
Program
Insinyur Kecerdasan Buatan (AI) untuk Pengembang
26 Hr
Untuk panduan ini, saya menggunakan mesin virtual GPU 4× H100 80GB. Mistral Medium 3.5 adalah model dense 128B, jadi membutuhkan penyiapan multi-GPU. SGLang merekomendasikan menjalankannya dengan paralelisme tensor menggunakan --tp 4 pada GPU H100 atau H200. Model ini mendukung jendela konteks besar, tetapi saya sarankan memulai dengan 100.000 token terlebih dahulu alih-alih konteks penuh 256K untuk memudahkan pengujian dan debug.
Saya menggunakan Hyperbolic karena menyediakan akses ke VM GPU penuh, yang memudahkan memasang Docker, mengonfigurasi runtime kontainer NVIDIA, dan menjalankan image Docker SGLang secara manual. Anda juga bisa menggunakan platform seperti RunPod atau Vast.ai, tetapi beberapa instance mereka sudah terikat pada lingkungan Docker khusus, sehingga kontrol Anda lebih terbatas.
Di Hyperbolic, pilih H100 PCIe 80GB, pilih 4 GPU, tambahkan sekitar 3TB penyimpanan, masukkan kunci publik SSH Anda, dan beri nama instance seperti MM-35. Saya memilih H100 PCIe karena merupakan opsi H100 termurah yang tersedia untuk pengujian ini.
Setelah mengeklik Start Building, mesin mungkin membutuhkan sekitar 10 menit untuk mulai. Setelah siap, Hyperbolic akan menampilkan perintah akses SSH yang Anda perlukan untuk langkah berikutnya.
Setelah instance siap, sambungkan dari terminal lokal Anda menggunakan perintah SSH yang ditampilkan di dasbor Hyperbolic:
ssh ubuntu@XXXXXXUntuk mengakses API SGLang dari mesin lokal nanti, Anda juga bisa meneruskan port 30000:
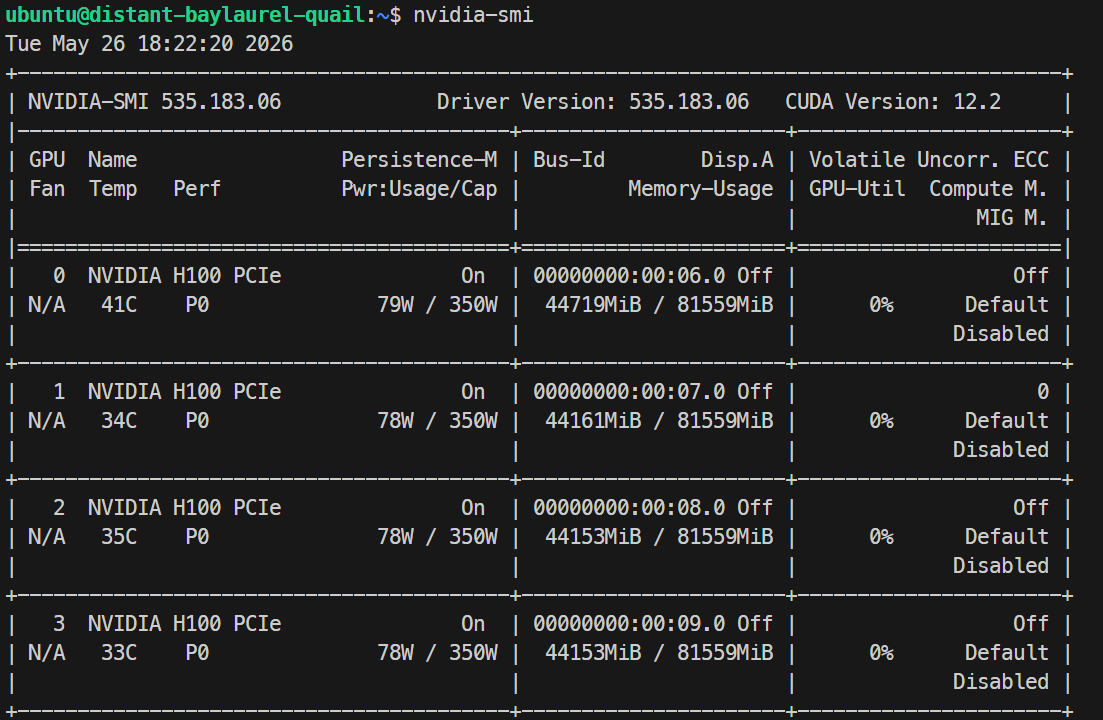
ssh -L 30000:localhost:30000 ubuntu@XXXXXXJika kunci SSH Anda memiliki frasa sandi, masukkan saat diminta. Setelah masuk, periksa semua GPU tersedia:
Nvidia-smiAnda seharusnya melihat 4× GPU NVIDIA H100 PCIe 80GB terdaftar. Ini mengonfirmasi bahwa server siap untuk penyiapan Docker dan SGLang.
Pertama, ekspor token Hugging Face Anda agar server dapat mengunduh model Mistral nanti:
echo 'export HF_TOKEN="your_huggingface_token_here"' >> ~/.bashrc
source ~/.bashrcCatatan: Anda bisa mendapatkan token Hugging Face dari halaman Access Tokens.
Buat folder cache Hugging Face:
mkdir -p ~/.cache/huggingfaceSekarang pasang Docker:
sudo apt update
sudo apt install -y docker.ioMulai Docker dan aktifkan agar berjalan otomatis setelah reboot:
sudo systemctl start docker
sudo systemctl enable dockerPeriksa bahwa Docker sudah terpasang dengan benar:
docker –versionAnda juga dapat menggunakan perintah pencarian Docker untuk memastikan Docker dapat mencari image publik dari Docker Hub:
docker search nvidia/cudaIni akan menampilkan image NVIDIA CUDA yang tersedia. Nanti, kita akan menggunakan salah satu image CUDA ini untuk memverifikasi bahwa Docker dapat mengakses GPU.
Selanjutnya, izinkan pengguna Anda menjalankan perintah Docker tanpa sudo:
sudo usermod -aG docker $USER
newgrp dockerSekarang pasang dan konfigurasikan NVIDIA Container Toolkit agar Docker dapat mengakses GPU:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/libnvidia-container/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt update
sudo apt install -y nvidia-container-toolkit
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart dockerTerakhir, uji bahwa Docker dapat melihat GPU dari dalam kontainer:
docker run --rm --gpus all nvidia/cuda:12.4.1-base-ubuntu22.04 nvidia-smiJika ini menampilkan daftar GPU H100 yang sama di dalam kontainer Docker, penyiapan Docker GPU Anda berfungsi dengan benar.
Selanjutnya, tarik image Docker SGLang yang dibangun untuk Mistral Medium 3.5:
docker pull lmsysorg/sglang:dev-mistral-medium-3.5
Ini mungkin membutuhkan waktu, tergantung kecepatan internet Anda. Dalam kasus saya, sekitar 10 menit. Setelah image diunduh, Docker akan menampilkan pesan sukses seperti:
Status: Downloaded newer image for lmsysorg/sglang:dev-mistral-medium-3.5Sekarang mulai server SGLang:
docker run -d \
--name mistral-sglang \
--gpus all \
--shm-size 64g \
--ipc=host \
--cap-add SYS_NICE \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e HF_TOKEN=$HF_TOKEN \
-e PYTORCH_ALLOC_CONF=expandable_segments:True \
lmsysorg/sglang:dev-mistral-medium-3.5 \
sglang serve \
--model-path mistralai/Mistral-Medium-3.5-128B \
--served-model-name mistral-medium-3.5 \
--host 0.0.0.0 \
--port 30000 \
--tp 4 \
--trust-remote-code \
--dtype bfloat16 \
--context-length 100000 \
--mem-fraction-static 0.85 \
--disable-custom-all-reduce \
--tool-call-parser mistral \
--reasoning-parser mistralSaya menggunakan --dtype bfloat16 karena penyiapan EAGLE nanti juga memerlukan bf16, sehingga menjaga keselarasan antara run dasar dan run spekulatif menghindari perubahan dtype di antara pengujian. Saya juga mulai dengan --context-length 100000 alih-alih jendela konteks penuh untuk memudahkan debug pada run pertama.
Periksa log kontainer dengan:
docker logs -f mistral-sglang
Peluncuran pertama akan memakan waktu lebih lama karena SGLang perlu mengunduh berkas model dari Hugging Face. Repositori penuh berukuran besar, jadi ini bisa memakan waktu sekitar satu jam atau lebih, tergantung kecepatan instance Anda.
Saat server siap, log akan menunjukkan bahwa Uvicorn berjalan pada port 30000.
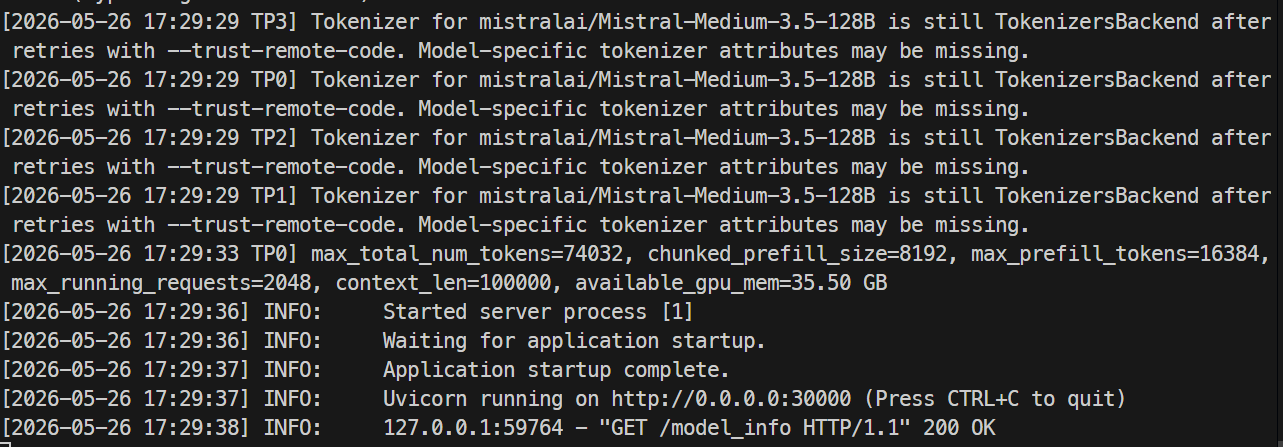
Di terminal lain, SSH lagi ke server dan periksa endpoint model:
curl http://localhost:30000/v1/modelsAnda akan melihat mistral-medium-3.5 terdaftar dengan max_model_len sebesar 100000.
{"object":"list","data":[{"id":"mistral-medium-3.5","object":"model","created":1779816738,"owned_by":"sglang","root":"mistral-medium-3.5","parent":null,"max_model_len":100000}]}Terakhir, uji chat completion:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mistral-medium-3.5",
"messages": [
{
"role": "user",
"content": "Write a short introduction to Mistral Medium 3.5."
}
],
"max_tokens": 300,
"temperature": 0.7,
"top_p": 0.95
}'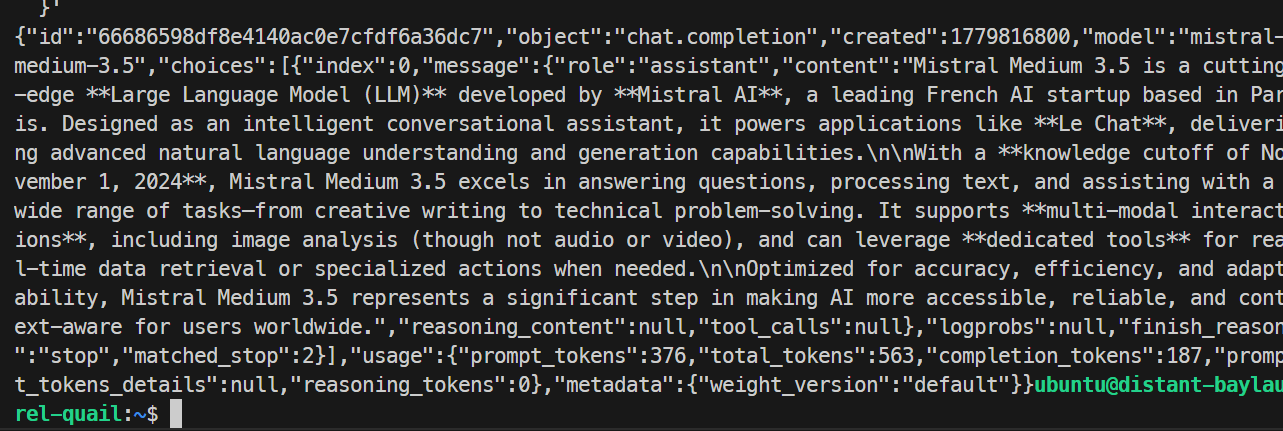
Dalam pengujian saya, model merespons dengan sukses dan menyelesaikan permintaan dengan bersih, mengonfirmasi bahwa endpoint SGLang berfungsi. Run dasar menghasilkan sekitar 35,6 token per detik.
Decoding spekulatif dapat mempercepat generasi dengan menggunakan model draf yang lebih kecil untuk memprediksi token lebih awal, sementara model utama memverifikasinya.
EAGLE berguna di sini karena dirancang untuk penyajian yang sensitif terhadap latensi, terutama saat Anda menjalankan model besar seperti Mistral Medium 3.5 secara lokal. Ini tidak selalu lebih cepat, tetapi layak diuji karena manfaatnya bergantung pada panjang prompt, panjang output, konkurensi, dan penggunaan GPU.
Pertama, hapus kontainer dasar:
docker rm -f mistral-sglangLalu jalankan versi EAGLE:
docker run -d \
--name mistral-sglang-eagle \
--gpus all \
--shm-size 64g \
--ipc=host \
--cap-add SYS_NICE \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e HF_TOKEN="$HF_TOKEN" \
-e PYTORCH_ALLOC_CONF=expandable_segments:True \
lmsysorg/sglang:dev-mistral-medium-3.5 \
sglang serve \
--model-path mistralai/Mistral-Medium-3.5-128B \
--served-model-name mistral-medium-3.5-eagle \
--host 0.0.0.0 \
--port 30000 \
--tp 4 \
--trust-remote-code \
--dtype bfloat16 \
--context-length 100000 \
--mem-fraction-static 0.85 \
--disable-custom-all-reduce \
--tool-call-parser mistral \
--reasoning-parser mistral \
--enable-metrics \
--speculative-algorithm EAGLE \
--speculative-draft-model-path mistralai/Mistral-Medium-3.5-128B-EAGLE \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4SGLang merekomendasikan penyiapan EAGLE ini sebagai titik awal yang baik: --speculative-num-steps 3, --speculative-eagle-topk 1, dan --speculative-num-draft-tokens 4. Run pertama mungkin lebih lama karena juga mengunduh model draf EAGLE.
Setelah dimuat, Anda dapat memeriksa penggunaan GPU dengan nvidia-smi; pada run saya, model menggunakan sekitar 44GB per GPU H100.
Pantau log dengan:
docker logs -f mistral-sglang-eagle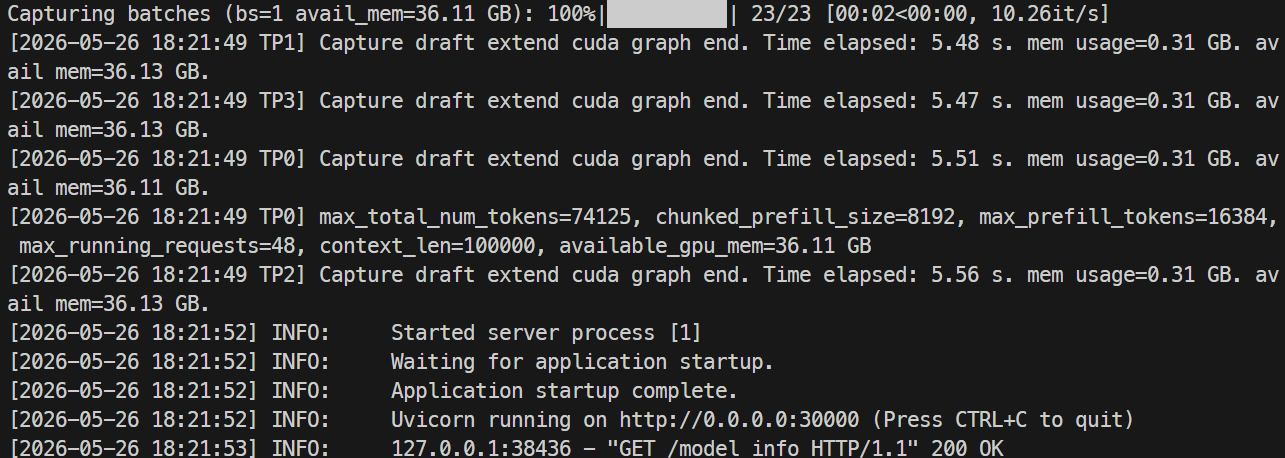
Saat log menunjukkan Uvicorn berjalan pada 0.0.0.0:30000, uji endpoint:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mistral-medium-3.5-eagle",
"messages": [
{
"role": "user",
"content": "Generate a simple Python game."
}
],
"reasoning_effort": "none",
"max_tokens": 300,
"temperature": 0.7,
"top_p": 0.95
}'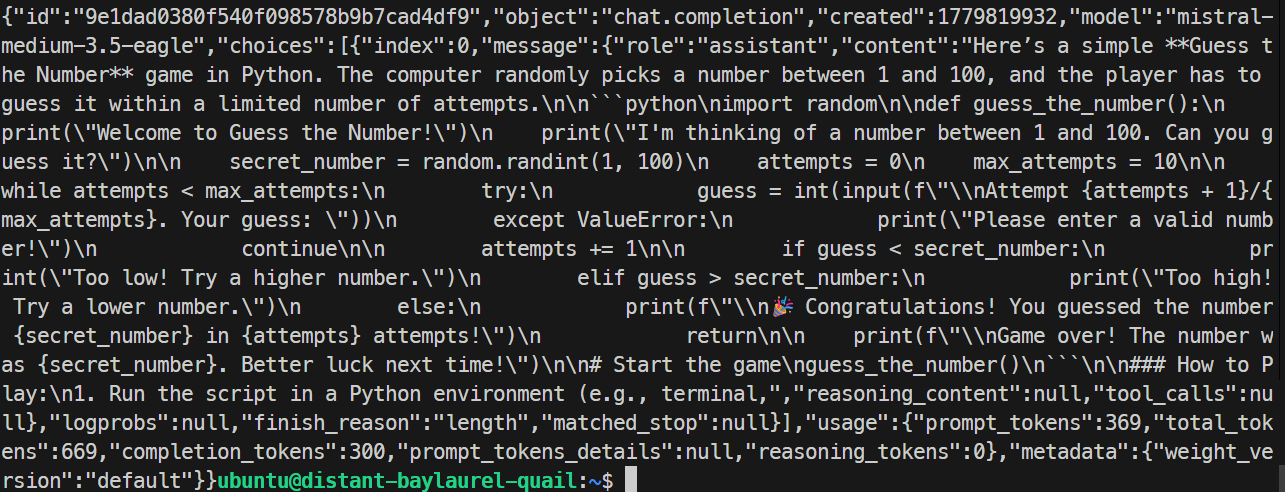
Dalam pengujian saya, server EAGLE merespons dengan benar dan menghasilkan gim Python sederhana. Run ini mencapai sekitar 32 token per detik, sedikit lebih lambat daripada run dasar, jadi EAGLE tidak meningkatkan pengujian spesifik ini.
Ini normal: decoding spekulatif sangat bergantung pada beban kerja, dan cara terbaik menilainya adalah mengujinya dengan prompt dan tingkat konkurensi Anda sendiri.
OpenCode adalah agen pengkodean AI open-source yang dapat terhubung ke endpoint model yang kompatibel dengan OpenAI. Karena SGLang mengekspos Mistral Medium 3.5 melalui API lokal yang kompatibel dengan OpenAI, kita dapat menggunakannya langsung di dalam OpenCode.
Pasang OpenCode jika Anda belum melakukannya:
curl -fsSL https://opencode.ai/install | bashLalu masuk ke direktori proyek Anda dan buat berkas opencode.json.
Tambahkan konfigurasi berikut:
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"sglang": {
"npm": "@ai-sdk/openai-compatible",
"name": "SGLang Local",
"options": {
"baseURL": "http://127.0.0.1:30000/v1",
"apiKey": "EMPTY"
},
"models": {
"mistral-medium-3.5-eagle": {
"name": "Mistral Medium 3.5 EAGLE",
"limit": {
"context": 100000,
"output": 8192
}
}
}
}
},
"model": "sglang/mistral-medium-3.5-eagle"
}Sekarang jalankan OpenCode dari direktori proyek yang sama:
OpencodeAnda akan melihat Mistral Medium 3.5 EAGLE SGLang Local terpilih di dalam OpenCode. Ini berarti OpenCode sekarang berkomunikasi dengan server SGLang lokal Anda melalui port 30000 yang diteruskan, sama seperti saat memanggil API yang kompatibel dengan OpenAI mana pun.
Dalam pengujian saya, saya meminta OpenCode untuk menjelaskan proyek, dan ia membaca berkas repositori dalam beberapa detik dan menghasilkan ringkasannya.
Kemudian, saya memintanya membuat emulator Badger 2040, dan ia terlebih dahulu memeriksa berkas proyek yang ada, memvalidasi struktur, lalu membuat berkas Python yang diperlukan. Seluruh proses memakan waktu sekitar 2 menit.
Setelah itu, saya memintanya menguji emulator secara lokal. OpenCode menjalankan kode dan membuka jendela emulator dengan sukses.
Font-nya tidak persis sama dengan tampilan Badger 2040 asli, tetapi tata letak, tampilan waktu, penempatan tanggal, dan struktur keseluruhan hampir sempurna.

Saya benar-benar terkejut dengan hasilnya karena saya telah mencoba tugas yang sama dengan Claude Code dan GPT-5.5 sebelumnya, dan keduanya kesulitan, sementara Mistral Medium 3.5 menanganinya dengan sangat baik melalui penyiapan SGLang lokal.
Ada beberapa kendala di sepanjang jalan. Izinkan saya menjelaskan masalah yang mungkin Anda temui dan cara mengatasinya.
Pertama-tama, Anda perlu bersabar. Penyiapan penuh ini memakan waktu hampir 3 jam. Meluncurkan VM GPU sekitar 15 menit, memasang Docker dan toolkit kontainer NVIDIA sekitar 10 menit, menarik image Docker SGLang sekitar 30 menit, dan mengunduh serta memuat bobot model Mistral Medium 3.5 sekitar 1 jam.
Memulai penyiapan EAGLE juga memakan waktu ekstra karena memuat model lagi dan mungkin mengunduh model draf EAGLE. Jika Anda ingin pengalaman yang lebih mulus, gunakan jaringan yang lebih cepat, GPU yang lebih baru seperti H200 jika tersedia, dan penyimpanan yang cukup untuk cache Hugging Face penuh.
Jika nvidia-smi berfungsi di host tetapi Docker tidak dapat mengakses GPU, kemungkinan runtime kontainer NVIDIA belum dikonfigurasi dengan benar. Jalankan kembali konfigurasi toolkit kontainer NVIDIA dan mulai ulang Docker:
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart dockerDokumentasi NVIDIA juga merekomendasikan langkah konfigurasi runtime nvidia-ctk ini untuk akses GPU Docker.
Pastikan cache Hugging Face di-mount ke dalam kontainer:
-v ~/.cache/huggingface:/root/.cache/huggingfaceIni memungkinkan Docker menggunakan kembali berkas model yang sudah diunduh alih-alih mengunduhnya lagi setiap kali. Hugging Face menggunakan cache lokal untuk menghindari pengunduhan ulang berkas yang sudah mutakhir.
Repositori Mistral Medium 3.5 berukuran besar, jadi unduhan pertama bisa memakan waktu lama. Jika terlihat macet, periksa kecepatan internet, ruang disk, dan token Hugging Face Anda. Pastikan juga Anda telah menerima syarat akses model yang diperlukan di Hugging Face sebelum menjalankan kontainer.
Server belum siap hingga log menunjukkan bahwa Uvicorn berjalan pada port 30000. Periksa log dengan:
docker logs -f mistral-sglangatau untuk EAGLE:
docker logs -f mistral-sglang-eaglePastikan juga kontainer mengekspos port dengan benar menggunakan:
-p 30000:30000Ini normal. Decoding spekulatif tidak dijamin meningkatkan setiap permintaan. Mekanismenya menggunakan model draf untuk mengusulkan token dan model utama untuk memverifikasinya, tetapi percepatan bergantung pada tingkat penerimaan, panjang prompt, panjang output, konkurensi, dan pemanfaatan GPU.
Jika Anda menemui masalah memori, kurangi panjang konteks terlebih dahulu. Misalnya, mulailah dengan --context-length 100000 alih-alih langsung mencoba jendela konteks penuh. Anda juga dapat menurunkan --mem-fraction-static sedikit jika startup gagal, tetapi mengurangi panjang konteks biasanya langkah pertama yang paling mudah.
Pastikan server SGLang berjalan dan opencode.json Anda menggunakan endpoint lokal yang benar:
"baseURL": "http://127.0.0.1:30000/v1"Jika Anda mengakses server dari mesin lokal, mulai SSH dengan port forwarding:
ssh -L 30000:localhost:30000 ubuntu@XXXXXXLalu jalankan OpenCode dari direktori yang sama tempat berkas opencode.json Anda disimpan.
Saya benar-benar terkejut betapa mulusnya penyiapan teknisnya. Menjalankan Mistral Medium 3.5 128B dengan image Docker SGLang native jauh lebih mudah daripada yang saya perkirakan. Image Docker berhasil ditarik, model dimuat, endpoint yang kompatibel dengan OpenAI berfungsi, dan OpenCode terhubung tanpa banyak masalah. S
aya sangat menyarankan menggunakan image Docker SGLang alih-alih memasang semuanya melalui paket Python jika Anda mencoba ini sendiri. Saat memasang melalui Python, mudah terjadi kekacauan dengan CUDA, PyTorch, dan dependensi lainnya. Docker menjaga semuanya tetap bersih dan terisolasi.
Namun hal terbesar yang saya dapatkan dari eksperimen ini adalah biayanya. Saya jujur tidak tahu bagaimana perusahaan AI menghasilkan uang dari inferensi. Bahkan dengan salah satu opsi H100 PCIe yang lebih murah dan lebih lama, penyiapan ini masih mendekati $10 per jam. Dan ini hanya untuk model 128B pada 4 GPU. Sekarang bayangkan menjalankan model dengan triliunan parameter yang jauh lebih besar pada 16× H100. Tagihan Anda bisa dengan mudah mencapai $40+ per jam, sebelum memikirkan penyimpanan, jaringan, pemantauan, uptime, dan pekerjaan rekayasa.
Untuk perusahaan kecil, saya rasa tidak masuk akal menyajikan model seperti ini secara lokal kecuali ada alasan yang sangat kuat, seperti privasi, riset, atau kontrol mendalam atas tumpukan inferensi. Biaya inferensi sudah tinggi, tetapi beban operasional juga menjadi masalah. Anda perlu menjaga server tetap berjalan, memastikan model tidak crash, memantau memori GPU, menangani kontainer yang gagal, dan menjaga endpoint tetap tersedia.
Serverless juga tidak benar-benar menyelesaikan ini untuk model yang sangat besar. Cold start terlalu lama. Dalam penyiapan ini, meluncurkan VM GPU, memasang dependensi, menarik image Docker, mengunduh bobot, dan memuat model memakan waktu hampir 3 jam secara total.
Bahkan jika penyiapan Anda lebih cepat, memuat model sebesar ini tetap dapat memakan waktu lama. Jadi jika setiap permintaan baru memerlukan peluncuran klaster GPU lain dan memuat ulang model, itu mengalahkan tujuan serverless. Dalam praktiknya, perusahaan perlu menjaga klaster GPU tetap hangat, yang berarti mereka tetap membayar meski GPU menganggur.
Ini juga menjelaskan mengapa ada harga GPU off-peak. Penyedia ingin orang menggunakan kapasitas GPU yang menganggur karena GPU yang tidak digunakan hanya membakar uang. Bagi pengguna, itu bisa menjadi cara yang baik untuk bereksperimen dengan lebih murah, tetapi juga menunjukkan betapa rumitnya ekonomi inferensi model besar.
Secara keseluruhan, saya sangat menyukai SGLang untuk penyiapan ini. Alur kerja berbasis Docker membuat penyajian Mistral Medium 3.5 128B jauh lebih mudah daripada yang diharapkan, dan pengujian OpenCode benar-benar mengesankan. Namun eksperimen ini juga membuat satu hal sangat jelas bagi saya: menjalankan model open-source besar secara lokal itu mungkin, tetapi menjalankannya secara andal dan terjangkau sebagai produk nyata adalah tantangan yang benar-benar berbeda.
Belajar AI dengan DataCamp!
Program
Kursus
Kursus
blogs
Javier Canales Luna
14 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
David Woods
13 mnt
blogs
Dario Radečić
15 mnt
