Kurs
Maschinelles Lernen mit baumbasierten Modellen in Python
5 Std.
116.5K
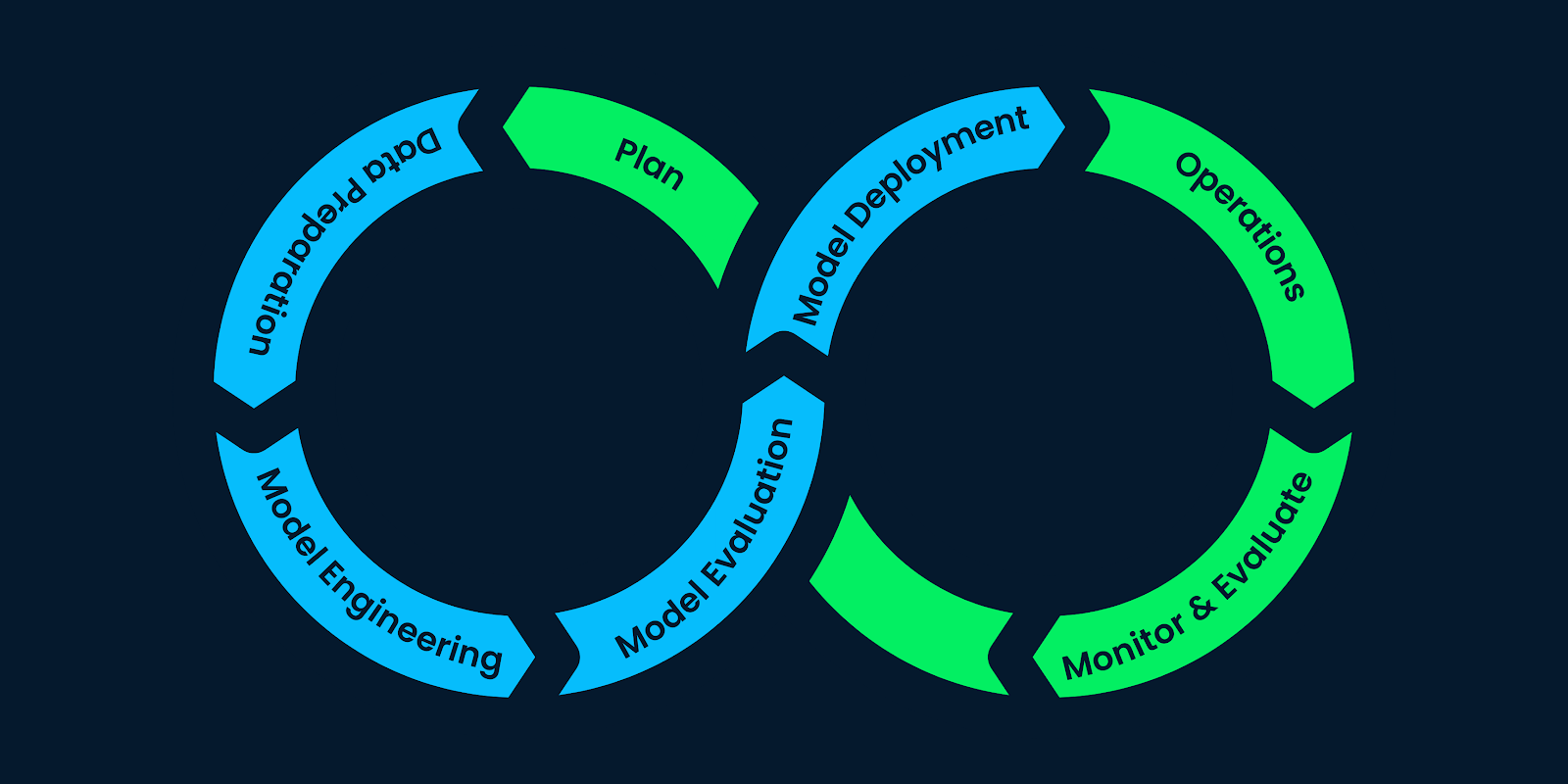
Normalerweise denken wir, dass Projekte des maschinellen Lernens (ML) die Verarbeitung von Daten, das Trainieren von Modellen und den Einsatz von Modellen beinhalten. Aber es ist so viel mehr als das.
Wir brauchen Geschäfts- und Datenverständnis, Datenerfassungstechniken, Datenanalyse, Modellbildung und Modellbewertung. Außerdem brauchen wir nach der Einführung eine ständige Überwachung und Wartung.
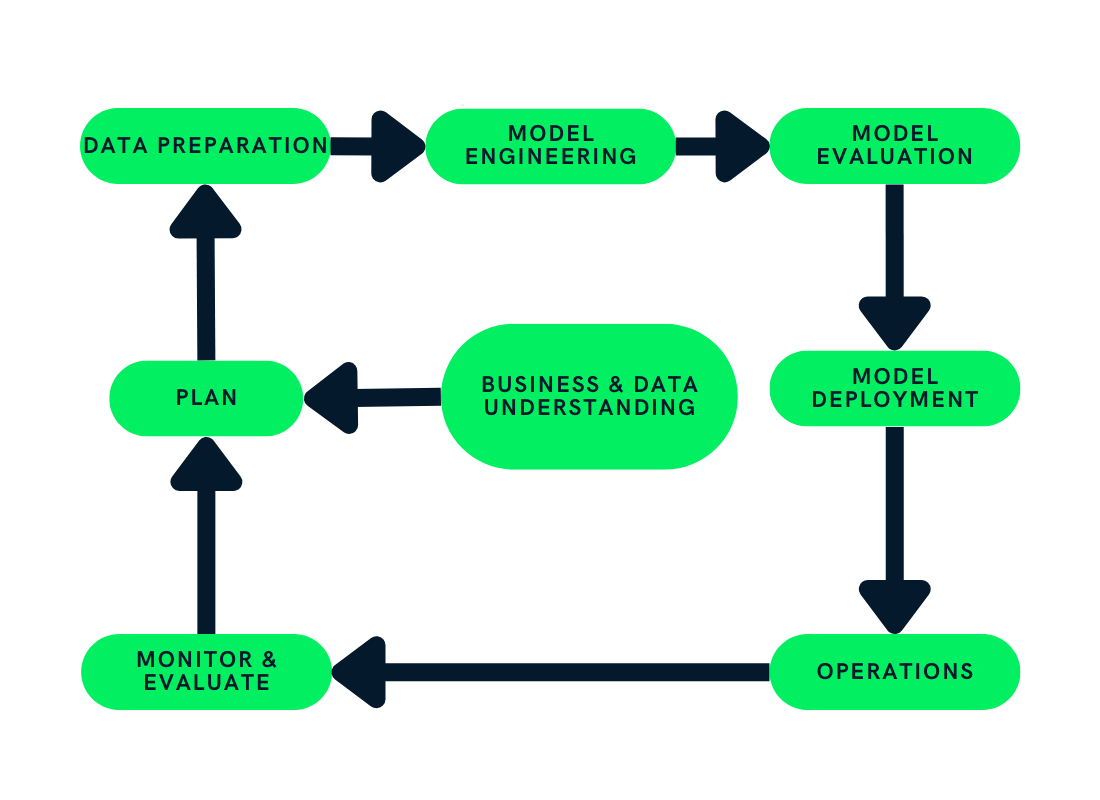
Der Lebenszyklus des maschinellen Lernens besteht aus Schritten, die dem Projekt des maschinellen Lernens Struktur verleihen und die Ressourcen des Unternehmens effektiv aufteilen. Wenn du diese Schritte befolgst, können Unternehmen nachhaltige, kosteneffiziente und hochwertige KI-Produkte entwickeln.
In diesem Beitrag werden wir den Cross-Industry Standard Process for the development of Machine Learning applications with Quality assurance methodology(CRISP-ML(Q)) verwenden, um jeden Schritt im Lebenszyklus des maschinellen Lernens zu erklären. Die CRISP-ML(Q) ist ein Industriestandard für den Aufbau nachhaltiger Machine-Learning-Anwendungen.
Jede Phase im Zyklus des maschinellen Lernens folgt einem Qualitätssicherungsrahmen für die ständige Verbesserung und Wartung durch die strikte Einhaltung von Anforderungen und Einschränkungen. Mehr über Qualitätssicherung erfährst du im CRISP-ML(Q) Blog.
Für technisch nicht versierte Personen und Manager gibt es einen kurzen Kurs zum Verständnis der Grundlagen des maschinellen Lernens. Es wird ihnen helfen, maschinelles Lernen im Allgemeinen, Modellierung und Deep Learning (KI) zu verstehen. Die Unterschiede zwischen KI und maschinellem Lernen kannst du auch in einem anderen Artikel nachlesen.

Bild vom Autor
In der Planungsphase geht es darum, den Umfang, die Erfolgskriterien und die Machbarkeit der ML-Anwendung zu bewerten. Du musst das Geschäft verstehen und wissen, wie du maschinelles Lernen nutzen kannst, um den aktuellen Prozess zu verbessern. Zum Beispiel: Brauchen wir maschinelles Lernen? Können wir ähnliche Wünsche mit einfacher Programmierung erreichen?
Du musst auch die Kosten-Nutzen-Analyse verstehen und wissen, wie du die Lösung in mehreren Phasen ausliefern wirst. Außerdem musst du klare und messbare Erfolgskennzahlen für das Geschäft, die Machine-Learning-Modelle (Genauigkeit, F1-Score, AUC) und die Wirtschaft (Leistungskennzahlen) definieren.
Schließlich musst du einen Machbarkeitsbericht erstellen.
Sie enthält Informationen über:
Führungskräfte können die Grundlagen des maschinellen Lernens erlernen, indem sie einen Kurs zum maschinellen Lernen für Unternehmen besuchen und diese Lektionen anwenden, um Geschäftsstrategien zu entwickeln und ML-Lösungen zu implementieren.
 vom Autor
vom Autor
Der Abschnitt Datenaufbereitung ist in vier Teile unterteilt: Datenbeschaffung und -kennzeichnung, Bereinigung, Verwaltung und Verarbeitung.
Zuerst müssen wir entscheiden, wie wir die Daten sammeln wollen: mit internen Daten, mit Open-Source-Daten, mit Daten, die wir von Anbietern kaufen, oder mit synthetischen Daten. Jede Methode hat Vor- und Nachteile, und in manchen Fällen erhalten wir die Daten aus allen vier Methoden.
Nach dem Sammeln müssen wir die Daten beschriften. Der Kauf von bereinigten und gekennzeichneten Daten ist nicht für alle Unternehmen machbar, und möglicherweise musst du auch während des Entwicklungsprozesses Änderungen an der Datenauswahl vornehmen. Das ist der Grund, warum du sie nicht in großen Mengen kaufen kannst und warum die Daten letztendlich für die Lösung unbrauchbar sein können.
Die Datenerfassung und -kennzeichnung erfordert die meisten Ressourcen des Unternehmens: Geld, Zeit, Fachleute, Experten und rechtliche Vereinbarungen.
Als Nächstes bereinigen wir die Daten, indem wir fehlende Werte ergänzen, falsch beschriftete Daten analysieren, Ausreißer entfernen und das Rauschen reduzieren. Du wirst eine Datenpipeline erstellen, um diesen Prozess zu automatisieren und die Datenqualität zu überprüfen.
Die Datenverarbeitung umfasst die Auswahl von Merkmalen, den Umgang mit unausgewogenen Klassen, das Feature Engineering, die Datenerweiterung sowie die Normalisierung und Skalierung der Daten.
Um die Reproduzierbarkeit zu gewährleisten, werden wir die Metadaten, die Datenmodellierung, die Transformationspipelines und die Feature Stores speichern und versionieren.
Schließlich werden wir Lösungen für die Datenspeicherung, die Versionierung von Daten zur Reproduzierbarkeit, die Speicherung von Metadaten und die Erstellung von ETL-Pipelines erarbeiten. Dieser Teil sorgt für einen konstanten Datenstrom für das Modelltraining.

Bild vom Autor
In dieser Phase werden wir alle Informationen aus der Planungsphase nutzen, um ein maschinelles Lernmodell zu erstellen und zu trainieren. Zum Beispiel: Verfolgung von Modellmetriken, Gewährleistung von Skalierbarkeit und Robustheit und Optimierung von Speicher- und Rechenressourcen.
Wir werden uns auf Modellarchitektur, Codequalität, Experimente zum maschinellen Lernen, Modelltraining und Ensembling konzentrieren.
Die Merkmale, Hyperparameter, ML-Experimente, Modellarchitektur, Entwicklungsumgebung und Metadaten werden zur Reproduzierbarkeit gespeichert und versioniert.
Im Lernpfad "Machine Learning Scientist with Python " lernst du die Schritte der Modellentwicklung kennen. Es wird dir helfen, die notwendigen Fähigkeiten zu beherrschen, um einen Job als Ingenieur für maschinelles Lernen zu bekommen.
 vom Autor
vom Autor
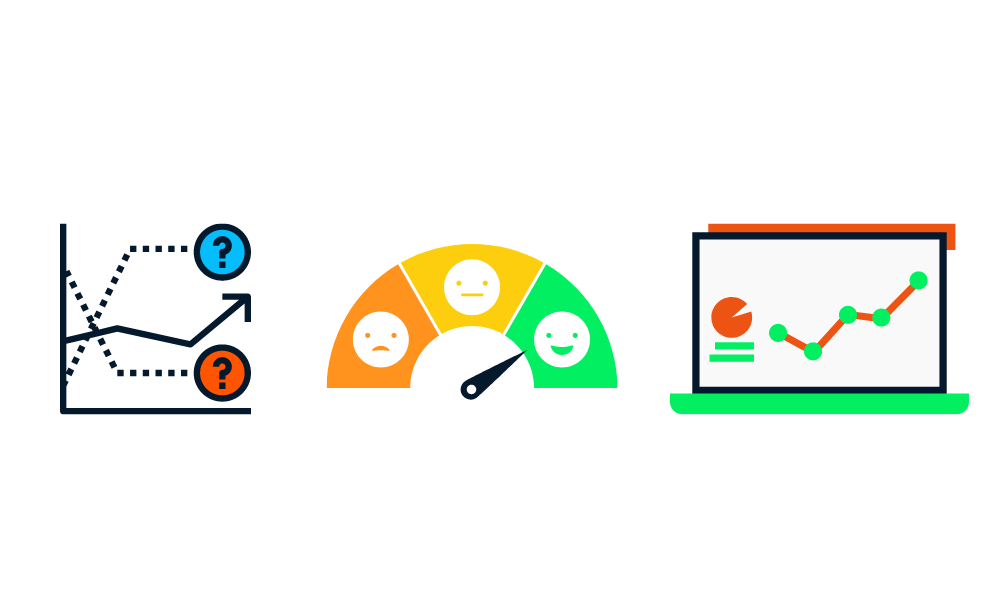
Jetzt, wo wir die Version des Modells fertiggestellt haben, ist es an der Zeit, verschiedene Metriken zu testen. Und warum? So können wir sicherstellen, dass unser Modell für die Produktion bereit ist.
Wir werden unser Modell zunächst an einem Testdatensatz testen und sicherstellen, dass wir Fachexperten einbeziehen, um die Fehler in den Vorhersagen zu identifizieren.
Wir müssen auch sicherstellen, dass wir die industriellen, ethischen und rechtlichen Rahmenbedingungen für die Entwicklung von KI-Lösungen einhalten.
Außerdem testen wir unser Modell auf seine Robustheit anhand von Zufallsdaten und realen Daten. Sicherstellen, dass das Modell schnell genug Schlüsse zieht, um den Wert zu bringen.
Schließlich vergleichen wir die Ergebnisse mit den geplanten Erfolgskennzahlen und entscheiden, ob wir das Modell einsetzen oder nicht. In dieser Phase wird jeder Prozess aufgezeichnet und versioniert, um Qualität und Reproduzierbarkeit zu gewährleisten.
 nach Autor
nach Autor
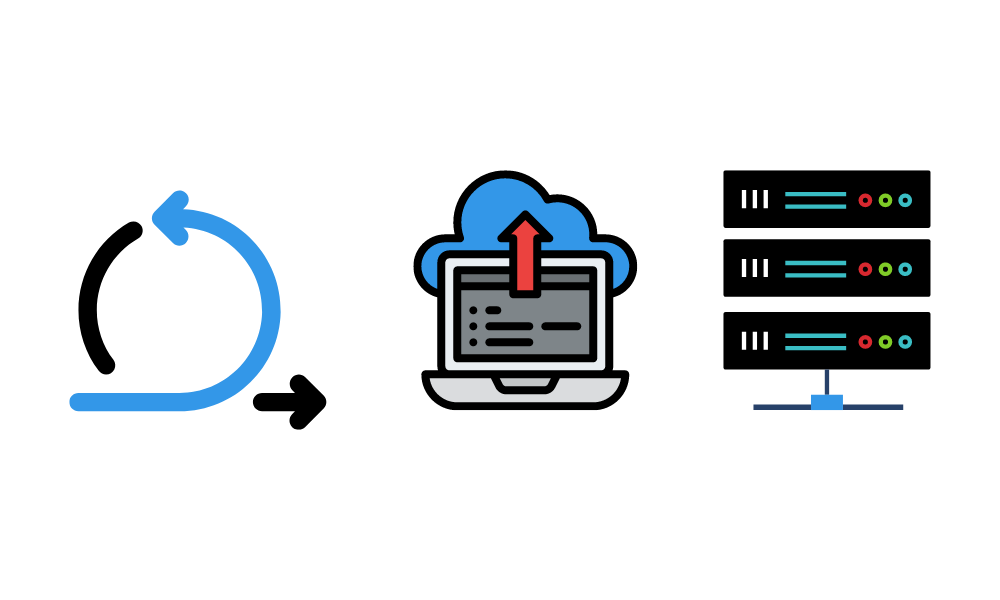
In dieser Phase setzen wir maschinelle Lernmodelle im aktuellen System ein. Zum Beispiel: Einführung einer automatischen Lagerauszeichnung anhand der Form des Produkts. Wir werden ein Computer-Vision-Modell in das aktuelle System einbauen, das die Bilder der Kamera zum Drucken der Etiketten verwendet.
Im Allgemeinen können die Modelle in der Cloud und auf lokalen Servern, im Webbrowser, als Softwarepaket und auf Edge-Geräten eingesetzt werden. Danach kannst du über die API, die Web-App, Plugins oder das Dashboard auf die Vorhersagen zugreifen.
Bei der Bereitstellung definieren wir die Inferenz-Hardware. Wir müssen sicherstellen, dass wir genug Arbeitsspeicher, Speicherplatz und Rechenleistung haben, um schnelle Ergebnisse zu erzielen. Danach werden wir die Leistung des Modells in der Produktion mithilfe von A/B-Tests bewerten, um die Akzeptanz der Nutzer sicherzustellen.
Die Einsatzstrategie ist wichtig. Du musst sicherstellen, dass die Änderungen nahtlos sind und dass sie das Nutzererlebnis verbessert haben. Außerdem sollte ein Projektmanager einen Katastrophenmanagementplan erstellen. Sie sollte eine Ausweichstrategie, ständige Überwachung, die Erkennung von Anomalien und die Minimierung von Verlusten beinhalten.
 des Autors
des Autors
Nach dem Einsatz des Modells in der Produktion müssen wir das System ständig überwachen und verbessern. Wir werden die Modellmetriken, die Leistung der Hard- und Software und die Kundenzufriedenheit überwachen.
Die Überwachung erfolgt völlig automatisch, und die Fachkräfte werden über Anomalien, verringerte Modell- und Systemleistung und schlechte Kundenrezensionen informiert.
Wenn wir eine Meldung über eine verminderte Leistung erhalten, bewerten wir die Probleme und versuchen, das Modell mit neuen Daten zu trainieren oder Änderungen an der Modellarchitektur vorzunehmen. Es ist ein kontinuierlicher Prozess.
In seltenen Fällen müssen wir den gesamten Lebenszyklus des maschinellen Lernens überarbeiten, um die Datenverarbeitung und die Modelltrainingstechniken zu verbessern, neue Software und Hardware zu aktualisieren und ein neues Framework für die kontinuierliche Integration einzuführen.
An den meisten Universitäten lernen die Studierenden der Datenwissenschaften nur etwas über Datenverarbeitung, Modellbildung und -training und in einigen Fällen auch über den Einsatz. Sie werden nicht über die in der Industrie üblichen Qualitätssicherungspraktiken, Techniken zur Datenerfassung und -kennzeichnung, Pipelines für maschinelles Lernen, Datenversionierung, Nachverfolgung von ML-Experimenten und ständige Überwachung und Wartung unterrichtet.
 des Autors
des Autors
Auch wenn du ein Data-Science-Profi bist, musst du lernen, wie die großen fünf Tech-Unternehmen nachhaltige Machine-Learning-Anwendungen für Milliarden von Kunden entwickeln. Du kannst auch lernen, Workflows für maschinelles Lernen in Python zu entwerfen, um Pipelines zu erstellen, die den Test der Zeit bestehen. Du lernst Standard-Workflows, Human-in-the-Loop-Prozesse, Model Lifecycle Management und unbeaufsichtigte Workflows.
In diesem Artikel haben wir etwas über die Projektplanung für maschinelles Lernen gelernt, die auf den Anforderungen und Einschränkungen, der Datenerfassung und -kennzeichnung, der Modellentwicklung, der Modellevaluierung, der Modellbereitstellung sowie der Überwachung und Wartung basiert. Außerdem haben wir verschiedene Methoden gelernt, um die Qualität zu sichern, die Ergebnisse zu reproduzieren und den Prozess im Falle eines Fehlers zu debuggen.
Kurse zum maschinellen Lernen
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nathaniel Taylor-Leach
