
Course
Big Data Fundamentals with PySpark
4 hr
65.2K
Scala is a powerful language that blends functional and object-oriented programming. It is widely used in big data processing and web apps, due to its concise syntax, scalability, and performance benefits.
As Scala expertise is increasingly sought after in the data industry, this article will provide a comprehensive guide to Scala interview questions, covering various topics from basic concepts to advanced techniques and data engineering questions.
Let's start by exploring some fundamental Scala interview questions that assess your understanding of this powerful language's core concepts and advantages.
If you're new to the language, start with our Introduction to Scala course to build a strong foundation before tackling interview questions.
The name Scala comes from the word scalable. Scala is a statically typed programming language that combines object-oriented and functional programming paradigms. It's concise, expressive, and designed to address many of Java's shortcomings. For example, Scala runs on the Java Virtual Machine (JVM), which means you can use Java libraries and frameworks smoothly.
While Java is strictly object-oriented, Scala allows both object-oriented and functional programming. Scala also provides advanced features like immutability, higher-order functions, pattern matching, and more, all with a concise syntax.
If you’re coming from a Java background, check out the Introduction to Java course to revisit the foundations. To compare object-oriented principles in Java and Scala, try the Introduction to OOP in Java course.
Scala has some powerful features that make it stand out and popular among programmers. Here are some of these features:
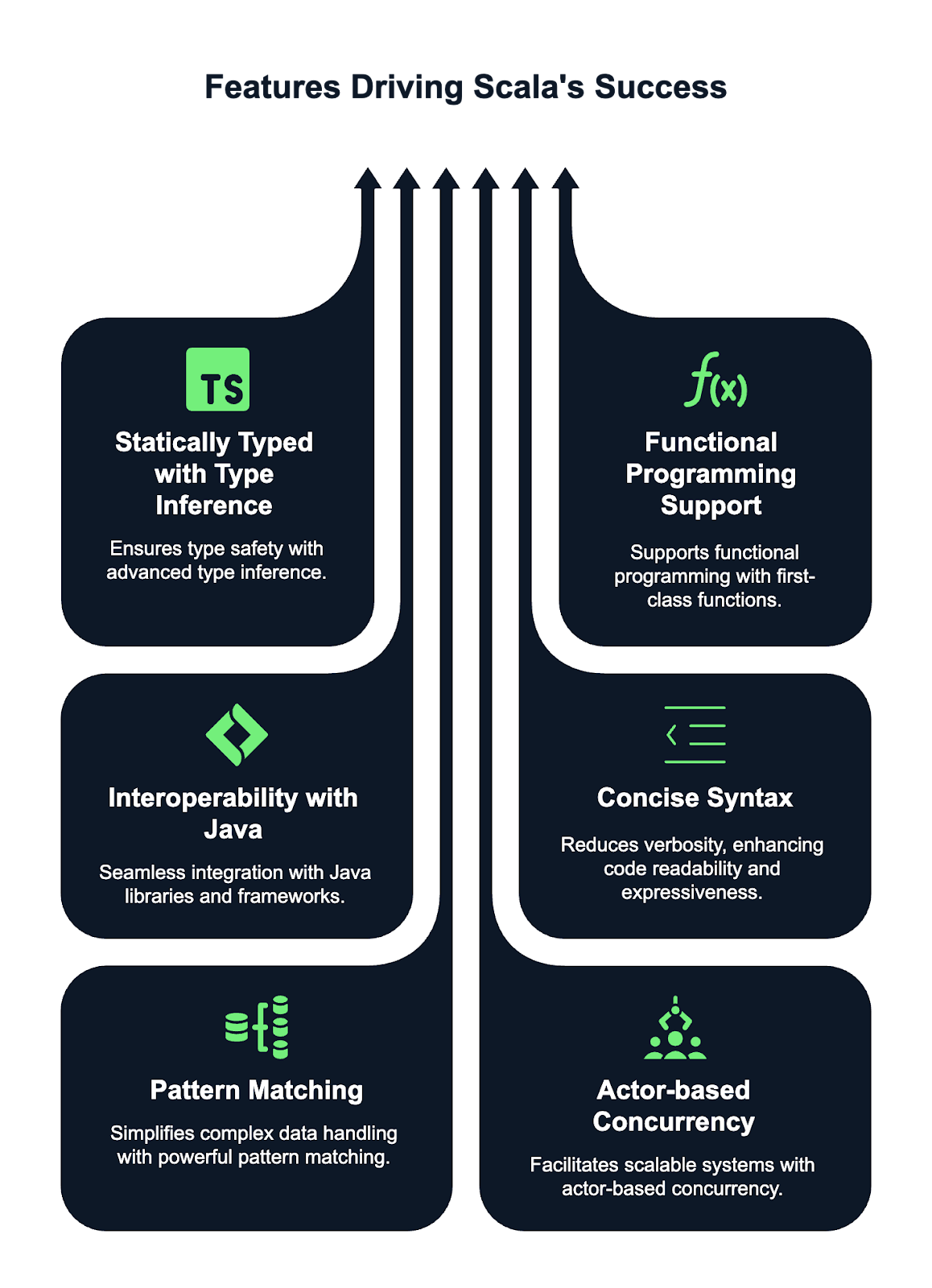
A case class in Scala is a special class optimized for use with immutable data structures. It automatically provides implementations for methods like toString, equals, and hashCode. Case classes are also pattern-matchable, making them incredibly useful for handling data in a functional style.
You typically use case classes to represent data objects that shouldn’t change after they’re created. I left you an example below:
case class Person(name: String, age: Int)
val person1 = Person("John", 30)In Scala, immutability is encouraged, especially for functional programming. You can declare an immutable variable using val as opposed to var, which is mutable. Once you assign a value to a val, it can’t be changed. Immutability leads to safer and more predictable code, as there’s less room for unintended side effects. Check my example below:
val name = "Alice"
// Trying to change it will result in a compile-time error
name = "Bob" // Error: reassignment to valA companion object is an object that shares the same name as a class and is defined in the same file. The main purpose of a companion object is to provide methods and functions that are closely related to the class but aren’t tied to an instance of it.
The companion object can hold factory methods or other utility functions, such as the example I wrote below:
class Person(val name: String, val age: Int)
object Person {
def apply(name: String, age: Int): Person = new Person(name, age)
}The apply method in the Person companion object allows me to create a Person without using the new keyword, just as I show below:
val p = Person("John", 25)In Scala, the var, val, and lazy val keywords are used to define variables, but they differ in terms of mutability, initialization, and evaluation timing.
A var is a mutable variable, meaning its value can be changed after it is initialized. You can reassign a new value to a var:
var x = 10
x = 20 // ReassignableOn the other hand, a val is an immutable reference, meaning once it is assigned a value, it cannot be reassigned, but the object it refers to can still be mutable
val y = 10
// y = 20 // Error: reassignment to valA lazy val is a special type of val that is not evaluated until it is accessed for the first time, which is called lazy evaluation. This can be helpful for performance optimization when working with expensive or resource-intensive computations.
lazy val z = {
println("Computing z")
42
}For a deeper look into variable declarations and best practices in Scala, check out this Variables in Scala tutorial.
In Scala, a higher-order function is a function that either takes one or more functions as parameters or returns a function as a result. This concept allows functions to be treated as first-class values, enabling greater flexibility and abstraction in your code.
Higher-order functions enable behaviors to be passed around and customized, making code more modular, reusable, and expressive.
Below, I left an example of a higher-order function that accepts another function as an argument:
// Define a higher-order function that takes a function as a parameter
def applyFunction(f: Int => Int, x: Int): Int = f(x)
// Call the higher-order function with a function that multiplies the input by 2
val result = applyFunction(x => x * 2, 5) // 10In this case, applyFunction is a higher-order function that takes a function f, which multiplies by 2, and applies it to 5.
In Scala, String is immutable, meaning modifications create new objects, which can be inefficient for repeated changes. It’s suitable for infrequent string operations.
In contrast, StringBuilder is mutable, allowing in-place modifications without creating new objects. This makes it more efficient for frequent string manipulations like appending or modifying content.
I recommend using String when immutability is preferred and performance isn’t critical and opting for StringBuilder when you need better performance in scenarios involving multiple string modifications.
The @tailrec annotation is used to mark a method as tail-recursive, meaning the recursive call is the last operation in the method. This allows the Scala compiler to optimize the method to avoid stack overflow errors by transforming the recursion into a loop. If the method isn’t tail-recursive, the compiler will throw an error.
Let’s see an example:
@tailrec
def factorial(n: Int, accumulator: Int = 1): Int = {
if (n <= 0) accumulator
else factorial(n - 1, n * accumulator)
}Having covered the basics, let's move on to some intermediate-level Scala interview questions that help you understand more about how the language works.
In Scala, map, flatMap, and foreach are higher-order functions used on collections, but they serve different purposes.
map transforms each element of a collection and returns a new collection of the same size with the transformed elements. flatMap also transforms each element but flattens the resulting structure, which makes it useful when the transformation itself results in collections. foreach is used for side-effects, applying a function to each element without returning anything, commonly used for operations like printing or updating external states.Pattern matching in Scala is a powerful feature that allows you to match values against patterns, making code more expressive and concise. It is similar to switch or case statements in other languages, but is more flexible and can be used with a variety of types, like integers, strings, lists, and even complex data structures. It can be used with match expressions, which compare the value of an expression against multiple patterns.
Some use cases for pattern matching include:
Some or None values in Option, allowing for concise handling of nullable values.Here, I left an example:
// Define a variable x with value 3
val x = 3
// Pattern matching on the value of x
x match {
// If 'x' is equal to 1, print "One"
case 1 => println("One")
// If 'x' is equal to 2, print "Two"
case 2 => println("Two")
// If 'x' doesn't match any of the above cases, print "Other"
case _ => println("Other")
}In Scala, Option is a container type used to represent a value that may or may not exist, helping to avoid null values and null pointer exceptions. It has two subtypes: Some and None.
Some wraps a valid value, indicating the presence of a value, while None signifies the absence of a value. This allows developers to explicitly handle cases where a value could be missing, promoting safer and more functional code.
Option is often used in methods that may fail to return a result, reducing the need for error-prone null checks.
Check the code below:
// Function that returns an Option
def findFirstEvenNumber(list: List[Int]): Option[Int] = {
list.find(_ % 2 == 0) // Returns Some(number) if an even number is found, otherwise None
}
// Example usage:
val numbers = List(1, 3, 5, 7, 8)
val result = findFirstEvenNumber(numbers)
result match {
case Some(number) => println(s"Found an even number: $number") // Output: Found an even number: 8
case None => println("No even number found")
}Scala provides a rich set of collections categorized into mutable and immutable types.
List, Set, Map, and Vector, cannot be modified after creation, promoting functional programming practices.ArrayBuffer, HashSet, and HashMap, allow modifications. Collections are highly flexible, supporting various operations like filtering, mapping, and folding. The standard library also offers specialized collections like Queue, Stack, and SortedSet, catering to different data manipulation needs efficiently. Immutable collections are preferred for thread safety and functional purity.
In Scala, implicit parameters are values the compiler passes automatically to a method or constructor without explicitly specifying them. They are marked with the implicit keyword and are typically used for things like dependency injection, configuration, or context passing.
// Define a function that takes an implicit parameter 'name' of type String
def greet(implicit name: String) = s"Hello, $name"
// Define an implicit value 'myName' of type String in the scope
implicit val myName = "Alice"
// Call the greet function without explicitly passing 'name'
// The compiler automatically uses the implicit value 'myName'
println(greet) // Output: "Hello, Alice"In Scala, traits are similar to interfaces in Java but with additional capabilities. A trait is a reusable component that can be mixed into classes or other traits. It allows you to define both abstract methods and concrete methods. Traits can also maintain state, unlike Java interfaces, which can only define method signatures.
Scala supports mixing multiple traits into a single class, enabling multiple inheritance, while Java allows implementing multiple interfaces but only one class, limiting inheritance flexibility.
Here is an example:
trait Logger {
def log(message: String): Unit = println(s"Log: $message")
}The Scala REPL is an interactive shell that allows you to write and evaluate Scala code in real time. It works in four steps:
This process enables quick experimentation and testing of Scala code, making it a powerful tool for learning, debugging, and prototyping in Scala. You can define variables and functions, and explore libraries interactively.

Figure: The Scala REPL is a command-line interpreter you can use to test your Scala code as a playground area. Source: Scala docs
For those seeking more senior roles or aiming to demonstrate a deeper understanding of Scala, let's explore some advanced interview questions that dive into handling asynchronous computations and concurrency, as well as complex structures and conversions.
These questions will assess your expertise in functional programming, concurrency, and scalable system design.
In Scala, Future and Await are both related to handling asynchronous computations but serve different purposes.
Future represents a computation that will eventually be completed with a result or an exception. It allows other tasks to continue while waiting for the computation's result. Await is used to block the current thread until the result of a Future is available. It forces a thread to wait for the completion of a Future. It is often used when you need to synchronize and wait for the result in a non-asynchronous context.I show here some examples of how to use these functionalities:
import scala.concurrent.Future
import scala.concurrent.ExecutionContext.Implicits.global
import scala.concurrent.Await
import scala.concurrent.duration._
val futureValue = Future { 42 } // A Future that computes the value 42 asynchronously.
val result = Await.result(futureValue, 2.seconds) // Blocks the thread for up to 2 seconds, waiting for the result of the Future.Scala handles concurrency using both low-level mechanisms like threads and high-level abstractions like Futures and Promises for asynchronous programming.
The standard library includes scala.concurrent.Future, which allows for non-blocking computations, and ExecutionContext for managing execution threads.
For more advanced concurrency, Akka is widely used, providing tools for building highly concurrent, distributed systems using the Actor model. Additionally, libraries like Cats Effect and ZIO offer functional programming approaches to handle concurrency, providing safe, composable abstractions for managing side effects, asynchronous tasks, and resources.
Monads are a design pattern used to handle computations in a structured way, especially when dealing with side effects like asynchronous operations or nullable values. A monad provides a way to wrap a value and apply transformations while maintaining the structure. In Scala, Option and Future are examples of monads.
val result = Some(5).flatMap(x => Some(x * 2))The Akka framework in Scala is designed to simplify building distributed, concurrent, and fault-tolerant systems. It uses the Actor model, where each actor is a lightweight, independent unit that communicates asynchronously via message passing.
Akka abstracts away low-level concurrency details, allowing developers to focus on business logic. It supports distributed systems by enabling actors to run on different nodes. Akka's Cluster module facilitates seamless communication, load balancing, and resilience, making it ideal for scalable, highly available systems.
In Scala, implicit conversions allow the automatic transformation of one type into another. They are defined using the implicit keyword and are used to enable operations between types that wouldn't normally be compatible. The compiler applies implicit conversions when necessary, reducing boilerplate code.
As an example, I show you how to convert a String to an Int automatically when performing arithmetic operations:
implicit def intToString(x: Int): String = x.toString
val str: String = 42 // Implicitly converted to “42”In Scala, type variance refers to how subtypes of a generic type relate to each other. It is controlled using covariant (+), contravariant (-), and invariant (=) type parameters.
List[+A] means a List of type A can be used wherever a List of a supertype of A is expected. Example: List[Dog] can be used as List[Animal] if Dog extends Animal.Function1[-A, +B] means a Function1 can accept a supertype of A and return a subtype of B. Example: Function1[Animal, Dog] can be used as Function1[Dog, Dog].List[A] is invariant, meaning List[Dog] and List[Animal] are not interchangeable.If you're interviewing for a data engineering role, expect questions that assess your ability to design, optimize, and troubleshoot Scala applications in a production environment. Let's delve into some typical interview questions you might encounter.
To define a custom annotation in Scala, you need to create a class that extends scala.annotation.Annotation. This class takes constructor parameters to store metadata. Annotations are then applied to classes, methods, or fields with the @symbol.
I found that one useful feature about annotations is that custom annotations can be accessed at runtime using reflection to retrieve their metadata, typically through getAnnotations or similar methods.
import scala.annotation.StaticAnnotation
class MyAnnotation extends StaticAnnotation
@MyAnnotation class MyClassScala is the native language for Apache Spark, providing seamless integration and high performance.
It is used to write distributed data processing jobs, leveraging Spark’s core features like RDDs (Resilient Distributed Datasets), DataFrames, and Datasets. With Scala, you can create and manipulate large datasets, apply transformations, and execute complex operations efficiently across a cluster.
Spark's Scala API offers a concise and expressive syntax for handling big data tasks, from batch processing to machine learning pipelines, enabling large-scale data analysis and processing in parallel.
You might also be interested in learning PySpark from the ground up—this complete guide to PySpark is a great place to start.
In Spark, RDDs (Resilient Distributed Datasets) are the low-level abstraction, representing distributed data that can be operated on in parallel. DataFrames are higher-level abstractions built on top of RDDs, offering structured data handling with optimized execution using Spark’s Catalyst optimizer.
Datasets combine the best of both RDDs and DataFrames, offering the type-safety of RDDs while providing the optimizations of DataFrames. Datasets are strongly typed, while DataFrames are untyped, allowing for more efficient transformations and actions in Spark.
A basic Spark job in Scala involves:
SparkSession.Here you can see an example:
// Import the SparkSession class which is the entry point for Spark SQL
import org.apache.spark.sql.SparkSession
// Create a SparkSession.
val spark = SparkSession.builder.appName("MySparkApp").getOrCreate()
// Read the input text file as a DataFrame.
val data = spark.read.text("data.txt")
// Perform the transformation on the text file
val wordCount = textFile.flatMap(_.split(" ")).groupByKey(identity).count()
wordCount.show()Transformations in Spark are operations that define a new RDD, DataFrame, or Dataset, like map(), filter(), or groupBy(). They are lazily evaluated, meaning they are not executed until an action is triggered.
Actions are operations that trigger execution, such as collect(), count(), or save(). Transformations are applied to data lazily, while actions force Spark to execute the DAG of operations and return a result or persist data.
Lazy evaluation in Spark means that transformations are not executed immediately. Instead, Spark builds an execution plan (DAG) and only runs the computations when an action is called. This allows Spark to optimize the execution by minimizing data shuffling, combining operations, and applying filters earlier in the processing pipeline.
Optimizing Spark jobs involves several strategies, such as minimizing data shuffling, caching intermediate results, and using appropriate partitioning.
Some of the strategies I recommend using to optimize Spark jobs are:
groupBy).Common challenges in Scala for big data projects include managing memory and performance for large datasets, handling data skew, and efficiently dealing with faults in distributed environments.
Debugging Spark jobs can be tricky due to the complexity of distributed systems and lazy evaluation. Additionally, optimizing Spark jobs to avoid bottlenecks and reduce overhead often requires fine-tuning configurations and understanding the underlying execution plan.
Also, dealing with inconsistent data formats, data quality issues, and the complexity of writing and maintaining scalable code can be difficult in big data scenarios.
In this article, we've covered a wide range of Scala interview questions spanning basic, intermediate, and advanced topics. From understanding the core concepts and advantages of Scala to diving into more complex optimizations, handling, and conversions, we've explored the key areas that potential employers might inquire about.
To solidify your preparation, start practicing with our Introduction to Scala course or get a quick refresher! Preparing for a dual Java-Scala role? Don’t miss our Java interview questions guide for a complete perspective.
Learn more about Scala and data engineering with these courses!
Course
Course
Course
blog
Maria Eugenia Inzaugarat
15 min
blog
Kevin Babitz
14 min
blog
Marie Fayard
15 min
blog
Dhiraj Kumar
15 min
blog
Elena Kosourova
15 min
blog
Maria Eugenia Inzaugarat
15 min