
Curso
Projetando Sistemas Agentes com LangChain
3 h
12.1K
O Mistral Large 3 é um modelo multimodal MoE feito pra ler, entender e organizar informações de documentos visuais complexos. Em vez de tratar gráficos e PDFs como imagens estáticas, ele foi feito pra extrair tabelas, insights e criar narrativas bem elaboradas a partir deles.
Neste tutorial, vamos usar o modelo Mistral Large 3 (mistral-large-2512) para criar um Hub de Avaliação de Inteligência Multimodal ( ) no Streamlit. O fluxo é assim:
Tudo isso é feito com um único modelo (mistral-large-2512), um único endpoint (/v1/chat/completions) e um esquema JSON rigoroso para manter as saídas estruturadas e confiáveis.
Recomendo a leitura do nosso artigo sobre o Mistral 3, que apresenta as principais características dos novos modelos.
O Mistral Large 3 é uma arquitetura MOE (mixtura de especialistas) com 41 bilhões de parâmetros ativos de um total de 675 bilhões e um codificador de visão com 2,5 bilhões de parâmetros para compreensão de imagens.
Aqui estão algumas propriedades importantes relacionadas a esse modelo:
O cartão modelo e os documentos do ecossistema também falam de algumas coisas importantes:
Nesta seção, vamos criar um Centro de Avaliação de Inteligência Multimodal usando o Mistral Large 3 integrado a um aplicativo Streamlit. Em resumo, eis o que o aplicativo final faz:
mistral-large-2512, que usa response_format no modo JSON Schema para trazer de volta uma carga JSON estruturada.Isso transforma um relatório visual estático em um assistente de inteligência interativo totalmente alimentado pelo Mistral Large 3.

Vamos construir passo a passo.
Antes de criarmos nossa demonstração do Streamlit com base no Mistral Large 3, precisamos de um ambiente local básico para nos comunicarmos com o modelo por meio da API do Mistral. Comece instalando algumas bibliotecas auxiliares para lidar com a interface do usuário, documentos e configuração.
pip install streamlit mistralai pillow pdf2image pandas python-dotenvVamos usar as bibliotecas principais acima, como streamlit para a interface interativa do aplicativo web, mistralai para falar com a API Mistral, pillow e pdf2image para abrir e converter PDFs em imagens, pandas para lidar com quaisquer dados tabulares ou registros, e python-dotenv para carregar com segurança variáveis de ambiente, como MISTRAL_API_KEY, a partir de um arquivo .env.
Depois, entra na Plataforma Mistral AI e vá para a Chaves API ..
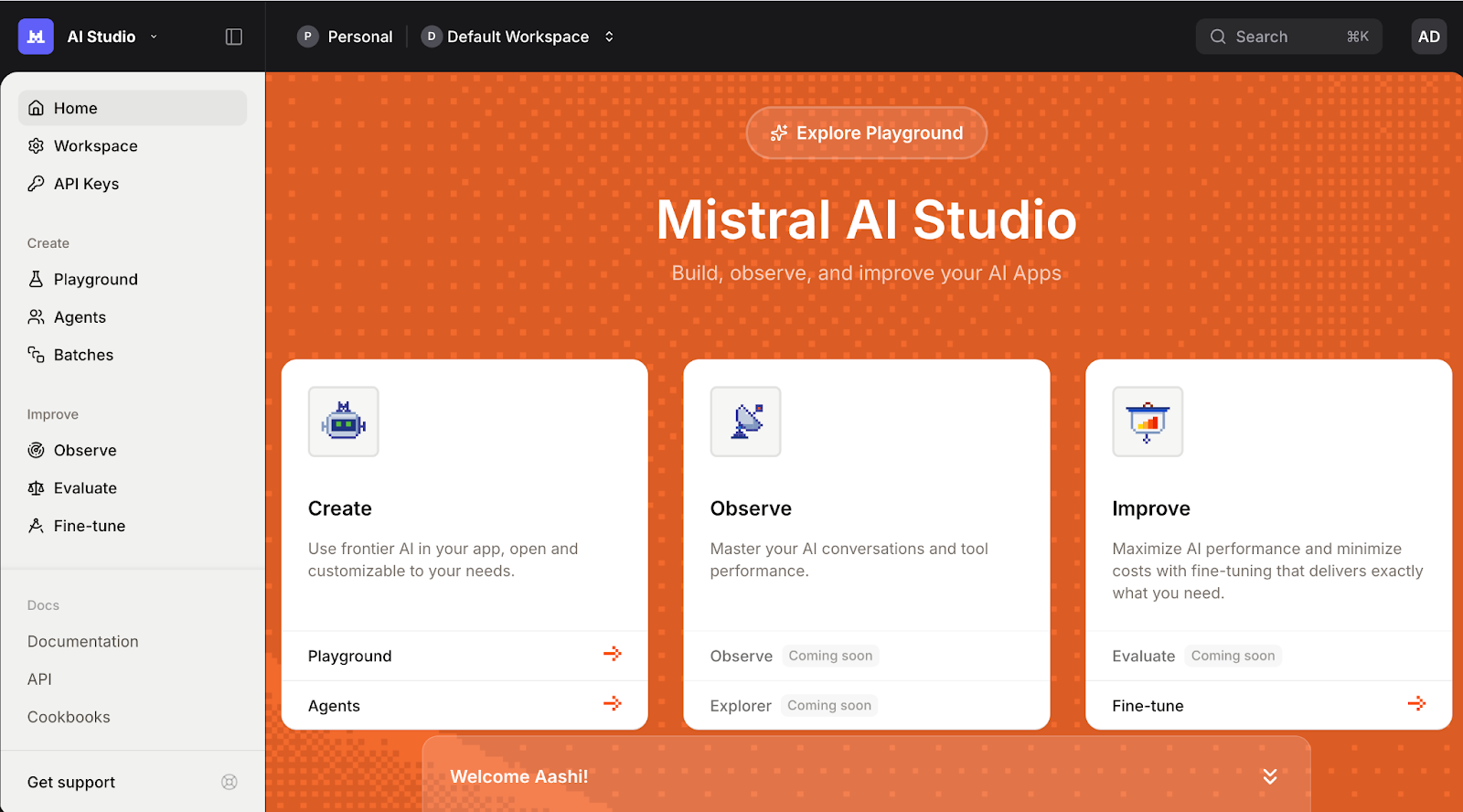
Defina seu espaço de trabalho padrão (se solicitado) e clique em Criar nova chave.
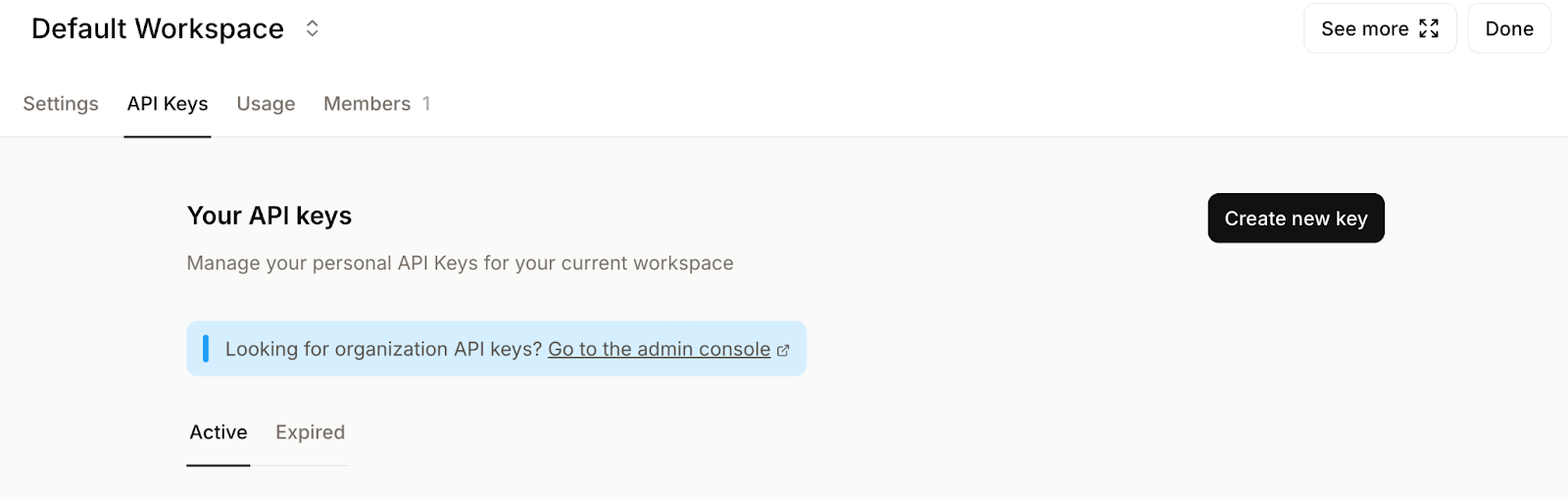
Dê um nome significativo à sua chave e, se quiser, defina uma data de validade.
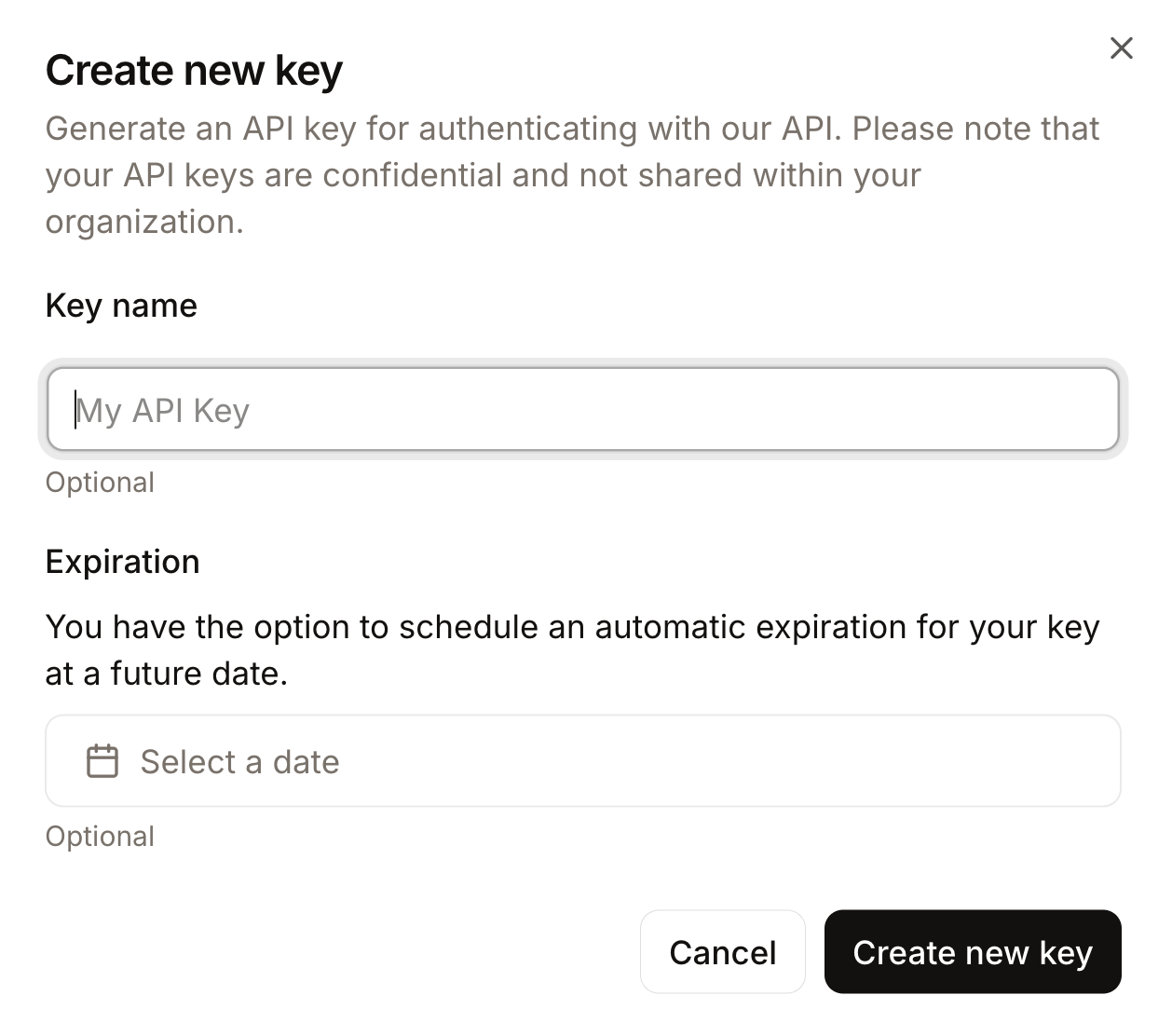
Por fim, copie a chave gerada e exporte-a como um variável de ambiente da seguinte maneira:
export MISTRAL_API_KEY="your_mistral_api_key_here"Agora, nosso ambiente está pronto para fazer a autenticação com a API Mistral.
Com o ambiente configurado e as dependências instaladas, o próximo passo é inicializar o cliente Mistral que vai cuidar de todas as nossas chamadas para o modelo Mistral Large 3. Isso nos dá um ponto de entrada para enviar prompts do nosso aplicativo Streamlit para o Mistral Large 3.
MISTRAL_API_KEY = os.getenv("MISTRAL_API_KEY")
MODEL_ID = "mistral-large-2512"
if MISTRAL_API_KEY is None:
raise RuntimeError("Please set the MISTRAL_API_KEY environment variable.")
client = MistralClient(api_key=MISTRAL_API_KEY)O bloco de código acima faz três coisas:
MISTRAL_API_KEY do nosso ambiente e guarda o nome do modelo em MODEL_ID, o que nos permite reutilizá-lo em todo o aplicativo.MistralClient usando o SDK oficial mistralai, que vamos usar para todas as solicitações seguintes ao modelo.Com o cliente inicializado, vamos criar algumas funções auxiliares que enviam prompts e lidam com respostas dentro da interface do usuário do Streamlit.
Antes de mandarmos qualquer imagem ou PDF para o Mistral Large 3, precisamos deixá-los “prontos para o modelo”. A API Vision funciona melhor quando as entradas são quadradas, têm um tamanho razoável e são codificadas num formato consistente.
Começamos carregando a imagem enviada e convertendo-a em um recorte quadrado.
def load_image_from_upload(uploaded_file) -> Image.Image:
return Image.open(io.BytesIO(uploaded_file.read())).convert("RGB")
def center_crop_to_square(img: Image.Image) -> Image.Image:
width, height = img.size
if width == height:
return img
if width > height:
offset = (width - height) // 2
box = (offset, 0, offset + height, height)
else:
offset = (height - width) // 2
box = (0, offset, width, offset + width)
return img.crop(box)O bloco de código acima garante que os gráficos ou tabelas que enviamos sejam convertidos em um recorte quadrado antes de irem para o modelo, alinhando-se com a orientação de visão do Mistral.
Depois, a gente redimensiona a imagem para um tamanho máximo (1024×1024) pra equilibrar qualidade, latência e custo do token.
def resize_for_vlm(img: Image.Image, max_size: int = 1024) -> Image.Image:
width, height = img.size
scale = min(max_size / width, max_size / height, 1.0)
if scale == 1.0:
return img
new_w = int(width * scale)
new_h = int(height * scale)
return img.resize((new_w, new_h), Image.LANCZOS)Aqui, calculamos um fator de scale que mantém ambas as dimensões abaixo de max_size , preservando a proporção da imagem. Se a imagem já estiver pequena o suficiente, a gente devolve ela como está. Caso contrário, calculamos as novas dimensões e usamos LANCZOS para uma redução de tamanho de alta qualidade.
Essa etapa garante que as imagens não explodam sua janela de contexto nem deixem as respostas lentas sem necessidade.
Para PDFs, muitas vezes queremos mostrar o modelo em mais de uma página. Um truque simples é renderizar todas as páginas e empilhá-las verticalmente em uma imagem alta.
def stack_images_vertically(images: List[Image.Image]) -> Image.Image:
if not images:
raise ValueError("No images to stack")
target_width = images[0].size[0]
resized_images = []
for img in images:
if img.size[0] != target_width:
aspect_ratio = img.size[1] / img.size[0]
new_height = int(target_width * aspect_ratio)
img = img.resize((target_width, new_height), Image.LANCZOS)
resized_images.append(img)
total_height = sum(img.size[1] for img in resized_images)
stacked = Image.new('RGB', (target_width, total_height))
y_offset = 0
for img in resized_images:
stacked.paste(img, (0, y_offset))
y_offset += img.size[1]
return stacked
def uploaded_file_to_square_base64(uploaded_file) -> Tuple[str, str]:
mime_type = uploaded_file.type
raw_bytes = uploaded_file.getvalue()
if mime_type == "application/pdf":
pages = convert_from_bytes(raw_bytes)
pages_rgb = [page.convert("RGB") for page in pages]
img = stack_images_vertically(pages_rgb)
img = resize_for_vlm(img, max_size=1024)
mime_type = "image/png"
else:
img = Image.open(io.BytesIO(raw_bytes)).convert("RGB")
img = center_crop_to_square(img)
img = resize_for_vlm(img, max_size=1024)
return mime_type, image_to_base64_data_url(img, mime_type=mime_type)A função stack_images_vertically() pega uma lista de imagens PIL, normaliza-as para uma largura comum, mantendo a proporção, calcula a altura total e cola-as uma abaixo da outra em uma única tela RGB. Enquanto afunção uploaded_file_to_square_base64() decide o que fazer com base no tipo MIME:
Em ambos os casos, ele retorna uma imagem normalizada junto com um tipo MIME para a etapa final de codificação.
A API Vision da Mistral aceita imagens como objetos image_url, que podem ser URLs reais ou URLs data:.
def image_to_base64_data_url(img: Image.Image, mime_type: str = "image/png") -> str:
buffer = io.BytesIO()
if mime_type == "image/jpeg":
img.save(buffer, format="JPEG", quality=90)
else:
img.save(buffer, format="PNG")
mime_type = "image/png"
b64 = base64.b64encode(buffer.getvalue()).decode("utf-8")
return f"data:{mime_type};base64,{b64}"Começamos gravando a imagem em um buffer na memória e escolhendo um formato apropriado (como JPEG ou PNG), antes de finalmente codificar os bytes em base64.
Por fim, colocamos a string codificada em uma URL data:{mime_type};base64 que pode ser passada direto para a API do Mistral Vision como image_url.
No final dessa etapa, todos os arquivos enviados, seja um único PNG, um painel amplo ou um PDF com várias páginas, passam pelo mesmo processo de recorte central, redimensionamento, empilhamento de PDF e conversão de URL de dados base64.
Nesta etapa, juntamos tudo em uma única função auxiliar que manda uma solicitação de visão mais texto e faz com que o modelo responda no formato JSON. Fazemos isso juntando:
response_format para que a saída seja estruturada e fácil de analisar.def call_mistral_large_multimodal(
mime_type: str,
image_data_url: str,
user_instruction: str,
languages: List[str],
) -> Dict[str, Any]:
json_schema = {
"type": "object",
"properties": {
"csv_tables": {
"type": "array",
"items": {"type": "string"},
"description": "Each item is a CSV string representing one table found in the image."
},
"insights": {
"type": "array",
"items": {"type": "string"},
"description": "Up to 5 key insights about the content."
},
"risks": {
"type": "array",
"items": {"type": "string"},
"description": "Up to 5 key risks or red flags."
},
"anomalies": {
"type": "array",
"items": {"type": "string"},
"description": "Any anomalies, outliers, or surprising patterns you detect."
},
"translations": {
"type": "object",
"properties": {
lang: {"type": "string"} for lang in languages
},
"description": "Short high-level summaries in the selected languages."
},
},
"required": ["csv_tables", "insights", "risks"],
"additionalProperties": False,
}
system_prompt = (
"You are a Multimodal Intelligence Evaluator using Mistral Large 3.\n"
"You are given a single document-like image (e.g. chart + table, financial report page).\n\n"
"Your tasks:\n"
"1. Read all visible text and numbers directly from the image.\n"
"2. Reconstruct any clearly visible tables into valid CSV strings.\n"
" - Use the first row as headers when possible.\n"
" - Use commas as separators and newline per row.\n"
"3. Derive up to 5 concise INSIGHTS about trends, patterns, or takeaways.\n"
"4. Derive up to 5 concise RISKS or red flags (business, financial, operational, etc.).\n"
"5. Detect any anomalies or surprising patterns if present (else return an empty list).\n"
"6. Provide short summaries in the requested languages.\n\n"
"You MUST respond ONLY with a JSON object that matches the provided JSON schema.\n"
"Do not include any extra commentary outside of the JSON."
)
messages = [
{
"role": "system",
"content": [
{"type": "text", "text": system_prompt},
],
},
{
"role": "user",
"content": [
{
"type": "text",
"text": user_instruction or "Analyze this financial report page.",
},
{
"type": "image_url",
"image_url": image_data_url,
},
],
},
]
response = client.chat(
model=MODEL_ID,
messages=messages,
temperature=0.2,
max_tokens=2048,
response_format={
"type": "json_schema",
"json_schema": {
"name": "multimodal_intel_eval",
"schema": json_schema,
"strict": True,
},
},
)
content = response.choices[0].message.content
try:
parsed = json.loads(content)
except json.JSONDecodeError:
try:
start = content.index("{")
end = content.rindex("}") + 1
parsed = json.loads(content[start:end])
except Exception:
raise ValueError(f"Model did not return valid JSON. Raw content:\n{content}")
return parsedA função call_mistral_large_multimodal() é o motor central da demonstração de inteligência multimodal.
csv_tables, insights, risks, anomalies e um objeto translations com chaves derivadas da lista languages. call_mistral_large_multimodal() ` cria a matriz de mensagens no formato de chat, juntando as instruções do sistema com uma mensagem do usuário que inclui tanto instruções de texto quanto a carga útil ` image_url `. Ele chama client.chat() com MODEL_ID enquanto mantém a temperatura baixa para uma saída determinística, e response_format={"type": "json_schema",}, para que a resposta esteja de acordo com o esquema. Por fim, tentamos analisá-lo com json.loads.Com isso pronto, você agora tem um ponto de partida legal para transformar um gráfico ou imagem de relatório bruto em uma narrativa estruturada.
Com o pipeline de pré-processamento e o cliente Mistral instalados, o passo final é integrar tudo em uma interface Streamlit.
st.set_page_config(
page_title="Multimodal Intelligence Evaluation Hub - Mistral Large 3",
layout="wide",
)
st.title("Multimodal Intelligence Evaluation Hub")
st.caption("Powered by **Mistral Large 3**")
col_left, col_right = st.columns([2, 1])
with col_left:
uploaded_file = st.file_uploader(
"Upload an image or report (PNG, JPG, WEBP, or PDF)",
type=["png", "jpg", "jpeg", "webp", "pdf"],
)
default_prompt = (
"Give me 3–5 key insights and risks from this input and export any tables you see as CSV "
"Also write down the findings for a professional audience."
)
user_instruction = st.text_area(
"Instruction to Mistral Large 3",
value=default_prompt,
height=120,
)
with col_right:
st.subheader("Multilingual Options")
languages = st.multiselect(
"Additional summary languages",
options=["fr", "de", "es", "hi", "zh", "ja"],
default=["hi"],
help="Mistral Large 3 supports dozens of languages; these will receive short summaries.",
label_visibility="collapsed",
)
run_button = st.button("Run Analysis", type="primary")
if run_button:
if uploaded_file is None:
st.error("Please upload an image or PDF first.")
st.stop()
prep_msg = "Preparing PDF (combining all pages)..." if uploaded_file.type == "application/pdf" else "Preparing image..."
with st.spinner(prep_msg):
mime_type, data_url = uploaded_file_to_square_base64(uploaded_file)
mime, b64_part = data_url.split(",", 1)
img_bytes = base64.b64decode(b64_part)
st.image(img_bytes, caption="Center-cropped & resized image for the model", width=400)
with st.spinner("Processing..."):
try:
result = call_mistral_large_multimodal(
mime_type=mime_type,
image_data_url=data_url,
user_instruction=user_instruction,
languages=languages,
)
except Exception as e:
st.error(f"Error calling Mistral Large 3: {e}")
st.stop()
st.header("Results")
csv_tables = result.get("csv_tables", [])
if csv_tables:
st.subheader("Reconstructed Tables (CSV)")
for i, csv_str in enumerate(csv_tables):
st.markdown(f"**Table {i+1}**")
try:
df = pd.read_csv(io.StringIO(csv_str))
st.dataframe(df, use_container_width=True)
except Exception:
st.text_area(f"Raw CSV for Table {i+1}", value=csv_str, height=150)
st.download_button(
label=f"Download Table {i+1} as CSV",
data=csv_str,
file_name=f"table_{i+1}.csv",
mime="text/csv",
key=f"csv_download_{i}",
)
else:
st.info("No tables were detected or reconstructed.")
insights = result.get("insights", [])
risks = result.get("risks", [])
anomalies = result.get("anomalies", [])
col_ins, col_risk = st.columns(2)
with col_ins:
st.subheader("Key Insights")
if insights:
for bullet in insights:
st.markdown(f"- {bullet}")
else:
st.write("_No explicit insights returned._")
with col_risk:
st.subheader("Risks")
if risks:
for bullet in risks:
st.markdown(f"- {bullet}")
else:
st.write("_No explicit risks returned._")
st.subheader("Anomalies")
if anomalies:
for bullet in anomalies:
st.markdown(f"- {bullet}")
else:
st.write("_No anomalies reported._")
translations = result.get("translations", {}) or {}
if translations:
st.subheader(" Multilingual Summaries")
for lang_code, summary in translations.items():
with st.expander(f"Summary in {lang_code}"):
st.write(summary)
else:
st.info("No multilingual summaries were requested or returned.")
# Raw JSON (debug)
# with st.expander(" Raw JSON (debug)"):
# st.json(result)O código StreamLit UI acima faz algumas coisas importantes:
O método ` st.set_page_config ` divide o layout em duas colunas. O lado esquerdo cuida das entradas principais (carregador de arquivos e uma área de texto editável com instruções padrão). Já o lado direito tem opções em vários idiomas pelo site st.multiselect e um botão principal Run Analysis. Quando você clica no botão, o aplicativo verifica se tem um arquivo e transforma imagens ou PDFs em uma URL de dados base64, mostrando uma prévia da imagem.
Quando o resultado aparece, as tabelas CSV reconstruídas são transformadas em dataframes, junto com insights, riscos, anomalias e quaisquer resumos multilíngues. Opcionalmente, também podemos depurar visualizações (comentadas), o que nos permite inspecionar o JSON bruto durante o desenvolvimento.
Depois de fazer isso, você pode salvar tudo como app.py e curtir a experiência completa com:
streamlit run app.pyNo vídeo abaixo, você pode ver uma versão resumida do fluxo de trabalho em ação com entradas de imagem e PDF:
Cursos mais populares do DataCamp
Curso
Curso
Curso
blog
Ryan Ong
8 min
blog
Stanislav Karzhev
9 min
Tutorial
Zoumana Keita
Tutorial
Nadia mhadhbi
Tutorial
Josep Ferrer
Tutorial
Abid Ali Awan

