
Cours
Concevoir des systèmes agentiques avec LangChain
3 h
12.1K
Mistral Large 3 est un modèle multimodal MoE conçu pour lire, analyser et structurer les informations issues de documents visuels complexes. Au lieu de traiter les graphiques et les fichiers PDF comme des images statiques, il est conçu pour extraire des tableaux, des informations et générer des récits soignés à partir de ceux-ci.
Dans ce tutoriel, nous utiliserons le modèle Mistral Large 3 (mistral-large-2512) pour créer un hub d'évaluation de l'intelligence multimodale ( ) dans Streamlit. Le flux se présente comme suit :
Tout cela est réalisé à l'aide d'un modèle unique (mistral-large-2512), d'un point de terminaison unique (/v1/chat/completions) et d'un schéma JSON strict afin de garantir la structure et la fiabilité des résultats.
Je vous recommande de lire notre article sur le Mistral 3, qui présente les principales caractéristiques des nouveaux modèles.
Mistral Large 3 est une architecture MOE (mixture-of-experts) clairsemée avec 41 milliards de paramètres actifs sur un total de 675 milliards et un encodeur de vision à 2,5 milliards de paramètres pour la compréhension des images.
Voici quelques propriétés clés pertinentes pour ce modèle :
La fiche modèle et la documentation relative à l'écosystème mentionnent également certaines mises en garde importantes :
Dans cette section, nous allons créer un centre d'évaluation de l'intelligence multimodale à l'aide de Mistral Large 3 intégré dans une application Streamlit. À un niveau élevé, voici ce que fait l'application finale :
mistral-large-2512, qui utilise response_format en mode JSON Schema pour renvoyer une charge utile JSON structurée.Cela transforme un rapport visuel statique en un assistant intelligent interactif entièrement alimenté par Mistral Large 3.

Construisons-le étape par étape.
Avant de pouvoir développer notre démonstration Streamlit sur Mistral Large 3, nous avons besoin d'un environnement local de base pour communiquer avec le modèle via l'API Mistral. Commencez par installer quelques bibliothèques d'aide pour gérer l'interface utilisateur, les documents et la configuration.
pip install streamlit mistralai pillow pdf2image pandas python-dotenvNous utiliserons les bibliothèques principales ci-dessus telles que streamlit pour l'interface utilisateur interactive de l'application web, mistralai pour communiquer avec l'API Mistral, pillow et pdf2image pour ouvrir et convertir des fichiers PDF en images, pandas pour traiter toutes les données tabulaires ou les journaux, et python-dotenv pour charger en toute sécurité des variables d'environnement telles que MISTRAL_API_KEY à partir d'un fichier .env.
Ensuite, veuillez vous connecter à la plateforme Mistral AI et accédez à la section Clés API ..
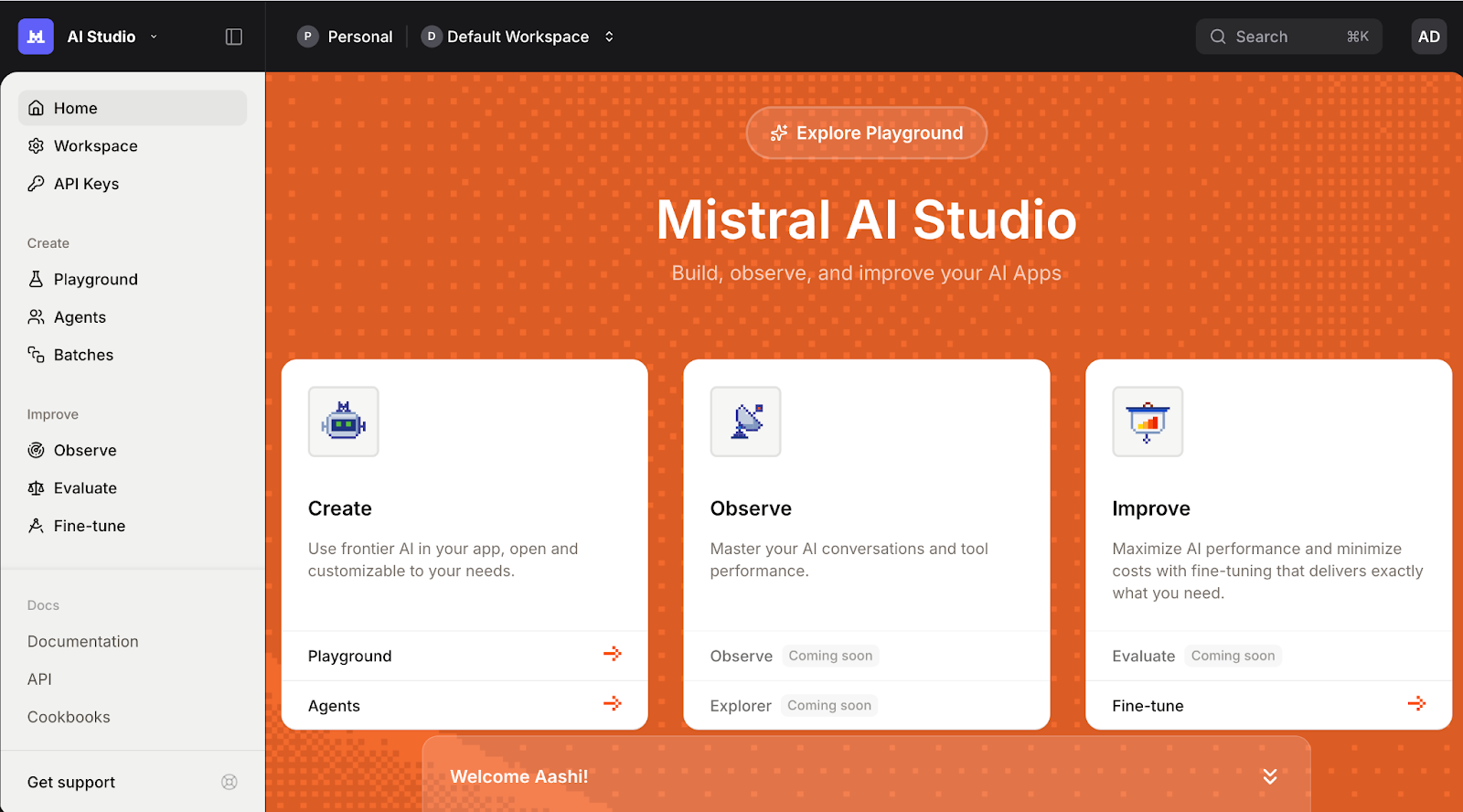
Définissez votre espace de travail par défaut (si vous y êtes invité) et cliquez sur Créer une nouvelle clé.
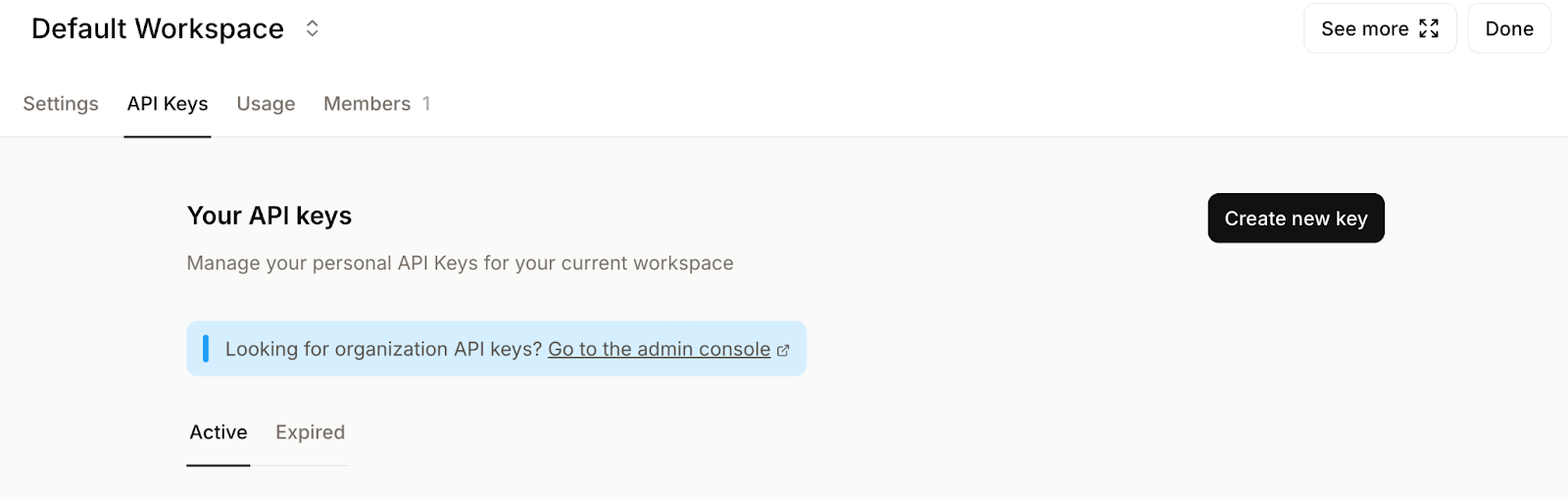
Veuillez attribuer un nom significatif à votre clé et, si vous le souhaitez, définir une date d'expiration.
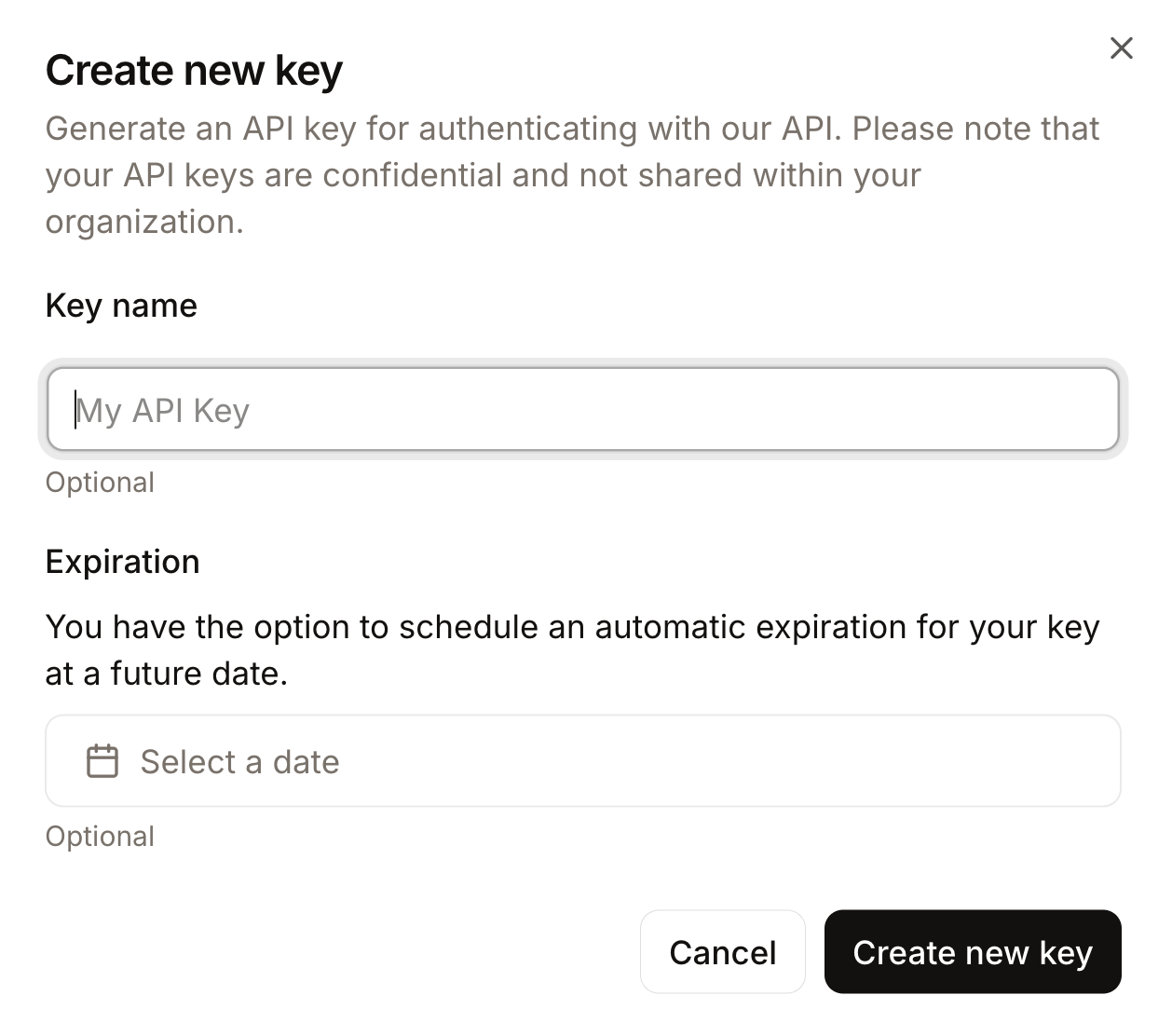
Enfin, veuillez copier la clé générée et l'exporter sous forme de fichier variable d'environnement comme suit :
export MISTRAL_API_KEY="your_mistral_api_key_here"À ce stade, notre environnement est désormais prêt pour l'authentification avec l'API Mistral.
Une fois l'environnement configuré et les dépendances installées, l'étape suivante consiste à initialiser le client Mistral qui gérera tous nos appels vers le modèle Mistral Large 3. Cela nous fournit un point d'entrée pour envoyer des invites depuis notre application Streamlit vers Mistral Large 3.
MISTRAL_API_KEY = os.getenv("MISTRAL_API_KEY")
MODEL_ID = "mistral-large-2512"
if MISTRAL_API_KEY is None:
raise RuntimeError("Please set the MISTRAL_API_KEY environment variable.")
client = MistralClient(api_key=MISTRAL_API_KEY)Le bloc de code ci-dessus effectue trois opérations :
MISTRAL_API_KEY e de notre environnement et stocke le nom du modèle dans MODEL_ID, ce qui nous permet de le réutiliser dans toute l'application.MistralClient à l'aide du SDK officiel mistralai, que nous utiliserons pour toutes les requêtes ultérieures adressées au modèle.Une fois le client initialisé, nous allons créer quelques fonctions d'aide qui envoient des invites et gèrent les réponses dans l'interface utilisateur Streamlit.
Avant d'envoyer des images ou des fichiers PDF à Mistral Large 3, il est nécessaire de les rendre « compatibles avec le modèle ». L'API Vision fonctionne de manière optimale lorsque les entrées sont carrées, de taille raisonnable et encodées dans un format cohérent.
Nous commençons par charger l'image téléchargée et la convertir en un recadrage carré.
def load_image_from_upload(uploaded_file) -> Image.Image:
return Image.open(io.BytesIO(uploaded_file.read())).convert("RGB")
def center_crop_to_square(img: Image.Image) -> Image.Image:
width, height = img.size
if width == height:
return img
if width > height:
offset = (width - height) // 2
box = (offset, 0, offset + height, height)
else:
offset = (height - width) // 2
box = (0, offset, width, offset + width)
return img.crop(box)Le bloc de code ci-dessus garantit que les graphiques ou tableaux que nous téléchargeons sont convertis en un recadrage carré avant d'être transmis au modèle, conformément aux directives de Mistral en matière de vision.
Ensuite, nous redimensionnons l'image à une taille maximale (1024 × 1024) afin d'équilibrer la qualité, la latence et le coût des jetons.
def resize_for_vlm(img: Image.Image, max_size: int = 1024) -> Image.Image:
width, height = img.size
scale = min(max_size / width, max_size / height, 1.0)
if scale == 1.0:
return img
new_w = int(width * scale)
new_h = int(height * scale)
return img.resize((new_w, new_h), Image.LANCZOS)Ici, nous calculons un facteur d'scale e qui maintient les deux dimensions en dessous de l'max_size e tout en préservant le rapport d'aspect. Si l'image est déjà suffisamment petite, nous la renvoyons telle quelle. Sinon, nous calculons les nouvelles dimensions et utilisons LANCZOS pour obtenir une réduction de taille de haute qualité.
Cette étape garantit que les images n'encombrent pas votre fenêtre contextuelle et ne ralentissent pas inutilement les réponses.
Pour les fichiers PDF, nous souhaitons souvent afficher le modèle sur plusieurs pages. Une astuce simple consiste à afficher toutes les pages et à les empiler verticalement pour former une seule image haute.
def stack_images_vertically(images: List[Image.Image]) -> Image.Image:
if not images:
raise ValueError("No images to stack")
target_width = images[0].size[0]
resized_images = []
for img in images:
if img.size[0] != target_width:
aspect_ratio = img.size[1] / img.size[0]
new_height = int(target_width * aspect_ratio)
img = img.resize((target_width, new_height), Image.LANCZOS)
resized_images.append(img)
total_height = sum(img.size[1] for img in resized_images)
stacked = Image.new('RGB', (target_width, total_height))
y_offset = 0
for img in resized_images:
stacked.paste(img, (0, y_offset))
y_offset += img.size[1]
return stacked
def uploaded_file_to_square_base64(uploaded_file) -> Tuple[str, str]:
mime_type = uploaded_file.type
raw_bytes = uploaded_file.getvalue()
if mime_type == "application/pdf":
pages = convert_from_bytes(raw_bytes)
pages_rgb = [page.convert("RGB") for page in pages]
img = stack_images_vertically(pages_rgb)
img = resize_for_vlm(img, max_size=1024)
mime_type = "image/png"
else:
img = Image.open(io.BytesIO(raw_bytes)).convert("RGB")
img = center_crop_to_square(img)
img = resize_for_vlm(img, max_size=1024)
return mime_type, image_to_base64_data_url(img, mime_type=mime_type)La fonction stack_images_vertically() prend une liste d'images PIL, les normalise à une largeur commune tout en conservant leur rapport d'aspect, calcule la hauteur totale et les assemble les unes sous les autres dans un seul canevas RVB. Lafonction uploaded_file_to_square_base64() détermine ensuite la marche à suivre en fonction du type MIME :
Dans les deux cas, il renvoie une image normalisée accompagnée d'un type MIME pour l'étape finale d'encodage.
L'API Vision de Mistral accepte les images sous forme d'objets image_url, qui peuvent être soit des URL réelles, soit des URL data:.
def image_to_base64_data_url(img: Image.Image, mime_type: str = "image/png") -> str:
buffer = io.BytesIO()
if mime_type == "image/jpeg":
img.save(buffer, format="JPEG", quality=90)
else:
img.save(buffer, format="PNG")
mime_type = "image/png"
b64 = base64.b64encode(buffer.getvalue()).decode("utf-8")
return f"data:{mime_type};base64,{b64}"Nous commençons par enregistrer l'image dans une mémoire tampon et sélectionner un format approprié (tel que JPEG ou PNG), avant de procéder au codage base64 des octets.
Enfin, nous intégrons la chaîne codée dans une URL data:{mime_type};base64 qui peut être transmise directement à l'API Mistral Vision sous la forme image_url.
À la fin de cette étape, chaque fichier téléchargé, qu'il s'agisse d'un simple fichier PNG, d'un tableau de bord large ou d'un PDF de plusieurs pages, suit le même processus de recadrage central, de redimensionnement, d'empilement de PDF et de conversion en URL de données base64.
Dans cette étape, nous regroupons tous les éléments dans une seule fonction d'aide qui envoie une requête Vision Plus Text et oblige le modèle à répondre au format JSON. Nous y parvenons en combinant :
response_format afin que le résultat soit structuré et facile à analyser.def call_mistral_large_multimodal(
mime_type: str,
image_data_url: str,
user_instruction: str,
languages: List[str],
) -> Dict[str, Any]:
json_schema = {
"type": "object",
"properties": {
"csv_tables": {
"type": "array",
"items": {"type": "string"},
"description": "Each item is a CSV string representing one table found in the image."
},
"insights": {
"type": "array",
"items": {"type": "string"},
"description": "Up to 5 key insights about the content."
},
"risks": {
"type": "array",
"items": {"type": "string"},
"description": "Up to 5 key risks or red flags."
},
"anomalies": {
"type": "array",
"items": {"type": "string"},
"description": "Any anomalies, outliers, or surprising patterns you detect."
},
"translations": {
"type": "object",
"properties": {
lang: {"type": "string"} for lang in languages
},
"description": "Short high-level summaries in the selected languages."
},
},
"required": ["csv_tables", "insights", "risks"],
"additionalProperties": False,
}
system_prompt = (
"You are a Multimodal Intelligence Evaluator using Mistral Large 3.\n"
"You are given a single document-like image (e.g. chart + table, financial report page).\n\n"
"Your tasks:\n"
"1. Read all visible text and numbers directly from the image.\n"
"2. Reconstruct any clearly visible tables into valid CSV strings.\n"
" - Use the first row as headers when possible.\n"
" - Use commas as separators and newline per row.\n"
"3. Derive up to 5 concise INSIGHTS about trends, patterns, or takeaways.\n"
"4. Derive up to 5 concise RISKS or red flags (business, financial, operational, etc.).\n"
"5. Detect any anomalies or surprising patterns if present (else return an empty list).\n"
"6. Provide short summaries in the requested languages.\n\n"
"You MUST respond ONLY with a JSON object that matches the provided JSON schema.\n"
"Do not include any extra commentary outside of the JSON."
)
messages = [
{
"role": "system",
"content": [
{"type": "text", "text": system_prompt},
],
},
{
"role": "user",
"content": [
{
"type": "text",
"text": user_instruction or "Analyze this financial report page.",
},
{
"type": "image_url",
"image_url": image_data_url,
},
],
},
]
response = client.chat(
model=MODEL_ID,
messages=messages,
temperature=0.2,
max_tokens=2048,
response_format={
"type": "json_schema",
"json_schema": {
"name": "multimodal_intel_eval",
"schema": json_schema,
"strict": True,
},
},
)
content = response.choices[0].message.content
try:
parsed = json.loads(content)
except json.JSONDecodeError:
try:
start = content.index("{")
end = content.rindex("}") + 1
parsed = json.loads(content[start:end])
except Exception:
raise ValueError(f"Model did not return valid JSON. Raw content:\n{content}")
return parsedLa fonction d'call_mistral_large_multimodal() s constitue le moteur central de la démonstration d'intelligence multimodale.
csv_tables, insights, risks, anomalies et un objet translations avec des clés dérivées de la liste languages. call_mistral_large_multimodal() construit ensuite le tableau de messages au format chat en combinant les instructions système avec un message utilisateur qui comprend à la fois les instructions textuelles et la charge utile image_url. Il appelle client.chat() avec MODEL_ID tout en maintenant la température basse pour une sortie déterministe, et response_format={"type": "json_schema",}, afin que la réponse soit conforme au schéma. Enfin, nous tentons de l'analyser avec json.loads.Une fois cela en place, vous disposez désormais d'un point d'entrée solide pour transformer un graphique ou un rapport brut en un récit structuré.
Une fois le pipeline de prétraitement et le client Mistral mis en place, la dernière étape consiste à intégrer l'ensemble dans une interface Streamlit.
st.set_page_config(
page_title="Multimodal Intelligence Evaluation Hub - Mistral Large 3",
layout="wide",
)
st.title("Multimodal Intelligence Evaluation Hub")
st.caption("Powered by **Mistral Large 3**")
col_left, col_right = st.columns([2, 1])
with col_left:
uploaded_file = st.file_uploader(
"Upload an image or report (PNG, JPG, WEBP, or PDF)",
type=["png", "jpg", "jpeg", "webp", "pdf"],
)
default_prompt = (
"Give me 3–5 key insights and risks from this input and export any tables you see as CSV "
"Also write down the findings for a professional audience."
)
user_instruction = st.text_area(
"Instruction to Mistral Large 3",
value=default_prompt,
height=120,
)
with col_right:
st.subheader("Multilingual Options")
languages = st.multiselect(
"Additional summary languages",
options=["fr", "de", "es", "hi", "zh", "ja"],
default=["hi"],
help="Mistral Large 3 supports dozens of languages; these will receive short summaries.",
label_visibility="collapsed",
)
run_button = st.button("Run Analysis", type="primary")
if run_button:
if uploaded_file is None:
st.error("Please upload an image or PDF first.")
st.stop()
prep_msg = "Preparing PDF (combining all pages)..." if uploaded_file.type == "application/pdf" else "Preparing image..."
with st.spinner(prep_msg):
mime_type, data_url = uploaded_file_to_square_base64(uploaded_file)
mime, b64_part = data_url.split(",", 1)
img_bytes = base64.b64decode(b64_part)
st.image(img_bytes, caption="Center-cropped & resized image for the model", width=400)
with st.spinner("Processing..."):
try:
result = call_mistral_large_multimodal(
mime_type=mime_type,
image_data_url=data_url,
user_instruction=user_instruction,
languages=languages,
)
except Exception as e:
st.error(f"Error calling Mistral Large 3: {e}")
st.stop()
st.header("Results")
csv_tables = result.get("csv_tables", [])
if csv_tables:
st.subheader("Reconstructed Tables (CSV)")
for i, csv_str in enumerate(csv_tables):
st.markdown(f"**Table {i+1}**")
try:
df = pd.read_csv(io.StringIO(csv_str))
st.dataframe(df, use_container_width=True)
except Exception:
st.text_area(f"Raw CSV for Table {i+1}", value=csv_str, height=150)
st.download_button(
label=f"Download Table {i+1} as CSV",
data=csv_str,
file_name=f"table_{i+1}.csv",
mime="text/csv",
key=f"csv_download_{i}",
)
else:
st.info("No tables were detected or reconstructed.")
insights = result.get("insights", [])
risks = result.get("risks", [])
anomalies = result.get("anomalies", [])
col_ins, col_risk = st.columns(2)
with col_ins:
st.subheader("Key Insights")
if insights:
for bullet in insights:
st.markdown(f"- {bullet}")
else:
st.write("_No explicit insights returned._")
with col_risk:
st.subheader("Risks")
if risks:
for bullet in risks:
st.markdown(f"- {bullet}")
else:
st.write("_No explicit risks returned._")
st.subheader("Anomalies")
if anomalies:
for bullet in anomalies:
st.markdown(f"- {bullet}")
else:
st.write("_No anomalies reported._")
translations = result.get("translations", {}) or {}
if translations:
st.subheader(" Multilingual Summaries")
for lang_code, summary in translations.items():
with st.expander(f"Summary in {lang_code}"):
st.write(summary)
else:
st.info("No multilingual summaries were requested or returned.")
# Raw JSON (debug)
# with st.expander(" Raw JSON (debug)"):
# st.json(result)Le code StreamLit UI ci-dessus effectue plusieurs opérations essentielles :
La méthode ` st.set_page_config ` divise la mise en page en deux colonnes. Le côté gauche gère les entrées principales (téléchargeur de fichiers et zone de texte modifiable avec des instructions par défaut). En revanche, le côté droit propose des options multilingues via st.multiselect et un bouton principal « » (Analyse des courses). Lorsque l'utilisateur clique sur le bouton, l'application vérifie la présence d'un fichier, convertit les images ou les PDF en URL de données base64 et affiche l'aperçu de l'image.
Une fois les résultats obtenus, les tableaux CSV reconstitués sont présentés sous forme de DataFrame, accompagnés d'informations, de risques, d'anomalies et de résumés multilingues. En option, nous pouvons également déboguer les vues (commentées), ce qui nous permet d'inspecter le JSON brut pendant le développement.
Une fois cette étape terminée, vous pouvez enregistrer l'ensemble sous le nom app.py et lancer l'expérience complète à l'aide de la commande suivante :
streamlit run app.pyDans la vidéo ci-dessous, vous pouvez observer une version abrégée du flux de travail en action avec des entrées sous forme d'images et de PDF :
Meilleurs cours DataCamp
Cours
Cours
Cours
blog
Kurtis Pykes
9 min
blog
blog
Kurtis Pykes
15 min
Tutoriel
Tutoriel
DataCamp Team
Tutoriel
Matt Crabtree
