tracks
개발자를 위한 AI 엔지니어 보조
26
이 가이드에서는 H100 80GB 4개가 장착된 GPU 가상 머신을 사용했습니다. Mistral Medium 3.5는 128B 밀집 모델이므로 멀티 GPU 구성이 필요합니다. SGLang은 H100 또는 H200 GPU에서 --tp 4로 텐서 병렬 처리 실행을 권장합니다. 모델은 큰 컨텍스트 윈도우를 지원하지만, 테스트와 디버깅을 수월하게 하기 위해 우선 100,000 토큰부터 시작할 것을 권합니다(전체 256K 컨텍스트 대신).
저는 Hyperbolic을 사용했습니다. 전체 GPU VM에 접근할 수 있어 Docker 설치, NVIDIA 컨테이너 런타임 구성, SGLang Docker 이미지를 수동으로 실행하기가 수월하기 때문입니다. RunPod나 Vast.ai 같은 플랫폼도 사용할 수 있지만, 일부 인스턴스는 맞춤형 Docker 환경에 이미 묶여 있어 제어권이 줄어듭니다.
Hyperbolic에서 H100 PCIe 80GB를 선택하고 GPU 4개를 지정한 뒤, 약 3TB의 스토리지를 추가하고, SSH 공개 키를 입력한 다음, 인스턴스 이름을 MM-35처럼 지정하세요. 이번 테스트에서는 H100 PCIe가 사용 가능한 H100 옵션 중 가장 저렴해 선택했습니다.
Start Building을 클릭하면 머신이 시작되기까지 약 10분이 걸릴 수 있습니다. 준비가 완료되면 Hyperbolic이 다음 단계에서 필요한 SSH 접속 명령을 표시합니다.
인스턴스가 준비되면 Hyperbolic 대시보드에 표시된 SSH 명령을 사용해 로컬 터미널에서 접속하세요:
ssh ubuntu@XXXXXX나중에 로컬 머신에서 SGLang API에 접근하려면 포트 30000을 포워딩할 수도 있습니다:
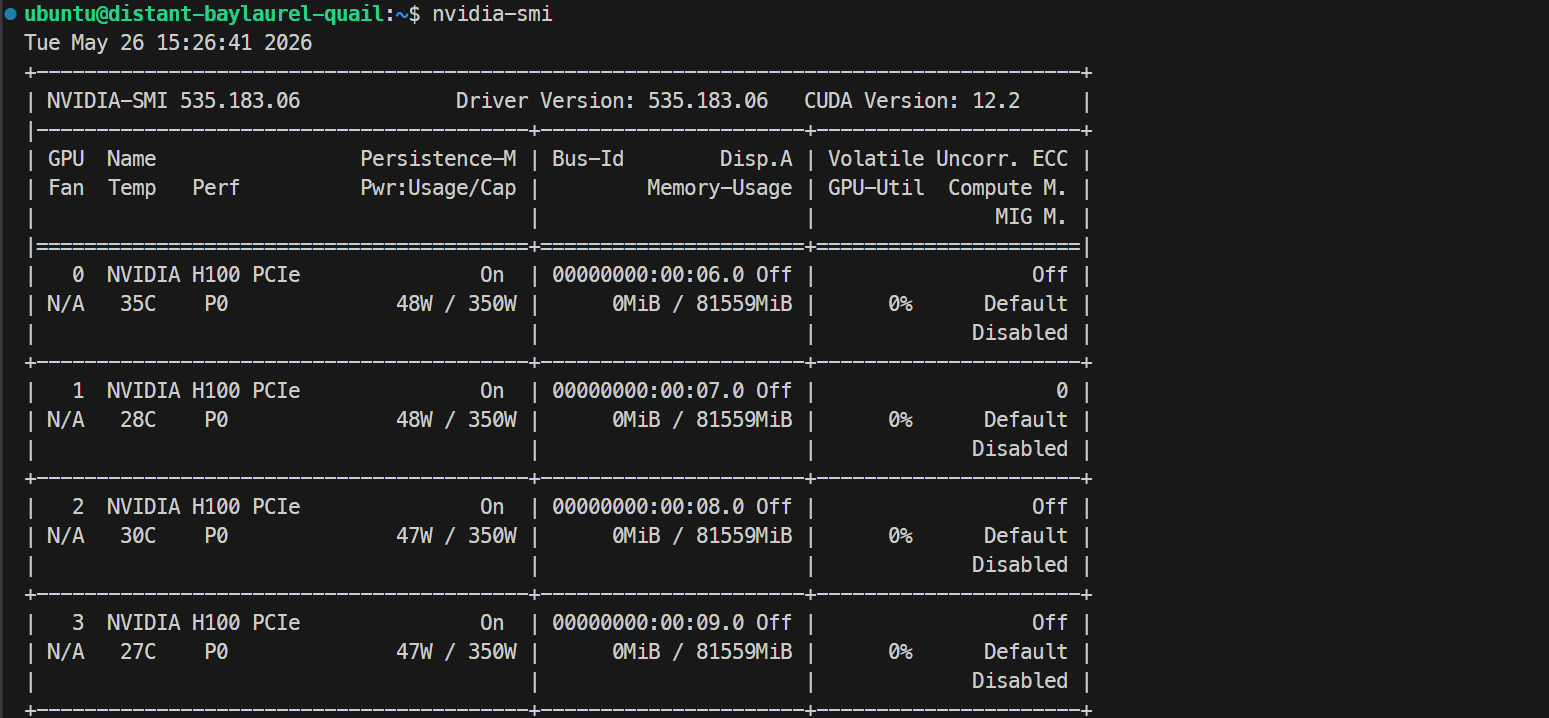
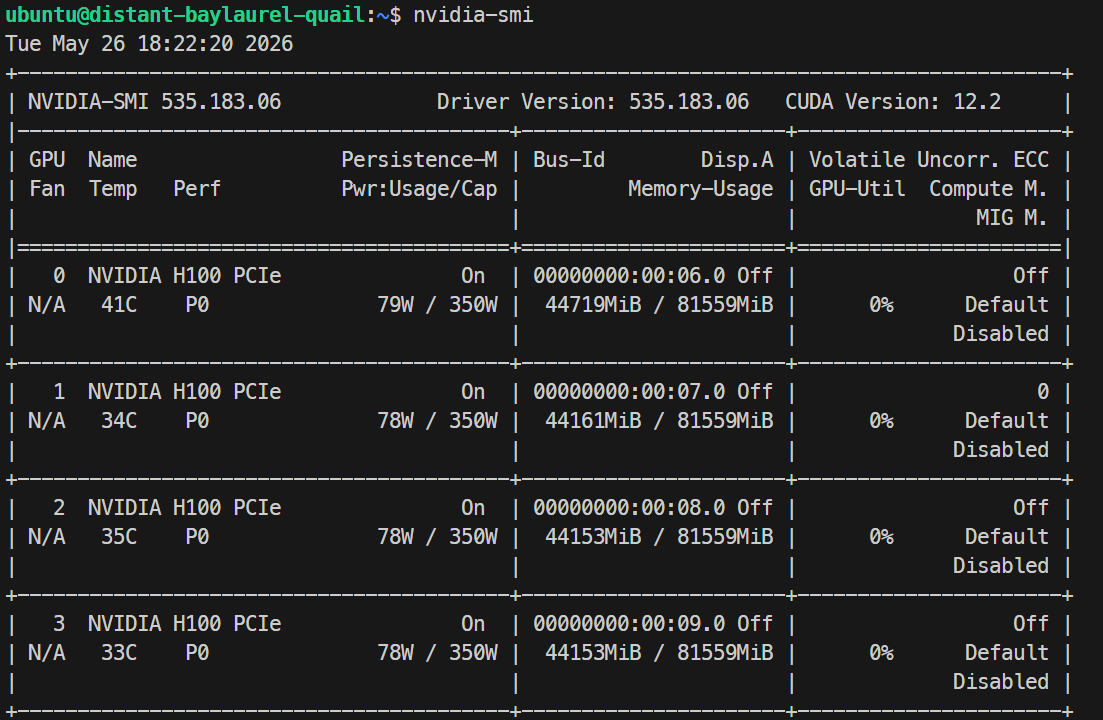
ssh -L 30000:localhost:30000 ubuntu@XXXXXXSSH 키에 암호가 있으면 프롬프트에 따라 입력하세요. 로그인 후 모든 GPU가 보이는지 확인합니다:
Nvidia-smiNVIDIA H100 PCIe 80GB GPU 4대가 표시되어야 합니다. 이는 Docker 및 SGLang 설정을 위한 서버 준비가 완료되었음을 의미합니다.
먼저 Hugging Face 토큰을 내보내 모델 다운로드에 사용할 수 있도록 합니다:
echo 'export HF_TOKEN="your_huggingface_token_here"' >> ~/.bashrc
source ~/.bashrc참고: Hugging Face 토큰은 Access Tokens 페이지에서 발급받을 수 있습니다.
Hugging Face 캐시 폴더를 생성합니다:
mkdir -p ~/.cache/huggingface이제 Docker를 설치합니다:
sudo apt update
sudo apt install -y docker.ioDocker를 시작하고 재부팅 후 자동 실행되도록 설정합니다:
sudo systemctl start docker
sudo systemctl enable dockerDocker가 올바르게 설치되었는지 확인합니다:
docker –version또한 Docker Hub의 공개 이미지를 검색할 수 있는지 확인하려면 다음 명령을 사용합니다:
docker search nvidia/cudaNVIDIA CUDA 이미지 목록이 반환되어야 합니다. 이후 이들 중 하나를 사용해 Docker가 GPU에 접근할 수 있는지 검증합니다.
다음으로, sudo 없이도 Docker 명령을 실행할 수 있도록 사용자 권한을 설정합니다:
sudo usermod -aG docker $USER
newgrp docker이제 NVIDIA Container Toolkit을 설치하고 구성해 Docker가 GPU에 접근할 수 있도록 합니다:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/libnvidia-container/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt update
sudo apt install -y nvidia-container-toolkit
sudo nvidia-ctk runtime configure --runtime=docker
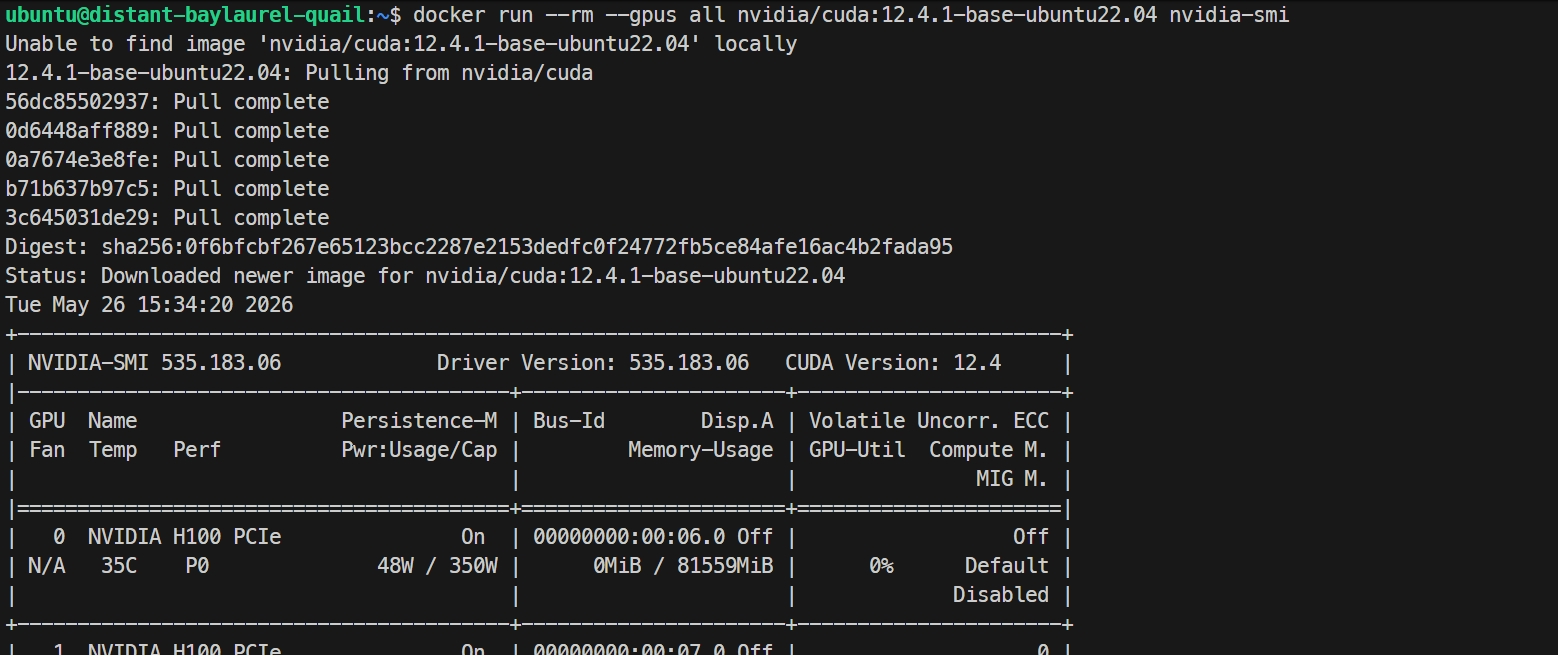
sudo systemctl restart docker마지막으로, 컨테이너 내부에서 Docker가 GPU를 인식하는지 테스트합니다:
docker run --rm --gpus all nvidia/cuda:12.4.1-base-ubuntu22.04 nvidia-smi컨테이너 내부에서도 동일한 H100 GPU 목록이 출력되면 GPU Docker 설정이 올바르게 작동하는 것입니다.
다음으로, Mistral Medium 3.5용 SGLang Docker 이미지를 가져옵니다:
docker pull lmsysorg/sglang:dev-mistral-medium-3.5
인터넷 속도에 따라 시간이 걸릴 수 있습니다. 제 경우 약 10분이 소요되었습니다. 이미지 다운로드가 완료되면 다음과 유사한 성공 메시지가 표시됩니다:
Status: Downloaded newer image for lmsysorg/sglang:dev-mistral-medium-3.5이제 SGLang 서버를 시작합니다:
docker run -d \
--name mistral-sglang \
--gpus all \
--shm-size 64g \
--ipc=host \
--cap-add SYS_NICE \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e HF_TOKEN=$HF_TOKEN \
-e PYTORCH_ALLOC_CONF=expandable_segments:True \
lmsysorg/sglang:dev-mistral-medium-3.5 \
sglang serve \
--model-path mistralai/Mistral-Medium-3.5-128B \
--served-model-name mistral-medium-3.5 \
--host 0.0.0.0 \
--port 30000 \
--tp 4 \
--trust-remote-code \
--dtype bfloat16 \
--context-length 100000 \
--mem-fraction-static 0.85 \
--disable-custom-all-reduce \
--tool-call-parser mistral \
--reasoning-parser mistral--dtype bfloat16을 사용한 이유는 이후 EAGLE 설정에서도 bf16이 필요하기 때문입니다. 기본 실행과 추론 가속 실행의 dtype을 맞추면 테스트 간 dtype을 바꿀 필요가 없습니다. 또한 첫 실행은 디버깅을 쉽게 하기 위해 전체 컨텍스트 윈도우 대신 --context-length 100000으로 시작했습니다.
컨테이너 로그는 다음으로 확인합니다:
docker logs -f mistral-sglang
첫 실행은 Hugging Face에서 모델 파일을 다운로드해야 하므로 더 오래 걸립니다. 리포지토리 용량이 크기 때문에 인스턴스 속도에 따라 한 시간 이상 소요될 수 있습니다.
서버 준비가 완료되면 로그에 Uvicorn이 포트 30000에서 실행 중임이 표시됩니다.
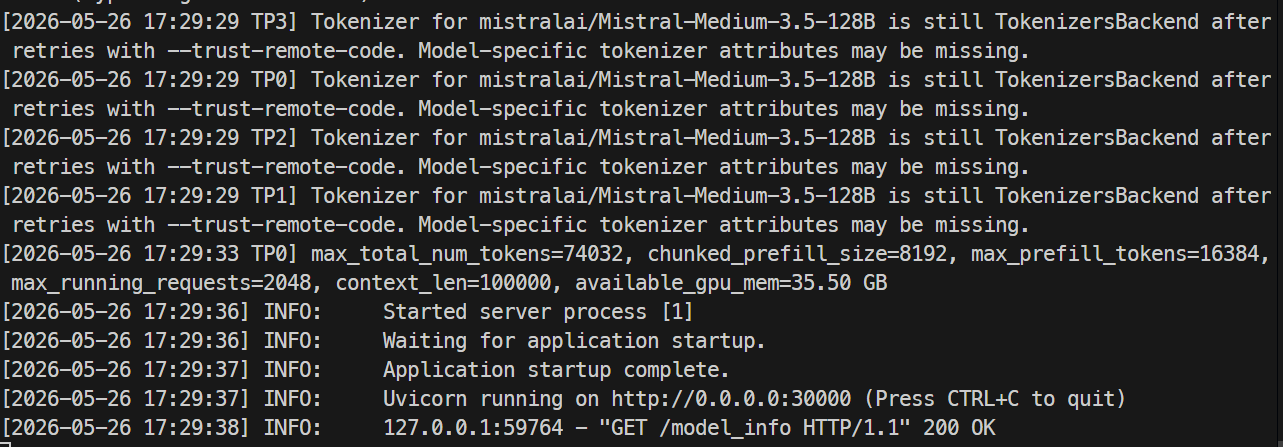
다른 터미널에서 서버에 다시 SSH로 접속해 엔드포인트를 확인합니다:
curl http://localhost:30000/v1/modelsmistral-medium-3.5가 max_model_len 100000으로 표시되어야 합니다.
{"object":"list","data":[{"id":"mistral-medium-3.5","object":"model","created":1779816738,"owned_by":"sglang","root":"mistral-medium-3.5","parent":null,"max_model_len":100000}]}마지막으로 채팅 완성을 테스트합니다:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mistral-medium-3.5",
"messages": [
{
"role": "user",
"content": "Write a short introduction to Mistral Medium 3.5."
}
],
"max_tokens": 300,
"temperature": 0.7,
"top_p": 0.95
}'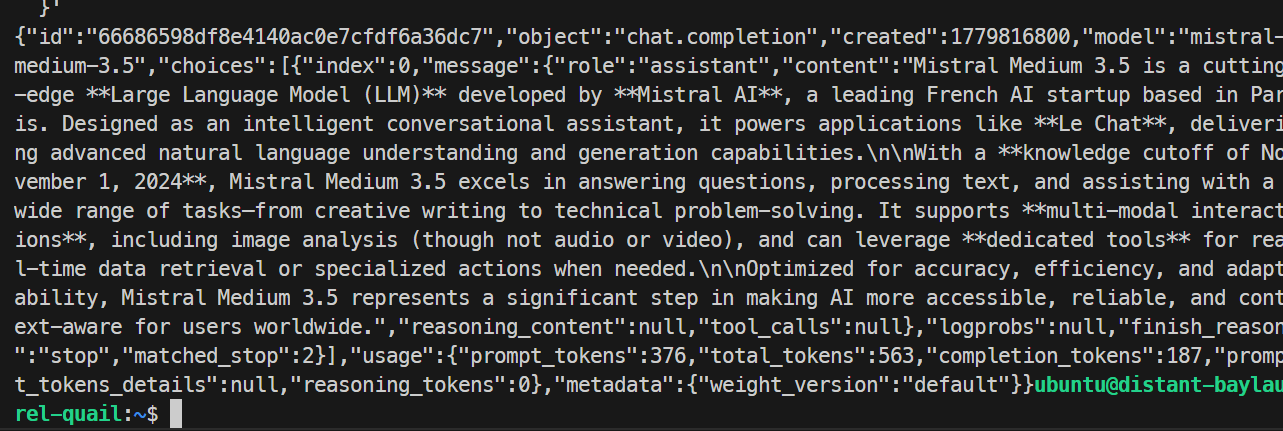
테스트에서 모델은 정상적으로 응답하고 요청을 깔끔하게 처리해 SGLang 엔드포인트가 동작함을 확인했습니다. 기본 실행은 초당 약 35.6 토큰을 생성했습니다.
추론 가속(speculative decoding)은 더 작은 드래프트 모델이 앞선 토큰을 예측하고, 메인 모델이 이를 검증하는 방식으로 생성 속도를 높일 수 있습니다.
EAGLE은 지연 시간에 민감한 서빙에 유용합니다. 특히 Mistral Medium 3.5 같은 대형 모델을 로컬에서 실행할 때 그렇습니다. 항상 더 빠르지는 않지만, 프롬프트 길이, 출력 길이, 동시성, GPU 사용량에 따라 이점이 달라지므로 시험해 볼 가치는 있습니다.
먼저 기본 컨테이너를 제거합니다:
docker rm -f mistral-sglang이제 EAGLE 버전을 시작합니다:
docker run -d \
--name mistral-sglang-eagle \
--gpus all \
--shm-size 64g \
--ipc=host \
--cap-add SYS_NICE \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e HF_TOKEN="$HF_TOKEN" \
-e PYTORCH_ALLOC_CONF=expandable_segments:True \
lmsysorg/sglang:dev-mistral-medium-3.5 \
sglang serve \
--model-path mistralai/Mistral-Medium-3.5-128B \
--served-model-name mistral-medium-3.5-eagle \
--host 0.0.0.0 \
--port 30000 \
--tp 4 \
--trust-remote-code \
--dtype bfloat16 \
--context-length 100000 \
--mem-fraction-static 0.85 \
--disable-custom-all-reduce \
--tool-call-parser mistral \
--reasoning-parser mistral \
--enable-metrics \
--speculative-algorithm EAGLE \
--speculative-draft-model-path mistralai/Mistral-Medium-3.5-128B-EAGLE \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4SGLang이 권장하는 EAGLE 기본 설정은 --speculative-num-steps 3, --speculative-eagle-topk 1, --speculative-num-draft-tokens 4입니다. 첫 실행은 EAGLE 드래프트 모델도 다운로드하므로 더 오래 걸릴 수 있습니다.
로딩이 완료되면 nvidia-smi로 GPU 사용량을 확인하세요. 제 실행에서는 GPU당 약 44GB를 사용했습니다.
로그 모니터링은 다음으로 합니다:
docker logs -f mistral-sglang-eagle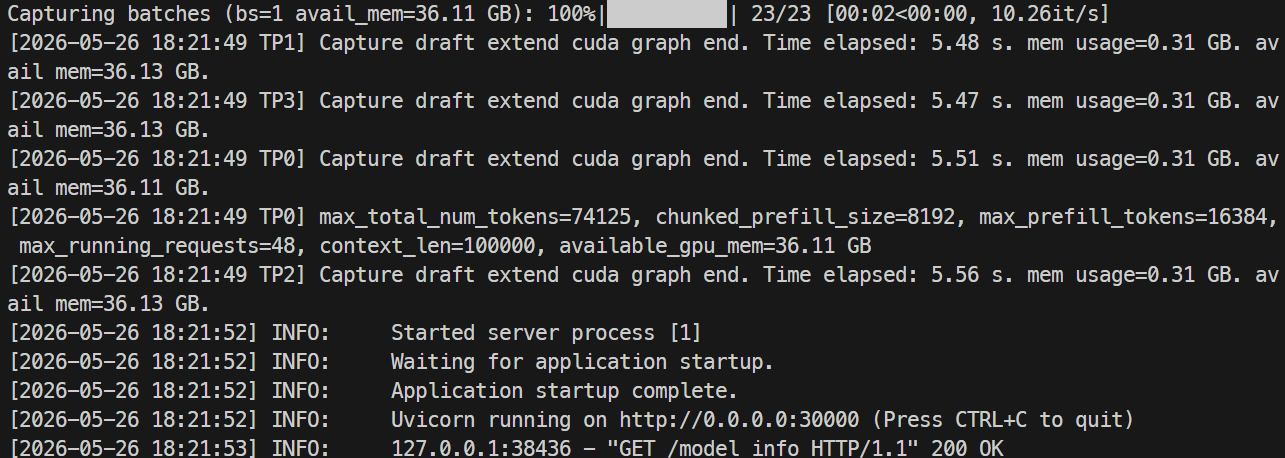
로그에 0.0.0.0:30000에서 Uvicorn 실행 중이라고 표시되면 엔드포인트를 테스트합니다:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mistral-medium-3.5-eagle",
"messages": [
{
"role": "user",
"content": "Generate a simple Python game."
}
],
"reasoning_effort": "none",
"max_tokens": 300,
"temperature": 0.7,
"top_p": 0.95
}'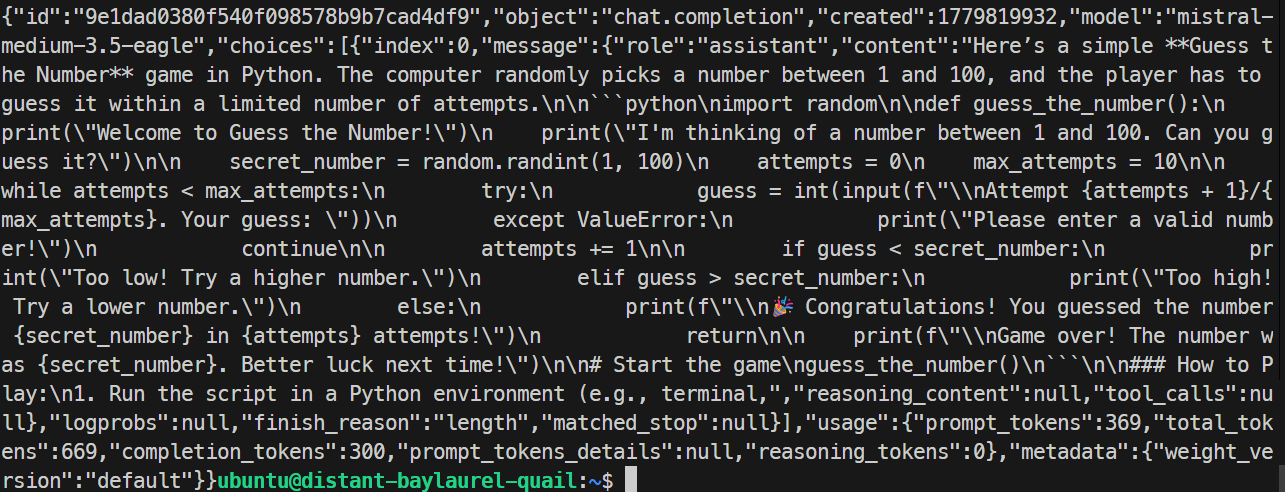
테스트에서 EAGLE 서버는 정상적으로 응답했고 간단한 Python 게임을 생성했습니다. 성능은 초당 약 32 토큰으로 기본 실행보다 약간 느렸고, 이 테스트에서는 EAGLE이 향상을 보이지 않았습니다.
이는 정상적인 결과입니다. 추론 가속의 효과는 워크로드에 크게 좌우되며, 자체 프롬프트와 동시성 수준으로 직접 판단하는 것이 가장 좋습니다.
OpenCode는 OpenAI 호환 모델 엔드포인트에 연결할 수 있는 오픈 소스 AI 코딩 에이전트입니다. SGLang은 Mistral Medium 3.5를 로컬 OpenAI 호환 API로 노출하므로, OpenCode에서 바로 사용할 수 있습니다.
아직 설치하지 않았다면 OpenCode를 설치하세요:
curl -fsSL https://opencode.ai/install | bash그런 다음 프로젝트 디렉터리로 이동해 opencode.json 파일을 만듭니다.
다음 구성을 추가합니다.
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"sglang": {
"npm": "@ai-sdk/openai-compatible",
"name": "SGLang Local",
"options": {
"baseURL": "http://127.0.0.1:30000/v1",
"apiKey": "EMPTY"
},
"models": {
"mistral-medium-3.5-eagle": {
"name": "Mistral Medium 3.5 EAGLE",
"limit": {
"context": 100000,
"output": 8192
}
}
}
}
},
"model": "sglang/mistral-medium-3.5-eagle"
}이제 같은 프로젝트 디렉터리에서 OpenCode를 실행합니다.
OpencodeOpenCode 내에서 Mistral Medium 3.5 EAGLE SGLang Local이 선택된 것을 확인할 수 있어야 합니다. 이는 OpenCode가 전달된 30000 포트를 통해 로컬 SGLang 서버와 통신한다는 뜻으로, 일반적인 OpenAI 호환 API 호출과 동일하게 동작합니다.
테스트에서는 OpenCode에 프로젝트 설명을 요청했고, 몇 초 안에 리포지토리 파일을 읽고 요약을 생성했습니다.
이어 Badger 2040 에뮬레이터 생성을 요청했고, 기존 프로젝트 파일을 먼저 점검하고 구조를 검증한 뒤 필요한 Python 파일을 만들었습니다. 전체 과정은 약 2분이 걸렸습니다.
그다음 로컬에서 에뮬레이터를 테스트하도록 요청했고, OpenCode가 코드를 실행해 에뮬레이터 창을 성공적으로 열었습니다.
폰트는 실제 Badger 2040 디스플레이와 완전히 일치하진 않았지만, 레이아웃, 시간/날짜 배치, 전체 구조는 매우 유사했습니다.

결과는 상당히 놀라웠습니다. 같은 작업을 Claude Code와 GPT-5.5로 시도했을 때는 둘 다 어려움을 겪었지만, Mistral Medium 3.5는 로컬 SGLang 설정을 통해 훨씬 수월하게 처리했습니다.
진행 중 주의할 점이 몇 가지 있습니다. 겪을 수 있는 문제와 해결 방법을 안내합니다.
무엇보다도 인내심이 필요합니다. 전체 설정에는 거의 3시간이 걸렸습니다. GPU VM 시작에 약 15분, Docker와 NVIDIA 컨테이너 툴킷 설치에 약 10분, SGLang Docker 이미지 풀에 약 30분, Mistral Medium 3.5 모델 가중치 다운로드 및 로딩에 약 1시간이 소요되었습니다.
EAGLE 설정도 모델을 다시 로드하고 EAGLE 드래프트 모델을 다운로드할 수 있어 추가 시간이 듭니다. 더 원활히 진행하려면 빠른 네트워크, 가능하면 H200 등 최신 GPU, 충분한 Hugging Face 캐시 저장 공간을 확보하세요.
호스트에서는 nvidia-smi가 동작하는데 Docker에서 GPU에 접근하지 못한다면 NVIDIA 컨테이너 런타임 구성이 올바르지 않을 수 있습니다. NVIDIA 컨테이너 툴킷 구성을 다시 수행하고 Docker를 재시작하세요:
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart dockerNVIDIA 문서에서도 Docker의 GPU 접근을 위해 이 nvidia-ctk 런타임 구성 단계를 권장합니다.
Hugging Face 캐시가 컨테이너에 마운트되었는지 확인하세요:
-v ~/.cache/huggingface:/root/.cache/huggingface이렇게 하면 다운로드된 모델 파일을 재사용해 매번 다시 받지 않아도 됩니다. Hugging Face는 로컬 캐시를 사용해 최신 파일을 재다운로드하지 않도록 합니다.
Mistral Medium 3.5 리포지토리는 용량이 큰 편이라 첫 다운로드에 시간이 많이 걸릴 수 있습니다. 멈춘 것 같다면 인터넷 속도, 디스크 용량, Hugging Face 토큰을 확인하세요. 또한 컨테이너 실행 전에 Hugging Face에서 필요한 모델 접근 약관에 동의했는지도 확인하세요.
로그에 Uvicorn이 포트 30000에서 실행 중이라고 표시되기 전까지 서버는 준비되지 않습니다. 다음으로 로그를 확인하세요:
docker logs -f mistral-sglangEAGLE의 경우:
docker logs -f mistral-sglang-eagle또한 컨테이너가 포트를 올바르게 노출하는지 확인하세요:
-p 30000:30000정상적입니다. 추론 가속은 모든 요청에서 개선을 보장하지 않습니다. 드래프트 모델이 토큰을 제안하고 메인 모델이 검증하는 구조이므로, 속도 향상은 수용률, 프롬프트 길이, 출력 길이, 동시성, GPU 활용도에 좌우됩니다.
메모리 문제가 발생하면 먼저 컨텍스트 길이를 줄이세요. 예를 들어, 처음부터 전체 컨텍스트 윈도우를 시도하기보다 --context-length 100000으로 시작합니다. 시작이 실패한다면 --mem-fraction-static을 약간 낮출 수도 있지만, 보통은 컨텍스트 길이를 줄이는 것이 가장 쉬운 해결책입니다.
SGLang 서버가 실행 중인지, opencode.json이 올바른 로컬 엔드포인트를 사용하는지 확인하세요:
"baseURL": "http://127.0.0.1:30000/v1"로컬 머신에서 서버에 접근 중이라면 포트 포워딩을 사용해 SSH를 시작하세요:
ssh -L 30000:localhost:30000 ubuntu@XXXXXX그런 다음 opencode.json 파일이 저장된 동일한 디렉터리에서 OpenCode를 실행하세요.
기술적 설정 과정이 예상보다 훨씬 매끄러워 솔직히 놀랐습니다. SGLang의 네이티브 Docker 이미지를 사용해 Mistral Medium 3.5 128B를 실행하는 일은 생각보다 훨씬 쉬웠습니다. Docker 이미지는 정상적으로 받아졌고, 모델이 로드되었으며, OpenAI 호환 엔드포인트가 동작했고, OpenCode도 큰 어려움 없이 연결되었습니다. I
직접 시도한다면 Python 패키지로 모든 것을 설치하는 대신 SGLang Docker 이미지를 사용할 것을 강력히 권합니다. Python 경로로 설치하면 CUDA, PyTorch 및 기타 의존성과 충돌이 생기기 쉽습니다. Docker는 모든 것을 깔끔하고 격리된 상태로 유지해 줍니다.
하지만 이 실험에서 가장 크게 느낀 점은 비용이었습니다. 솔직히 말해 AI 기업들이 추론으로 어떻게 수익을 내는지 모르겠습니다. 비교적 저렴하고 구형인 H100 PCIe 옵션 중 하나를 사용했음에도 시간당 비용이 약 $10에 달했습니다. 게다가 이는 4개 GPU에서 128B 모델을 돌린 경우입니다. 16대 H100에서 조 단위 파라미터 모델을 돌린다고 상상해 보세요. 스토리지, 네트워킹, 모니터링, 가용성, 엔지니어링 작업을 고려하기 전에도 시간당 $40+까지 쉽게 올라갈 수 있습니다.
소규모 기업이 특수한 이유(예: 프라이버시, 연구, 추론 스택에 대한 깊은 통제)가 있지 않은 한, 이런 방식으로 로컬에서 모델을 서빙하는 것은 합리적이지 않다고 봅니다. 추론 비용이 이미 높은 데다 운영 부담도 큽니다. 서버를 계속 가동하고, 모델이 크래시하지 않도록 관리하며, GPU 메모리를 모니터링하고, 실패한 컨테이너를 처리하고, 엔드포인트 가용성을 유지해야 합니다.
서버리스도 초대형 모델에는 실질적인 해결책이 되지 못합니다. 콜드 스타트가 지나치게 길기 때문입니다. 이번 설정에서 GPU VM 가동, 의존성 설치, Docker 이미지 풀, 가중치 다운로드, 모델 로딩까지 합쳐 거의 3시간이 걸렸습니다.
설정이 더 빠르더라도 이 크기의 모델을 로드하는 데는 여전히 많은 시간이 듭니다. 매 요청마다 새로운 GPU 클러스터를 띄우고 모델을 다시 로드해야 한다면 서버리스의 장점이 사라집니다. 실제로는 기업이 워밍된 GPU 클러스터를 유지해야 하고, 이는 GPU가 유휴 상태일 때도 비용을 지불한다는 뜻입니다.
이 때문에 비혼잡 시간대 GPU 가격이 존재합니다. 제공자는 유휴 GPU 용량이 비용만 초래하므로 이를 사용하게 하려 합니다. 사용자 입장에서는 더 저렴하게 실험할 수 있는 방법이지만, 대형 모델 추론의 경제성이 얼마나 어렵운지 보여주기도 합니다.
전반적으로, 이번 설정에서 SGLang이 매우 마음에 들었습니다. Docker 기반 워크플로 덕분에 Mistral Medium 3.5 128B 서빙이 예상보다 훨씬 쉬웠고, OpenCode 테스트도 인상적이었습니다. 하지만 이 실험이 분명히 보여준 건 하나입니다. 대형 오픈 모델을 로컬에서 돌리는 것은 가능하지만, 이를 실제 제품으로 안정적이고 합리적 비용으로 운영하는 일은 전혀 다른 도전이라는 점입니다.
DataCamp으로 AI를 배워보세요!
tracks
courses
courses