
Curso
Aprendizado de máquina com modelos baseados em árvores em Python
5 h
116.4K
Antes de criar o SOM, precisamos preparar o ambiente com os pacotes necessários.
Precisamos desses pacotes:
matplotlib é usado para traçar vários gráficos e tabelas para visualizar os dados. datasets de sklearn é usado para importar conjuntos de dados nos quais você aplicará o SOM . MinMaxScaler de sklearn normaliza o conjunto de dados . O trecho de código a seguir importa esses pacotes:
from minisom import MiniSom
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.preprocessing import MinMaxScalerNeste tutorial, usamos o MiniSom para criar um SOM e, em seguida, treiná-lo no conjunto de dados IRIS canônico. Esse conjunto de dadosconsiste em 3 classes de plantas de íris. Cada classe tem 50 instâncias. Para preparar os dados, seguimos estas etapas:
sklearn, O código a seguir implementa essas etapas:
dataset_iris = datasets.load_iris()
data_iris = dataset_iris.data
target_iris = dataset_iris.target
data_iris_normalized = MinMaxScaler().fit_transform(data_iris)
labels_iris = {1:'1', 2:'2', 3:'3'}
data = data_iris_normalized
target = target_irisPara implementar um SOM em Python, definimos e inicializamos a grade antes de treiná-la no conjunto de dados. Em seguida, podemos visualizar os neurônios treinados e o conjunto de dados agrupados.
Conforme explicado anteriormente, um SOM é uma grade de neurônios. Usando o MiniSom, podemos criar grades bidimensionais. As dimensões X e Y da grade são o número de neurônios ao longo de cada eixo. Para definir a grade do SOM, também precisamos especificar:
Declare esses parâmetros como constantes Python:
SOM_X_AXIS_NODES = 8
SOM_Y_AXIS_NODES = 8
SOM_N_VARIABLES = data.shape[1]O código de exemplo abaixo ilustra como você pode declarar a grade usando o MiniSom:
som = MiniSom(SOM_X_AXIS_NODES, SOM_Y_AXIS_NODES, SOM_N_VARIABLES)Os dois primeiros parâmetros são o número de neurônios ao longo dos eixos X e Y, e o terceiro parâmetro é o número de variáveis.
Declaramos outros parâmetros e hiperparâmetros ao criar a grade SOM. Explicaremos isso mais adiante no tutorial. Por enquanto, declare esses parâmetros conforme mostrado abaixo:
ALPHA = 0.5
DECAY_FUNC = 'linear_decay_to_zero'
SIGMA0 = 1.5
SIGMA_DECAY_FUNC = 'linear_decay_to_one'
NEIGHBORHOOD_FUNC = 'triangle'
DISTANCE_FUNC = 'euclidean'
TOPOLOGY = 'rectangular'
RANDOM_SEED = 123Crie um SOM usando esses parâmetros:
som = MiniSom(
SOM_X_AXIS_NODES,
SOM_Y_AXIS_NODES,
SOM_N_VARIABLES,
sigma=SIGMA0,
learning_rate=ALPHA,
neighborhood_function=NEIGHBORHOOD_FUNC,
activation_distance=DISTANCE_FUNC,
topology=TOPOLOGY,
sigma_decay_function = SIGMA_DECAY_FUNC,
decay_function = DECAY_FUNC,
random_seed=RANDOM_SEED,
)O comando acima cria um SOM com pesos aleatórios para todos os neurônios. A inicialização dos neurônios com pesos extraídos dos dados (em vez de números aleatórios) pode tornar o processo de treinamento mais eficiente.
Ao usar o MiniSom para criar um mapa de auto-organização (SOM), há duas maneiras de inicializar os pesos dos neurônios com base nos dados:
.random_weights_init() ao SOM . Neste guia, usamos a inicialização do PCA. Para aplicar a inicialização do PCA aos pesos do SOM, use a função .pca_weights_init(), conforme mostrado abaixo:
som.pca_weights_init(data)O processo de treinamento atualiza os pesos do SOM para minimizar a distância entre os neurônios e os pontos de dados.
A seguir, explicamos o processo de treinamento iterativo:
Para treinar o SOM, apresentamos o modelo com os dados de entrada. Você pode escolher uma das duas abordagens para fazer isso:
.train_random() implementa essa técnica . .train_batch(). Essas funções aceitam os dados de entrada e o número de iterações como parâmetros. Neste guia, usamos a função .train_random() . Declare o número de iterações como uma constante e passe-o para a função de treinamento:
N_ITERATIONS = 5000
som.train_random(data, N_ITERATIONS, verbose=True) Após a execução do script e a conclusão do treinamento, é exibida uma mensagem com o erro de quantização:
quantization error: 0.05357240680504421 O erro de quantização indica a quantidade de informações perdidas quando o SOM quantiza (reduz a dimensionalidade) os dados. Um grande erro de quantização indica uma distância maior entre os neurônios e os pontos de dados. Isso também significa que o agrupamento é menos confiável.
Agora temos um modelo SOM treinado. Para visualizá-lo, usamos um mapa de distância (também conhecido como U-matrix). O mapa de distância exibe os neurônios do SOM como uma grade de células. A cor de cada célula representa sua distância dos neurônios vizinhos.
O mapa de distância é uma grade com as mesmas dimensões do SOM. Cada célula no mapa de distância é a soma normalizada das distâncias (euclidianas) entre um neurônio e seus vizinhos.
Acesse o site SOM distance map usando a função .distance_map(). Para gerar a matriz U, seguimos estas etapas:
pyplot para criar uma figura com as mesmas dimensões do SOM. Neste exemplo, as dimensões são 8x8. .pcolor(). Neste exemplo, usamos gist_yarg como o esquema de cores. colorbar, um índice que mapeia cores diferentes para valores escalares diferentes. Nesse caso, como as distâncias são normalizadas, os valores de distância escalar variam de 0 a 1. O código abaixo implementa essas etapas:
# create the grid
plt.figure(figsize=(8, 8))
#plot the distance map
plt.pcolor(som.distance_map().T, cmap='gist_yarg')
# show the color bar
plt.colorbar()
plt.show()Neste exemplo, a matriz U usa um esquema de cores monótono. Você pode entender isso usando estas diretrizes:
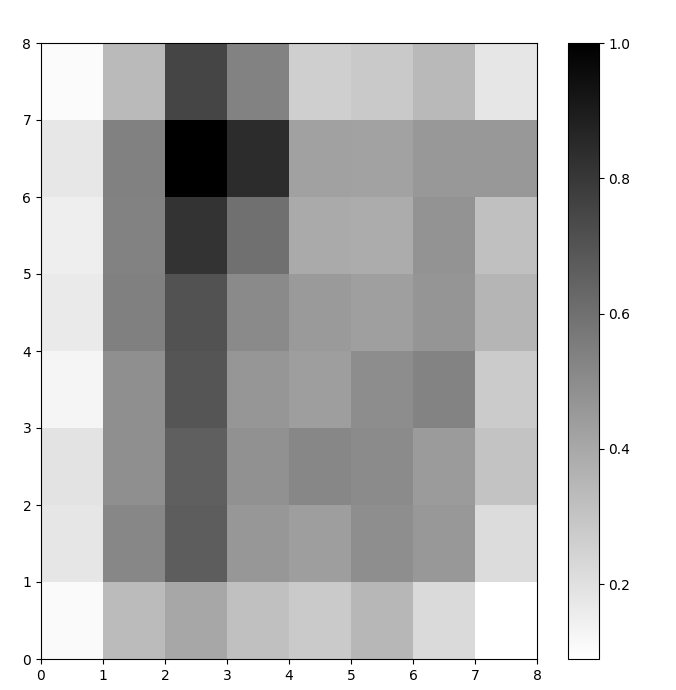
Figura 1: Matriz U do SOM treinado no conjunto de dados Iris (imagem do autor)
A figura anterior ilustrou graficamente os neurônios do SOM. Nesta seção, mostramos como visualizar como o SOM agrupou os dados.
Sobrepomos marcadores sobre a matriz U acima para indicar a classe da planta Iris que cada célula (neurônio) representa. Para fazer isso:
pyplot, trace o mapa de distância e mostre a barra de cores . .winner(). w[0] e w[1] fornecem as coordenadas X e Y do neurônio, respectivamente. Um valor de 0,5 é adicionado a cada coordenada para plotá-la no meio da célula. O código abaixo mostra como você pode fazer isso:
# plot the distance map
plt.figure(figsize=(8, 8))
plt.pcolor(som.distance_map().T, cmap='gist_yarg')
plt.colorbar()
# create the markers and colors for each class
markers = ['o', 'x', '^']
colors = ['C0', 'C1', 'C2']
# plot the winning neuron for each data point
for count, datapoint in enumerate(data):
# get the winner
w = som.winner(datapoint)
# place a marker on the winning position for the sample data point
plt.plot(w[0]+.5, w[1]+.5, markers[target[count]-1], markerfacecolor='None',
markeredgecolor=colors[target[count]-1], markersize=12, markeredgewidth=2)
plt.show()A imagem resultante é mostrada abaixo:
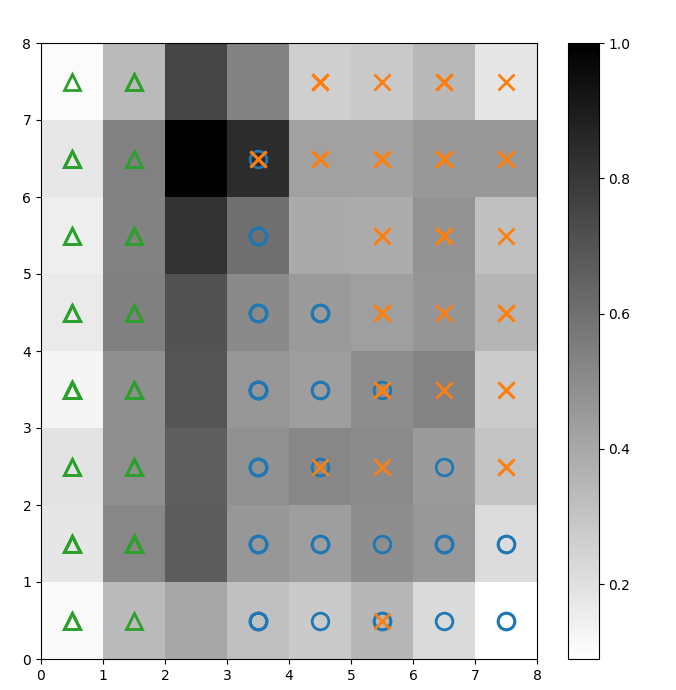
Figura 2: Matriz U sobreposta com marcadores de classe (imagem do autor)
Com base na documentação do conjunto de dados do Iris, "uma classe do é linearmente separável das outras duas; as últimas não são linearmente separáveis umas das outras". Na matriz U acima, essas três classes são representadas por três marcadores: triângulo, círculo e cruz.
Observe que não há um limite claro entre os círculos azuis e as cruzes laranja. Além disso, duas classes são sobrepostas no mesmo neurônio em muitas células. Isso significa que o neurônio está equidistante de ambas as classes.
Um SOM é um modelo de agrupamento. Pontos de dados semelhantes são mapeados para o mesmo neurônio. Os pontos de dados da mesma classe são mapeados para um cluster de neurônios vizinhos. Traçamos todos os pontos de dados na grade do SOM para estudar melhor o comportamento de agrupamento.
As etapas a seguir descrevem como você pode criar esse gráfico de dispersão:
plt.scatter() para criar um gráfico de dispersão de todos os neurônios vencedores para cada ponto de dados. Adicione um deslocamento aleatório a cada ponto para evitar sobreposições entre pontos de dados na mesma célula.Implementamos essas etapas no código abaixo:
# get the X and Y coordinates of the winning neuron for each data pointw_x, w_y = zip(*[som.winner(d) for d in data])
w_x = np.array(w_x)
w_y = np.array(w_y)
# plot the distance map
plt.figure(figsize=(8, 8))
plt.pcolor(som.distance_map().T, cmap='gist_yarg', alpha=.2)
plt.colorbar()
# make a scatter plot of all the winning neurons for each data point
# add a random offset to each point to avoid overlaps
for c in np.unique(target):
idx_target = target==c
plt.scatter(w_x[idx_target]+.5+(np.random.rand(np.sum(idx_target))-.5)*.8,
w_y[idx_target]+.5+(np.random.rand(np.sum(idx_target))-.5)*.8,
s=50,
c=colors[c-1],
label=labels_iris[c+1]
)
plt.legend(loc='upper right')
plt.grid()
plt.show()O gráfico a seguir mostra o gráfico de dispersão de saída:
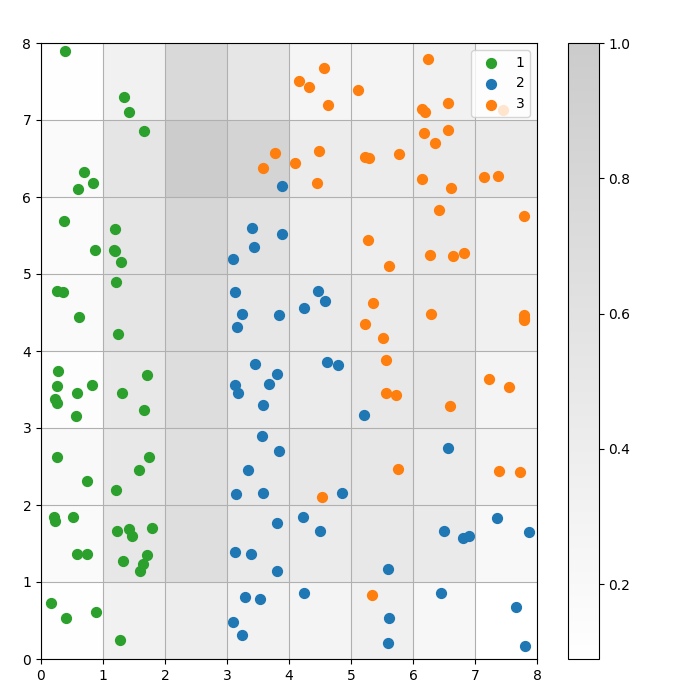 Figura 3: Gráfico de dispersão de pontos de dados dentro das células (imagem do autor)
Figura 3: Gráfico de dispersão de pontos de dados dentro das células (imagem do autor)
No gráfico de dispersão acima, observe que:
Você pode acessar e executar o código completo neste notebook do DataLab.
As seções anteriores mostraram como criar e treinar um modelo SOM e como estudar os resultados visualmente. Nesta seção, discutiremos como ajustar o desempenho dos modelos SOM.
Como em qualquer modelo de aprendizado de máquina, os hiperparâmetros afetam consideravelmente o desempenho do modelo.
Alguns dos hiperparâmetros importantes no treinamento de SOMs são:
Na próxima seção, discutiremos as diretrizes para definir os valores desses hiperparâmetros.
Os valores dos hiperparâmetros devem ser decididos com base no modelo e no conjunto de dados. Até certo ponto, a determinação desses valores é um processo de tentativa e erro. Nesta seção, fornecemos diretrizes para o ajuste de cada hiperparâmetro. Ao lado de cada hiperparâmetro, mencionamos (entre parênteses) as respectivas constantes Python usadas no código de exemplo.
SOM_X_AXIS_NODES e SOM_X_AXIS_NODES): O tamanho da grade depende do tamanho do conjunto de dados. A regra geral é que, com um conjunto de dados de tamanho N, a grade deve conter aproximadamente 5*sqrt(N) neurônios. Por exemplo, se o conjunto de dados tiver 150 amostras, a grade deverá conter 5*sqrt(150) = aproximadamente 61 neurônios. Neste tutorial, o conjunto de dados Iris tem 150 linhas e usamos uma grade 8x8. ALPHA): Uma taxa mais alta acelera a convergência, enquanto taxas mais baixas são usadas para ajustes mais finos após as primeiras iterações. A taxa de aprendizado inicial deve ser grande o suficiente para permitir uma adaptação rápida, mas não tão grande que ultrapasse os valores ideais de peso. Neste artigo, a taxa de aprendizado inicial é de 0,5. SIGMA0): Ele determina o tamanho inicial ou a expansão da vizinhança. Um valor maior considera padrões mais globais. Neste exemplo, usamos um desvio padrão inicial de 1,5. DECAY_FUNC ) e a taxa de decaimento sigma (SIGMA_DECAY_FUNC ), podemos escolher entre um dos três tipos de funções de decaimento : NEIGHBORHOOD_FUNC): A escolha padrão da função de vizinhança é a função Gaussiana. Outras funções, conforme explicado abaixo, também são usadas. DISTANCE_FUNC): Para medir a distância entre os neurônios e os pontos de dados, podemos escolher entre quatro métodos:TOPOLOGY): Em uma grade, os neurônios podem ser dispostos em uma estrutura hexagonal ou retangular: N_ITERATIONS): Em princípio, tempos de treinamento mais longos levam a erros menores e a um melhor alinhamento dos pesos com os dados de entrada. No entanto, o desempenho do modelo aumenta assintoticamente com o número de iterações. Assim, após um determinado número de iterações, o aumento de desempenho das interações subsequentes é apenas marginal. Para decidir o número correto de iterações, você precisa fazer algumas experiências. Neste tutorial, treinamos o modelo em 5.000 iterações. Para determinar a configuração correta dos hiperparâmetros, recomendamos que você experimente várias opções em um subconjunto menor de dados.
Os mapas auto-organizáveis são uma ferramenta robusta para aprendizado não supervisionado. Eles são usados para agrupamento, redução de dimensionalidade, detecção de anomalias e visualização de dados. Como eles preservam as propriedades topológicas dos dados de alta dimensão e os representam em uma grade de dimensão inferior, os SOMs facilitam a visualização e a interpretação de conjuntos de dados complexos.
Este tutorial discutiu os princípios subjacentes dos SOMs e mostrou como implementar um SOM usando a biblioteca MiniSom Python. Ele também demonstrou como analisar visualmente os resultados e explicou os hiperparâmetros importantes usados para treinar SOMs e ajustar seu desempenho.
Aprenda mais sobre aprendizado de máquina e Python com estes cursos!
Curso
Curso
Curso
Tutorial
Sejal Jaiswal
Tutorial
Moez Ali
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
Moez Ali