
Cursus
Les fondamentaux du lama
4 h
Llama 4 Scout est présenté comme ayant une fenêtre contextuelle massive de 10 millions de jetons, mais sa formation a été limitée à une taille d'entrée maximale de 256 000 jetons. Cela signifie que les performances peuvent se dégrader avec des entrées plus importantes. Pour éviter cela, nous pouvons utiliser Llama4 avec un pipeline de génération augmentée par récupération (RAG).
Dans ce tutoriel, je vais vous expliquer étape par étape comment construire un pipeline RAG en utilisant l'écosystème LangChain et créer une application web qui permet aux utilisateurs de télécharger des documents et de poser des questions à leur sujet.
Nous tenons nos lecteurs informés des dernières nouveautés en matière d'IA en leur envoyant The Median, notre lettre d'information gratuite du vendredi qui analyse les principaux sujets de la semaine. Abonnez-vous et restez à la pointe de la technologie en quelques minutes par semaine :
Le Llama 4 est doté d'une fenêtre contextuelle de 10 millions de jetons, ce qui signifie que nous pouvons lui donner 100 livres et recevoir des réponses contextuelles à leur sujet. Cependant, malgré cette caractéristique impressionnante, il y a des raisons impérieuses de coupler le Llama 4 avec le RAG. Voici pourquoi :
Bien que Llama 4 prenne en charge une fenêtre contextuelle massive, sa formation a été limitée à une taille d'entrée maximale de 256k toens. Les performances du modèle peuvent se dégrader lorsque les entrées approchent ou dépassent ce seuil. Le RAG atténue ce problème en ne récupérant que les informations les plus pertinentes, ce qui garantit que les données restent concises et ciblées.
RAG permet d'extraire des informations très pertinentes d'une base de données vectoriellesce qui permet au Llama 4 de traiter des données plus petites et plus ciblées. Cette approche améliore à la fois l'efficacité et la précision.
Le traitement d'entrées massives avec la fenêtre contextuelle complète de Llama 4 peut s'avérer coûteux en termes de calcul. En utilisant RAG, seules les données les plus pertinentes sont extraites et traitées, ce qui réduit considérablement la charge de calcul et les coûts associés.
Dans ce tutoriel, j'expliquerai étape par étape comment construire un simple pipeline de génération augmentée par récupération qui vous permet de charger un fichier .docx et de poser des questions sur son contenu.
Tout d'abord, nous devons créer un fichier GroqCloud et l'enregistrer en tant que variable d'environnement. Ensuite, nous installerons tous les paquets Python nécessaires au chargement, au fractionnement, à la vectorisation et à la récupération du contexte, ainsi qu'à la génération des réponses.
%%capture
%pip install langchain
%pip install langchain-community
%pip install langchainhub
%pip install langchain-chroma
%pip install langchain-groq
%pip install langchain-huggingface
%pip install unstructured[docx]Nous allons configurer l'objet modèle à l'aide de l'API Groq, en lui fournissant le nom du modèle et la clé API. De même, nous téléchargerons le modèle d'intégration de Hugging Face et le chargerons en tant que modèle d'intégration.
from langchain_groq import ChatGroq
from langchain_huggingface import HuggingFaceEmbeddings
llm = ChatGroq(model="meta-llama/llama-4-scout-17b-16e-instruct", api_key=groq_api_key)
embed_model = HuggingFaceEmbeddings(model_name="mixedbread-ai/mxbai-embed-large-v1")Nous chargerons le fichier .docx à partir du dossier racine et le découperons en morceaux de 1000 caractères.
from langchain_community.document_loaders import DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Initialize the text splitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=100,
separators=["\n\n", "\n"]
)
# Load the .docx files
loader = DirectoryLoader("./", glob="*.docx", use_multithreading=True)
documents = loader.load()
# Split the documents into chunks
chunks = text_splitter.split_documents(documents)
# Print the number of chunks
print(len(chunks))29Initialiser le magasin de vecteurs Chroma vector store et fournir les morceaux de texte à la base de données vectorielle. Le texte sera converti en embeddings avant d'être stocké. Ensuite, nous lancerons une recherche de similarité pour vérifier que notre magasin de vecteurs est correctement alimenté.
from langchain_chroma import Chroma
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=embed_model,
persist_directory="./Vectordb",
)
query = "What is this tutorial about?"
docs = vectorstore.similarity_search(query)
print(docs[0].page_content)Learn how to Fine-tune Stable Diffusion XL with DreamBooth and LoRA on your personal images.
Let's try another prompt:
Prompt:Ensuite, nous allons convertir notre magasin de vecteurs en un récupérateur et créer un modèle d'invite pour le pipeline RAG.
# Create retriever
retriever = vectorstore.as_retriever()
# Import PromptTemplate
from langchain_core.prompts import PromptTemplate
# Define a clearer, more professional prompt template
template = """You are an expert assistant tasked with answering questions based on the provided documents.
Use only the given context to generate your answer.
If the answer cannot be found in the context, clearly state that you do not know.
Be detailed and precise in your response, but avoid mentioning or referencing the context itself.
Context:
{context}
Question:
{question}
Answer:"""
# Create the PromptTemplate
rag_prompt = PromptTemplate.from_template(template)Enfin, nous créerons la chaîne RAG qui fournit à la fois le contexte et la question dans l'invite RAG, nous la ferons passer par le modèle Llama 4, puis nous générerons une réponse propre.
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| rag_prompt
| llm
| StrOutputParser()
)Nous allons maintenant demander à la chaîne RAG ce qu'elle pense du document.
from IPython.display import display, Markdown
response = rag_chain.invoke("What this tutorial about?")
Markdown(response)This tutorial is about setting up and using the Janus project, specifically Janus Pro, a multimodal model that can understand images and generate images from text prompts, and building a local solution to use the model privately on a laptop GPU. It covers learning about the Janus Series, setting up the Janus project, building a Docker container to run the model locally, and testing its capabilities with various image and text prompts.Comme vous pouvez le constater, la réponse est très précise et tient compte du contexte. Si vous rencontrez des problèmes lors de l'exécution du code ci-dessus, veuillez vous référer à ce classeur DataLab : Llama 4 RAG pipeline.
Dans cette section, nous allons transformer le code du pipeline RAG discuté précédemment en une application de chat fonctionnelle à l'aide du paquet Gradio. Pour commencer, vous devez installer Gradio à l'aide de la commande suivante : pip:
$ pip install gradioL'application est conçue pour être simple et conviviale, permettant aux utilisateurs de télécharger un seul fichier .docx, plusieurs fichiers .docx ou une archive .zip contenant des fichiers .docx. Les utilisateurs peuvent ensuite poser des questions sur le contenu de tous les fichiers téléchargés, ce qui constitue un moyen rapide et efficace d'obtenir des informations.
L'application présente les caractéristiques suivantes
Mettons tout cela bout à bout :
main.py:
# ========== Standard Library ==========
import os
import tempfile
import zipfile
from typing import List, Optional, Tuple, Union
import collections
# ========== Third-Party Libraries ==========
import gradio as gr
from groq import Groq
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import DirectoryLoader, UnstructuredFileLoader
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_groq import ChatGroq
from langchain_huggingface import HuggingFaceEmbeddings
# ========== Configs ==========
TITLE = """<h1 align="center">🗨️🦙 Llama 4 Docx Chatter</h1>"""
AVATAR_IMAGES = (
None,
"./logo.png",
)
# Acceptable file extensions
TEXT_EXTENSIONS = [".docx", ".zip"]
# ========== Models & Clients ==========
GROQ_API_KEY = os.getenv("GROQ_API_KEY")
client = Groq(api_key=GROQ_API_KEY)
llm = ChatGroq(model="meta-llama/llama-4-scout-17b-16e-instruct", api_key=GROQ_API_KEY)
embed_model = HuggingFaceEmbeddings(model_name="mixedbread-ai/mxbai-embed-large-v1")
# ========== Core Components ==========
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=100,
separators=["\n\n", "\n"],
)
rag_template = """You are an expert assistant tasked with answering questions based on the provided documents.
Use only the given context to generate your answer.
If the answer cannot be found in the context, clearly state that you do not know.
Be detailed and precise in your response, but avoid mentioning or referencing the context itself.
Context:
{context}
Question:
{question}
Answer:"""
rag_prompt = PromptTemplate.from_template(rag_template)
# ========== App State ==========
class AppState:
vectorstore: Optional[InMemoryVectorStore] = None
rag_chain = None
state = AppState()
# ========== Utility Functions ==========
def load_documents_from_files(files: List[str]) -> List:
"""Load documents from uploaded files directly without moving."""
all_documents = []
# Temporary directory if ZIP needs extraction
with tempfile.TemporaryDirectory() as temp_dir:
for file_path in files:
ext = os.path.splitext(file_path)[1].lower()
if ext == ".zip":
# Extract ZIP inside temp_dir
with zipfile.ZipFile(file_path, "r") as zip_ref:
zip_ref.extractall(temp_dir)
# Load all docx from extracted zip
loader = DirectoryLoader(
path=temp_dir,
glob="**/*.docx",
use_multithreading=True,
)
docs = loader.load()
all_documents.extend(docs)
elif ext == ".docx":
# Load single docx directly
loader = UnstructuredFileLoader(file_path)
docs = loader.load()
all_documents.extend(docs)
return all_documents
def get_last_user_message(chatbot: List[Union[gr.ChatMessage, dict]]) -> Optional[str]:
"""Get last user prompt."""
for message in reversed(chatbot):
content = (
message.get("content") if isinstance(message, dict) else message.content
)
if (
message.get("role") if isinstance(message, dict) else message.role
) == "user":
return content
return None
# ========== Main Logic ==========
def upload_files(
files: Optional[List[str]], chatbot: List[Union[gr.ChatMessage, dict]]
):
"""Handle file upload - .docx or .zip containing docx."""
if not files:
return chatbot
file_summaries = [] # <-- Collect formatted file/folder info
documents = []
with tempfile.TemporaryDirectory() as temp_dir:
for file_path in files:
filename = os.path.basename(file_path)
ext = os.path.splitext(file_path)[1].lower()
if ext == ".zip":
file_summaries.append(f"📦 **{filename}** (ZIP file) contains:")
try:
with zipfile.ZipFile(file_path, "r") as zip_ref:
zip_ref.extractall(temp_dir)
zip_contents = zip_ref.namelist()
# Group files by folder
folder_map = collections.defaultdict(list)
for item in zip_contents:
if item.endswith("/"):
continue # skip folder entries themselves
folder = os.path.dirname(item)
file_name = os.path.basename(item)
folder_map[folder].append(file_name)
# Format nicely
for folder, files_in_folder in folder_map.items():
if folder:
file_summaries.append(f"📂 {folder}/")
else:
file_summaries.append(f"📄 (root)")
for f in files_in_folder:
file_summaries.append(f" - {f}")
# Load docx files extracted from ZIP
loader = DirectoryLoader(
path=temp_dir,
glob="**/*.docx",
use_multithreading=True,
)
docs = loader.load()
documents.extend(docs)
except zipfile.BadZipFile:
chatbot.append(
gr.ChatMessage(
role="assistant",
content=f"❌ Failed to open ZIP file: {filename}",
)
)
elif ext == ".docx":
file_summaries.append(f"📄 **{filename}**")
loader = UnstructuredFileLoader(file_path)
docs = loader.load()
documents.extend(docs)
else:
file_summaries.append(f"❌ Unsupported file type: {filename}")
if not documents:
chatbot.append(
gr.ChatMessage(
role="assistant", content="No valid .docx files found in upload."
)
)
return chatbot
# Split documents
chunks = text_splitter.split_documents(documents)
if not chunks:
chatbot.append(
gr.ChatMessage(
role="assistant", content="Failed to split documents into chunks."
)
)
return chatbot
# Create Vectorstore
state.vectorstore = InMemoryVectorStore.from_documents(
documents=chunks,
embedding=embed_model,
)
retriever = state.vectorstore.as_retriever()
# Build RAG Chain
state.rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| rag_prompt
| llm
| StrOutputParser()
)
# Final display
chatbot.append(
gr.ChatMessage(
role="assistant",
content="**Uploaded Files:**\n"
+ "\n".join(file_summaries)
+ "\n\n✅ Ready to chat!",
)
)
return chatbot
def user_message(
text_prompt: str, chatbot: List[Union[gr.ChatMessage, dict]]
) -> Tuple[str, List[Union[gr.ChatMessage, dict]]]:
"""Add user's text input to conversation."""
if text_prompt.strip():
chatbot.append(gr.ChatMessage(role="user", content=text_prompt))
return "", chatbot
def process_query(
chatbot: List[Union[gr.ChatMessage, dict]],
) -> List[Union[gr.ChatMessage, dict]]:
"""Process user's query through RAG pipeline."""
prompt = get_last_user_message(chatbot)
if not prompt:
chatbot.append(
gr.ChatMessage(role="assistant", content="Please type a question first.")
)
return chatbot
if state.rag_chain is None:
chatbot.append(
gr.ChatMessage(role="assistant", content="Please upload documents first.")
)
return chatbot
chatbot.append(gr.ChatMessage(role="assistant", content="Thinking..."))
try:
response = state.rag_chain.invoke(prompt)
chatbot[-1].content = response
except Exception as e:
chatbot[-1].content = f"Error: {str(e)}"
return chatbot
def reset_app(
chatbot: List[Union[gr.ChatMessage, dict]],
) -> List[Union[gr.ChatMessage, dict]]:
"""Reset application state."""
state.vectorstore = None
state.rag_chain = None
return [
gr.ChatMessage(
role="assistant", content="App reset! Upload new documents to start."
)
]
# ========== UI Layout ==========
with gr.Blocks(theme=gr.themes.Soft()) as demo:
gr.HTML(TITLE)
chatbot = gr.Chatbot(
label="Llama 4 RAG",
type="messages",
bubble_full_width=False,
avatar_images=AVATAR_IMAGES,
scale=2,
height=350,
)
with gr.Row(equal_height=True):
text_prompt = gr.Textbox(
placeholder="Ask a question...", show_label=False, autofocus=True, scale=28
)
send_button = gr.Button(
value="Send",
variant="primary",
scale=1,
min_width=80,
)
upload_button = gr.UploadButton(
label="Upload",
file_count="multiple",
file_types=TEXT_EXTENSIONS,
scale=1,
min_width=80,
)
reset_button = gr.Button(
value="Reset",
variant="stop",
scale=1,
min_width=80,
)
send_button.click(
fn=user_message,
inputs=[text_prompt, chatbot],
outputs=[text_prompt, chatbot],
queue=False,
).then(fn=process_query, inputs=[chatbot], outputs=[chatbot])
text_prompt.submit(
fn=user_message,
inputs=[text_prompt, chatbot],
outputs=[text_prompt, chatbot],
queue=False,
).then(fn=process_query, inputs=[chatbot], outputs=[chatbot])
upload_button.upload(
fn=upload_files, inputs=[upload_button, chatbot], outputs=[chatbot], queue=False
)
reset_button.click(fn=reset_app, inputs=[chatbot], outputs=[chatbot], queue=False)
demo.queue().launch()Nous allons maintenant exécuter l'application web et tester ses fonctionnalités. Pour démarrer l'application, exécutez la commande suivante dans le terminal :
$ python main.py Une fois que le serveur web est opérationnel, accédez à l'URL suivante ou copiez et collez-la manuellement dans votre navigateur pour accéder à l'interface web : http://127.0.0.1:7860
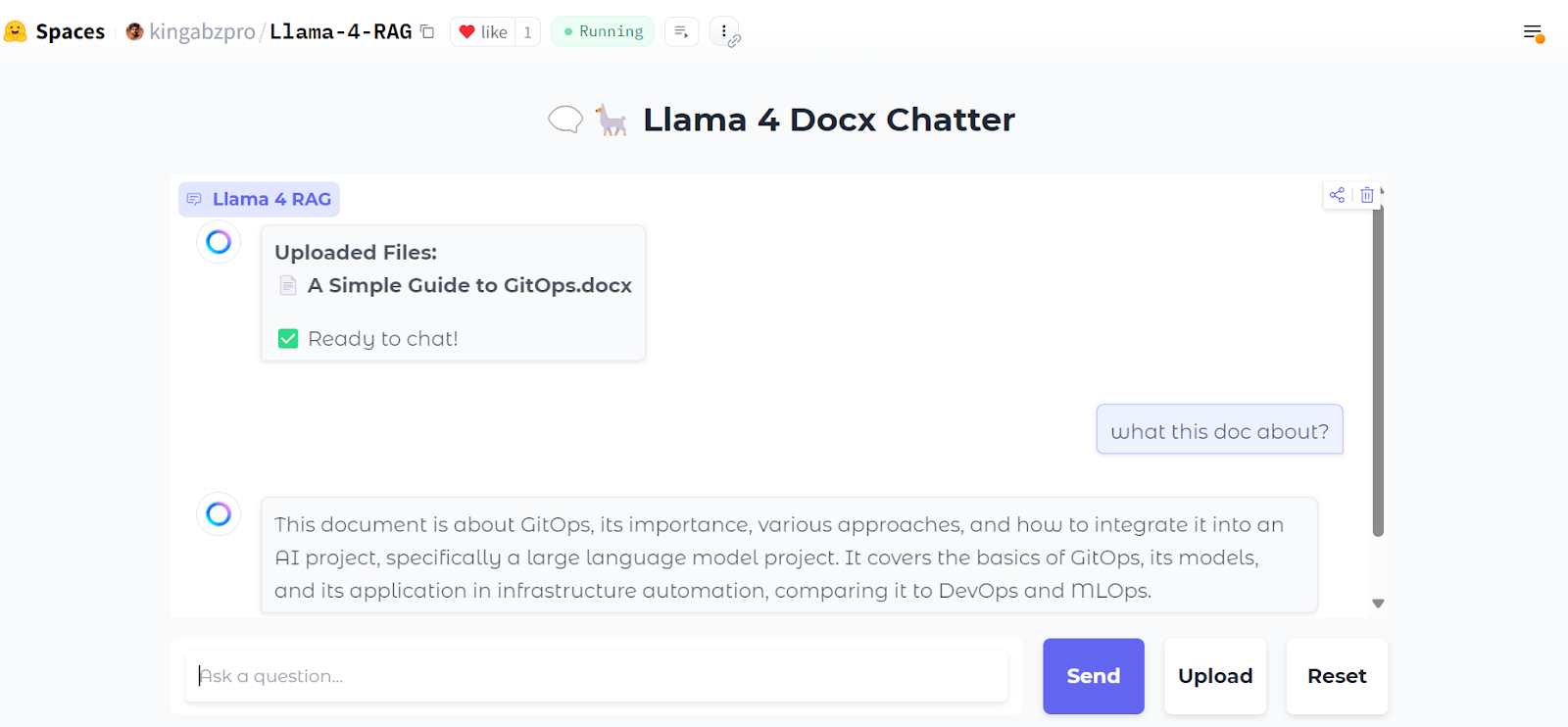
Voici à quoi ressemble notre interface de chat :
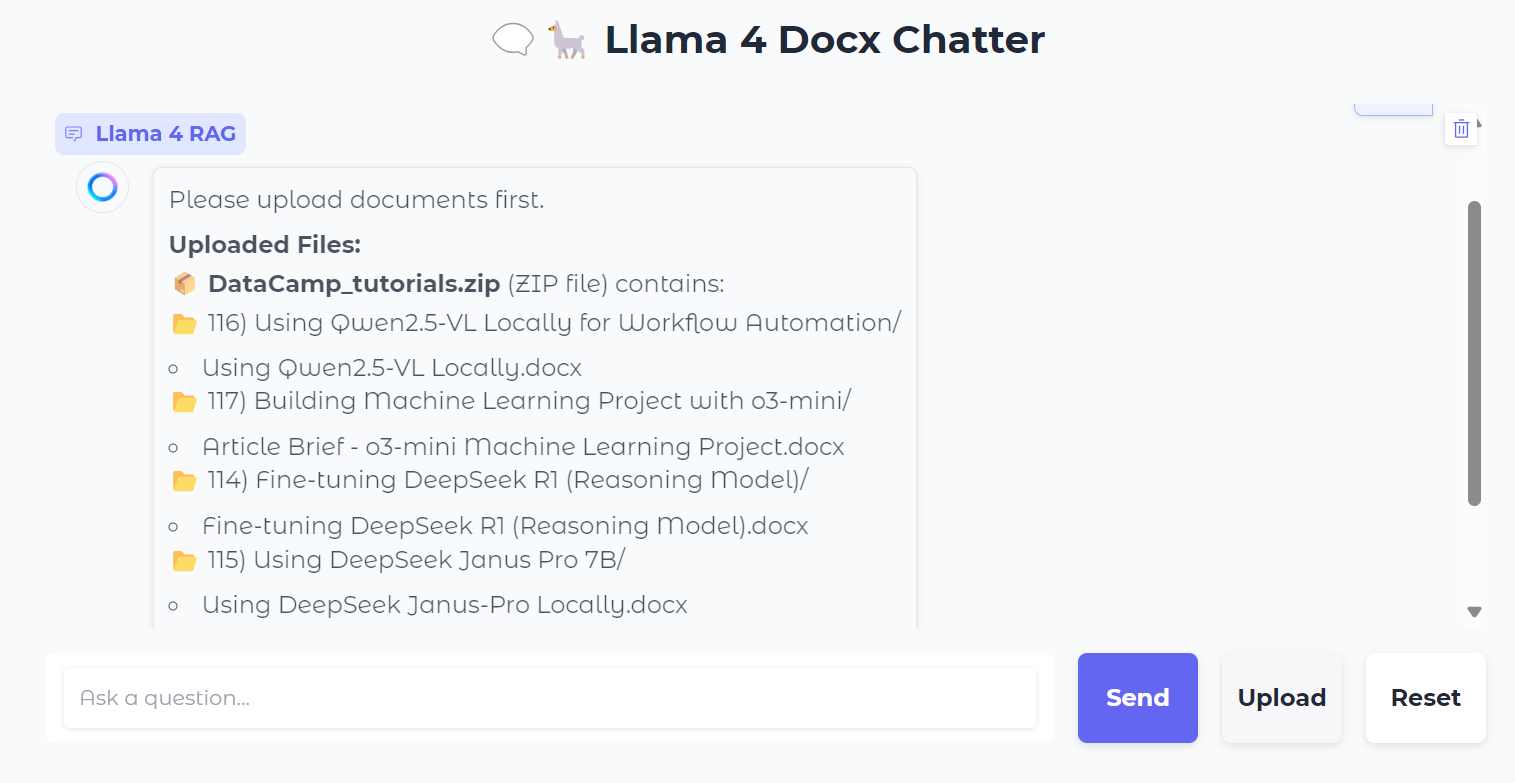
Nous allons télécharger un fichier .zip contenant des fichiers .docx, et vous verrez alors tous les dossiers et fichiers contenus dans le fichier zip.
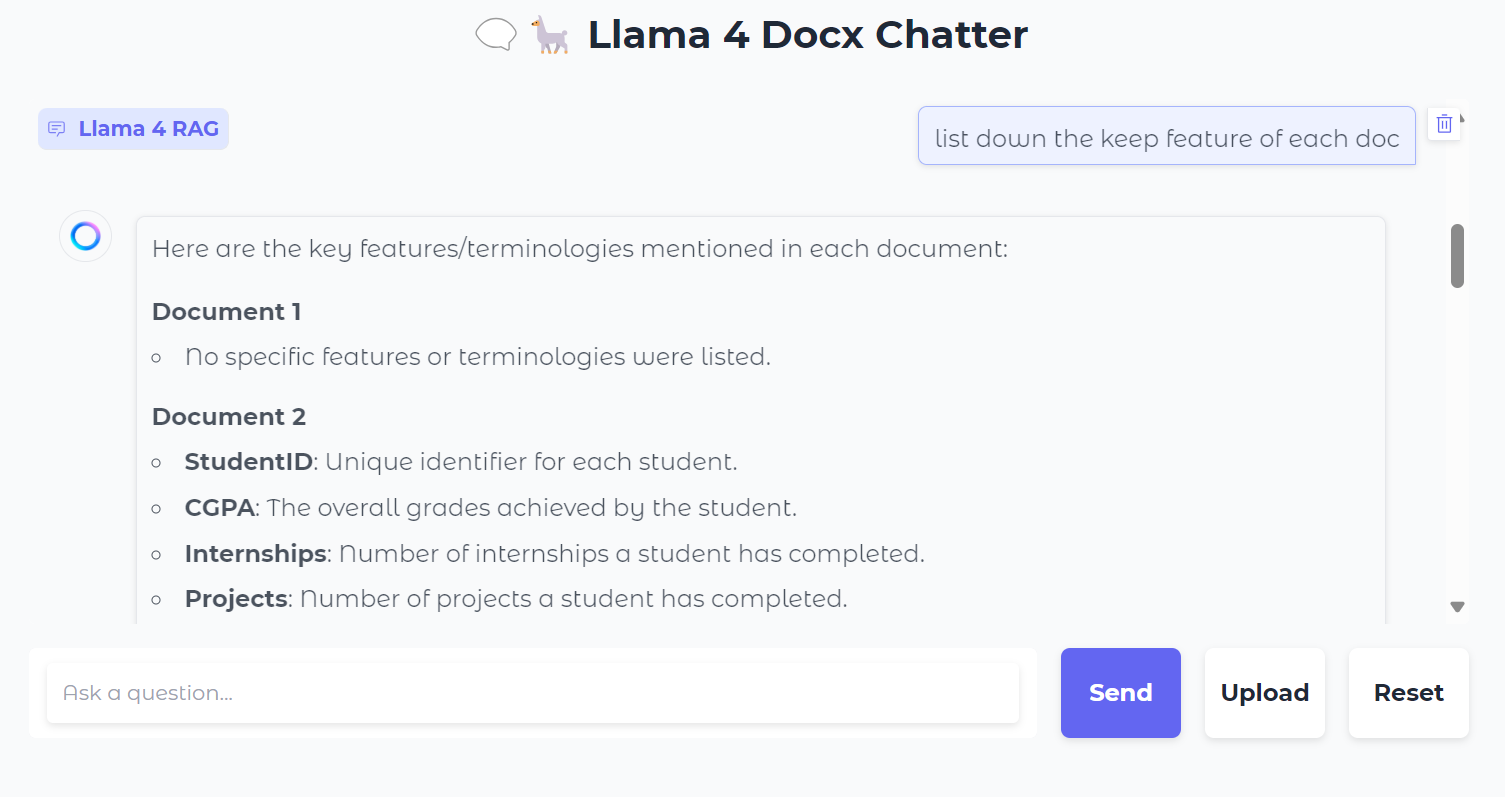
Ensuite, nous pouvons poser des questions spécifiques sur les documents :
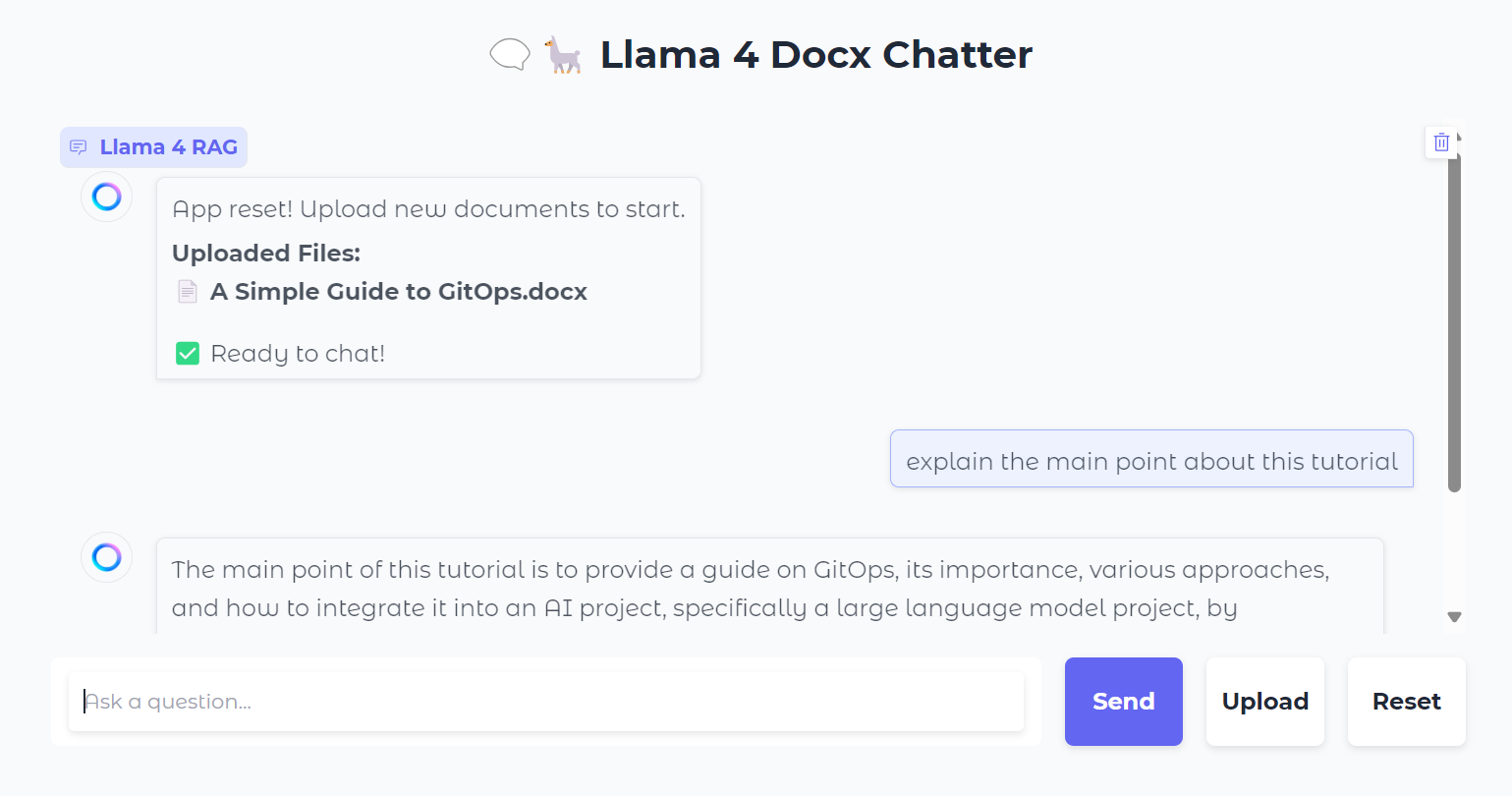
Vous pouvez également appuyer sur le bouton "Réinitialiser" pour télécharger un nouveau fichier et en discuter en quelques secondes.
Après l'avoir testée localement, vous pouvez facilement déployer l'application web sur Hugging Face gratuitement. Voici le lien vers l'application déployée : kingabzpro/Llama-4-RAG
Source : kingabzpro/Llama-4-RAG
Le code source, le carnet de notes et les fichiers de configuration se trouvent dans le répertoire kingabzpro/Llama-4-RAG dans le dépôt Kingabzpro/Llama-4-RAG.
Même avec l'introduction de modèles de fenêtres à contexte long, RAG ne deviendra jamais obsolète. Le RAG reste une méthode efficace et rentable pour récupérer des informations à partir de ressources externes, en fournissant un contexte supplémentaire aux modèles.
En outre, les systèmes RAG sont intrinsèquement plus économiques à exploiter que l'introduction directe d'un contexte étendu dans un modèle, qui nécessite d'importantes ressources informatiques. Cela fait de RAG une solution pratique et évolutive pour de nombreux cas d'utilisation.
Pour en savoir plus sur le lama 4, consultez les ressources suivantes :
Apprenez l'IA avec ces cours !
Cursus
Cours
Cours