
L'apprentissage non supervisé, un type fondamental d'apprentissage automatique, continue d'évoluer. Cette approche, qui se concentre sur les vecteurs d'entrée sans valeurs cibles correspondantes, a connu des développements remarquables dans sa capacité à regrouper et à interpréter les informations sur la base de similitudes, de modèles et de différences. Les dernières avancées en matière de modèles d'apprentissage profond non supervisé ont renforcé cette capacité, permettant une compréhension plus nuancée d'ensembles de données complexes.
En 2024, les algorithmes d'apprentissage non supervisé, qui traditionnellement ne s'appuient pas sur des correspondances entrée-sortie, sont devenus encore plus autonomes et efficaces pour découvrir les structures sous-jacentes des données non étiquetées. Cette indépendance vis-à-vis d'un "enseignant" a été renforcée par l'avènement de techniques sophistiquées d'apprentissage auto-supervisé, qui réduisent considérablement la dépendance à l'égard des données étiquetées.
En outre, le domaine a fait des progrès dans l'intégration de l'apprentissage non supervisé avec d'autres disciplines de l'IA, telles que l'apprentissage par renforcement, ce qui a permis de créer des systèmes plus adaptatifs et plus intelligents. Ces systèmes excellent dans l'identification de modèles et d'anomalies dans les données, ouvrant la voie à des applications innovantes dans divers secteurs. Cet article examine plus en détail l'apprentissage non supervisé, en explorant les différents types d'apprentissage et leur utilité.
Apprentissage supervisé ou non supervisé
Dans le tableau ci-dessous, nous avons comparé certaines des principales différences entre l'apprentissage non supervisé et l'apprentissage supervisé :
|
Apprentissage supervisé |
Apprentissage non supervisé |
|
|
Objectif |
Approximation d'une fonction qui associe des entrées à des sorties sur la base d'exemples de paires entrée-sortie. |
Construire une représentation concise des données et générer un contenu imaginatif à partir de celles-ci. |
|
Précision |
Très précis et fiable. |
Moins précis et moins fiable. |
|
Complexité |
Méthode plus simple. |
Complexe sur le plan informatique. |
|
Classes |
Le nombre de classes est connu. |
Le nombre de classes est inconnu. |
|
Sortie |
Une valeur de sortie souhaitée (également appelée signal de supervision). |
Pas de valeurs de sortie correspondantes. |
Types d'apprentissage non supervisé
Dans l'introduction, nous avons mentionné que l'apprentissage non supervisé est une méthode que nous utilisons pour regrouper des données en l'absence d'étiquettes. En l'absence d'étiquettes, des méthodes d'apprentissage non supervisées sont généralement appliquées pour construire une représentation concise des données afin d'en tirer un contenu imaginatif.
Par exemple, si nous lançons un nouveau produit, nous pouvons utiliser des méthodes d'apprentissage non supervisé pour identifier le marché cible du nouveau produit : en effet, nous ne disposons pas d'informations historiques sur le client cible et ses caractéristiques démographiques.
Mais l'apprentissage non supervisé peut être divisé en trois tâches principales :
- Regroupement
- Règles d'association
- Réduction de la dimensionnalité.
Approfondissons chacun d'entre eux :
Regroupement
D'un point de vue théorique, les instances d'un même groupe ont tendance à avoir des propriétés similaires. Vous pouvez observer ce phénomène dans le tableau périodique. Les membres d'un même groupe, séparés par dix-huit colonnes, ont le même nombre d'électrons dans les coques externes de leurs atomes et forment des liaisons du même type.
C'est l'idée qui est en jeu dans les algorithmes de regroupement. Les méthodes de regroupement consistent à grouper des données non étiquetées en fonction de leurs similitudes et de leurs différences. Lorsque deux instances apparaissent dans des groupes différents, on peut en déduire qu'elles ont des propriétés dissemblables.
Le regroupement est un type populaire d'approche d'apprentissage non supervisé. Vous pouvez même le décomposer en différents types de regroupement, par exemple :
- Regroupement exlusif: Les données sont regroupées de manière à ce qu'un seul point de données appartienne exclusivement à une grappe.
- Regroupement par chevauchement: Une grappe souple dans laquelle un seul point de données peut appartenir à plusieurs grappes avec des degrés d'appartenance variables.
- Regroupement hiérarchique: Un type de regroupement dans lequel des groupes sont créés de telle sorte que des instances similaires se trouvent dans le même groupe et que des objets différents se trouvent dans d'autres groupes.
- Regroupement probaliste: Les grappes sont créées à l'aide d'une distribution de probabilité.
Extraction de règles d'association
Ce type d'apprentissage automatique non supervisé adopte une approche basée sur des règles pour découvrir des relations intéressantes entre les caractéristiques d'un ensemble de données donné. Il fonctionne en utilisant une mesure d'intérêt pour identifier les règles fortes trouvées dans un ensemble de données.
L'extraction de règles d'association est généralement utilisée pour l'analyse du panier de la ménagère : il s'agit d'une technique d'extraction de données que les détaillants utilisent pour mieux comprendre les habitudes d'achat de leurs clients en se basant sur les relations entre les différents produits.
L'algorithme le plus utilisé pour l'apprentissage des règles d'association est l'algorithme Apriori. Cependant, d'autres algorithmes sont utilisés pour ce type d'apprentissage non supervisé, tels que les algorithmes Eclat et FP-growth.
Réduction de la dimensionnalité
Les algorithmes les plus utilisés pour la réduction de la dimensionnalité sont l'analyse en composantes principales (ACP) et la décomposition en valeurs singulières (SVD). Ces algorithmes cherchent à transformer les données d'espaces à haute dimension en espaces à basse dimension sans compromettre les propriétés significatives des données d'origine. Ces techniques sont généralement déployées au cours de l'analyse exploratoire des données (AED) ou du traitement des données afin de préparer les données pour la modélisation.
Il est utile de réduire la dimensionnalité d'un ensemble de données au cours de l'EDA pour faciliter la visualisation des données : en effet, il est difficile de visualiser des données en plus de trois dimensions. Du point de vue du traitement des données, la réduction de la dimensionnalité des données simplifie le problème de la modélisation.
Lorsque le modèle est alimenté par un plus grand nombre de caractéristiques d'entrée, il doit apprendre une fonction d'approximation plus complexe. Ce phénomène peut être résumé par une expression appelée la "malédiction de la dimensionnalité".
Applications de l'apprentissage non supervisé
La plupart des cadres n'auraient aucun mal à identifier des cas d'utilisation pour les tâches d'apprentissage automatique supervisé ; il n'en va pas de même pour l'apprentissage non supervisé.
L'une des raisons en est la simple nature du risque. L'apprentissage non supervisé présente beaucoup plus de risques que l'apprentissage non supervisé, car il n'existe pas de moyen clair de mesurer les résultats par rapport à la vérité de terrain de manière hors ligne, et il peut être trop risqué de procéder à une évaluation en ligne.
Néanmoins, il existe plusieurs cas d'utilisation précieux de l'apprentissage non supervisé au niveau de l'entreprise. Au-delà de l'utilisation de techniques non supervisées pour explorer les données, voici quelques cas d'utilisation courants dans le monde réel :
- Traitement du langage naturel (NLP). Google News est connu pour tirer parti de l'apprentissage non supervisé afin de classer les articles basés sur la même histoire et provenant de différents organes d'information. Par exemple, les résultats de la fenêtre de transfert pour le football peuvent tous être classés dans la catégorie "football".
- Analyse d'images et de vidéos. Les tâches de perception visuelle telles que la reconnaissance d'objets font appel à l'apprentissage non supervisé.
- Détection des anomalies. L'apprentissage non supervisé est utilisé pour identifier les points de données, les événements et/ou les observations qui s'écartent du comportement normal d'un ensemble de données.
- Segmentation de la clientèle. L'apprentissage non supervisé permet de créer des profils d'acheteurs intéressants. Cela aide les entreprises à comprendre les traits communs et les habitudes d'achat de leurs clients, ce qui leur permet d'adapter leurs produits en conséquence.
- Recommandation Moteurs. Le comportement d'achat antérieur, associé à l'apprentissage non supervisé, peut être utilisé pour aider les entreprises à découvrir les tendances des données qu'elles pourraient utiliser pour développer des stratégies de vente croisée efficaces.
Exemple d'apprentissage non supervisé en Python
L'analyse en composantes principales (ACP) consiste à calculer les composantes principales et à les utiliser pour effectuer un changement de base sur les données. En d'autres termes, l'ACP est une technique de réduction de la dimensionnalité par apprentissage non supervisé.
Il est utile de réduire la dimensionnalité d'un ensemble de données pour deux raisons principales :
- Lorsqu'il y a trop de dimensions dans un ensemble de données pour pouvoir les visualiser
- Identifier les n dimensions les plus prédictives pour la sélection des caractéristiques lors de la construction d'un modèle prédictif.
Dans cette section, nous allons mettre en œuvre l'algorithme d'ACP en Python sur le jeu de données Iris, puis le visualiser à l'aide de matplotlib. Consultez ce classeur DataLab pour suivre le code utilisé dans ce tutoriel.
Commençons par importer les bibliothèques nécessaires et les données.
from sklearn.datasets import load_iris # Dataset
from sklearn.decomposition import PCA # Algorithm
import matplotlib.pyplot as plt # Visualization
# Load the data
iris_data = load_iris(as_frame=True)
# Preview
iris_data.data.head()|
longueur du sépale (cm) |
largeur du sépale (cm) |
longueur des pétales (cm) |
largeur des pétales (cm) |
|
|
0 |
5.1 |
3.5 |
1.4 |
0.2 |
|
1 |
4.9 |
3 |
1.4 |
0.2 |
|
2 |
4.7 |
3.2 |
1.3 |
0.2 |
|
3 |
4.6 |
3.1 |
1.5 |
0.2 |
|
4 |
5 |
3.6 |
1.4 |
0.2 |
L'ensemble de données sur l'iris comporte quatre caractéristiques. Il est impossible d'essayer de visualiser des données en quatre dimensions ou plus, car nous n'avons aucune idée de l'aspect des choses dans une dimension aussi élevée. La meilleure chose à faire est de la représenter en trois dimensions, ce qui n'est pas impossible mais reste un défi.
Par exemple :
"""
Credit: Rishikesh Kumar Rishi
Link: https://www.tutorialspoint.com/how-to-make-a-4d-plot-with-matplotlib-using-arbitrary-data
"""
plt.rcParams["figure.figsize"] = [7.00, 3.50]
plt.rcParams["figure.autolayout"] = True
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
sepal_length = iris_data.data["sepal length (cm)"]
sepal_width = iris_data.data["sepal width (cm)"]
petal_length = iris_data.data["petal length (cm)"]
petal_width = iris_data.data["petal width (cm)"]
ax.scatter(sepal_length, sepal_width, petal_length, c=petal_width)
plt.show()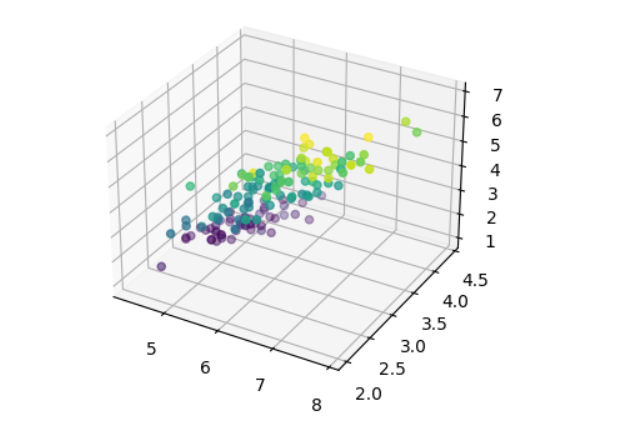
Il est assez difficile d'obtenir des informations à partir de cette visualisation, car toutes les instances sont mélangées, étant donné que nous n'avons accès qu'à un seul point de vue lorsque nous visualisons des données en trois dimensions dans ce scénario.
L'ACP permet de réduire les dimensions des données à deux, ce qui facilite la visualisation des données et la distinction des classes.
Note: Apprenez à mettre en œuvre l'ACP en R dans "Tutoriel sur l'analyse en composantes principales en R."
# Instantiate PCA with 2 components
pca = PCA(n_components=2)
# Train the model
pca.fit(iris_data.data)
iris_data_reduced = pca.fit_transform(iris_data.data)
# Plot data
plt.scatter(
iris_data_reduced[:,0],
iris_data_reduced[:,1],
c=iris_data.target
)
plt.show()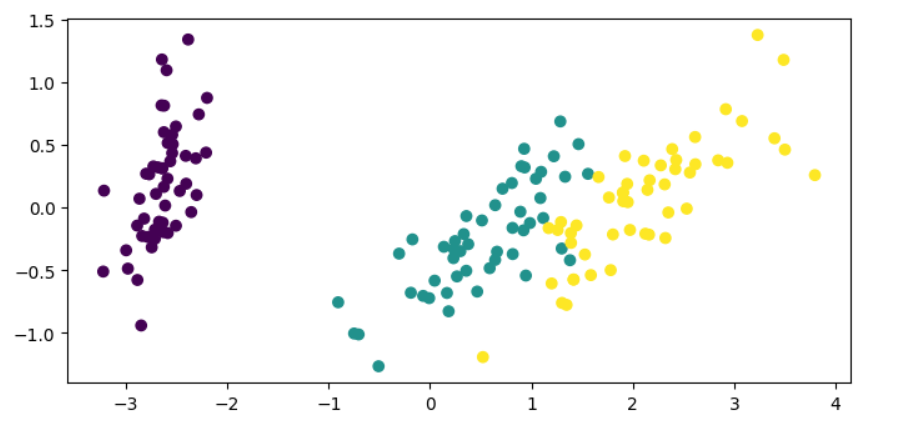
Dans le code ci-dessus, nous transformons les caractéristiques de l'ensemble de données de l'iris, en ne conservant que deux composantes, puis nous traçons les données réduites sur un plan bidimensionnel.
Désormais, il nous est beaucoup plus facile de recueillir des informations sur les données et sur la façon dont les classes sont séparées. Nous pouvons utiliser ces informations pour décider des prochaines étapes à suivre si nous devions adapter un modèle d'apprentissage automatique à nos données.
Dernières réflexions
L'apprentissage non supervisé fait référence à une classe de problèmes dans l'apprentissage automatique où un modèle est utilisé pour caractériser ou extraire des relations dans les données.
Contrairement à l'apprentissage supervisé, les algorithmes d'apprentissage non supervisé découvrent la structure sous-jacente d'un ensemble de données en utilisant uniquement les caractéristiques d'entrée. Cela signifie que les modèles d'apprentissage non supervisé n'ont pas besoin d'un enseignant pour les corriger, contrairement à l'apprentissage supervisé.
Dans cet article, vous avez appris les trois principaux types d'apprentissage non supervisé, à savoir l'extraction de règles d'association, le regroupement et la réduction de la dimensionnalité. Vous avez également appris plusieurs applications de l'apprentissage non supervisé, et comment effectuer une réduction de la dimensionnalité à l'aide de l'algorithme PCA en Python.
Pourquoi ne pas consulter ces ressources pour poursuivre votre formation ?