
Lernpfad
Grundlagen der KI
10 Std.
Meta hat eine neue Serie von großen Sprachmodellen (LLMs) mit dem Namen Llama 3 herausgebracht, eine Sammlung von vortrainierten und auf Anweisungen abgestimmten Text-zu-Text-Modellen.
Llama 3 ist ein autoregressives Sprachmodell, das eine optimierte Transformer-Architektur verwendet. Sowohl die vortrainierten als auch die instruktionsabgestimmten Modelle haben 8B und 70B Parameter mit einer Kontextlänge von 8K Token.
Llama 3 8B ist das beliebteste LLM auf Hugging Face. Seine anweisungsabgestimmte Version ist bei verschiedenen Leistungskennzahlen besser als Googles Gemma 7B-It und Mistral 7B Instruct. Die auf die 70B-Befehle abgestimmte Version hat Gemini Pro 1.5 und Claude Sonnet bei den meisten Leistungskennzahlen übertroffen:
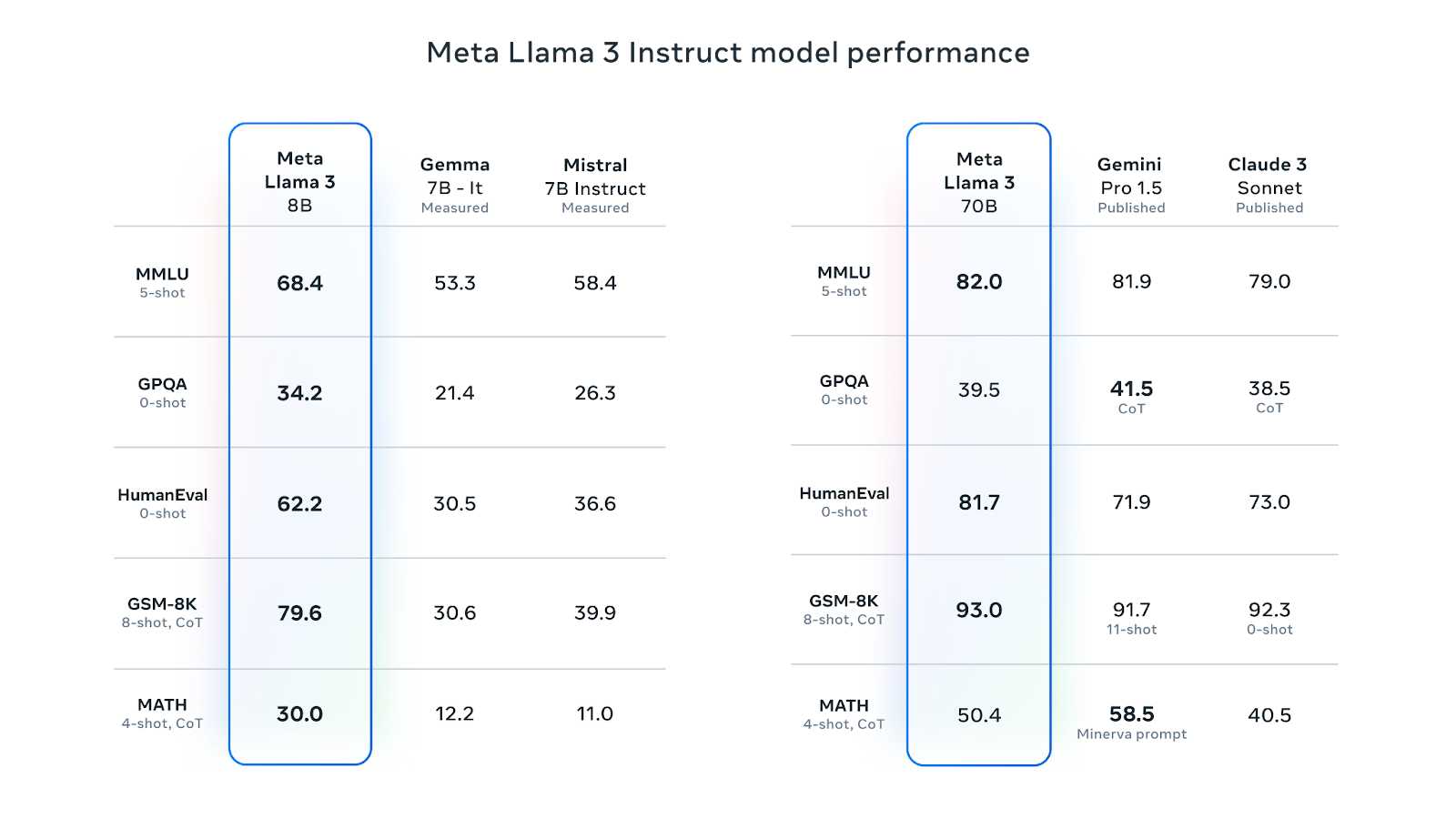
Quelle: Meta Llama 3
Meta hat Llama 3 mit einer neuen Mischung aus öffentlich verfügbaren Online-Daten trainiert, die über 15 Billionen Token umfassen. Das 8B-Modell hat eine Wissensgrenze von März 2023, während das 70B-Modell eine Grenze von Dezember 2023 hat. Die Modelle verwenden Grouped-Query Attention (GQA), was die Speicherbandbreite reduziert und die Effizienz verbessert.
Die Llama 3-Modelle wurden unter einer eigenen kommerziellen Lizenz veröffentlicht. Um auf das Modell zugreifen zu können, musst du das Formular mit deinem Namen, deiner Zugehörigkeit und deiner E-Mail-Adresse ausfüllen und die Allgemeinen Geschäftsbedingungen akzeptieren. Wenn du verschiedene E-Mail-Adressen für verschiedene Plattformen wie Kaggle und Hugging Face verwendest, musst du das Formular möglicherweise mehrmals ausfüllen.
Mehr über Llama 3 erfährst du in diesem Artikel über Was ist Llama 3?
In diesem Tutorial werden wir das Llama 3 8B-Chat-Modell anhand des ruslanmv/ai-medical-chatbot-Datensatzes feinabstimmen. Der Datensatz enthält 250k Dialoge zwischen einem Patienten und einem Arzt. Wir werden das Kaggle Notebook nutzen, um auf dieses Modell und freie GPUs zuzugreifen.
Bevor wir das Kaggle-Notebook starten, füllst du das Meta-Download-Formular mit deiner Kaggle-E-Mail-Adresse aus, gehst dann auf die Llama 3-Modellseite auf Kaggle und akzeptierst die Vereinbarung. Das Genehmigungsverfahren kann ein bis zwei Tage dauern.
Lass uns nun die folgenden Schritte unternehmen:
1. Starte das neue Notizbuch auf Kaggle und füge das Llama 3-Modell hinzu, indem du auf die Schaltfläche + Eingabe hinzufügen klickst, die Option Modelle auswählst und auf das Pluszeichen + neben dem Llama 3-Modell klickst. Danach wählst du das richtige Framework, die richtige Variante und Version aus und fügst das Modell hinzu.
2. Gehe zu den Sitzungsoptionen und wähle die GPU P100 als Beschleuniger aus.
3. Erzeuge die Token "Hugging Face" und "Weights & Biases" und erstelle die Kaggle Secrets. Du kannst die Kaggle-Geheimnisse erstellen und aktivieren, indem du zu Add-ons > Geheimnisse > Neues Geheimnis hinzufügen gehst.
4. Initiiere die Kaggle-Sitzung, indem du alle notwendigen Python-Pakete installierst.
%%capture
%pip install -U transformers
%pip install -U datasets
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes
%pip install -U wandb5. Importiere die notwendigen Python-Seiten, um den Datensatz, das Modell und den Tokenizer zu laden und die Feinabstimmung vorzunehmen.
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
HfArgumentParser,
TrainingArguments,
pipeline,
logging,
)
from peft import (
LoraConfig,
PeftModel,
prepare_model_for_kbit_training,
get_peft_model,
)
import os, torch, wandb
from datasets import load_dataset
from trl import SFTTrainer, setup_chat_format6. Wir werden den Trainingsprozess mit Hilfe von Weights & Biases nachverfolgen und dann das fein abgestimmte Modell auf Hugging Face speichern. Dafür müssen wir uns sowohl beim Hugging Face Hub als auch bei Weights & Biases mit dem API-Schlüssel anmelden.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)
wb_token = user_secrets.get_secret("wandb")
wandb.login(key=wb_token)
run = wandb.init(
project='Fine-tune Llama 3 8B on Medical Dataset',
job_type="training",
anonymous="allow"
)7. Lege das Basismodell, den Datensatz und die neue Modellvariable fest. Wir laden das Basismodell von Kaggle und den Datensatz aus dem HugginFace Hub und speichern dann das neue Modell.
base_model = "/kaggle/input/llama-3/transformers/8b-chat-hf/1"
dataset_name = "ruslanmv/ai-medical-chatbot"
new_model = "llama-3-8b-chat-doctor"8. Lege den Datentyp und die Aufmerksamkeitsimplementierung fest.
torch_dtype = torch.float16
attn_implementation = "eager"In diesem Teil laden wir das Modell von Kaggle. Aufgrund von Speicherplatzproblemen können wir jedoch nicht das gesamte Modell laden. Deshalb laden wir das Modell mit einer Genauigkeit von 4 Bit.
Unser Ziel in diesem Projekt ist es, den Speicherverbrauch zu reduzieren und den Feinabstimmungsprozess zu beschleunigen.
# QLoRA config
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch_dtype,
bnb_4bit_use_double_quant=True,
)
# Load model
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=bnb_config,
device_map="auto",
attn_implementation=attn_implementation
)Lade den Tokenizer und richte dann ein Modell und einen Tokenizer für Konversations-KI-Aufgaben ein. Standardmäßig wird die Vorlage chatml von OpenAI verwendet, die den eingegebenen Text in ein chatähnliches Format umwandelt.
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(base_model)
model, tokenizer = setup_chat_format(model, tokenizer)Die Feinabstimmung des gesamten Modells nimmt viel Zeit in Anspruch. Um die Trainingszeit zu verkürzen, fügen wir der Adapterschicht ein paar Parameter hinzu, damit der gesamte Prozess schneller und speichereffizienter wird.
# LoRA config
peft_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules=['up_proj', 'down_proj', 'gate_proj', 'k_proj', 'q_proj', 'v_proj', 'o_proj']
)
model = get_peft_model(model, peft_config)Um unseren Datensatz zu laden und vorzuverarbeiten, müssen wir:
1. Lade den Datensatz ruslanmv/ai-medical-chatbot, mische ihn und wähle nur die obersten 1000 Zeilen aus. Dadurch wird die Ausbildungszeit erheblich verkürzt.
2. Formatiere die Chatvorlage so, dass sie unterhaltsam ist. Kombiniere die Patientenfragen und die Antworten des Arztes in einer "Text"-Spalte.
3. Zeige ein Beispiel aus der Textspalte an (die Spalte "Text" hat ein Chat-ähnliches Format mit speziellen Token).
#Importing the dataset
dataset = load_dataset(dataset_name, split="all")
dataset = dataset.shuffle(seed=65).select(range(1000)) # Only use 1000 samples for quick demo
def format_chat_template(row):
row_json = [{"role": "user", "content": row["Patient"]},
{"role": "assistant", "content": row["Doctor"]}]
row["text"] = tokenizer.apply_chat_template(row_json, tokenize=False)
return row
dataset = dataset.map(
format_chat_template,
num_proc=4,
)
dataset['text'][3]
4. Teile den Datensatz in einen Trainings- und einen Validierungssatz auf.
dataset = dataset.train_test_split(test_size=0.1)Wir legen die Hyperparameter des Modells fest, damit wir es bei Kaggle einsetzen können. Du kannst mehr über die einzelnen Hyperparameter erfahren, indem du das Fine-Tuning Llama 2-Tutorial liest.
Wir führen eine Feinabstimmung des Modells für eine Epoche durch und protokollieren die Metriken mithilfe der Gewichte und Verzerrungen.
training_arguments = TrainingArguments(
output_dir=new_model,
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=2,
optim="paged_adamw_32bit",
num_train_epochs=1,
evaluation_strategy="steps",
eval_steps=0.2,
logging_steps=1,
warmup_steps=10,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
report_to="wandb"
)Wir richten nun einen SFT-Trainer ein und stellen einen Trainings- und Evaluierungsdatensatz, eine LoRA-Konfiguration, ein Trainingsargument, einen Tokenizer und ein Modell bereit. Wir halten die max_seq_length auf 512, um den GPU-Speicher während des Trainings nicht zu überlasten.
trainer = SFTTrainer(
model=model,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
peft_config=peft_config,
max_seq_length=512,
dataset_text_field="text",
tokenizer=tokenizer,
args=training_arguments,
packing= False,
)Wir beginnen die Feinabstimmung, indem wir den folgenden Code ausführen.
trainer.train()Sowohl die Trainings- als auch die Validierungsverluste sind zurückgegangen. Um bessere Ergebnisse zu erzielen, solltest du das Modell drei Epochen lang mit dem gesamten Datensatz trainieren.
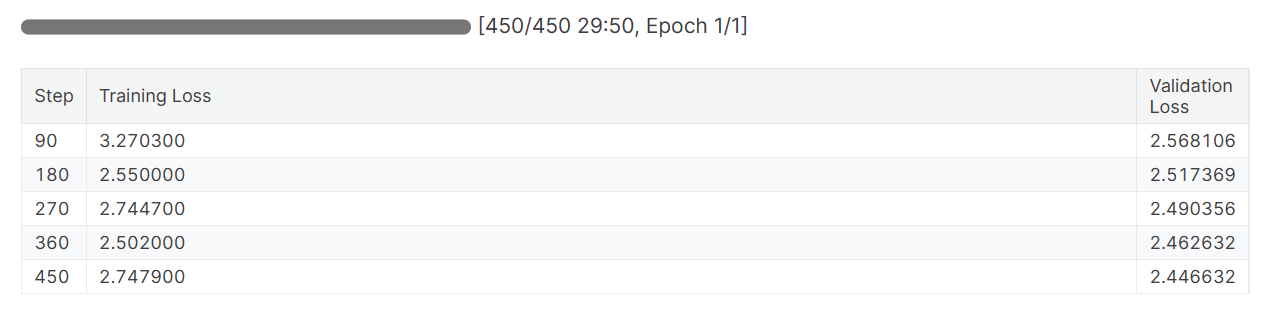
Wenn du die Sitzung "Gewichte & Verzerrungen" beendest, werden der Laufverlauf und die Zusammenfassung erstellt.
wandb.finish()
model.config.use_cache = True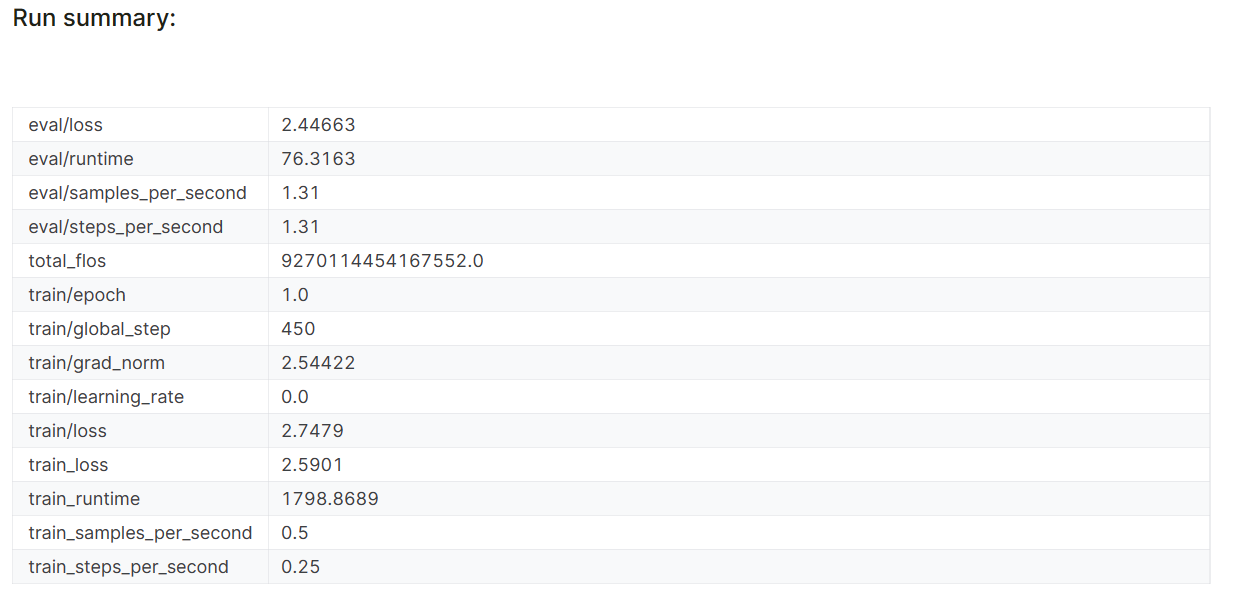
Die Leistungskennzahlen des Modells werden auch unter dem spezifischen Projektnamen in deinem Weights & Biases-Konto gespeichert.
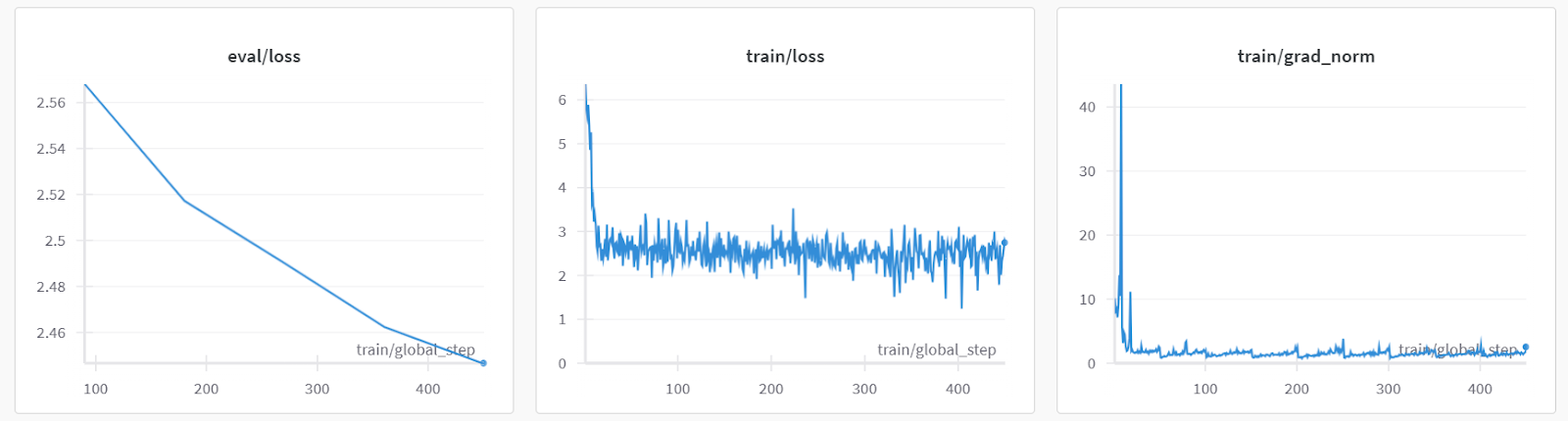
Lass uns das Modell an einer Beispiel-Patientenabfrage testen, um zu sehen, ob es richtig abgestimmt ist.
Um eine Antwort zu generieren, müssen wir Nachrichten in das Chat-Format umwandeln, sie durch den Tokenizer leiten, das Ergebnis in das Modell eingeben und dann das generierte Token dekodieren, um den Text anzuzeigen.
messages = [
{
"role": "user",
"content": "Hello doctor, I have bad acne. How do I get rid of it?"
}
]
prompt = tokenizer.apply_chat_template(messages, tokenize=False,
add_generation_prompt=True)
inputs = tokenizer(prompt, return_tensors='pt', padding=True,
truncation=True).to("cuda")
outputs = model.generate(**inputs, max_length=150,
num_return_sequences=1)
text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(text.split("assistant")[1])
Es zeigt sich, dass wir auch mit einer Epoche durchschnittliche Ergebnisse erzielen können.
Jetzt speichern wir den feinabgestimmten Adapter und schieben ihn zum Hugging Face Hub. Die Hub API erstellt automatisch das Repository und speichert die Adapterdatei.
trainer.model.save_pretrained(new_model)
trainer.model.push_to_hub(new_model, use_temp_dir=False)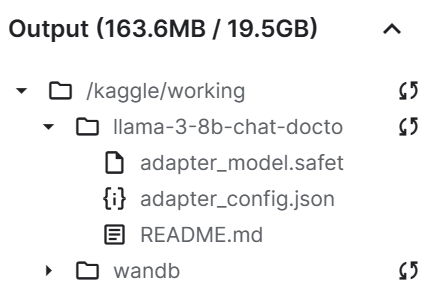
Wie wir sehen können, ist unsere Adapterdatei deutlich kleiner als das Basismodell.
Am Ende speichern wir das Notebook mit der Adapterdatei, um es mit dem Basismodell im neuen Notebook zusammenzuführen.
Um das Kaggle-Notizbuch zu speichern, klickst du oben rechts auf die Schaltfläche Version speichern, wählst als Versionstyp Schnellspeicherung aus , öffnest die erweiterten Einstellungen, wählst bei der Erstellung einer Schnellspeicherung die Option Ausgabe immer speichern und drückst dann die Schaltfläche Speichern.
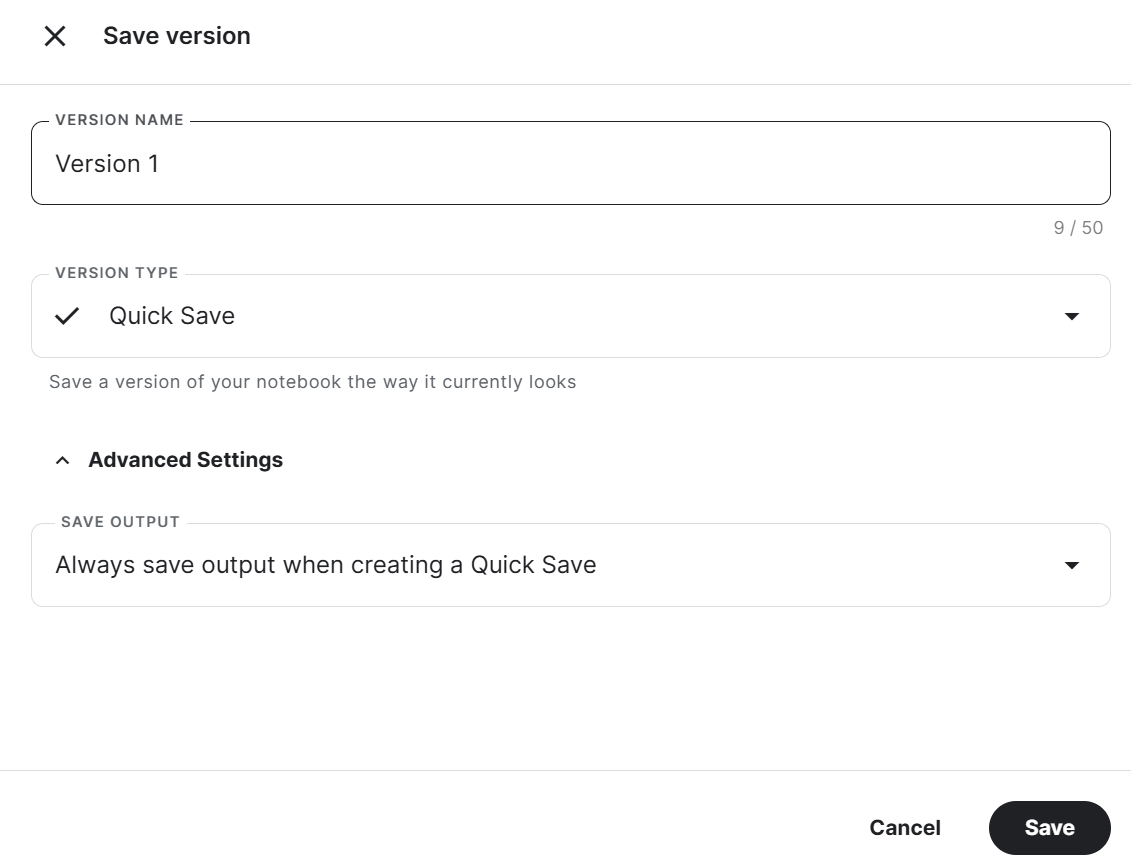
Wenn du beim Ausführen des Codes auf ein Problem stößt, sieh in diesem Kaggle Notebook nach: Feinabstimmung von Llama 3 8B auf medizinischen Daten.
Wir haben unser Modell mit Hilfe der GPU verfeinert. Du kannst auch lernen, LLMs mit Hilfe der TPUs fein abzustimmen, indem du das Tutorial Fine-Tune and Run Inference on Google's Gemma Model Using TPUs befolgst.
Wenn du lernen willst, wie du andere Modelle fein abstimmst, sieh dir dieses Mistral 7B Tutorial an: Eine Schritt-für-Schritt-Anleitung zur Verwendung und Feinabstimmung des Mistral 7B.
Um das fein abgestimmte Modell lokal zu verwenden, müssen wir zuerst den Adapter mit dem Basismodell zusammenführen und dann das vollständige Modell speichern.
Lass uns die folgenden Schritte unternehmen:
1. Erstelle ein neues Kaggle Notebook und installiere alle notwendigen Python-Pakete. Stelle sicher, dass du die GPU als Beschleuniger verwendest.
%%capture
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U accelerate
%pip install -U peft
%pip install -U trl2. Melde dich mit den Kaggle-Geheimnissen im Hugging Face Hub an. So können wir das vollständige, fein abgestimmte Modell leicht hochladen.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)3. Füge das Llama 3 8B Chat-Modell und ein fein abgestimmtes Kaggle-Notizbuch hinzu, das wir kürzlich gespeichert haben. Wir können die Notizbücher in der aktuellen Sitzung genauso hinzufügen, wie du einen Datensatz und Modelle hinzufügst.
Wenn wir Notebook zur Kaggle-Sitzung hinzufügen, können wir auf die Ausgabedateien zugreifen. In unserem Fall handelt es sich um eine Modelladapterdatei.
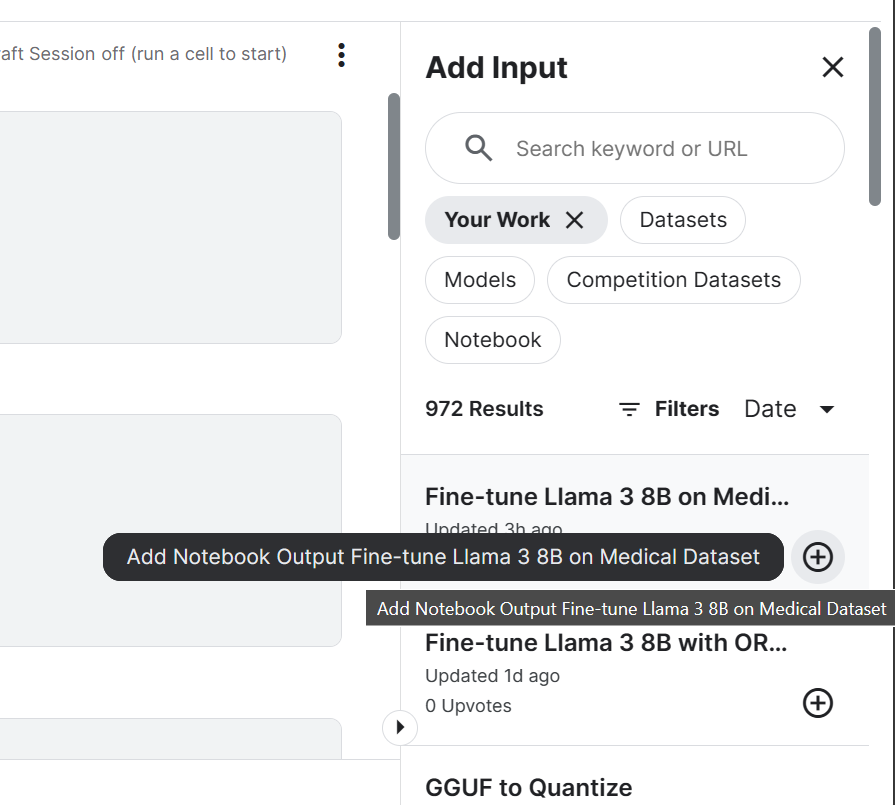
4. Einstellen der Variablen mit dem Standort des Basismodells und des Adapters.
base_model = "/kaggle/input/llama-3/transformers/8b-chat-hf/1"
new_model = "/kaggle/input/fine-tune-llama-3-8b-on-medical-dataset/llama-3-8b-chat-doctor/"Zuerst laden wir den Tokenizer und das Basismodell mithilfe der transformers Bibliothek. Dann richten wir das Chat-Format mithilfe der trl Bibliothek ein. Zum Schluss laden wir den Adapter und fügen ihn mit Hilfe der PEFT Bibliothek zum Basismodell zusammen.
Die Funktion merge_and_unload() hilft uns dabei, die Adaptergewichte mit dem Basismodell zu verschmelzen und es als eigenständiges Modell zu verwenden.
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
from peft import PeftModel
import torch
from trl import setup_chat_format
# Reload tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(base_model)
base_model_reload = AutoModelForCausalLM.from_pretrained(
base_model,
return_dict=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
)
base_model_reload, tokenizer = setup_chat_format(base_model_reload, tokenizer)
# Merge adapter with base model
model = PeftModel.from_pretrained(base_model_reload, new_model)
model = model.merge_and_unload()Um zu überprüfen, ob unser Modell korrekt zusammengeführt wurde, führen wir eine einfache Inferenz mit pipeline aus der Bibliothek transformers durch. Wir konvertieren die Nachricht mithilfe der Chat-Vorlage und geben dann eine Aufforderung an die Pipeline weiter. Die Pipeline wurde mit dem Modell, dem Tokenizer und dem Aufgabentyp initialisiert.
Nebenbei bemerkt kannst du device_map auf "auto" einstellen, wenn du mehrere GPUs nutzen willst.
messages = [{"role": "user", "content": "Hello doctor, I have bad acne. How do I get rid of it?"}]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipe(prompt, max_new_tokens=120, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
Unser fein abgestimmtes Modell funktioniert nach der Zusammenführung wie erwartet.
Jetzt werden wir einen Tokenizer und ein Modell mit der Funktion save_pretrained() speichern.
model.save_pretrained("llama-3-8b-chat-doctor")
tokenizer.save_pretrained("llama-3-8b-chat-doctor")Die Modelldateien werden im Safetensors-Format gespeichert, und die Gesamtgröße des Modells beträgt etwa 16 GB.
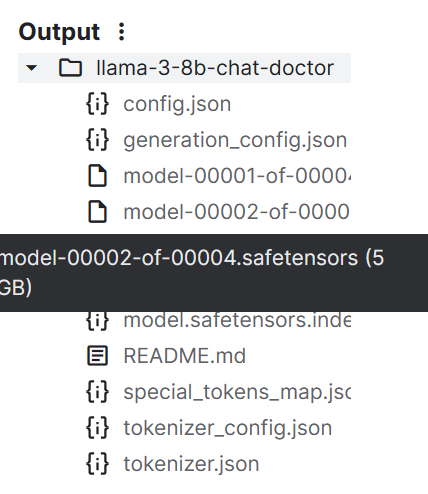
Wir können alle Dateien mit der Funktion push_to_hub() an den Hugging Face Hub senden.
model.push_to_hub("llama-3-8b-chat-doctor", use_temp_dir=False)
tokenizer.push_to_hub("llama-3-8b-chat-doctor", use_temp_dir=False)Am Ende können wir das Kaggle-Notizbuch genauso speichern, wie wir es zuvor getan haben.
Wenn du den Fine Tuned Adapter verwendest , um Kaggle Notebook vollständig zu modellieren, kannst du alle Probleme lösen, die mit der Ausführung des Codes auf eigene Faust zusammenhängen.
Wir können die safetensors-Dateien nicht lokal verwenden, da die meisten lokalen KI-Chatbots sie nicht unterstützen. Stattdessen konvertieren wir sie in das GGUF-Dateiformat llama.cpp.
Starte eine neue Kaggle-Notebook-Sitzung und füge den Fine Tuned Adapter zum vollständigen Modell des Notebooks hinzu.
Klone das llama.cpp-Repository und installiere das llama.cpp-Framework mit dem Befehl make wie unten gezeigt.
Nebenbei bemerkt funktioniert der unten stehende Befehl nur für das Kaggle Notebook. Du musst vielleicht ein paar Dinge ändern, um es auf anderen Plattformen oder lokal laufen zu lassen.
%cd /kaggle/working
!git clone --depth=1 https://github.com/ggerganov/llama.cpp.git
%cd /kaggle/working/llama.cpp
!sed -i 's|MK_LDFLAGS += -lcuda|MK_LDFLAGS += -L/usr/local/nvidia/lib64 -lcuda|' Makefile
!LLAMA_CUDA=1 conda run -n base make -j > /dev/nullFühre den folgenden Befehl in der Zelle von Kaggle Notebook aus, um das Modell in das GGUF-Format zu konvertieren.
Die convert-hf-to-gguf.py benötigt ein Verzeichnis für das Eingabemodell, ein Verzeichnis für die Ausgabedatei und einen Ausgabentyp.
!python convert-hf-to-gguf.py /kaggle/input/fine-tuned-adapter-to-full-model/llama-3-8b-chat-doctor/ \
--outfile /kaggle/working/llama-3-8b-chat-doctor.gguf \
--outtype f16Innerhalb weniger Minuten ist das Modell konvertiert und lokal gespeichert. Wir können dann das Notizbuch speichern, um die Datei zu sichern.
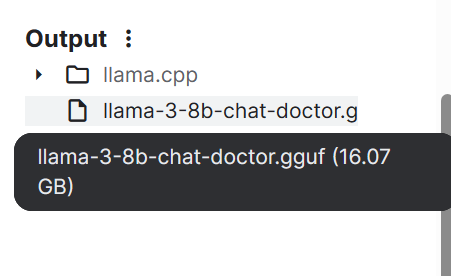
Wenn du Probleme hast, den obigen Code auszuführen, schau im HF LLM to GGUF Kaggle Notebook nach.
Normale Laptops haben nicht genug RAM und GPU-Speicher, um das gesamte Modell zu laden. Deshalb müssen wir das GGUF-Modell quantifizieren und das 16-GB-Modell auf etwa 4-5 GB reduzieren.
Starte eine neue Kaggle Notebook-Sitzung und füge die HF LLM zu GGUF Notebook hinzu.
Installiere dann die llama.cpp, indem du den folgenden Befehl in der Kaggle Notebook Zelle ausführst.
%cd /kaggle/working
!git clone --depth=1 https://github.com/ggerganov/llama.cpp.git
%cd /kaggle/working/llama.cpp
!sed -i 's|MK_LDFLAGS += -lcuda|MK_LDFLAGS += -L/usr/local/nvidia/lib64 -lcuda|' Makefile
!LLAMA_CUDA=1 conda run -n base make -j > /dev/nullDas Quantisierungsskript benötigt ein GGUF-Modellverzeichnis, ein Ausgabedateiverzeichnis und eine Quantisierungsmethode. Wir konvertieren das Modell mit der Methode Q4_K_M.
%cd /kaggle/working/
!./llama.cpp/llama-quantize /kaggle/input/hf-llm-to-gguf/llama-3-8b-chat-doctor.gguf llama-3-8b-chat-doctor-Q4_K_M.gguf Q4_K_M
Die Größe unseres Modells hat sich von 15317,05 MB auf 4685,32 MB deutlich verringert.
Um die einzelne Datei zum Hugging Face Hub zu schieben, werden wir:
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
from huggingface_hub import HfApi
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)
api = HfApi()
api.upload_file(
path_or_fileobj="/kaggle/working/llama-3-8b-chat-doctor-Q4_K_M.gguf",
path_in_repo="llama-3-8b-chat-doctor-Q4_K_M.gguf",
repo_id="kingabzpro/llama-3-8b-chat-doctor",
repo_type="model",
)
Unser Modell wurde erfolgreich auf den Remote-Server übertragen, wie unten dargestellt.
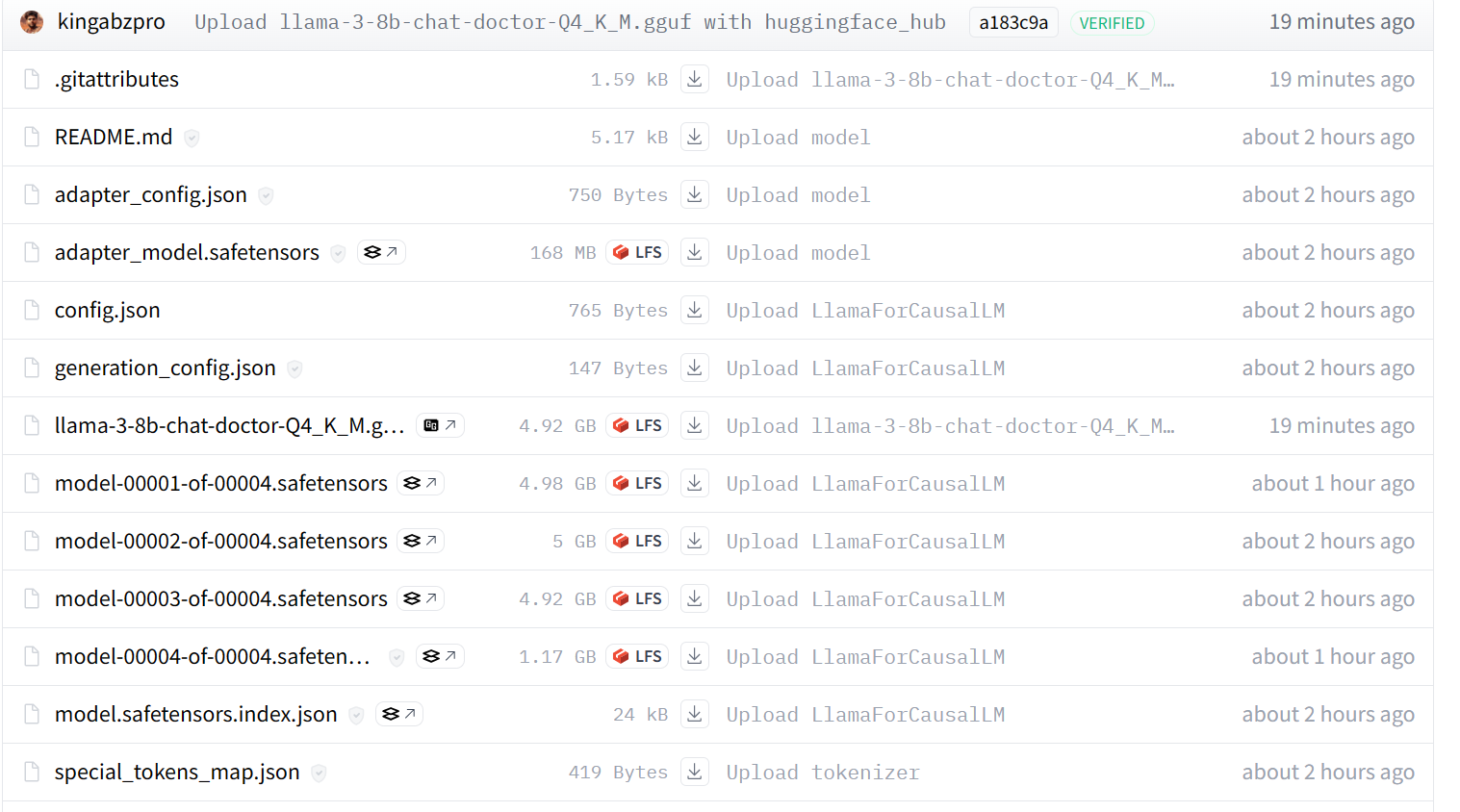
Wenn du immer noch Probleme hast, sieh dir bitte das GGUF to Quantize Kaggle Notebook an, das den gesamten Code und die Ausgabe enthält.
Wenn du nach einer einfacheren Möglichkeit suchst, dein Modell zu konvertieren und zu quantisieren, besuche diesen Hugging Face Space und gib ihm die Hub Model Id.
Um das GGUF-Modell lokal zu verwenden, musst du es herunterladen und in die Jan-Anwendung importieren.
Um das Modell herunterzuladen, müssen wir:
1. Gehe zu unserem Hugging Face Repository.
2. Klicke auf die Registerkarte Dateien.
3. Klicke auf die quantisierte Modelldatei mit der Erweiterung GGUF.

4. Klicke auf den Download-Button.
Es wird einige Minuten dauern, bis die Datei lokal heruntergeladen ist.
Lade die Jan-Anwendung von Jan AI herunter und installiere sie.
So sieht es aus, wenn du die Jan-Fenster-Anwendung startest:
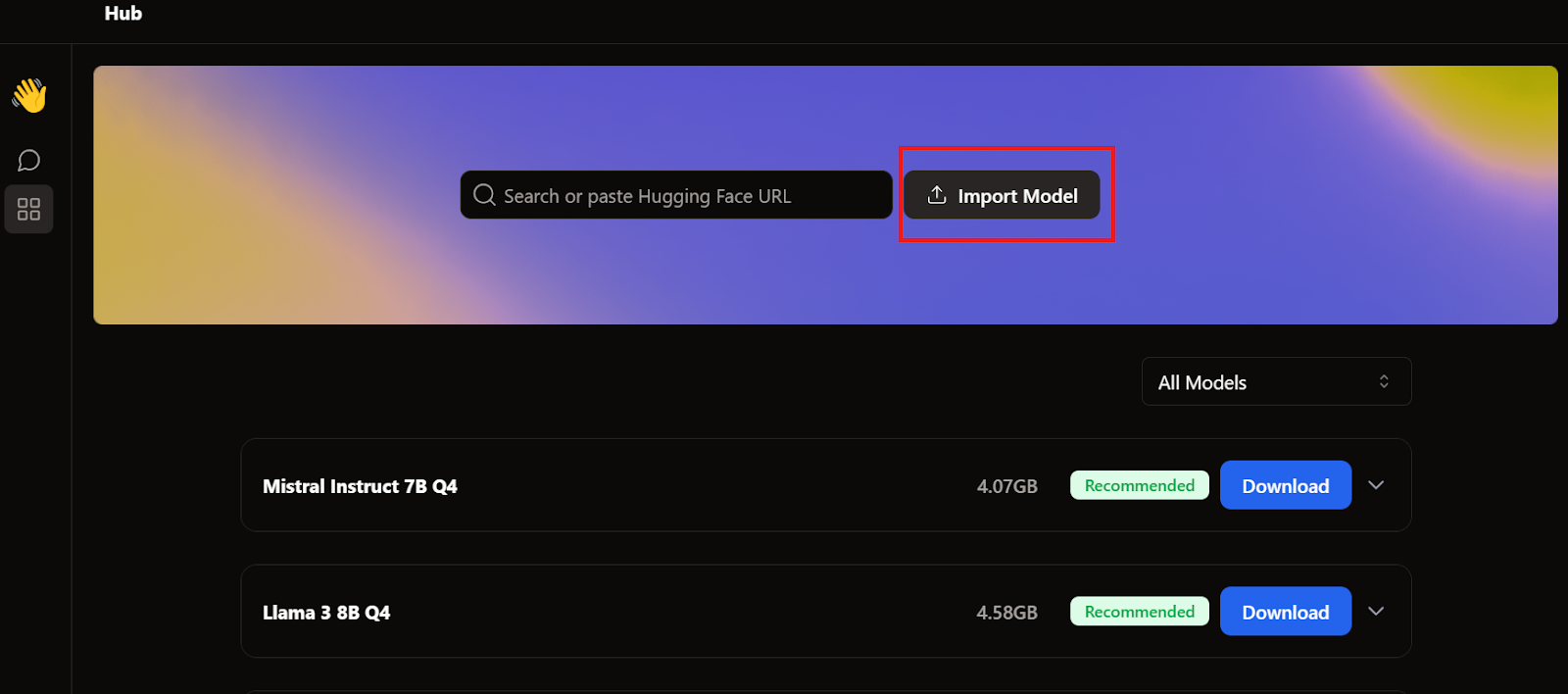
Um das Modell zur Jan-Anwendung hinzuzufügen, müssen wir die quantisierte GGUF-Datei importieren.
Wir müssen zum Hub-Menü gehen und auf Modell importieren klicken , wie unten gezeigt. Wir geben den Ort der zuletzt heruntergeladenen Datei an, und das war's.
Wir gehen ins Themenmenü und wählen das fein abgestimmte Modell.
Bevor wir das Modell verwenden, müssen wir es anpassen, damit die Antwort richtig angezeigt wird. Zuerst ändern wir die Aufforderungsvorlage im Abschnitt Modellparameter.
<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistantWir fügen das Stop-Token hinzu und ändern das Max-Token in den Inferenzparametern auf 512.
<endofstring>, Best, Regards, Thanks,-->Wir fangen an, die Anfragen zu schreiben, und der Arzt wird entsprechend antworten.
Unser fein abgestimmtes Modell funktioniert vor Ort perfekt.
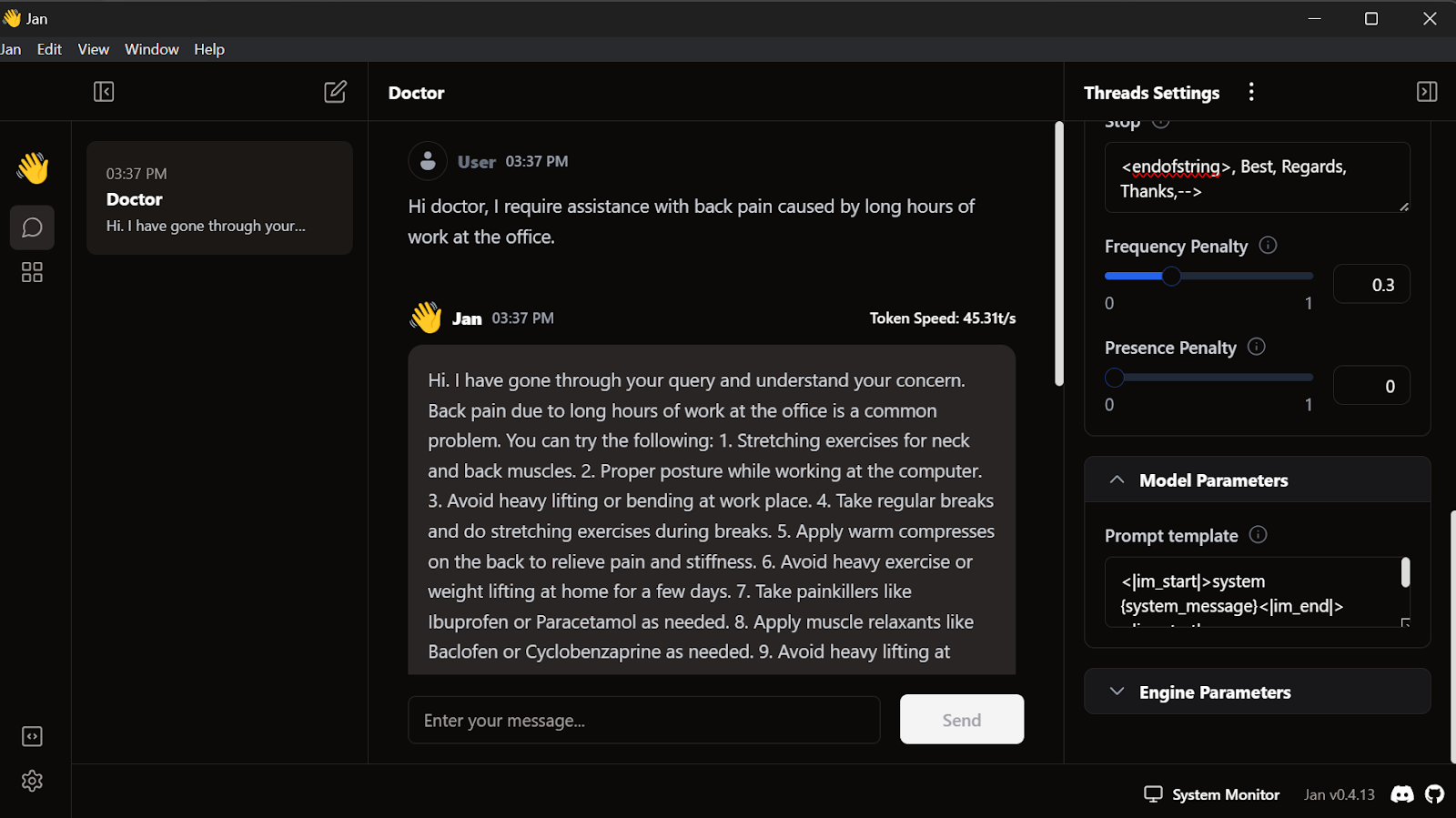
Dieses Modell funktioniert mit GPT4ALL, Llama.cpp, Ollama und vielen anderen lokalen KI-Anwendungen. Wenn du wissen willst, wie man sie benutzt, schau dir dieses Tutorial an, in dem du erfährst, wie man LLMs lokal ausführt.
Die Feinabstimmung des Llama 3-Modells auf einem benutzerdefinierten Datensatz und dessen lokale Nutzung hat viele Möglichkeiten für die Entwicklung innovativer Anwendungen eröffnet. Die potenziellen Anwendungsfälle reichen von privaten und maßgeschneiderten KI-Lösungen bis hin zu domänenspezifischen Chatbots, Textklassifizierung, Sprachübersetzung, personalisierten Empfehlungssystemen zur Beantwortung von Fragen und sogar Anwendungen für das Gesundheitswesen und die Marketingautomatisierung.
Mit den Frameworks Ollama und Langchain ist es jetzt einfacher denn je, eine eigene KI-Anwendung zu erstellen, für die nur ein paar Zeilen Code nötig sind. Um das zu tun, folge dem LlamaIndex: A Data Framework for Large Language Models (LLMs)- based applications tutorial.
In diesem Lernprogramm haben wir gelernt, den Llama 3 8B Chat an einem medizinischen Datensatz zu verfeinern. Wir haben den Adapter mit dem Basismodell zusammengeführt, ihn in das GGUF-Format konvertiert und für die lokale Verwendung in einer Jan-Chatbot-Anwendung quantifiziert.
Wenn du mehr erfahren möchtest, dann schau dir diesen vierteiligen Kurs über die Entwicklung von großen Sprachmodellen an.
Lerne KI mit diesen Kursen!
Lernpfad
Lernpfad
Lernpfad