We live in remarkable times where open-source projects driven by dedicated communities rival the capabilities of costly proprietary solutions from major corporations. Among the remarkable advancements, we find smaller yet highly efficient language models such as Vicuna, Koala, Alpaca, and StableLM, which require minimal compute resources while delivering results on par with ChatGPT. What ties them together is their foundation is on Meta AI's LLaMA models.
Read 12 GPT-4 Open-Source Alternatives to learn about other popular open-source development in language technologies.
In this post, we will learn about Meta AI’s LLaMA models, explore their functionality, access them through the transformers library, compare their performance, and discuss challenges and limitations. Since the original writing of this article, we have seen both LLaMA 2 and LLaMA 3 launch, and you can find out more details about each in our separate articles.
What is LLaMA?
LLaMA(Large Language Model Meta AI) is a collection of state-of-the-art foundation language models ranging from 7B to 65B parameters. These models are smaller in size while delivering exceptional performance, significantly reducing the computational power and resources needed to experiment with novel methodologies, validate the work of others, and explore innovative use cases.
The foundation models were trained on large unlabeled datasets, making them ideal for fine-tuning on a variety of tasks. The model was trained on the following source:
- 67.0% CommonCrawl
- 15.0% C4
- 4.5% GitHub
- 4.5% Wikipedia
- 4.5% Books
- 2.5% ArXiv
- 2.0% StackExchange
The wide variety of datasets has empowered the models to achieve state-of-the-art performance that rivals the top-performing models, namely Chinchilla-70B and PaLM-540B.
Gain a comprehensive understanding of the evolution of OpenAI's models, including GPT-1, GPT-2, GPT-3, and the current state of the model GPT-4 by reading: What is GPT-4 and Why Does it Matter?
How Does Meta's LLaMA Work?
LLaMA, an auto-regressive language model, is built on the transformer architecture. Like other prominent language models, LLaMA functions by taking a sequence of words as input and predicting the next word, recursively generating text.
What sets LLaMA apart is its training on a publicly available wide array of text data encompassing numerous languages such as Bulgarian, Catalan, Czech, Danish, German, English, Spanish, French, Croatian, Hungarian, Italian, Dutch, Polish, Portuguese, Romanian, Russian, Slovenian, Serbian, Swedish, and Ukrainian. As of 2024, LLaMA 2 has been introduced, featuring improved architecture and training methodologies, further enhancing its multilingual capabilities and efficiency.
The LLaMA models are available in several sizes: 7B, 13B, 33B, and 65B parameters, and you can access them on Hugging Face (LLaMA models converted to work with Transformers) or on the official repository facebookresearch/llama.
Getting Started with LLaMA Models
The official inference code is available facebookresearch/llama repository, but to make things simple, we will use the Hugging Face `transformers` library module LLaMA to load the model and generate the text.
1. Install all the necessary Python Libraries to run the module.
Note: we are using Google Colab to run the LLaMA inference.
%%capture
%pip install transformers SentencePiece accelerate2. Loading LLaMA tokens and model weights.
Note: “decapoda-research/llama-7b-hf” is not the official model weight. Decapoda Research has converted original model weights to work with Transformers.
import transformers, torch
from transformers import LlamaTokenizer, LlamaForCausalLM, GenerationConfig
tokenizer = LlamaTokenizer.from_pretrained("decapoda-research/llama-7b-hf")
model = LlamaForCausalLM.from_pretrained(
"decapoda-research/llama-7b-hf",
load_in_8bit=False,
torch_dtype=torch.float16,
device_map="auto",
)3. Writing the question.
4. Converting the text into tokens.
5. Creating model generation configuration.
6. Using tokens and generation configuration to generate output text.
7. Decoding the printing of the response.
instruction = "How old is the universe?"
inputs = tokenizer(
f"""Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction: {instruction}
### Response:""",
return_tensors="pt",
)
input_ids = inputs["input_ids"].to("cuda")
generation_config = transformers.GenerationConfig(
do_sample=True,
temperature=0.1,
top_p=0.75,
top_k=80,
repetition_penalty=1.5,
max_new_tokens=128,
)
with torch.no_grad():
generation_output = model.generate(
input_ids=input_ids,
attention_mask=torch.ones_like(input_ids),
generation_config=generation_config,
)
output_text = tokenizer.decode(
generation_output[0].cuda(), skip_special_tokens=True
).strip()
print(output_text)Output:
The model not only produces a precise estimate of 13 billion years for the age of the universe but also reveals the reasoning behind its calculation.
Below is an instruction that describes a task. Write a response that
appropriately completes the request.
### Instruction: How old is the universe?
### Response: The age of our Universe can be calculated by measuring
how fast it expands and then using this information to calculate its
size at different points in time, which allows us determine when
things happened relative to each other (evolutionary biology). This
method has been used for many years now with great success; however
there are still some uncertainties about what exactly we're seeing
because light takes so long travel from distant galaxies back here on
Earth! So while scientists have determined roughly 13 billion
year-old as being correct they don't know if their calculations were
off or not due to these limitations mentioned aboveAdditionally, the transformers can be used for fine-tuning diverse tasks and datasets, enabling a significant improvement in both accuracy and performance.
If you're interested in the more practical side of open-source development, check out the 5 Projects Build with Generative Models article for inspiration.
How Does LLaMA Differ From Other AI Models?
The paper presents a comprehensive evaluation of LLaMA models, comparing them with other state-of-the-art language models such as GPT-3, GPT-NeoX, Gopher, Chinchilla, and PaLM. The benchmark tests include common sense reasoning, trivia, reading comprehension, question answering, mathematical reasoning, code generation, and general domain knowledge.
- Common sense reasoning. The LLaMA-65B model has outperformed SOTA model architectures in PIQA, SIQA, and OpenBookQA reasoning benchmarks. Even smaller model 33B has outperformed all of them in ARC, easy and challenging.
- Closed-Book Question Answering & Trivia. The test measures LLM's ability to interpret and respond to realistic, human questions. LLaMA model has consistently outperformed GPT3, Gopher, Chinchilla, and PaLM in Natural Questions and TriviaQA benchmarks.
- Reading comprehension. It uses RACE-middle and RACE-high benchmark tests. LLaMA models have outperformed GPT-3 and have similar performance to PaLM 540B.
- Mathematical Reasoning. LLaMA was not fine-tuned on any mathematical data, and it performed quite poorly compared to Minerva.
- Code Generation. It uses HumanEval and MBPP test benchmarks. LLaMA has outperformed both LAMDA and PaLM in HumanEval@100, MBP@1, and MBP@80.
Domain knowledge. LLaMA models have performed worse compared to the massive PaLM 540B parameter model. PaLM has wide domain knowledge due to a larger number of parameters.
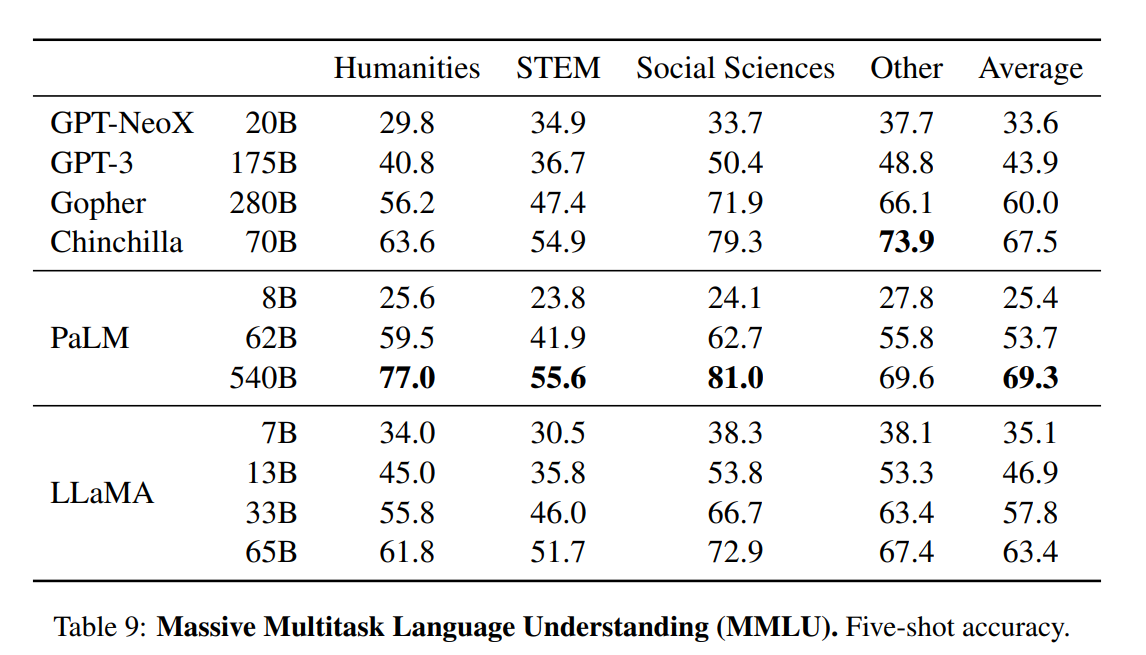
Challenges and Limitations of LLaMA
Just like other Large Language Models, LLaMA also suffers from hallucination. It can generate factually wrong information.
Other than that:
- Since the majority of our dataset comprises English text, it is important to note that the performance of the model on languages other than English may be comparatively lower.
- The primary purpose of the LLaMA models is for research applications(non-commercial license). The release of these models aims to facilitate researchers in evaluating and addressing issues such as biases, risks, the generation of toxic or harmful content, and hallucinations.
- LLaMA is a base model, and it should not be used to create applications without risk evaluation and mitigation.
- It is not good at mathematical reasoning and domain knowledge.
To gain insights into closed-source development, read The Latest On OpenAI, Google AI, and What it Means For Data Science. The blog talks about disruptive language, vision, and multimodal technologies and how it is making us more productive and effective.
With the subsequent release of LLaMA 2 and LLaMA 3, new challenges and limitations have been identified. Improvements have been made in areas such as context length limitations and with methods like fine-tuning, it's becoming possible to overcome struggles with tasks requiring deep domain-specific knowledge. As ever, the community is actively working on these aspects to enhance the robustness and applicability of these models.
Conclusion
The LLaMA models have sparked a revolutionary wave in open-source AI development. With the smaller foundation model LLaMA-13B surpassing the capabilities of GPT-3 and LLaMA-65B, demonstrating comparable performance to cutting-edge models like Chinchilla-70B and PaLM-540B, these advancements have unveiled the potential for achieving state-of-the-art results through training on publicly available data, all while utilizing minimal computing resources.
Additionally, the paper highlights the potential performance improvement achieved by fine-tuning LLaMA models using instructions. Notably, the Vicuna and Stanford Alpaca models that are fine-tuned from LLaMA on instruction-following demonstrations have shown similar results to ChatGPT and Bard.
If you're keen on leveraging large language models for your data science projects, check out A Guide to Using ChatGPT For Data Science Projects. You can also enhance your skills in prompt engineering by reviewing ChatGPT Cheat Sheets for Data Science.





