
Program
Geliştiriciler için Yardımcı Yapay Zeka Mühendisi
26 sa
Bu rehber için 4× H100 80GB GPU’lu bir sanal makine kullandım. Mistral Medium 3.5 yoğun bir 128B model olduğundan çok GPU’lu bir kurulum gerektirir. SGLang, H100 veya H200 GPU’larda --tp 4 ile tensör paralelliği kullanarak çalıştırılmasını önerir. Model geniş bir bağlam penceresini destekler, ancak kurulumu test etmeyi ve hata ayıklamayı kolaylaştırmak için önce 100.000 token ile başlamanızı, tam 256K bağlam yerine, öneririm.
Ben Hyperbolic’i kullandım çünkü tam bir GPU VM’e erişim sağlıyor; bu da Docker kurmayı, NVIDIA konteyner çalışma zamanını yapılandırmayı ve SGLang Docker imajını elle çalıştırmayı kolaylaştırıyor. RunPod veya Vast.ai gibi platformları da kullanabilirsiniz, ancak bazılarının örnekleri özel Docker ortamlarına bağlanmış durumdadır; bu da size daha az kontrol sağlar.
Hyperbolic’te, H100 PCIe 80GB’yi seçin, 4 GPU tercih edin, yaklaşık 3 TB depolama ekleyin, SSH ortak anahtarınızı girin ve örneğe MM-35 gibi bir ad verin. Bu test için en ucuz mevcut H100 seçeneği olduğu için H100 PCIe’yi seçtim.
Start Building’e tıkladıktan sonra makinenin başlaması yaklaşık 10 dakika sürebilir. Hazır olduğunda, Hyperbolic bir sonraki adım için gereken SSH erişim komutunu gösterecektir.
Örnek hazır olduğunda, Hyperbolic panosunda gösterilen SSH komutunu kullanarak yerel terminalinizden bağlanın:
ssh ubuntu@XXXXXXDaha sonra yerel makinenizden SGLang API’sine erişmek için 30000 numaralı bağlantı noktasını da iletebilirsiniz:
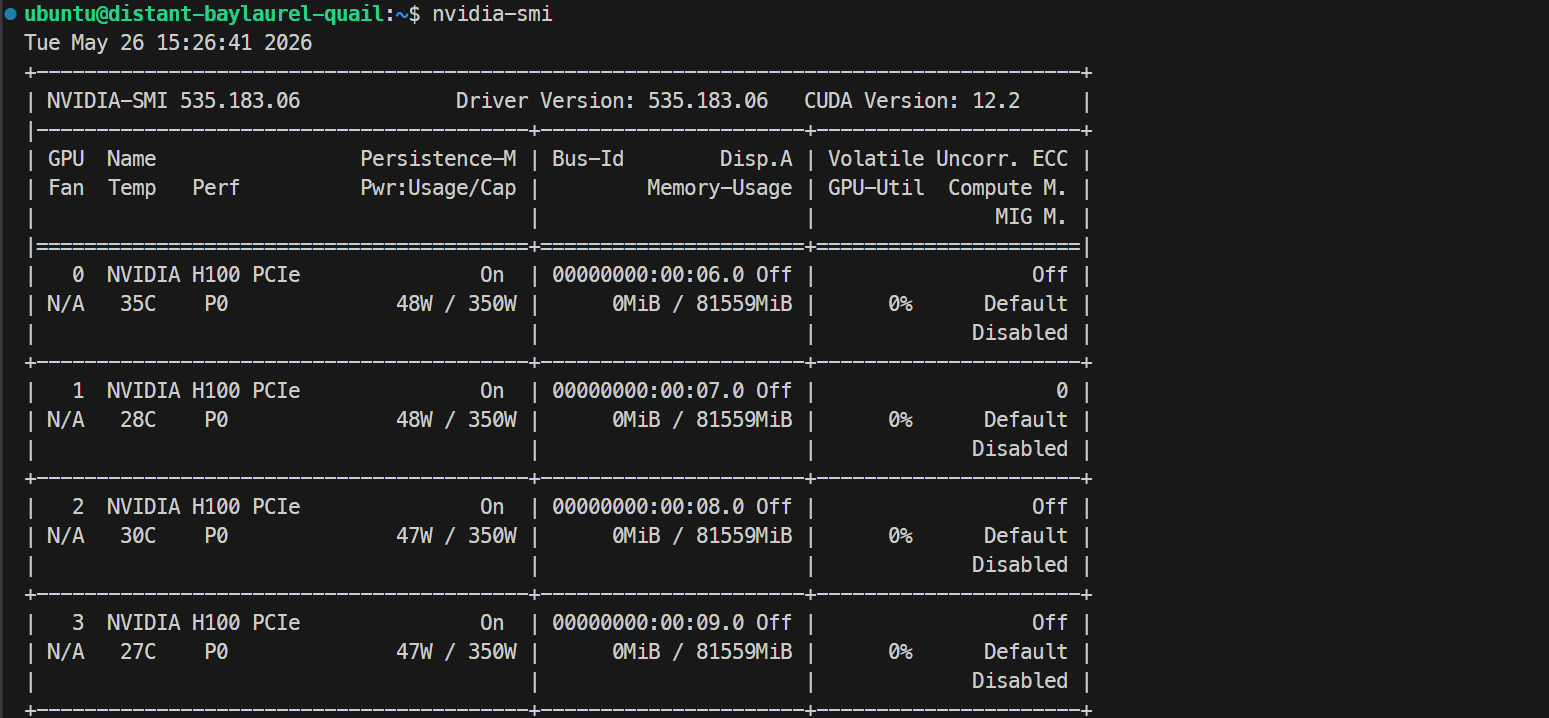
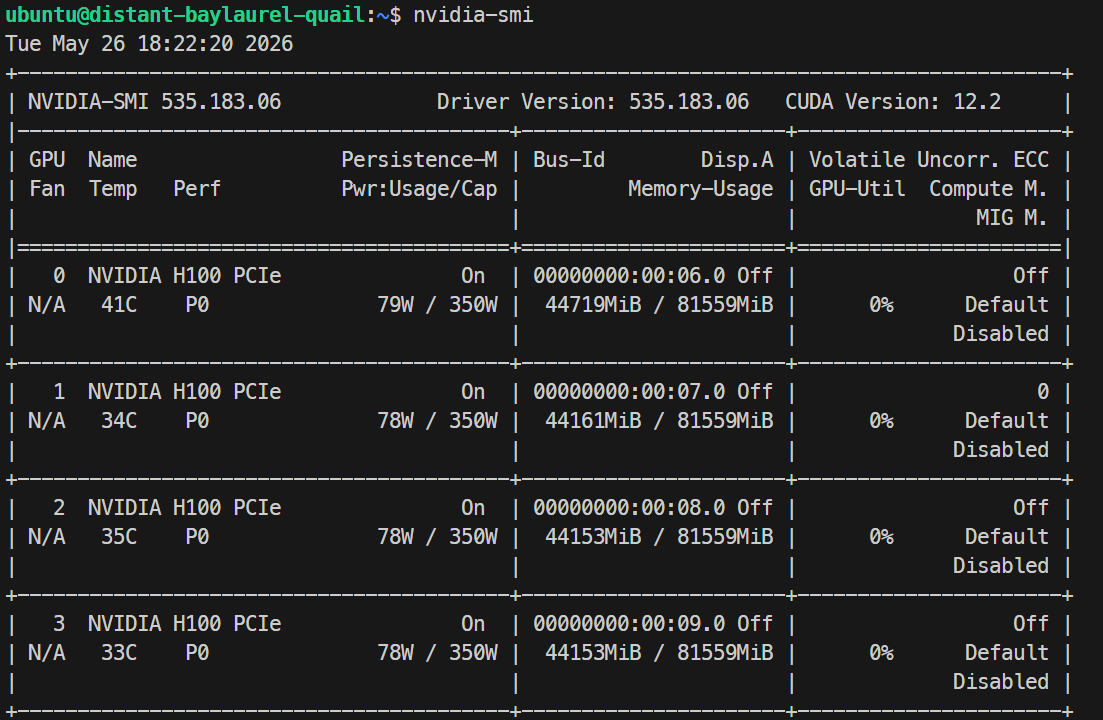
ssh -L 30000:localhost:30000 ubuntu@XXXXXXSSH anahtarınızın bir parola öbeği varsa, istenildiğinde girin. Oturum açtıktan sonra tüm GPU’ların kullanılabilir olduğunu kontrol edin:
Nvidia-smiListede 4× NVIDIA H100 PCIe 80GB GPU görmelisiniz. Bu, sunucunun Docker ve SGLang kurulumu için hazır olduğunu doğrular.
Önce Hugging Face belirtecinizi dışa aktarın; böylece sunucu daha sonra Mistral modelini indirebilsin:
echo 'export HF_TOKEN="your_huggingface_token_here"' >> ~/.bashrc
source ~/.bashrcNot: Hugging Face belirtecinizi Access Tokens sayfasından alabilirsiniz.
Hugging Face önbellek klasörünü oluşturun:
mkdir -p ~/.cache/huggingfaceŞimdi Docker’ı kurun:
sudo apt update
sudo apt install -y docker.ioDocker’ı başlatın ve yeniden başlatma sonrası otomatik çalışacak şekilde etkinleştirin:
sudo systemctl start docker
sudo systemctl enable dockerDocker’ın doğru kurulduğunu kontrol edin:
docker –versionDocker Hub’dan genel imajları arayabildiğini doğrulamak için Docker arama komutunu da kullanabilirsiniz:
docker search nvidia/cudaBu komut, mevcut NVIDIA CUDA imajlarını döndürmelidir. Daha sonra, Docker’ın GPU’lara erişebildiğini doğrulamak için bu CUDA imajlarından birini kullanacağız.
Sonraki adımda, sudo olmadan Docker komutları çalıştırabilmeniz için kullanıcınıza izin verin:
sudo usermod -aG docker $USER
newgrp dockerŞimdi Docker’ın GPU’lara erişebilmesi için NVIDIA Container Toolkit’i kurup yapılandırın:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/libnvidia-container/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt update
sudo apt install -y nvidia-container-toolkit
sudo nvidia-ctk runtime configure --runtime=docker
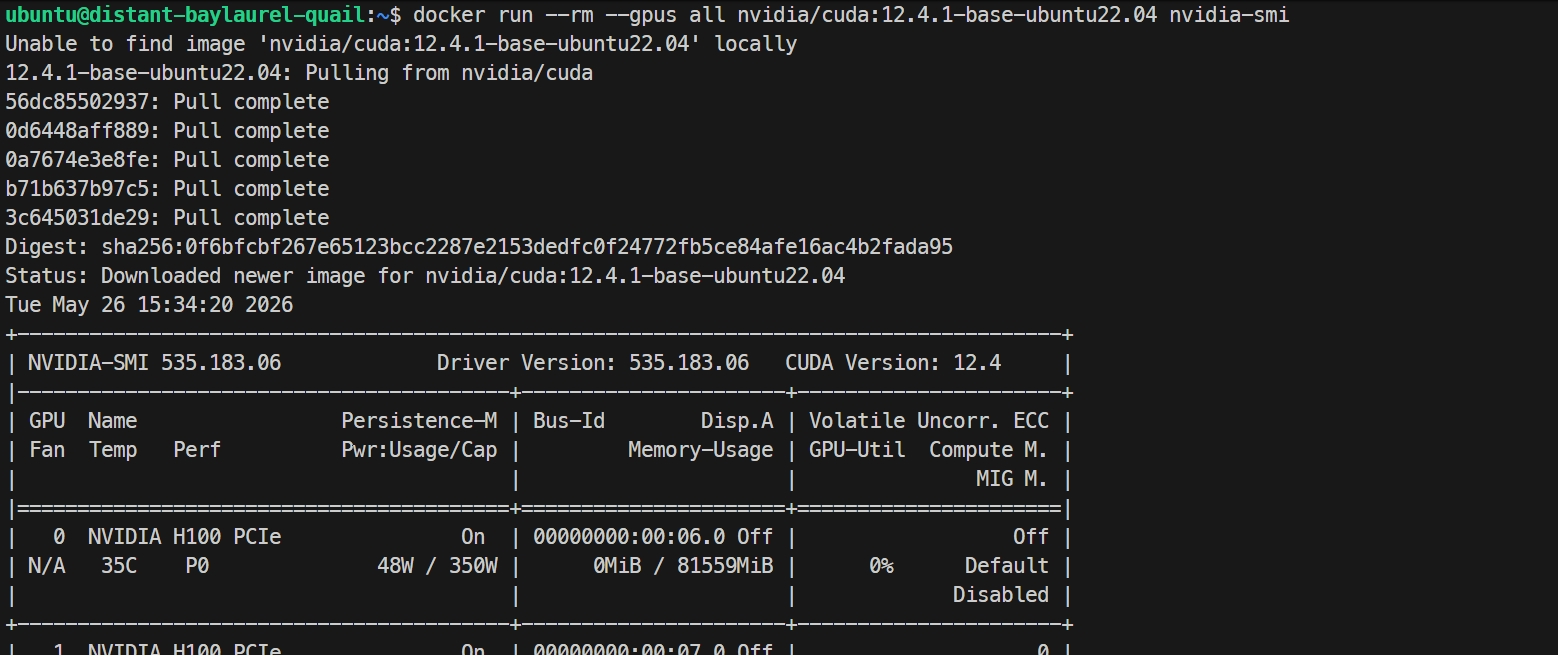
sudo systemctl restart dockerSon olarak, Docker’ın bir konteyner içinden GPU’ları görebildiğini test edin:
docker run --rm --gpus all nvidia/cuda:12.4.1-base-ubuntu22.04 nvidia-smiBu, Docker konteyneri içinde aynı H100 GPU listesini yazdırıyorsa, GPU Docker kurulumunuz doğru çalışıyor demektir.
Sırada, Mistral Medium 3.5 için oluşturulmuş SGLang Docker imajını çekmek var:
docker pull lmsysorg/sglang:dev-mistral-medium-3.5
Bu işlem internet hızınıza bağlı olarak biraz zaman alabilir. Benim durumumda yaklaşık 10 dakika sürdü. İmaj indirildiğinde, Docker aşağıdakine benzer bir başarı mesajı gösterecektir:
Status: Downloaded newer image for lmsysorg/sglang:dev-mistral-medium-3.5Şimdi SGLang sunucusunu başlatın:
docker run -d \
--name mistral-sglang \
--gpus all \
--shm-size 64g \
--ipc=host \
--cap-add SYS_NICE \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e HF_TOKEN=$HF_TOKEN \
-e PYTORCH_ALLOC_CONF=expandable_segments:True \
lmsysorg/sglang:dev-mistral-medium-3.5 \
sglang serve \
--model-path mistralai/Mistral-Medium-3.5-128B \
--served-model-name mistral-medium-3.5 \
--host 0.0.0.0 \
--port 30000 \
--tp 4 \
--trust-remote-code \
--dtype bfloat16 \
--context-length 100000 \
--mem-fraction-static 0.85 \
--disable-custom-all-reduce \
--tool-call-parser mistral \
--reasoning-parser mistral--dtype bfloat16 kullandım çünkü daha sonra yapacağımız EAGLE kurulumu da bf16 gerektiriyor; bu nedenle temel çalışma ve spekülatif çalışmayı hizalı tutmak, testler arasında dtype değiştirmeyi önler. Ayrıca ilk çalıştırmayı daha kolay hata ayıklanabilir kılmak için tam bağlam penceresi yerine --context-length 100000 ile başladım.
Konteyner günlüklerini şu komutla kontrol edin:
docker logs -f mistral-sglang
İlk başlatma daha uzun sürecektir çünkü SGLang’in model dosyalarını Hugging Face’ten indirmesi gerekir. Depo oldukça büyüktür; örneğinizin hızına bağlı olarak bu işlem bir saat veya daha fazla sürebilir.
Sunucu hazır olduğunda, günlüklerde Uvicorn’un 30000 portunda çalıştığı görülmelidir.
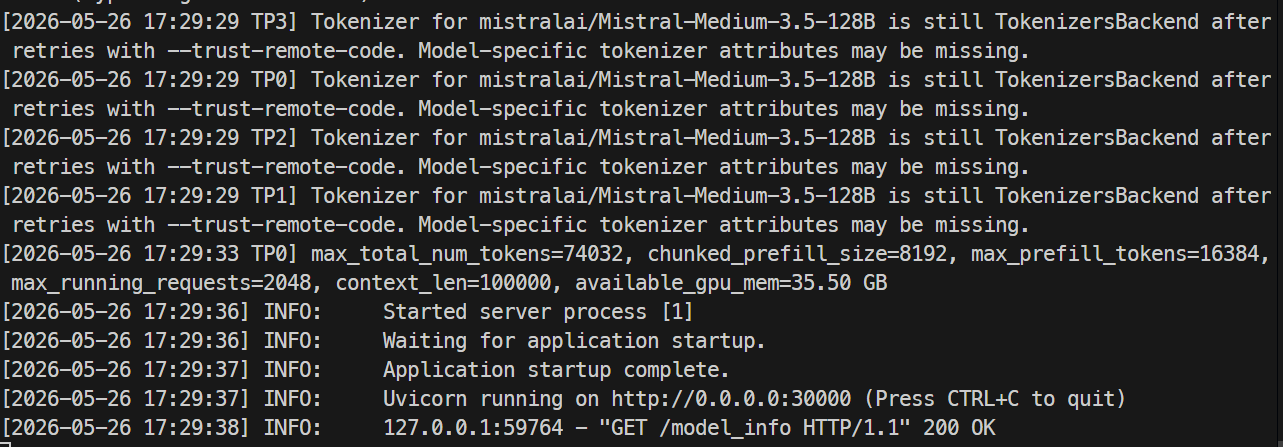
Başka bir terminalde, sunucuya tekrar SSH ile bağlanın ve model uç noktasını kontrol edin:
curl http://localhost:30000/v1/modelsmistral-medium-3.5 modelinin max_model_len değeri 100000 olacak şekilde listelendiğini görmelisiniz.
{"object":"list","data":[{"id":"mistral-medium-3.5","object":"model","created":1779816738,"owned_by":"sglang","root":"mistral-medium-3.5","parent":null,"max_model_len":100000}]}Son olarak bir sohbet tamamlama testi yapın:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mistral-medium-3.5",
"messages": [
{
"role": "user",
"content": "Write a short introduction to Mistral Medium 3.5."
}
],
"max_tokens": 300,
"temperature": 0.7,
"top_p": 0.95
}'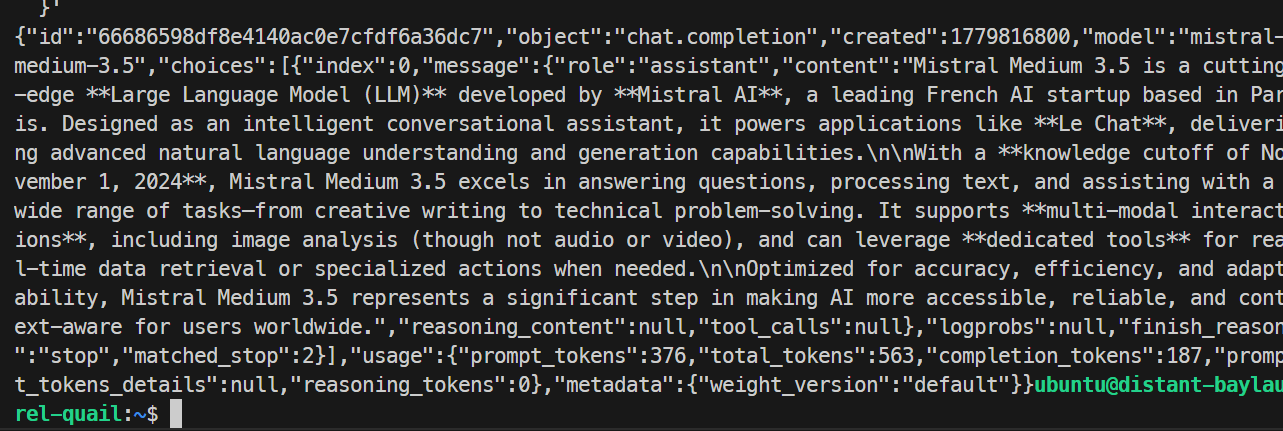
Benim testimde model başarıyla yanıt verdi ve isteği temiz şekilde tamamladı; bu da SGLang uç noktasının çalıştığını doğruladı. Temel çalıştırma saniyede yaklaşık 35,6 token üretti.
Spekülatif kod çözme, ana model doğrularken, daha küçük bir taslak modelin token’ları önceden tahmin etmesini kullanarak üretimi hızlandırabilir.
EAGLE burada faydalıdır çünkü özellikle Mistral Medium 3.5 gibi büyük bir modeli yerelde çalıştırırken, gecikmeye duyarlı sunum için tasarlanmıştır. Her zaman daha hızlı olmayabilir; ancak fayda, istem uzunluğu, çıktı uzunluğu, eşzamanlılık ve GPU kullanımına bağlı olduğundan test etmeye değerdir.
Önce temel konteyneri kaldırın:
docker rm -f mistral-sglangArdından EAGLE sürümünü başlatın:
docker run -d \
--name mistral-sglang-eagle \
--gpus all \
--shm-size 64g \
--ipc=host \
--cap-add SYS_NICE \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e HF_TOKEN="$HF_TOKEN" \
-e PYTORCH_ALLOC_CONF=expandable_segments:True \
lmsysorg/sglang:dev-mistral-medium-3.5 \
sglang serve \
--model-path mistralai/Mistral-Medium-3.5-128B \
--served-model-name mistral-medium-3.5-eagle \
--host 0.0.0.0 \
--port 30000 \
--tp 4 \
--trust-remote-code \
--dtype bfloat16 \
--context-length 100000 \
--mem-fraction-static 0.85 \
--disable-custom-all-reduce \
--tool-call-parser mistral \
--reasoning-parser mistral \
--enable-metrics \
--speculative-algorithm EAGLE \
--speculative-draft-model-path mistralai/Mistral-Medium-3.5-128B-EAGLE \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4SGLang bu EAGLE kurulumunu iyi bir başlangıç noktası olarak önerir: --speculative-num-steps 3, --speculative-eagle-topk 1 ve --speculative-num-draft-tokens 4. İlk çalıştırma daha uzun sürebilir çünkü EAGLE taslak modelini de indirir.
Yüklendikten sonra, nvidia-smi ile GPU kullanımını kontrol edebilirsiniz; benim çalıştırmamda model GPU başına yaklaşık 44 GB H100 belleği kullandı.
Günlükleri şu komutla izleyin:
docker logs -f mistral-sglang-eagle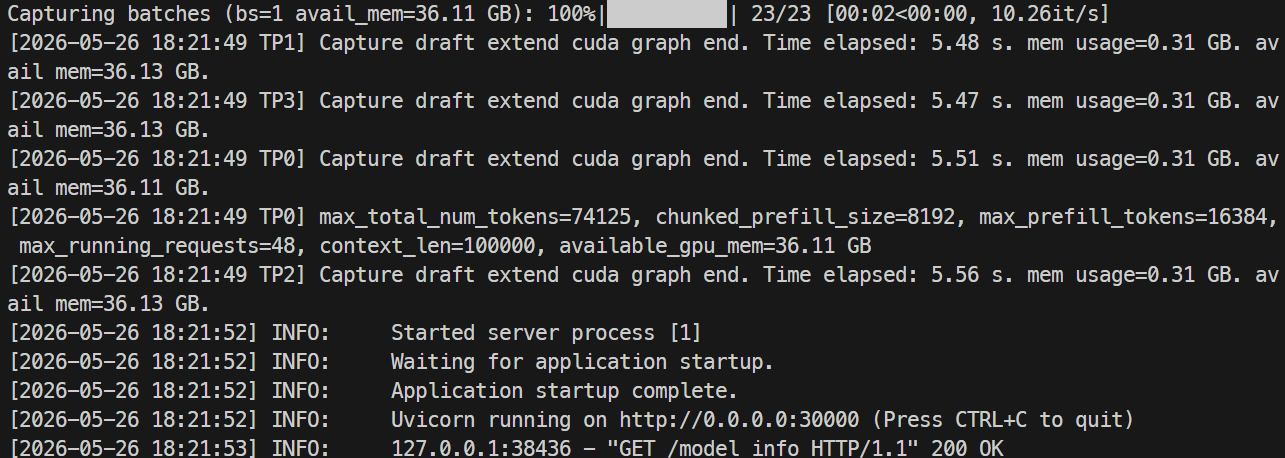
Günlüklerde Uvicorn’un 0.0.0.0:30000 üzerinde çalıştığını gördüğünüzde uç noktayı test edin:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mistral-medium-3.5-eagle",
"messages": [
{
"role": "user",
"content": "Generate a simple Python game."
}
],
"reasoning_effort": "none",
"max_tokens": 300,
"temperature": 0.7,
"top_p": 0.95
}'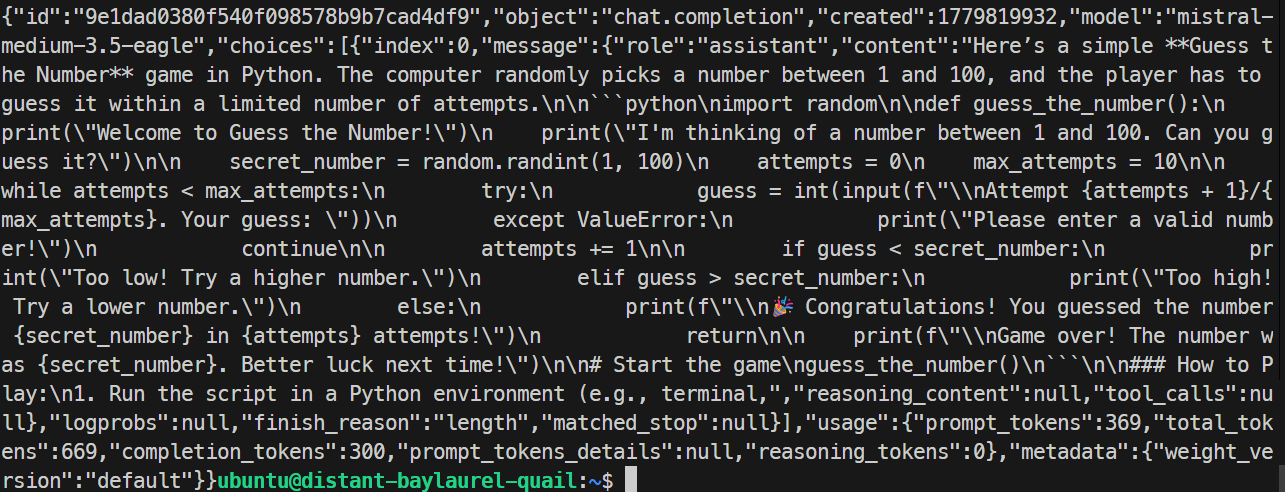
Benim testimde EAGLE sunucusu doğru şekilde yanıt verdi ve basit bir Python oyunu üretti. Çalıştırma saniyede yaklaşık 32 token’a ulaştı; bu da temel çalıştırmadan biraz daha yavaştı; dolayısıyla EAGLE bu özel testte iyileşme sağlamadı.
Bu normaldir: spekülatif kod çözme iş yüküne çok bağlıdır ve en iyi değerlendirme yöntemi kendi istemleriniz ve eşzamanlılık düzeyinizle test etmektir.
OpenCode, OpenAI uyumlu model uç noktalarına bağlanabilen açık kaynaklı bir AI kodlama ajanıdır. SGLang, Mistral Medium 3.5’i yerel bir OpenAI uyumlu API üzerinden sunduğundan, onu doğrudan OpenCode içinde kullanabiliriz.
Henüz kurmadıysanız OpenCode’u yükleyin:
curl -fsSL https://opencode.ai/install | bashSonra proje dizininize gidin ve bir opencode.json dosyası oluşturun.
Aşağıdaki yapılandırmayı ekleyin:
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"sglang": {
"npm": "@ai-sdk/openai-compatible",
"name": "SGLang Local",
"options": {
"baseURL": "http://127.0.0.1:30000/v1",
"apiKey": "EMPTY"
},
"models": {
"mistral-medium-3.5-eagle": {
"name": "Mistral Medium 3.5 EAGLE",
"limit": {
"context": 100000,
"output": 8192
}
}
}
}
},
"model": "sglang/mistral-medium-3.5-eagle"
}Şimdi aynı proje dizininden OpenCode’u başlatın:
OpencodeOpenCode içinde Mistral Medium 3.5 EAGLE SGLang Local seçili görünmelidir. Bu, OpenCode’un şimdi iletilen 30000 bağlantı noktası üzerinden yerel SGLang sunucunuzla konuştuğu, tıpkı herhangi bir OpenAI uyumlu API’yi çağırır gibi, anlamına gelir.
Testimde OpenCode’dan projeyi açıklamasını istedim; depo dosyalarını birkaç saniye içinde okuyup özeti oluşturdu.
Ardından ondan bir Badger 2040 emülatörü oluşturmasını istedim; önce mevcut proje dosyalarını inceledi, yapıyı doğruladı ve ardından gerekli Python dosyasını oluşturdu. Tüm süreç yaklaşık 2 dakika sürdü.
Sonrasında emülatörü yerelde test etmesini istedim. OpenCode kodu çalıştırdı ve emülatör penceresini başarıyla açtı.
Yazı tipi gerçek Badger 2040 ekranıyla birebir aynı değildi; ancak yerleşim, saat ve tarih yerleşimi ile genel yapı neredeyse kusursuzdu.

Sonuç beni gerçekten şaşırttı; çünkü aynı görevi daha önce Claude Code ve GPT-5.5 ile denemiştim ve ikisi de zorlanmıştı; Mistral Medium 3.5 ise yerel SGLang kurulumu üzerinden bunu gayet iyi başardı.
Yolda birkaç tuzak var. Karşılaşabileceğiniz sorunları ve nasıl çözeceğinizi anlatayım.
Her şeyden önce sabırlı olmanız gerekecek. Bu tam kurulum neredeyse 3 saat sürdü. GPU VM’nin başlatılması yaklaşık 15 dakika, Docker ve NVIDIA konteyner aracının kurulumu yaklaşık 10 dakika, SGLang Docker imajının çekilmesi yaklaşık 30 dakika ve Mistral Medium 3.5 model ağırlıklarının indirilmesi artı yüklenmesi yaklaşık 1 saat aldı.
EAGLE kurulumu da ek zaman alır çünkü modeli yeniden yükler ve EAGLE taslak modelini indirebilir. Daha akıcı bir deneyim için daha hızlı ağ, mevcutsa H200 gibi daha yeni GPU’lar ve tam Hugging Face önbelleği için yeterli depolama kullanın.
nvidia-smi ana makinede çalışıyor ancak Docker GPU’lara erişemiyorsa, NVIDIA konteyner çalışma zamanı muhtemelen doğru yapılandırılmamıştır. NVIDIA konteyner araç takımının yapılandırmasını yeniden çalıştırın ve Docker’ı yeniden başlatın:
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart dockerNVIDIA’nın belgeleri, Docker GPU erişimi için bu nvidia-ctk çalışma zamanı yapılandırma adımını da önerir.
Hugging Face önbelleğinin konteynere bağlandığından emin olun:
-v ~/.cache/huggingface:/root/.cache/huggingfaceBu, Docker’ın indirilen model dosyalarını yeniden indirmek yerine yeniden kullanmasına olanak tanır. Hugging Face, güncel dosyaların yeniden indirilmesini önlemek için yerel bir önbellek kullanır.
Mistral Medium 3.5 deposu büyüktür; bu nedenle ilk indirme uzun sürebilir. Takılmış görünüyorsa internet hızınızı, disk alanınızı ve Hugging Face belirtecinizi kontrol edin. Ayrıca konteyneri çalıştırmadan önce Hugging Face’te gerekli model erişim koşullarını kabul ettiğinizden emin olun.
Günlüklerde Uvicorn’un 30000 portunda çalıştığı görülmeden sunucu hazır değildir. Günlükleri şu komutla kontrol edin:
docker logs -f mistral-sglangveya EAGLE için:
docker logs -f mistral-sglang-eagleAyrıca konteynerin bağlantı noktasını doğru şekilde dışa açtığından emin olun:
-p 30000:30000Bu normaldir. Spekülatif kod çözmenin her isteği iyileştirmesi garanti değildir. Taslak modelin token önermesi ve ana modelin bunları doğrulamasıyla çalışır; ancak hızlanma, kabul oranı, istem uzunluğu, çıktı uzunluğu, eşzamanlılık ve GPU kullanımına bağlıdır.
Bellek sorunları yaşarsanız önce bağlam uzunluğunu azaltın. Örneğin, tam bağlam penceresini hemen denemek yerine --context-length 100000 ile başlayın. Başlangıç başarısız olursa --mem-fraction-static değerini biraz düşürebilirsiniz; ancak genellikle bağlam uzunluğunu azaltmak en kolay ilk adımdır.
SGLang sunucusunun çalıştığından ve opencode.json dosyanızın doğru yerel uç noktayı kullandığından emin olun:
"baseURL": "http://127.0.0.1:30000/v1"Sunucuya yerel makinenizden erişiyorsanız, bağlantı noktası iletimiyle SSH’yi başlatın:
ssh -L 30000:localhost:30000 ubuntu@XXXXXXArdından OpenCode’u, opencode.json dosyanızın kayıtlı olduğu aynı dizinden başlatın.
Teknik kurulumun ne kadar sorunsuz olduğuna gerçekten şaşırdım. Yerel SGLang Docker imajıyla Mistral Medium 3.5 128B’yi çalıştırmak beklediğimden çok daha kolaydı. Docker imajı sorunsuz çekildi, model yüklendi, OpenAI uyumlu uç nokta çalıştı ve OpenCode fazla sorun çıkarmadan bağlandı. B
unu kendiniz deniyorsanız, her şeyi Python paketleriyle kurmak yerine SGLang Docker imajını kullanmanızı şiddetle tavsiye ederim. Python üzerinden kurulum, CUDA, PyTorch ve diğer bağımlılıkları kolayca karıştırabilir. Docker her şeyi temiz ve yalıtılmış tutar.
Ancak bu deneyden çıkardığım en büyük sonuç maliyet oldu. Açıkçası, yapay zeka şirketleri çıkarımdan nasıl para kazanıyor bilmiyorum. Daha ucuz ve eski H100 PCIe seçeneklerinden birini kullansam bile bu kurulum saat başına 10 $’a yakındı. Ve bu yalnızca 4 GPU üzerinde bir 128B model için. Şimdi 16× H100 üzerinde trilyon parametreli çok daha büyük bir modeli çalıştırmayı hayal edin. Depolama, ağ, izleme, çalışma süresi ve mühendislik işini düşünmeden önce bile faturanız kolayca saatte 40 $+’a ulaşabilir.
Küçük şirketler için, mahremiyet, araştırma veya çıkarım yığını üzerinde derin kontrol gibi çok güçlü bir gerekçe olmadıkça bu tür modelleri yerelde sunmanın mantıklı olduğunu düşünmüyorum. Çıkarım maliyeti zaten yüksek, ancak operasyonel yük de bir sorun. Sunucuyu çalışır durumda tutmanız, modelin çökmediğinden emin olmanız, GPU belleğini izlemeniz, başarısız konteynerleri ele almanız ve uç noktayı erişilebilir tutmanız gerekir.
Sunucusuz mimari de çok büyük modeller için bunu gerçekten çözmüyor. Soğuk başlatma süresi basitçe çok uzun. Bu kurulumda GPU VM’yi başlatmak, bağımlılıkları kurmak, Docker imajını çekmek, ağırlıkları indirmek ve modeli yüklemek toplamda neredeyse 3 saat sürdü.
Kurulumunuz daha hızlı olsa bile, bu boyuttaki bir modeli yüklemek yine de uzun sürebilir. Dolayısıyla her yeni istek başka bir GPU kümesini başlatmayı ve modeli yeniden yüklemeyi gerektiriyorsa, bu sunucusuz mimarinin amacını boşa çıkarır. Pratikte şirketlerin sıcak GPU kümelerini çalışır halde tutması gerekir; bu da GPU’lar boşta kalsa bile ödeme yapıldığı anlamına gelir.
Bu durum, yoğun olmayan saatlerde GPU fiyatlandırmasının neden var olduğunu da açıklar. Sağlayıcılar, boştaki GPU kapasitesini insanların kullanmasını ister; çünkü kullanılmayan GPU’lar sadece para yakar. Kullanıcılar için bu, daha ucuza denemeler yapmak için iyi bir yol olabilir; ancak büyük model çıkarımının ekonomisinin ne kadar zor olduğunu da gösterir.
Genel olarak bu kurulum için SGLang’i gerçekten beğendim. Docker tabanlı iş akışı, Mistral Medium 3.5 128B’yi beklediğimden çok daha kolay sunmamı sağladı ve OpenCode testi gerçekten etkileyiciydi. Ancak bu deney bir şeyi de çok net gösterdi: büyük açık modelleri yerelde çalıştırmak mümkün; fakat bunları gerçek bir ürün olarak güvenilir ve uygun maliyetli şekilde çalıştırmak tamamen farklı bir zorluktur.
DataCamp ile AI öğrenin!
Program
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
