Tracks
วิศวกร AI ระดับ Associate สำหรับนักพัฒนา
26 ชม.
สำหรับคู่มือนี้ ฉันใช้เครื่องเสมือน GPU แบบ 4× H100 80GB Mistral Medium 3.5 เป็นโมเดล dense ขนาด 128B จึงต้องใช้การตั้งค่าหลาย GPU SGLang แนะนำให้รันด้วย tensor parallelism โดยใช้ --tp 4 บน GPU รุ่น H100 หรือ H200 โมเดลรองรับหน้าต่างบริบทขนาดใหญ่ แต่ขอแนะนำให้เริ่มจาก 100,000 โทเค็น ก่อน แทนที่จะใช้ 256K เต็ม เพื่อให้ง่ายต่อการทดสอบและดีบัก
ฉันใช้ Hyperbolic เพราะให้เข้าถึง VM ที่มี GPU เต็มรูปแบบ ทำให้ติดตั้ง Docker ตั้งค่า NVIDIA container runtime และรันอิมเมจ Docker ของ SGLang ด้วยตนเองได้ง่าย คุณยังสามารถใช้แพลตฟอร์มอย่าง RunPod หรือ Vast.ai ได้ แต่บางอินสแตนซ์ของพวกเขาผูกกับสภาพแวดล้อม Docker แบบกำหนดเองอยู่แล้ว ซึ่งทำให้ควบคุมน้อยลง
ใน Hyperbolic ให้เลือก H100 PCIe 80GB เลือก 4 GPUs เพิ่มพื้นที่เก็บข้อมูลประมาณ 3TB ป้อน SSH public key และตั้งชื่ออินสแตนซ์ เช่น MM-35 ฉันเลือก H100 PCIe เพราะเป็นตัวเลือก H100 ที่ถูกที่สุดสำหรับการทดสอบนี้
หลังจากคลิก Start Building เครื่องอาจใช้เวลาประมาณ 10 นาทีในการเริ่มทำงาน เมื่อพร้อมแล้ว Hyperbolic จะแสดงคำสั่ง SSH สำหรับขั้นตอนถัดไป
เมื่ออินสแตนซ์พร้อมแล้ว ให้เชื่อมต่อจากเทอร์มินัลโลคอลด้วยคำสั่ง SSH ที่แสดงในแดชบอร์ด Hyperbolic:
ssh ubuntu@XXXXXXเพื่อเข้าถึง SGLang API จากเครื่องโลคอลภายหลัง สามารถทำพอร์ตฟอร์เวิร์ด 30000 ได้เช่นกัน:
ssh -L 30000:localhost:30000 ubuntu@XXXXXXหากคีย์ SSH มีพาสเฟรส ให้ป้อนเมื่อระบบร้องขอ หลังจากล็อกอินแล้ว ตรวจสอบว่า GPU ทั้งหมดพร้อมใช้งาน:
Nvidia-smiควรเห็น GPU NVIDIA H100 PCIe 80GB จำนวน 4 ตัวอยู่ในรายการ แสดงว่าเซิร์ฟเวอร์พร้อมสำหรับการตั้งค่า Docker และ SGLang แล้ว
ก่อนอื่น export โทเค็น Hugging Face เพื่อให้เซิร์ฟเวอร์ดาวน์โหลดโมเดล Mistral ได้ในภายหลัง:
echo 'export HF_TOKEN="your_huggingface_token_here"' >> ~/.bashrc
source ~/.bashrcหมายเหตุ: สามารถรับโทเค็น Hugging Face ได้จากหน้า Access Tokens
สร้างโฟลเดอร์แคชของ Hugging Face:
mkdir -p ~/.cache/huggingfaceตอนนี้ติดตั้ง Docker:
sudo apt update
sudo apt install -y docker.ioสตาร์ท Docker และตั้งค่าให้รันอัตโนมัติหลังรีบูต:
sudo systemctl start docker
sudo systemctl enable dockerตรวจสอบว่า Docker ติดตั้งถูกต้อง:
docker –versionสามารถใช้คำสั่งค้นหา Docker เพื่อตรวจสอบว่า Docker สามารถค้นหาอิมเมจสาธารณะจาก Docker Hub ได้:
docker search nvidia/cudaควรแสดงอิมเมจ NVIDIA CUDA ที่พร้อมใช้งาน ภายหลัง เราจะใช้อิมเมจ CUDA เหล่านี้ตัวใดตัวหนึ่งเพื่อตรวจสอบว่า Docker เข้าถึง GPU ได้
ถัดไป อนุญาตให้ผู้ใช้ของคุณรันคำสั่ง Docker โดยไม่ต้องใช้ sudo:
sudo usermod -aG docker $USER
newgrp dockerจากนั้นติดตั้งและตั้งค่า NVIDIA Container Toolkit เพื่อให้ Docker เข้าถึง GPU ได้:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/libnvidia-container/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt update
sudo apt install -y nvidia-container-toolkit
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart dockerท้ายสุด ทดสอบว่า Docker มองเห็น GPU ได้จากในคอนเทนเนอร์:
docker run --rm --gpus all nvidia/cuda:12.4.1-base-ubuntu22.04 nvidia-smiหากแสดงรายการ GPU H100 เดิมภายในคอนเทนเนอร์ Docker แสดงว่าการตั้งค่า GPU ของ Docker ทำงานถูกต้อง
ถัดไป ดึงอิมเมจ Docker ของ SGLang ที่สร้างมาสำหรับ Mistral Medium 3.5:
docker pull lmsysorg/sglang:dev-mistral-medium-3.5
อาจใช้เวลาสักครู่ขึ้นอยู่กับความเร็วอินเทอร์เน็ต ในกรณีของฉันใช้เวลาประมาณ 10 นาที เมื่อดาวน์โหลดอิมเมจเสร็จ Docker จะแสดงข้อความสำเร็จคล้ายกับ:
Status: Downloaded newer image for lmsysorg/sglang:dev-mistral-medium-3.5ตอนนี้เริ่มเซิร์ฟเวอร์ SGLang:
docker run -d \
--name mistral-sglang \
--gpus all \
--shm-size 64g \
--ipc=host \
--cap-add SYS_NICE \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e HF_TOKEN=$HF_TOKEN \
-e PYTORCH_ALLOC_CONF=expandable_segments:True \
lmsysorg/sglang:dev-mistral-medium-3.5 \
sglang serve \
--model-path mistralai/Mistral-Medium-3.5-128B \
--served-model-name mistral-medium-3.5 \
--host 0.0.0.0 \
--port 30000 \
--tp 4 \
--trust-remote-code \
--dtype bfloat16 \
--context-length 100000 \
--mem-fraction-static 0.85 \
--disable-custom-all-reduce \
--tool-call-parser mistral \
--reasoning-parser mistralฉันใช้ --dtype bfloat16 เพราะการตั้งค่า EAGLE ภายหลังก็ต้องใช้ bf16 เช่นกัน จึงคงค่า dtype ให้ตรงกันทั้งรันพื้นฐานและรันแบบ speculative เพื่อลดการเปลี่ยน dtype ระหว่างการทดสอบ นอกจากนี้ฉันเริ่มด้วย --context-length 100000 แทนหน้าต่างบริบทยาวสุดเพื่อให้การรันครั้งแรกดีบักได้ง่าย
ตรวจสอบล็อกของคอนเทนเนอร์ด้วย:
docker logs -f mistral-sglang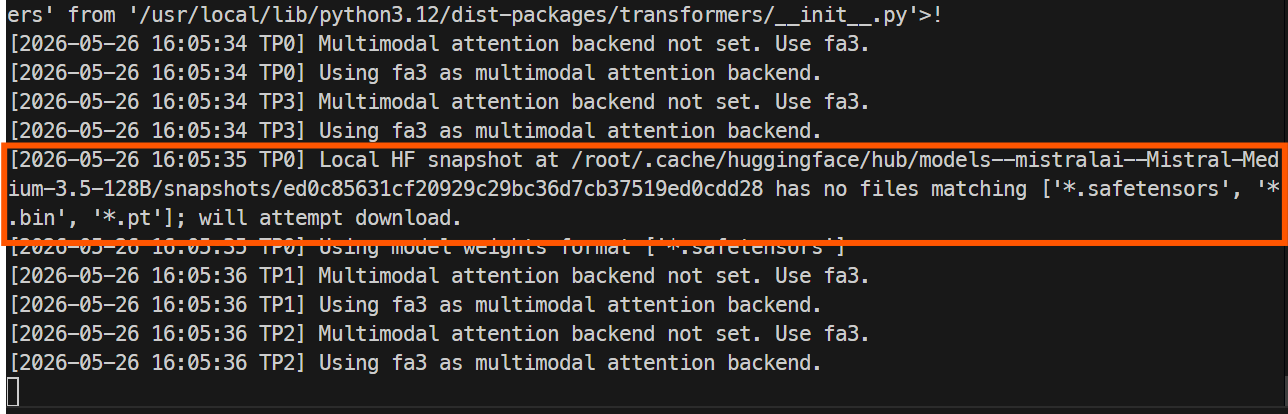
การเปิดครั้งแรกจะใช้เวลานานกว่า เพราะ SGLang ต้องดาวน์โหลดไฟล์โมเดลจาก Hugging Face ที่เก็บทั้งชุดมีขนาดใหญ่ จึงอาจใช้เวลาประมาณชั่วโมงหนึ่งหรือมากกว่านั้น ขึ้นอยู่กับความเร็วของอินสแตนซ์
เมื่อเซิร์ฟเวอร์พร้อม ล็อกควรจะแสดงว่า Uvicorn กำลังรันบนพอร์ต 30000
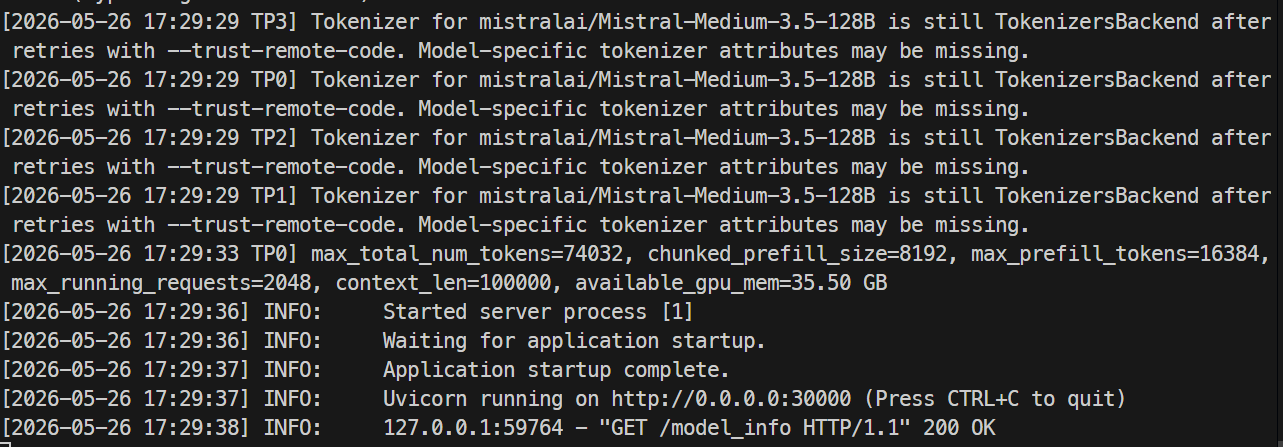
ในเทอร์มินัลอีกหน้าต่าง ให้ SSH เข้าสู่เซิร์ฟเวอร์อีกครั้งและตรวจสอบเอ็นด์พอยน์ต์ของโมเดล:
curl http://localhost:30000/v1/modelsควรเห็น mistral-medium-3.5 พร้อมค่า max_model_len เป็น 100000
{"object":"list","data":[{"id":"mistral-medium-3.5","object":"model","created":1779816738,"owned_by":"sglang","root":"mistral-medium-3.5","parent":null,"max_model_len":100000}]}สุดท้าย ทดสอบการทำงานของแชต completion:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mistral-medium-3.5",
"messages": [
{
"role": "user",
"content": "Write a short introduction to Mistral Medium 3.5."
}
],
"max_tokens": 300,
"temperature": 0.7,
"top_p": 0.95
}'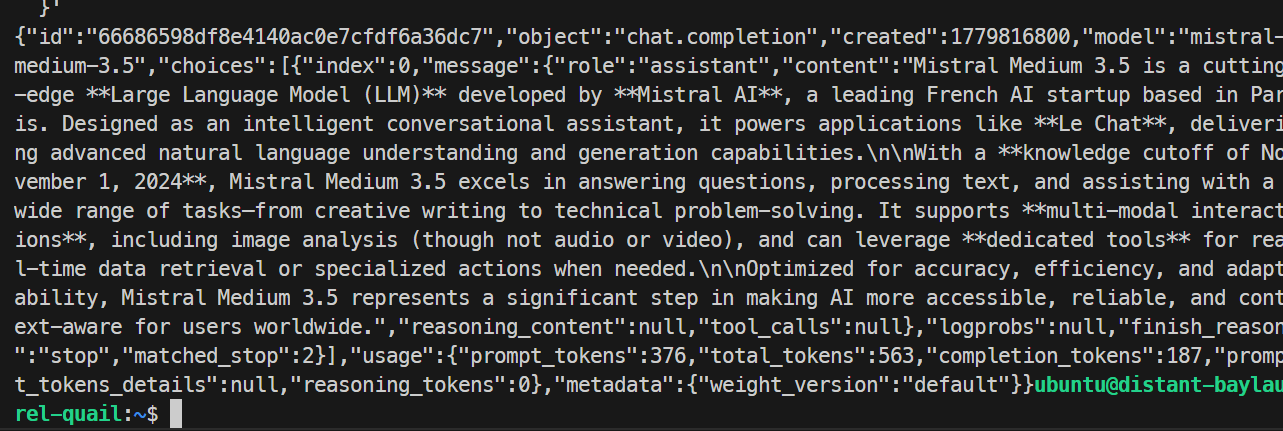
ในการทดสอบของฉัน โมเดลตอบกลับสำเร็จและประมวลผลคำขอได้อย่างเรียบร้อย ยืนยันว่าเอ็นด์พอยน์ต์ SGLang ทำงานแล้ว การรันพื้นฐานคร่าว ๆ ได้ประมาณ 35.6 โทเค็นต่อวินาที
Speculative decoding สามารถเร่งความเร็วการสร้างผลลัพธ์ด้วยการใช้โมเดลแบบร่างที่เล็กกว่าคาดเดาโทเค็นล่วงหน้า ขณะที่โมเดลหลักทำการยืนยัน
EAGLE มีประโยชน์ในที่นี้เพราะออกแบบมาสำหรับการให้บริการที่ไวต่อระยะหน่วง โดยเฉพาะเมื่อรันโมเดลขนาดใหญ่แบบโลคอลอย่าง Mistral Medium 3.5 มันอาจไม่เร็วกว่าเสมอไป แต่ก็คุ้มค่าที่จะทดสอบ เพราะประโยชน์ขึ้นอยู่กับความยาวพรอมป์ ความยาวผลลัพธ์ ความขนานของคำขอ และการใช้งาน GPU
ก่อนอื่น ลบคอนเทนเนอร์พื้นฐาน:
docker rm -f mistral-sglangจากนั้นเริ่มเวอร์ชัน EAGLE:
docker run -d \
--name mistral-sglang-eagle \
--gpus all \
--shm-size 64g \
--ipc=host \
--cap-add SYS_NICE \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e HF_TOKEN="$HF_TOKEN" \
-e PYTORCH_ALLOC_CONF=expandable_segments:True \
lmsysorg/sglang:dev-mistral-medium-3.5 \
sglang serve \
--model-path mistralai/Mistral-Medium-3.5-128B \
--served-model-name mistral-medium-3.5-eagle \
--host 0.0.0.0 \
--port 30000 \
--tp 4 \
--trust-remote-code \
--dtype bfloat16 \
--context-length 100000 \
--mem-fraction-static 0.85 \
--disable-custom-all-reduce \
--tool-call-parser mistral \
--reasoning-parser mistral \
--enable-metrics \
--speculative-algorithm EAGLE \
--speculative-draft-model-path mistralai/Mistral-Medium-3.5-128B-EAGLE \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4SGLang แนะนำการตั้งค่า EAGLE นี้เป็นจุดเริ่มต้นที่ดี: --speculative-num-steps 3, --speculative-eagle-topk 1 และ --speculative-num-draft-tokens 4 การรันครั้งแรกอาจใช้เวลานานขึ้นเพราะต้องดาวน์โหลดโมเดลร่าง EAGLE ด้วย
เมื่อโหลดเสร็จ สามารถตรวจสอบการใช้งาน GPU ด้วย nvidia-smi ในการรันของฉัน โมเดลใช้หน่วยความจำประมาณ 44GB ต่อ H100 GPU
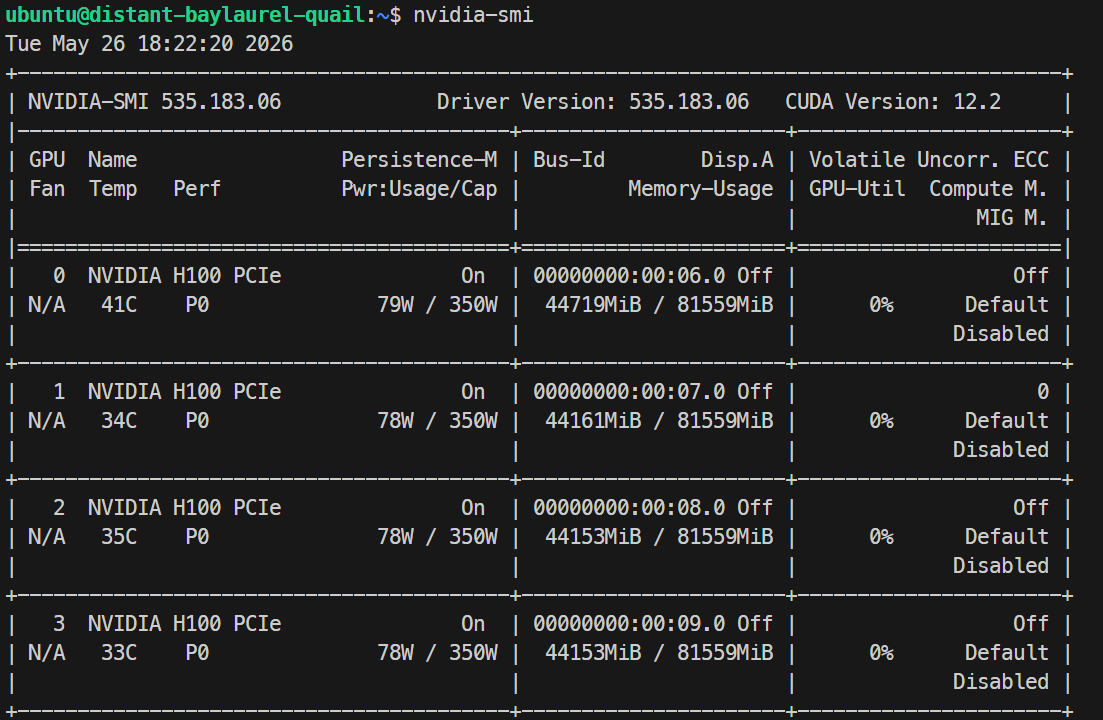
ติดตามล็อกด้วย:
docker logs -f mistral-sglang-eagle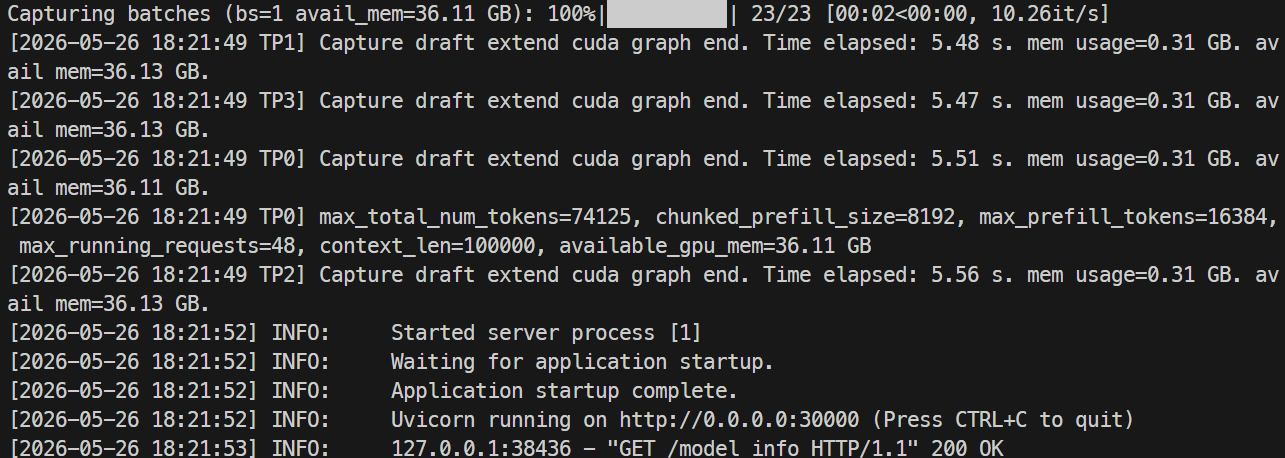
เมื่อเห็นในล็อกว่า Uvicorn กำลังรันบน 0.0.0.0:30000 ให้ทดสอบเอ็นด์พอยน์ต์:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mistral-medium-3.5-eagle",
"messages": [
{
"role": "user",
"content": "Generate a simple Python game."
}
],
"reasoning_effort": "none",
"max_tokens": 300,
"temperature": 0.7,
"top_p": 0.95
}'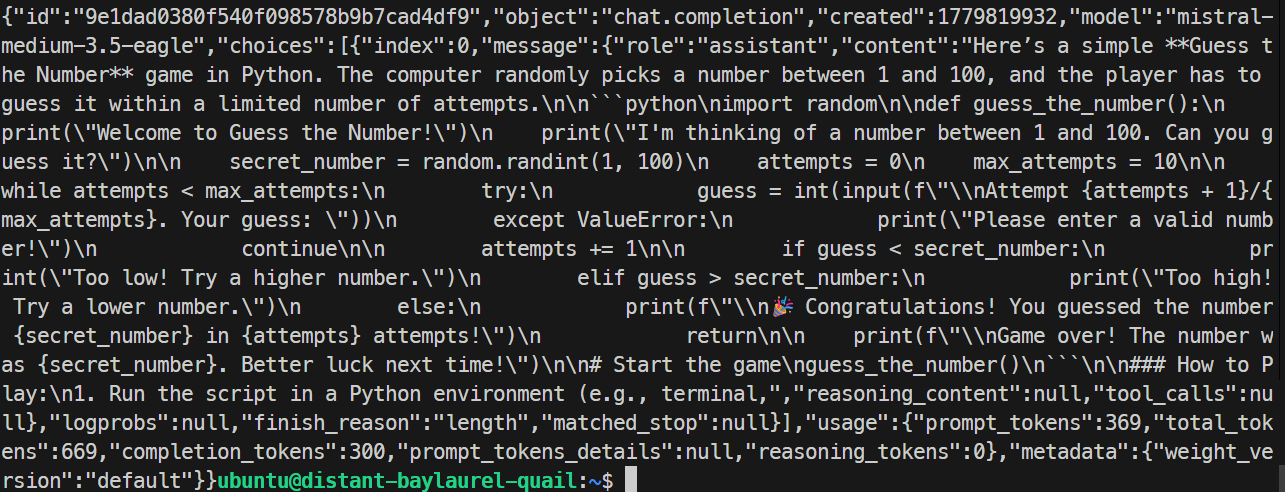
ในการทดสอบของฉัน เซิร์ฟเวอร์ EAGLE ตอบกลับถูกต้องและสร้างเกม Python อย่างง่าย การรันได้ประมาณ 32 โทเค็นต่อวินาที ซึ่งช้ากว่ารันพื้นฐานเล็กน้อย ดังนั้น EAGLE ไม่ได้ช่วยในเคสนี้
นี่เป็นเรื่องปกติ: ประสิทธิภาพของ speculative decoding ขึ้นอยู่กับเวิร์กโหลด วิธีที่ดีที่สุดในการประเมินคือทดสอบด้วยพรอมป์และระดับ concurrency ของงานจริง
OpenCode เป็นเอเจนต์โค้ด AI แบบโอเพนซอร์สที่เชื่อมต่อกับเอ็นด์พอยน์ต์โมเดลที่เข้ากันได้กับ OpenAI ได้ เนื่องจาก SGLang เปิดให้ใช้งาน Mistral Medium 3.5 ผ่าน API แบบโลคอลที่เข้ากันได้กับ OpenAI เราจึงใช้มันใน OpenCode ได้โดยตรง
ติดตั้ง OpenCode หากยังไม่ได้ติดตั้ง:
curl -fsSL https://opencode.ai/install | bashจากนั้นเข้าไปยังไดเรกทอรีโปรเจ็กต์และสร้างไฟล์ opencode.json
เพิ่มการตั้งค่าต่อไปนี้:
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"sglang": {
"npm": "@ai-sdk/openai-compatible",
"name": "SGLang Local",
"options": {
"baseURL": "http://127.0.0.1:30000/v1",
"apiKey": "EMPTY"
},
"models": {
"mistral-medium-3.5-eagle": {
"name": "Mistral Medium 3.5 EAGLE",
"limit": {
"context": 100000,
"output": 8192
}
}
}
}
},
"model": "sglang/mistral-medium-3.5-eagle"
}ตอนนี้เปิด OpenCode จากไดเรกทอรีโปรเจ็กต์เดียวกัน:
Opencodeควรเห็นว่าเลือก Mistral Medium 3.5 EAGLE SGLang Local อยู่ใน OpenCode ซึ่งหมายความว่า OpenCode กำลังสื่อสารกับเซิร์ฟเวอร์ SGLang โลคอลผ่านพอร์ตที่ฟอร์เวิร์ด 30000 เช่นเดียวกับการเรียก API ที่เข้ากันได้กับ OpenAI อื่น ๆ
ในการทดสอบของฉัน ฉันให้ OpenCode อธิบายโปรเจ็กต์ มันอ่านไฟล์ในรีโพภายในไม่กี่วินาทีและสร้างสรุปออกมาได้
ต่อมา ฉันให้มันสร้าง อีมูเลเตอร์ Badger 2040 ซึ่งมันตรวจสอบไฟล์โปรเจ็กต์ที่มีอยู่ก่อน ยืนยันโครงสร้าง และสร้างไฟล์ Python ที่ต้องการ กระบวนการทั้งหมดใช้เวลาประมาณ 2 นาที
หลังจากนั้น ฉันให้มันทดสอบอีมูเลเตอร์แบบโลคอล OpenCode รันโค้ดและเปิดหน้าต่างอีมูเลเตอร์ได้สำเร็จ
แบบอักษรไม่เหมือนกับจอจริงของ Badger 2040 เป๊ะ ๆ แต่เลย์เอาต์ การแสดงเวลา ตำแหน่งวันที่ และโครงสร้างโดยรวมถือว่าแทบสมบูรณ์แบบ

ฉันประทับใจผลลัพธ์จริง ๆ เพราะเคยลองงานเดียวกันกับ Claude Code และ GPT-5.5 มาก่อน และทั้งคู่ทำได้ยาก ขณะที่ Mistral Medium 3.5 จัดการได้ดีมากผ่านการตั้งค่า SGLang แบบโลคอลนี้
มีจุดติดขัดอยู่บ้างระหว่างทาง ขออธิบายปัญหาที่อาจพบและแนวทางแก้ไข
ก่อนอื่นต้องใจเย็น ๆ การตั้งค่าทั้งหมดนี้ใช้เวลารวมเกือบ 3 ชั่วโมง การเปิดตัว VM ที่มี GPU ใช้เวลาราว 15 นาที การติดตั้ง Docker และ NVIDIA container toolkit ใช้เวลาประมาณ 10 นาที การดึงอิมเมจ Docker ของ SGLang ใช้เวลาราว 30 นาที และการดาวน์โหลดพร้อมโหลดเวทของโมเดล Mistral Medium 3.5 ใช้เวลาประมาณ 1 ชั่วโมง
การเริ่มตั้งค่า EAGLE ก็ใช้เวลาเพิ่ม เพราะโหลดโมเดลอีกครั้งและอาจต้องดาวน์โหลดโมเดลร่าง EAGLE หากต้องการประสบการณ์ที่ลื่นไหลขึ้น ให้ใช้เครือข่ายที่เร็วกว่า GPU รุ่นใหม่กว่าอย่าง H200 หากมี และพื้นที่เก็บข้อมูลเพียงพอสำหรับแคช Hugging Face ทั้งหมด
หาก nvidia-smi ใช้ได้บนโฮสต์ แต่ Docker เข้าถึง GPU ไม่ได้ แสดงว่า NVIDIA container runtime อาจยังไม่ถูกตั้งค่าอย่างถูกต้อง ให้รันการตั้งค่า NVIDIA container toolkit ใหม่และรีสตาร์ท Docker:
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart dockerเอกสารของ NVIDIA ยังแนะนำขั้นตอนตั้งค่า runtime ด้วย nvidia-ctk สำหรับการเข้าถึง GPU ของ Docker
ตรวจสอบให้แน่ใจว่าได้เมานต์แคชของ Hugging Face เข้าไปในคอนเทนเนอร์:
-v ~/.cache/huggingface:/root/.cache/huggingfaceนี่ช่วยให้ Docker ใช้ไฟล์โมเดลที่ดาวน์โหลดไว้แล้วซ้ำ แทนที่จะดาวน์โหลดใหม่ทุกครั้ง Hugging Face ใช้แคชโลคอลเพื่อหลีกเลี่ยงการดาวน์โหลดไฟล์ที่เป็นเวอร์ชันล่าสุดอยู่แล้ว
รีโพของ Mistral Medium 3.5 มีขนาดใหญ่ ดังนั้นการดาวน์โหลดครั้งแรกอาจใช้เวลานาน หากดูเหมือนค้าง ให้ตรวจสอบความเร็วอินเทอร์เน็ต พื้นที่ดิสก์ และโทเค็น Hugging Face ตรวจสอบด้วยว่าคุณยอมรับเงื่อนไขการเข้าถึงโมเดลที่จำเป็นบน Hugging Face แล้วก่อนรันคอนเทนเนอร์
เซิร์ฟเวอร์ยังไม่พร้อมจนกว่าล็อกจะแสดงว่า Uvicorn กำลังรันบนพอร์ต 30000 ตรวจสอบล็อกด้วย:
docker logs -f mistral-sglangหรือสำหรับ EAGLE:
docker logs -f mistral-sglang-eagleตรวจสอบด้วยว่าคอนเทนเนอร์เปิดพอร์ตถูกต้องด้วย:
-p 30000:30000เป็นเรื่องปกติ Speculative decoding ไม่ได้การันตีว่าจะเร็วขึ้นทุกคำขอ มันทำงานโดยใช้โมเดลแบบร่างเสนอโทเค็น และโมเดลหลักยืนยัน แต่ความเร็วที่เพิ่มขึ้นขึ้นอยู่กับอัตราการยอมรับ ความยาวพรอมป์ ความยาวผลลัพธ์ ระดับ concurrency และการใช้ GPU
หากเจอปัญหาหน่วยความจำ ให้ลดความยาวบริบทก่อน เช่น เริ่มที่ --context-length 100000 แทนที่จะลองค่าหน้าต่างบริบทยาวสุดทันที นอกจากนี้อาจลดค่า --mem-fraction-static ลงเล็กน้อยหากสตาร์ทไม่ขึ้น แต่โดยทั่วไปการลดความยาวบริบทเป็นขั้นตอนแรกที่ง่ายที่สุด
ตรวจสอบให้แน่ใจว่าเซิร์ฟเวอร์ SGLang กำลังรันอยู่ และไฟล์ opencode.json ใช้เอ็นด์พอยน์ต์โลคอลที่ถูกต้อง:
"baseURL": "http://127.0.0.1:30000/v1"หากเข้าถึงเซิร์ฟเวอร์จากเครื่องโลคอล ให้เริ่ม SSH พร้อมพอร์ตฟอร์เวิร์ด:
ssh -L 30000:localhost:30000 ubuntu@XXXXXXจากนั้นเปิด OpenCode จากไดเรกทอรีเดียวกับที่บันทึกไฟล์ opencode.json
ต้องบอกว่าฉันประหลาดใจกับความลื่นไหลของการตั้งค่าทางเทคนิค การรัน Mistral Medium 3.5 128B ด้วยอิมเมจ Docker แบบเนทีฟของ SGLang ง่ายกว่าที่คาดไว้มาก อิมเมจ Docker ดึงได้ถูกต้อง โมเดลโหลดขึ้น เอ็นด์พอยน์ต์ที่เข้ากันได้กับ OpenAI ทำงาน และ OpenCode ก็เชื่อมต่อได้โดยไม่มีปัญหามากนัก ฉัน
หากจะลองทำเอง ขอแนะนำอย่างยิ่งให้ใช้อิมเมจ Docker ของ SGLang แทนการติดตั้งทุกอย่างผ่านแพ็กเกจ Python เพราะการติดตั้งผ่าน Python อาจทำให้ CUDA, PyTorch และดีเพนเดนซีอื่น ๆ ป่วนได้ง่าย Docker ช่วยให้ทุกอย่างสะอาดและแยกส่วน
แต่สิ่งที่ชัดเจนที่สุดจากการทดลองนี้คือเรื่องต้นทุน ฉันไม่แน่ใจจริง ๆ ว่าบริษัท AI ทำกำไรจากอินเฟอเรนซ์กันอย่างไร แม้จะใช้ตัวเลือก H100 PCIe ที่ถูกและเก่ากว่า การตั้งค่านี้ยังมีต้นทุนเกือบ $10 ต่อชั่วโมง และนี่เป็นเพียงโมเดล 128B บน 4 GPU ลองนึกภาพการรันโมเดลระดับล้านล้านพารามิเตอร์บน H100 16 ตัว บิลสามารถพุ่งไปที่ $40+ ต่อชั่วโมง ได้ง่าย ๆ ก่อนจะคิดถึงค่าเก็บข้อมูล เครือข่าย มอนิเตอร์ อัปไทม์ และงานวิศวกรรม
สำหรับบริษัทขนาดเล็ก ฉันคิดว่าไม่คุ้มที่จะให้บริการโมเดลแบบนี้แบบโลคอล เว้นแต่จะมีเหตุผลที่หนักแน่น เช่น ความเป็นส่วนตัว งานวิจัย หรือการควบคุมสแตกอินเฟอเรนซ์อย่างลึก ต้นทุนอินเฟอเรนซ์สูงอยู่แล้ว และภาระการปฏิบัติการก็เป็นปัญหา ต้องทำให้เซิร์ฟเวอร์รันต่อเนื่อง ดูว่าโมเดลไม่ล่ม เฝ้าหน่วยความจำ GPU จัดการคอนเทนเนอร์ที่ล้มเหลว และคงเอ็นด์พอยน์ต์ให้พร้อมใช้งาน
เซิร์ฟเวอร์เลสเองก็ไม่ได้แก้ปัญหานี้สำหรับโมเดลใหญ่มาก ๆ เพราะเวลาสตาร์ทครั้งแรกยาวเกินไป ในการตั้งค่านี้ การเปิด VM ที่มี GPU ติดตั้งดีเพนเดนซี ดึงอิมเมจ Docker ดาวน์โหลดเวท และโหลดโมเดล ใช้เวลารวมเกือบ 3 ชั่วโมง
ต่อให้การตั้งค่าของคุณเร็วกว่า การโหลดโมเดลขนาดนี้ก็ยังใช้เวลานานอยู่ดี ดังนั้นหากทุกคำขอต้องเปิดคลัสเตอร์ GPU ใหม่และโหลดโมเดลอีกครั้ง ก็ขัดกับแนวคิดของเซิร์ฟเวอร์เลส ในทางปฏิบัติ บริษัทต้องคงคลัสเตอร์ GPU ให้อุ่นอยู่เสมอ หมายความว่าต้องจ่ายเงินแม้ GPU จะว่างงาน
นี่ยังอธิบายว่าทำไมจึงมีราคา GPU ช่วงนอกพีค ผู้ให้บริการต้องการให้คนใช้ความจุ GPU ที่ว่าง เพราะ GPU ที่ไม่ได้ใช้คือค่าใช้จ่ายทิ้ง สำหรับผู้ใช้ นั่นอาจเป็นวิธีทดลองที่ถูกลง แต่ก็ชี้ให้เห็นถึงความยากของเศรษฐศาสตร์ด้านอินเฟอเรนซ์ของโมเดลขนาดใหญ่
โดยรวมแล้ว ฉันชอบ SGLang สำหรับการตั้งค่านี้มาก เวิร์กโฟลว์แบบ Docker ทำให้การให้บริการ Mistral Medium 3.5 128B ง่ายกว่าที่คาด และการทดสอบกับ OpenCode ก็ประทับใจจริง ๆ แต่การทดลองนี้ทำให้เห็นชัดเจนอย่างหนึ่ง: การรันโมเดลเปิดขนาดใหญ่แบบโลคอลทำได้ แต่การรันให้เสถียรและคุ้มค่าในฐานะผลิตภัณฑ์จริงเป็นอีกความท้าทายหนึ่งโดยสิ้นเชิง
เรียนรู้ AI กับ DataCamp!
Tracks
Courses
Courses