
Curso
Machine learning con modelos basados en árboles en Python
5 h
116.4K
Antes de construir el SOM, tenemos que preparar el entorno con los paquetes necesarios.
Necesitamos estos paquetes:
matplotlib se utiliza para trazar diversos gráficos y diagramas para visualizar los datos. datasets de sklearn se utiliza para importar conjuntos de datos sobre los que aplicar el SOM . MinMaxScaler de sklearn normaliza el conjunto de datos . El siguiente fragmento de código importa estos paquetes:
from minisom import MiniSom
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.preprocessing import MinMaxScalerEn este tutorial, utilizamos MiniSom para construir un SOM y luego lo entrenamos con el conjunto de datos canónico IRIS. Este conjunto de datosconsta de 3 clases de plantas de iris. Cada clase tiene 50 instancias. Para preparar los datos, seguimos estos pasos:
sklearn, El siguiente código implementa estos pasos:
dataset_iris = datasets.load_iris()
data_iris = dataset_iris.data
target_iris = dataset_iris.target
data_iris_normalized = MinMaxScaler().fit_transform(data_iris)
labels_iris = {1:'1', 2:'2', 3:'3'}
data = data_iris_normalized
target = target_irisPara implementar un SOM en Python, definimos e inicializamos la malla antes de entrenarla con el conjunto de datos. A continuación, podemos visualizar las neuronas entrenadas y el conjunto de datos agrupados.
Como ya se ha explicado, un SOM es una red de neuronas. Con MiniSom podemos crear cuadrículas bidimensionales. Las dimensiones X e Y de la cuadrícula son el número de neuronas a lo largo de cada eje. Para definir la malla SOM, también tenemos que especificar:
Declara estos parámetros como constantes de Python:
SOM_X_AXIS_NODES = 8
SOM_Y_AXIS_NODES = 8
SOM_N_VARIABLES = data.shape[1]El código de ejemplo que aparece a continuación ilustra cómo declarar la rejilla utilizando MiniSom:
som = MiniSom(SOM_X_AXIS_NODES, SOM_Y_AXIS_NODES, SOM_N_VARIABLES)Los dos primeros parámetros son el número de neuronas a lo largo de los ejes X e Y, y el tercer parámetro es el número de variables.
Declaramos otros parámetros e hiperparámetros al crear la malla SOM. Los explicaremos más adelante en el tutorial. De momento, declara estos parámetros como se muestra a continuación:
ALPHA = 0.5
DECAY_FUNC = 'linear_decay_to_zero'
SIGMA0 = 1.5
SIGMA_DECAY_FUNC = 'linear_decay_to_one'
NEIGHBORHOOD_FUNC = 'triangle'
DISTANCE_FUNC = 'euclidean'
TOPOLOGY = 'rectangular'
RANDOM_SEED = 123Crea un SOM utilizando estos parámetros:
som = MiniSom(
SOM_X_AXIS_NODES,
SOM_Y_AXIS_NODES,
SOM_N_VARIABLES,
sigma=SIGMA0,
learning_rate=ALPHA,
neighborhood_function=NEIGHBORHOOD_FUNC,
activation_distance=DISTANCE_FUNC,
topology=TOPOLOGY,
sigma_decay_function = SIGMA_DECAY_FUNC,
decay_function = DECAY_FUNC,
random_seed=RANDOM_SEED,
)El comando anterior crea un SOM con pesos aleatorios para todas las neuronas. Inicializar las neuronas con pesos extraídos de los datos (en lugar de números aleatorios) puede hacer que el proceso de entrenamiento sea más eficaz.
Cuando se utiliza MiniSom para crear un Mapa Autoorganizado (SOM), hay dos formas de inicializar los pesos de las neuronas en función de los datos:
.random_weights_init() al SOM . En esta guía, utilizamos la inicialización PCA. Para aplicar la inicialización PCA a los pesos SOM, utiliza la función .pca_weights_init() como se muestra a continuación:
som.pca_weights_init(data)El proceso de entrenamiento actualiza los pesos del SOM para minimizar la distancia entre las neuronas y los puntos de datos.
A continuación, explicamos el proceso de entrenamiento iterativo:
Para entrenar el SOM, presentamos el modelo con los datos de entrada. Podemos elegir uno de los dos enfoques para hacerlo:
.train_random() pone en práctica esta técnica . .train_batch(). Estas funciones aceptan como parámetros los datos de entrada y el número de iteraciones. En esta guía utilizamos la función .train_random() . Declara el número de iteraciones como una constante y pásalo a la función de entrenamiento:
N_ITERATIONS = 5000
som.train_random(data, N_ITERATIONS, verbose=True) Tras ejecutar el script y completar el entrenamiento, aparece un mensaje con el error de cuantización:
quantization error: 0.05357240680504421 El error de cuantización indica la cantidad de información que se pierde cuando el SOM cuantiza (reduce la dimensionalidad) los datos. Un error de cuantización grande indica una mayor distancia entre las neuronas y los puntos de datos. También significa que la agrupación es menos fiable.
Ahora tenemos un modelo SOM entrenado. Para visualizarlo, utilizamos un mapa de distancias (también conocido como U-matrix). El mapa de distancias muestra las neuronas del SOM como una cuadrícula de celdas. El color de cada célula representa su distancia a las neuronas vecinas.
El mapa de distancias es una cuadrícula con las mismas dimensiones que el SOM. Cada celda del mapa de distancias es la suma normalizada de las distancias (euclidianas) entre una neurona y sus vecinas.
Accede a SOM distance map utilizando la función .distance_map(). Para generar la matriz U, seguimos estos pasos:
pyplot para crear una figura con las mismas dimensiones que el SOM. En este ejemplo, las dimensiones son 8x8. .pcolor(). En este ejemplo, utilizamos gist_yarg como esquema de color. colorbar, un índice que asigna diferentes colores a diferentes valores escalares. En este caso, como las distancias están normalizadas, los valores escalares de distancia van de 0 a 1. El código siguiente implementa estos pasos:
# create the grid
plt.figure(figsize=(8, 8))
#plot the distance map
plt.pcolor(som.distance_map().T, cmap='gist_yarg')
# show the color bar
plt.colorbar()
plt.show()En este ejemplo, la matriz U utiliza un esquema de colores monótono. Se puede entender siguiendo estas pautas:
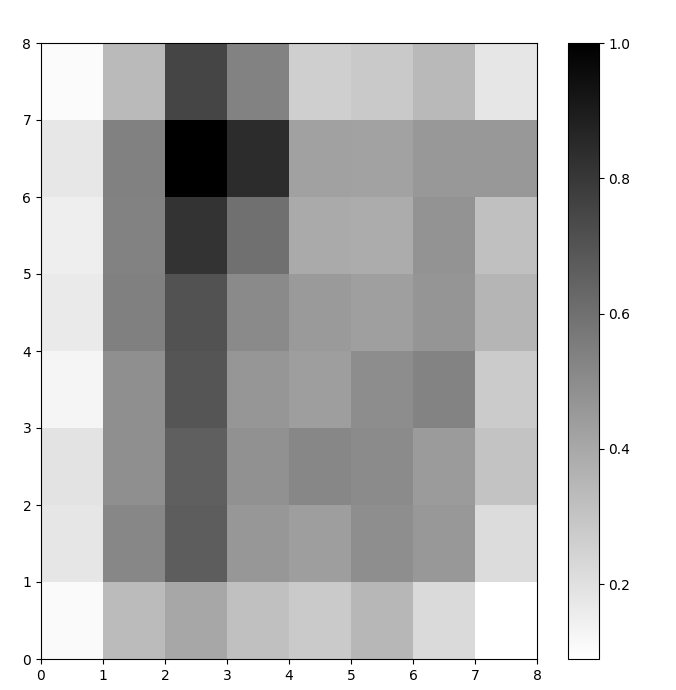
Figura 1: Matriz U del SOM entrenado en el conjunto de datos Iris (imagen del autor)
La figura anterior ilustraba gráficamente las neuronas del SOM. En esta sección, mostramos cómo visualizar la forma en que el SOM agrupó los datos.
Superponemos marcadores sobre la matriz en U anterior para denotar qué clase de planta Iris representa cada célula (neurona). Para ello:
pyplot, traza el mapa de distancias y muestra la barra de colores . .winner(). w[0] y w[1] dan las coordenadas X e Y de la neurona, respectivamente. Se añade un valor de 0,5 a cada coordenada para trazarla en el centro de la celda. El código siguiente muestra cómo hacerlo:
# plot the distance map
plt.figure(figsize=(8, 8))
plt.pcolor(som.distance_map().T, cmap='gist_yarg')
plt.colorbar()
# create the markers and colors for each class
markers = ['o', 'x', '^']
colors = ['C0', 'C1', 'C2']
# plot the winning neuron for each data point
for count, datapoint in enumerate(data):
# get the winner
w = som.winner(datapoint)
# place a marker on the winning position for the sample data point
plt.plot(w[0]+.5, w[1]+.5, markers[target[count]-1], markerfacecolor='None',
markeredgecolor=colors[target[count]-1], markersize=12, markeredgewidth=2)
plt.show()La imagen resultante se muestra a continuación:
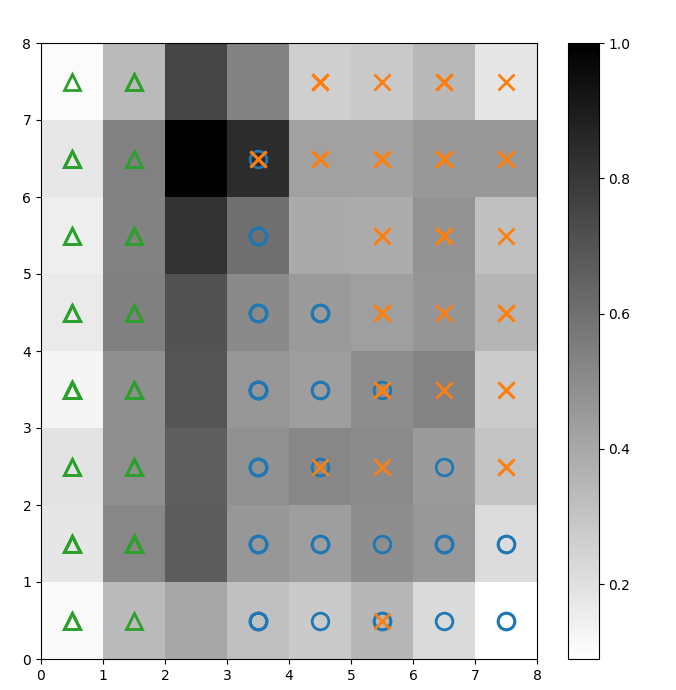
Figura 2: Matriz U superpuesta con marcadores de clase (imagen del autor)
Según la documentación del conjunto de datos Iris, "una clase es linealmente separable de las otras 2; estas últimas no son linealmente separables entre sí". En la matriz U anterior, estas tres clases están representadas por tres marcadores: triángulo, círculo y cruz.
Observa que no hay un límite claro entre los círculos azules y las cruces naranjas. Además, en muchas células se superponen dos clases en la misma neurona. Esto significa que la neurona es equidistante de ambas clases.
Un SOM es un modelo de agrupación. Los puntos de datos similares se asignan a la misma neurona. Los puntos de datos de la misma clase se asignan a un grupo de neuronas vecinas. Trazamos todos los puntos de datos en la cuadrícula SOM para estudiar mejor el comportamiento de agrupación.
Los pasos siguientes describen cómo crear este gráfico de dispersión:
plt.scatter() para hacer un diagrama de dispersión de todas las neuronas ganadoras para cada punto de datos. Añade un desplazamiento aleatorio a cada punto para evitar solapamientos entre puntos de datos dentro de la misma celda.Ejecutamos estos pasos en el código siguiente:
# get the X and Y coordinates of the winning neuron for each data pointw_x, w_y = zip(*[som.winner(d) for d in data])
w_x = np.array(w_x)
w_y = np.array(w_y)
# plot the distance map
plt.figure(figsize=(8, 8))
plt.pcolor(som.distance_map().T, cmap='gist_yarg', alpha=.2)
plt.colorbar()
# make a scatter plot of all the winning neurons for each data point
# add a random offset to each point to avoid overlaps
for c in np.unique(target):
idx_target = target==c
plt.scatter(w_x[idx_target]+.5+(np.random.rand(np.sum(idx_target))-.5)*.8,
w_y[idx_target]+.5+(np.random.rand(np.sum(idx_target))-.5)*.8,
s=50,
c=colors[c-1],
label=labels_iris[c+1]
)
plt.legend(loc='upper right')
plt.grid()
plt.show()El siguiente gráfico muestra el diagrama de dispersión de salida:
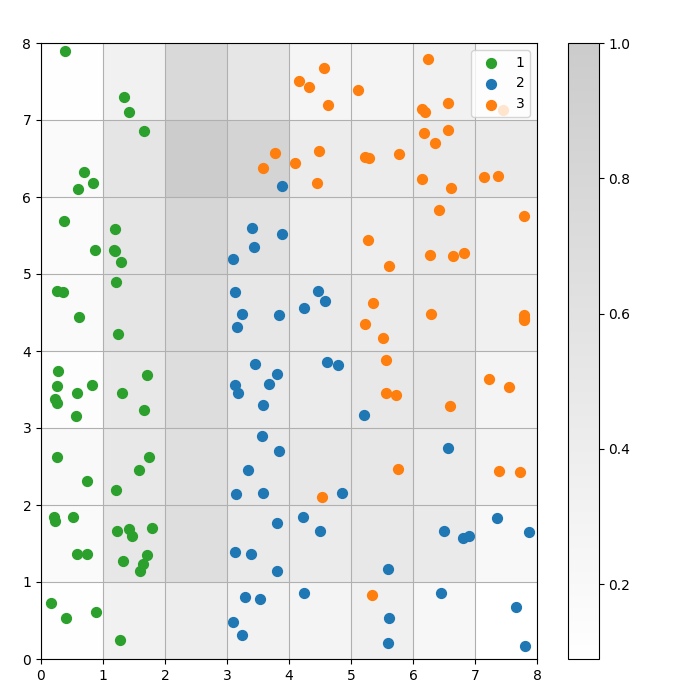 Figura 3: Diagrama de dispersión de los puntos de datos dentro de las celdas (imagen del autor)
Figura 3: Diagrama de dispersión de los puntos de datos dentro de las celdas (imagen del autor)
En el diagrama de dispersión anterior, observa que
Puedes acceder al código completo y ejecutarlo en este cuaderno DataLab.
Las secciones anteriores mostraban cómo crear y entrenar un modelo SOM y cómo estudiar los resultados visualmente. En esta sección, tratamos cómo ajustar el rendimiento de los modelos SOM.
Como ocurre con cualquier modelo de aprendizaje automático, los hiperparámetros influyen considerablemente en el rendimiento del modelo.
Algunos de los hiperparámetros importantes en el entrenamiento de los SOM son:
En la siguiente sección, discutiremos las directrices para establecer los valores de estos hiperparámetros.
Los valores de los hiperparámetros deben decidirse en función del modelo y del conjunto de datos. Hasta cierto punto, determinar estos valores es un proceso de ensayo y error. En esta sección, damos pautas para afinar cada hiperparámetro. Junto a cada hiperparámetro, mencionamos (entre paréntesis) las respectivas constantes Python utilizadas en el código de ejemplo.
SOM_X_AXIS_NODES y SOM_X_AXIS_NODES): El tamaño de la cuadrícula depende del tamaño del conjunto de datos. La regla general es que, dado un conjunto de datos de tamaño N, la cuadrícula debe contener aproximadamente 5*sqrt(N) neuronas. Por ejemplo, si el conjunto de datos tiene 150 muestras, la cuadrícula debe contener 5*sqrt(150) = aproximadamente 61 neuronas. En este tutorial, el conjunto de datos Iris tiene 150 filas y utilizamos una cuadrícula de 8x8. ALPHA): Una tasa más alta acelera la convergencia, mientras que las tasas más bajas se utilizan para ajustes más finos después de las primeras iteraciones. La tasa de aprendizaje inicial debe ser lo suficientemente grande como para permitir una adaptación rápida, pero no tanto como para sobrepasar los valores óptimos de peso. En este artículo, la tasa de aprendizaje inicial es 0,5. SIGMA0): Determina el tamaño inicial o la extensión del barrio. Un valor mayor considera patrones más globales. En este ejemplo, utilizamos una desviación típica inicial de 1,5. DECAY_FUNC ) y la tasa de decaimiento sigma (SIGMA_DECAY_FUNC ), podemos elegir entre uno de los tres tipos de funciones de decaimiento : NEIGHBORHOOD_FUNC): La elección por defecto de la función de vecindad es la función gaussiana. También se utilizan otras funciones, como se explica a continuación. DISTANCE_FUNC): Para medir la distancia entre las neuronas y los puntos de datos, podemos elegir entre 4 métodos:TOPOLOGY): En una rejilla, las neuronas pueden disponerse en una estructura hexagonal o rectangular: N_ITERATIONS): En principio, tiempos de entrenamiento más largos conducen a errores más bajos y a una mejor alineación de los pesos con los datos de entrada. Sin embargo, el rendimiento del modelo aumenta asintóticamente con el número de iteraciones. Así, tras un cierto número de iteraciones, el aumento de rendimiento de las interacciones posteriores es sólo marginal. Decidir el número correcto de iteraciones requiere cierta experimentación. En este tutorial, entrenamos el modelo durante 5000 iteraciones. Para determinar la configuración adecuada de los hiperparámetros, recomendamos experimentar con varias opciones en un subconjunto más pequeño de datos.
Los mapas autoorganizados son una herramienta robusta para el aprendizaje no supervisado. Se utilizan para la agrupación, la reducción de la dimensionalidad, la detección de anomalías y la visualización de datos. Como conservan las propiedades topológicas de los datos de alta dimensión y los representan en una cuadrícula de dimensión inferior, los SOM facilitan la visualización e interpretación de conjuntos de datos complejos.
Este tutorial trata los principios subyacentes de los SOM y muestra cómo implementar un SOM utilizando la biblioteca MiniSom Python. También demostró cómo analizar visualmente los resultados y explicó los hiperparámetros importantes utilizados para entrenar los SOM y ajustar su rendimiento.
¡Aprende más sobre aprendizaje automático y Python con estos cursos!
Curso
Curso
Curso
Tutorial
Moez Ali
Tutorial
Sejal Jaiswal
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
Tutorial
Moez Ali
Tutorial
Bex Tuychiev