Cours
Machine learning avec des modèles arborescents en Python
5 h
116.4K
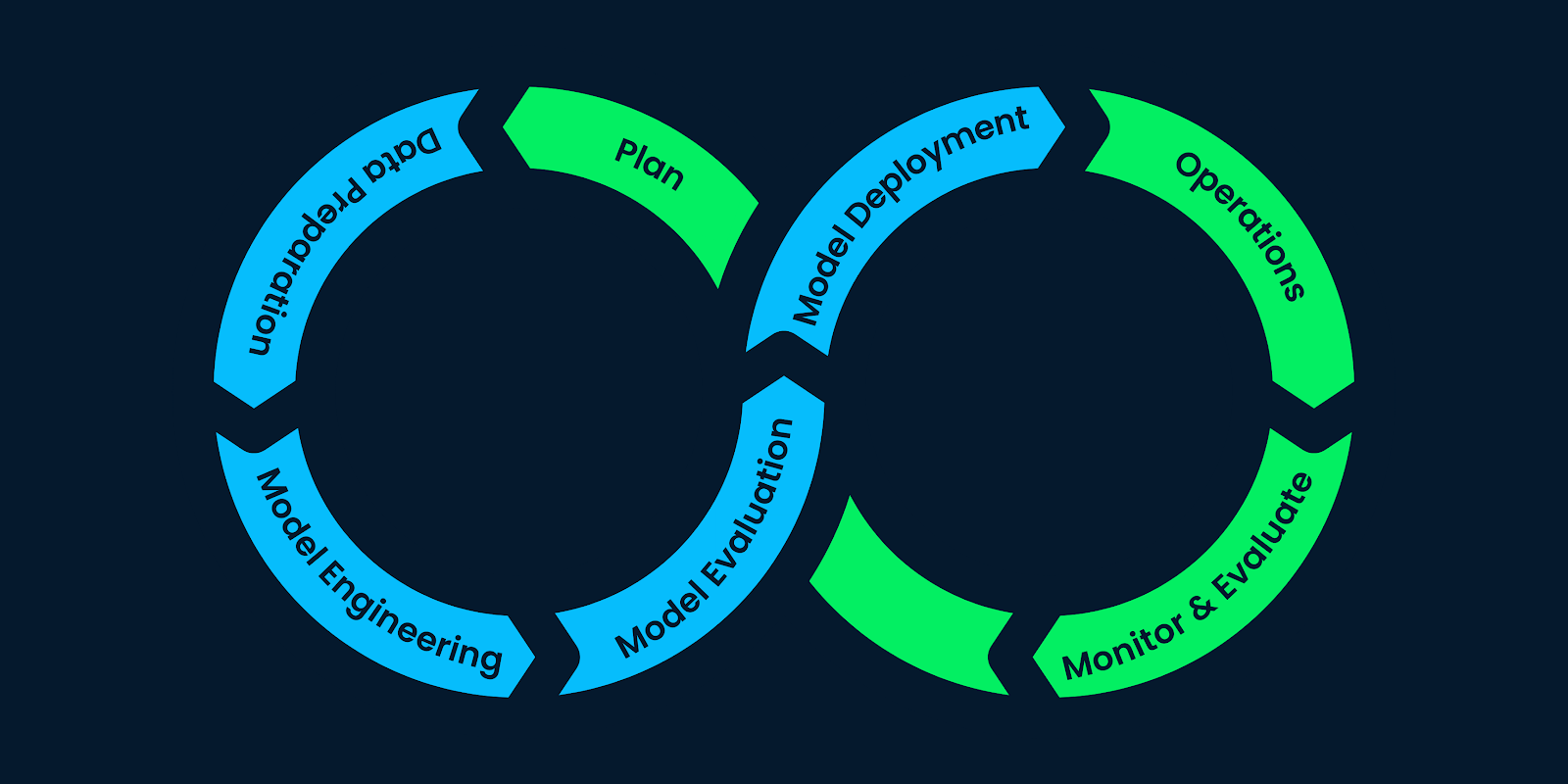
Nous pensons généralement que les projets d'apprentissage machine (ML) impliquent le traitement des données, l'entraînement des modèles et le déploiement des modèles. Mais c'est bien plus que cela.
Nous avons besoin d'une compréhension de l'entreprise et des données, de techniques de collecte de données, d'analyse de données, de construction de modèles et d'évaluation de modèles. En outre, après le déploiement, nous avons besoin d'une surveillance et d'une maintenance constantes.
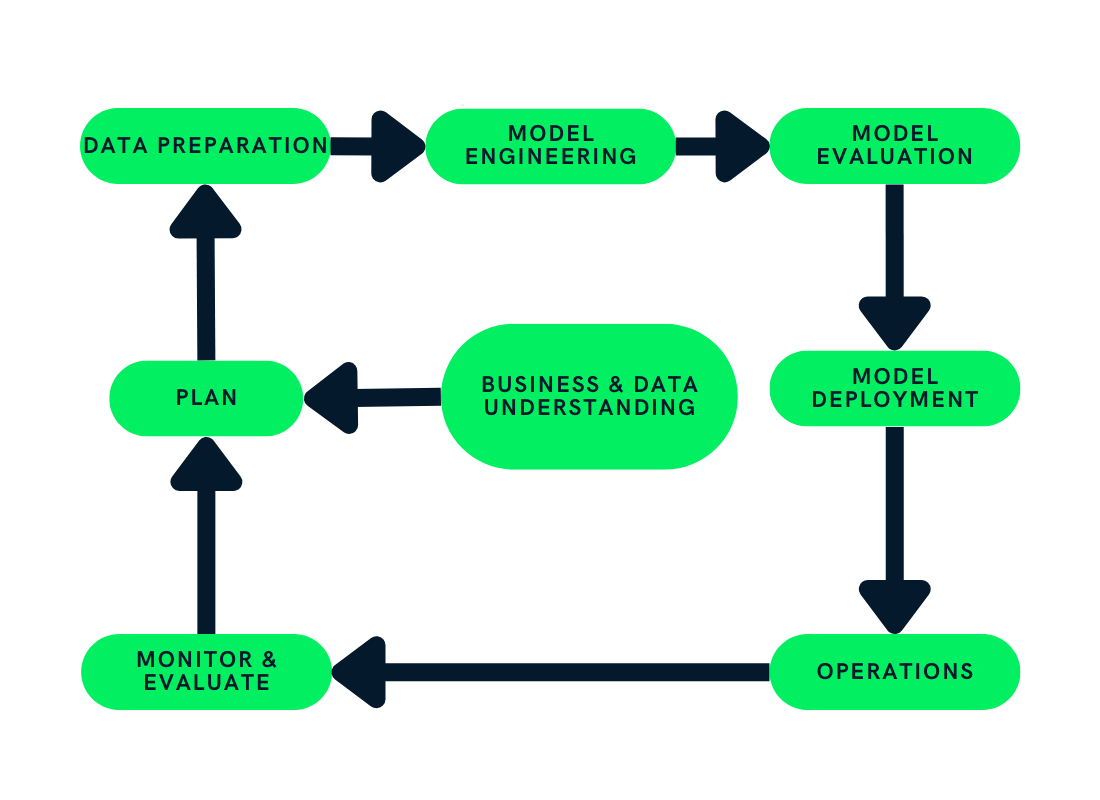
Le cycle de vie de l'apprentissage automatique se compose d'étapes qui structurent le projet d'apprentissage automatique et répartissent efficacement les ressources de l'entreprise. Le respect de ces étapes aide les entreprises à créer des produits d'IA durables, rentables et de qualité.
Dans ce billet, nous utiliserons le Cross-Industry Standard Process for the development of Machine Learning applications with Quality assurance methodology(CRISP-ML(Q)) pour expliquer chaque étape du cycle de vie de l'apprentissage automatique. Le CRISP-ML(Q) est un standard industriel pour la construction d'applications durables d'apprentissage automatique.
Chaque phase du cycle d'apprentissage automatique suit un cadre d'assurance qualité pour une amélioration et une maintenance constantes en respectant strictement les exigences et les contraintes. Pour en savoir plus sur l'assurance qualité, consultez le blog du CRISP-ML(Q).
Pour les personnes non techniques et les managers, consultez notre cours de courte durée sur la compréhension des principes fondamentaux de l'apprentissage automatique. Il les aidera à comprendre l'apprentissage automatique en général, la modélisation et l'apprentissage profond (IA). Vous pouvez également explorer les différences entre l'IA et l'apprentissage automatique dans un autre article.

Image par l'auteur
La phase de planification consiste à évaluer la portée, la mesure du succès et la faisabilité de l'application de ML. Vous devez comprendre l'activité et la manière d'utiliser l'apprentissage automatique pour améliorer le processus actuel. Par exemple : avons-nous besoin de l'apprentissage automatique ? Est-il possible de répondre à des demandes similaires avec une programmation simple ?
Vous devez également comprendre l'analyse coût-bénéfice et la manière dont vous livrerez la solution en plusieurs phases. En outre, vous devez définir des paramètres de réussite clairs et mesurables pour l'entreprise, les modèles d'apprentissage automatique (précision, score F1, AUC) et l'économie (indicateurs clés de performance).
Enfin, vous devez créer un rapport de faisabilité.
Il comprendra des informations sur
Les chefs d'entreprise peuvent apprendre les principes fondamentaux de l'apprentissage automatique en suivant un cours sur l'apprentissage automatique pour les entreprises et en appliquant ces leçons pour créer des stratégies d'entreprise et mettre en œuvre des solutions d'apprentissage automatique.
 by Author
by Author
La section sur la préparation des données est divisée en quatre parties : acquisition et étiquetage des données, nettoyage, gestion et traitement.
Nous devons d'abord décider de la manière dont nous allons collecter les données, en rassemblant les données internes, en utilisant des sources ouvertes, en les achetant aux fournisseurs ou en générant des données synthétiques. Chaque méthode a ses avantages et ses inconvénients et, dans certains cas, nous obtenons les données des quatre méthodologies.
Après la collecte, nous devons étiqueter les données. L'achat de données nettoyées et étiquetées n'est pas possible pour toutes les entreprises, et il se peut que vous deviez apporter des modifications à la sélection des données au cours du processus de développement. C'est la raison pour laquelle vous ne pouvez pas l'acheter en gros et que les données peuvent finalement être inutiles pour la solution.
La collecte et l'étiquetage des données requièrent la plupart des ressources de l'entreprise : argent, temps, professionnels, experts en la matière et accords juridiques.
Ensuite, nous nettoyons les données en imputant les valeurs manquantes, en analysant les données mal étiquetées, en supprimant les valeurs aberrantes et en réduisant le bruit. Vous allez créer un pipeline de données pour automatiser ce processus et vérifier la qualité des données.
L'étape du traitement des données comprend la sélection des caractéristiques, le traitement des classes déséquilibrées, l'ingénierie des caractéristiques, l'augmentation des données, ainsi que la normalisation et la mise à l'échelle des données.
Pour des raisons de reproductibilité, nous stockerons les métadonnées, la modélisation des données, les pipelines de transformation et les magasins d'éléments et nous les mettrons à jour.
Enfin, nous trouverons des solutions pour le stockage des données, le versionnage des données pour la reproductibilité, le stockage des métadonnées et la création de pipelines ETL. Cette partie garantira un flux de données constant pour l'entraînement du modèle.

Image par l'auteur
Dans cette phase, nous utiliserons toutes les informations de la phase de planification pour construire et former un modèle d'apprentissage automatique. Par exemple : le cursus des métriques du modèle, la garantie de l'évolutivité et de la robustesse, et l'optimisation des ressources de stockage et de calcul.
Nous nous concentrerons sur l'architecture des modèles, la qualité du code, les expériences d'apprentissage automatique, l'entraînement des modèles et l'assemblage.
Les caractéristiques, les hyperparamètres, les expériences de ML, l'architecture du modèle, l'environnement de développement et les métadonnées sont stockés et versionnés à des fins de reproductibilité.
Découvrez les étapes de l'ingénierie des modèles en suivant le cursus Machine Learning Scientist with Python. Il vous aidera à maîtriser les compétences nécessaires pour décrocher un emploi d'ingénieur en apprentissage automatique.
 l'auteur
l'auteur
Maintenant que nous avons finalisé la version du modèle, il est temps de tester différentes mesures. Pourquoi ? Nous pouvons ainsi nous assurer que notre modèle est prêt pour la production.
Nous testerons d'abord notre modèle sur un ensemble de données de test et veillerons à impliquer des experts en la matière pour identifier les erreurs dans les prédictions.
Nous devons également veiller à respecter les cadres industriels, éthiques et juridiques pour la mise en place de solutions d'IA.
En outre, nous testerons la robustesse de notre modèle sur des données aléatoires et réelles. S'assurer que les déductions du modèle sont suffisamment rapides pour apporter la valeur.
Enfin, nous comparerons les résultats avec les paramètres de réussite prévus et déciderons de déployer ou non le modèle. Au cours de cette phase, chaque processus est enregistré et versionné afin de maintenir la qualité et la reproductibilité.
 par auteur
par auteur
Dans cette phase, nous déployons des modèles d'apprentissage automatique dans le système actuel. Par exemple : introduction de l'étiquetage automatique des entrepôts à partir de la forme du produit. Nous allons déployer un modèle de vision artificielle dans le système actuel, qui utilisera les images de la caméra pour imprimer les étiquettes.
En général, les modèles peuvent être déployés sur le cloud et le serveur local, le navigateur web, le progiciel en tant que logiciel et l'appareil périphérique. Ensuite, vous pouvez utiliser l'API, l'application web, les plugins ou le tableau de bord pour accéder aux prédictions.
Dans le processus de déploiement, nous définissons le matériel d'inférence. Nous devons nous assurer que nous disposons de suffisamment de mémoire vive, d'espace de stockage et de puissance de calcul pour produire des résultats rapides. Ensuite, nous évaluerons les performances du modèle en production à l'aide de tests A/B, afin de garantir l'acceptabilité par l'utilisateur.
La stratégie de déploiement est importante. Vous devez vous assurer que les changements sont transparents et qu'ils ont amélioré l'expérience de l'utilisateur. En outre, un gestionnaire de projet doit préparer un plan de gestion des catastrophes. Il doit comprendre une stratégie de repli, une surveillance constante, la détection des anomalies et la minimisation des pertes.
 l'auteur
l'auteur
Après avoir déployé le modèle en production, nous devons constamment contrôler et améliorer le système. Nous surveillerons les paramètres du modèle, les performances du matériel et des logiciels, ainsi que la satisfaction des clients.
La surveillance est entièrement automatisée et les professionnels sont informés des anomalies, de la baisse des performances du modèle et du système, et des mauvaises critiques de la part des clients.
Lorsque nous recevons une alerte de performance réduite, nous évaluons les problèmes et essayons d'entraîner le modèle sur de nouvelles données ou de modifier les architectures du modèle. Il s'agit d'un processus continu.
Dans de rares cas, nous devons réorganiser l'ensemble du cycle de vie de l'apprentissage automatique pour améliorer les techniques de traitement des données et d'apprentissage des modèles, mettre à jour les nouveaux logiciels et matériels et introduire un nouveau cadre pour l'intégration continue.
Dans la plupart des universités, les étudiants en science des données n'apprennent que le traitement des données, la construction et l'entraînement de modèles et, dans certains cas, le déploiement. On ne leur enseigne pas les pratiques industrielles standard en matière d'assurance qualité, les techniques de collecte et d'étiquetage des données, les pipelines d'apprentissage automatique, le versionnage des données, le cursus des expériences de ML, ainsi que la surveillance et la maintenance constantes.
 l'auteur
l'auteur
Même si vous êtes un professionnel de la science des données, vous devez apprendre comment les cinq grandes entreprises technologiques créent des applications durables d'apprentissage automatique pour des milliards de clients. Vous pouvez également apprendre à Concevoir des flux de travail d'apprentissage automatique en Python pour construire des pipelines qui résistent à l'épreuve du temps. Il vous enseignera le flux de travail standard, les processus humains dans la boucle, la gestion du cycle de vie du modèle et le flux de travail non supervisé.
Dans cet article, nous avons appris à planifier un projet d'apprentissage automatique en fonction des exigences et des contraintes, de la collecte et de l'étiquetage des données, de l'ingénierie des modèles, de l'évaluation des modèles, du déploiement des modèles, ainsi que de la surveillance et de la maintenance. En outre, nous avons appris diverses manières de maintenir la qualité, de reproduire les résultats et de déboguer le processus en cas d'échec.
Cours sur l'apprentissage automatique
Cours
Cours
Cours
blog
Nathaniel Taylor-Leach
blog
Nathaniel Taylor-Leach
8 min
blog
Nisha Arya Ahmed
15 min
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach