Cours
Machine learning avec des modèles arborescents en Python
5 h
116.4K
L'apprentissage automatique supervisé est un type d'apprentissage automatique qui apprend la relation entre l'entrée et la sortie. Les données d'entrée sont appelées caractéristiques ou "variables X" et les données de sortie sont généralement appelées cibles ou "variables y". Le type de données qui contient à la fois les caractéristiques et la cible est connu sous le nom de données étiquetées. C'est la principale différence entre l'apprentissage automatique supervisé et non supervisé, deux types importants d'apprentissage automatique. Dans ce tutoriel, vous apprendrez :
L'apprentissage automatique supervisé apprend des modèles et des relations entre les données d'entrée et de sortie. Il se définit par l'utilisation de données étiquetées. Une donnée étiquetée est un ensemble de données contenant un grand nombre d'exemples de caractéristiques et de cibles. L'apprentissage supervisé utilise des algorithmes qui apprennent la relation entre les caractéristiques et la cible à partir de l'ensemble de données. Ce processus est appelé formation ou adaptation.
Il existe deux types d'algorithmes d'apprentissage supervisé :
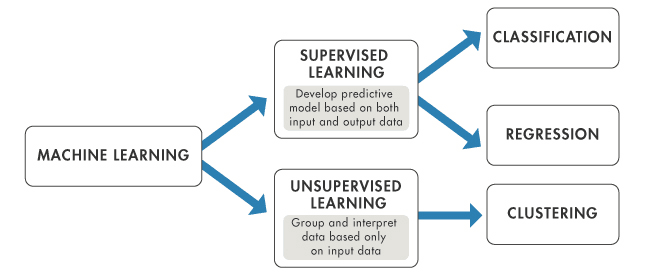
Source de l'image : https://www.mathworks.com/help/stats/machine-learning-in-matlab.html
La classification est un type d'apprentissage automatique supervisé dans lequel les algorithmes apprennent à partir des données à prédire un résultat ou un événement futur. Par exemple :
Une banque peut disposer d'un ensemble de données sur ses clients, contenant leurs antécédents en matière de crédit, de prêts, d'investissements, etc. et elle peut vouloir savoir si l'un d'entre eux va manquer à ses obligations. Dans les données historiques, nous aurons les caractéristiques et la cible.
Les algorithmes de classification sont utilisés pour prédire des résultats discrets, si le résultat peut prendre deux valeurs possibles telles que Vrai ou Faux, Défaut ou Non Défaut, Oui ou Non, il s'agit d'une classification binaire. Lorsque le résultat contient plus de deux valeurs possibles, on parle de classification multi-classe. Il existe de nombreux algorithmes d'apprentissage automatique qui peuvent être utilisés pour les tâches de classification. En voici quelques-unes :
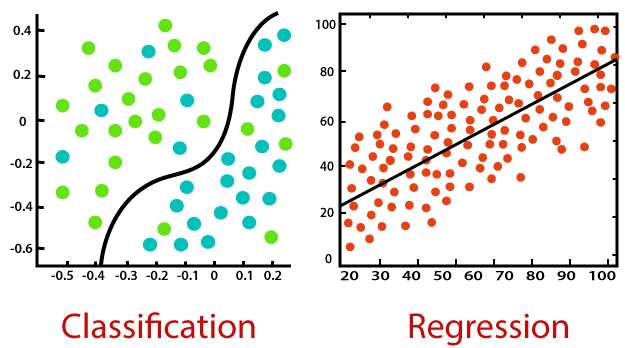
La régression est un type d'apprentissage automatique supervisé dans lequel les algorithmes apprennent à partir des données à prédire des valeurs continues telles que les ventes, le salaire, le poids ou la température. Par exemple :
Un ensemble de données contenant des caractéristiques de la maison telles que la taille du terrain, le nombre de chambres, le nombre de salles de bain, le quartier, etc. et le prix de la maison, un algorithme de régression peut être formé pour apprendre la relation entre les caractéristiques et le prix de la maison.
Il existe de nombreux algorithmes d'apprentissage automatique qui peuvent être utilisés pour les tâches de régression. En voici quelques-unes :
Source de l'image : https://static.javatpoint.com/tutorial/machine-learning/images/regression-vs-classification-in-machine-learning.png
La principale différence entre l'apprentissage automatique supervisé et non supervisé est que l'apprentissage supervisé utilise des données étiquetées. Les données étiquetées sont des données qui contiennent à la fois les caractéristiques (variables X) et la cible (variable y).
Lors de l'utilisation de l'apprentissage supervisé, l'algorithme apprend de manière itérative à prédire la variable cible en fonction des caractéristiques et modifie la réponse appropriée afin d'"apprendre" à partir de l'ensemble de données d'apprentissage. Ce processus est appelé formation ou adaptation. Les modèles d'apprentissage supervisé produisent généralement des résultats plus précis que l'apprentissage non supervisé, mais ils nécessitent une interaction humaine au départ afin d'identifier correctement les données. Si les étiquettes de l'ensemble de données ne sont pas correctement identifiées, les algorithmes supervisés apprendront des détails erronés.
Les modèles d'apprentissage non supervisés, quant à eux, travaillent de manière autonome pour identifier la structure innée des données qui n'ont pas été étiquetées. Il est important de garder à l'esprit que la validation des variables de sortie nécessite toujours un certain niveau d'implication humaine. Par exemple, un modèle d'apprentissage non supervisé peut déterminer que les clients qui font des achats en ligne ont tendance à acheter plusieurs articles de la même catégorie en même temps. Toutefois, un analyste humain devrait vérifier qu'il est logique pour un moteur de recommandation d'associer l'article X à l'article Y.
Il existe deux principaux cas d'utilisation de l'apprentissage supervisé, à savoir la classification et la régression. Dans les deux cas, un algorithme supervisé apprend à partir des données d'apprentissage à prédire quelque chose. Si la variable prédite est discrète, comme "Oui" ou "Non", 1 ou 0, "Fraude" ou "Pas de fraude", un algorithme de classification est nécessaire. Si la variable prédite est continue, comme les ventes, le coût, le salaire, la température, etc., l'algorithme de régression est nécessaire.
Le regroupement et la détection d'anomalies sont deux cas d'utilisation importants de l'apprentissage non supervisé. Pour en savoir plus sur le regroupement, consultez cet article. Si vous souhaitez plonger plus profondément dans l'apprentissage automatique non supervisé, consultez ce cours intéressant de DataCamp. Vous apprendrez à regrouper, transformer, visualiser et extraire des informations à partir d'ensembles de données non marquées en utilisant scikit-learn et scipy.
L'objectif de l'apprentissage supervisé est de prévoir les résultats de nouvelles données sur la base d'un modèle qui a été appris à partir d'un ensemble de données de formation étiquetées. Le type de résultats que vous pouvez anticiper est connu d'emblée sous la forme de données étiquetées. L'objectif d'un algorithme d'apprentissage non supervisé est de tirer des enseignements de quantités massives de données sans étiquettes explicites. Les algorithmes non supervisés apprennent également à partir de l'ensemble de données d'apprentissage, mais ces dernières ne contiennent pas d'étiquettes.
L'apprentissage automatique supervisé est plus simple que l'apprentissage non supervisé. Les modèles d'apprentissage non supervisé nécessitent généralement un grand ensemble d'apprentissage pour produire les résultats souhaités, ce qui les rend complexes sur le plan informatique.
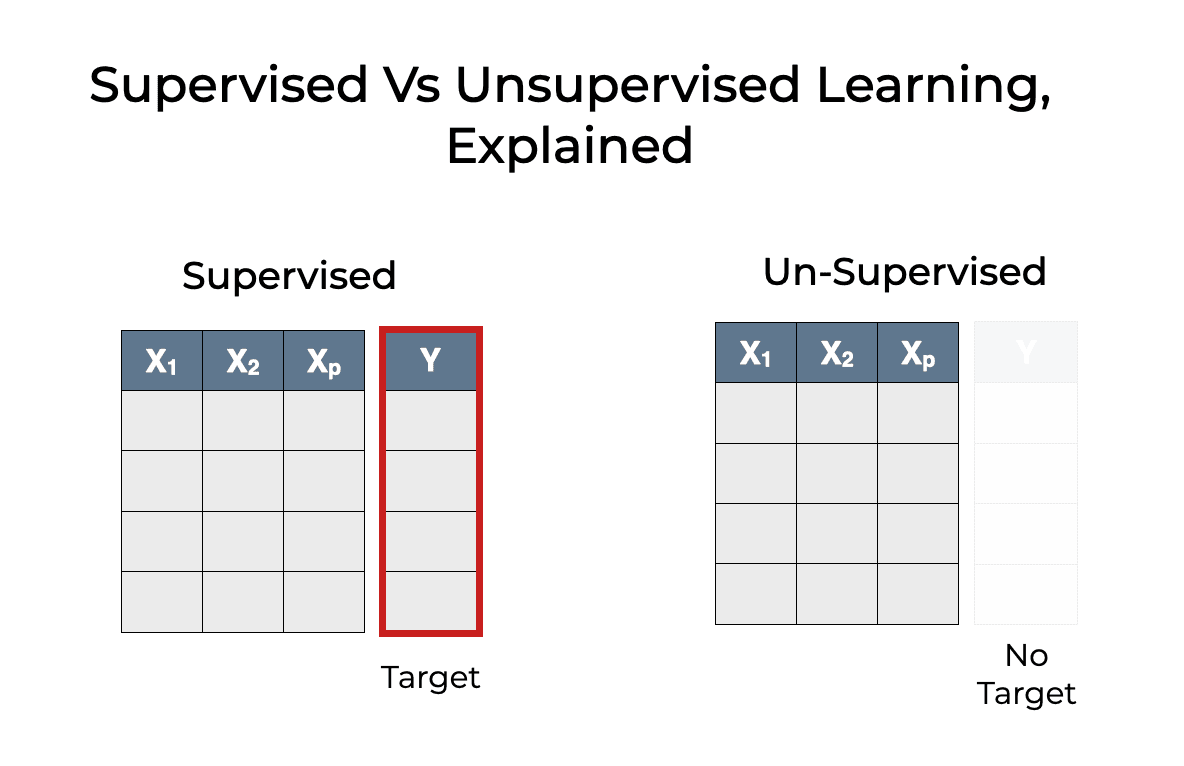
Image Source : https://www.sharpsightlabs.com/blog/supervised-vs-unsupervised-learning/
L'apprentissage semi-supervisé est un type d'apprentissage automatique relativement nouveau et moins populaire qui, au cours de la formation, mélange une quantité importante de données non étiquetées avec une petite quantité de données étiquetées. L'apprentissage semi-supervisé se situe entre l'apprentissage supervisé (avec des données de formation étiquetées) et l'apprentissage non supervisé (données de formation non étiquetées).
L'apprentissage semi-supervisé offre de nombreuses applications dans le monde réel. Dans de nombreux domaines, on manque de données étiquetées. Parce qu'elles font appel à des annotateurs humains, à des équipements spécialisés ou à des études longues et coûteuses, les étiquettes (variables cibles) peuvent être difficiles à obtenir.
L'apprentissage semi-supervisé est de deux types :
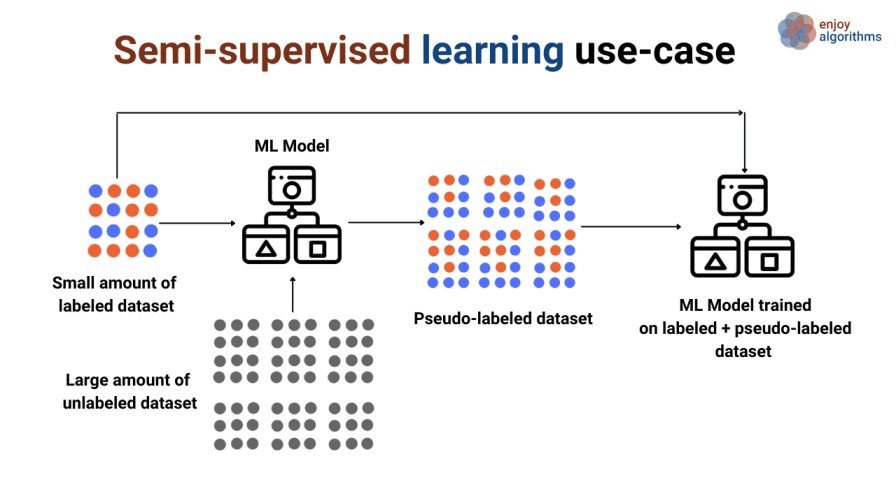
Source de l'image : https://www.enjoyalgorithms.com/blogs/supervised-unsupervised-and-semisupervised-learning
Dans cette section, nous aborderons quelques algorithmes courants d'apprentissage automatique supervisé :
La régression linéaire est l'un des algorithmes d'apprentissage automatique les plus simples. Elle est utilisée pour apprendre à prédire une valeur continue (variable dépendante) en fonction des caractéristiques (variable indépendante) de l'ensemble de données d'apprentissage. La valeur de la variable dépendante, qui représente l'effet, est influencée par les changements de la valeur de la variable indépendante.
Si vous vous souvenez de la "ligne de meilleur ajustement" de l'école, c'est exactement ce qu'est la régression linéaire. La prédiction du poids d'une personne en fonction de sa taille est un exemple simple de ce concept.
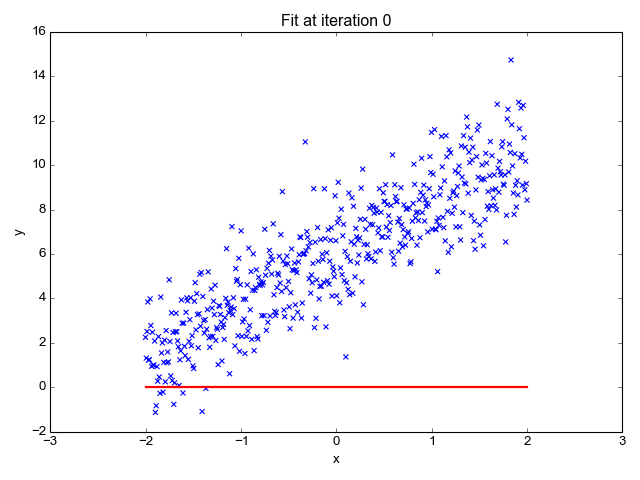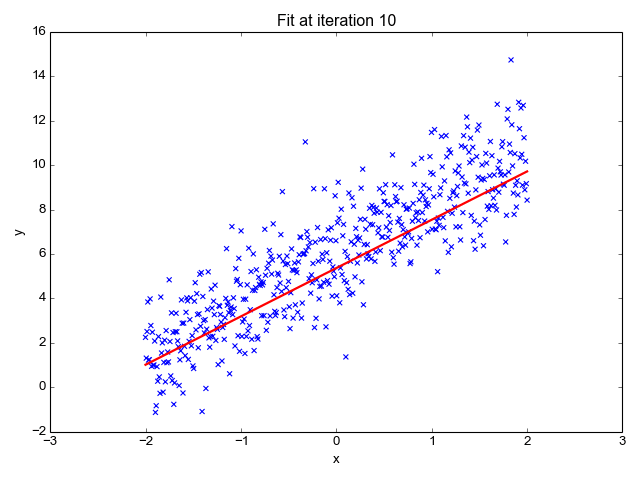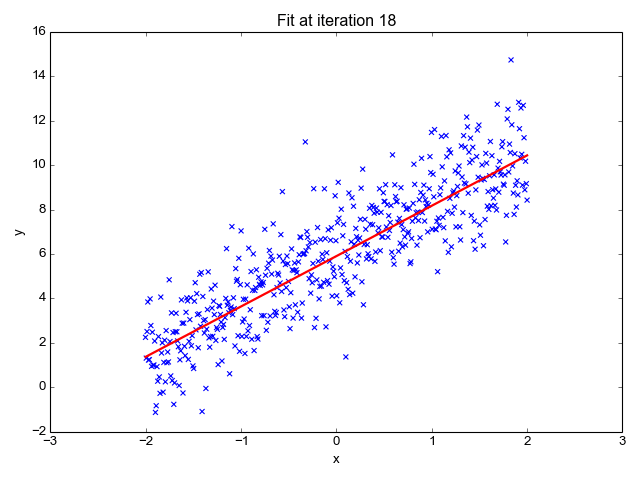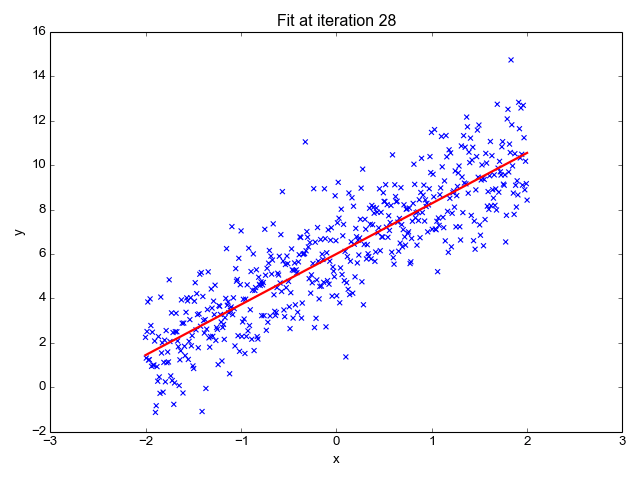
Source de l'image : http://primo.ai/index.php?title=Linear_Regression
|
AVANTAGES |
CONS |
|
Simple, facile à comprendre et à interpréter |
Facile à adapter |
|
Performances exceptionnelles pour les données linéairement séparables |
Suppose une linéarité entre les caractéristiques et la variable cible. |
La régression logistique est un cas particulier de régression linéaire où la variable cible (y) est discrète / catégorique, comme 1 ou 0, Vrai ou Faux, Oui ou Non, Défaut ou Pas de Défaut. Le logarithme de la cote est utilisé comme variable dépendante. En utilisant une fonction logit, la régression logistique permet de prédire la probabilité qu'un événement binaire se produise.
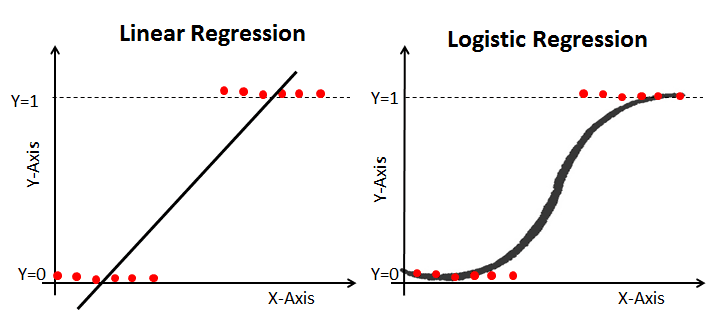
Pour en savoir plus sur ce sujet, consultez cet excellent article du tutoriel Comprendre la régression logistique en Python sur DataCamp.
|
AVANTAGES |
CONS |
|
Simple, facile à comprendre et à interpréter |
Surajustement |
|
Bien calibré pour les probabilités de sortie |
Difficulté à saisir les relations complexes |
Les algorithmes d'arbre de décision sont un type de modèle structurel semblable à un arbre de probabilité qui sépare continuellement les données afin de les classer ou de faire des prédictions en fonction des résultats de la série de questions précédente. Le modèle analyse les données et fournit des réponses aux questions afin de vous aider à faire des choix plus éclairés.
Vous pouvez, par exemple, utiliser un arbre de décision dans lequel les réponses Oui ou Non sont utilisées pour sélectionner une certaine espèce d'oiseau sur la base d'éléments de données tels que les plumes de l'oiseau, sa capacité à voler ou à nager, le type de bec qu'il possède, etc.
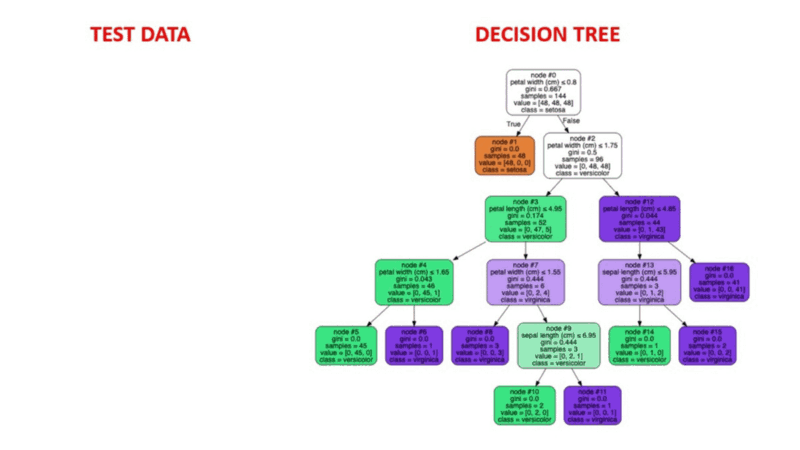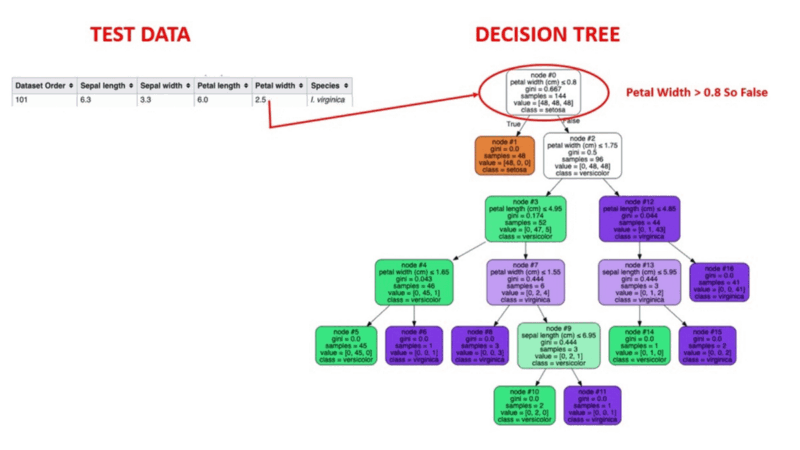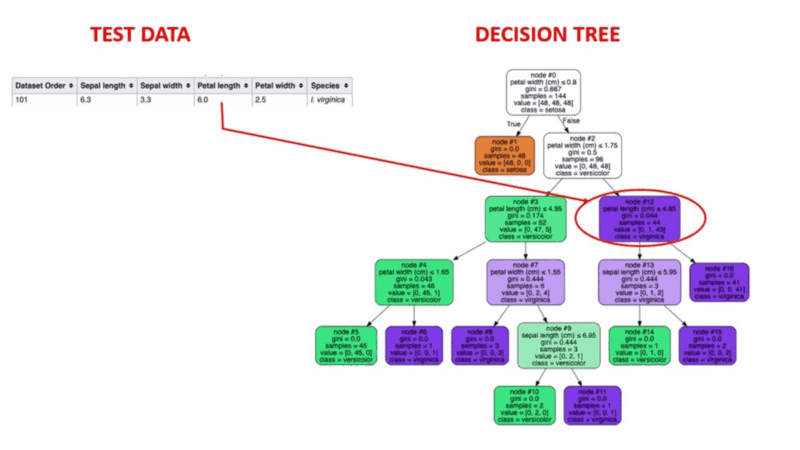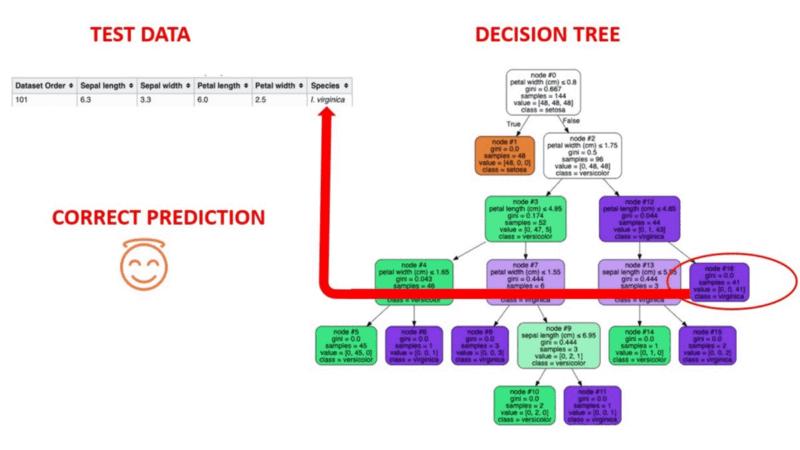
Source de l'image : https://aigraduate.com/decision-tree-visualisation---quick-ml-tutorial-for-beginners/
|
AVANTAGES |
CONS |
|
Très intuitif et facile à expliquer |
Instable - un petit changement dans les données d'apprentissage peut entraîner des différences considérables dans les prédictions. |
|
Les arbres de décision ne nécessitent pas une grande préparation des données, contrairement à certains modèles linéaires. |
Sujet à l'overfitting (surajustement) |
Pour en savoir plus sur l'apprentissage automatique avec des modèles arborescents en Python, consultez ce cours intéressant de DataCamp. Dans ce cours, vous apprendrez à utiliser des modèles basés sur des arbres et des ensembles pour la régression et la classification en utilisant scikit-learn.
La méthode des K-voisins les plus proches est une méthode statistique qui évalue la proximité d'un point de données par rapport à un autre point de données afin de décider si les deux points de données peuvent être regroupés ou non. La proximité des points de données représente le degré de comparabilité entre eux.
Supposons, par exemple, que nous ayons un graphique comportant deux groupes distincts de points de données situés à proximité l'un de l'autre et nommés respectivement groupe A et groupe B. Chacun de ces groupes de points de données est représenté par un point sur le graphique. Lorsque nous ajoutons un nouveau point de données, le groupe de cette instance dépendra du groupe dont le nouveau point est le plus proche.
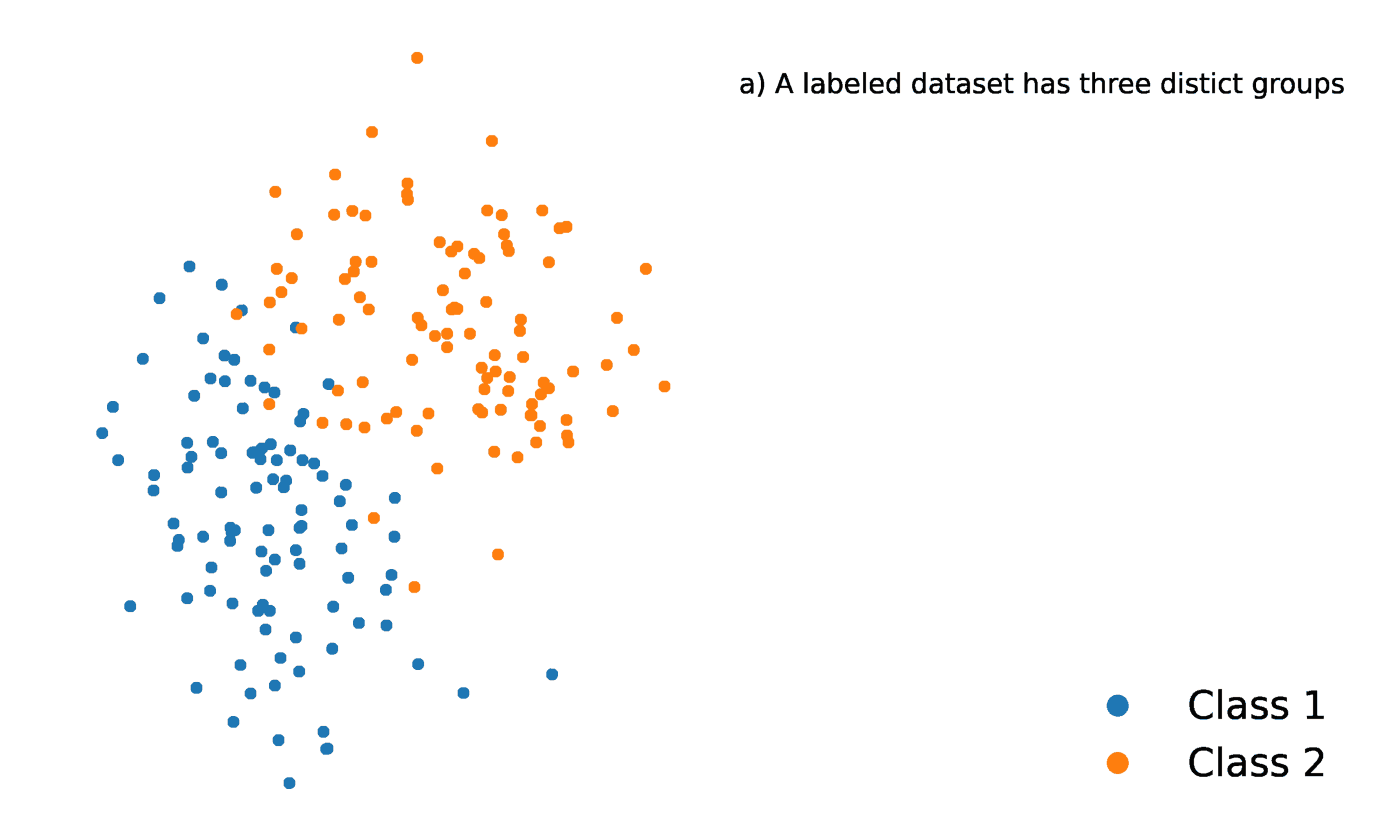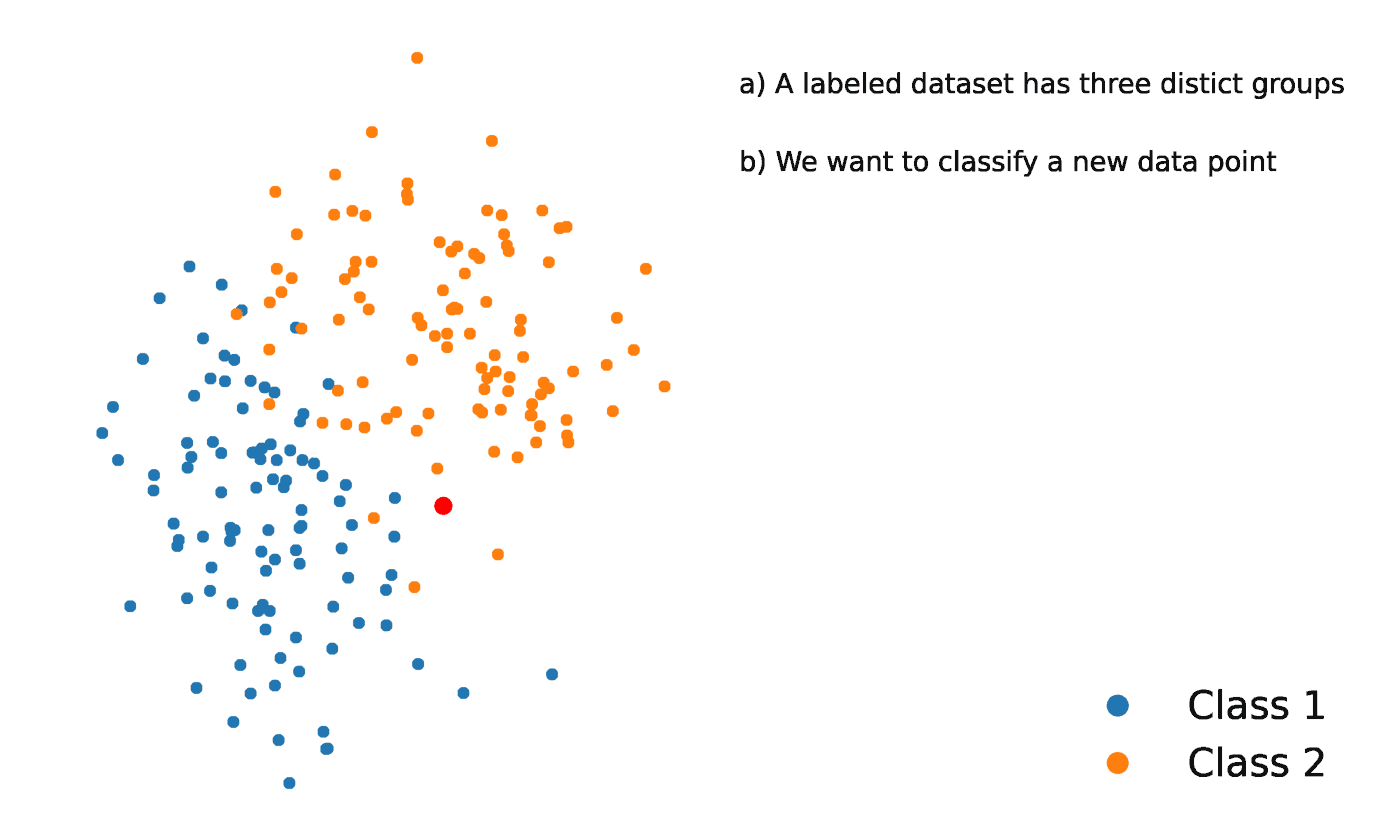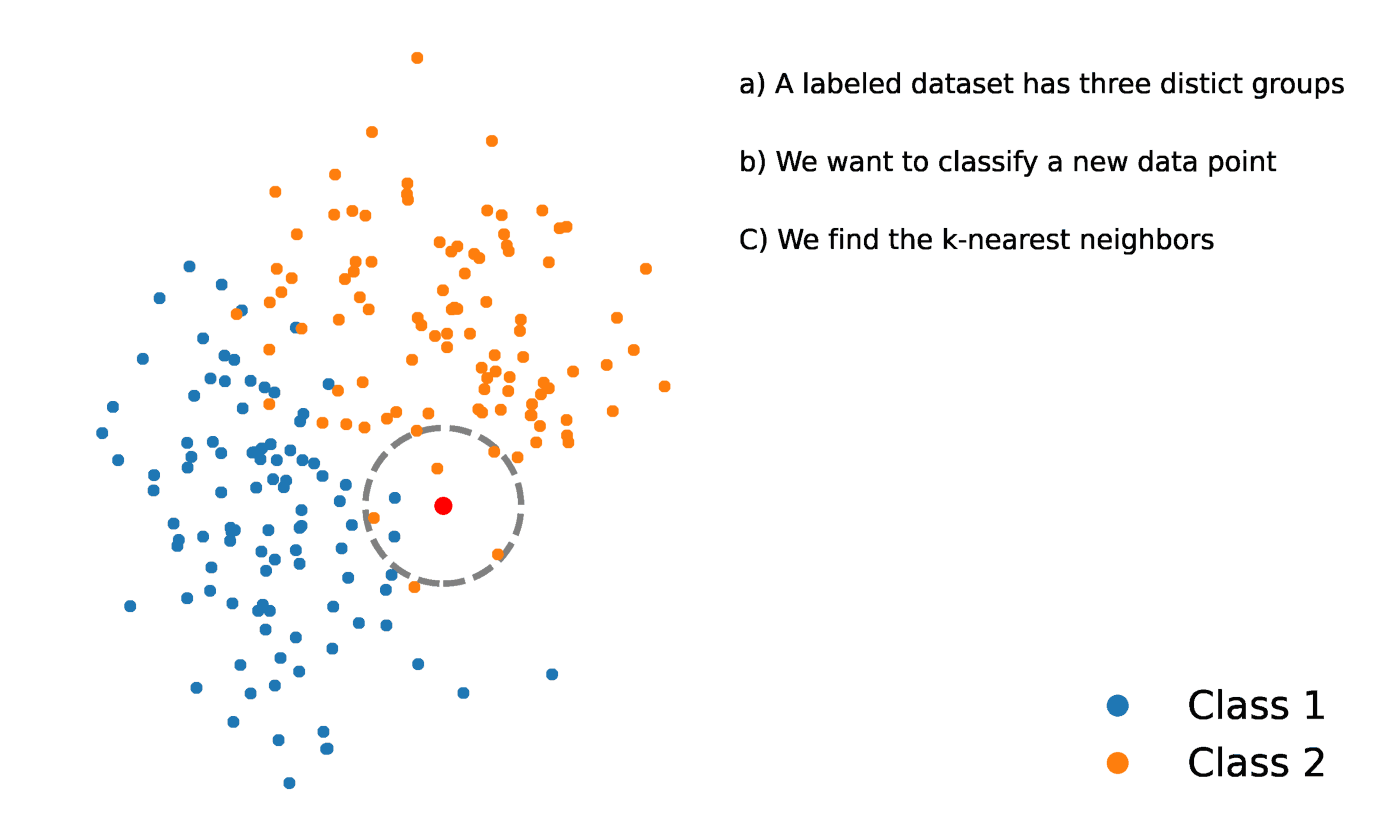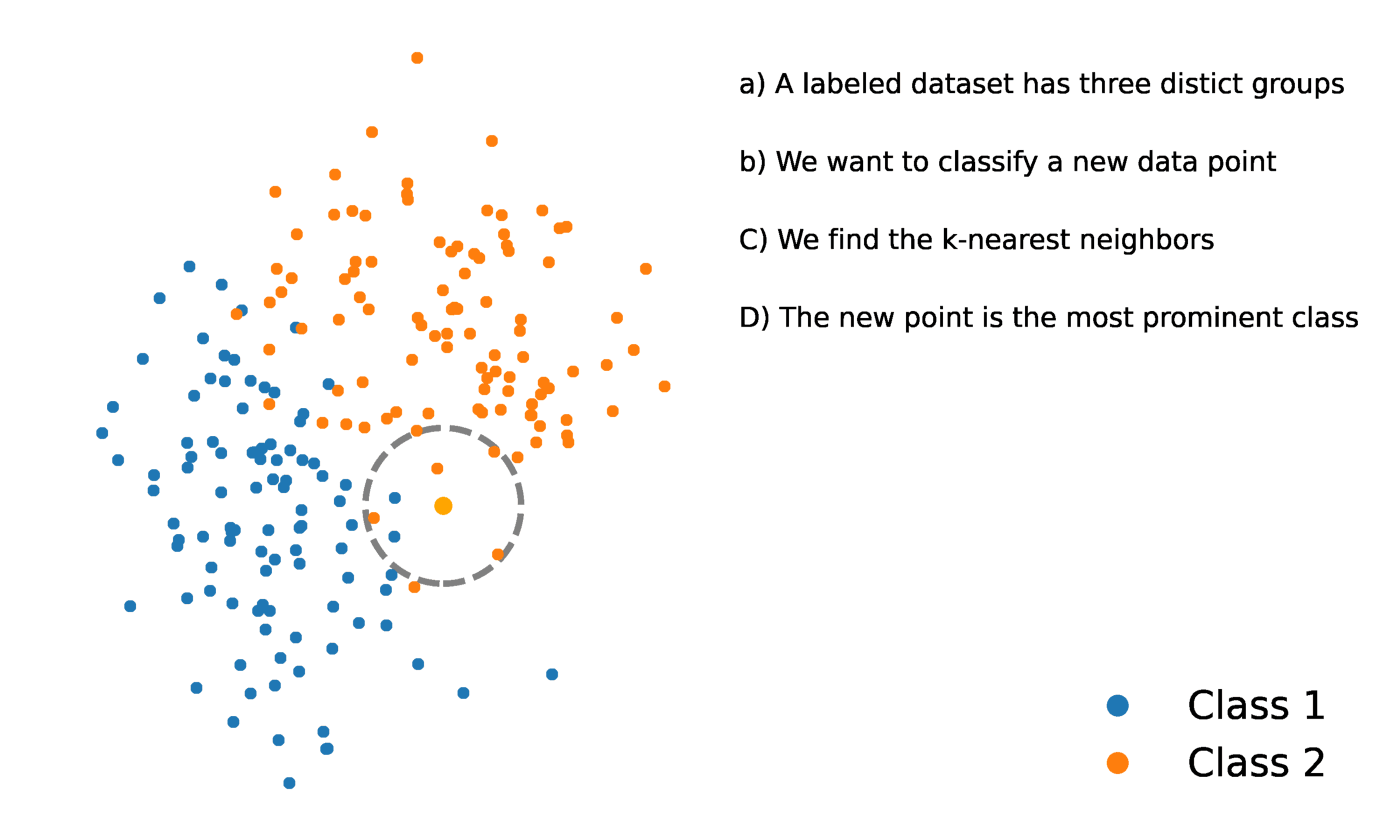
Source : https://towardsdatascience.com/getting-acquainted-with-k-nearest-neighbors-ba0a9ecf354f
|
AVANTAGES |
CONS |
|
Ne fait aucune hypothèse sur les données |
La formation prend beaucoup de temps |
|
Intuitif et simple |
KNN fonctionne bien avec un petit nombre de caractéristiques, mais au fur et à mesure que le nombre de caractéristiques augmente, il peine à prédire avec précision. |
Random Forest est un autre exemple d'algorithme basé sur des arbres, tout comme les arbres de décision. Contrairement à l'arbre de décision, qui ne comporte qu'un seul arbre, la forêt aléatoire utilise un certain nombre d'arbres de décision pour émettre des jugements, créant ainsi ce qui est essentiellement une forêt d'arbres.
Pour ce faire, il combine un certain nombre de modèles différents afin de produire des prédictions, et il peut être utilisé à la fois pour la classification et la régression.
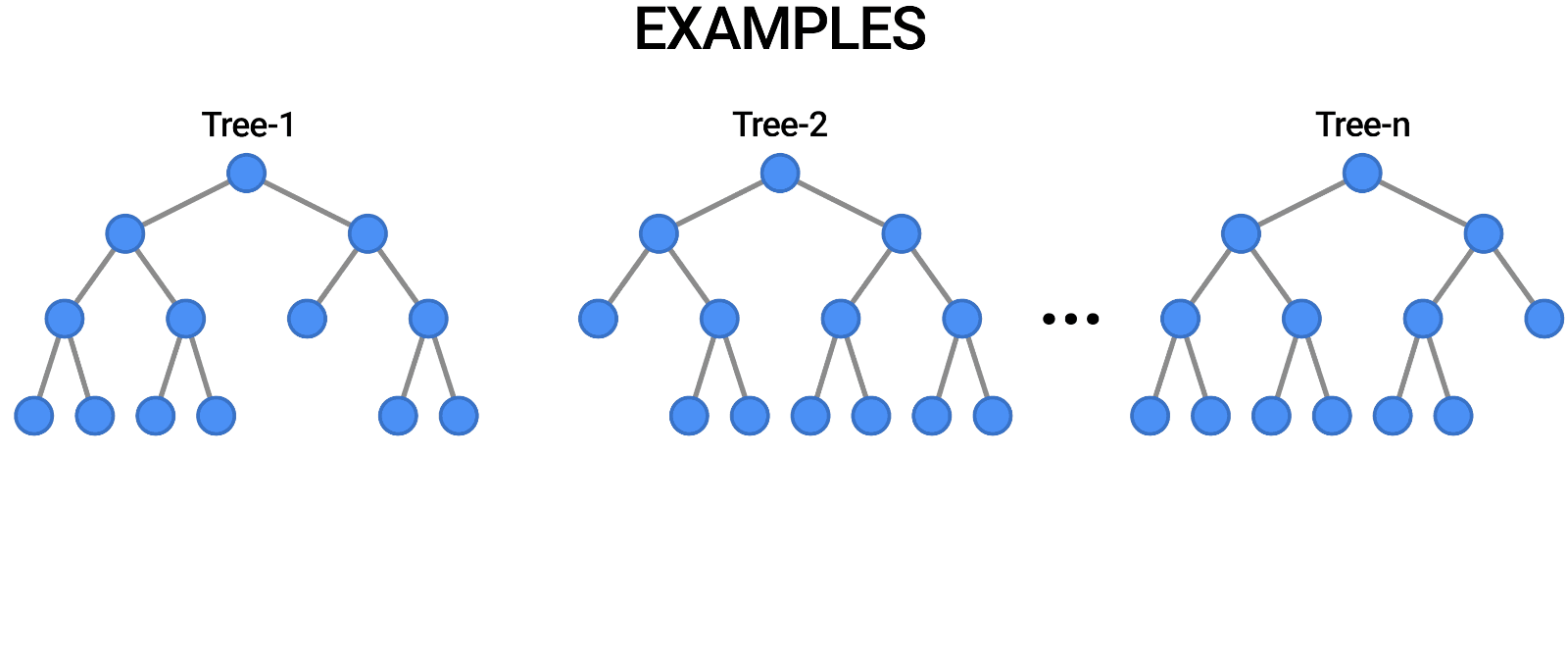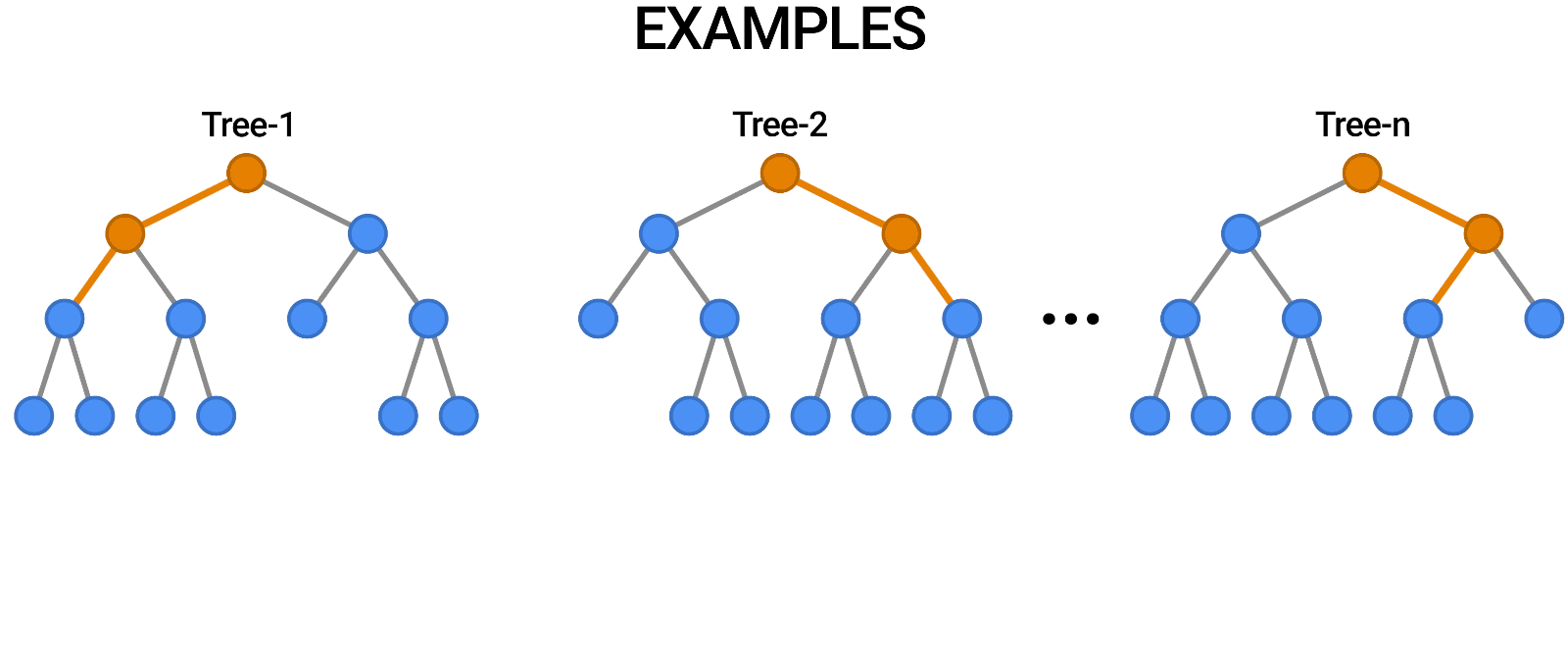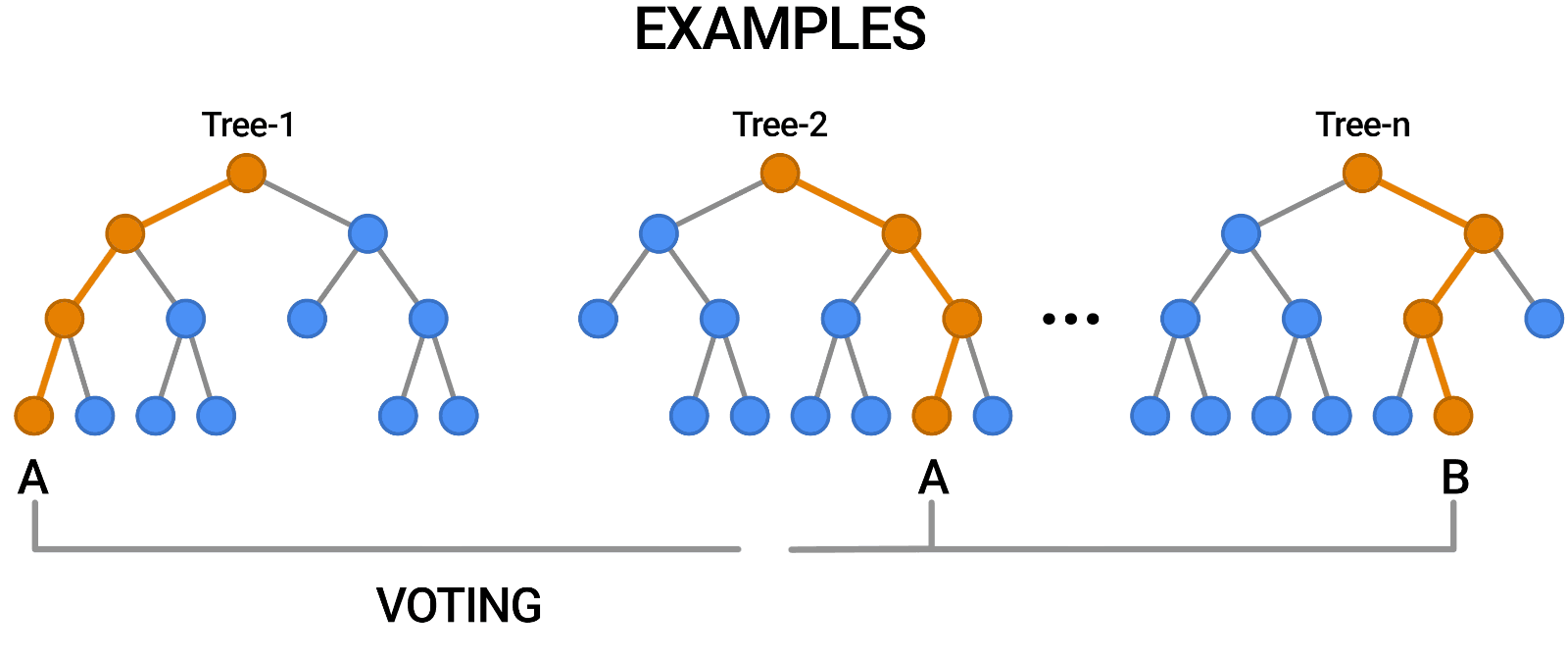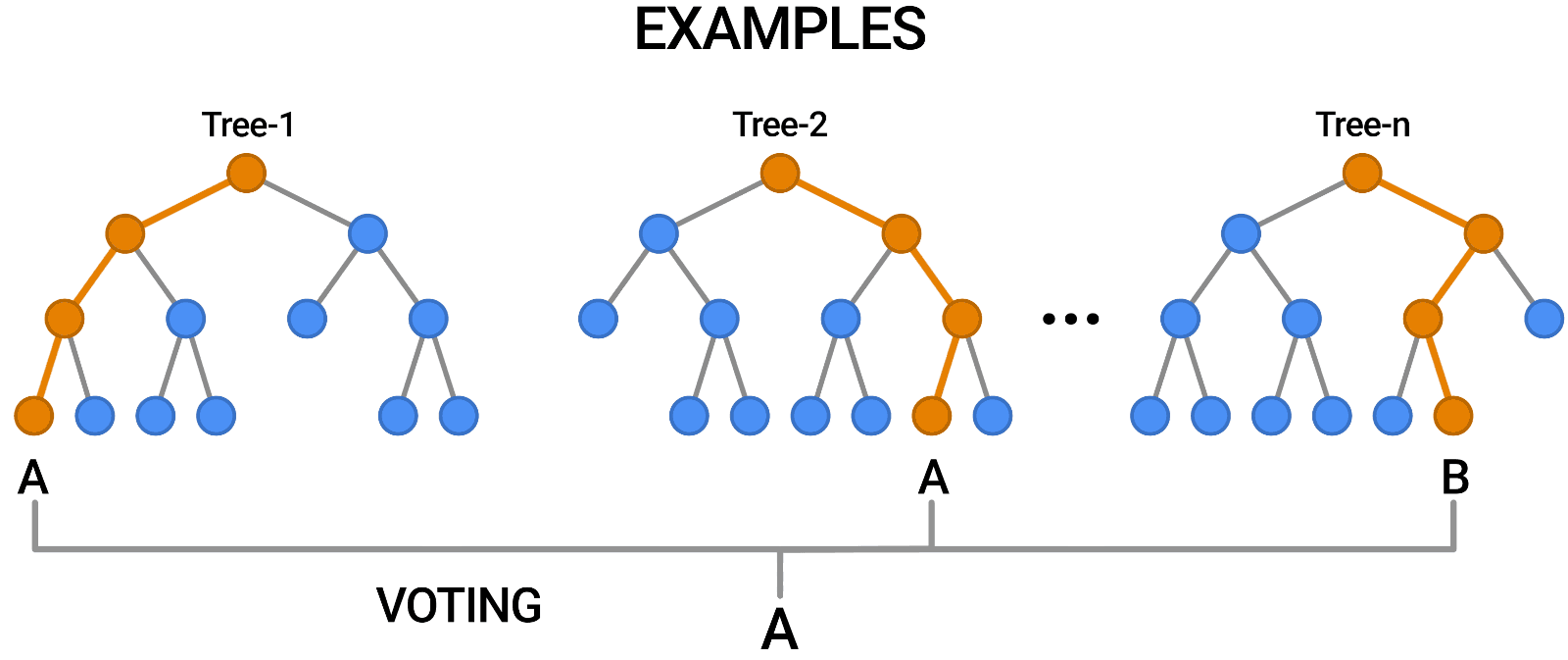
Source : https://blog.tensorflow.org/2021/05/introducing-tensorflow-decision-forests.html
|
AVANTAGES |
CONS |
|
Les forêts aléatoires peuvent facilement traiter les relations non linéaires dans les données. |
Difficile à interpréter en raison de la présence de plusieurs arbres. |
|
Les forêts aléatoires effectuent implicitement une sélection des caractéristiques. |
Les forêts aléatoires sont coûteuses en termes de calcul pour les grands ensembles de données. |
Le théorème de Bayes est une formule mathématique utilisée pour calculer les probabilités conditionnelles, et Naive Bayes est une application de cette formule. La probabilité qu'un résultat se produise si un autre événement a déjà eu lieu est appelée probabilité conditionnelle.
Il prédit que les probabilités de chaque classe appartiennent à une classe spécifique et que la classe ayant la probabilité la plus élevée est celle qui est considérée comme la plus probable.
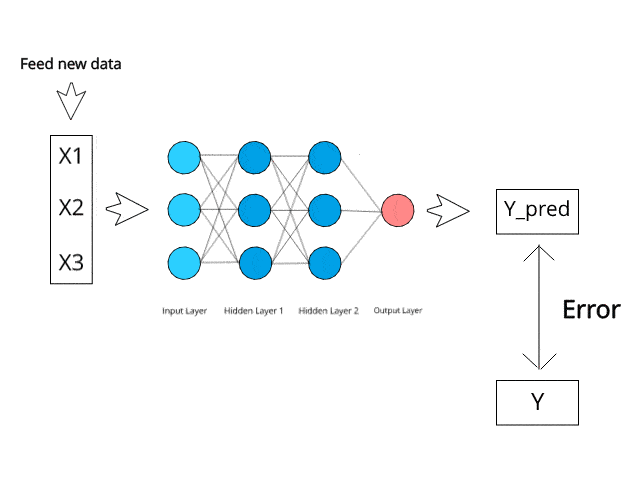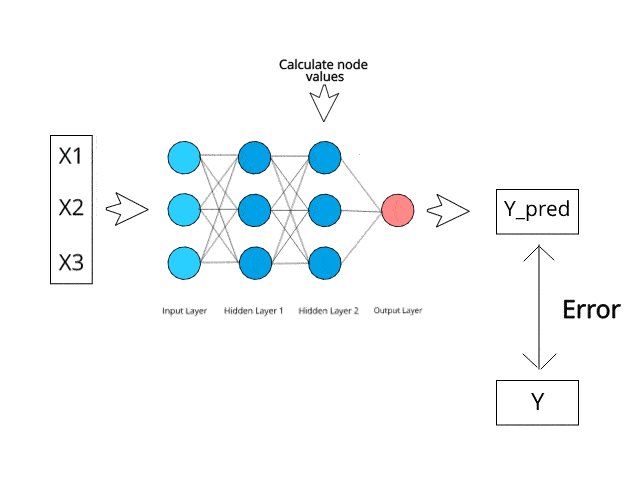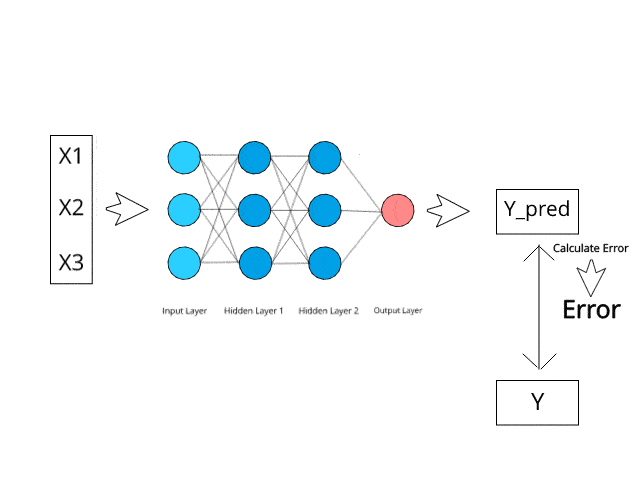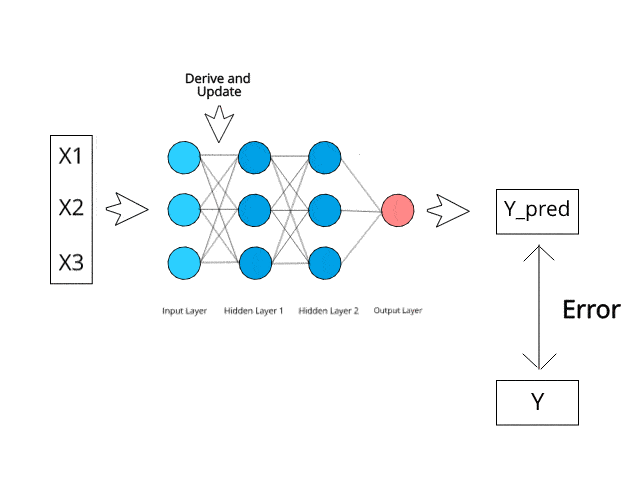
Source de l'image : https://www.kdnuggets.com/2019/10/introduction-artificial-neural-networks.html
|
AVANTAGES |
CONS |
|
L'algorithme est très rapide. |
Il suppose que toutes les caractéristiques sont indépendantes. |
|
Il est simple et facile à mettre en œuvre |
L'algorithme se heurte au "problème de la fréquence zéro", qui consiste à attribuer à une variable catégorielle une probabilité nulle si sa catégorie n'est pas présente dans l'ensemble de données d'apprentissage. |
Dans cette partie, nous allons utiliser scikit-learn en Python pour entraîner un modèle de régression logistique (classification) sur un jeu de données factices. Consultez l'intégralité du carnet de notes ici.
```
# create fake binary classification dataset with 1000 rows and 10 features
from sklearn.datasets import make_classification
X, y = make_classification(n_samples = 1000, n_features = 10, n_classes = 2)
# check shape of X and y
X.shape, y.shape
# train test split
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
# import and initialize logistic regression model
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
# fit logistic regression model
lr.fit(X_train, y_train)
# generate hard predictions on test set
y_pred = lr.predict(X_test)
y_pred
# evaluate accuracy score of the model
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_pred)
```Si vous souhaitez apprendre l'apprentissage automatique supervisé en R, consultez ce cours Supervised Learning in R par DataCamp. Dans ce cours, vous apprendrez les bases de l'apprentissage automatique pour la classification dans le langage de programmation R.
L'apprentissage automatique a complètement changé la façon dont nous menons nos activités ces dernières années. L'innovation radicale qui distingue l'apprentissage automatique des autres stratégies d'automatisation consiste à s'éloigner de la programmation basée sur des règles. Grâce aux techniques d'apprentissage automatique supervisé, les ingénieurs peuvent utiliser des données sans former explicitement des machines à résoudre des problèmes d'une certaine manière.
Dans l'apprentissage automatique supervisé, la solution attendue d'un problème peut ne pas être connue pour les données futures, mais peut être connue et capturée dans un ensemble de données historiques et le travail des algorithmes d'apprentissage supervisé est d'apprendre cette relation à partir des données historiques pour prédire un résultat, un événement ou une valeur à l'avenir.
Dans cet article, nous avons acquis une compréhension fondamentale de ce qu'est l'apprentissage supervisé et de la manière dont il diffère de l'apprentissage non supervisé. Nous avons également passé en revue quelques algorithmes courants de l'apprentissage supervisé. Cependant, il y a beaucoup de choses que nous n'avons pas abordées, comme l'évaluation des modèles, la validation croisée ou l'ajustement des hyperparamètres. Si vous souhaitez approfondir l'un de ces sujets et développer vos compétences, consultez ces cours intéressants :
Cours pour l'apprentissage automatique
Cours
Cours
Cours
blog
Nathaniel Taylor-Leach
8 min
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach