
Cursus
Associate AI Engineer pour développeurs
26 h
Meta vient de lancer la série Llama 4, qui comprend deux modèles avancés : Llama 4 Scout et Llama 4 Maverick. Les deux sont à poids ouvert, mais le réglage fin de Llama 4 Scout nécessite quatre GPU H100, et Llama 4 Maverick en nécessite huit. Cela signifie que seules les entreprises disposant de ressources importantes peuvent se permettre de les affiner.
Dans ce blog, je vous montrerai comment peaufiner le Llama 4 Scout pour seulement 10 $ en utilisant la plateforme RunPod. Vous apprendrez :
Nous tenons nos lecteurs informés des dernières nouveautés en matière d'IA en leur envoyant The Median, notre lettre d'information gratuite du vendredi qui analyse les principaux sujets de la semaine. Abonnez-vous et restez à la pointe de la technologie en quelques minutes par semaine :
Allez sur le site de RunPod et créez un compte. Ensuite, allez dans la section Facturation Runpod et ajoutez 25 $ en utilisant la carte de crédit. Vous pouvez également payer avec des crypto-monnaies.
Accédez à la page Mes Pods pour commencer à configurer votre module. Le pod sert de serveur virtuel qui vous fournit les processeurs, les GPU, la mémoire et le stockage nécessaires à vos tâches.
Nous choisirons 3x H200 SXM GPUs, qui fourniront suffisamment de mémoire pour charger le modèle , quantifier le quantifier et l'ajuster sur le nouveau jeu de données. Vous pouvez également utiliser la fonction Unsloth pour exécuter le modèle sur un seul H100, mais cette approche n'a pas fonctionné efficacement dans mon cas.
Pour configurer votre pod, suivez les étapes suivantes :
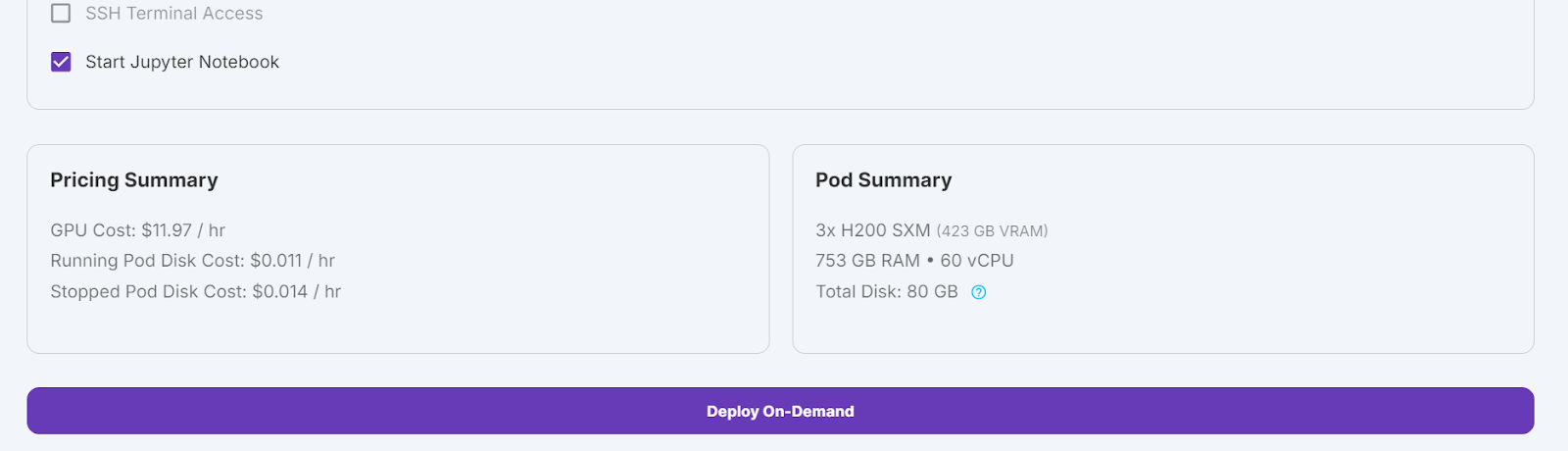
Nous allons modifier notre pod en augmentant la taille du disque du conteneur à 300 Go et en ajoutant la variable d'environnement HF_TOKEN, qui est votre jeton d'accès Hugging Face. Ce jeton est essentiel pour charger et sauvegarder efficacement le modèle.
La mise en place du conteneur prendra un certain temps. Une fois que tout est configuré, cliquez sur le bouton "Connect" et lancez l'Instance JupyterLab.
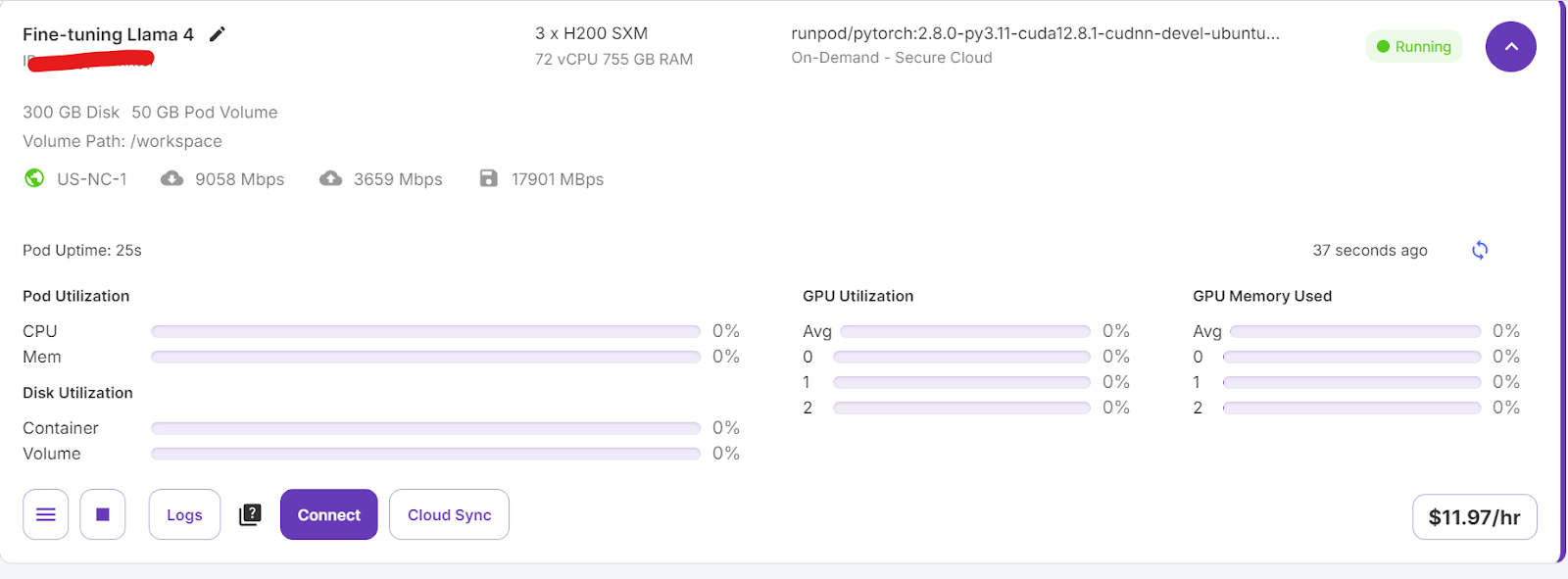
Créez un nouvel ordinateur portable et commencez à utiliser ce nouvel environnement, similaire à votre installation locale.
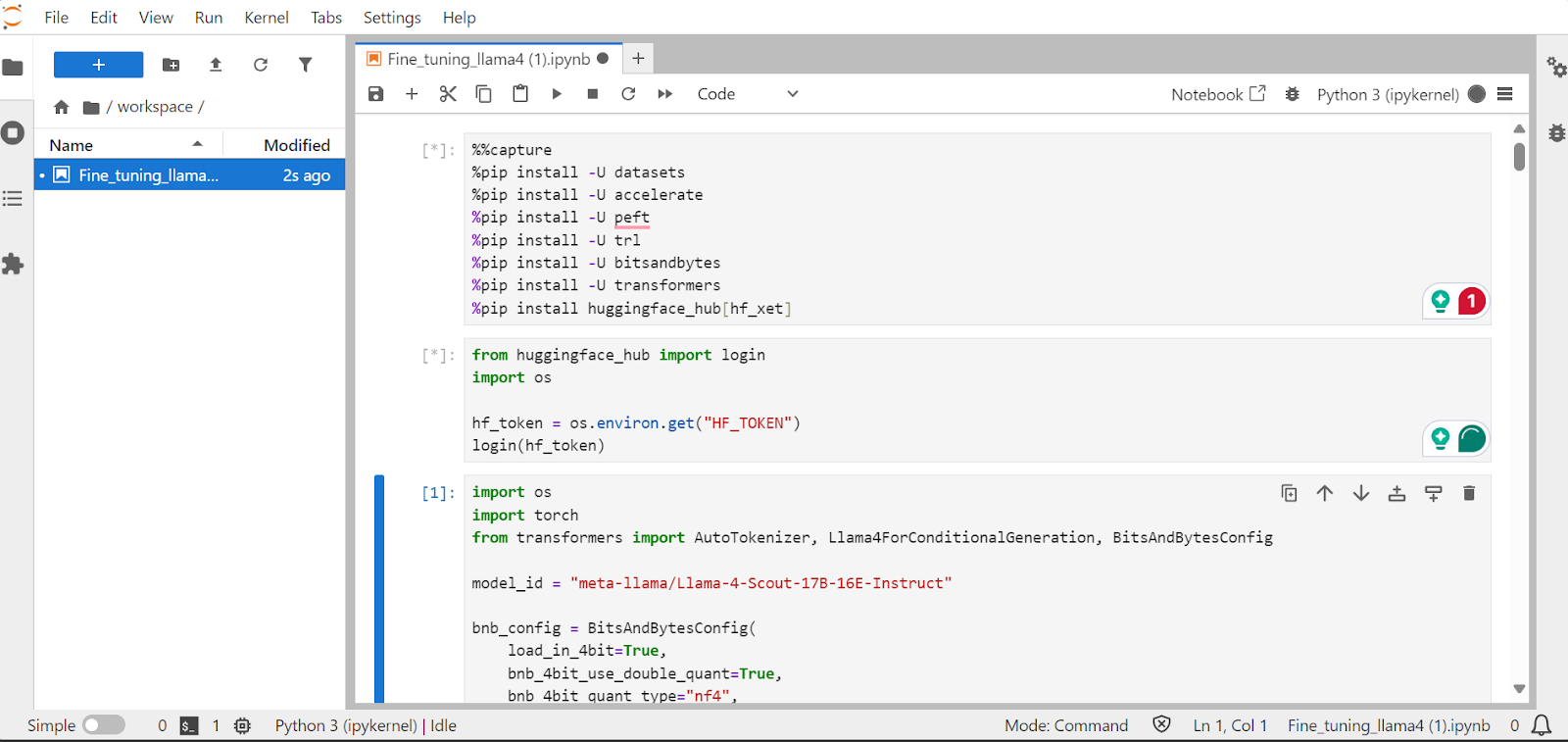
Dans cette section, nous apprendrons comment relever les défis courants lors de la mise au point du nouveau modèle Llama 4, tels que les problèmes de mémoire saturée et les bogues dans la bibliothèque Transformers. Nous verrons également comment charger, affiner et sauvegarder l'adaptateur LoRA de manière transparente. En suivant ces étapes, vous pouvez vous concentrer sur le processus de mise au point sans vous soucier des obstacles techniques.
Nous installerons les paquets Python nécessaires pour affiner les grands modèles de langage.
Note :
xet qui est plus rapide que Git-LFS. Cette intégration permettra de multiplier par trois la vitesse de téléchargement.%%capture
!pip install transformers==4.51.0
%pip install -U datasets
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes
%pip install huggingface_hub[hf_xet]Chargez la clé API à partir de la variable d'environnement variable d'environnement pour vous connecter à Hugging Face. En vous connectant, vous pouvez accéder aux modèles à accès limité et sauvegarder les modèles et tokenizers affinés.
from huggingface_hub import login
import os
hf_token = os.environ.get("HF_TOKEN")
login(hf_token)Chargez le Llama-4-Scout-17B-16E-Instruct avec une quantification sur 4 bits pour une utilisation efficace de la mémoire. Assurez-vous d'avoir réglé le site device_map sur auto pour utiliser les trois GPU H200.
Note : Assurez-vous d'avoir accès au modèle, car ce modèle est protégé et vous devez remplir le formulaire en vous rendant sur le site suivant meta-llama/Llama-4-Scout-17B-16E-Instruct URL.
import os
import torch
from transformers import AutoTokenizer, Llama4ForConditionalGeneration, BitsAndBytesConfig
model_id = "meta-llama/Llama-4-Scout-17B-16E-Instruct"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=False,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
model = Llama4ForConditionalGeneration.from_pretrained(
model_id,
device_map="auto",
torch_dtype=torch.bfloat16,
quantization_config=bnb_config,
trust_remote_code=True,
)
model.config.use_cache = False
model.config.pretraining_tp = 1
Nous chargerons également le tokenizer en utilisant le même ID de modèle.
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)En exécutant la commande ci-dessous, vous pouvez vérifier la quantité de mémoire restante pour configurer l'unité didactique et affiner le modèle.
!nvidia-smi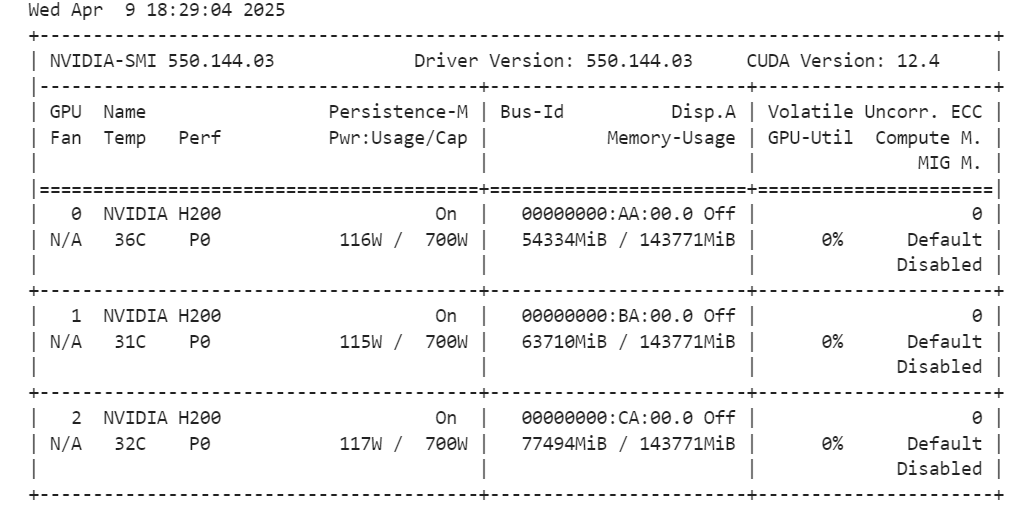
Nous allons créer un style d'invite pour le modèle, y compris une invite système avec des espaces réservés pour la question, la chaîne de penséeet la réponse. Cette invite aidera le modèle à réfléchir étape par étape et à donner des réponses claires et précises.
train_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>
{}
</think>
{}"""Ensuite, nous allons créer la fonction Python pour générer la colonne “text” en utilisant le style d'invite d'entraînement et les colonnes de l'ensemble de données.
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["Question"]
complex_cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for question, cot, response in zip(inputs, complex_cots, outputs):
# Append the EOS token to the response if it's not already there
if not response.endswith(tokenizer.eos_token):
response += tokenizer.eos_token
text = train_prompt_style.format(question, cot, response)
texts.append(text)
return {"text": texts}Nous chargerons les 500 premiers échantillons de la base de données FreedomIntelligence/medical-o1-reasoning-SFT disponible sur le Hugging Face Hub, puis nous appliquerons la fonction formatting_prompts_func pour créer la colonne “text”.
from datasets import load_dataset
dataset = load_dataset("FreedomIntelligence/medical-o1-reasoning-SFT","en", split = "train[0:500]",trust_remote_code=True)
dataset = dataset.map(formatting_prompts_func, batched = True,)
dataset["text"][0]La colonne "texte" contient une invite du système, des instructions, une question, une chaîne de pensée et la réponse.

Le nouveau formateur STF n'accepte pas les tokenizers, nous allons donc convertir le tokenizer en data collator et fournir au formateur le data collator au lieu du tokenizer.
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False
)Nous allons maintenant créer un style d'invite de test qui reprend tous les éléments du style d'invite de formation, à l'exception de la chaîne de pensée et de la réponse.
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>{}"""Nous allons prendre la première question de l'ensemble de données, la convertir en message-guide à l'aide du style de message-guide de test, puis la préparer pour que le modèle génère la réponse.
question = dataset[0]['Question']
inputs = tokenizer(
[prompt_style.format(question, "") + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])La chaîne de pensée du modèle est longue et la réponse qu'il fournit est assez brève et diffère considérablement de l'ensemble des données.
<think>assistant
To approach this question, let's break down the key elements provided and analyze them step by step:
1. **Symptoms**: The patient experiences involuntary urine loss during activities like coughing or sneezing but has no leakage at night. This pattern of urinary incontinence is suggestive of stress urinary incontinence (SUI), which is characterized by the involuntary leakage of urine on effort or exertion, or on sneezing or coughing.
2. **Diagnostic Tests Mentioned**:
- **Gynecological Exam**: This is likely performed to assess the pelvic anatomy, including the position and support of the urethra and bladder neck, and to check for any pelvic organ prolapse.
- **Q-tip Test**: This test is used to assess urethral mobility. A Q-tip (cotton swab) is inserted into the urethra, and its angle of movement is measured. Increased mobility (an angle change of more than 30 degrees) is often associated with stress urinary incontinence.
3. **Cystometry (Cystometrogram)**: This test measures the pressure within the bladder during filling and helps assess bladder function, including the residual volume and detrusor muscle contractions. The detrusor muscle is the smooth muscle in the wall of the bladder that contracts to allow urine to be expelled.
Given that the patient likely has stress urinary incontinence (SUI) based on her symptoms:
- **Residual Volume**: In patients with SUI, the bladder usually functions normally, and thus, the residual volume (the amount of urine left in the bladder after urination) is typically not significantly affected. Therefore, one would expect the residual volume to be normal or near-normal.
- **Detrusor Contractions**: In SUI, the problem primarily lies with the urethral sphincter mechanism and support rather than with the detrusor muscle itself. Hence, detrusor contractions are usually normal. The patient does not have symptoms suggestive of an overactive bladder (like urgency, urge incontinence, or nocturia), which would be more indicative of detrusor overactivity.
Based on this analysis, cystometry in this patient would most likely reveal:
- A **normal residual volume**, as her symptoms do not suggest a problem with bladder emptying.
- **Normal detrusor contractions**, as her condition (stress urinary incontinence) primarily involves issues with urethral support and continence mechanisms rather than detrusor function.
Therefore, cystometry would likely show that she has a normal residual volume and normal detrusor contractions.
</think>
The final answer is: $\boxed{Normal residual volume and normal detrusor contractions}$Nous allons maintenant mettre en œuvre LoRA (Low-Rank Adaptation) pour un réglage fin efficace des paramètres et l'appliquer au modèle. LoRA est une technique conçue pour affiner les grands modèles linguistiques en gelant la majorité des paramètres du modèle et en n'entraînant qu'un petit sous-ensemble de paramètres supplémentaires.
Cette approche est économe en mémoire, plus rapide et moins coûteuse, tout en conservant une précision élevée comparable à un réglage fin complet.
from peft import LoraConfig, get_peft_model
# LoRA config
peft_config = LoraConfig(
lora_alpha=16, # Scaling factor for LoRA
lora_dropout=0.05, # Add slight dropout for regularization
r=64, # Rank of the LoRA update matrices
bias="none", # No bias reparameterization
task_type="CAUSAL_LM", # Task type: Causal Language Modeling
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
], # Target modules for LoRA
)
model = get_peft_model(model, peft_config)Nous allons maintenant configurer et initialiser le SFTTrainer (Supervised Fine-Tuning Trainer) en lui fournissant le jeu de données, le modèle, le collecteur de données, les arguments d'entraînement et la configuration LoRA. Le SFTTrainer simplifie le processus de réglage fin en intégrant tous ces composants dans un flux de travail unique et rationalisé, ce qui facilite la formation de grands modèles linguistiques comme Llama 4 avec LoRA.
from trl import SFTTrainer
from transformers import TrainingArguments
# Training Arguments
training_arguments = TrainingArguments(
output_dir="output",
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=2,
optim="paged_adamw_32bit",
num_train_epochs=1,
logging_steps=0.2,
warmup_steps=10,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
report_to="none"
)
# Initialize the Trainer
trainer = SFTTrainer(
model=model,
args=training_arguments,
train_dataset=dataset,
peft_config=peft_config,
data_collator=data_collator,
)Commencez le processus de formation en exécutant la commande suivante :
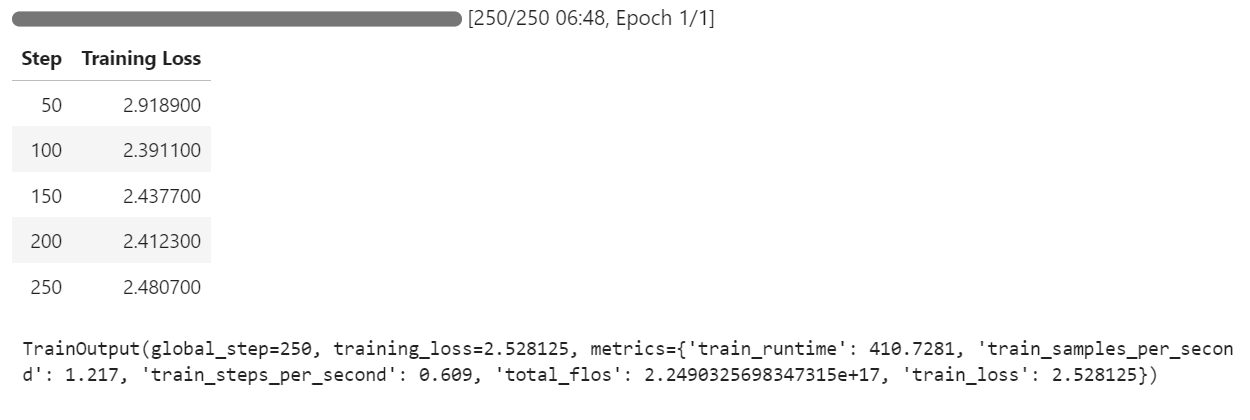
trainer.train()Si vous passez à votre tableau de bord Pod, vous verrez que le formateur utilise les trois GPU pour la formation.
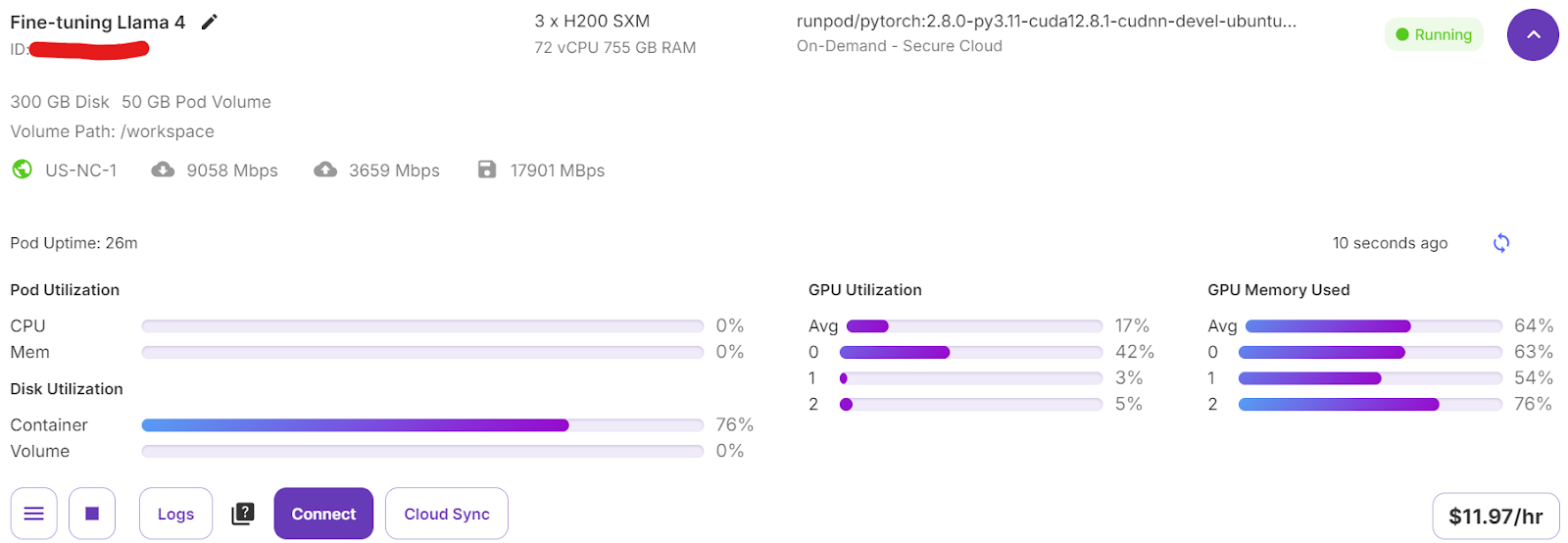
Il ne nous a fallu que 7 minutes pour affiner le modèle et 30 minutes au total pour mener à bien l'ensemble du projet.
Nous allons maintenant tester le modèle affiné en utilisant le même échantillon que précédemment afin de comparer ses performances après l'affinage. Cela nous aidera à évaluer dans quelle mesure le modèle s'est amélioré en matière de raisonnement et de génération de réponses détaillées.
question = dataset[0]['Question']
inputs = tokenizer(
[prompt_style.format(question, "") + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Le processus de raisonnement du modèle est précis et la réponse est détaillée et logique :
<think>
Alright, let's think about what's going on with this 61-year-old woman. She's experiencing involuntary urine loss when she coughs or sneezes, which is classic for stress urinary incontinence. But there's no leakage at night, which is interesting. That detail might help us rule out other types of incontinence, like overactive bladder.
Now, let's think about the tests she's had. The gynecological exam and the Q-tip test are usually done to check for any anatomical issues that could be causing her symptoms. If the Q-tip test is positive, it means there's some mobility in the urethra, which can be a sign of stress incontinence.
Okay, so we've got stress urinary incontinence in mind. What does cystometry tell us? It's a test that looks at how well the bladder functions by measuring pressure and volume during filling and voiding.
For someone with stress incontinence, the cystometry would probably show that her bladder is doing its job properly. The residual volume, which is the amount of urine left in the bladder after she pees, should be normal. This means her bladder is emptying well enough.
Also, with stress incontinence, you wouldn't expect to see abnormal detrusor contractions. These are like muscle spasms in the bladder that can cause urgency and urge incontinence. But in stress incontinence, the problem is more about the urethral support and pressure control during activities, not the bladder muscle itself.
So, putting it all together, the cystometry should show a normal residual volume and no abnormal detrusor contractions. This fits perfectly with what we know about stress urinary incontinence. Yep, that's what I'd expect to see in this case.
</think>
In this scenario, the cystometry would most likely reveal a normal residual volume and no abnormal detrusor contractions. This is because stress urinary incontinence, as indicated by the patient's symptoms and the positive Q-tip test, is primarily related to issues with urethral support and pressure control during activities, not with the bladder muscle's function or emptying ability.Testons le modèle sur un autre échantillon de l'ensemble de données afin d'évaluer plus précisément ses performances.
question = dataset[10]['Question']
inputs = tokenizer(
[prompt_style.format(question, "") + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])La réponse est logique, détaillée et démontre la capacité du modèle à appliquer efficacement le raisonnement médical :
<think>
Alright, let's break this down. So, we have a 42-year-old guy who's just recovered from pneumonia, and his T3 levels are low. Now, his TSH is slightly elevated at 4.7 µU/mL, which isn't too high but is definitely not normal. T4 is at 6 µg/dL, which is kind of in the middle range, and T3 is 68 ng/dL, which is low. Hmm, these numbers make me think of a condition called sick euthyroid syndrome. It's like when the body gets sick, the thyroid function tests can get all wonky, even if the thyroid itself is working fine.
In this syndrome, T3 usually drops first, and T4 might stay normal or even rise a bit. This makes sense here because his T3 is low, but T4 is still around 6 µg/dL. Now, the TSH is slightly elevated, which is a bit puzzling, but in sick euthyroid syndrome, TSH can be normal or even slightly elevated. So, this fits.
But wait, what about the other hormones? In sick euthyroid syndrome, we often see an increase in reverse T3 (rT3). This is because the body might convert T4 to rT3 instead of T3 when it's stressed. So, if I were to guess, I'd say the reverse T3 level is probably elevated in this case.
This all makes sense because the clinical picture and lab results are lining up nicely with sick euthyroid syndrome. So, if I had to pick an additional hormone that's likely elevated, it would be the reverse T3. Yeah, that seems to fit the scenario perfectly.
</think>
In this scenario, considering the clinical context of a 42-year-old man recovering from pneumonia with decreased T3 levels and slightly elevated TSH, along with normal T4 levels, the likely condition is sick euthyroid syndrome. In this condition, the body often converts T4 to reverse T3 (rT3) instead of T3 during stress or illness. Therefore, the additional hormone level that is likely to be elevated in this patient is reverse T3 (rT3).Nous allons maintenant pousser le modèle affiné (adaptateur LoRA) et le tokenizer vers le Hub de Hugging Face. Ce processus créera automatiquement un dépôt pour vous et téléchargera tous les fichiers de modèle nécessaires, rendant le modèle accessible au public pour une utilisation ultérieure ou un partage.
model.push_to_hub("Llama-4-Scout-17B-16E-Instruct-Medical-ChatBot")
tokenizer.push_to_hub("Llama-4-Scout-17B-16E-Instruct-Medical-ChatBot")
Une fois le processus terminé, vous pouvez accéder au référentiel de modèles en cliquant sur le lien suivant : kingabzpro/Llama-4-Scout-17B-16E-Instruct-Medical-ChatBot
Voici le cahier d'accompagnement qui contient tout le code nécessaire, les sorties et les instructions détaillées pour vous aider à mettre au point votre propre modèle de Llama 4.
La création de ce didacticiel a été une expérience difficile mais gratifiante. En travaillant avec le lama 4, j'ai rencontré plusieurs problèmes qui ont mis en évidence la complexité de l'utilisation de ce modèle. À mon avis, Llama 4 n'est pas encore totalement optimisé pour une utilisation généralisée, en particulier pour les personnes qui dépendent de GPU de qualité grand public. Voici quelques-uns des principaux défis auxquels j'ai été confronté :
Malgré ces difficultés, si vous suivez ce guide étape par étape, vous devriez être en mesure d'affiner Llama 4 sur n'importe quel nouvel ensemble de données avec une relative facilité.
Pour en savoir plus sur le lama 4, consultez les ressources suivantes :
Apprenez l'IA avec ces cours !
Cursus
Cursus
Cours