
Cursus
Traitement du langage naturel en Python
20 h
Les percées scientifiques ont rarement lieu dans le vide. Au contraire, ils sont souvent l'avant-dernière marche d'un escalier construit sur la base des connaissances humaines accumulées. Pour comprendre le succès des grands modèles de langage (LLM), tels que ChatGPT et Google Bart, nous devons remonter dans le temps et parler de l'ORET.
Développé en 2018 par des chercheurs de Google, BERT est l'un des premiers LLM. Grâce à ses résultats étonnants, il est rapidement devenu une référence omniprésente dans les tâches de NLP, notamment la compréhension du langage général, les questions-réponses et la reconnaissance des entités nommées.
Vous souhaitez en savoir plus sur les LLM ? Commencez dès aujourd'hui le chapitre 1 de notre cours sur les concepts des grands modèles linguistiques (LLM).
On peut dire que BERT a ouvert la voie à la révolution de l'IA générative à laquelle nous assistons aujourd'hui. Bien qu'il s'agisse de l'un des premiers LLM, le BERT est encore largement utilisé, avec des milliers de modèles BERT open-source, gratuits et pré-entraînés disponibles pour des cas d'utilisation spécifiques, tels que l'analyse des sentiments, l'analyse des notes cliniques et la détection des commentaires toxiques.
Vous êtes curieux de savoir ce qu'est l'ORET ? Poursuivez la lecture de cet article, où nous explorerons l'architecture de Ber, le fonctionnement interne de la technologie, certaines de ses applications dans le monde réel et ses limites.
BERT (pour Bidirectional Encoder Representations from Transformers) est un modèle open-source développé par Google en 2018. Il s'agissait d'une expérience ambitieuse visant à tester les performances du transformateur - une architecture neuronale innovante présentée par les chercheurs de Google dans le célèbre article Attention is All You Need en 2017 - sur des tâches de langage naturel (NLP).
La clé du succès de BERT réside dans l'architecture de son transformateur. Avant l'arrivée des transformateurs, la modélisation du langage naturel était une tâche très difficile. Malgré l'essor des réseaux neuronaux sophistiqués - à savoir les réseaux neuronaux récurrents ou convolutifs - les résultats n'ont été que partiellement satisfaisants.
La principale difficulté réside dans le mécanisme des réseaux neuronaux utilisés pour prédire le mot manquant dans une phrase. À l'époque, les réseaux neuronaux de pointe reposaient sur l'architecture codeur-décodeur, un mécanisme puissant mais gourmand en temps et en ressources, qui n'est pas adapté à l'informatique parallèle.
C'est en tenant compte de ces défis que les chercheurs de Google ont mis au point le transformateur, une architecture neuronale innovante basée sur le mécanisme de l'attention, comme l'explique la section suivante.
Examinons le fonctionnement de l'ORET, en abordant la technologie qui sous-tend le modèle, la manière dont il est formé et la façon dont il traite les données.
Les réseaux neuronaux récurrents et convolutifs utilisent le calcul séquentiel pour générer des prédictions. En d'autres termes, ils peuvent prédire quel mot suivra une séquence de mots donnée après avoir été entraînés sur d'énormes ensembles de données. En ce sens, ils ont été considérés comme des algorithmes unidirectionnels ou sans contexte.
En revanche, les modèles à transformateur comme BERT, qui sont également basés sur l'architecture codeur-décodeur, sont bidirectionnels car ils prédisent les mots en se basant sur les mots précédents et les mots suivants. Ce résultat est obtenu grâce au mécanisme d'auto-attention, une couche qui est incorporée à la fois dans le codeur et dans le décodeur. L'objectif de la couche d'attention est de capturer les relations contextuelles existant entre les différents mots de la phrase d'entrée.
Aujourd'hui, il existe de nombreuses versions de BERT pré-entraînées, mais dans l'article original, Google a entraîné deux versions de BERT : BERTbase et BERTlarge avec différentes architectures neuronales. Essentiellement, BERTbase a été développé avec 12 couches de transformateurs, 12 couches d'attention et 110 millions de paramètres, tandis que BERTlarge a utilisé 24 couches de transformateurs, 16 couches d'attention et 340 millions de paramètres. Comme prévu, le BERTlarge a surpassé son petit frère dans les tests de précision.
Pour savoir en détail comment fonctionne l'architecture codeur-décodeur dans les transformateurs, nous vous recommandons vivement de lire notre Introduction à l'utilisation des transformateurs et Hugging Face.
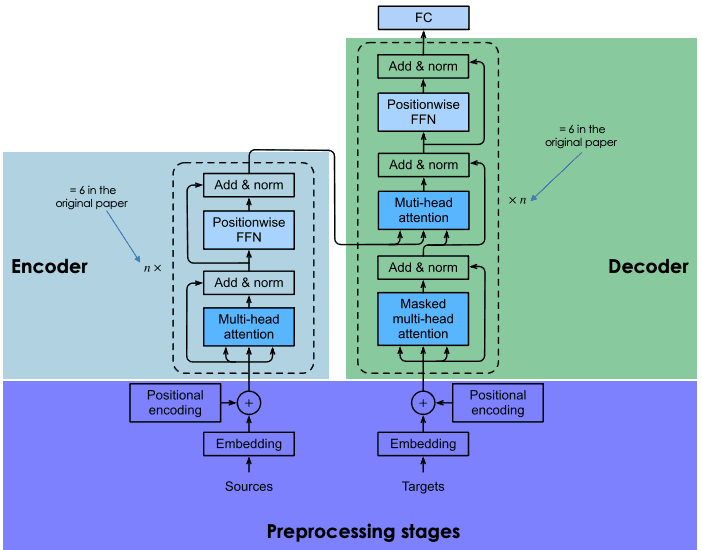
Explication de l'architecture des transformateurs
Les transformateurs sont formés à partir de zéro sur un énorme corpus de données, selon un processus long et coûteux (que seul un groupe limité d'entreprises, dont Google, peut se permettre).
Dans le cas de BERT, il a été pré-entraîné pendant quatre jours sur Wikipedia (~2,5 milliards de mots) et sur le BooksCorpus de Google (~800 millions de mots). Cela permet au modèle d'acquérir des connaissances non seulement en anglais, mais aussi dans de nombreuses autres langues du monde entier.
Pour optimiser le processus de formation, Google a développé un nouveau matériel, le TPU (Tensor Processing Unit), spécialement conçu pour les tâches d'apprentissage automatique.
Pour éviter les interactions inutiles et coûteuses dans le processus de formation, les chercheurs de Google ont utilisé des techniques d'apprentissage par transfert pour séparer la phase de (pré)formation de la phase de mise au point. Cela permet aux développeurs de choisir des modèles pré-entraînés, d'affiner les données du couple entrée-sortie de la tâche cible et de réentraîner la tête du modèle pré-entraîné en utilisant des données spécifiques au domaine. C'est cette caractéristique qui fait des LLM comme BERT le modèle de base d' une infinité d'applications construites au-dessus d'eux,
L'élément clé pour réaliser l'apprentissage bidirectionnel dans BERT (et tout LLM basé sur des transformateurs) est le mécanisme d'attention. Ce mécanisme est basé sur la modélisation du langage masqué (MLM). En masquant un mot dans une phrase, cette technique oblige le modèle à analyser les mots restants dans les deux sens de la phrase afin d'augmenter les chances de prédire le mot masqué. La MLM est basée sur des techniques déjà éprouvées dans le domaine de la vision par ordinateur, et elle est idéale pour les tâches qui nécessitent une bonne compréhension contextuelle de l'ensemble d'une séquence.
BERT a été le premier LLM à appliquer cette technique. En particulier, un pourcentage aléatoire de 15 % des mots symbolisés a été masqué pendant la formation. Le résultat montre que BERT peut prédire les mots cachés avec une grande précision.
Vous êtes curieux d'en savoir plus sur la modélisation du langage masqué ? Consultez notre cours sur les concepts des grands modèles linguistiques (LLM ) pour connaître tous les détails de cette technique innovante.
Alimenté par des transformateurs, le BERT a été en mesure d'obtenir des résultats de pointe dans de multiples tâches NLP. Voici quelques-uns des tests où BERT excelle :
De nombreux LLM ont été testés dans des ensembles expérimentaux, mais peu ont été incorporés dans des applications bien établies. Ce n'est pas le cas de l'ORET, qui est utilisé chaque jour par des millions de personnes (même si nous n'en sommes pas conscients).
La recherche Google en est un bon exemple. En 2020, Google a annoncé qu'il avait adopté l'ORET par le biais de Google Search dans plus de 70 langues. Cela signifie que Google utilise BERT pour classer le contenu et afficher les extraits en vedette. Grâce au mécanisme d'attention, Google peut désormais utiliser le contexte de votre question pour vous fournir des informations utiles, comme le montre l'exemple suivant.
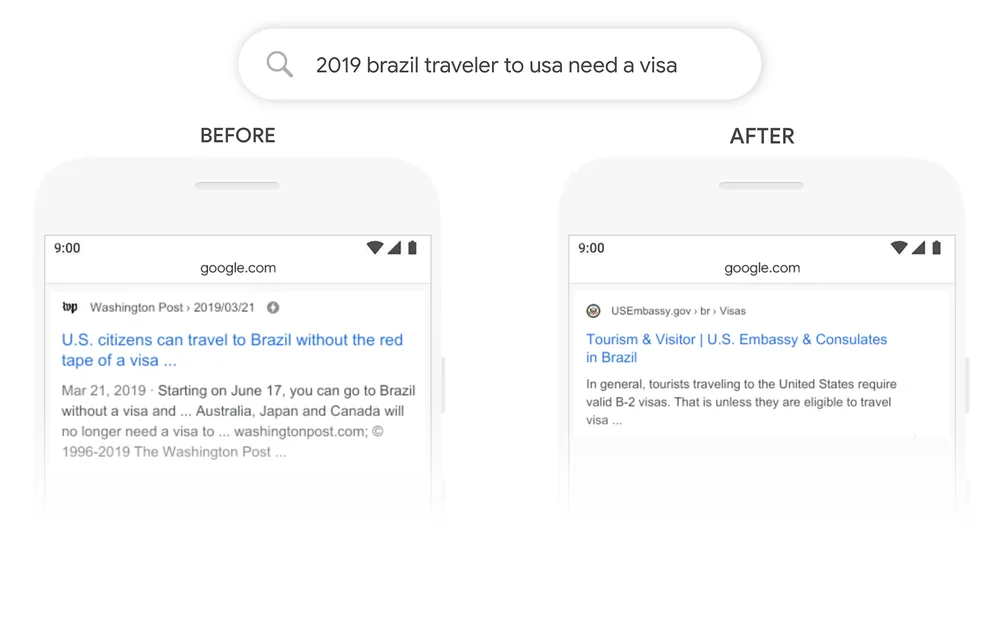
Source : Google
Mais ce n'est qu'une partie de l'histoire. Le succès de l'ORET est dû en grande partie à sa nature de logiciel libre, qui a permis aux développeurs d'accéder au code source de l'ORET d'origine et de créer de nouvelles fonctionnalités et améliorations.
Cela a donné lieu à un grand nombre de variantes de l'ORET. Vous trouverez ci-dessous quelques-unes des variantes les plus connues :
Si vous souhaitez en savoir plus sur le mouvement des LLM open-source, nous vous recommandons vivement de lire notre article sur les meilleurs LLM open-source en 2023.
L'une des grandes qualités de l'ORET, et des LLM en général, est que le processus de pré-entraînement est séparé du processus de réglage fin. Cela signifie que les développeurs peuvent prendre des versions pré-entraînées de BERT et les adapter à leurs cas d'utilisation spécifiques.
Dans le cas de BERT, il existe des centaines de versions affinées de BERT développées pour une grande diversité de tâches NLP. Vous trouverez ci-dessous une liste très, très limitée de versions affinées de l'ORET :
BERT s'accompagne des limitations et des problèmes traditionnels associés aux LLM. Les prédictions de l'ORET sont toujours basées sur la quantité et la qualité des données utilisées pour la formation. Si les données d'entraînement sont limitées, médiocres et biaisées, l'ORET peut produire des résultats inexacts et nuisibles, voire des hallucinations LLM.
Dans le cas de l'ORET d'origine, c'est encore plus probable, car le modèle a été formé sans apprentissage par renforcement à partir de commentaires humains (RLHF), une technique standard utilisée par des modèles plus avancés, comme ChatGPT, LLaMA 2 et Google Bard, pour améliorer la sécurité de l'IA. La RLHF consiste à utiliser le retour d'information humain pour contrôler et orienter le processus d'apprentissage du LLM pendant la formation, garantissant ainsi des systèmes efficaces, plus sûrs et fiables.
En outre, bien qu'il puisse être considéré comme un petit modèle par rapport à d'autres LLM de pointe, comme ChatGPT, il nécessite toujours une puissance de calcul considérable pour le faire fonctionner, sans parler de l'entraîner à partir de zéro. Par conséquent, les développeurs disposant de ressources limitées risquent de ne pas pouvoir l'utiliser.
BERT a été l'un des premiers LLM modernes. Mais loin d'être démodé, le BERT reste l'un des LLM les plus performants et les plus largement utilisés. Grâce à sa nature open-source, il existe aujourd'hui de multiples variantes et des centaines de versions pré-entraînées de BERT conçues pour des tâches NLP spécifiques.
Si vous souhaitez suivre l'évolution de l'ORET et des développements récents en matière de PNL, DataCamp est là pour vous aider. Consultez notre documentation et restez à l'écoute de la révolution actuelle de l'IA générative !
Commencez votre voyage PNL dès aujourd'hui !
Cursus
Cours
Cours
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach