
Cours
Principes fondamentaux des mégadonnées avec PySpark
4 h
65.2K
Scala est un langage puissant qui combine la programmation fonctionnelle et la programmation orientée objet. Il est largement utilisé dans le traitement des mégadonnées et les applications web, en raison de sa syntaxe concise, de son évolutivité et de ses performances avantageuses.
L'expertise Scala étant de plus en plus recherchée dans le secteur des données, cet article fournit un guide complet des questions d'entretien Scala, couvrant divers sujets, des concepts de base aux techniques avancées, en passant par les questions relatives à l'ingénierie des données.
Commençons par examiner quelques questions fondamentales d'entretien sur Scala qui évaluent votre compréhension des concepts clés et des avantages de ce langage puissant.
Si vous débutez dans ce langage, nous vous recommandons de commencer par notrecours Introduction à Scalaafin d'acquérir des bases solides avant d'aborder les questions d'entretien.
Le nom Scala provient du terme «scalable » (évolutif). Scala est un langage de programmation à typage statique qui combine les paradigmes de la programmation orientée objet et de la programmation fonctionnelle. Il est concis, expressif et conçu pour pallier de nombreuses lacunes de Java. Par exemple, Scala fonctionne sur la machine virtuelle Java (JVM), ce qui signifie que vous pouvez utiliser les bibliothèques et les frameworks Java sans difficulté.
Alors que Java est strictement orienté objet, Scala permet à la fois la programmation orientée objet et la programmation fonctionnelle. Scala offre également des fonctionnalités avancées telles que l'immuabilité, les fonctions d'ordre supérieur, la correspondance de motifs, et bien d'autres encore, le tout avec une syntaxe concise.
Si vous avez une formation en Java, veuillez consulter lecours Introduction à Java pour revoir les bases. Pour comparer les principes orientés objet en Java et Scala, veuillez essayer le cours Introduction à la POO en Java.
Scala dispose de fonctionnalités puissantes qui le distinguent et le rendent populaire auprès des programmeurs. Voici quelques-unes de ces fonctionnalités :
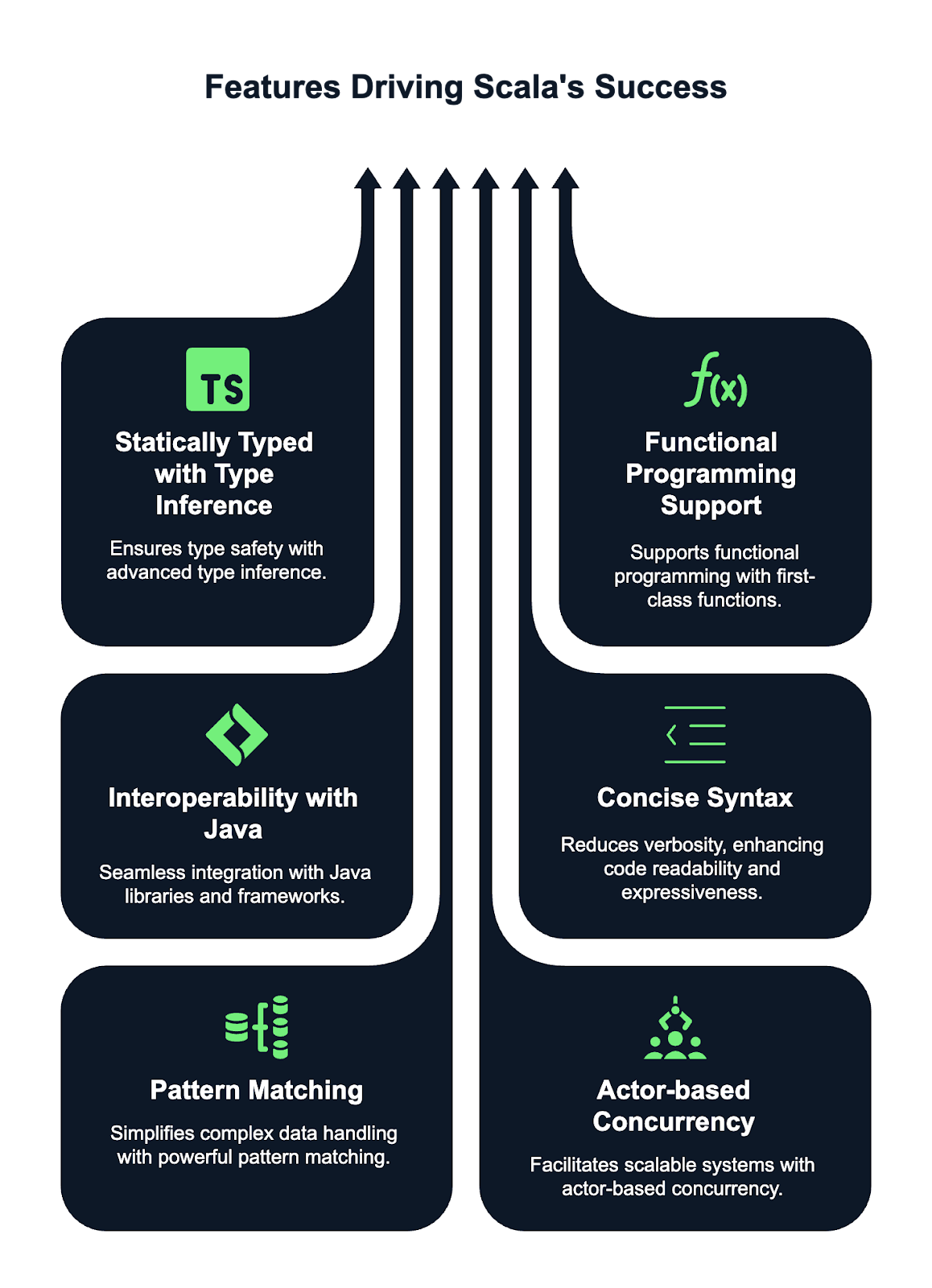
Une classe de cas dans Scala est une classe spéciale optimisée pour être utilisée avec des structures de données immuables. Il fournit automatiquement des implémentations pour des méthodes telles que ` toString`, ` equals` et ` hashCode`. Les classes de cas sont également compatibles avec les modèles, ce qui les rend extrêmement utiles pour traiter les données de manière fonctionnelle.
Les classes de cas sont généralement utilisées pour représenter des objets de données qui ne devraient pas changer après leur création. Je vous ai fourni un exemple ci-dessous :
case class Person(name: String, age: Int)
val person1 = Person("John", 30)Dans Scala, l'immuabilité est encouragée, en particulier pour la programmation fonctionnelle. Vous pouvez déclarer une variable immuable en utilisant « val » (déclaration de variable immuable) par opposition à « var » (déclaration de variable mutable). valUne fois qu'une valeur est attribuée à une variable, il n'est plus possible de la modifier. L'immuabilité conduit à un code plus sûr et plus prévisible, car elle réduit les risques d'effets secondaires indésirables. Veuillez consulter mon exemple ci-dessous :
val name = "Alice"
// Trying to change it will result in a compile-time error
name = "Bob" // Error: reassignment to valUn objet compagnon est un objet qui partage le même nom qu'une classe et qui est défini dans le même fichier. L'objectif principal d'un objet compagnon est de fournir des méthodes et des fonctions étroitement liées à la classe, mais qui ne sont pas liées à une instance de celle-ci.
L'objet compagnon peut contenir des méthodes d'usine ou d'autres fonctions utilitaires, comme dans l'exemple que j'ai écrit ci-dessous :
class Person(val name: String, val age: Int)
object Person {
def apply(name: String, age: Int): Person = new Person(name, age)
}La méthode apply dans l'objet compagnon Person me permet de créer un Person sans utiliser le mot-clé new, comme illustré ci-dessous :
val p = Person("John", 25)En Scala, les mots-clés ` var`, ` val` et ` lazy val ` sont utilisés pour définir des variables, mais ils diffèrent en termes de mutabilité, d'initialisation et de moment d'évaluation.
Une variable d'instance ( var ) est une variable modifiable, ce qui signifie que sa valeur peut être modifiée après son initialisation. Vous pouvez attribuer une nouvelle valeur à une variable : var
var x = 10
x = 20 // ReassignableD'autre part, une référence ( val ) est une référence immuable, ce qui signifie qu'une fois qu'une valeur lui est attribuée, elle ne peut plus être réattribuée, mais l'objet auquel elle fait référence peut toujours être modifiable.
val y = 10
// y = 20 // Error: reassignment to valUne évaluation paresseuse ( lazy val ) est un type particulier d'évaluation ( val ) qui n'est évalué que lors de son premier accès, ce qui est appelé évaluation paresseuse (lazy evaluation) (). Cela peut être utile pour optimiser les performances lorsque vous effectuez des calculs coûteux ou gourmands en ressources.
lazy val z = {
println("Computing z")
42
}Pour approfondir vos connaissances sur les déclarations de variables et les meilleures pratiques dans Scala, veuillez consulter ce tutoriel sur les variables dans Scala.
En Scala, une fonction d'ordre supérieur est une fonction qui prend une ou plusieurs fonctions comme paramètres ou qui renvoie une fonction comme résultat. Ce concept permet de traiter les fonctions comme des valeurs de premier ordre, ce qui offre une plus grande flexibilité et abstraction dans votre code.
Les fonctions d'ordre supérieur permettent de transmettre et de personnaliser les comportements, rendant ainsi le code plus modulaire, réutilisable et expressif.
Ci-dessous, je vous présente un exemple de fonction d'ordre supérieur qui accepte une autre fonction comme argument :
// Define a higher-order function that takes a function as a parameter
def applyFunction(f: Int => Int, x: Int): Int = f(x)
// Call the higher-order function with a function that multiplies the input by 2
val result = applyFunction(x => x * 2, 5) // 10Dans ce cas, applyFunction est une fonction d'ordre supérieur qui prend une fonction f, qui multiplie par 2, et l'applique à 5.
En Scala, l'String e est immuable, ce qui signifie que les modifications créent de nouveaux objets, ce qui peut s'avérer inefficace en cas de changements répétés. Il convient aux opérations sur les chaînes peu fréquentes.
En revanche, StringBuilder est mutable, ce qui permet d'effectuer des modifications sur place sans créer de nouveaux objets. Cela rend plus efficaces les manipulations fréquentes de chaînes, telles que l'ajout ou la modification de contenu.
Je recommande d'utiliser String lorsque l'immuabilité est préférable et que les performances ne sont pas essentielles, et d'opter pour StringBuilder lorsque vous avez besoin de meilleures performances dans des scénarios impliquant de multiples modifications de chaînes.
L'annotation ` @tailrec ` est utilisée pour marquer une méthode comme récursive en queue, ce qui signifie que l'appel récursif est la dernière opération de la méthode. Cela permet au compilateur Scala d'optimiser la méthode afin d'éviter les erreurs de débordement de pile en transformant la récursivité en boucle. Si la méthode n'est pas récursive en queue, le compilateur générera une erreur.
Veuillez considérer l'exemple suivant :
@tailrec
def factorial(n: Int, accumulator: Int = 1): Int = {
if (n <= 0) accumulator
else factorial(n - 1, n * accumulator)
}Après avoir abordé les notions de base, passons à des questions d'entretien de niveau intermédiaire sur Scala qui vous aideront à mieux comprendre le fonctionnement du langage.
En Scala, ` map`, ` flatMap` et ` foreach ` sont des fonctions d'ordre supérieur utilisées sur des collections, mais elles ont des objectifs différents.
map transforme chaque élément d'une collection et renvoie une nouvelle collection de même taille contenant les éléments transformés. flatMap transforme également chaque élément, mais aplatit la structure résultante, ce qui le rend utile lorsque la transformation elle-même aboutit à des collections. foreach est utilisé pour les effets secondaires, en appliquant une fonction à chaque élément sans renvoyer quoi que ce soit, couramment utilisé pour des opérations telles que l'impression ou la mise à jour d'états externes.La correspondance de motifs dans Scala est une fonctionnalité puissante qui permet de comparer des valeurs à des motifs, rendant ainsi le code plus expressif et concis. Il est similaire aux instructions « switch » ou « case » dans d'autres langages, mais il est plus flexible et peut être utilisé avec divers types, tels que les entiers, les chaînes de caractères, les listes et même les structures de données complexes. Il peut être utilisé avec des expressions de type « match », qui comparent la valeur d'une expression à plusieurs modèles.
Voici quelques cas d'utilisation de la correspondance de motifs :
Some ou None dans Option, permettant une gestion concise des valeurs pouvant être nulles.Voici un exemple que j'ai laissé :
// Define a variable x with value 3
val x = 3
// Pattern matching on the value of x
x match {
// If 'x' is equal to 1, print "One"
case 1 => println("One")
// If 'x' is equal to 2, print "Two"
case 2 => println("Two")
// If 'x' doesn't match any of the above cases, print "Other"
case _ => println("Other")
}En Scala, l'interface « Option » est un type de conteneur utilisé pour représenter une valeur qui peut exister ou non, ce qui permet d'éviter les valeurs d'null s et les exceptions de pointeur nul. Il existe deux sous-types : Some et None.
Some indique la présence d'une valeur valide, tandis que None signale l'absence de valeur. Cela permet aux développeurs de gérer explicitement les cas où une valeur pourrait être manquante, favorisant ainsi un code plus sûr et plus fonctionnel.
Option est fréquemment utilisé dans les méthodes susceptibles de ne pas renvoyer de résultat, ce qui réduit le besoin de vérifications null sujettes à erreur.
Veuillez examiner le code ci-dessous :
// Function that returns an Option
def findFirstEvenNumber(list: List[Int]): Option[Int] = {
list.find(_ % 2 == 0) // Returns Some(number) if an even number is found, otherwise None
}
// Example usage:
val numbers = List(1, 3, 5, 7, 8)
val result = findFirstEvenNumber(numbers)
result match {
case Some(number) => println(s"Found an even number: $number") // Output: Found an even number: 8
case None => println("No even number found")
}Scala propose un ensemble complet de collections classées en types modifiables et immuables.
List, Set, Map et Vector, ne peuvent pas être modifiées après leur création, ce qui favorise les pratiques de programmation fonctionnelle.ArrayBuffer, HashSet et HashMap, permettent des modifications. Les collections sont extrêmement flexibles et prennent en charge diverses opérations telles que le filtrage, le mappage et le pliage. La bibliothèque standard propose également des collections spécialisées telles que Queue, Stack et SortedSet, qui répondent efficacement à différents besoins en matière de manipulation de données. Les collections immuables sont privilégiées pour la sécurité des threads et la pureté fonctionnelle.
En Scala, les paramètres implicites sont des valeurs que le compilateur transmet automatiquement à une méthode ou à un constructeur sans les spécifier explicitement. Ils sont marqués avec le mot-clé ` implicit ` et sont généralement utilisés pour des éléments tels que l'injection de dépendances, la configuration ou le passage de contexte.
// Define a function that takes an implicit parameter 'name' of type String
def greet(implicit name: String) = s"Hello, $name"
// Define an implicit value 'myName' of type String in the scope
implicit val myName = "Alice"
// Call the greet function without explicitly passing 'name'
// The compiler automatically uses the implicit value 'myName'
println(greet) // Output: "Hello, Alice"En Scala, les objets de type « traits » sont similaires aux objets « interfaces » en Java, mais avec des capacités supplémentaires. Un trait est un composant réutilisable qui peut être intégré à des classes ou à d'autres traits. Il vous permet de définir à la fois des méthodes abstraites et des méthodes concrètes. Les traits peuvent également conserver leur état, contrairement aux interfaces Java, qui ne peuvent définir que des signatures de méthodes.
Scala permet de combiner plusieurs traits dans une seule classe, ce qui rend possible l'héritage multiple, tandis que Java autorise l'implémentation de plusieurs interfaces, mais une seule classe, ce qui limite la flexibilité de l'héritage.
Voici un exemple :
trait Logger {
def log(message: String): Unit = println(s"Log: $message")
}Le REPL Scala est un shell interactif qui permet d'écrire et d'évaluer du code Scala en temps réel. Le processus se déroule en quatre étapes :
Ce processus permet d'expérimenter et de tester rapidement du code Scala, ce qui en fait un outil puissant pour l'apprentissage, le débogage et le prototypage en Scala. Vous pouvez définir des variables et des fonctions, et explorer des bibliothèques de manière interactive.

Figure : Le REPL Scala est un interpréteur en ligne de commande que vous pouvez utiliser pour tester votre code Scala comme un espace de travail. Source : Documentation Scala
Pour ceux qui aspirent à des postes plus élevés ou qui souhaitent démontrer une compréhension plus approfondie de Scala, nous allons explorer quelques questions d'entretien avancées qui abordent le traitement des calculs asynchrones et la concurrence, ainsi que les structures et conversions complexes.
Ces questions évalueront votre expertise en programmation fonctionnelle, en concurrence et en conception de systèmes évolutifs.
Dans Scala, les méthodes ` Future ` et ` Await ` sont toutes deux liées au traitement des calculs asynchrones, mais elles ont des objectifs différents.
Future représente un calcul qui aboutira à un résultat ou à une exception. Cela permet à d'autres tâches de se poursuivre pendant l'attente du résultat du calcul. Await Future est utilisé pour bloquer le thread actuel jusqu'à ce que le résultat d'une opération soit disponible. Cela oblige un thread à attendre la fin d'une opération d'Future. Il est fréquemment utilisé lorsque vous devez synchroniser et attendre le résultat dans un contexte non asynchrone.Je vous présente ici quelques exemples d'utilisation de ces fonctionnalités :
import scala.concurrent.Future
import scala.concurrent.ExecutionContext.Implicits.global
import scala.concurrent.Await
import scala.concurrent.duration._
val futureValue = Future { 42 } // A Future that computes the value 42 asynchronously.
val result = Await.result(futureValue, 2.seconds) // Blocks the thread for up to 2 seconds, waiting for the result of the Future.Scala gère la concurrence à l'aide de mécanismes de bas niveau tels que les threads et d'abstractions de haut niveau telles que Futures et Promises pour la programmation asynchrone.
La bibliothèque standard comprend scala.concurrent.Future, qui permet des calculs non bloquants, et ExecutionContext pour la gestion des threads d'exécution.
Pour une concurrence plus avancée, Akka est largement utilisé, fournissant des outils pour construire des systèmes distribués hautement concurrents à l'aide du modèle Actor. De plus, des bibliothèques telles que Cats Effect et ZIO proposent des approches de programmation fonctionnelle pour gérer la concurrence, fournissant des abstractions sûres et composables pour gérer les effets secondaires, les tâches asynchrones et les ressources.
Les monades constituent un modèle de conception utilisé pour gérer les calculs de manière structurée, en particulier lorsqu'il s'agit d'effets secondaires tels que les opérations asynchrones ou les valeurs nullables. Une monade permet d'encapsuler une valeur et d'appliquer des transformations tout en conservant la structure. En Scala, Option et Future sont des exemples de monades.
val result = Some(5).flatMap(x => Some(x * 2))Le framework Akka en Scala est conçu pour simplifier la création de systèmes distribués, concurrents et tolérants aux pannes. Il utilise l'approche orientée acteur ( Actor model), dans laquelle chaque acteur est une unité légère et indépendante qui communique de manière asynchrone par le biais de messages.
Akka masque les détails de bas niveau liés à la concurrence, permettant ainsi aux développeurs de se concentrer sur la logique métier. Il prend en charge les systèmes distribués en permettant aux acteurs de fonctionner sur différents nœuds. Le module Cluster d'Akka facilite la communication transparente, l'équilibrage de charge et la résilience, ce qui le rend idéal pour les systèmes évolutifs et hautement disponibles.
Dans Scala, les conversions implicites permettent la transformation automatique d'un type en un autre. Ils sont définis à l'aide du mot-clé « implicit » et permettent d'effectuer des opérations entre des types qui ne seraient normalement pas compatibles. Le compilateur effectue des conversions implicites lorsque cela est nécessaire, ce qui réduit le code répétitif.
À titre d'exemple, je vous montre comment convertir automatiquement un String en Int lors de l'exécution d'opérations arithmétiques :
implicit def intToString(x: Int): String = x.toString
val str: String = 42 // Implicitly converted to “42”En Scala, la variance de type fait référence à la manière dont les sous-types d'un type générique sont liés les uns aux autres. Il est contrôlé à l'aide de paramètres de type covariant (+), contravariant (-) et invariant (=).
List[+A] signifie qu'une List de type A peut être utilisée partout où une List d'un supertype de A est attendue. Exemple : List[Dog] peut être utilisé comme List[Animal] si Dog étend Animal.Function1[-A, +B] signifie qu'une application Function1 peut accepter un supertype de A et renvoyer un sous-type de B. Exemple : Function1[Animal, Dog] peut être utilisé comme Function1[Dog, Dog].List[A] est invariant, ce qui signifie que List[Dog] et List[Animal] ne sont pas interchangeables.Si vous postulez pour un poste d'ingénieur de données, attendez-vous à des questions évaluant votre capacité à concevoir, optimiser et dépanner des applications Scala dans un environnement de production. Examinons quelques questions d'entretien typiques auxquelles vous pourriez être confronté.
Pour définir une annotation personnalisée dans Scala, il est nécessaire de créer une classe qui étend l'scala.annotation.Annotation. Cette classe utilise des paramètres de constructeur pour stocker des métadonnées. Les annotations sont ensuite appliquées aux classes, méthodes ou champs à l'aide de l'@symbol.
J'ai constaté qu'une fonctionnalité utile des annotations est que les annotations personnalisées sont accessibles lors de l'exécution à l'aide de la réflexion pour récupérer leurs métadonnées, généralement via getAnnotations ou des méthodes similaires.
import scala.annotation.StaticAnnotation
class MyAnnotation extends StaticAnnotation
@MyAnnotation class MyClassScala est le langage natif d'Apache Spark, offrant une intégration transparente et des performances élevées.
Il est utilisé pour écrire des tâches de traitement de données distribuées, en tirant parti des fonctionnalités principales de Spark telles que les RDD (Resilient Distributed Datasets), les DataFrame et les Datasets. Avec Scala, vous pouvez créer et manipuler de grands ensembles de données, appliquer des transformations et exécuter efficacement des opérations complexes sur un cluster.
L'API Scala de Spark propose une syntaxe concise et expressive pour gérer les tâches liées au Big Data, du traitement par lots aux pipelines d'apprentissage automatique, permettant ainsi l'analyse et le traitement de données à grande échelle en parallèle.
Vous pourriez également être intéressé par l'apprentissage de PySpark depuis le début. Ce guide complet sur PySpark constitue unexcellent point de départ.
Dans Spark, les RDD (Resilient Distributed Datasets) constituent l'abstraction de bas niveau, représentant des données distribuées pouvant être traitées en parallèle. Les DataFrame sont des abstractions de niveau supérieur construites à partir des RDD, offrant une gestion structurée des données avec une exécution optimisée à l'aide de l'optimiseur Catalyst de Spark.
Les ensembles de données combinent les avantages des RDD et des DataFrame, offrant la sécurité de type des RDD tout en fournissant les optimisations des DataFrame. Les ensembles de données sont fortement typés, tandis que les DataFrame ne sont pas typés, ce qui permet des transformations et des actions plus efficaces dans Spark.
Une tâche Spark de base en Scala implique :
SparkSession.Voici un exemple :
// Import the SparkSession class which is the entry point for Spark SQL
import org.apache.spark.sql.SparkSession
// Create a SparkSession.
val spark = SparkSession.builder.appName("MySparkApp").getOrCreate()
// Read the input text file as a DataFrame.
val data = spark.read.text("data.txt")
// Perform the transformation on the text file
val wordCount = textFile.flatMap(_.split(" ")).groupByKey(identity).count()
wordCount.show()Les transformations dans Spark sont des opérations qui définissent un nouveau RDD, DataFrame ou Dataset, comme map(), filter() ou groupBy(). Ils sont évalués de manière différée, ce qui signifie qu'ils ne sont exécutés qu'une fois qu'une action est déclenchée.
Les actions sont des opérations qui déclenchent l'exécution, telles que collect(), count() ou save(). Les transformations sont appliquées aux données de manière différée, tandis que les actions obligent Spark à exécuter le DAGd'opérations et àrenvoyer un résultat ou à conserver les données.
Dans Spark, l'évaluation paresseuse signifie que les transformations ne sont pas exécutées immédiatement. Au lieu de cela, Spark élabore un plan d'exécution (DAG) et n'exécute les calculs que lorsqu'une action est appelée. Cela permet à Spark d'optimiser l'exécution en minimisant le brassage des données, en combinant les opérations et en appliquant les filtres plus tôt dans le pipeline de traitement.
L'optimisation des tâches Spark implique plusieurs stratégies, telles que la réduction du brassage des données, la mise en cache des résultats intermédiaires et l'utilisation d'un partitionnement approprié.
Voici quelques-unes des stratégies que je recommande d'utiliser pour optimiser les tâches Spark :
groupBy).Les défis courants rencontrés dans Scala pour les projets Big Data comprennent la gestion de la mémoire et des performances pour les grands ensembles de données, le traitement des asymétries de données et la gestion efficace des défaillances dans les environnements distribués.
Le débogage des tâches Spark peut s'avérer complexe en raison de la nature des systèmes distribués et de l'évaluation paresseuse. De plus, l'optimisation des tâches Spark afin d'éviter les goulots d'étranglement et de réduire les frais généraux nécessite souvent un réglage précis des configurations et une bonne compréhension du plan d'exécution sous-jacent.
De plus, la gestion des formats de données incohérents, des problèmes de qualité des données et de la complexité de l'écriture et de la maintenance d'un code évolutif peut s'avérer difficile dans les scénarios de mégadonnées.
Dans cet article, nous avons abordé un large éventail de questions d'entretien sur Scala, couvrant des sujets de niveau débutant, intermédiaire et avancé. De la compréhension des concepts fondamentaux et des avantages de Scala à l'exploration d'optimisations, de manipulations et de conversions plus complexes, nous avons examiné les domaines clés sur lesquels les employeurs potentiels pourraient s'interroger.
Afin de consolider votre préparation, nous vous invitons à commencer à vous exercer avec notre cours Introduction à Scala ou à suivre une formation de remise à niveau rapide. Vous vous préparez à assumer un double rôle Java-Scala ? Nous vous invitons à consulter notre guide des questions d'entretien Java pour obtenir une perspective complète.
Veuillez approfondir vos connaissances sur Scala et l'ingénierie des données grâce à ces cours.
Cours
Cours
Cours