track
Inginer AI asociat pentru dezvoltatori
26 oră
Pentru acest ghid, am folosit o mașină virtuală cu 4× H100 80GB GPU. Mistral Medium 3.5 este un model dens de 128B, deci are nevoie de o configurație multi-GPU. SGLang recomandă rularea cu paralelism tensorial folosind --tp 4 pe GPU-uri H100 sau H200. Modelul suportă o fereastră mare de context, dar îți recomand să începi cu 100.000 de tokenuri în loc de întregul context de 256K, pentru a face configurarea mai ușor de testat și depanat.
Am folosit Hyperbolic pentru că oferă acces la o mașină virtuală GPU completă, ceea ce face mai ușoară instalarea Docker, configurarea runtime-ului NVIDIA pentru containere și rularea manuală a imaginii Docker SGLang. Poți folosi și platforme precum RunPod sau Vast.ai, dar unele dintre instanțele lor sunt deja legate de medii Docker personalizate, ceea ce îți oferă mai puțin control.
În Hyperbolic, selectează H100 PCIe 80GB, alege 4 GPU-uri, adaugă aproximativ 3TB stocare, introdu cheia publică SSH și dă un nume instanței, de exemplu MM-35. Am ales H100 PCIe pentru că a fost cea mai ieftină opțiune H100 disponibilă pentru acest test.
După ce dai clic pe Start Building, mașina poate avea nevoie de aproximativ 10 minute pentru a porni. Când e gata, Hyperbolic îți va afișa comanda de acces SSH de care ai nevoie pentru pasul următor.
După ce instanța e gata, conectează-te din terminalul local folosind comanda SSH afișată în panoul Hyperbolic:
ssh ubuntu@XXXXXXPentru a accesa ulterior API-ul SGLang de pe mașina ta locală, poți de asemenea să redirecționezi portul 30000:
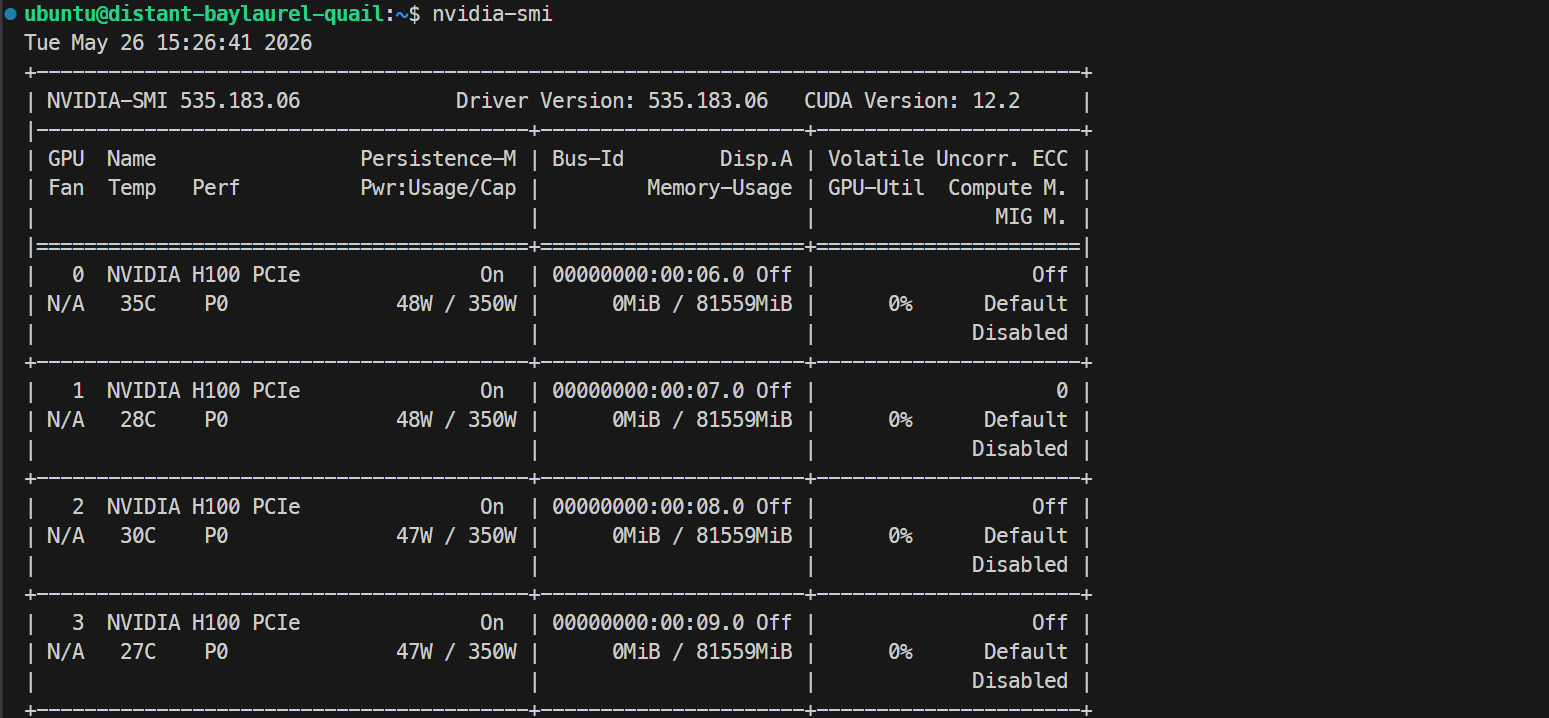
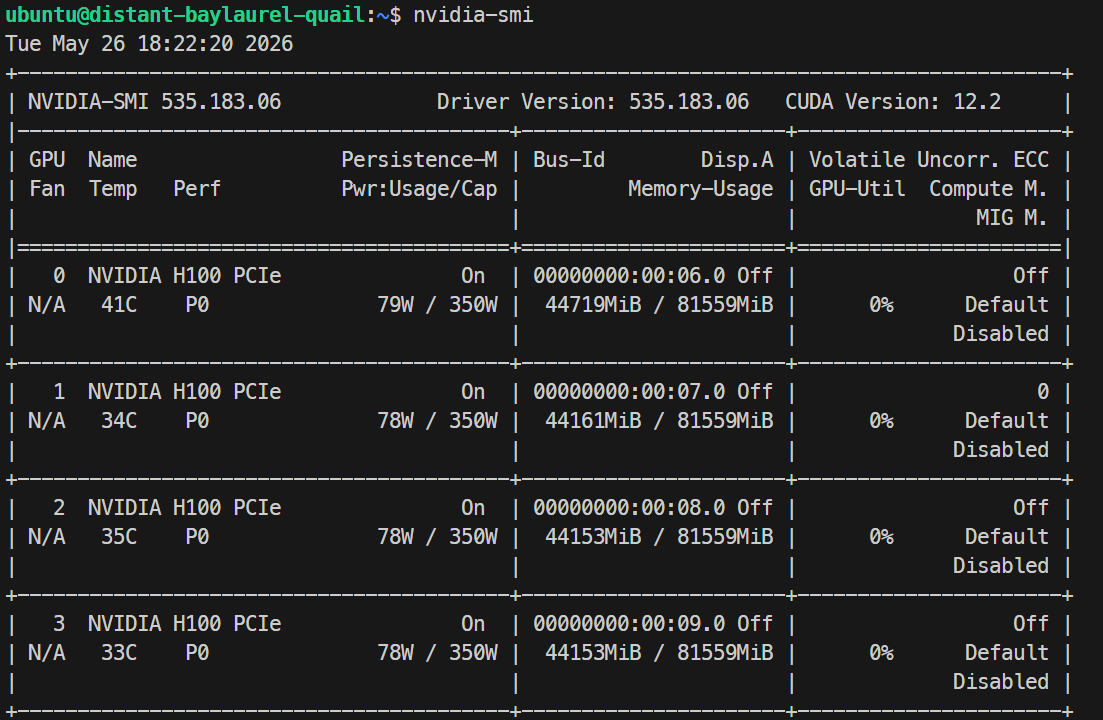
ssh -L 30000:localhost:30000 ubuntu@XXXXXXDacă cheia ta SSH are o parolă, introdu-o când ți se solicită. După autentificare, verifică dacă toate GPU-urile sunt disponibile:
Nvidia-smiAr trebui să vezi listate 4× NVIDIA H100 PCIe 80GB. Asta confirmă că serverul este gata pentru configurarea Docker și SGLang.
Mai întâi, exportă tokenul tău Hugging Face ca serverul să poată descărca ulterior modelul Mistral:
echo 'export HF_TOKEN="your_huggingface_token_here"' >> ~/.bashrc
source ~/.bashrcNotă: Poți obține tokenul Hugging Face de pe pagina Access Tokens.
Creează folderul de cache Hugging Face:
mkdir -p ~/.cache/huggingfaceAcum instalează Docker:
sudo apt update
sudo apt install -y docker.ioPornește Docker și activează-l să ruleze automat după reboot:
sudo systemctl start docker
sudo systemctl enable dockerVerifică dacă Docker a fost instalat corect:
docker –versionPoți folosi și comanda de căutare Docker pentru a confirma că poate căuta imagini publice din Docker Hub:
docker search nvidia/cudaAr trebui să returneze imagini NVIDIA CUDA disponibile. Mai târziu, vom folosi una dintre aceste imagini CUDA pentru a verifica dacă Docker poate accesa GPU-urile.
În continuare, permite utilizatorului tău să ruleze comenzi Docker fără sudo:
sudo usermod -aG docker $USER
newgrp dockerAcum instalează și configurează NVIDIA Container Toolkit ca Docker să poată accesa GPU-urile:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/libnvidia-container/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt update
sudo apt install -y nvidia-container-toolkit
sudo nvidia-ctk runtime configure --runtime=docker
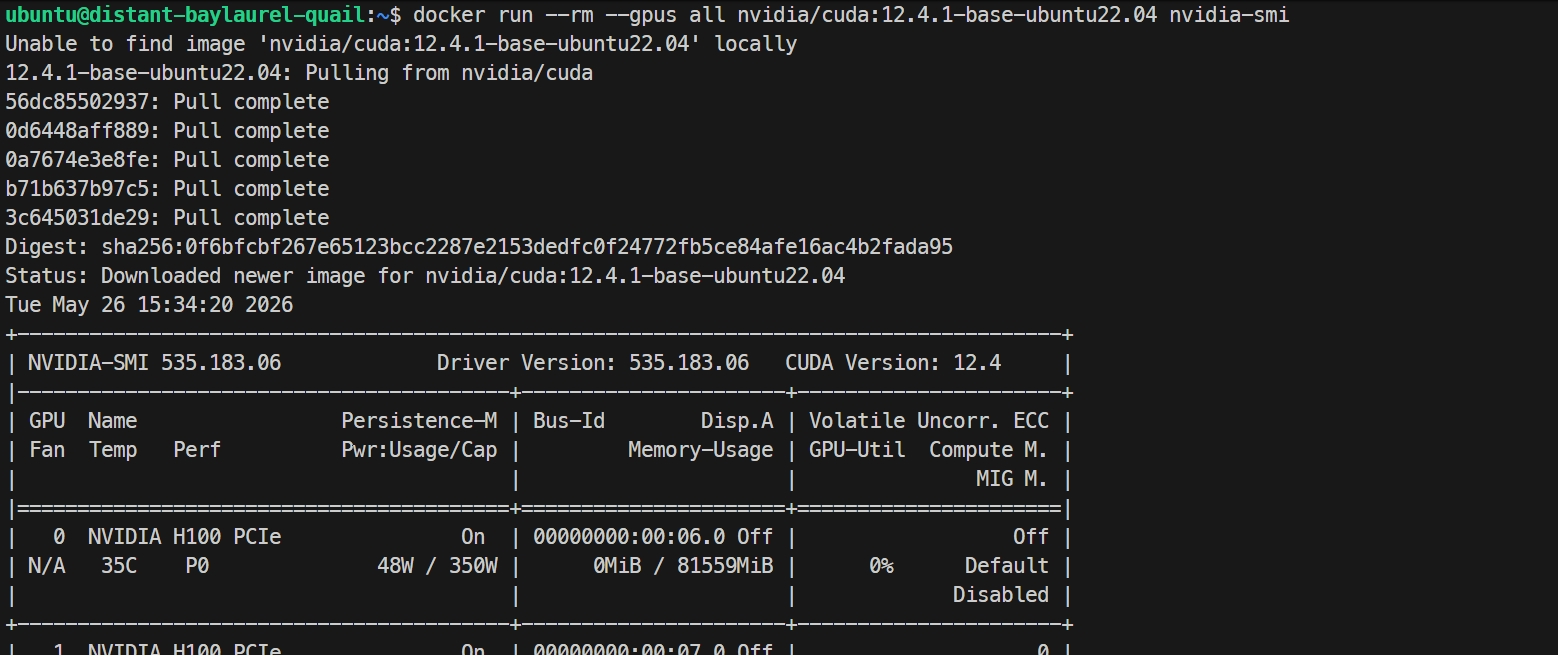
sudo systemctl restart dockerÎn final, testează dacă Docker vede GPU-urile din interiorul unui container:
docker run --rm --gpus all nvidia/cuda:12.4.1-base-ubuntu22.04 nvidia-smiDacă afișează aceeași listă de GPU-uri H100 în containerul Docker, configurația ta GPU Docker funcționează corect.
În continuare, descarcă imaginea Docker SGLang construită pentru Mistral Medium 3.5:
docker pull lmsysorg/sglang:dev-mistral-medium-3.5
Acest pas poate dura ceva timp, în funcție de viteza internetului. În cazul meu, a durat în jur de 10 minute. După ce imaginea este descărcată, Docker va afișa un mesaj de succes similar cu:
Status: Downloaded newer image for lmsysorg/sglang:dev-mistral-medium-3.5Acum pornește serverul SGLang:
docker run -d \
--name mistral-sglang \
--gpus all \
--shm-size 64g \
--ipc=host \
--cap-add SYS_NICE \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e HF_TOKEN=$HF_TOKEN \
-e PYTORCH_ALLOC_CONF=expandable_segments:True \
lmsysorg/sglang:dev-mistral-medium-3.5 \
sglang serve \
--model-path mistralai/Mistral-Medium-3.5-128B \
--served-model-name mistral-medium-3.5 \
--host 0.0.0.0 \
--port 30000 \
--tp 4 \
--trust-remote-code \
--dtype bfloat16 \
--context-length 100000 \
--mem-fraction-static 0.85 \
--disable-custom-all-reduce \
--tool-call-parser mistral \
--reasoning-parser mistralAm folosit --dtype bfloat16 deoarece configurația EAGLE de mai târziu necesită și bf16, așa că menținerea aliniată a rulării de bază și a celei speculative evită schimbarea dtype-ului între teste. Am început și cu --context-length 100000 în locul întregii ferestre de context, pentru a face prima rulare mai ușor de depanat.
Verifică jurnalele containerului cu:
docker logs -f mistral-sglang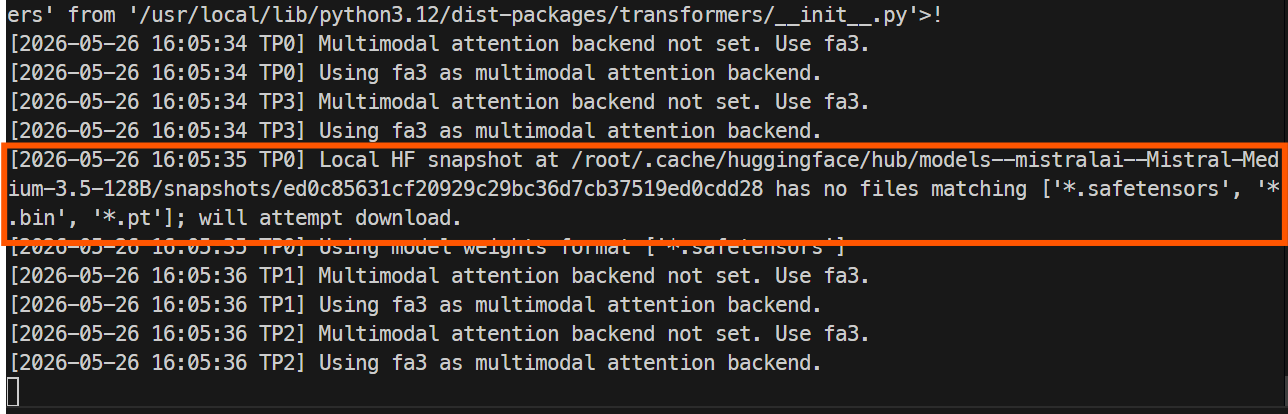
Prima pornire va dura mai mult deoarece SGLang trebuie să descarce fișierele modelului de pe Hugging Face. Repository-ul complet este mare, astfel că poate dura în jur de o oră sau mai mult, în funcție de viteza instanței tale.
Când serverul este gata, jurnalele ar trebui să arate că Uvicorn rulează pe portul 30000.
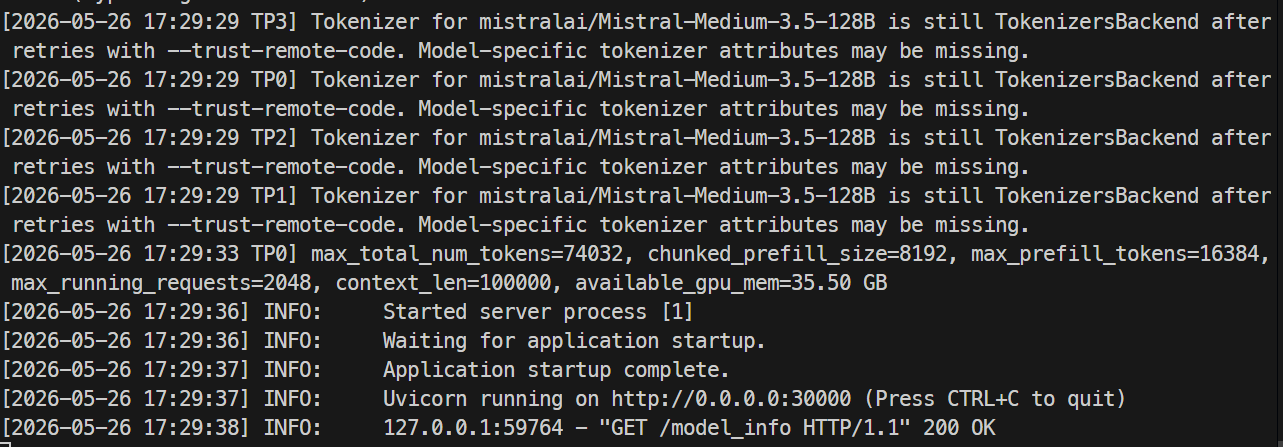
Într-un alt terminal, conectează-te din nou prin SSH la server și verifică endpointul modelului:
curl http://localhost:30000/v1/modelsAr trebui să vezi mistral-medium-3.5 listat cu un max_model_len de 100000.
{"object":"list","data":[{"id":"mistral-medium-3.5","object":"model","created":1779816738,"owned_by":"sglang","root":"mistral-medium-3.5","parent":null,"max_model_len":100000}]}În final, testează un chat completion:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mistral-medium-3.5",
"messages": [
{
"role": "user",
"content": "Write a short introduction to Mistral Medium 3.5."
}
],
"max_tokens": 300,
"temperature": 0.7,
"top_p": 0.95
}'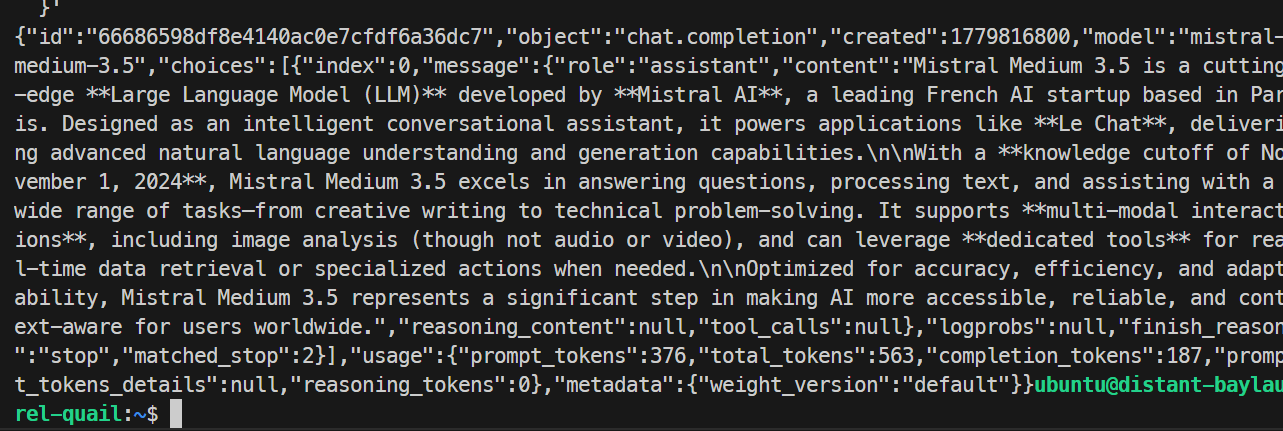
În testul meu, modelul a răspuns cu succes și a finalizat cererea corect, confirmând că endpointul SGLang funcționează. Rularea de bază a generat aproximativ 35,6 tokenuri pe secundă.
Decodarea speculativă poate accelera generarea folosind un model de schiță mai mic pentru a prezice tokenuri în avans, în timp ce modelul principal le verifică.
EAGLE este util aici deoarece este conceput pentru servire sensibilă la latență, mai ales când rulezi local un model mare precum Mistral Medium 3.5. Nu va fi întotdeauna mai rapid, dar merită testat, deoarece beneficiul depinde de lungimea promptului, lungimea rezultatului, concurență și utilizarea GPU-ului.
Mai întâi, oprește și șterge containerul de bază:
docker rm -f mistral-sglangApoi pornește versiunea EAGLE:
docker run -d \
--name mistral-sglang-eagle \
--gpus all \
--shm-size 64g \
--ipc=host \
--cap-add SYS_NICE \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e HF_TOKEN="$HF_TOKEN" \
-e PYTORCH_ALLOC_CONF=expandable_segments:True \
lmsysorg/sglang:dev-mistral-medium-3.5 \
sglang serve \
--model-path mistralai/Mistral-Medium-3.5-128B \
--served-model-name mistral-medium-3.5-eagle \
--host 0.0.0.0 \
--port 30000 \
--tp 4 \
--trust-remote-code \
--dtype bfloat16 \
--context-length 100000 \
--mem-fraction-static 0.85 \
--disable-custom-all-reduce \
--tool-call-parser mistral \
--reasoning-parser mistral \
--enable-metrics \
--speculative-algorithm EAGLE \
--speculative-draft-model-path mistralai/Mistral-Medium-3.5-128B-EAGLE \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4SGLang recomandă această configurație EAGLE ca punct de plecare bun: --speculative-num-steps 3, --speculative-eagle-topk 1 și --speculative-num-draft-tokens 4. Prima rulare poate dura mai mult deoarece descarcă și modelul de schiță EAGLE.
După încărcare, poți verifica utilizarea GPU-ului cu nvidia-smi; în rularea mea, modelul a folosit aproximativ 44GB per GPU H100.
Monitorizează jurnalele cu:
docker logs -f mistral-sglang-eagle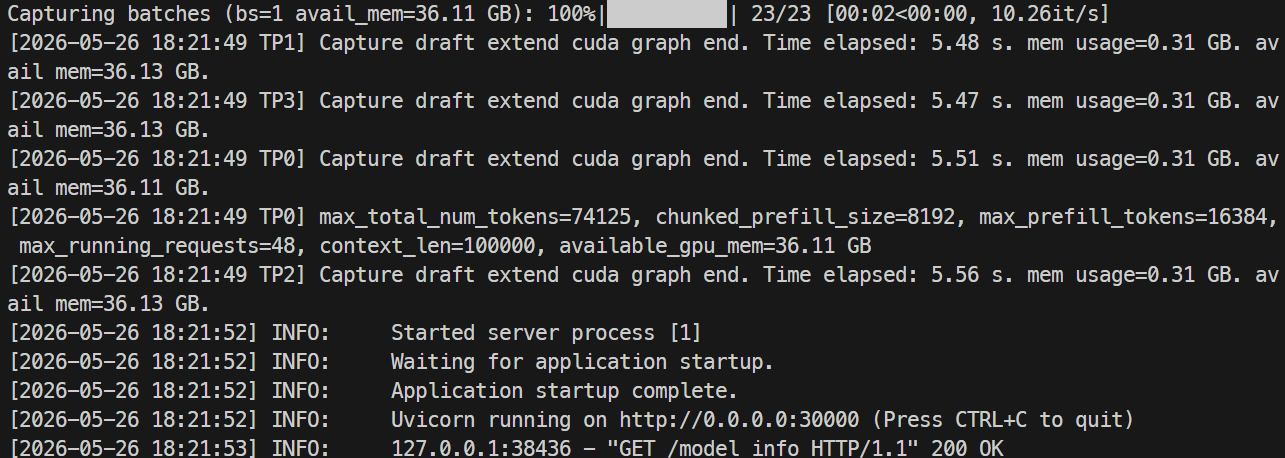
Când jurnalele arată că Uvicorn rulează pe 0.0.0.0:30000, testează endpointul:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mistral-medium-3.5-eagle",
"messages": [
{
"role": "user",
"content": "Generate a simple Python game."
}
],
"reasoning_effort": "none",
"max_tokens": 300,
"temperature": 0.7,
"top_p": 0.95
}'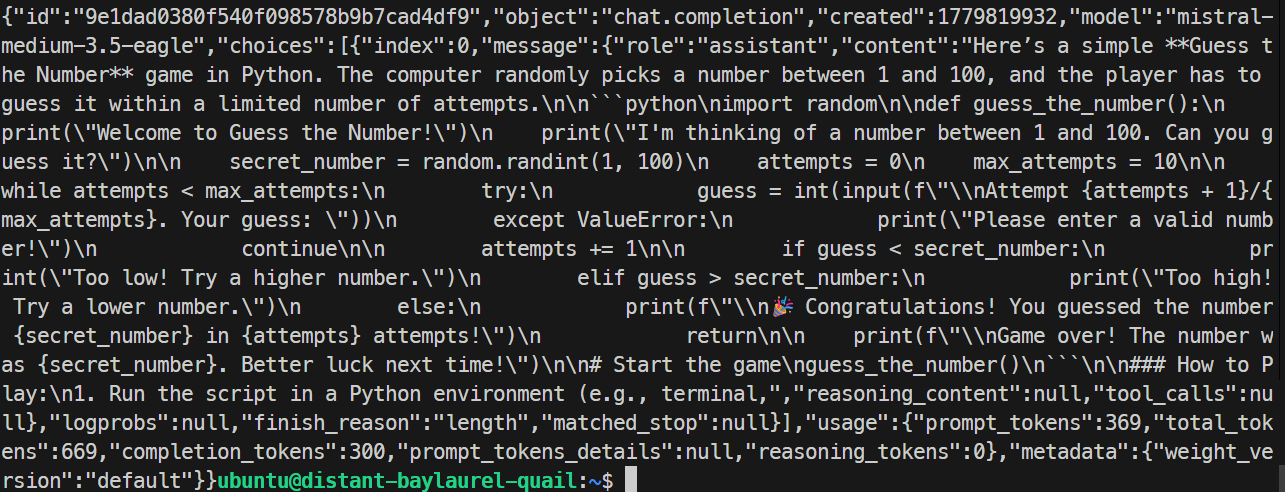
În testul meu, serverul EAGLE a răspuns corect și a generat un joc Python simplu. Rularea a atins aproximativ 32 de tokenuri pe secundă, puțin mai lent decât rularea de bază, deci EAGLE nu a îmbunătățit acest test specific.
Este normal: decodarea speculativă depinde mult de sarcină, iar cel mai bun mod de a o evalua este să o testezi cu propriile prompturi și nivel de concurență.
OpenCode este un agent AI open-source pentru cod care se poate conecta la endpointuri de model compatibile cu OpenAI. Deoarece SGLang expune Mistral Medium 3.5 printr-un API local compatibil cu OpenAI, îl putem folosi direct în OpenCode.
Instalează OpenCode dacă nu ai făcut-o deja:
curl -fsSL https://opencode.ai/install | bashApoi intră în directorul proiectului tău și creează un fișier opencode.json.
Adaugă următoarea configurație:
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"sglang": {
"npm": "@ai-sdk/openai-compatible",
"name": "SGLang Local",
"options": {
"baseURL": "http://127.0.0.1:30000/v1",
"apiKey": "EMPTY"
},
"models": {
"mistral-medium-3.5-eagle": {
"name": "Mistral Medium 3.5 EAGLE",
"limit": {
"context": 100000,
"output": 8192
}
}
}
}
},
"model": "sglang/mistral-medium-3.5-eagle"
}Acum pornește OpenCode din același director al proiectului:
OpencodeAr trebui să vezi Mistral Medium 3.5 EAGLE SGLang Local selectat în OpenCode. Asta înseamnă că OpenCode comunică acum cu serverul tău local SGLang prin portul 30000 redirecționat, exact cum ar apela orice API compatibil cu OpenAI.
În testul meu, am cerut OpenCode să explice proiectul, iar acesta a citit fișierele repository-ului în câteva secunde și a generat un rezumat.
Apoi i-am cerut să creeze un emulator Badger 2040, iar mai întâi a inspectat fișierele existente ale proiectului, a validat structura și apoi a creat fișierul Python necesar. Întregul proces a durat aproximativ 2 minute.
După aceea, i-am cerut să testeze emulatorul local. OpenCode a rulat codul și a deschis cu succes fereastra emulatorului.
Fontul nu era exact același ca pe ecranul real Badger 2040, dar layoutul, afișajul orei, plasarea datei și structura generală au fost aproape perfecte.

Am fost sincer surprins de rezultat, pentru că încercasem aceeași sarcină înainte cu Claude Code și GPT-5.5, iar ambele s-au chinuit cu ea, în timp ce Mistral Medium 3.5 s-a descurcat foarte bine prin configurația locală SGLang.
Există câteva capcane pe parcurs. Te trec prin problemele pe care le-ai putea întâlni și cum să le rezolvi.
În primul rând, va trebui să ai răbdare. Întreaga configurare mi-a luat aproape 3 ore. Lansarea VM-ului GPU a durat aproximativ 15 minute, instalarea Docker și a toolkitului NVIDIA pentru containere aproximativ 10 minute, descărcarea imaginii Docker SGLang în jur de 30 de minute, iar descărcarea și încărcarea greutăților modelului Mistral Medium 3.5 în jur de 1 oră.
Pornirea configurației EAGLE durează și ea în plus, deoarece încarcă din nou modelul și poate descărca modelul de schiță EAGLE. Dacă vrei o experiență mai fluidă, folosește o rețea mai rapidă, GPU-uri mai noi precum H200 dacă sunt disponibile și suficientă stocare pentru întregul cache Hugging Face.
Dacă nvidia-smi funcționează pe host, dar Docker nu poate accesa GPU-urile, probabil runtime-ul NVIDIA pentru containere nu este configurat corect. Rulează din nou configurarea NVIDIA Container Toolkit și repornește Docker:
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart dockerDocumentația NVIDIA recomandă și acest pas de configurare a runtime-ului nvidia-ctk pentru accesul GPU în Docker.
Asigură-te că montezi cache-ul Hugging Face în container:
-v ~/.cache/huggingface:/root/.cache/huggingfaceAstfel Docker poate reutiliza fișierele de model deja descărcate, în loc să le descarce din nou de fiecare dată. Hugging Face folosește un cache local pentru a evita re-descărcarea fișierelor deja actualizate.
Repository-ul Mistral Medium 3.5 este mare, astfel că prima descărcare poate dura mult. Dacă pare blocată, verifică viteza internetului, spațiul pe disc și tokenul Hugging Face. Asigură-te, de asemenea, că ai acceptat pe Hugging Face eventualele condiții necesare pentru accesul la model înainte de a rula containerul.
Serverul nu este gata până când jurnalele nu arată că Uvicorn rulează pe portul 30000. Verifică jurnalele cu:
docker logs -f mistral-sglangsau pentru EAGLE:
docker logs -f mistral-sglang-eagleDe asemenea, asigură-te că portul este expus corect în container cu:
-p 30000:30000Este normal. Decodarea speculativă nu garantează îmbunătățirea fiecărei cereri. Funcționează folosind un model de schiță pentru a propune tokenuri și modelul principal pentru a le verifica, dar accelerarea depinde de rata de acceptare, lungimea promptului, lungimea rezultatului, concurență și utilizarea GPU-ului.
Dacă întâmpini probleme de memorie, reduce mai întâi lungimea contextului. De exemplu, pornește cu --context-length 100000 în loc să încerci imediat întreaga fereastră de context. Poți reduce ușor și --mem-fraction-static dacă pornirea eșuează, dar reducerea lungimii contextului este de obicei cel mai simplu prim pas.
Asigură-te că serverul SGLang rulează și că fișierul tău opencode.json folosește endpointul local corect:
"baseURL": "http://127.0.0.1:30000/v1"Dacă accesezi serverul de pe mașina locală, pornește SSH cu redirecționare de port:
ssh -L 30000:localhost:30000 ubuntu@XXXXXXApoi pornește OpenCode din același director în care este salvat fișierul opencode.json.
Am fost sincer surprins de cât de lin a decurs configurarea tehnică. Rularea Mistral Medium 3.5 128B cu imaginea Docker SGLang nativă a fost mult mai ușoară decât mă așteptam. Imaginea Docker s-a descărcat corect, modelul s-a încărcat, endpointul compatibil cu OpenAI a funcționat, iar OpenCode s-a conectat fără prea multe bătăi de cap. E
dacă încerci și tu, îți recomand cu tărie să folosești imaginea Docker SGLang în loc să instalezi totul prin pachete Python. Când instalezi prin Python, se poate încurca ușor cu CUDA, PyTorch și alte dependențe. Docker păstrează totul curat și izolat.
Dar cel mai important lucru pe care l-am învățat din acest experiment este costul. Sincer, nu știu cum companiile de AI fac bani din inferență. Chiar și cu una dintre opțiunile H100 PCIe mai ieftine și mai vechi, această configurare a fost tot aproape de 10 USD pe oră. Și asta doar pentru un model de 128B pe 4 GPU-uri. Acum imaginează-ți să rulezi un model mult mai mare, cu trilioane de parametri, pe 16× H100. Factura poate ajunge ușor la 40+ USD pe oră, înainte să te gândești măcar la stocare, rețea, monitorizare, disponibilitate și munca de inginerie.
Pentru companiile mici, nu cred că are sens să servești local astfel de modele decât dacă există un motiv foarte puternic, cum ar fi confidențialitatea, cercetarea sau controlul profund asupra stivei de inferență. Costul de inferență este deja ridicat, dar și povara operațională e o problemă. Trebuie să ții serverul pornit, să te asiguri că modelul nu se prăbușește, să monitorizezi memoria GPU, să gestionezi containerele eșuate și să menții endpointul disponibil.
Serverless nici nu rezolvă cu adevărat asta pentru modele foarte mari. Timpul de cold start este pur și simplu prea lung. În această configurare, lansarea VM-ului GPU, instalarea dependențelor, descărcarea imaginii Docker, descărcarea greutăților și încărcarea modelului au durat aproape 3 ore în total.
Chiar dacă setup-ul tău e mai rapid, încărcarea unui model de această dimensiune poate dura mult. Așa că, dacă fiecare cerere nouă necesită lansarea unui alt cluster GPU și încărcarea modelului din nou, se anulează scopul serverless. În practică, companiile trebuie să mențină clustere GPU „calde”, ceea ce înseamnă că plătesc chiar și când GPU-urile sunt inactivate.
Asta explică și de ce există prețuri off-peak pentru GPU. Furnizorii vor ca oamenii să folosească capacitatea GPU inactivă, pentru că GPU-urile neutilizate doar ard bani. Pentru utilizatori, acesta poate fi un mod bun de a experimenta mai ieftin, dar arată și cât de dificile sunt economiile inferenței pe modele mari.
Per total, mi-a plăcut foarte mult SGLang pentru această configurare. Fluxul de lucru bazat pe Docker a făcut servirea Mistral Medium 3.5 128B mult mai ușoară decât mă așteptam, iar testul cu OpenCode a fost cu adevărat impresionant. Dar acest experiment mi-a arătat și ceva foarte clar: rularea locală a modelelor mari open este posibilă, însă rularea lor fiabilă și la costuri acceptabile ca produs real este o provocare cu totul diferită.
Învață AI cu DataCamp!
track
course
course