
Curso
Fundamentos de Big Data com PySpark
4 h
65.2K
Scala é uma linguagem poderosa que combina programação funcional e orientada a objetos. É muito usado no processamento de big data e em aplicativos web, por causa da sua sintaxe simples, escalabilidade e vantagens de desempenho.
Como o conhecimento em Scala está cada vez mais em alta na indústria de dados, este artigo vai te dar um guia completo com perguntas de entrevista sobre Scala, cobrindo vários assuntos, desde conceitos básicos até técnicas avançadas e perguntas sobre engenharia de dados.
Vamos começar explorando algumas perguntas fundamentais da entrevista sobre Scala que avaliam sua compreensão dos conceitos básicos e das vantagens dessa poderosa linguagem.
Se você é novo na linguagem, comece com nossocurso Introdução ao Scalapara construir uma base sólida antes de responder às perguntas da entrevista.
O nome Scala vem da palavra escalável. Scala é uma linguagem de programação estaticamente tipada que junta paradigmas de programação orientada a objetos e funcional. É conciso, expressivo e feito pra resolver várias das falhas do Java. Por exemplo, o Scala roda na Máquina Virtual Java (JVM), o que significa que você pode usar bibliotecas e frameworks Java sem problemas.
Enquanto Java é estritamente orientado a objetos, Scala permite tanto a programação orientada a objetos quanto a funcional. O Scala também oferece recursos avançados como imutabilidade, funções de ordem superior, correspondência de padrões e muito mais, tudo com uma sintaxe bem direta.
Se você tem experiência com Java, dê uma olhada nocurso Introdução ao Java para revisar os fundamentos. Pra comparar os princípios orientados a objetos em Java e Scala, dá uma olhada no curso Introdução à POO em Java.
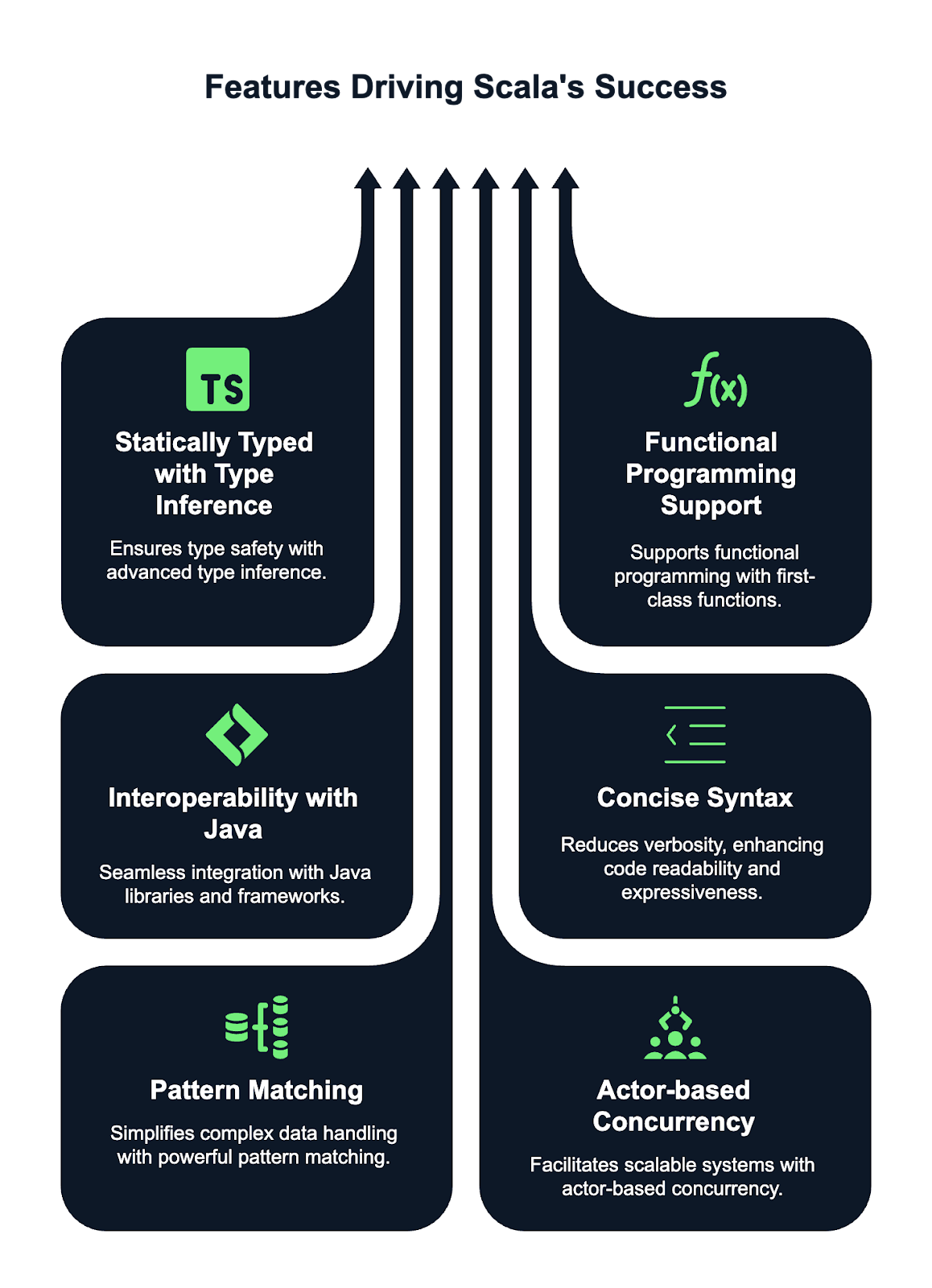
O Scala tem algumas funcionalidades poderosas que o fazem se destacar e ser popular entre os programadores. Aqui estão algumas dessas funcionalidades:
Uma classe de caso em Scala é uma classe especial otimizada para uso com estruturas de dados imutáveis. Ele automaticamente fornece implementações para métodos como ` toString`, ` equals` e ` hashCode`. As classes de caso também podem ser comparadas com padrões, o que as torna super úteis para lidar com dados de um jeito funcional.
Normalmente, você usa classes de caso para representar objetos de dados que não devem mudar depois de criados. Deixei um exemplo pra você aqui embaixo:
case class Person(name: String, age: Int)
val person1 = Person("John", 30)Em Scala, a imutabilidade é incentivada, especialmente para programação funcional. Você pode declarar uma variável imutável usando ` val `, em vez de ` var`, que é mutável. Depois de atribuir um valor a um val, ele não pode ser alterado. A imutabilidade torna o código mais seguro e previsível, já que dá menos espaço para efeitos colaterais indesejados. Dá uma olhada no meu exemplo abaixo:
val name = "Alice"
// Trying to change it will result in a compile-time error
name = "Bob" // Error: reassignment to valUm objeto companheiro é um objeto que tem o mesmo nome de uma classe e é definido no mesmo arquivo. O principal objetivo de um objeto companheiro é fornecer métodos e funções que estão intimamente relacionados à classe, mas não estão vinculados a uma instância dela.
O objeto companheiro pode conter métodos de fábrica ou outras funções utilitárias, como no exemplo que escrevi abaixo:
class Person(val name: String, val age: Int)
object Person {
def apply(name: String, age: Int): Person = new Person(name, age)
}O método apply no objeto complementar Person me permite criar um Person sem usar a palavra-chave new, como mostro abaixo:
val p = Person("John", 25)Em Scala, as palavras-chave ` var`, ` val` e ` lazy val ` são usadas para definir variáveis, mas elas diferem em termos de mutabilidade, inicialização e momento de avaliação.
Uma variável mutável ( var ) é uma variável cujo valor pode ser alterado depois de inicializado. Você pode atribuir um novo valor a um objeto ` var`:
var x = 10
x = 20 // ReassignablePor outro lado, uma referência imutável ( val ) é uma referência que não pode ser alterada, ou seja, uma vez que um valor é atribuído a ela, não pode ser reatribuído, mas o objeto ao qual ela se refere ainda pode ser mutável.
val y = 10
// y = 20 // Error: reassignment to valUma expressão preguiçosa ( lazy val ) é um tipo especial de expressão ( val ) que só é avaliada quando acessada pela primeira vez, o que é chamado de avaliação preguiçosa (lazy evaluation). Isso pode ser útil para otimizar o desempenho quando você estiver lidando com cálculos caros ou que exigem muitos recursos.
lazy val z = {
println("Computing z")
42
}Pra saber mais sobre declarações de variáveis e as melhores práticas em Scala, dá uma olhada nesse tutorial sobre Variáveis em Scala.
Em Scala, uma função de ordem superior é uma função que recebe uma ou mais funções como parâmetros ou retorna uma função como resultado. Esse conceito permite que as funções sejam tratadas como valores de primeira classe, proporcionando maior flexibilidade e abstração no seu código.
As funções de ordem superior permitem que os comportamentos sejam passados e personalizados, tornando o código mais modular, reutilizável e expressivo.
Abaixo, deixei um exemplo de uma função de ordem superior que aceita outra função como argumento:
// Define a higher-order function that takes a function as a parameter
def applyFunction(f: Int => Int, x: Int): Int = f(x)
// Call the higher-order function with a function that multiplies the input by 2
val result = applyFunction(x => x * 2, 5) // 10Nesse caso, applyFunction é uma função de ordem superior que pega uma função f, que multiplica por 2, e aplica isso a 5.
Em Scala, String é imutável, o que significa que as modificações criam novos objetos, o que pode ser ineficiente para alterações repetidas. É ideal para operações de cadeia de caracteres que não são muito frequentes.
Por outro lado, StringBuilder é mutável, permitindo modificações no local sem criar novos objetos. Isso torna mais eficiente as manipulações frequentes de strings, como adicionar ou modificar conteúdo.
Eu recomendo usar String quando a imutabilidade é preferível e o desempenho não é crítico, e optar por StringBuilder quando você precisa de melhor desempenho em cenários que envolvem várias modificações de strings.
A anotação ` @tailrec ` é usada para marcar um método como recursivo de cauda, o que significa que a chamada recursiva é a última operação no método. Isso permite que o compilador Scala otimize o método para evitar erros de estouro de pilha, transformando a recursão em um loop. Se o método não for recursivo, o compilador vai dar um erro.
Vamos ver um exemplo:
@tailrec
def factorial(n: Int, accumulator: Int = 1): Int = {
if (n <= 0) accumulator
else factorial(n - 1, n * accumulator)
}Depois de ver o básico, vamos passar para algumas perguntas de nível intermediário sobre Scala que te ajudam a entender melhor como a linguagem funciona.
Em Scala, map, flatMap e foreach são funções de ordem superior usadas em coleções, mas têm finalidades diferentes.
map Transforma cada elemento de uma coleção e retorna uma nova coleção do mesmo tamanho com os elementos transformados. flatMap também transforma cada elemento, mas achata a estrutura resultante, o que o torna útil quando a transformação em si resulta em coleções. foreach é usado para efeitos colaterais, aplicando uma função a cada elemento sem retornar nada, comumente usado para operações como imprimir ou atualizar estados externos.A correspondência de padrões no Scala é um recurso poderoso que permite comparar valores com padrões, tornando o código mais expressivo e conciso. É parecido com as instruções “ switch ” ou “ case ” em outras linguagens, mas é mais flexível e pode ser usado com vários tipos, como inteiros, strings, listas e até estruturas de dados complexas. Pode ser usado com expressões de correspondência ( match ), que comparam o valor de uma expressão com vários padrões.
Alguns casos de uso para correspondência de padrões incluem:
Some ) ou nulos permitidos ( None ) em Option, o que permite lidar com valores nulos de forma mais simples.Aqui, deixei um exemplo:
// Define a variable x with value 3
val x = 3
// Pattern matching on the value of x
x match {
// If 'x' is equal to 1, print "One"
case 1 => println("One")
// If 'x' is equal to 2, print "Two"
case 2 => println("Two")
// If 'x' doesn't match any of the above cases, print "Other"
case _ => println("Other")
}Em Scala, o tipo de contêiner ` Option ` é usado pra representar um valor que pode ou não existir, ajudando a evitar valores nulos ( null ) e exceções de ponteiro nulo (null pointer exceptions). Tem dois subtipos: Some e None.
Some envolve um valor válido, indicando a presença de um valor, enquanto None significa a ausência de um valor. Isso permite que os desenvolvedores lidem explicitamente com casos em que um valor pode estar faltando, promovendo um código mais seguro e funcional.
Option é frequentemente usado em métodos que podem não retornar um resultado, reduzindo a necessidade de verificações nulas propensas a erros.
Dá uma olhada no código abaixo:
// Function that returns an Option
def findFirstEvenNumber(list: List[Int]): Option[Int] = {
list.find(_ % 2 == 0) // Returns Some(number) if an even number is found, otherwise None
}
// Example usage:
val numbers = List(1, 3, 5, 7, 8)
val result = findFirstEvenNumber(numbers)
result match {
case Some(number) => println(s"Found an even number: $number") // Output: Found an even number: 8
case None => println("No even number found")
}O Scala oferece um conjunto completo de coleções, divididas em tipos mutáveis e imutáveis.
List, Set, Map e Vector, não podem ser modificadas depois de criadas, o que ajuda nas práticas de programação funcional.ArrayBuffer, HashSet e HashMap, permitem modificações. As coleções são super flexíveis, dando suporte a várias operações, como filtragem, mapeamento e dobragem. A biblioteca padrão também oferece coleções especializadas como Queue, Stack e SortedSet, atendendo a diferentes necessidades de manipulação de dados de forma eficiente. Coleções imutáveis são as preferidas por segurança de thread e pureza funcional.
Em Scala, os parâmetros implícitos são valores que o compilador passa automaticamente para um método ou construtor sem precisar especificá-los explicitamente. Eles são marcados com a palavra-chave ` implicit ` e geralmente são usados para coisas como injeção de dependência, configuração ou passagem de contexto.
// Define a function that takes an implicit parameter 'name' of type String
def greet(implicit name: String) = s"Hello, $name"
// Define an implicit value 'myName' of type String in the scope
implicit val myName = "Alice"
// Call the greet function without explicitly passing 'name'
// The compiler automatically uses the implicit value 'myName'
println(greet) // Output: "Hello, Alice"Em Scala, os objetos de lista ( traits ) são parecidos com os objetos de lista ( interfaces ) em Java, mas com recursos extras. Uma característica é um componente reutilizável que pode ser misturado em classes ou outras características. Permite definir métodos abstratos e métodos concretos. Os traços também podem manter o estado, ao contrário das interfaces Java, que só podem definir assinaturas de métodos.
O Scala dá pra juntar várias características numa única classe, o que permite herança múltipla, enquanto o Java deixa implementar várias interfaces, mas só uma classe, o que limita a flexibilidade da herança.
Aqui vai um exemplo:
trait Logger {
def log(message: String): Unit = println(s"Log: $message")
}O Scala REPL é um shell interativo que permite escrever e avaliar código Scala em tempo real. Funciona em quatro etapas:
Esse processo permite experimentar e testar rapidamente o código Scala, tornando-o uma ferramenta poderosa para aprender, depurar e criar protótipos em Scala. Você pode definir variáveis e funções, além de explorar bibliotecas de forma interativa.

Figura: O Scala REPL é um interpretador de linha de comando que você pode usar para testar seu código Scala como uma área de testes. Fonte: Documentação Scala
Pra quem tá procurando cargos mais altos ou quer mostrar que entende bem de Scala, vamos ver algumas perguntas avançadas de entrevista que falam sobre como lidar com cálculos assíncronos e concorrência, além de estruturas e conversões complexas.
Essas perguntas vão avaliar sua experiência em programação funcional, concorrência e design de sistemas escaláveis.
Em Scala, Future e Await estão ambos relacionados com o tratamento de cálculos assíncronos, mas têm finalidades diferentes.
Future representa um cálculo que vai acabar com um resultado ou uma exceção. Permite que outras tarefas continuem enquanto se aguarda o resultado do cálculo. Await é usado para bloquear o thread atual até que o resultado de um Future esteja disponível. Isso faz com que um thread espere até que uma operação de bloqueio/desbloqueio ( Future) seja concluída. É frequentemente usado quando você precisa sincronizar e aguardar o resultado em um contexto não assíncrono.Aqui estão alguns exemplos de como usar essas funcionalidades:
import scala.concurrent.Future
import scala.concurrent.ExecutionContext.Implicits.global
import scala.concurrent.Await
import scala.concurrent.duration._
val futureValue = Future { 42 } // A Future that computes the value 42 asynchronously.
val result = Await.result(futureValue, 2.seconds) // Blocks the thread for up to 2 seconds, waiting for the result of the Future.O Scala lida com a concorrência usando tanto mecanismos de baixo nível, como threads, quanto abstrações de alto nível, como Futures e Promises para programação assíncrona.
A biblioteca padrão inclui scala.concurrent.Future, que permite cálculos sem bloqueio, e ExecutionContext para gerenciar threads de execução.
Para uma concorrência mais avançada, o Akka é muito usado, oferecendo ferramentas para criar sistemas distribuídos altamente concorrentes usando o modelo Actor. Além disso, bibliotecas como Cats Effect e ZIO oferecem abordagens de programação funcional para lidar com a concorrência, fornecendo abstrações seguras e composíveis para gerenciar efeitos colaterais, tarefas assíncronas e recursos.
Monads são um padrão de design usado para lidar com cálculos de forma estruturada, especialmente quando se trata de efeitos colaterais, como operações assíncronas ou valores nulos. Uma mônada é uma maneira de envolver um valor e aplicar transformações, mantendo a estrutura. Em Scala, Option e Future são exemplos de monads.
val result = Some(5).flatMap(x => Some(x * 2))A estrutura Akka em Scala foi criada pra facilitar a construção de sistemas distribuídos, simultâneos e tolerantes a falhas. Ele usa o Modelo de Ator/Mesa ( Actor model), onde cada ator é uma unidade leve e independente que se comunica de forma assíncrona através da passagem de mensagens.
O Akka abstrai os detalhes de concorrência de baixo nível, permitindo que os desenvolvedores se concentrem na lógica de negócios. Ele dá suporte a sistemas distribuídos, permitindo que os atores funcionem em diferentes nós. O módulo Cluster da Akka facilita a comunicação sem interrupções, o balanceamento de carga e a resiliência, tornando-o ideal para sistemas escaláveis e altamente disponíveis.
Em Scala, as conversões implícitas permitem a transformação automática de um tipo em outro. Eles são definidos usando a palavra-chave ` implicit ` e são usados para permitir operações entre tipos que normalmente não seriam compatíveis. O compilador faz conversões implícitas quando precisa, reduzindo o código repetitivo.
Como exemplo, vou mostrar como converter um String para um Int automaticamente ao fazer operações aritméticas:
implicit def intToString(x: Int): String = x.toString
val str: String = 42 // Implicitly converted to “42”Em Scala, a variância de tipos é como os subtipos de um tipo genérico se relacionam entre si. É controlado usando parâmetros de tipo covariantes (+), contravariantes (-) e invariantes (=).
List[+A] significa que um List do tipo A pode ser usado sempre que um List de um supertipo de A for esperado. Exemplo: List[Dog] pode ser usado como List[Animal] se Dog estender Animal.Function1[-A, +B] significa que um Function1 pode aceitar um supertipo de A e retornar um subtipo de B. Exemplo: Function1[Animal, Dog] pode ser usado como Function1[Dog, Dog].List[A] é invariável, o que significa que List[Dog] e List[Animal] não são intercambiáveis.Se você estiver sendo entrevistado para uma vaga de engenheiro de dados, espere perguntas que avaliem sua capacidade de projetar, otimizar e solucionar problemas em aplicativos Scala em um ambiente de produção. Vamos ver algumas perguntas típicas que você pode encontrar numa entrevista.
Para definir uma anotação personalizada em Scala, você precisa criar uma classe que estenda scala.annotation.Annotation. Essa classe usa parâmetros do construtor para guardar metadados. As anotações são então aplicadas a classes, métodos ou campos com o comando ` @symbol`.
Descobri que uma característica útil das anotações é que as anotações personalizadas podem ser acessadas em tempo de execução usando reflexão para recuperar seus metadados, normalmente através de getAnnotations ou métodos parecidos.
import scala.annotation.StaticAnnotation
class MyAnnotation extends StaticAnnotation
@MyAnnotation class MyClassScala é a linguagem nativa do Apache Spark, oferecendo integração perfeita e alto desempenho.
É usado para escrever tarefas de processamento de dados distribuídos, aproveitando os recursos principais do Spark, como RDDs (conjuntos de dados distribuídos resilientes), DataFrame e conjuntos de dados. Com o Scala, você pode criar e mexer em grandes conjuntos de dados, aplicar transformações e fazer operações complexas de forma eficiente em um cluster.
A API Scala do Spark tem uma sintaxe curta e fácil de entender pra lidar com tarefas de big data, desde processamento em lote até pipelines de machine learning, permitindo análise e processamento de dados em grande escala ao mesmo tempo.
Você também pode se interessar em aprender PySpark desde o início— este guia completo sobre PySpark é umótimo ponto de partida.
No Spark, os RDDs (Resilient Distributed Datasets) são a abstração de baixo nível, representando dados distribuídos que podem ser operados em paralelo. DataFrame são abstrações de nível superior construídas sobre RDDs, oferecendo tratamento de dados estruturados com execução otimizada usando o otimizador Catalyst do Spark.
Os conjuntos de dados juntam o melhor dos RDDs e dos DataFrame, oferecendo a segurança de tipos dos RDDs e as otimizações dos DataFrame. Os conjuntos de dados são fortemente tipados, enquanto os DataFrame não são tipados, o que permite transformações e ações mais eficientes no Spark.
Um trabalho básico do Spark em Scala envolve:
SparkSession.Aqui você pode ver um exemplo:
// Import the SparkSession class which is the entry point for Spark SQL
import org.apache.spark.sql.SparkSession
// Create a SparkSession.
val spark = SparkSession.builder.appName("MySparkApp").getOrCreate()
// Read the input text file as a DataFrame.
val data = spark.read.text("data.txt")
// Perform the transformation on the text file
val wordCount = textFile.flatMap(_.split(" ")).groupByKey(identity).count()
wordCount.show()Transformações no Spark são operações que definem um novo RDD, DataFrame ou Dataset, como map(), filter() ou groupBy(). Elas são avaliadas de forma preguiçosa, ou seja, só são executadas quando uma ação é acionada.
Ações são operações que fazem a execução acontecer, como collect(), count() ou save(). As transformações são aplicadas aos dados de forma preguiçosa, enquanto as ações forçam o Spark a executar o DAG deoperações e retornar um resultado ou persistir os dados.
A avaliação preguiçosa no Spark significa que as transformações não são feitas na hora. Em vez disso, o Spark cria um plano de execução (DAG) e só faz os cálculos quando uma ação é chamada. Isso permite que o Spark otimize a execução, minimizando a reorganização de dados, combinando operações e aplicando filtros mais cedo no pipeline de processamento.
Otimizar tarefas do Spark envolve várias estratégias, como minimizar a reorganização de dados, armazenar resultados intermediários em cache e usar particionamento adequado.
Algumas das estratégias que recomendo usar para otimizar os trabalhos do Spark são:
groupBy).Os desafios comuns no Scala para projetos de big data incluem gerenciar a memória e o desempenho para grandes conjuntos de dados, lidar com o desvio de dados e resolver com eficiência as falhas em ambientes distribuídos.
Depurar tarefas do Spark pode ser complicado por causa da complexidade dos sistemas distribuídos e da avaliação preguiçosa. Além disso, otimizar tarefas do Spark para evitar gargalos e reduzir a sobrecarga geralmente exige ajustes nas configurações e entender o plano de execução por trás disso.
Além disso, lidar com formatos de dados inconsistentes, problemas de qualidade dos dados e a complexidade de escrever e manter código escalável pode ser complicado em cenários de big data.
Neste artigo, falamos sobre várias perguntas de entrevista sobre Scala, desde o básico até o avançado. Desde entender os conceitos básicos e as vantagens do Scala até mergulhar em otimizações, manipulações e conversões mais complexas, exploramos as principais áreas que os possíveis empregadores podem perguntar.
Para consolidar sua preparação, comece a praticar com nosso curso Introdução ao Scala ou faça uma rápida revisão! Preparando-se para uma função dupla em Java-Scala? Não deixe de conferir nosso guia de perguntas para entrevistas sobre Java para ter uma visão completa.
Aprenda mais sobre Scala e engenharia de dados com esses cursos!
Curso
Curso
Curso
blog
Nisha Arya Ahmed
15 min
blog
Javier Canales Luna
15 min
blog
Tim Lu
9 min
blog
Elena Kosourova
15 min
blog
Javier Canales Luna
15 min

