
Programa
Llama Fundamentals
4 h
O Llama 4 Scout é comercializado como tendo uma janela de contexto maciço de 10 milhões de tokens, mas seu treinamento foi limitado a um tamanho máximo de entrada de 256 mil tokens. Isso significa que o desempenho pode se degradar com entradas maiores. Para evitar isso, podemos usar o Llama4 com um pipeline de geração aumentada por recuperação (RAG).
Neste tutorial, explicarei passo a passo como criar um pipeline RAG usando o ecossistema LangChain e criar um aplicativo da Web que permita aos usuários carregar documentos e fazer perguntas sobre eles.
Mantemos nossos leitores atualizados sobre as últimas novidades em IA enviando o The Median, nosso boletim informativo gratuito de sexta-feira que detalha as principais histórias da semana. Inscreva-se e fique atento em apenas alguns minutos por semana:
O Llama 4 vem com uma janela de contexto de 10 milhões de tokens, o que significa que podemos alimentá-lo com 100 livros e receber respostas contextuais sobre eles. No entanto, apesar desse recurso impressionante, há motivos convincentes para você combinar o Llama 4 com o RAG. Aqui está o motivo:
Embora o Llama 4 seja compatível com uma janela de contexto enorme, seu treinamento foi limitado a um tamanho máximo de entrada de 256 mil tokens. O desempenho do modelo pode se degradar quando as entradas se aproximam ou excedem esse limite. O RAG atenua esse problema recuperando apenas as informações mais relevantes, garantindo que a entrada permaneça concisa e focada.
O RAG permite a recuperação de informações altamente relevantes de um banco de dados vetorialpermitindo que a Llama 4 processe entradas menores e mais direcionadas. Essa abordagem melhora a eficiência e a precisão.
O processamento de entradas massivas com a janela de contexto total do Llama 4 pode ser computacionalmente caro. Ao usar o RAG, somente os dados mais relevantes são recuperados e processados, reduzindo significativamente a carga computacional e os custos associados.
Neste tutorial, explicarei passo a passo como criar um pipeline simples de geração aumentada por recuperação que permite que você carregue um arquivo .docx e faça perguntas sobre seu conteúdo.
Primeiro, precisamos criar um arquivo GroqCloud e salvá-la como uma variável de ambiente variável de ambiente. Em seguida, instalaremos todos os pacotes Python necessários para carregar, dividir, vetorizar e recuperar o contexto, bem como gerar respostas.
%%capture
%pip install langchain
%pip install langchain-community
%pip install langchainhub
%pip install langchain-chroma
%pip install langchain-groq
%pip install langchain-huggingface
%pip install unstructured[docx]Configuraremos o objeto de modelo usando a API do Groq, fornecendo a ele o nome do modelo e a chave da API. Da mesma forma, faremos o download do modelo de incorporação do Hugging Face e o carregaremos como nosso modelo de incorporação.
from langchain_groq import ChatGroq
from langchain_huggingface import HuggingFaceEmbeddings
llm = ChatGroq(model="meta-llama/llama-4-scout-17b-16e-instruct", api_key=groq_api_key)
embed_model = HuggingFaceEmbeddings(model_name="mixedbread-ai/mxbai-embed-large-v1")Carregaremos o arquivo .docx da pasta raiz e o dividiremos em partes de 1.000 caracteres.
from langchain_community.document_loaders import DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Initialize the text splitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=100,
separators=["\n\n", "\n"]
)
# Load the .docx files
loader = DirectoryLoader("./", glob="*.docx", use_multithreading=True)
documents = loader.load()
# Split the documents into chunks
chunks = text_splitter.split_documents(documents)
# Print the number of chunks
print(len(chunks))29Inicialize o armazenamento do vetor armazenamento de vetores do Chroma e forneça os blocos de texto ao banco de dados de vetores. O texto será convertido em embeddings antes de ser armazenado. Depois disso, executaremos uma pesquisa de similaridade para testar se nosso armazenamento de vetores está preenchido corretamente.
from langchain_chroma import Chroma
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=embed_model,
persist_directory="./Vectordb",
)
query = "What is this tutorial about?"
docs = vectorstore.similarity_search(query)
print(docs[0].page_content)Learn how to Fine-tune Stable Diffusion XL with DreamBooth and LoRA on your personal images.
Let's try another prompt:
Prompt:Em seguida, converteremos nosso armazenamento de vetores em um retriever e criaremos um modelo de prompt para o pipeline RAG.
# Create retriever
retriever = vectorstore.as_retriever()
# Import PromptTemplate
from langchain_core.prompts import PromptTemplate
# Define a clearer, more professional prompt template
template = """You are an expert assistant tasked with answering questions based on the provided documents.
Use only the given context to generate your answer.
If the answer cannot be found in the context, clearly state that you do not know.
Be detailed and precise in your response, but avoid mentioning or referencing the context itself.
Context:
{context}
Question:
{question}
Answer:"""
# Create the PromptTemplate
rag_prompt = PromptTemplate.from_template(template)Por fim, criaremos a cadeia RAG que fornece o contexto e a pergunta no prompt RAG, passaremos pelo modelo Llama 4 e, em seguida, geraremos uma resposta limpa.
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| rag_prompt
| llm
| StrOutputParser()
)Agora, perguntaremos à cadeia RAG sobre o documento.
from IPython.display import display, Markdown
response = rag_chain.invoke("What this tutorial about?")
Markdown(response)This tutorial is about setting up and using the Janus project, specifically Janus Pro, a multimodal model that can understand images and generate images from text prompts, and building a local solution to use the model privately on a laptop GPU. It covers learning about the Janus Series, setting up the Janus project, building a Docker container to run the model locally, and testing its capabilities with various image and text prompts.Como você pode ver, a resposta é altamente precisa e sensível ao contexto. Se você tiver algum problema ao executar o código acima, consulte esta pasta de trabalho do DataLab: Llama 4 RAG pipeline.
Nesta seção, transformaremos o código do pipeline RAG discutido anteriormente em um aplicativo de bate-papo funcional usando o pacote Gradio. Para começar, você precisa instalar o Gradio usando o seguinte comando pip:
$ pip install gradioO aplicativo foi projetado para ser simples e fácil de usar, permitindo que os usuários carreguem um único arquivo .docx, vários arquivos .docx ou um arquivo .zip contendo arquivos .docx. Os usuários podem então fazer perguntas sobre o conteúdo de todos os arquivos carregados, fornecendo uma maneira rápida e eficiente de recuperar informações.
Os recursos do aplicativo:
Vamos juntar tudo isso:
main.py:
# ========== Standard Library ==========
import os
import tempfile
import zipfile
from typing import List, Optional, Tuple, Union
import collections
# ========== Third-Party Libraries ==========
import gradio as gr
from groq import Groq
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import DirectoryLoader, UnstructuredFileLoader
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_groq import ChatGroq
from langchain_huggingface import HuggingFaceEmbeddings
# ========== Configs ==========
TITLE = """<h1 align="center">🗨️🦙 Llama 4 Docx Chatter</h1>"""
AVATAR_IMAGES = (
None,
"./logo.png",
)
# Acceptable file extensions
TEXT_EXTENSIONS = [".docx", ".zip"]
# ========== Models & Clients ==========
GROQ_API_KEY = os.getenv("GROQ_API_KEY")
client = Groq(api_key=GROQ_API_KEY)
llm = ChatGroq(model="meta-llama/llama-4-scout-17b-16e-instruct", api_key=GROQ_API_KEY)
embed_model = HuggingFaceEmbeddings(model_name="mixedbread-ai/mxbai-embed-large-v1")
# ========== Core Components ==========
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=100,
separators=["\n\n", "\n"],
)
rag_template = """You are an expert assistant tasked with answering questions based on the provided documents.
Use only the given context to generate your answer.
If the answer cannot be found in the context, clearly state that you do not know.
Be detailed and precise in your response, but avoid mentioning or referencing the context itself.
Context:
{context}
Question:
{question}
Answer:"""
rag_prompt = PromptTemplate.from_template(rag_template)
# ========== App State ==========
class AppState:
vectorstore: Optional[InMemoryVectorStore] = None
rag_chain = None
state = AppState()
# ========== Utility Functions ==========
def load_documents_from_files(files: List[str]) -> List:
"""Load documents from uploaded files directly without moving."""
all_documents = []
# Temporary directory if ZIP needs extraction
with tempfile.TemporaryDirectory() as temp_dir:
for file_path in files:
ext = os.path.splitext(file_path)[1].lower()
if ext == ".zip":
# Extract ZIP inside temp_dir
with zipfile.ZipFile(file_path, "r") as zip_ref:
zip_ref.extractall(temp_dir)
# Load all docx from extracted zip
loader = DirectoryLoader(
path=temp_dir,
glob="**/*.docx",
use_multithreading=True,
)
docs = loader.load()
all_documents.extend(docs)
elif ext == ".docx":
# Load single docx directly
loader = UnstructuredFileLoader(file_path)
docs = loader.load()
all_documents.extend(docs)
return all_documents
def get_last_user_message(chatbot: List[Union[gr.ChatMessage, dict]]) -> Optional[str]:
"""Get last user prompt."""
for message in reversed(chatbot):
content = (
message.get("content") if isinstance(message, dict) else message.content
)
if (
message.get("role") if isinstance(message, dict) else message.role
) == "user":
return content
return None
# ========== Main Logic ==========
def upload_files(
files: Optional[List[str]], chatbot: List[Union[gr.ChatMessage, dict]]
):
"""Handle file upload - .docx or .zip containing docx."""
if not files:
return chatbot
file_summaries = [] # <-- Collect formatted file/folder info
documents = []
with tempfile.TemporaryDirectory() as temp_dir:
for file_path in files:
filename = os.path.basename(file_path)
ext = os.path.splitext(file_path)[1].lower()
if ext == ".zip":
file_summaries.append(f"📦 **{filename}** (ZIP file) contains:")
try:
with zipfile.ZipFile(file_path, "r") as zip_ref:
zip_ref.extractall(temp_dir)
zip_contents = zip_ref.namelist()
# Group files by folder
folder_map = collections.defaultdict(list)
for item in zip_contents:
if item.endswith("/"):
continue # skip folder entries themselves
folder = os.path.dirname(item)
file_name = os.path.basename(item)
folder_map[folder].append(file_name)
# Format nicely
for folder, files_in_folder in folder_map.items():
if folder:
file_summaries.append(f"📂 {folder}/")
else:
file_summaries.append(f"📄 (root)")
for f in files_in_folder:
file_summaries.append(f" - {f}")
# Load docx files extracted from ZIP
loader = DirectoryLoader(
path=temp_dir,
glob="**/*.docx",
use_multithreading=True,
)
docs = loader.load()
documents.extend(docs)
except zipfile.BadZipFile:
chatbot.append(
gr.ChatMessage(
role="assistant",
content=f"❌ Failed to open ZIP file: {filename}",
)
)
elif ext == ".docx":
file_summaries.append(f"📄 **{filename}**")
loader = UnstructuredFileLoader(file_path)
docs = loader.load()
documents.extend(docs)
else:
file_summaries.append(f"❌ Unsupported file type: {filename}")
if not documents:
chatbot.append(
gr.ChatMessage(
role="assistant", content="No valid .docx files found in upload."
)
)
return chatbot
# Split documents
chunks = text_splitter.split_documents(documents)
if not chunks:
chatbot.append(
gr.ChatMessage(
role="assistant", content="Failed to split documents into chunks."
)
)
return chatbot
# Create Vectorstore
state.vectorstore = InMemoryVectorStore.from_documents(
documents=chunks,
embedding=embed_model,
)
retriever = state.vectorstore.as_retriever()
# Build RAG Chain
state.rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| rag_prompt
| llm
| StrOutputParser()
)
# Final display
chatbot.append(
gr.ChatMessage(
role="assistant",
content="**Uploaded Files:**\n"
+ "\n".join(file_summaries)
+ "\n\n✅ Ready to chat!",
)
)
return chatbot
def user_message(
text_prompt: str, chatbot: List[Union[gr.ChatMessage, dict]]
) -> Tuple[str, List[Union[gr.ChatMessage, dict]]]:
"""Add user's text input to conversation."""
if text_prompt.strip():
chatbot.append(gr.ChatMessage(role="user", content=text_prompt))
return "", chatbot
def process_query(
chatbot: List[Union[gr.ChatMessage, dict]],
) -> List[Union[gr.ChatMessage, dict]]:
"""Process user's query through RAG pipeline."""
prompt = get_last_user_message(chatbot)
if not prompt:
chatbot.append(
gr.ChatMessage(role="assistant", content="Please type a question first.")
)
return chatbot
if state.rag_chain is None:
chatbot.append(
gr.ChatMessage(role="assistant", content="Please upload documents first.")
)
return chatbot
chatbot.append(gr.ChatMessage(role="assistant", content="Thinking..."))
try:
response = state.rag_chain.invoke(prompt)
chatbot[-1].content = response
except Exception as e:
chatbot[-1].content = f"Error: {str(e)}"
return chatbot
def reset_app(
chatbot: List[Union[gr.ChatMessage, dict]],
) -> List[Union[gr.ChatMessage, dict]]:
"""Reset application state."""
state.vectorstore = None
state.rag_chain = None
return [
gr.ChatMessage(
role="assistant", content="App reset! Upload new documents to start."
)
]
# ========== UI Layout ==========
with gr.Blocks(theme=gr.themes.Soft()) as demo:
gr.HTML(TITLE)
chatbot = gr.Chatbot(
label="Llama 4 RAG",
type="messages",
bubble_full_width=False,
avatar_images=AVATAR_IMAGES,
scale=2,
height=350,
)
with gr.Row(equal_height=True):
text_prompt = gr.Textbox(
placeholder="Ask a question...", show_label=False, autofocus=True, scale=28
)
send_button = gr.Button(
value="Send",
variant="primary",
scale=1,
min_width=80,
)
upload_button = gr.UploadButton(
label="Upload",
file_count="multiple",
file_types=TEXT_EXTENSIONS,
scale=1,
min_width=80,
)
reset_button = gr.Button(
value="Reset",
variant="stop",
scale=1,
min_width=80,
)
send_button.click(
fn=user_message,
inputs=[text_prompt, chatbot],
outputs=[text_prompt, chatbot],
queue=False,
).then(fn=process_query, inputs=[chatbot], outputs=[chatbot])
text_prompt.submit(
fn=user_message,
inputs=[text_prompt, chatbot],
outputs=[text_prompt, chatbot],
queue=False,
).then(fn=process_query, inputs=[chatbot], outputs=[chatbot])
upload_button.upload(
fn=upload_files, inputs=[upload_button, chatbot], outputs=[chatbot], queue=False
)
reset_button.click(fn=reset_app, inputs=[chatbot], outputs=[chatbot], queue=False)
demo.queue().launch()Agora, executaremos o aplicativo Web e testaremos suas funcionalidades. Para iniciar o aplicativo, execute o seguinte comando no terminal:
$ python main.py Quando o servidor da Web estiver em funcionamento, navegue até a URL a seguir ou copie e cole-a manualmente no navegador para acessar a interface da Web: http://127.0.0.1:7860
Esta é a aparência da nossa interface de bate-papo:
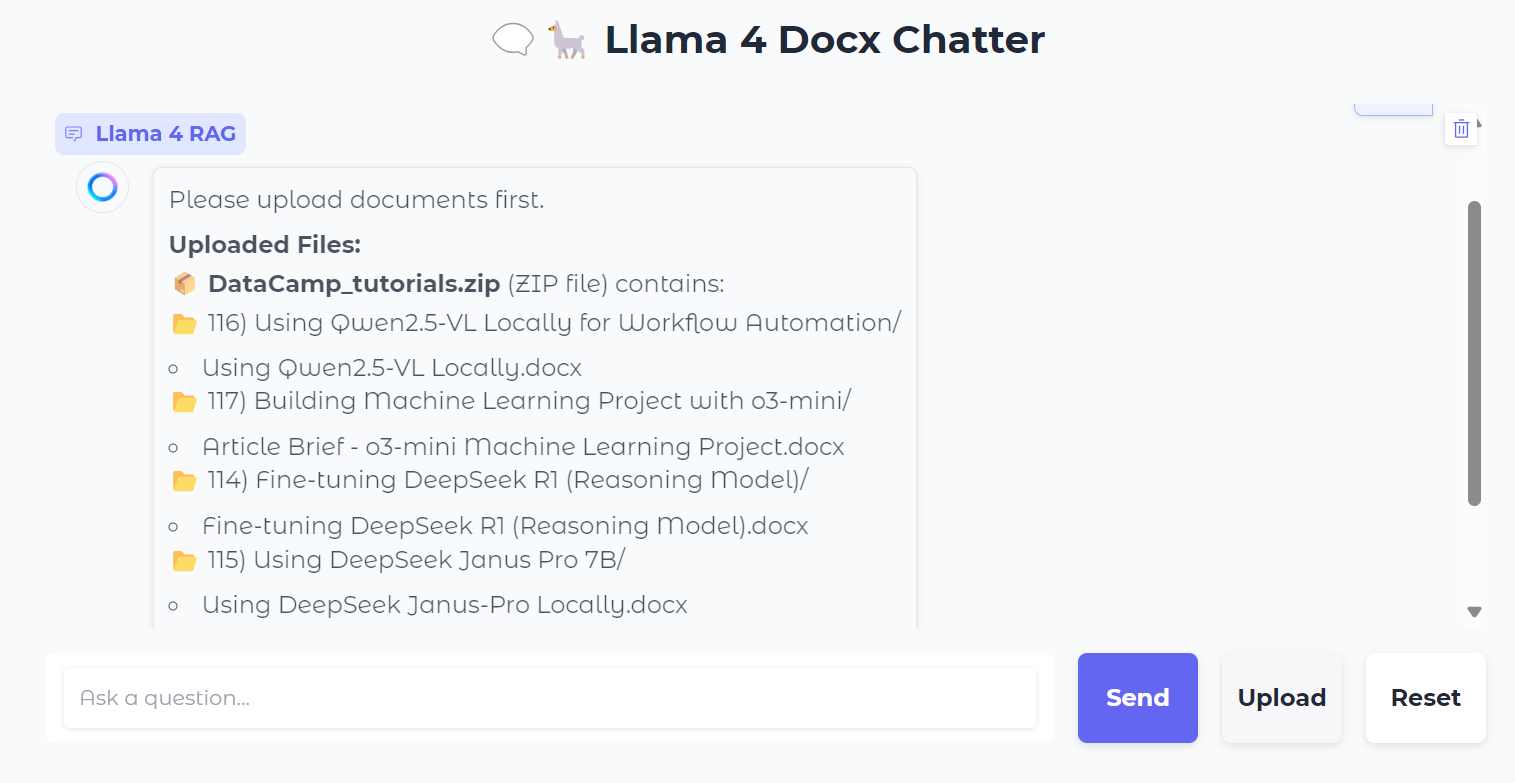
Faremos upload de um arquivo .zip contendo arquivos .docx e, ao fazer isso, você verá todas as pastas e arquivos dentro do arquivo zip.
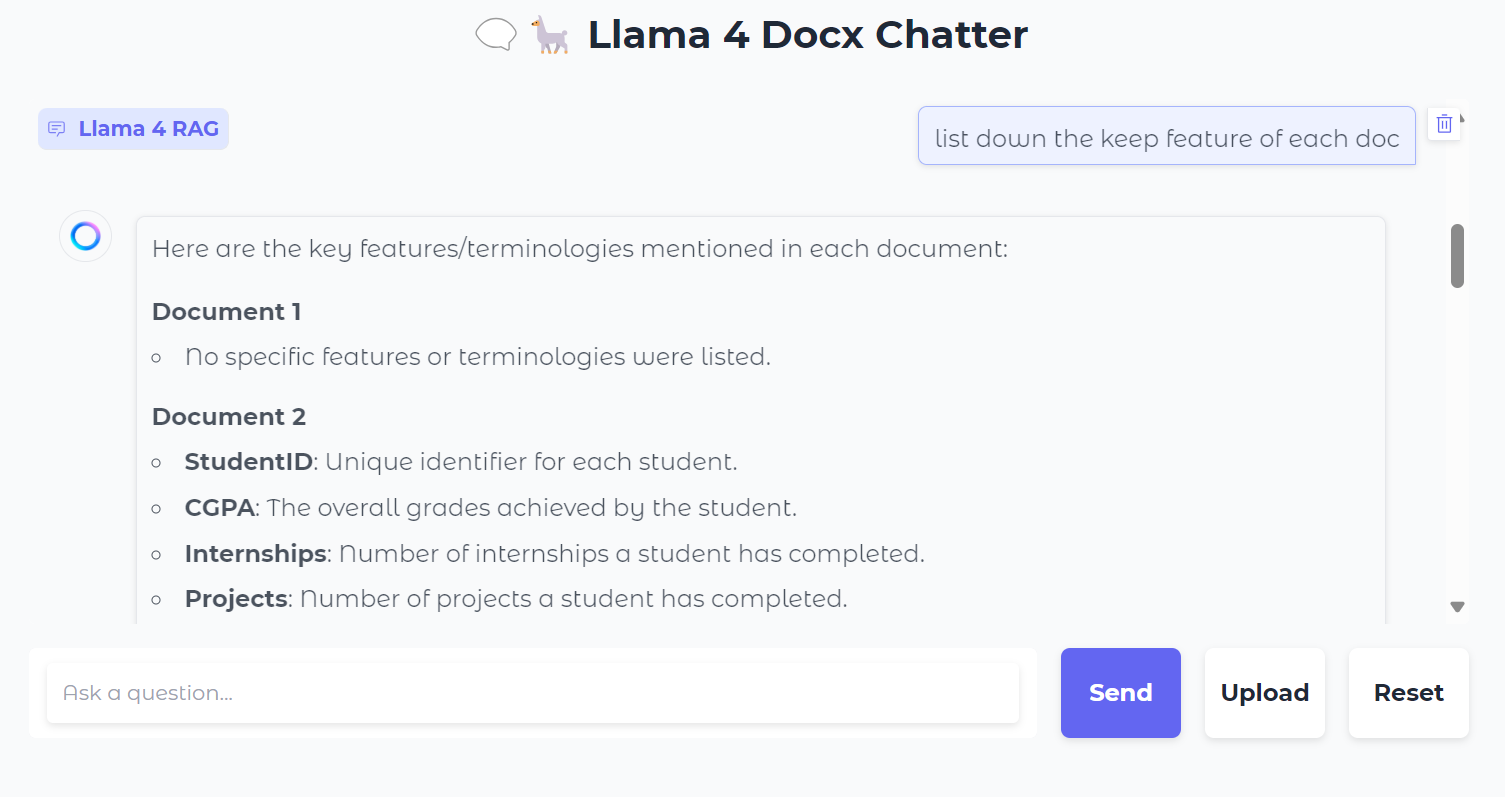
Em seguida, podemos fazer perguntas específicas sobre os documentos:
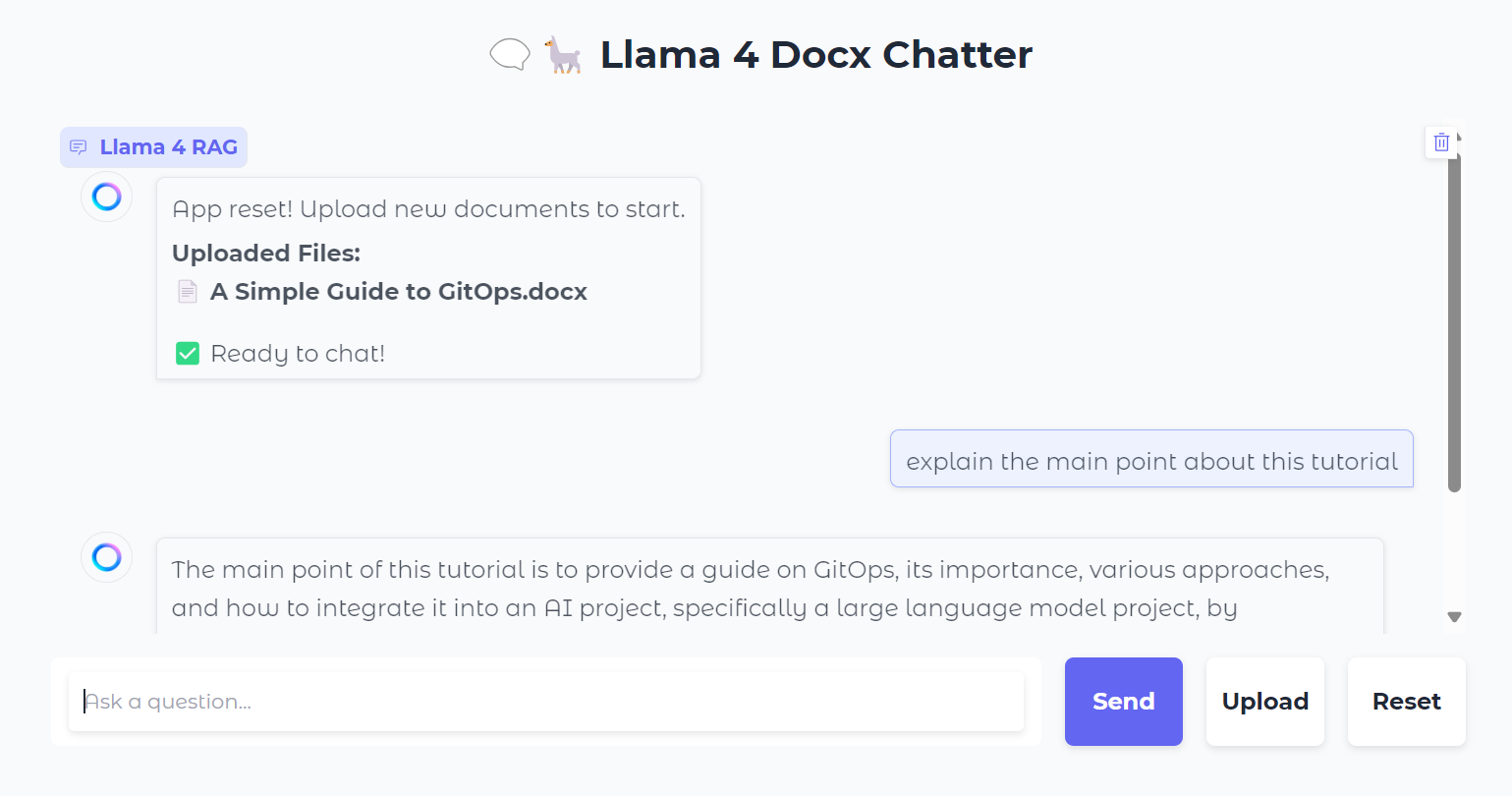
Você também pode pressionar o botão "Reset" para carregar um novo arquivo e conversar sobre ele em apenas alguns segundos.
Depois de testá-lo localmente, você pode implantar facilmente o aplicativo da Web no Hugging Face Space gratuitamente. Aqui está o link para o aplicativo implantado: kingabzpro/Llama-4-RAG
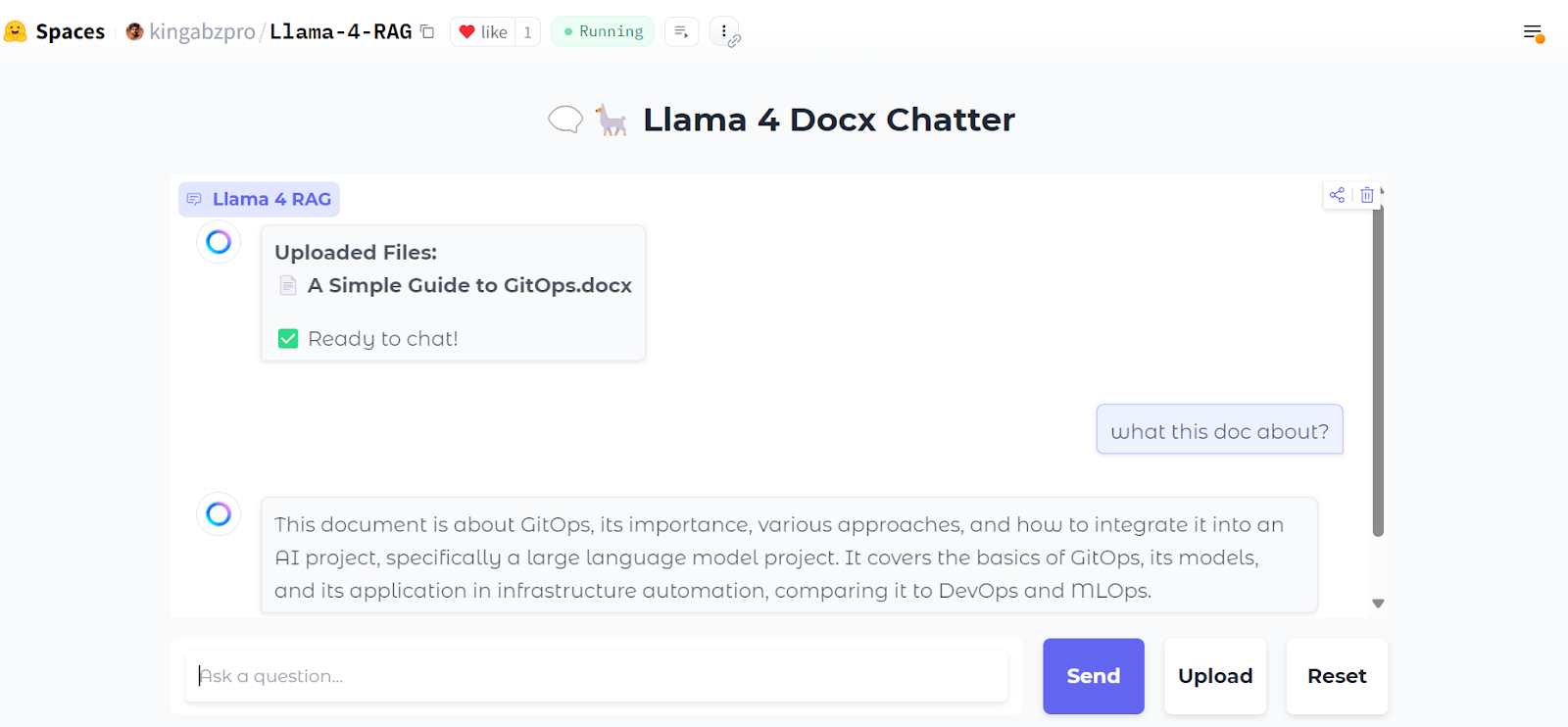
Fonte: kingabzpro/Llama-4-RAG
O código-fonte, o notebook e os arquivos de configuração podem ser encontrados no diretório kingabzpro/Llama-4-RAG que você pode encontrar no repositório kingabzpro/Llama-4-RAG.
Mesmo com a introdução de modelos de janelas de contexto longo, o RAG nunca se tornará obsoleto. O RAG continua sendo um método eficiente e econômico para recuperar informações de recursos externos, fornecendo contexto adicional aos modelos.
Além disso, os sistemas RAG são inerentemente mais econômicos para operar em comparação com a alimentação de um contexto extenso diretamente em um modelo, o que exige recursos computacionais significativos. Isso torna o RAG uma solução prática e dimensionável para muitos casos de uso.
Para saber mais sobre a Llama 4, confira estes recursos:
Aprenda IA com estes cursos!
Programa
Curso
Curso
blog
Natassha Selvaraj
10 min
Tutorial
Ryan Ong
Tutorial
Moez Ali
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer

