Track
Inżynier AI Associate dla programistów
26 godz.
Do tego przewodnika użyłem maszyny wirtualnej GPU 4× H100 80GB. Mistral Medium 3.5 to gęsty model 128B, więc wymaga konfiguracji z wieloma GPU. SGLang zaleca uruchamianie go z równoległością tensorową przy użyciu --tp 4 na GPU H100 lub H200. Model obsługuje duże okno kontekstu, ale polecam zacząć od 100 000 tokenów zamiast pełnych 256K, by łatwiej testować i debugować konfigurację.
Korzystałem z Hyperbolic, bo daje dostęp do pełnej maszyny wirtualnej z GPU, co ułatwia instalację Dockera, konfigurację środowiska kontenerowego NVIDIA i ręczne uruchomienie obrazu Dockera SGLang. Możesz też użyć platform takich jak RunPod czy Vast.ai, ale niektóre ich instancje są już powiązane z niestandardowymi środowiskami Dockera, co daje mniejszą kontrolę.
W Hyperbolic wybierz H100 PCIe 80GB, ustaw 4 GPU, dodaj ok. 3 TB przestrzeni, wprowadź swój klucz publiczny SSH i nadaj instancji nazwę, np. MM-35. Wybrałem H100 PCIe, bo to była najtańsza dostępna opcja H100 do tego testu.
Po kliknięciu Start Building maszyna może uruchamiać się ok. 10 minut. Gdy będzie gotowa, Hyperbolic wyświetli polecenie SSH potrzebne w kolejnym kroku.
Gdy instancja będzie gotowa, połącz się z nią z lokalnego terminala, używając polecenia SSH widocznego w panelu Hyperbolic:
ssh ubuntu@XXXXXXAby później uzyskać dostęp do API SGLang z lokalnej maszyny, możesz też przekierować port 30000:
ssh -L 30000:localhost:30000 ubuntu@XXXXXXJeśli twój klucz SSH ma hasło, wprowadź je po wyświetleniu monitu. Po zalogowaniu sprawdź dostępność wszystkich GPU:
Nvidia-smiPowinieneś zobaczyć 4× NVIDIA H100 PCIe 80GB na liście. To potwierdza, że serwer jest gotowy do konfiguracji Dockera i SGLang.
Najpierw wyeksportuj swój token Hugging Face, aby serwer mógł później pobrać model Mistral:
echo 'export HF_TOKEN="your_huggingface_token_here"' >> ~/.bashrc
source ~/.bashrcUwaga: swój token Hugging Face znajdziesz na stronie Access Tokens.
Utwórz folder cache Hugging Face:
mkdir -p ~/.cache/huggingfaceTeraz zainstaluj Dockera:
sudo apt update
sudo apt install -y docker.ioUruchom Dockera i włącz autostart po restarcie:
sudo systemctl start docker
sudo systemctl enable dockerSprawdź, czy Docker został poprawnie zainstalowany:
docker –versionMożesz też użyć polecenia wyszukiwania obrazów, by potwierdzić, że Docker umie szukać publicznych obrazów z Docker Hub:
docker search nvidia/cudaPowinno to zwrócić dostępne obrazy NVIDIA CUDA. Później użyjemy jednego z tych obrazów CUDA, aby zweryfikować dostęp Dockera do GPU.
Następnie zezwól swojemu użytkownikowi na uruchamianie poleceń Dockera bez sudo:
sudo usermod -aG docker $USER
newgrp dockerTeraz zainstaluj i skonfiguruj NVIDIA Container Toolkit, aby Docker miał dostęp do GPU:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/libnvidia-container/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt update
sudo apt install -y nvidia-container-toolkit
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart dockerNa koniec sprawdź, czy Docker widzi GPU wewnątrz kontenera:
docker run --rm --gpus all nvidia/cuda:12.4.1-base-ubuntu22.04 nvidia-smiJeśli to polecenie wypisze tę samą listę H100 wewnątrz kontenera Dockera, twoja konfiguracja GPU dla Dockera działa poprawnie.
Następnie pobierz obraz Dockera SGLang zbudowany dla Mistral Medium 3.5:
docker pull lmsysorg/sglang:dev-mistral-medium-3.5
To może chwilę potrwać, zależnie od prędkości internetu. U mnie około 10 minut. Gdy obraz zostanie pobrany, Docker pokaże komunikat podobny do:
Status: Downloaded newer image for lmsysorg/sglang:dev-mistral-medium-3.5Teraz uruchom serwer SGLang:
docker run -d \
--name mistral-sglang \
--gpus all \
--shm-size 64g \
--ipc=host \
--cap-add SYS_NICE \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e HF_TOKEN=$HF_TOKEN \
-e PYTORCH_ALLOC_CONF=expandable_segments:True \
lmsysorg/sglang:dev-mistral-medium-3.5 \
sglang serve \
--model-path mistralai/Mistral-Medium-3.5-128B \
--served-model-name mistral-medium-3.5 \
--host 0.0.0.0 \
--port 30000 \
--tp 4 \
--trust-remote-code \
--dtype bfloat16 \
--context-length 100000 \
--mem-fraction-static 0.85 \
--disable-custom-all-reduce \
--tool-call-parser mistral \
--reasoning-parser mistralUżyłem --dtype bfloat16, ponieważ późniejsza konfiguracja EAGLE też wymaga bf16, więc utrzymanie zgodności między bazowym i spekulacyjnym przebiegiem pozwala uniknąć zmiany dtype między testami. Zacząłem też od --context-length 100000 zamiast pełnego okna, by pierwsze uruchomienie łatwiej debugować.
Sprawdź logi kontenera:
docker logs -f mistral-sglang
Pierwsze uruchomienie potrwa dłużej, ponieważ SGLang musi pobrać pliki modelu z Hugging Face. Repozytorium jest duże, więc może to zająć około godziny lub więcej, w zależności od szybkości instancji.
Gdy serwer będzie gotowy, w logach pojawi się informacja, że Uvicorn działa na porcie 30000.
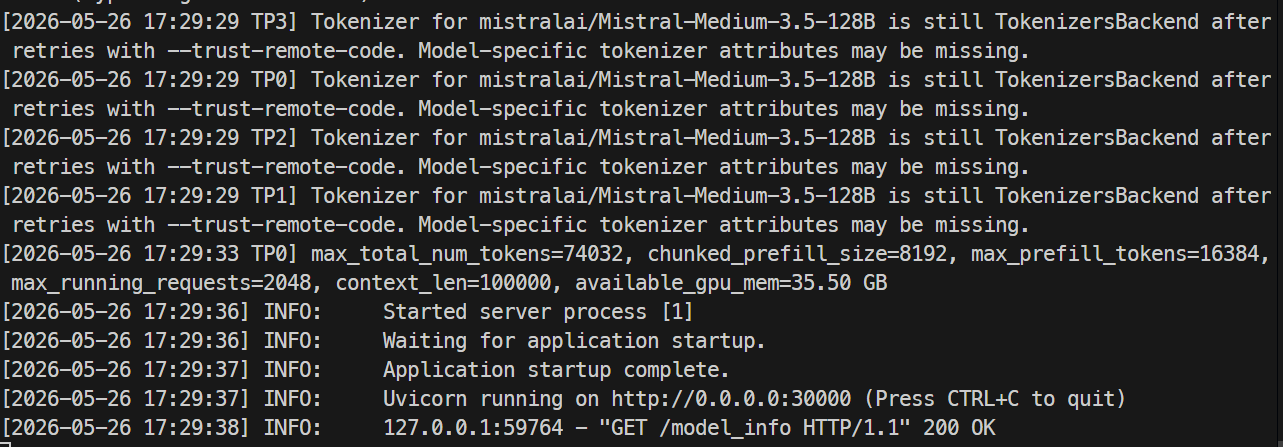
W innym terminalu zaloguj się ponownie przez SSH i sprawdź endpoint modelu:
curl http://localhost:30000/v1/modelsPowinieneś zobaczyć mistral-medium-3.5 z max_model_len równym 100000.
{"object":"list","data":[{"id":"mistral-medium-3.5","object":"model","created":1779816738,"owned_by":"sglang","root":"mistral-medium-3.5","parent":null,"max_model_len":100000}]}Na koniec przetestuj chat completion:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mistral-medium-3.5",
"messages": [
{
"role": "user",
"content": "Write a short introduction to Mistral Medium 3.5."
}
],
"max_tokens": 300,
"temperature": 0.7,
"top_p": 0.95
}'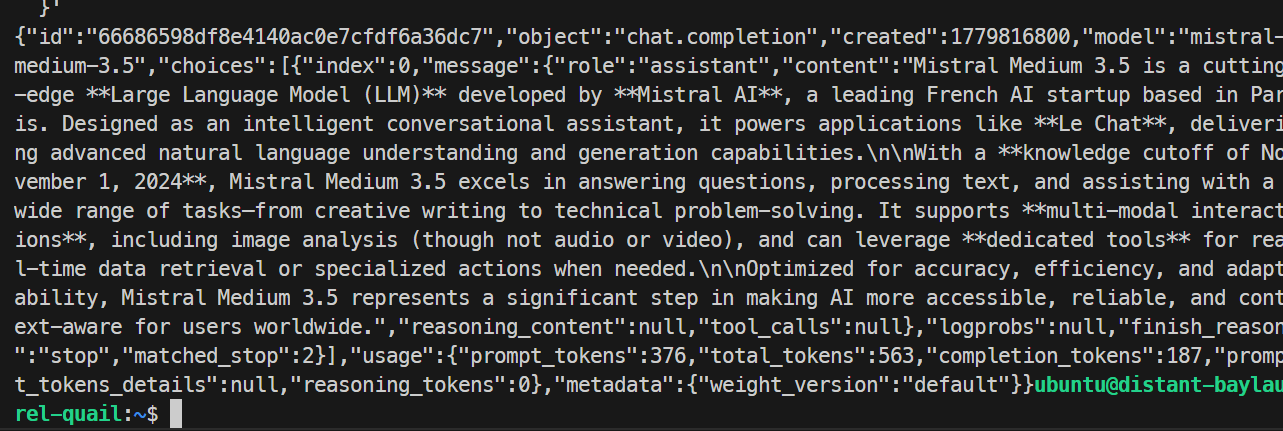
W moim teście model odpowiedział poprawnie i zrealizował żądanie bez problemu, co potwierdziło działanie endpointu SGLang. Bazowe uruchomienie osiągnęło ok. 35,6 tokena na sekundę.
Spekulacyjne dekodowanie może przyspieszyć generację, używając mniejszego modelu szkicowego do przewidywania tokenów z wyprzedzeniem, podczas gdy główny model je weryfikuje.
EAGLE jest tu przydatny, bo został zaprojektowany pod kątem serwowania wrażliwego na opóźnienia, zwłaszcza gdy lokalnie uruchamiasz duży model, taki jak Mistral Medium 3.5. Nie zawsze będzie szybszy, ale warto go przetestować, bo korzyści zależą od długości promptu, długości wyjścia, współbieżności i wykorzystania GPU.
Najpierw usuń kontener bazowy:
docker rm -f mistral-sglangNastępnie uruchom wersję EAGLE:
docker run -d \
--name mistral-sglang-eagle \
--gpus all \
--shm-size 64g \
--ipc=host \
--cap-add SYS_NICE \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e HF_TOKEN="$HF_TOKEN" \
-e PYTORCH_ALLOC_CONF=expandable_segments:True \
lmsysorg/sglang:dev-mistral-medium-3.5 \
sglang serve \
--model-path mistralai/Mistral-Medium-3.5-128B \
--served-model-name mistral-medium-3.5-eagle \
--host 0.0.0.0 \
--port 30000 \
--tp 4 \
--trust-remote-code \
--dtype bfloat16 \
--context-length 100000 \
--mem-fraction-static 0.85 \
--disable-custom-all-reduce \
--tool-call-parser mistral \
--reasoning-parser mistral \
--enable-metrics \
--speculative-algorithm EAGLE \
--speculative-draft-model-path mistralai/Mistral-Medium-3.5-128B-EAGLE \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4SGLang zaleca taką konfigurację EAGLE jako dobry punkt startowy: --speculative-num-steps 3, --speculative-eagle-topk 1 i --speculative-num-draft-tokens 4. Pierwsze uruchomienie może potrwać dłużej, bo pobierze też model szkicowy EAGLE.
Po załadowaniu możesz sprawdzić użycie GPU poleceniem nvidia-smi; u mnie model zużywał około 44 GB na każde GPU H100.
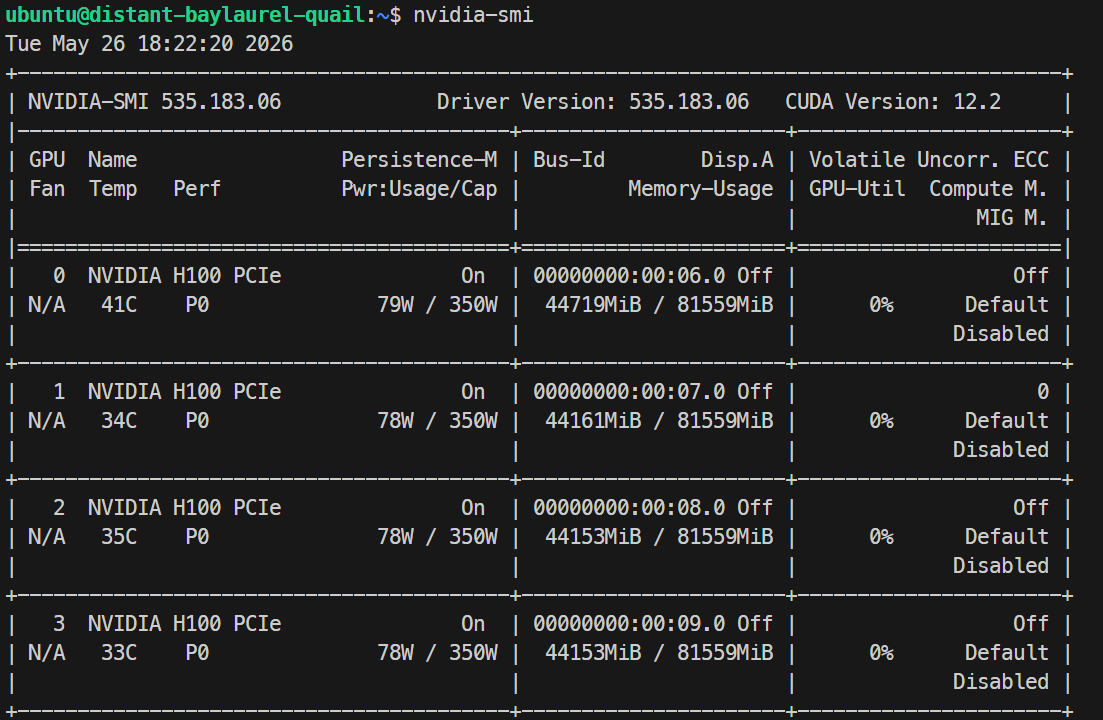
Monitoruj logi poleceniem:
docker logs -f mistral-sglang-eagle
Gdy w logach pojawi się informacja, że Uvicorn działa na 0.0.0.0:30000, przetestuj endpoint:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mistral-medium-3.5-eagle",
"messages": [
{
"role": "user",
"content": "Generate a simple Python game."
}
],
"reasoning_effort": "none",
"max_tokens": 300,
"temperature": 0.7,
"top_p": 0.95
}'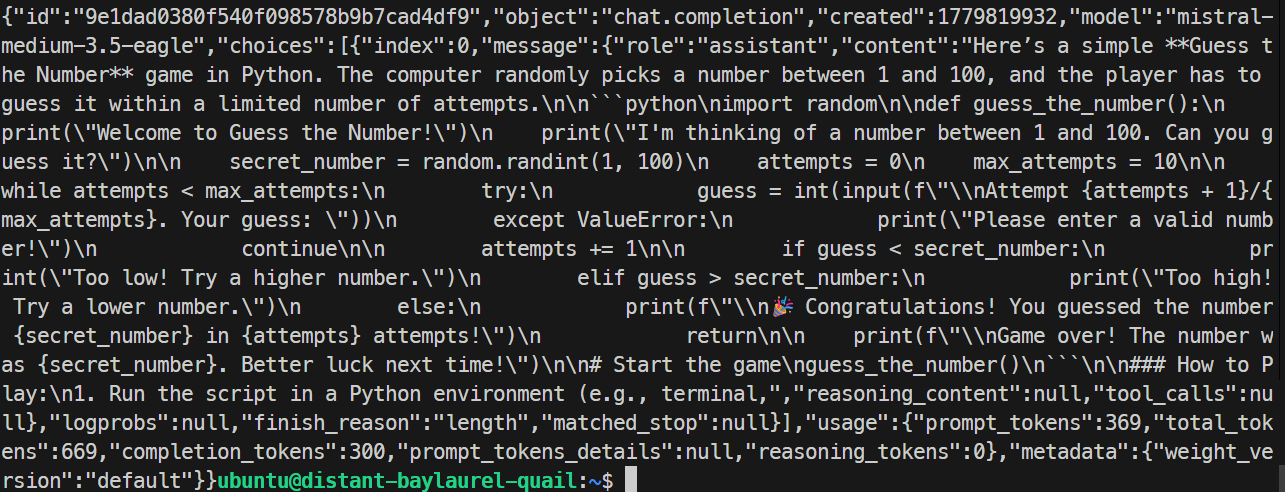
W moim teście serwer EAGLE odpowiedział poprawnie i wygenerował prostą grę w Pythonie. Uzyskano ok. 32 tokeny na sekundę, czyli nieco wolniej niż w bazowym uruchomieniu, więc EAGLE nie poprawił wyniku w tym konkretnym teście.
To normalne: skuteczność spekulacyjnego dekodowania mocno zależy od obciążenia — najlepiej ocenić je, testując własne prompty i poziom współbieżności.
OpenCode to otwartoźródłowy agent do kodowania, który potrafi łączyć się z endpointami modeli zgodnymi z OpenAI. Ponieważ SGLang wystawia Mistral Medium 3.5 przez lokalne API zgodne z OpenAI, możemy użyć go bezpośrednio w OpenCode.
Zainstaluj OpenCode, jeśli jeszcze go nie masz:
curl -fsSL https://opencode.ai/install | bashNastępnie przejdź do katalogu projektu i utwórz plik opencode.json.
Dodaj następującą konfigurację:
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"sglang": {
"npm": "@ai-sdk/openai-compatible",
"name": "SGLang Local",
"options": {
"baseURL": "http://127.0.0.1:30000/v1",
"apiKey": "EMPTY"
},
"models": {
"mistral-medium-3.5-eagle": {
"name": "Mistral Medium 3.5 EAGLE",
"limit": {
"context": 100000,
"output": 8192
}
}
}
}
},
"model": "sglang/mistral-medium-3.5-eagle"
}Teraz uruchom OpenCode z tego samego katalogu projektu:
OpencodeW OpenCode powinieneś zobaczyć wybrany Mistral Medium 3.5 EAGLE SGLang Local. Oznacza to, że OpenCode komunikuje się teraz z twoim lokalnym serwerem SGLang przez przekierowany port 30000, tak jak z każdym API zgodnym z OpenAI.
W moim teście poprosiłem OpenCode o wyjaśnienie projektu; w kilka sekund wczytał pliki repozytorium i wygenerował podsumowanie.
Następnie poprosiłem o stworzenie emulatora Badger 2040; narzędzie najpierw przeanalizowało istniejące pliki projektu, zweryfikowało strukturę, a potem utworzyło wymagany plik Pythona. Całość zajęła około 2 minut.
Potem poprosiłem o przetestowanie emulatora lokalnie. OpenCode uruchomił kod i poprawnie otworzył okno emulatora.
Czcionka nie była identyczna jak w prawdziwym wyświetlaczu Badger 2040, ale układ, wyświetlanie czasu, położenie daty i ogólna struktura były niemal idealne.

Byłem szczerze zaskoczony wynikiem, bo próbowałem wcześniej tego samego zadania z Claude Code i GPT-5.5 i oba miały z tym trudności, podczas gdy Mistral Medium 3.5 poradził sobie bardzo dobrze w lokalnej konfiguracji SGLang.
Po drodze można trafić na kilka pułapek. Oto problemy, na jakie możesz natrafić, i sposoby ich rozwiązania.
Przede wszystkim musisz uzbroić się w cierpliwość. Całość zajęła mi prawie 3 godziny. Uruchomienie VM z GPU — ok. 15 minut, instalacja Dockera i narzędzi NVIDIA — ok. 10 minut, pobranie obrazu SGLang — ok. 30 minut, a pobranie i załadowanie wag Mistral Medium 3.5 — ok. 1 godziny.
Uruchomienie EAGLE też zajmuje dodatkowy czas, bo model jest ładowany ponownie i może być potrzebne pobranie modelu szkicowego EAGLE. Dla płynniejszego doświadczenia użyj szybszej sieci, nowszych GPU, np. H200, jeśli są dostępne, i zapewnij wystarczającą przestrzeń na pełny cache Hugging Face.
Jeśli nvidia-smi działa na hoście, ale Docker nie ma dostępu do GPU, prawdopodobnie runtime kontenerów NVIDIA nie jest poprawnie skonfigurowany. Ponownie wykonaj konfigurację NVIDIA Container Toolkit i zrestartuj Dockera:
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart dockerDokumentacja NVIDIA również zaleca ten krok konfiguracji runtime nvidia-ctk do dostępu Dockera do GPU.
Upewnij się, że cache Hugging Face jest zamontowany w kontenerze:
-v ~/.cache/huggingface:/root/.cache/huggingfaceDzięki temu Docker będzie używać pobranych już plików modelu zamiast ściągać je za każdym razem. Hugging Face korzysta z lokalnego cache, aby unikać ponownego pobierania aktualnych plików.
Repozytorium Mistral Medium 3.5 jest duże, więc pierwszy download może zająć dużo czasu. Jeśli wygląda na zawieszone, sprawdź prędkość internetu, miejsce na dysku i token Hugging Face. Upewnij się też, że zaakceptowałeś wymagane warunki dostępu do modelu na Hugging Face przed uruchomieniem kontenera.
Serwer nie jest gotowy, dopóki w logach nie pojawi się informacja, że Uvicorn działa na porcie 30000. Sprawdź logi poleceniem:
docker logs -f mistral-sglanglub dla EAGLE:
docker logs -f mistral-sglang-eagleUpewnij się też, że kontener poprawnie wystawia port:
-p 30000:30000To normalne. Spekulacyjne dekodowanie nie gwarantuje przyspieszenia każdego żądania. Działa tak, że model szkicowy proponuje tokeny, a główny model je weryfikuje, ale przyspieszenie zależy od współczynnika akceptacji, długości promptu, długości wyjścia, współbieżności i wykorzystania GPU.
Jeśli trafisz na problemy z pamięcią, najpierw zmniejsz długość kontekstu. Na przykład zacznij od --context-length 100000 zamiast od razu próbować pełnego okna. Możesz też nieco obniżyć --mem-fraction-static, jeśli start się nie udaje, ale zwykle najłatwiejszym krokiem jest redukcja długości kontekstu.
Upewnij się, że serwer SGLang działa i że plik opencode.json wskazuje właściwy lokalny endpoint:
"baseURL": "http://127.0.0.1:30000/v1"Jeśli uzyskujesz dostęp do serwera z lokalnej maszyny, uruchom SSH z przekierowaniem portu:
ssh -L 30000:localhost:30000 ubuntu@XXXXXXNastępnie uruchom OpenCode z tego samego katalogu, w którym zapisany jest plik opencode.json.
Szczerze zaskoczyło mnie, jak gładko poszła strona techniczna. Uruchomienie Mistral Medium 3.5 128B z natywnym obrazem Dockera SGLang było dużo prostsze, niż się spodziewałem. Obraz pobrał się poprawnie, model się załadował, endpoint zgodny z OpenAI działał, a OpenCode połączył się bez większych problemów. J
eśli sam będziesz to robić, zdecydowanie polecam użycie obrazu Dockera SGLang zamiast instalacji wszystkiego przez pakiety Pythona. Przy instalacji przez Pythona łatwo namieszać w CUDA, PyTorch i innych zależnościach. Docker trzyma wszystko w ryzach i izolacji.
Ale największym wnioskiem z tego eksperymentu jest koszt. Naprawdę nie wiem, jak firmy AI zarabiają na wnioskowaniu. Nawet przy jednej z tańszych i starszych opcji H100 PCIe ta konfiguracja kosztowała blisko 10 USD za godzinę. I to tylko dla modelu 128B na 4 GPU. Teraz wyobraź sobie uruchomienie znacznie większego, bilionowego modelu na 16× H100. Rachunek łatwo sięgnie 40+ USD za godzinę, zanim w ogóle pomyślisz o storage’u, sieci, monitoringu, dostępności i pracy inżynierskiej.
Dla małych firm nie ma moim zdaniem sensu serwować lokalnie takich modeli bez bardzo mocnego powodu, jak prywatność, badania czy głęboka kontrola nad stosem wnioskowania. Koszt wnioskowania jest już wysoki, a do tego dochodzi ciężar operacyjny. Trzeba utrzymywać serwer, pilnować, by model się nie wysypywał, monitorować pamięć GPU, obsługiwać padnięte kontenery i utrzymywać dostępność endpointu.
Serverless też tego nie rozwiązuje dla bardzo dużych modeli. Cold start jest po prostu zbyt długi. W tej konfiguracji uruchomienie VM z GPU, instalacja zależności, pobranie obrazu Dockera, pobranie wag i załadowanie modelu zajęły łącznie prawie 3 godziny.
Nawet jeśli twoja konfiguracja jest szybsza, samo ładowanie modelu tej wielkości i tak może długo trwać. Jeśli każde nowe żądanie wymaga uruchomienia kolejnego klastra GPU i ponownego ładowania modelu, mija się to z celem serverless. W praktyce firmy muszą utrzymywać ciepłe klastry GPU — czyli płacą nawet wtedy, gdy GPU się nudzą.
To też tłumaczy, skąd biorą się ceny poza godzinami szczytu. Dostawcy chcą, by ludzie korzystali z bezczynnych GPU, bo niewykorzystane GPU generują straty. Dla użytkowników to dobry sposób na tańsze eksperymenty, ale pokazuje też, jak trudna jest ekonomia wnioskowania dużych modeli.
Podsumowując, SGLang bardzo mi się spodobał w tej konfiguracji. Praca w oparciu o Dockera sprawiła, że serwowanie Mistral Medium 3.5 128B było dużo łatwiejsze niż oczekiwałem, a test w OpenCode szczerze imponujący. Ten eksperyment uświadomił mi jednak coś jeszcze: uruchomienie dużych otwartych modeli lokalnie jest możliwe, ale utrzymanie ich niezawodnie i tanio jako prawdziwego produktu to zupełnie inne wyzwanie.
Ucz się AI z DataCamp!
Track
course
course