Course
Machine Learning with Tree-Based Models in Python
5 hr
116.3K
We usually think that machine learning (ML) projects involve data processing, model training, and model deployment. But it is so much more than that.
We need business and data understanding, data collection techniques, data analytics, model building, and model evaluation. Furthermore, after deployment, we need constant monitoring and maintenance.
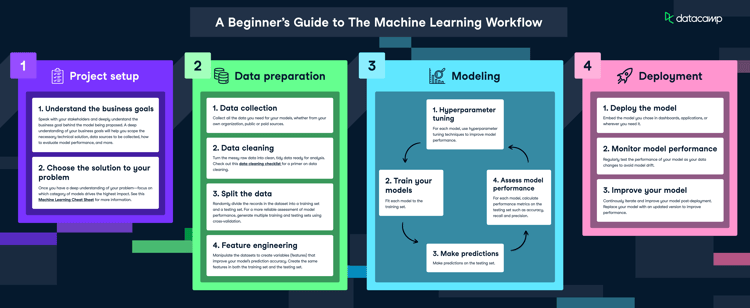
The machine learning life cycle consists of steps that provide structure to the machine learning project and effectively divide the company’s resources. Following these steps helps companies build sustainable, cost-effective, quality AI products.
In this post, we will be using the Cross-Industry Standard Process for the development of Machine Learning applications with Quality assurance methodology (CRISP-ML(Q)) to explain each step in the machine learning life cycle. The CRISP-ML(Q) is an industrial standard for building sustainable machine learning applications.
Each phase in the machine learning cycle follows a quality assurance framework for constant improvement and maintenance by strictly following requirements and constraints. Learn more about quality assurance by reading the CRISP-ML(Q) blog.
For non-technical individuals and managers, check out our short course on Understanding Machine Learning fundamentals. It will help them understand machine learning in general, modeling, and deep learning (AI). You can also explore the differences between AI and machine learning in a separate article.

Image by Author
The planning phase involves assessing the scope, success metric, and feasibility of the ML application. You need to understand the business and how to use machine learning to improve the current process. For example: do we require machine learning? Can we achieve similar requests with simple programming?
You also need to understand the cost-benefit analysis and how you will ship the solution in multiple phases. Furthermore, you need to define clear and measurable success metrics for business, machine learning models (Accuracy, F1 score, AUC), and economic (key performance indicators).
Finally, you need to create a feasibility report.
It will consist of the information about:
Business leaders can learn the fundamentals of machine learning by taking a Machine Learning for Business course and applying these lessons to create business strategies and implement ML solutions.
 Image by Author
Image by Author
The data preparation section is further divided into four parts: data procurement and labeling, cleaning, management, and processing.
We need first to decide how we will collect the data by gathering the internal data, open-source, buying it from the vendors, or generating synthetic data. Each method has pros and cons, and in some cases, we get the data from all four methodologies.
After collection, we need to label the data. Buying cleaned and labeled data is not feasible for all companies, and you may also need to make changes to the data selection during the development process. That is why you cannot buy it in bulk and why the data can eventually be useless for the solution.
The data collection and labeling require most of the company resources: money, time, professionals, subject matter experts, and legal agreements.
Next, we will clean the data by imputing missing values, analyzing wrong-labeled data, removing outliers, and reducing the noise. You will create a data pipeline to automate this process and perform data quality verification.
The data processing stage involves feature selection, dealing with imbalanced classes, feature engineering, data augmentation, and normalizing and scaling the data.
For reproducibility, we will store and version the metadata, data modeling, transformation pipelines, and feature stores.
Finally, we will figure out data storage solutions, data versioning for reproducibility, storing metadata, and creating ETL pipelines. This part will ensure a constant data stream for model training.

Image by Author
In this phase, we will be using all the information from the planning phase to build and train a machine learning model. For example: tracking model metrics, ensuring scalability and robustness, and optimizing storage and compute resources.
We will be focusing on model architecture, code quality, machine learning experiments, model training, and ensembling.
The features, hyperparameters, ML experiments, model architecture, development environment, and metadata are stored and versioned for reproducibility.
Learn about the steps involved in model engineering by taking the Machine Learning Scientist with Python career track. It will help you master the necessary skills to land a job as a machine learning engineer.
 Image by Author
Image by Author
Now that we have finalized the version of the model, it is time to test various metrics. Why? So that we can ensure that our model is ready for production.
We will first test our model on a test dataset and make sure we involve subject matter experts to identify the error in the predictions.
We also need to ensure that we follow industrial, ethical, and legal frameworks for building AI solutions.
Furthermore, we will test our model for robustness on random and real-world data. Making sure that the model inferences fast enough to bring the value.
Finally, we will compare the results with the planned success metrics and decide on whether to deploy the model or not. In this phase, every process is recorded and versioned to maintain quality and reproducibility.
 Image by Author
Image by Author
In this phase, we deploy machine learning models to the current system. For example: introducing automatic warehouse labeling using the shape of the product. We will be deploying a computer vision model into the current system, which will use the images from the camera to print the labels.
Generally, the models can be deployed on the cloud and local server, web browser, package as software, and edge device. After that, you can use API, web app, plugins, or dashboard to access the predictions.
In the deployment process, we define the inference hardware. We need to make sure we have enough RAM, storage, and computing power to produce fast results. After that, we will evaluate the model performance in production using A/B testing, ensuring user acceptability.
The deployment strategy is important. You need to make sure that the changes are seamless and that they have improved the user experience. Moreover, a project manager should prepare a disaster management plan. It should include a fallback strategy, constant monitoring, anomaly detection, and minimizing losses.
 Image by Author
Image by Author
After deploying the model to production we need to constantly monitor and improve the system. We will be monitoring model metrics, hardware and software performance, and customer satisfaction.
The monitoring is done completely automatically, and the professionals are notified about the anomalies, reduced model and system performance, and bad customer reviews.
After we get a reduced performance alert, we will assess the issues and try to train the model on new data or make changes to model architectures. It is a continuous process.
In rare cases, we have to revamp the complete machine learning life cycle to improve the data processing and model training techniques, update new software and hardware, and introduce a new framework for continuous integration.
The data science student in most universities learns only about data processing, model building and training, and in some cases, deployment. They are not taught about standard industrial quality assurance practice, data collection and labeling techniques, machine learning pipelines, data versioning, tracking ML experiments, and constant monitoring and maintenance.
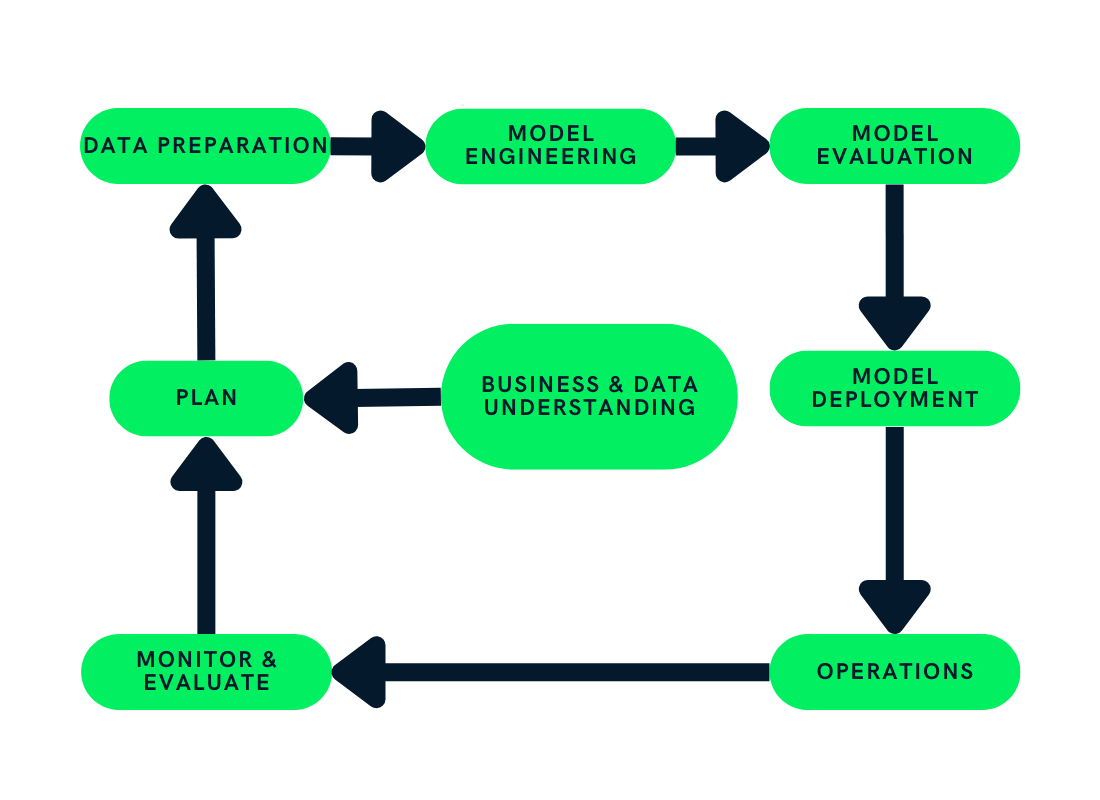 Image by Author
Image by Author
Even if you are a data science professional, you need to learn how the big five tech companies are building sustainable machine learning applications for billions of customers. You can also learn Designing Machine Learning Workflows in Python to build pipelines that stand the test of time. It will teach you standard workflow, human-in-the-loop processes, model lifecycle management, and unsupervised workflow.
In this article, we have learned about machine learning project planning based on requirements and constraints, data collection and labeling, model engineering, model evaluation, model deployment, and monitoring and maintenance. Apart from that, we have learned various ways to maintain quality, reproduce the results, and debug the process in case of failure.
Machine Learning Courses
Course
Course
Course
blog
Josep Ferrer
10 min
blog
DataCamp Team
2 min
Tutorial
Moez Ali
Tutorial
Moez Ali
code-along
Weston Bassler
code-along
George Boorman