
Lernpfad
Llama-Grundlagen
4 Std.
Llama 4 Scout wird mit einem riesigen Kontextfenster von 10 Millionen Token beworben, aber sein Training war auf eine maximale Eingabegröße von 256k Token beschränkt. Das bedeutet, dass die Leistung bei größeren Eingaben abnehmen kann. Um dies zu verhindern, können wir Llama4 mit einer RAG-Pipeline (retrieval-augmented generation) verwenden.
In diesem Tutorial erkläre ich dir Schritt für Schritt, wie du mit dem LangChain-Ökosystem eine RAG-Pipeline aufbaust und eine Webanwendung erstellst, mit der Nutzer Dokumente hochladen und Fragen dazu stellen können.
Wir halten unsere Leserinnen und Leser mit The Median auf dem Laufenden, unserem kostenlosen Freitags-Newsletter, der die wichtigsten Meldungen der Woche aufschlüsselt. Melde dich an und bleibe in nur ein paar Minuten pro Woche auf dem Laufenden:
Llama 4 verfügt über ein Kontextfenster mit 10 Millionen Token, d.h. wir können es mit 100 Büchern füttern und erhalten kontextbezogene Antworten zu ihnen. Doch trotz dieser beeindruckenden Funktion gibt es zwingende Gründe, Llama 4 mit RAG. Hier ist der Grund dafür:
Obwohl Llama 4 ein riesiges Kontextfenster unterstützt, war sein Training auf eine maximale Eingabegröße von 256k Token beschränkt. Die Leistung des Modells kann sich verschlechtern, wenn die Eingaben diesen Schwellenwert erreichen oder überschreiten. RAG entschärft dieses Problem, indem es nur die wichtigsten Informationen abruft und so sicherstellt, dass die Eingaben kurz und bündig bleiben.
RAG ermöglicht das Abrufen von hochrelevanten Informationen aus einer Vektor-DatenbankDadurch kann Llama 4 kleinere, gezieltere Eingaben verarbeiten. Dieser Ansatz verbessert sowohl die Effizienz als auch die Genauigkeit.
Die Verarbeitung umfangreicher Eingaben mit dem vollständigen Kontextfenster von Llama 4 kann sehr rechenintensiv sein. Durch den Einsatz von RAG werden nur die relevantesten Daten abgerufen und verarbeitet, was den Rechenaufwand und die damit verbundenen Kosten erheblich reduziert.
In diesem Tutorial erkläre ich dir Schritt für Schritt, wie du eine einfache Pipeline zur Generierung von Abfragen aufbaust, mit der du eine .docx Datei laden und Fragen zu ihrem Inhalt stellen kannst.
Zuerst müssen wir eine GroqCloud API-Schlüssel und speichern ihn als Umgebungsvariable. Als Nächstes werden wir alle notwendigen Python-Pakete installieren, die zum Laden, Teilen, Vektorisieren und Abrufen des Kontexts sowie zum Generieren von Antworten benötigt werden.
%%capture
%pip install langchain
%pip install langchain-community
%pip install langchainhub
%pip install langchain-chroma
%pip install langchain-groq
%pip install langchain-huggingface
%pip install unstructured[docx]Wir richten das Modellobjekt über die Groq-API ein, indem wir ihm den Modellnamen und den API-Schlüssel geben. Auf ähnliche Weise laden wir das Einbettungsmodell von Hugging Face herunter und verwenden es als unser Einbettungsmodell.
from langchain_groq import ChatGroq
from langchain_huggingface import HuggingFaceEmbeddings
llm = ChatGroq(model="meta-llama/llama-4-scout-17b-16e-instruct", api_key=groq_api_key)
embed_model = HuggingFaceEmbeddings(model_name="mixedbread-ai/mxbai-embed-large-v1")Wir laden die Datei .docx aus dem Stammordner und teilen sie in Abschnitte von 1000 Zeichen auf.
from langchain_community.document_loaders import DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Initialize the text splitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=100,
separators=["\n\n", "\n"]
)
# Load the .docx files
loader = DirectoryLoader("./", glob="*.docx", use_multithreading=True)
documents = loader.load()
# Split the documents into chunks
chunks = text_splitter.split_documents(documents)
# Print the number of chunks
print(len(chunks))29Initialisiere den Chroma-Vektorspeicher und stelle der Vektordatenbank die Textstücke zur Verfügung. Der Text wird in Einbettungen umgewandelt, bevor er gespeichert wird. Danach führen wir eine Ähnlichkeitssuche durch, um zu testen, ob unser Vektorspeicher richtig befüllt ist.
from langchain_chroma import Chroma
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=embed_model,
persist_directory="./Vectordb",
)
query = "What is this tutorial about?"
docs = vectorstore.similarity_search(query)
print(docs[0].page_content)Learn how to Fine-tune Stable Diffusion XL with DreamBooth and LoRA on your personal images.
Let's try another prompt:
Prompt:Als Nächstes werden wir unseren Vektorspeicher in einen Retriever umwandeln und eine Prompt-Vorlage für die RAG-Pipeline erstellen.
# Create retriever
retriever = vectorstore.as_retriever()
# Import PromptTemplate
from langchain_core.prompts import PromptTemplate
# Define a clearer, more professional prompt template
template = """You are an expert assistant tasked with answering questions based on the provided documents.
Use only the given context to generate your answer.
If the answer cannot be found in the context, clearly state that you do not know.
Be detailed and precise in your response, but avoid mentioning or referencing the context itself.
Context:
{context}
Question:
{question}
Answer:"""
# Create the PromptTemplate
rag_prompt = PromptTemplate.from_template(template)Zum Schluss erstellen wir die RAG-Kette, die sowohl den Kontext als auch die Frage in der RAG-Aufforderung enthält, durchlaufen das Llama 4-Modell und erzeugen dann eine saubere Antwort.
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| rag_prompt
| llm
| StrOutputParser()
)Wir werden jetzt die RAG-Kette über das Dokument befragen.
from IPython.display import display, Markdown
response = rag_chain.invoke("What this tutorial about?")
Markdown(response)This tutorial is about setting up and using the Janus project, specifically Janus Pro, a multimodal model that can understand images and generate images from text prompts, and building a local solution to use the model privately on a laptop GPU. It covers learning about the Janus Series, setting up the Janus project, building a Docker container to run the model locally, and testing its capabilities with various image and text prompts.Wie du siehst, ist die Antwort sehr genau und kontextabhängig. Wenn du bei der Ausführung des obigen Codes auf Probleme stößt, sieh dir bitte diese DataLab-Arbeitsmappe an: Llama 4 RAG-Pipeline.
In diesem Abschnitt werden wir den zuvor besprochenen RAG-Pipeline-Code mit Hilfe des Gradio-Pakets in eine funktionale Chat-Anwendung umwandeln. Um loszulegen, musst du Gradio mit dem folgenden pip Befehl installieren:
$ pip install gradioDie Anwendung ist einfach und benutzerfreundlich gestaltet und ermöglicht es den Nutzern, eine einzelne .docx Datei, mehrere .docx Dateien oder ein .zip Archiv mit .docx Dateien hochzuladen. Die Nutzer können dann Fragen zum Inhalt aller hochgeladenen Dateien stellen und so schnell und effizient Informationen abrufen.
Die Anwendung bietet folgende Funktionen:
Fassen wir das alles zusammen:
main.py:
# ========== Standard Library ==========
import os
import tempfile
import zipfile
from typing import List, Optional, Tuple, Union
import collections
# ========== Third-Party Libraries ==========
import gradio as gr
from groq import Groq
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import DirectoryLoader, UnstructuredFileLoader
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_groq import ChatGroq
from langchain_huggingface import HuggingFaceEmbeddings
# ========== Configs ==========
TITLE = """<h1 align="center">🗨️🦙 Llama 4 Docx Chatter</h1>"""
AVATAR_IMAGES = (
None,
"./logo.png",
)
# Acceptable file extensions
TEXT_EXTENSIONS = [".docx", ".zip"]
# ========== Models & Clients ==========
GROQ_API_KEY = os.getenv("GROQ_API_KEY")
client = Groq(api_key=GROQ_API_KEY)
llm = ChatGroq(model="meta-llama/llama-4-scout-17b-16e-instruct", api_key=GROQ_API_KEY)
embed_model = HuggingFaceEmbeddings(model_name="mixedbread-ai/mxbai-embed-large-v1")
# ========== Core Components ==========
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=100,
separators=["\n\n", "\n"],
)
rag_template = """You are an expert assistant tasked with answering questions based on the provided documents.
Use only the given context to generate your answer.
If the answer cannot be found in the context, clearly state that you do not know.
Be detailed and precise in your response, but avoid mentioning or referencing the context itself.
Context:
{context}
Question:
{question}
Answer:"""
rag_prompt = PromptTemplate.from_template(rag_template)
# ========== App State ==========
class AppState:
vectorstore: Optional[InMemoryVectorStore] = None
rag_chain = None
state = AppState()
# ========== Utility Functions ==========
def load_documents_from_files(files: List[str]) -> List:
"""Load documents from uploaded files directly without moving."""
all_documents = []
# Temporary directory if ZIP needs extraction
with tempfile.TemporaryDirectory() as temp_dir:
for file_path in files:
ext = os.path.splitext(file_path)[1].lower()
if ext == ".zip":
# Extract ZIP inside temp_dir
with zipfile.ZipFile(file_path, "r") as zip_ref:
zip_ref.extractall(temp_dir)
# Load all docx from extracted zip
loader = DirectoryLoader(
path=temp_dir,
glob="**/*.docx",
use_multithreading=True,
)
docs = loader.load()
all_documents.extend(docs)
elif ext == ".docx":
# Load single docx directly
loader = UnstructuredFileLoader(file_path)
docs = loader.load()
all_documents.extend(docs)
return all_documents
def get_last_user_message(chatbot: List[Union[gr.ChatMessage, dict]]) -> Optional[str]:
"""Get last user prompt."""
for message in reversed(chatbot):
content = (
message.get("content") if isinstance(message, dict) else message.content
)
if (
message.get("role") if isinstance(message, dict) else message.role
) == "user":
return content
return None
# ========== Main Logic ==========
def upload_files(
files: Optional[List[str]], chatbot: List[Union[gr.ChatMessage, dict]]
):
"""Handle file upload - .docx or .zip containing docx."""
if not files:
return chatbot
file_summaries = [] # <-- Collect formatted file/folder info
documents = []
with tempfile.TemporaryDirectory() as temp_dir:
for file_path in files:
filename = os.path.basename(file_path)
ext = os.path.splitext(file_path)[1].lower()
if ext == ".zip":
file_summaries.append(f"📦 **{filename}** (ZIP file) contains:")
try:
with zipfile.ZipFile(file_path, "r") as zip_ref:
zip_ref.extractall(temp_dir)
zip_contents = zip_ref.namelist()
# Group files by folder
folder_map = collections.defaultdict(list)
for item in zip_contents:
if item.endswith("/"):
continue # skip folder entries themselves
folder = os.path.dirname(item)
file_name = os.path.basename(item)
folder_map[folder].append(file_name)
# Format nicely
for folder, files_in_folder in folder_map.items():
if folder:
file_summaries.append(f"📂 {folder}/")
else:
file_summaries.append(f"📄 (root)")
for f in files_in_folder:
file_summaries.append(f" - {f}")
# Load docx files extracted from ZIP
loader = DirectoryLoader(
path=temp_dir,
glob="**/*.docx",
use_multithreading=True,
)
docs = loader.load()
documents.extend(docs)
except zipfile.BadZipFile:
chatbot.append(
gr.ChatMessage(
role="assistant",
content=f"❌ Failed to open ZIP file: {filename}",
)
)
elif ext == ".docx":
file_summaries.append(f"📄 **{filename}**")
loader = UnstructuredFileLoader(file_path)
docs = loader.load()
documents.extend(docs)
else:
file_summaries.append(f"❌ Unsupported file type: {filename}")
if not documents:
chatbot.append(
gr.ChatMessage(
role="assistant", content="No valid .docx files found in upload."
)
)
return chatbot
# Split documents
chunks = text_splitter.split_documents(documents)
if not chunks:
chatbot.append(
gr.ChatMessage(
role="assistant", content="Failed to split documents into chunks."
)
)
return chatbot
# Create Vectorstore
state.vectorstore = InMemoryVectorStore.from_documents(
documents=chunks,
embedding=embed_model,
)
retriever = state.vectorstore.as_retriever()
# Build RAG Chain
state.rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| rag_prompt
| llm
| StrOutputParser()
)
# Final display
chatbot.append(
gr.ChatMessage(
role="assistant",
content="**Uploaded Files:**\n"
+ "\n".join(file_summaries)
+ "\n\n✅ Ready to chat!",
)
)
return chatbot
def user_message(
text_prompt: str, chatbot: List[Union[gr.ChatMessage, dict]]
) -> Tuple[str, List[Union[gr.ChatMessage, dict]]]:
"""Add user's text input to conversation."""
if text_prompt.strip():
chatbot.append(gr.ChatMessage(role="user", content=text_prompt))
return "", chatbot
def process_query(
chatbot: List[Union[gr.ChatMessage, dict]],
) -> List[Union[gr.ChatMessage, dict]]:
"""Process user's query through RAG pipeline."""
prompt = get_last_user_message(chatbot)
if not prompt:
chatbot.append(
gr.ChatMessage(role="assistant", content="Please type a question first.")
)
return chatbot
if state.rag_chain is None:
chatbot.append(
gr.ChatMessage(role="assistant", content="Please upload documents first.")
)
return chatbot
chatbot.append(gr.ChatMessage(role="assistant", content="Thinking..."))
try:
response = state.rag_chain.invoke(prompt)
chatbot[-1].content = response
except Exception as e:
chatbot[-1].content = f"Error: {str(e)}"
return chatbot
def reset_app(
chatbot: List[Union[gr.ChatMessage, dict]],
) -> List[Union[gr.ChatMessage, dict]]:
"""Reset application state."""
state.vectorstore = None
state.rag_chain = None
return [
gr.ChatMessage(
role="assistant", content="App reset! Upload new documents to start."
)
]
# ========== UI Layout ==========
with gr.Blocks(theme=gr.themes.Soft()) as demo:
gr.HTML(TITLE)
chatbot = gr.Chatbot(
label="Llama 4 RAG",
type="messages",
bubble_full_width=False,
avatar_images=AVATAR_IMAGES,
scale=2,
height=350,
)
with gr.Row(equal_height=True):
text_prompt = gr.Textbox(
placeholder="Ask a question...", show_label=False, autofocus=True, scale=28
)
send_button = gr.Button(
value="Send",
variant="primary",
scale=1,
min_width=80,
)
upload_button = gr.UploadButton(
label="Upload",
file_count="multiple",
file_types=TEXT_EXTENSIONS,
scale=1,
min_width=80,
)
reset_button = gr.Button(
value="Reset",
variant="stop",
scale=1,
min_width=80,
)
send_button.click(
fn=user_message,
inputs=[text_prompt, chatbot],
outputs=[text_prompt, chatbot],
queue=False,
).then(fn=process_query, inputs=[chatbot], outputs=[chatbot])
text_prompt.submit(
fn=user_message,
inputs=[text_prompt, chatbot],
outputs=[text_prompt, chatbot],
queue=False,
).then(fn=process_query, inputs=[chatbot], outputs=[chatbot])
upload_button.upload(
fn=upload_files, inputs=[upload_button, chatbot], outputs=[chatbot], queue=False
)
reset_button.click(fn=reset_app, inputs=[chatbot], outputs=[chatbot], queue=False)
demo.queue().launch()Jetzt werden wir die Webanwendung ausführen und ihre Funktionen testen. Um die Anwendung zu starten, führe den folgenden Befehl im Terminal aus:
$ python main.py Sobald der Webserver läuft, navigierst du zur folgenden URL oder kopierst sie und fügst sie manuell in deinen Browser ein, um die Weboberfläche aufzurufen: http://127.0.0.1:7860
So sieht unser Chat-Interface aus:
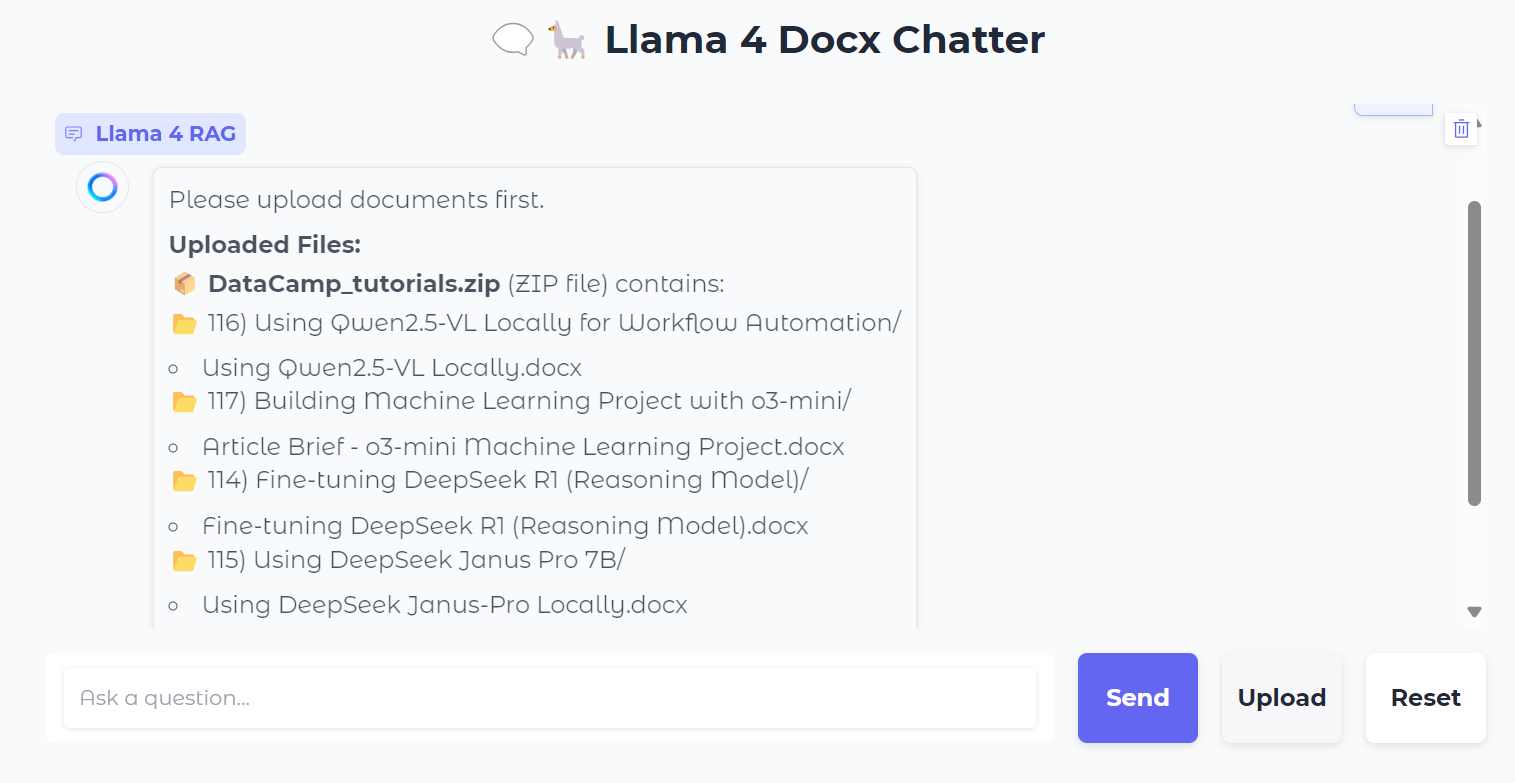
Wir laden eine .zip Datei hoch, die .docx Dateien enthält. Während wir das tun, siehst du alle Ordner und Dateien in der Zip-Datei.
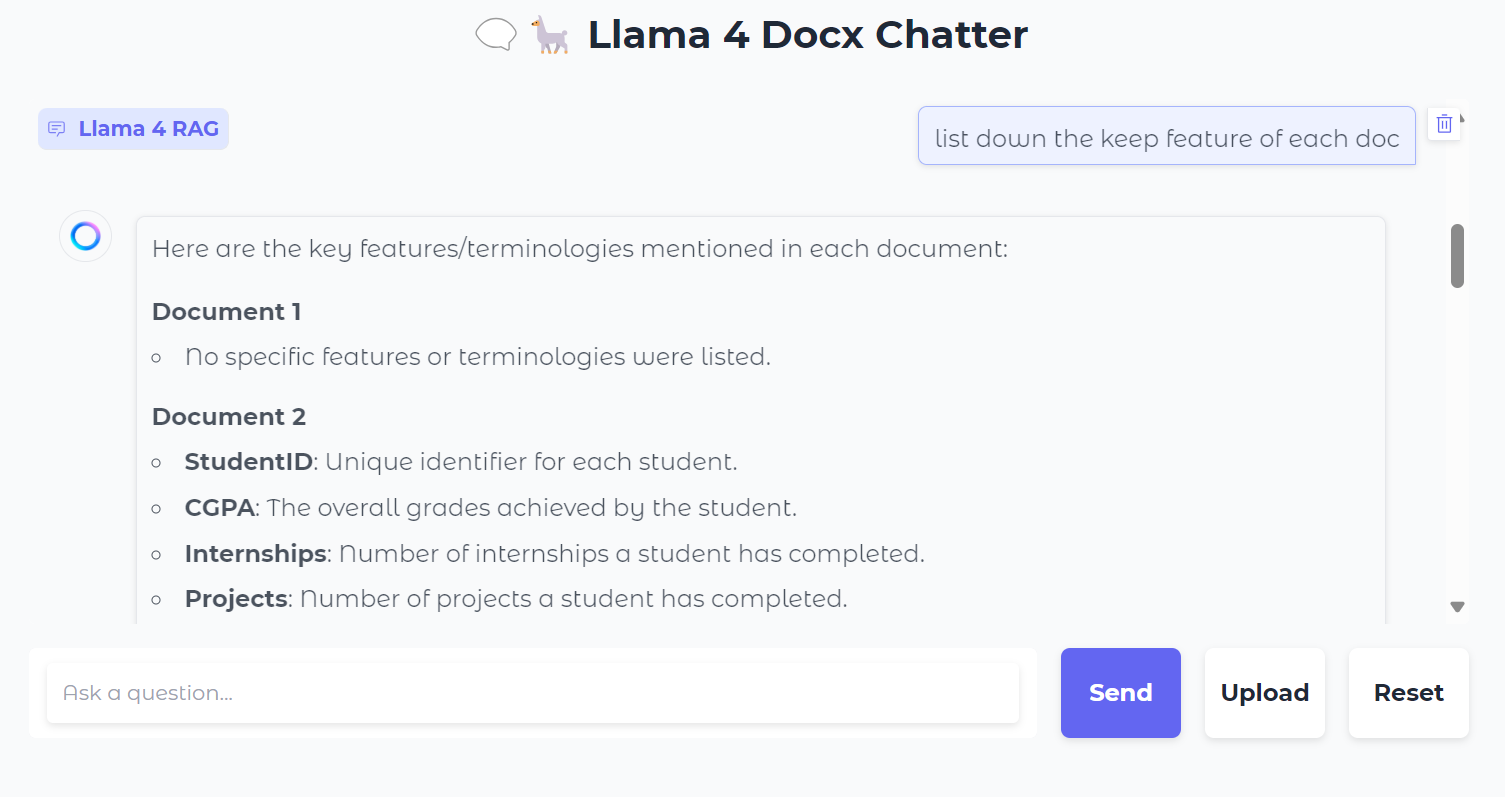
Als Nächstes können wir konkrete Fragen zu den Dokumenten stellen:
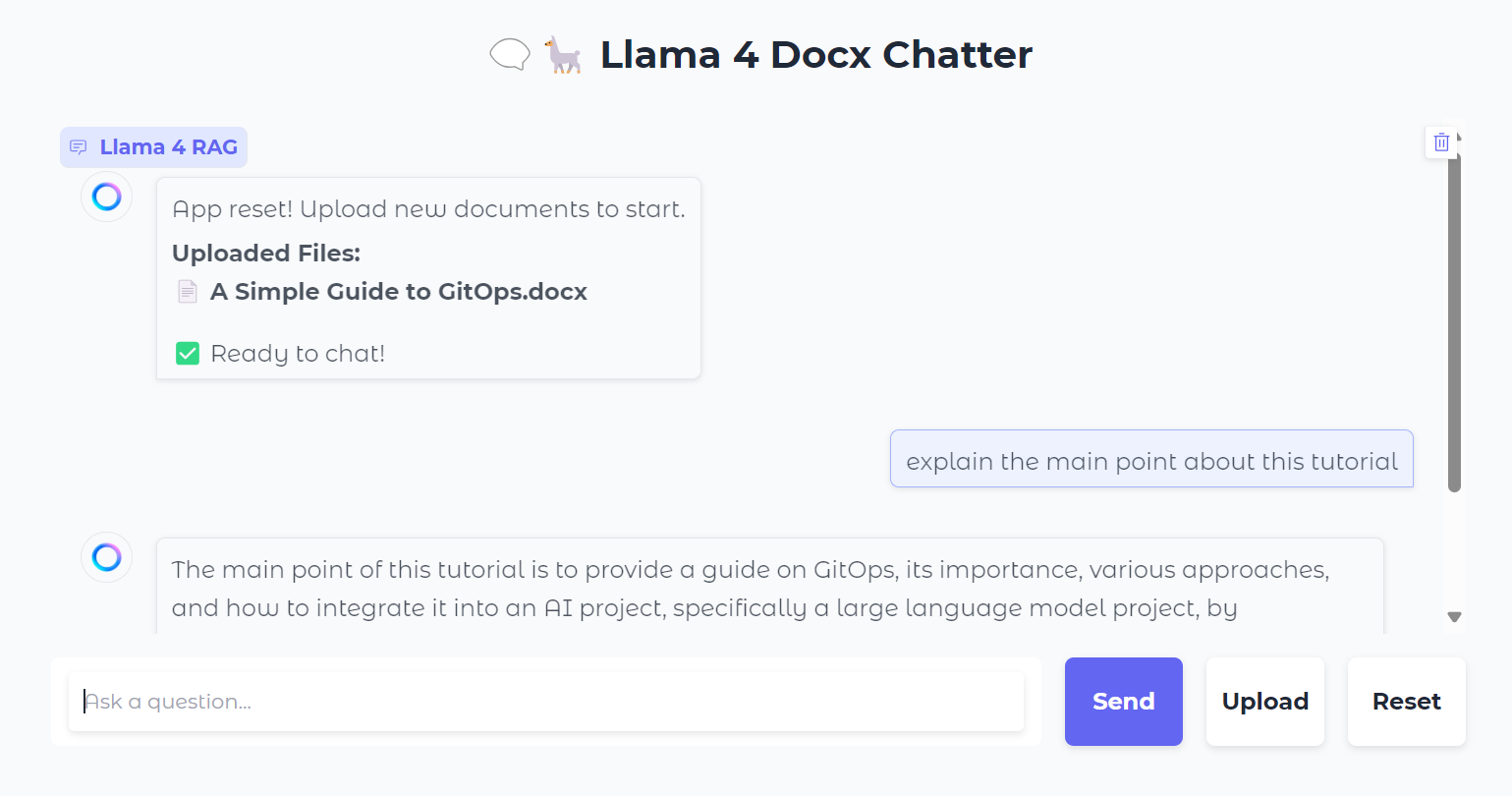
Du kannst auch die Schaltfläche "Zurücksetzen" drücken, um eine neue Datei hochzuladen und in wenigen Sekunden darüber zu chatten.
Nachdem du sie lokal getestet hast, kannst du die Webanwendung einfach und kostenlos auf Hugging Face Space bereitstellen. Hier ist der Link zur installierten App: kingabzpro/Llama-4-RAG
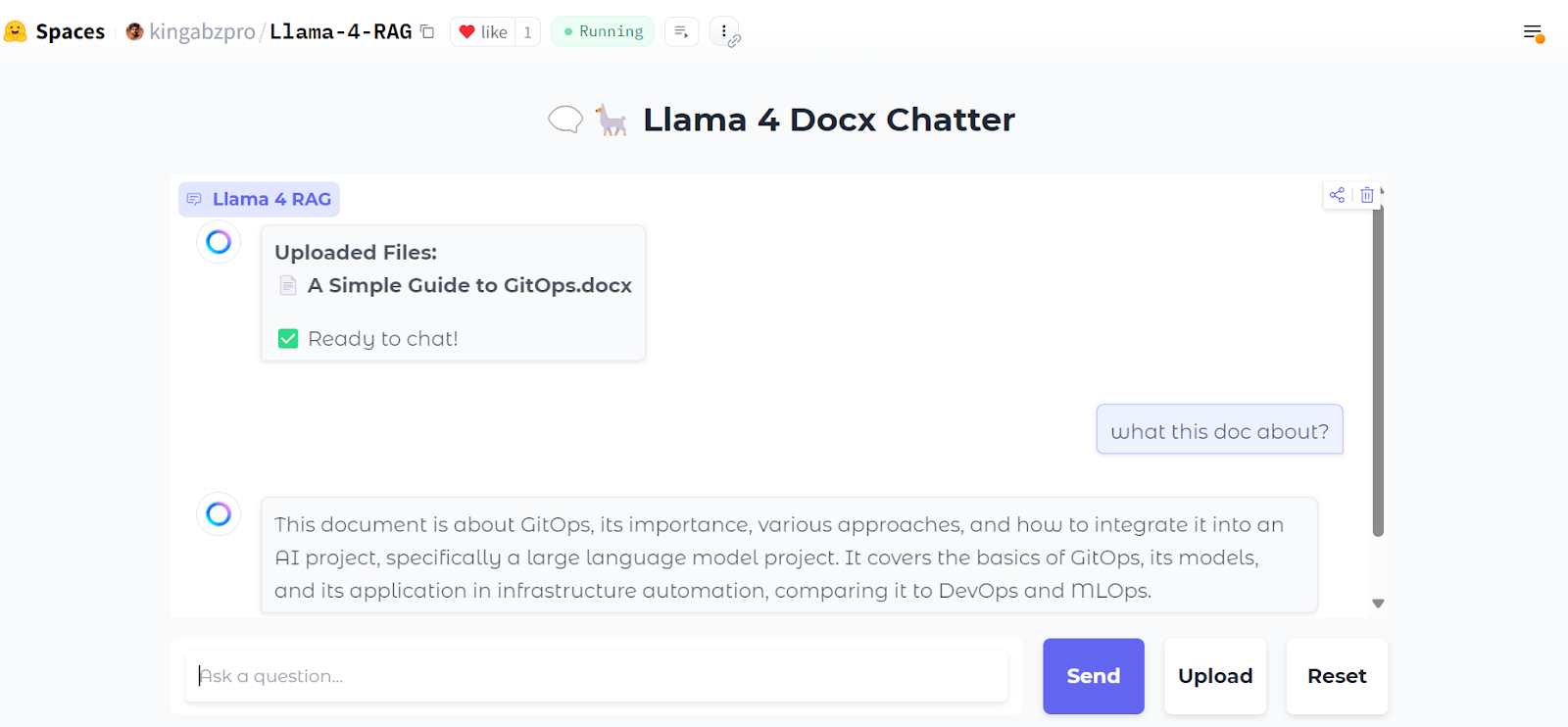
Quelle: kingabzpro/Llama-4-RAG
Der Quellcode, das Notizbuch und die Konfigurationsdateien befinden sich im Verzeichnis kingabzpro/Llama-4-RAG Repository.
Auch mit der Einführung von Fenstermodellen mit langem Kontext wird die RAG nie veraltet sein. RAG ist nach wie vor eine effiziente und kostengünstige Methode, um Informationen aus externen Ressourcen abzurufen und den Modellen zusätzlichen Kontext zu geben.
Außerdem sind RAG-Systeme von Natur aus wirtschaftlicher zu betreiben als die direkte Einspeisung von umfangreichem Kontext in ein Modell, was erhebliche Rechenressourcen erfordert. Das macht RAG zu einer praktischen und skalierbaren Lösung für viele Anwendungsfälle.
Um mehr über Llama 4 zu erfahren, schau dir diese Ressourcen an:
Lerne KI mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
