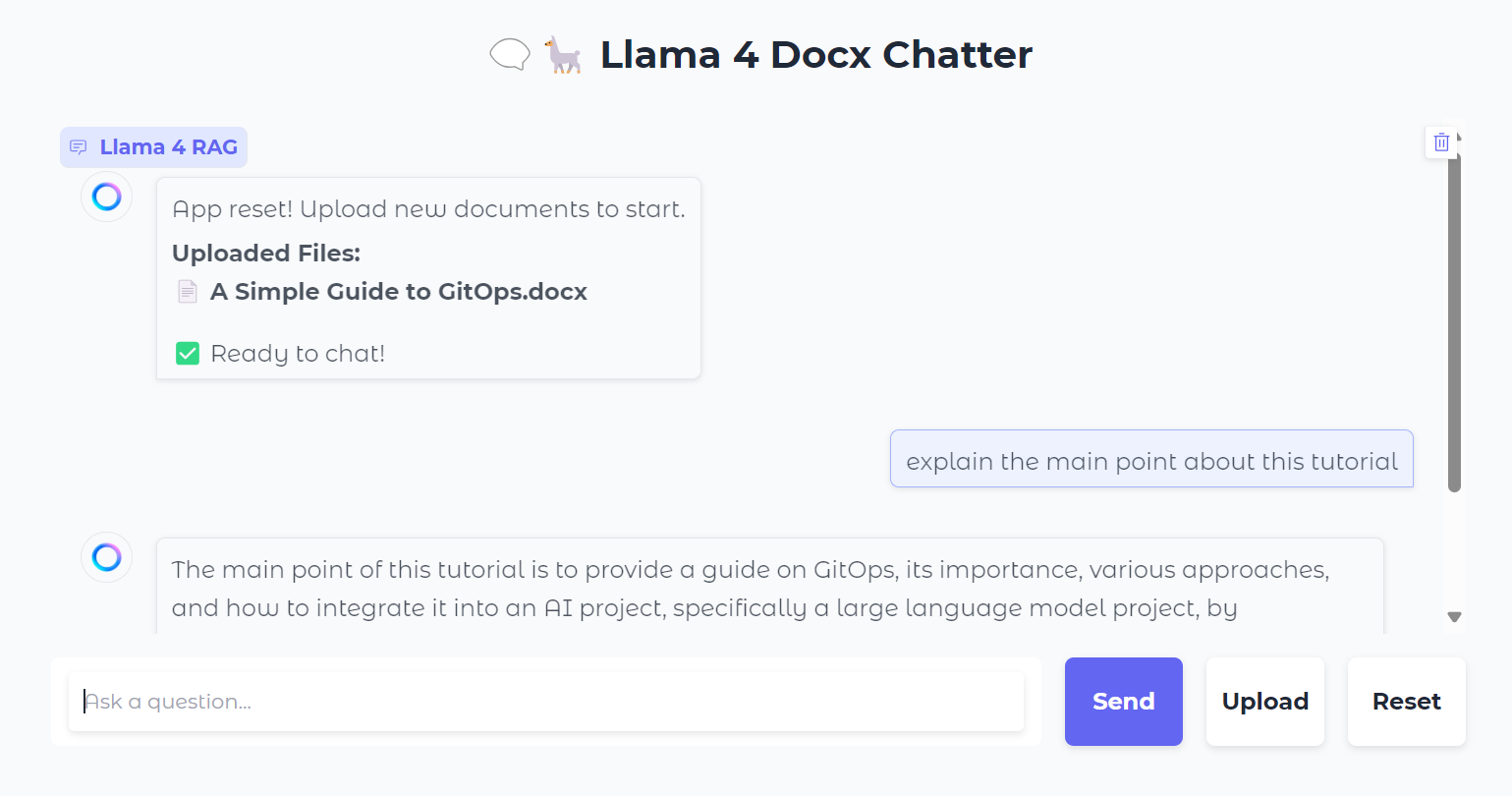
También puedes pulsar el botón "Reiniciar" para subir un nuevo archivo y chatear sobre él en sólo unos segundos.
Después de probarla localmente, puedes desplegar fácilmente la aplicación web en Hugging Face Space de forma gratuita. Aquí tienes el enlace a la aplicación desplegada: kingabzpro/Llama-4-RAG
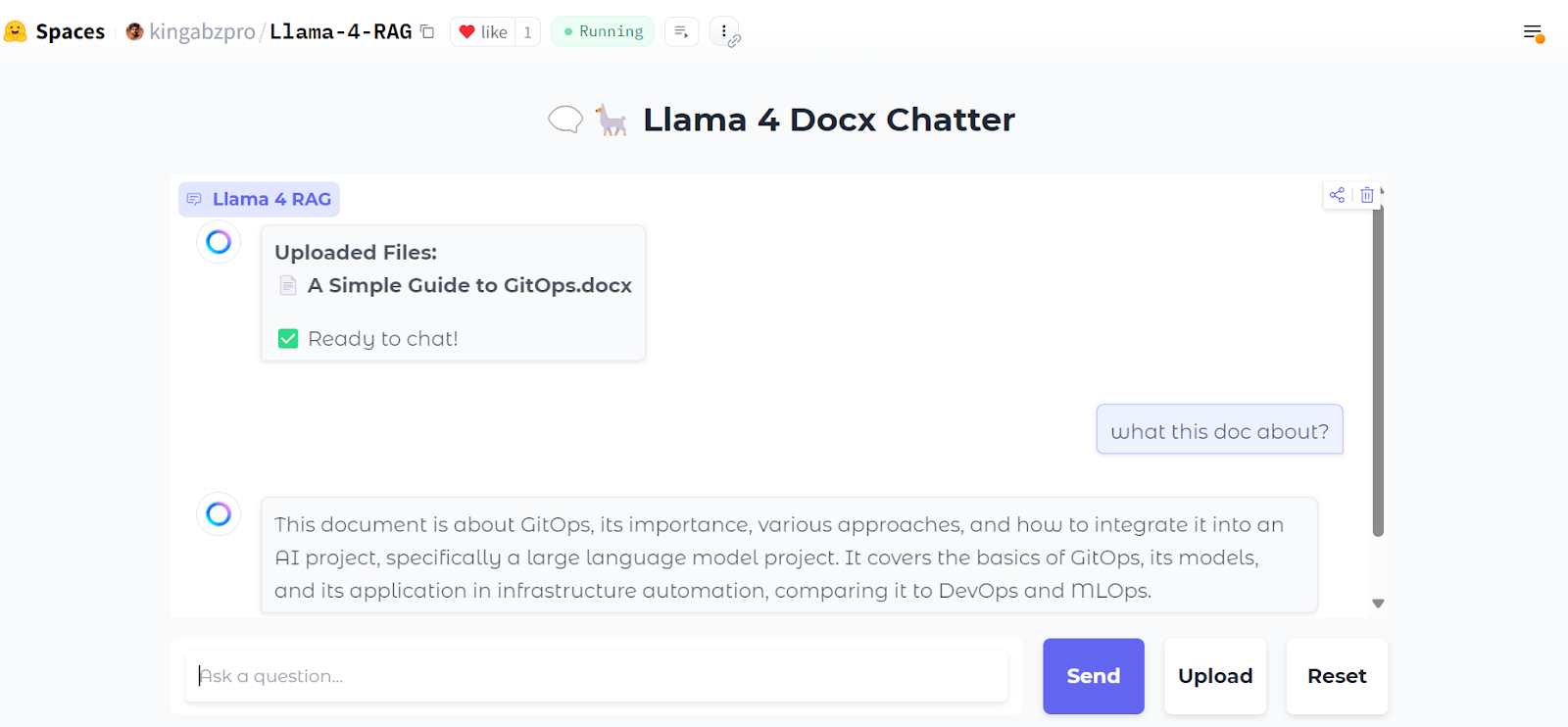
Fuente: kingabzpro/Llama-4-RAG
El código fuente, el bloc de notas y los archivos de configuración se encuentran en la carpeta kingabzpro/Llama-4-RAG repositorio.
Incluso con la introducción de modelos de ventana de contexto largo, la GAR nunca quedará obsoleta. La GAR sigue siendo un método eficaz y rentable para recuperar información de recursos externos, proporcionando un contexto adicional a los modelos.
Además, el funcionamiento de los sistemas RAG es intrínsecamente más económico que el de alimentar directamente un modelo con un contexto amplio, lo que requiere importantes recursos informáticos. Esto hace que la GAR sea una solución práctica y escalable para muchos casos de uso.
Para saber más sobre Llama 4, consulta estos recursos:
Aprende IA con estos cursos
programa
Curso
Curso
Tutorial
Ryan Ong
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Ryan Ong


