
Cours
Machine learning avec des modèles arborescents en Python
5 h
116.4K
Avant de construire le SOM, nous devons préparer l'environnement avec les paquets nécessaires.
Nous avons besoin de ces paquets :
matplotlib est utilisé pour tracer divers graphiques et diagrammes afin de visualiser les données. datasets de sklearn est utilisé pour importer des ensembles de données sur lesquels appliquer le SOM. MinMaxScaler de sklearn normalise l'ensemble des données . L'extrait de code suivant importe ces paquets :
from minisom import MiniSom
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.preprocessing import MinMaxScalerDans ce tutoriel, nous utilisons MiniSom pour construire un SOM et l'entraîner sur l' ensemble de données canoniques IRIS. Ce jeu de donnéesest composé de 3 classes de plantes d'iris. Chaque classe compte 50 instances. Pour préparer les données, nous suivons les étapes suivantes :
sklearn, Le code suivant met en œuvre ces étapes :
dataset_iris = datasets.load_iris()
data_iris = dataset_iris.data
target_iris = dataset_iris.target
data_iris_normalized = MinMaxScaler().fit_transform(data_iris)
labels_iris = {1:'1', 2:'2', 3:'3'}
data = data_iris_normalized
target = target_irisPour mettre en œuvre un SOM en Python, nous définissons et initialisons la grille avant de l'entraîner sur le jeu de données. Nous pouvons ensuite visualiser les neurones entraînés et l'ensemble des données regroupées.
Comme nous l'avons expliqué précédemment, une SOM est une grille de neurones. MiniSom permet de créer des grilles bidimensionnelles. Les dimensions X et Y de la grille correspondent au nombre de neurones sur chaque axe. Pour définir la grille SOM, nous devons également spécifier :
Déclarez ces paramètres comme des constantes Python :
SOM_X_AXIS_NODES = 8
SOM_Y_AXIS_NODES = 8
SOM_N_VARIABLES = data.shape[1]L'exemple de code ci-dessous illustre comment déclarer la grille à l'aide de MiniSom :
som = MiniSom(SOM_X_AXIS_NODES, SOM_Y_AXIS_NODES, SOM_N_VARIABLES)Les deux premiers paramètres sont le nombre de neurones le long des axes X et Y, et le troisième paramètre est le nombre de variables.
Nous déclarons d'autres paramètres et hyperparamètres lors de la création de la grille SOM. Nous les expliquerons plus loin dans ce tutoriel. Pour l'instant, déclarez ces paramètres comme indiqué ci-dessous :
ALPHA = 0.5
DECAY_FUNC = 'linear_decay_to_zero'
SIGMA0 = 1.5
SIGMA_DECAY_FUNC = 'linear_decay_to_one'
NEIGHBORHOOD_FUNC = 'triangle'
DISTANCE_FUNC = 'euclidean'
TOPOLOGY = 'rectangular'
RANDOM_SEED = 123Créez un SOM à l'aide de ces paramètres :
som = MiniSom(
SOM_X_AXIS_NODES,
SOM_Y_AXIS_NODES,
SOM_N_VARIABLES,
sigma=SIGMA0,
learning_rate=ALPHA,
neighborhood_function=NEIGHBORHOOD_FUNC,
activation_distance=DISTANCE_FUNC,
topology=TOPOLOGY,
sigma_decay_function = SIGMA_DECAY_FUNC,
decay_function = DECAY_FUNC,
random_seed=RANDOM_SEED,
)La commande ci-dessus crée un SOM avec des poids aléatoires pour tous les neurones. L'initialisation des neurones avec des poids tirés des données (au lieu de nombres aléatoires) peut rendre le processus d'apprentissage plus efficace.
Lorsque vous utilisez MiniSom pour créer une carte auto-organisatrice (SOM), il y a deux façons d'initialiser les poids des neurones en fonction des données :
.random_weights_init() au SOM. Dans ce guide, nous utilisons l'initialisation de l'ACP. Pour appliquer l'initialisation PCA aux poids SOM, utilisez la fonction .pca_weights_init() comme indiqué ci-dessous :
som.pca_weights_init(data)Le processus d'apprentissage met à jour les poids du SOM afin de minimiser la distance entre les neurones et les points de données.
Nous expliquons ci-dessous le processus de formation itératif :
Pour entraîner le SOM, nous présentons le modèle avec les données d'entrée. Pour ce faire, nous avons le choix entre deux approches :
.train_random() met en œuvre cette technique. .train_batch(). Ces fonctions acceptent les données d'entrée et le nombre d'itérations comme paramètres. Dans ce guide, nous utilisons la fonction .train_random() . Déclarez le nombre d'itérations comme une constante et transmettez-le à la fonction d'apprentissage :
N_ITERATIONS = 5000
som.train_random(data, N_ITERATIONS, verbose=True) Après avoir exécuté le script et terminé la formation, un message indiquant l'erreur de quantification s'affiche :
quantization error: 0.05357240680504421 L'erreur de quantification indique la quantité d'informations perdues lorsque le SOM quantifie (réduit la dimensionnalité) les données. Une erreur de quantification importante indique une plus grande distance entre les neurones et les points de données. Cela signifie également que le regroupement est moins fiable.
Nous disposons maintenant d'un modèle SOM formé. Pour la visualiser, nous utilisons une carte de distance (également connue sous le nom de U-matrix). La carte de distance affiche les neurones du SOM sous la forme d'une grille de cellules. La couleur de chaque cellule représente sa distance par rapport aux neurones voisins.
La carte des distances est une grille ayant les mêmes dimensions que le SOM. Chaque cellule de la carte des distances est la somme normalisée des distances (euclidiennes) entre un neurone et ses voisins.
Accédez au site SOM distance map en utilisant la fonction .distance_map(). Pour générer la matrice U, nous suivons les étapes suivantes :
pyplot pour créer une figure ayant les mêmes dimensions que le SOM. Dans cet exemple, les dimensions sont 8x8. .pcolor(). Dans cet exemple, nous utilisons gist_yarg comme palette de couleurs. colorbar, un index qui associe différentes couleurs à différentes valeurs scalaires. Dans ce cas, les distances étant normalisées, les valeurs de la distance scalaire sont comprises entre 0 et 1. Le code ci-dessous met en œuvre ces étapes :
# create the grid
plt.figure(figsize=(8, 8))
#plot the distance map
plt.pcolor(som.distance_map().T, cmap='gist_yarg')
# show the color bar
plt.colorbar()
plt.show()Dans cet exemple, la matrice U utilise un schéma de couleurs monotone. Il peut être compris à l'aide des lignes directrices suivantes :
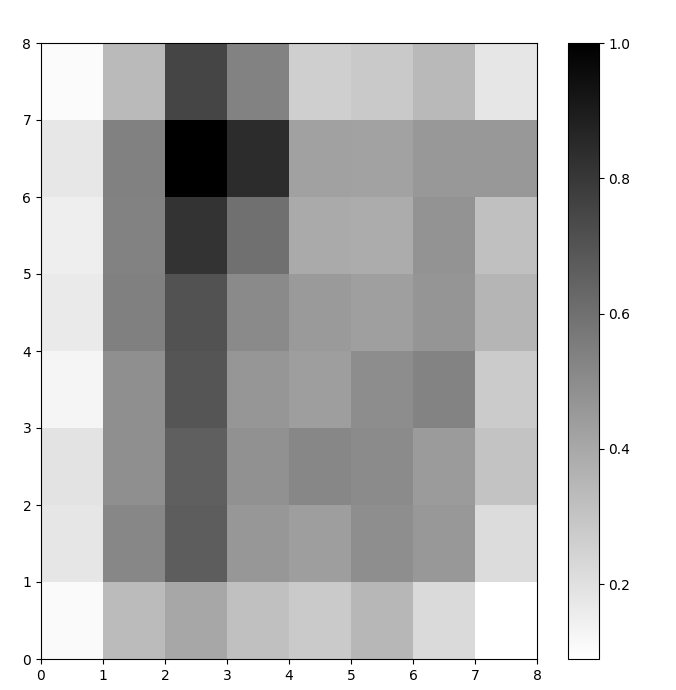
Figure 1 : Matrice U d'une SOM entraînée sur l'ensemble de données Iris (image de l'auteur)
La figure précédente illustre graphiquement les neurones du SOM. Dans cette section, nous montrons comment visualiser la façon dont le SOM a regroupé les données.
Nous superposons des marqueurs à la matrice U ci-dessus pour indiquer la classe d'Iris que chaque cellule (neurone) représente. Pour ce faire :
pyplot, tracez la carte des distances et affichez la barre de couleurs. .winner(). w[0] et w[1] indiquent les coordonnées X et Y du neurone, respectivement. Une valeur de 0,5 est ajoutée à chaque coordonnée pour la placer au milieu de la cellule. Le code ci-dessous montre comment procéder :
# plot the distance map
plt.figure(figsize=(8, 8))
plt.pcolor(som.distance_map().T, cmap='gist_yarg')
plt.colorbar()
# create the markers and colors for each class
markers = ['o', 'x', '^']
colors = ['C0', 'C1', 'C2']
# plot the winning neuron for each data point
for count, datapoint in enumerate(data):
# get the winner
w = som.winner(datapoint)
# place a marker on the winning position for the sample data point
plt.plot(w[0]+.5, w[1]+.5, markers[target[count]-1], markerfacecolor='None',
markeredgecolor=colors[target[count]-1], markersize=12, markeredgewidth=2)
plt.show()L'image obtenue est présentée ci-dessous :
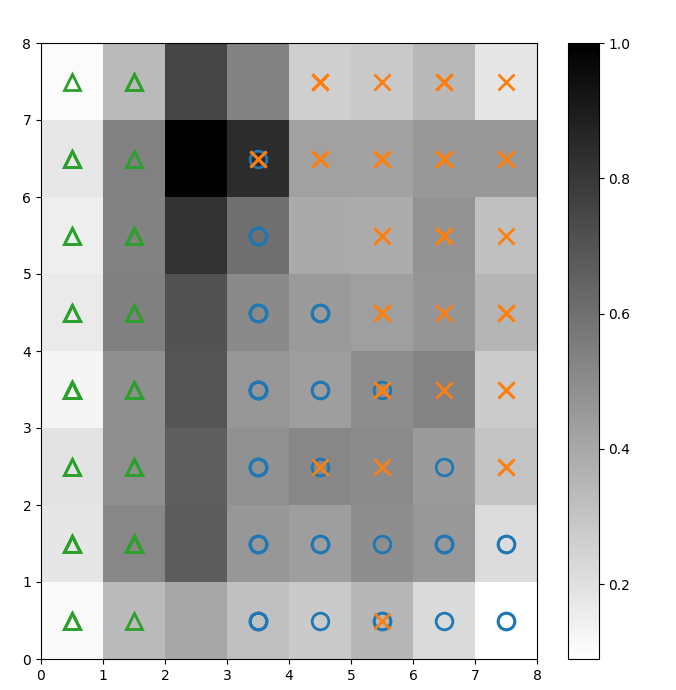
Figure 2 : Matrice U superposée aux marqueurs de classe (image de l'auteur)
D'après la documentation du jeu de données Iris, "une classe est linéairement séparable des deux autres ; ces dernières ne sont pas linéairement séparables les unes des autres". Dans la matrice U ci-dessus, ces trois classes sont représentées par trois marqueurs : le triangle, le cercle et la croix.
Remarquez qu'il n'y a pas de limite claire entre les cercles bleus et les croix orange. En outre, dans de nombreuses cellules, deux classes sont superposées sur le même neurone. Cela signifie que le neurone est équidistant des deux classes.
Un SOM est un modèle de regroupement. Les points de données similaires correspondent au même neurone. Les points de données de la même classe sont dirigés vers un groupe de neurones voisins. Nous traçons tous les points de données sur la grille SOM afin de mieux étudier le comportement de regroupement.
Les étapes suivantes décrivent comment créer ce diagramme de dispersion :
plt.scatter() pour créer un diagramme de dispersion de tous les neurones gagnants pour chaque point de données. Ajoutez un décalage aléatoire à chaque point pour éviter les chevauchements entre les points de données d'une même cellule.Nous mettons en œuvre ces étapes dans le code ci-dessous :
# get the X and Y coordinates of the winning neuron for each data pointw_x, w_y = zip(*[som.winner(d) for d in data])
w_x = np.array(w_x)
w_y = np.array(w_y)
# plot the distance map
plt.figure(figsize=(8, 8))
plt.pcolor(som.distance_map().T, cmap='gist_yarg', alpha=.2)
plt.colorbar()
# make a scatter plot of all the winning neurons for each data point
# add a random offset to each point to avoid overlaps
for c in np.unique(target):
idx_target = target==c
plt.scatter(w_x[idx_target]+.5+(np.random.rand(np.sum(idx_target))-.5)*.8,
w_y[idx_target]+.5+(np.random.rand(np.sum(idx_target))-.5)*.8,
s=50,
c=colors[c-1],
label=labels_iris[c+1]
)
plt.legend(loc='upper right')
plt.grid()
plt.show()Le graphique suivant montre le diagramme de dispersion de la sortie :
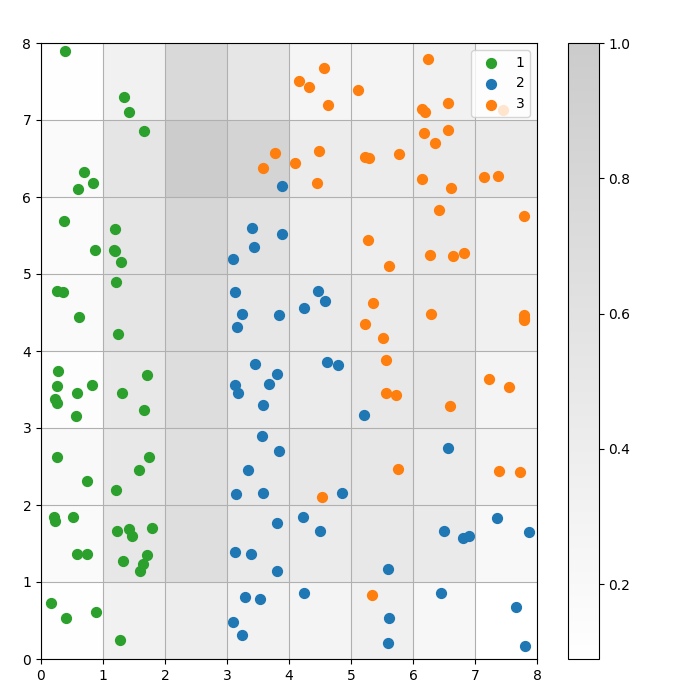 Figure 3 : Diagramme de dispersion des points de données dans les cellules (image de l'auteur)
Figure 3 : Diagramme de dispersion des points de données dans les cellules (image de l'auteur)
Dans le nuage de points ci-dessus, observez que :
Vous pouvez accéder au code complet et l'exécuter sur ce cahier DataLab.
Les sections précédentes ont montré comment créer et entraîner un modèle SOM et comment étudier les résultats visuellement. Dans cette section, nous expliquons comment ajuster les performances des modèles SOM.
Comme pour tout modèle d'apprentissage automatique, les hyperparamètres ont un impact considérable sur les performances du modèle.
Voici quelques-uns des hyperparamètres importants pour l'apprentissage des SOM :
Dans la section suivante, nous discutons des lignes directrices pour la définition des valeurs de ces hyperparamètres.
Les valeurs des hyperparamètres doivent être déterminées en fonction du modèle et de l'ensemble des données. Dans une certaine mesure, la détermination de ces valeurs est un processus d'essais et d'erreurs. Dans cette section, nous donnons des indications pour le réglage de chaque hyperparamètre. À côté de chaque hyperparamètre, nous mentionnons (entre parenthèses) les constantes Python respectives utilisées dans le code d'exemple.
SOM_X_AXIS_NODES et SOM_X_AXIS_NODES) : La taille de la grille dépend de la taille de l'ensemble de données. En règle générale, pour un ensemble de données de taille N, la grille doit contenir environ 5*sqrt(N) neurones. Par exemple, si l'ensemble de données comporte 150 échantillons, la grille doit contenir 5*sqrt(150) = environ 61 neurones. Dans ce tutoriel, l'ensemble de données Iris comporte 150 lignes et nous utilisons une grille de 8x8. ALPHA) : Un taux plus élevé accélère la convergence, tandis que des taux plus faibles sont utilisés pour des ajustements plus fins après les premières itérations. Le taux d'apprentissage initial doit être suffisamment élevé pour permettre une adaptation rapide, mais pas trop pour ne pas dépasser les valeurs de poids optimales. Dans cet article, le taux d'apprentissage initial est de 0,5. SIGMA0) : Il détermine la taille initiale ou l'étendue du quartier. Une valeur plus élevée prend en compte des modèles plus globaux. Dans cet exemple, nous utilisons un écart-type de départ de 1,5. DECAY_FUNC ) et le taux de décroissance sigma (SIGMA_DECAY_FUNC ), nous pouvons choisir parmi trois types de fonctions de décroissance : NEIGHBORHOOD_FUNC) : Le choix par défaut de la fonction de voisinage est la fonction gaussienne. D'autres fonctions, expliquées ci-dessous, sont également utilisées. DISTANCE_FUNC) : Pour mesurer la distance entre les neurones et les points de données, nous avons le choix entre 4 méthodes :TOPOLOGY) : Dans une grille, les neurones peuvent être disposés selon une structure hexagonale ou rectangulaire : N_ITERATIONS) : En principe, des temps d'apprentissage plus longs permettent de réduire les erreurs et de mieux aligner les poids sur les données d'entrée. Cependant, la performance du modèle augmente asymptotiquement avec le nombre d'itérations. Ainsi, après un certain nombre d'itérations, l'augmentation des performances due aux interactions ultérieures n'est que marginale. Le choix du nombre correct d'itérations demande un peu d'expérimentation. Dans ce tutoriel, nous entraînons le modèle sur 5000 itérations. Pour déterminer la bonne configuration des hyperparamètres, nous vous recommandons d'expérimenter différentes options sur un sous-ensemble plus petit des données.
Les cartes auto-organisatrices sont un outil robuste pour l'apprentissage non supervisé. Ils sont utilisés pour le regroupement, la réduction de la dimensionnalité, la détection des anomalies et la visualisation des données. Comme elles préservent les propriétés topologiques des données de haute dimension et les représentent sur une grille de dimension inférieure, les SOM facilitent la visualisation et l'interprétation d'ensembles de données complexes.
Ce tutoriel a abordé les principes sous-jacents des SOM et a montré comment mettre en œuvre un SOM à l'aide de la bibliothèque MiniSom Python. Il a également montré comment analyser visuellement les résultats et expliqué les hyperparamètres importants utilisés pour former les SOMs et affiner leurs performances.
Apprenez-en plus sur l'apprentissage automatique et Python avec ces cours !
Cours
Cours
Cours
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach
blog
Nisha Arya Ahmed
15 min
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach