
Track
Llama Fundamentals
4 hr
Llama 4 Scout is marketed as having a massive context window of 10 million tokens, but its training was limited to a maximum input size of 256k tokens. This means performance can degrade with larger inputs. To prevent this, we can use Llama 4 with a retrieval-augmented generation (RAG) pipeline.
In this tutorial, I’ll explain step-by-step how to build a RAG pipeline using the LangChain ecosystem and create a web application that allows users to upload documents and ask questions about them.
We keep our readers updated on the latest in AI by sending out The Median, our free Friday newsletter that breaks down the week’s key stories. Subscribe and stay sharp in just a few minutes a week:
Llama 4 comes with a 10 million token context window, meaning we can feed it 100 books and receive contextual answers about them. However, despite this impressive feature, there are compelling reasons to pair Llama 4 with RAG. Here is why:
While Llama 4 supports a massive context window, its training was limited to a maximum input size of 256k tokens. The model's performance can degrade when inputs approach or exceed this threshold. RAG mitigates this issue by retrieving only the most relevant information, ensuring the input remains concise and focused.
RAG enables the retrieval of highly relevant information from a vector database, allowing Llama 4 to process smaller, more targeted inputs. This approach improves both efficiency and accuracy.
Processing massive inputs with Llama 4's full context window can be computationally expensive. By using RAG, only the most relevant data is retrieved and processed, significantly reducing the computational load and associated costs.
In this tutorial, I will explain step-by-step how to build a simple retrieval-augmented generation pipeline that allows you to load a .docx file and ask questions about its content.
First, we need to create a GroqCloud API key and save it as an environment variable. Next, we will install all the necessary Python packages required to load, split, vectorize, and retrieve the context, as well as generate responses.
%%capture
%pip install langchain
%pip install langchain-community
%pip install langchainhub
%pip install langchain-chroma
%pip install langchain-groq
%pip install langchain-huggingface
%pip install unstructured[docx]We will set up the model object using the Groq API, providing it with the model name and API key. Similarly, we will download the embedding model from Hugging Face and load it as our embedding model.
from langchain_groq import ChatGroq
from langchain_huggingface import HuggingFaceEmbeddings
llm = ChatGroq(model="meta-llama/llama-4-scout-17b-16e-instruct", api_key=groq_api_key)
embed_model = HuggingFaceEmbeddings(model_name="mixedbread-ai/mxbai-embed-large-v1")We will load the .docx file from the root folder and split it into chunks of 1000 characters.
from langchain_community.document_loaders import DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Initialize the text splitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=100,
separators=["\n\n", "\n"]
)
# Load the .docx files
loader = DirectoryLoader("./", glob="*.docx", use_multithreading=True)
documents = loader.load()
# Split the documents into chunks
chunks = text_splitter.split_documents(documents)
# Print the number of chunks
print(len(chunks))29Initialize the Chroma vector store and provide the text chunks to the vector database. The text will be converted to embeddings before being stored. After that, we will run a similarity search to test if our vector store is properly populated.
from langchain_chroma import Chroma
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=embed_model,
persist_directory="./Vectordb",
)
query = "What is this tutorial about?"
docs = vectorstore.similarity_search(query)
print(docs[0].page_content)Learn how to Fine-tune Stable Diffusion XL with DreamBooth and LoRA on your personal images.
Let's try another prompt:
Prompt:Next, we will convert our vector store into a retriever and create a prompt template for the RAG pipeline.
# Create retriever
retriever = vectorstore.as_retriever()
# Import PromptTemplate
from langchain_core.prompts import PromptTemplate
# Define a clearer, more professional prompt template
template = """You are an expert assistant tasked with answering questions based on the provided documents.
Use only the given context to generate your answer.
If the answer cannot be found in the context, clearly state that you do not know.
Be detailed and precise in your response, but avoid mentioning or referencing the context itself.
Context:
{context}
Question:
{question}
Answer:"""
# Create the PromptTemplate
rag_prompt = PromptTemplate.from_template(template)Finally, we will create the RAG chain that provides both the context and the question in the RAG prompt, pass it through the Llama 4 model, and then generate a clean response.
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| rag_prompt
| llm
| StrOutputParser()
)We will now ask the RAG chain about the document.
from IPython.display import display, Markdown
response = rag_chain.invoke("What this tutorial about?")
Markdown(response)This tutorial is about setting up and using the Janus project, specifically Janus Pro, a multimodal model that can understand images and generate images from text prompts, and building a local solution to use the model privately on a laptop GPU. It covers learning about the Janus Series, setting up the Janus project, building a Docker container to run the model locally, and testing its capabilities with various image and text prompts.As you can see, the response is highly accurate and context-aware. If you encounter any issues running the above code, please refer to this DataLab workbook: Llama 4 RAG pipeline.
In this section, we will transform the previously discussed RAG pipeline code into a functional chat application using the Gradio package. To get started, you need to install Gradio using the following pip command:
$ pip install gradioThe application is designed to be simple and user-friendly, allowing users to upload a single .docx file, multiple .docx files, or a .zip archive containing .docx files. Users can then ask questions about the content of all uploaded files, providing a fast and efficient way to retrieve information.
The application features:
Let’s put it all together:
main.py:
# ========== Standard Library ==========
import os
import tempfile
import zipfile
from typing import List, Optional, Tuple, Union
import collections
# ========== Third-Party Libraries ==========
import gradio as gr
from groq import Groq
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import DirectoryLoader, UnstructuredFileLoader
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_groq import ChatGroq
from langchain_huggingface import HuggingFaceEmbeddings
# ========== Configs ==========
TITLE = """<h1 align="center">🗨️🦙 Llama 4 Docx Chatter</h1>"""
AVATAR_IMAGES = (
None,
"./logo.png",
)
# Acceptable file extensions
TEXT_EXTENSIONS = [".docx", ".zip"]
# ========== Models & Clients ==========
GROQ_API_KEY = os.getenv("GROQ_API_KEY")
client = Groq(api_key=GROQ_API_KEY)
llm = ChatGroq(model="meta-llama/llama-4-scout-17b-16e-instruct", api_key=GROQ_API_KEY)
embed_model = HuggingFaceEmbeddings(model_name="mixedbread-ai/mxbai-embed-large-v1")
# ========== Core Components ==========
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=100,
separators=["\n\n", "\n"],
)
rag_template = """You are an expert assistant tasked with answering questions based on the provided documents.
Use only the given context to generate your answer.
If the answer cannot be found in the context, clearly state that you do not know.
Be detailed and precise in your response, but avoid mentioning or referencing the context itself.
Context:
{context}
Question:
{question}
Answer:"""
rag_prompt = PromptTemplate.from_template(rag_template)
# ========== App State ==========
class AppState:
vectorstore: Optional[InMemoryVectorStore] = None
rag_chain = None
state = AppState()
# ========== Utility Functions ==========
def load_documents_from_files(files: List[str]) -> List:
"""Load documents from uploaded files directly without moving."""
all_documents = []
# Temporary directory if ZIP needs extraction
with tempfile.TemporaryDirectory() as temp_dir:
for file_path in files:
ext = os.path.splitext(file_path)[1].lower()
if ext == ".zip":
# Extract ZIP inside temp_dir
with zipfile.ZipFile(file_path, "r") as zip_ref:
zip_ref.extractall(temp_dir)
# Load all docx from extracted zip
loader = DirectoryLoader(
path=temp_dir,
glob="**/*.docx",
use_multithreading=True,
)
docs = loader.load()
all_documents.extend(docs)
elif ext == ".docx":
# Load single docx directly
loader = UnstructuredFileLoader(file_path)
docs = loader.load()
all_documents.extend(docs)
return all_documents
def get_last_user_message(chatbot: List[Union[gr.ChatMessage, dict]]) -> Optional[str]:
"""Get last user prompt."""
for message in reversed(chatbot):
content = (
message.get("content") if isinstance(message, dict) else message.content
)
if (
message.get("role") if isinstance(message, dict) else message.role
) == "user":
return content
return None
# ========== Main Logic ==========
def upload_files(
files: Optional[List[str]], chatbot: List[Union[gr.ChatMessage, dict]]
):
"""Handle file upload - .docx or .zip containing docx."""
if not files:
return chatbot
file_summaries = [] # <-- Collect formatted file/folder info
documents = []
with tempfile.TemporaryDirectory() as temp_dir:
for file_path in files:
filename = os.path.basename(file_path)
ext = os.path.splitext(file_path)[1].lower()
if ext == ".zip":
file_summaries.append(f"📦 **{filename}** (ZIP file) contains:")
try:
with zipfile.ZipFile(file_path, "r") as zip_ref:
zip_ref.extractall(temp_dir)
zip_contents = zip_ref.namelist()
# Group files by folder
folder_map = collections.defaultdict(list)
for item in zip_contents:
if item.endswith("/"):
continue # skip folder entries themselves
folder = os.path.dirname(item)
file_name = os.path.basename(item)
folder_map[folder].append(file_name)
# Format nicely
for folder, files_in_folder in folder_map.items():
if folder:
file_summaries.append(f"📂 {folder}/")
else:
file_summaries.append(f"📄 (root)")
for f in files_in_folder:
file_summaries.append(f" - {f}")
# Load docx files extracted from ZIP
loader = DirectoryLoader(
path=temp_dir,
glob="**/*.docx",
use_multithreading=True,
)
docs = loader.load()
documents.extend(docs)
except zipfile.BadZipFile:
chatbot.append(
gr.ChatMessage(
role="assistant",
content=f"❌ Failed to open ZIP file: {filename}",
)
)
elif ext == ".docx":
file_summaries.append(f"📄 **{filename}**")
loader = UnstructuredFileLoader(file_path)
docs = loader.load()
documents.extend(docs)
else:
file_summaries.append(f"❌ Unsupported file type: {filename}")
if not documents:
chatbot.append(
gr.ChatMessage(
role="assistant", content="No valid .docx files found in upload."
)
)
return chatbot
# Split documents
chunks = text_splitter.split_documents(documents)
if not chunks:
chatbot.append(
gr.ChatMessage(
role="assistant", content="Failed to split documents into chunks."
)
)
return chatbot
# Create Vectorstore
state.vectorstore = InMemoryVectorStore.from_documents(
documents=chunks,
embedding=embed_model,
)
retriever = state.vectorstore.as_retriever()
# Build RAG Chain
state.rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| rag_prompt
| llm
| StrOutputParser()
)
# Final display
chatbot.append(
gr.ChatMessage(
role="assistant",
content="**Uploaded Files:**\n"
+ "\n".join(file_summaries)
+ "\n\n✅ Ready to chat!",
)
)
return chatbot
def user_message(
text_prompt: str, chatbot: List[Union[gr.ChatMessage, dict]]
) -> Tuple[str, List[Union[gr.ChatMessage, dict]]]:
"""Add user's text input to conversation."""
if text_prompt.strip():
chatbot.append(gr.ChatMessage(role="user", content=text_prompt))
return "", chatbot
def process_query(
chatbot: List[Union[gr.ChatMessage, dict]],
) -> List[Union[gr.ChatMessage, dict]]:
"""Process user's query through RAG pipeline."""
prompt = get_last_user_message(chatbot)
if not prompt:
chatbot.append(
gr.ChatMessage(role="assistant", content="Please type a question first.")
)
return chatbot
if state.rag_chain is None:
chatbot.append(
gr.ChatMessage(role="assistant", content="Please upload documents first.")
)
return chatbot
chatbot.append(gr.ChatMessage(role="assistant", content="Thinking..."))
try:
response = state.rag_chain.invoke(prompt)
chatbot[-1].content = response
except Exception as e:
chatbot[-1].content = f"Error: {str(e)}"
return chatbot
def reset_app(
chatbot: List[Union[gr.ChatMessage, dict]],
) -> List[Union[gr.ChatMessage, dict]]:
"""Reset application state."""
state.vectorstore = None
state.rag_chain = None
return [
gr.ChatMessage(
role="assistant", content="App reset! Upload new documents to start."
)
]
# ========== UI Layout ==========
with gr.Blocks(theme=gr.themes.Soft()) as demo:
gr.HTML(TITLE)
chatbot = gr.Chatbot(
label="Llama 4 RAG",
type="messages",
bubble_full_width=False,
avatar_images=AVATAR_IMAGES,
scale=2,
height=350,
)
with gr.Row(equal_height=True):
text_prompt = gr.Textbox(
placeholder="Ask a question...", show_label=False, autofocus=True, scale=28
)
send_button = gr.Button(
value="Send",
variant="primary",
scale=1,
min_width=80,
)
upload_button = gr.UploadButton(
label="Upload",
file_count="multiple",
file_types=TEXT_EXTENSIONS,
scale=1,
min_width=80,
)
reset_button = gr.Button(
value="Reset",
variant="stop",
scale=1,
min_width=80,
)
send_button.click(
fn=user_message,
inputs=[text_prompt, chatbot],
outputs=[text_prompt, chatbot],
queue=False,
).then(fn=process_query, inputs=[chatbot], outputs=[chatbot])
text_prompt.submit(
fn=user_message,
inputs=[text_prompt, chatbot],
outputs=[text_prompt, chatbot],
queue=False,
).then(fn=process_query, inputs=[chatbot], outputs=[chatbot])
upload_button.upload(
fn=upload_files, inputs=[upload_button, chatbot], outputs=[chatbot], queue=False
)
reset_button.click(fn=reset_app, inputs=[chatbot], outputs=[chatbot], queue=False)
demo.queue().launch()Now, we will run the web application and test its functionalities. To start the application, run the following command in the terminal:
$ python main.py Once the web server is up and running, navigate to the following URL or copy and paste it manually into your browser to access the web interface: http://127.0.0.1:7860
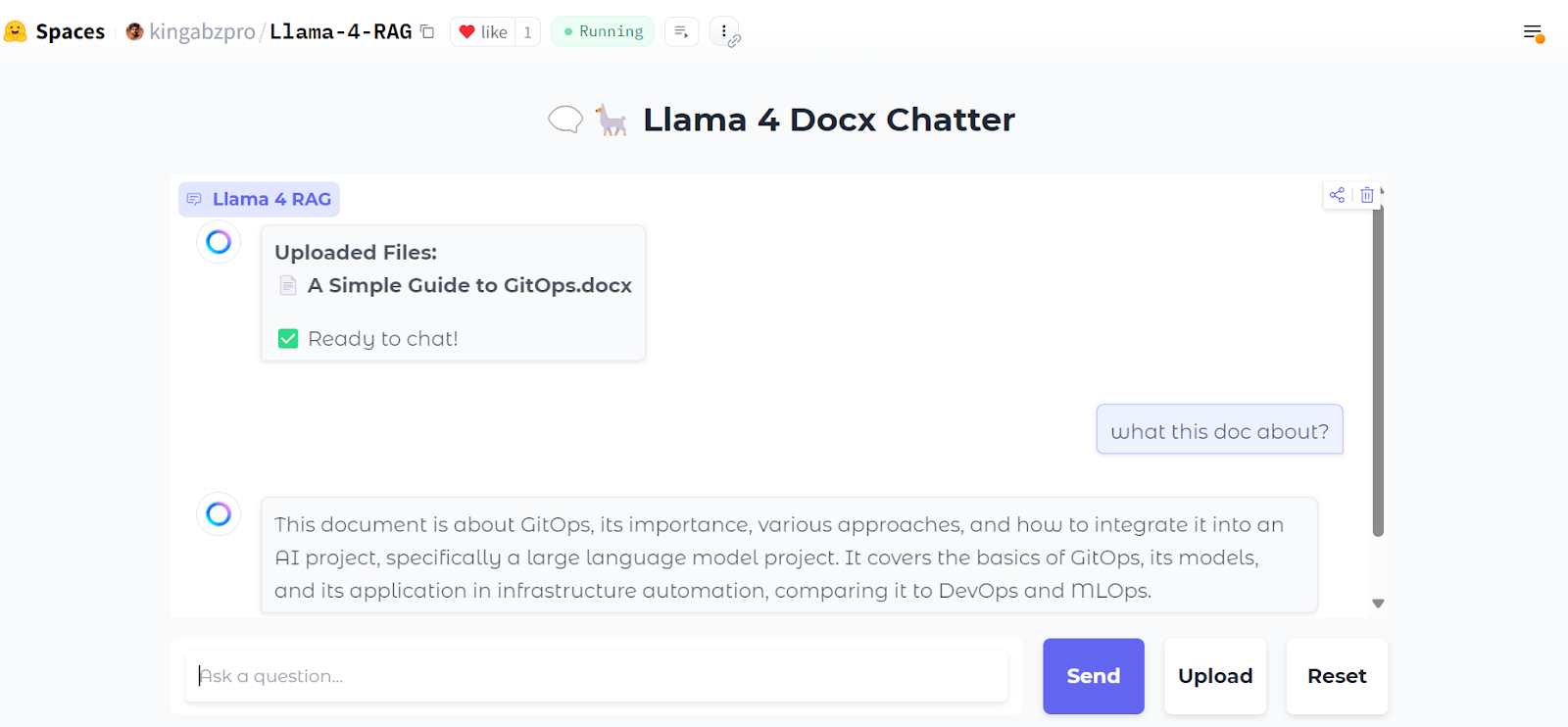
Here is how our chat interface looks:
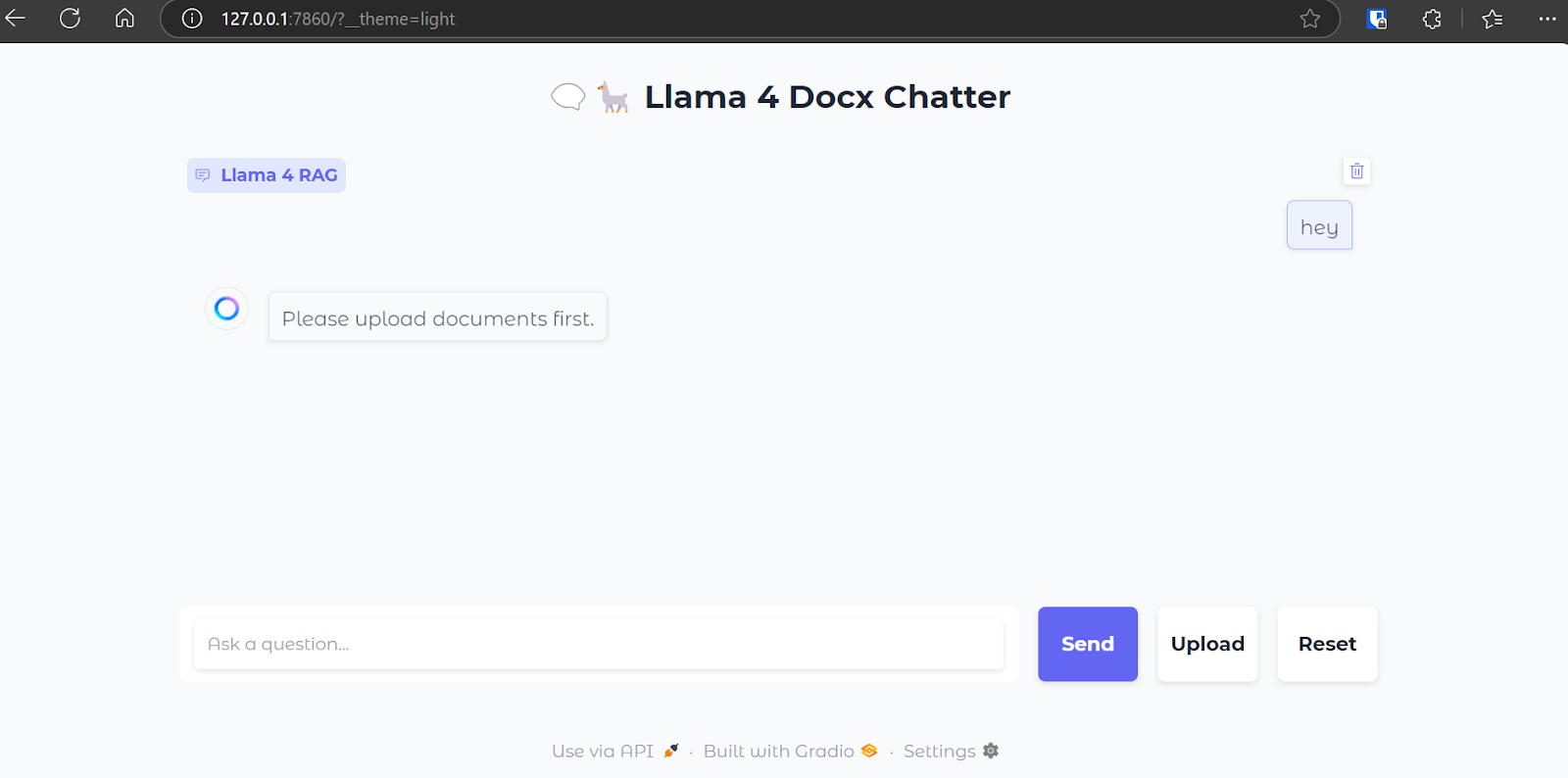
We will upload a .zip file containing .docx files, and as we do this, you will see all the folders and files within the zip file.
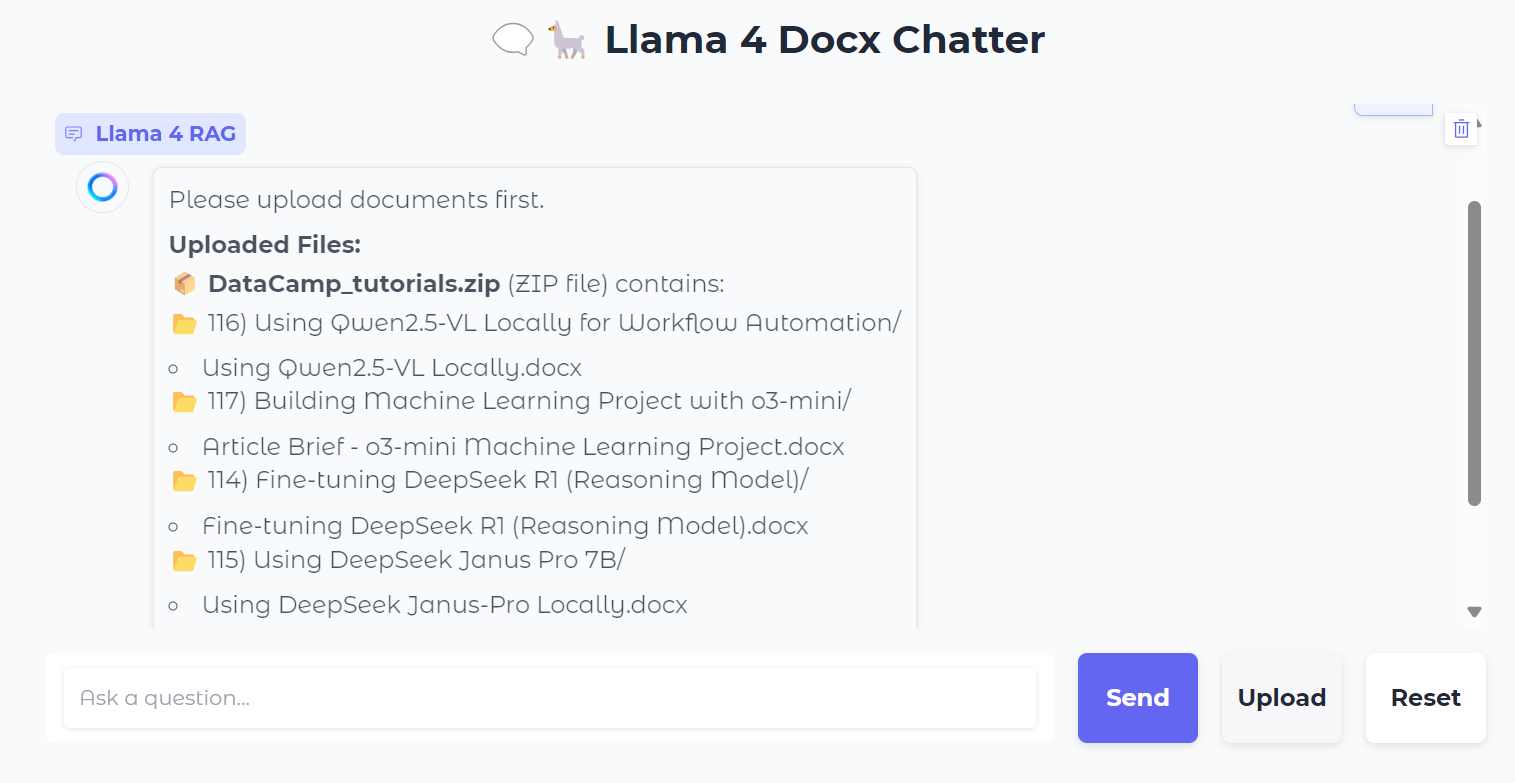
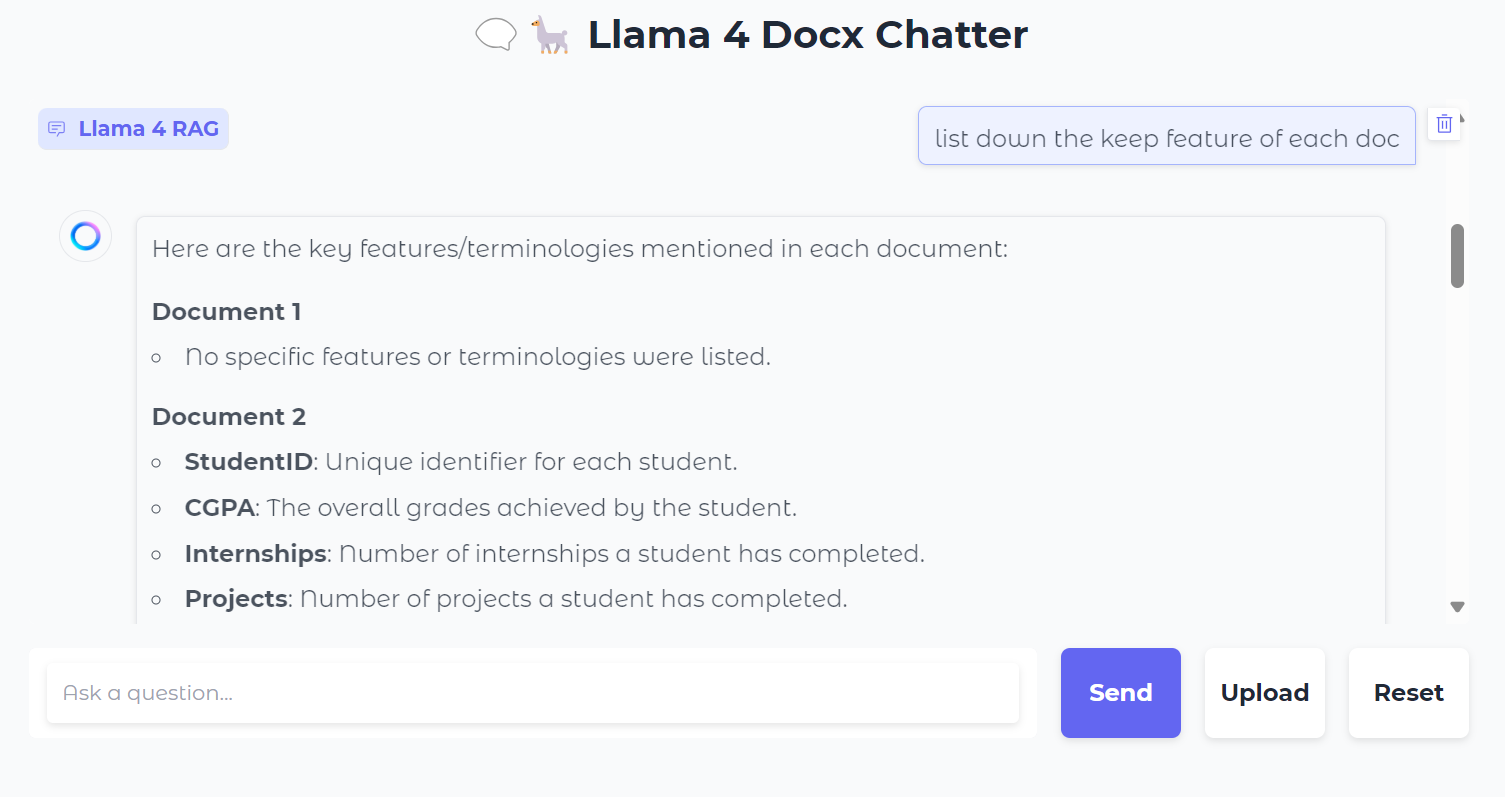
Next, we can ask specific questions about the documents:
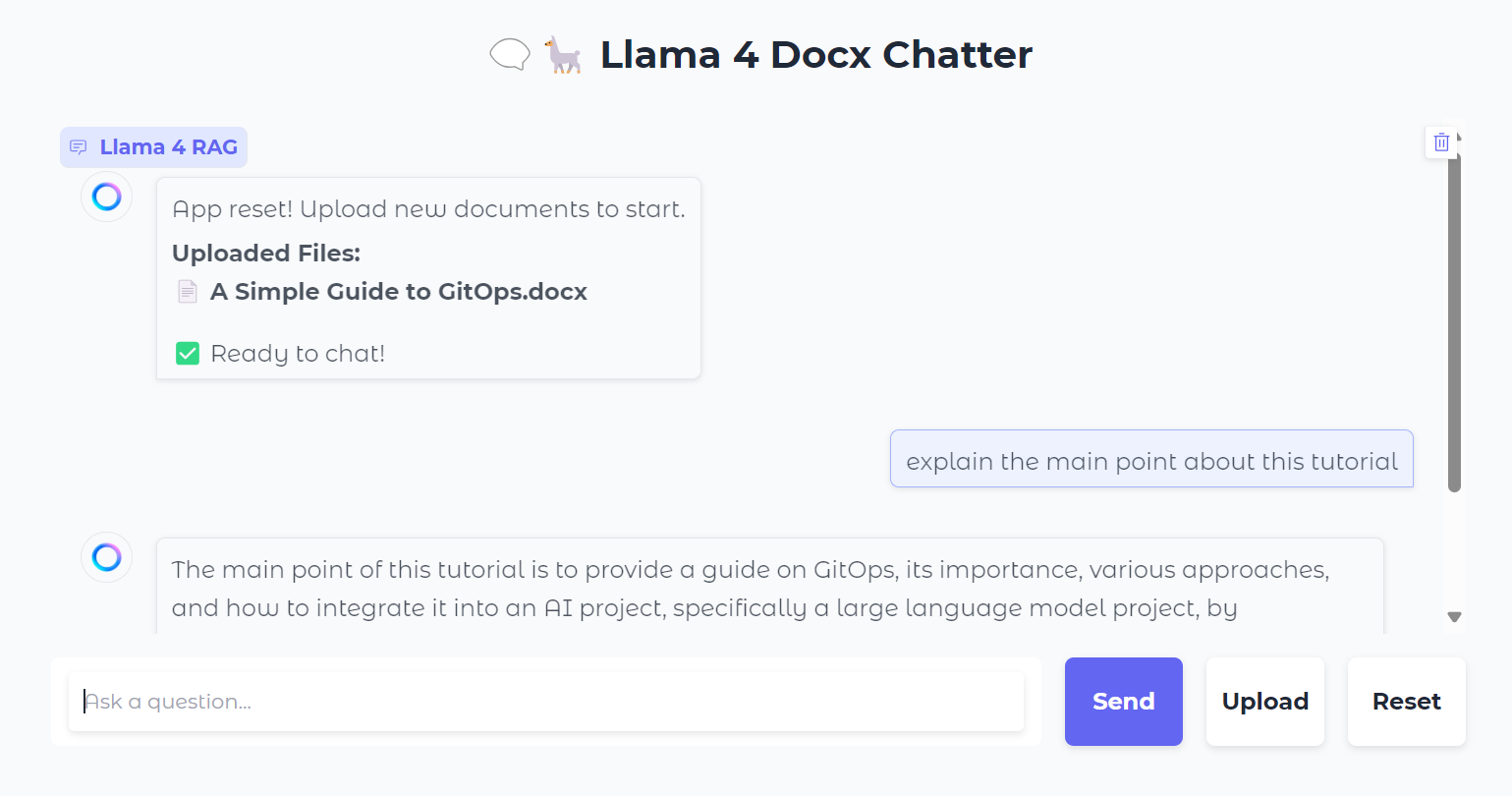
You can also press the “Reset” button to upload a new file and chat about it in just a few seconds.
After testing it locally, you can easily deploy the web application on Hugging Face Space for free. Here is the link to the deployed app: kingabzpro/Llama-4-RAG
Source: kingabzpro/Llama-4-RAG
The code source, notebook, and configuration files can be found in the kingabzpro/Llama-4-RAG repository.
Even with the introduction of long-context window models, RAG will never become obsolete. RAG remains an efficient and cost-effective method for retrieving information from external resources, providing additional context to models.
Moreover, RAG systems are inherently more economical to operate compared to feeding extensive context directly into a model, which requires significant computational resources. This makes RAG a practical and scalable solution for many use cases.
To learn more about Llama 4, check out these resources:
Learn AI with these courses!
Track
Course
Course
Tutorial
Ryan Ong
Tutorial
Ryan Ong
Tutorial
Ryan Ong
Tutorial
Bhavishya Pandit
Tutorial
Abid Ali Awan
code-along
Dan Becker

