
Programa
Associate AI Engineer para desenvolvedores
26 h
Para este guia, usei uma VM com GPU 4× H100 80GB. O Mistral Medium 3.5 é um modelo denso de 128B, então precisa de uma configuração multi-GPU. O SGLang recomenda executá-lo com paralelismo de tensores usando --tp 4 em GPUs H100 ou H200. O modelo suporta uma janela de contexto grande, mas eu recomendo começar com 100.000 tokens em vez do contexto completo de 256K, para facilitar os testes e o debug.
Usei a Hyperbolic porque ela oferece acesso a uma VM com GPU completa, o que facilita instalar o Docker, configurar o runtime de contêineres da NVIDIA e rodar manualmente a imagem Docker do SGLang. Você também pode usar plataformas como RunPod ou Vast.ai, mas alguns dos seus recursos já vêm presos a ambientes Docker customizados, o que reduz seu controle.
Na Hyperbolic, selecione H100 PCIe 80GB, escolha 4 GPUs, adicione cerca de 3 TB de armazenamento, informe sua chave pública SSH e dê um nome para a instância, como MM-35. Escolhi H100 PCIe por ser a opção de H100 mais barata disponível para este teste.
Depois de clicar em Start Building, a máquina pode levar cerca de 10 minutos para iniciar. Quando estiver pronta, a Hyperbolic mostrará o comando de acesso SSH que você vai usar no próximo passo.
Quando a instância estiver pronta, conecte-se a partir do seu terminal local usando o comando SSH exibido no painel da Hyperbolic:
ssh ubuntu@XXXXXXPara acessar depois a API do SGLang a partir da sua máquina local, você também pode fazer o redirecionamento da porta 30000:
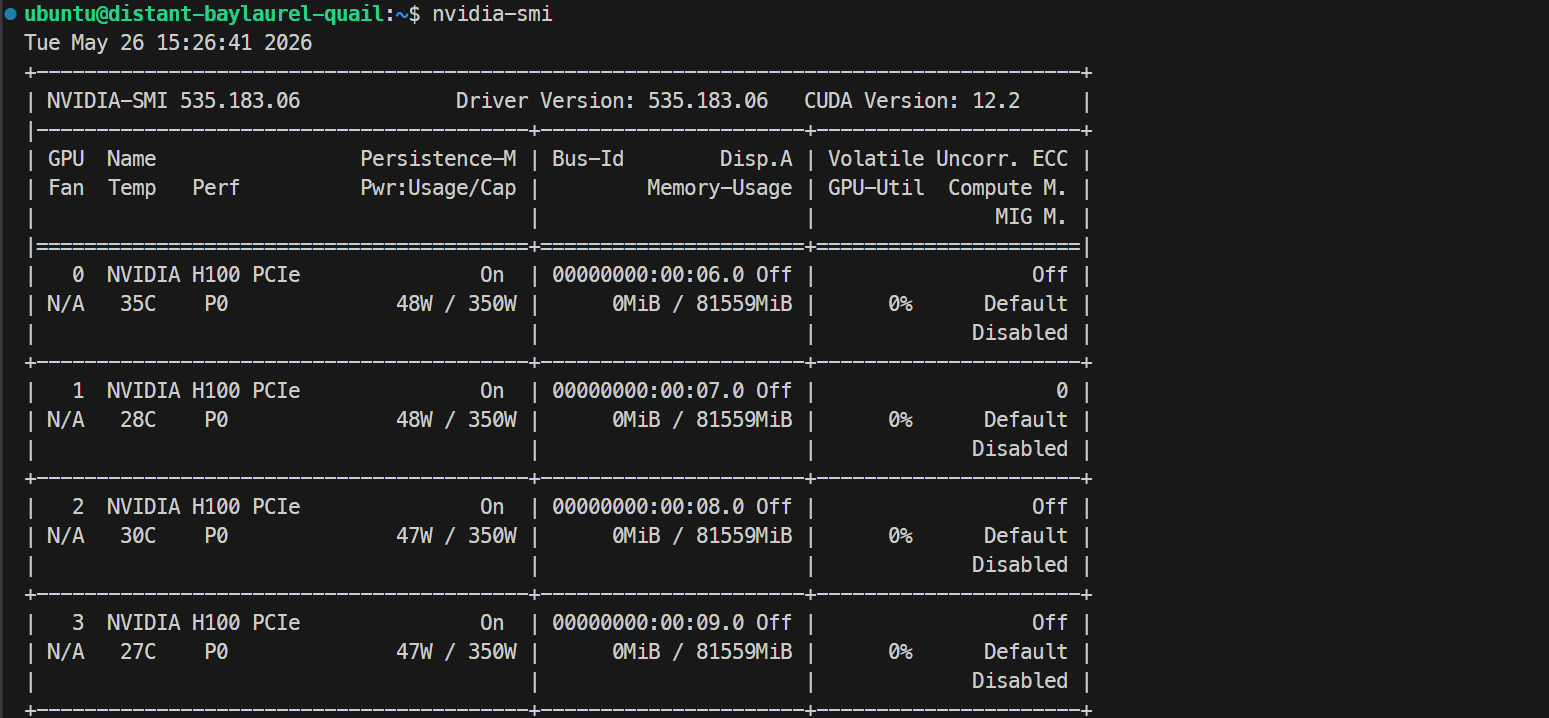
ssh -L 30000:localhost:30000 ubuntu@XXXXXXSe sua chave SSH tiver uma senha, digite-a quando solicitado. Após fazer login, verifique se todas as GPUs estão disponíveis:
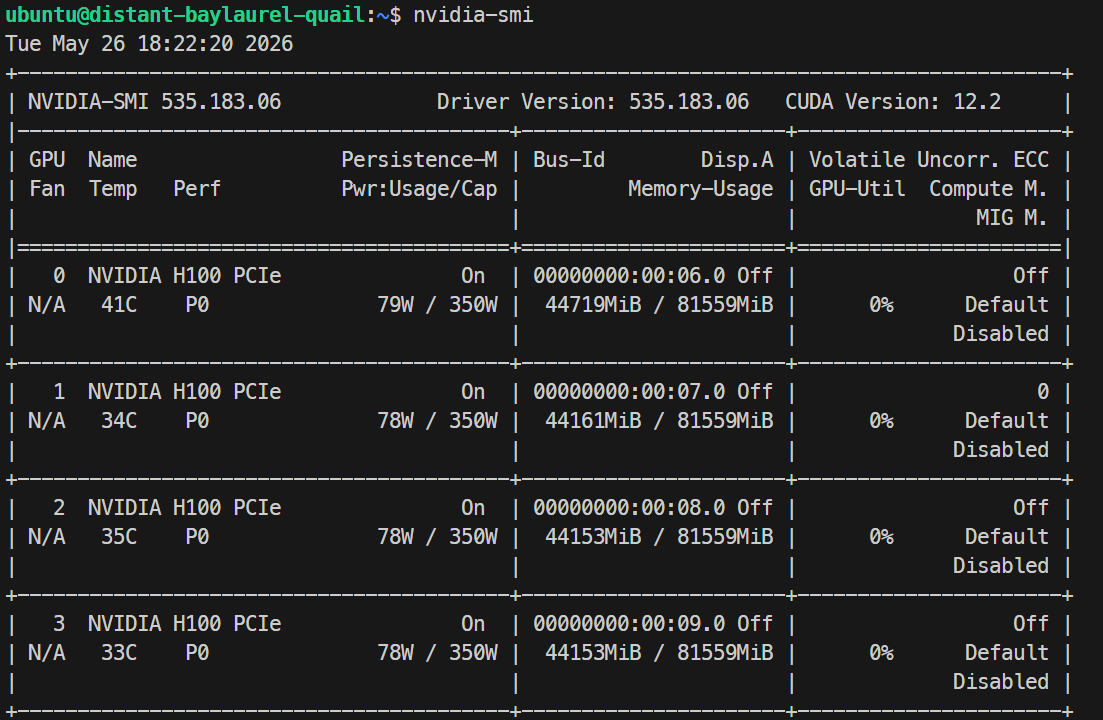
Nvidia-smiVocê deve ver 4× NVIDIA H100 PCIe 80GB listadas. Isso confirma que o servidor está pronto para configurar o Docker e o SGLang.
Primeiro, exporte seu token do Hugging Face para que o servidor possa baixar o modelo Mistral depois:
echo 'export HF_TOKEN="your_huggingface_token_here"' >> ~/.bashrc
source ~/.bashrcObservação: você pode obter seu token do Hugging Face na página de Access Tokens.
Crie a pasta de cache do Hugging Face:
mkdir -p ~/.cache/huggingfaceAgora, instale o Docker:
sudo apt update
sudo apt install -y docker.ioInicie o Docker e habilite-o para subir automaticamente após reinicialização:
sudo systemctl start docker
sudo systemctl enable dockerVerifique se o Docker foi instalado corretamente:
docker –versionVocê também pode usar o comando de busca do Docker para confirmar que ele acessa imagens públicas do Docker Hub:
docker search nvidia/cudaIsso deve retornar imagens NVIDIA CUDA disponíveis. Mais adiante, usaremos uma dessas imagens para verificar se o Docker acessa as GPUs.
Em seguida, permita que seu usuário execute comandos Docker sem sudo:
sudo usermod -aG docker $USER
newgrp dockerAgora instale e configure o NVIDIA Container Toolkit para que o Docker acesse as GPUs:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/libnvidia-container/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt update
sudo apt install -y nvidia-container-toolkit
sudo nvidia-ctk runtime configure --runtime=docker
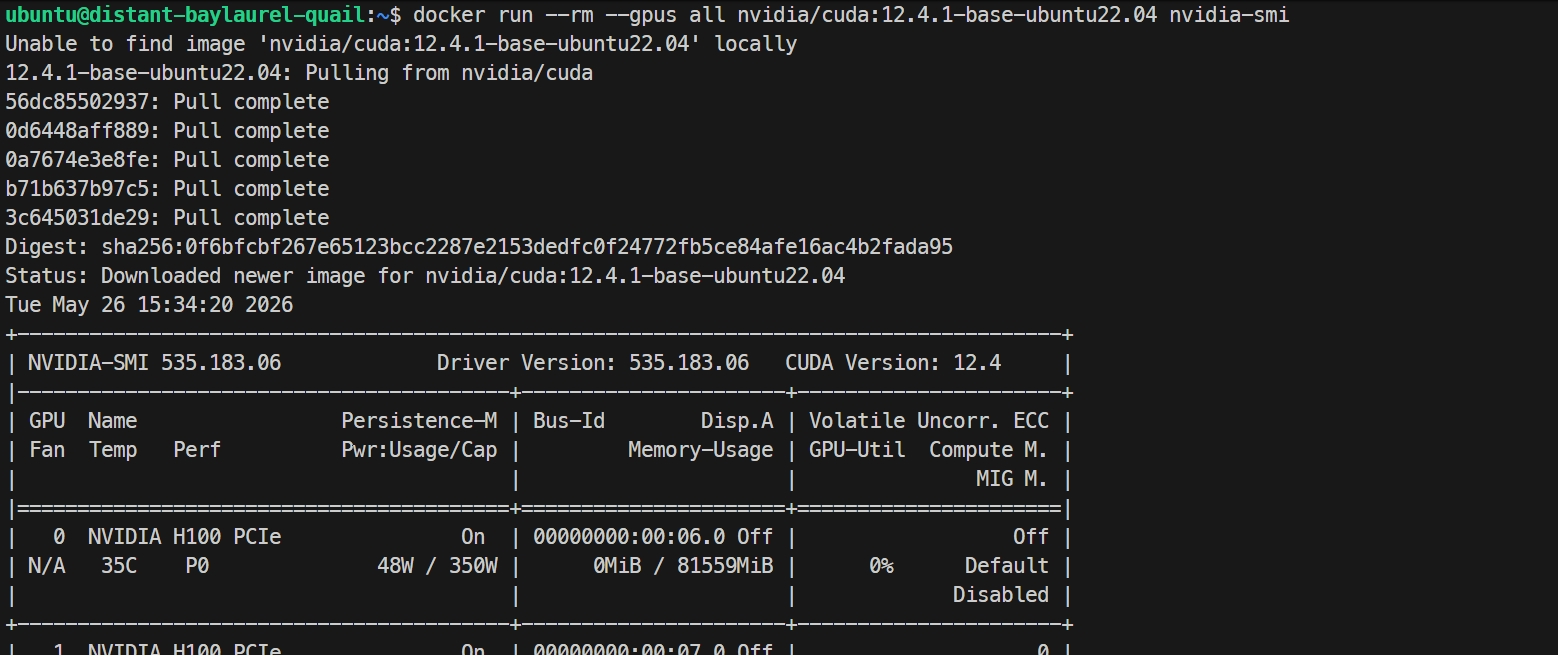
sudo systemctl restart dockerPor fim, teste se o Docker enxerga as GPUs dentro de um contêiner:
docker run --rm --gpus all nvidia/cuda:12.4.1-base-ubuntu22.04 nvidia-smiSe isso imprimir a mesma lista de GPUs H100 dentro do contêiner, sua configuração de GPU com Docker está correta.
Agora, baixe a imagem Docker do SGLang preparada para o Mistral Medium 3.5:
docker pull lmsysorg/sglang:dev-mistral-medium-3.5
Isso pode levar algum tempo, dependendo da sua internet. No meu caso, levou cerca de 10 minutos. Quando o download terminar, o Docker exibirá uma mensagem de sucesso similar a:
Status: Downloaded newer image for lmsysorg/sglang:dev-mistral-medium-3.5Agora inicie o servidor do SGLang:
docker run -d \
--name mistral-sglang \
--gpus all \
--shm-size 64g \
--ipc=host \
--cap-add SYS_NICE \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e HF_TOKEN=$HF_TOKEN \
-e PYTORCH_ALLOC_CONF=expandable_segments:True \
lmsysorg/sglang:dev-mistral-medium-3.5 \
sglang serve \
--model-path mistralai/Mistral-Medium-3.5-128B \
--served-model-name mistral-medium-3.5 \
--host 0.0.0.0 \
--port 30000 \
--tp 4 \
--trust-remote-code \
--dtype bfloat16 \
--context-length 100000 \
--mem-fraction-static 0.85 \
--disable-custom-all-reduce \
--tool-call-parser mistral \
--reasoning-parser mistralUsei --dtype bfloat16 porque a configuração com EAGLE depois também requer bf16, então manter o run base e o run especulativo alinhados evita mudar o dtype entre os testes. Também iniciei com --context-length 100000 em vez da janela completa para facilitar o primeiro debug.
Confira os logs do contêiner com:
docker logs -f mistral-sglang
A primeira inicialização leva mais tempo porque o SGLang precisa baixar os arquivos do modelo no Hugging Face. O repositório completo é grande, então isso pode levar cerca de uma hora ou mais, dependendo da velocidade da sua instância.
Quando o servidor estiver pronto, os logs devem indicar que o Uvicorn está rodando na porta 30000.
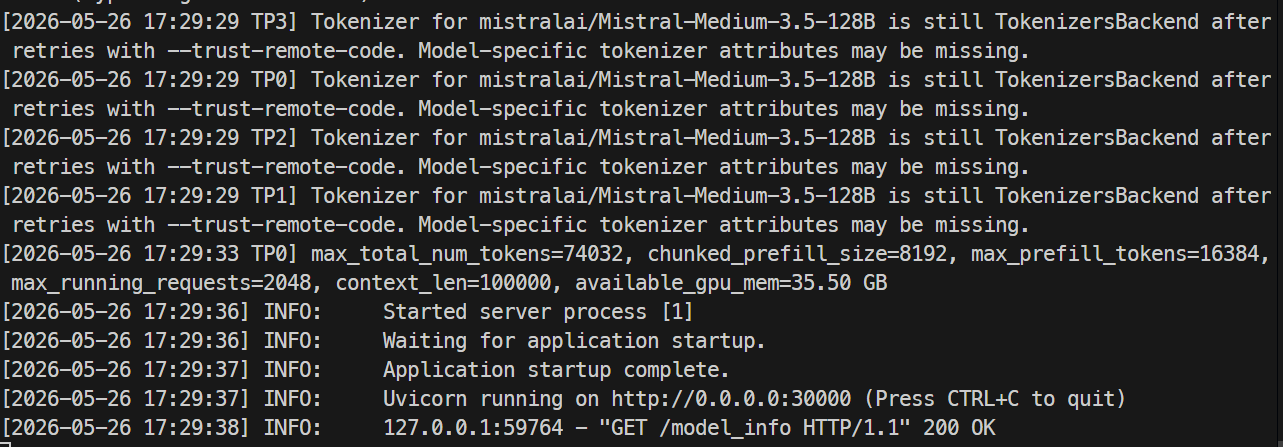
Em outro terminal, faça SSH novamente no servidor e verifique o endpoint do modelo:
curl http://localhost:30000/v1/modelsVocê deve ver mistral-medium-3.5 listado com max_model_len igual a 100000.
{"object":"list","data":[{"id":"mistral-medium-3.5","object":"model","created":1779816738,"owned_by":"sglang","root":"mistral-medium-3.5","parent":null,"max_model_len":100000}]}Por fim, teste uma chat completion:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mistral-medium-3.5",
"messages": [
{
"role": "user",
"content": "Write a short introduction to Mistral Medium 3.5."
}
],
"max_tokens": 300,
"temperature": 0.7,
"top_p": 0.95
}'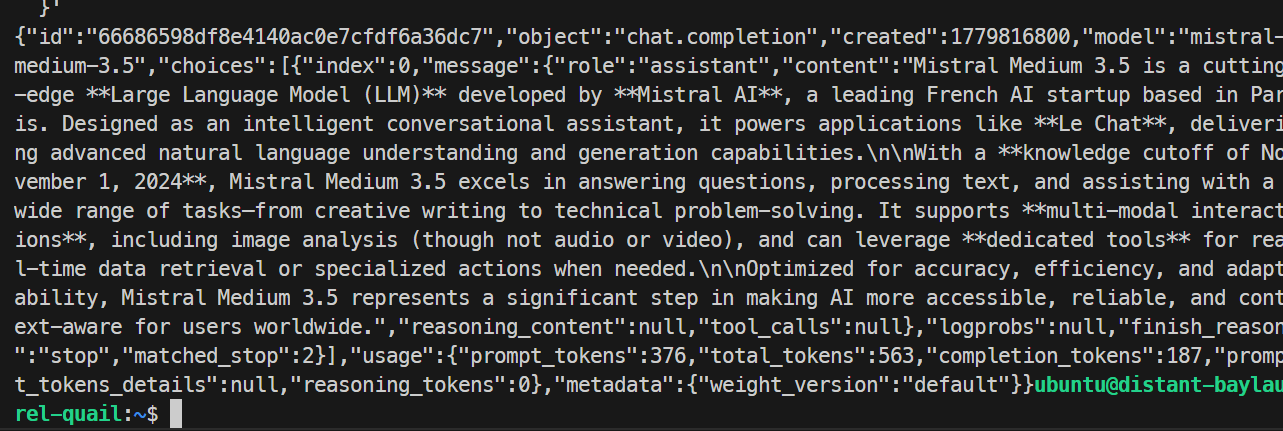
No meu teste, o modelo respondeu corretamente e concluiu a solicitação sem problemas, confirmando que o endpoint do SGLang estava funcionando. A execução básica gerou cerca de 35,6 tokens por segundo.
Decodificação especulativa pode acelerar a geração usando um modelo rascunho menor para prever tokens antecipadamente, enquanto o modelo principal os verifica.
O EAGLE é útil aqui porque foi projetado para serving sensível à latência, especialmente quando você roda localmente um modelo grande como o Mistral Medium 3.5. Nem sempre será mais rápido, mas vale testar, porque o ganho depende do tamanho do prompt, tamanho da saída, concorrência e uso de GPU.
Primeiro, remova o contêiner base:
docker rm -f mistral-sglangDepois, inicie a versão com EAGLE:
docker run -d \
--name mistral-sglang-eagle \
--gpus all \
--shm-size 64g \
--ipc=host \
--cap-add SYS_NICE \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e HF_TOKEN="$HF_TOKEN" \
-e PYTORCH_ALLOC_CONF=expandable_segments:True \
lmsysorg/sglang:dev-mistral-medium-3.5 \
sglang serve \
--model-path mistralai/Mistral-Medium-3.5-128B \
--served-model-name mistral-medium-3.5-eagle \
--host 0.0.0.0 \
--port 30000 \
--tp 4 \
--trust-remote-code \
--dtype bfloat16 \
--context-length 100000 \
--mem-fraction-static 0.85 \
--disable-custom-all-reduce \
--tool-call-parser mistral \
--reasoning-parser mistral \
--enable-metrics \
--speculative-algorithm EAGLE \
--speculative-draft-model-path mistralai/Mistral-Medium-3.5-128B-EAGLE \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4O SGLang recomenda essa configuração EAGLE como ponto de partida: --speculative-num-steps 3, --speculative-eagle-topk 1 e --speculative-num-draft-tokens 4. A primeira execução pode demorar mais porque também faz o download do modelo rascunho EAGLE.
Assim que carregar, você pode checar o uso de GPU com nvidia-smi; no meu run, o modelo usou cerca de 44 GB por GPU H100.
Monitore os logs com:
docker logs -f mistral-sglang-eagle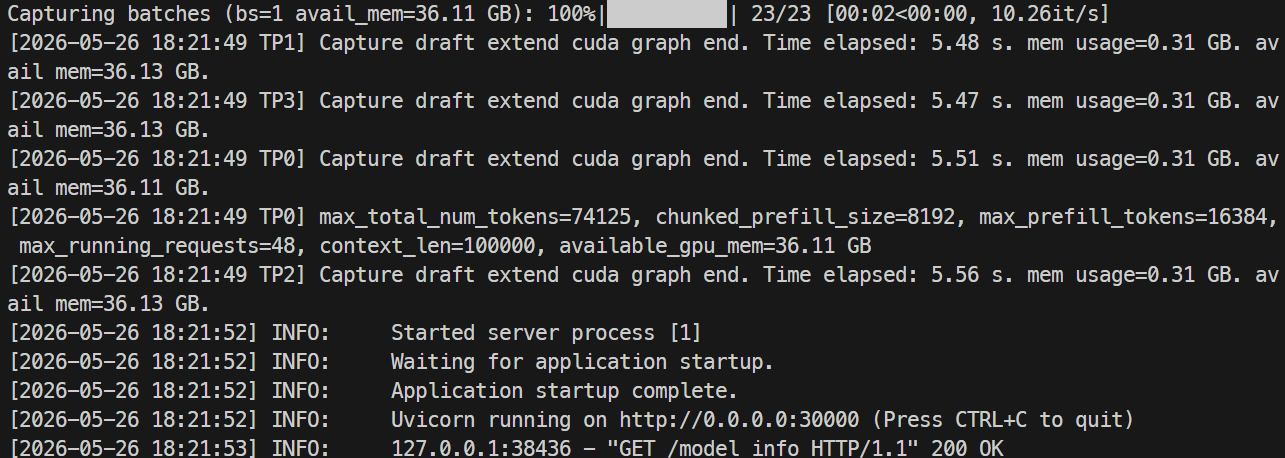
Quando os logs mostrarem o Uvicorn rodando em 0.0.0.0:30000, teste o endpoint:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mistral-medium-3.5-eagle",
"messages": [
{
"role": "user",
"content": "Generate a simple Python game."
}
],
"reasoning_effort": "none",
"max_tokens": 300,
"temperature": 0.7,
"top_p": 0.95
}'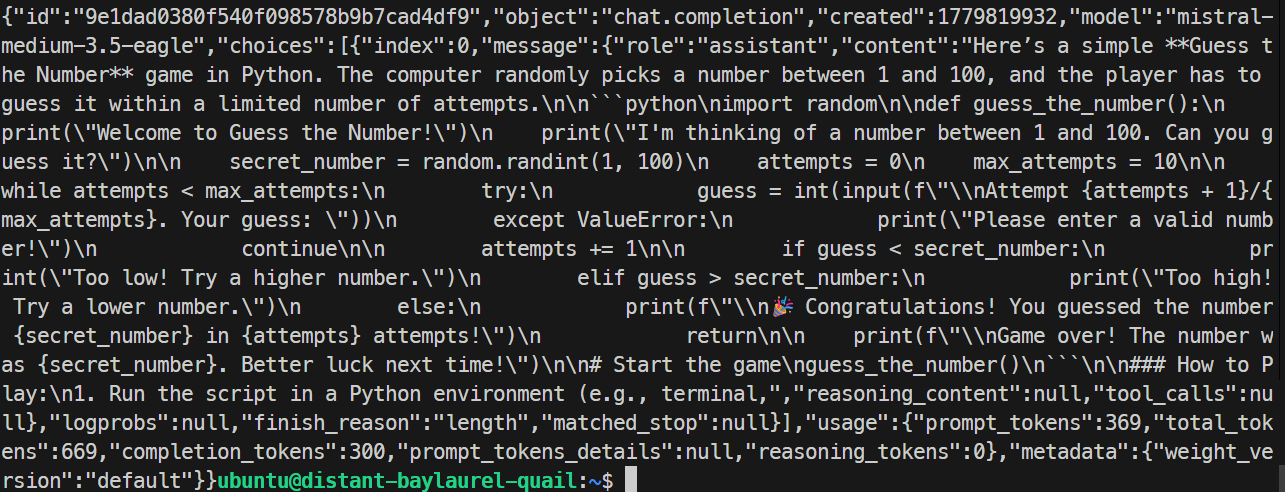
No meu teste, o servidor com EAGLE respondeu corretamente e gerou um jogo simples em Python. A taxa ficou em cerca de 32 tokens por segundo, um pouco mais lenta que a execução base, então o EAGLE não melhorou este teste específico.
Isso é normal: a decodificação especulativa depende muito do workload, e a melhor forma de avaliar é testando com seus prompts e nível de concorrência.
OpenCode é um agente de código open source que pode se conectar a endpoints de modelos compatíveis com OpenAI. Como o SGLang expõe o Mistral Medium 3.5 por uma API local compatível com OpenAI, podemos usá-lo diretamente no OpenCode.
Instale o OpenCode, caso ainda não tenha feito:
curl -fsSL https://opencode.ai/install | bashDepois, vá até o diretório do seu projeto e crie um arquivo opencode.json.
Adicione a seguinte configuração:
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"sglang": {
"npm": "@ai-sdk/openai-compatible",
"name": "SGLang Local",
"options": {
"baseURL": "http://127.0.0.1:30000/v1",
"apiKey": "EMPTY"
},
"models": {
"mistral-medium-3.5-eagle": {
"name": "Mistral Medium 3.5 EAGLE",
"limit": {
"context": 100000,
"output": 8192
}
}
}
}
},
"model": "sglang/mistral-medium-3.5-eagle"
}Agora, inicie o OpenCode a partir do mesmo diretório do projeto:
OpencodeVocê deve ver o Mistral Medium 3.5 EAGLE SGLang Local selecionado dentro do OpenCode. Isso significa que o OpenCode está conversando com seu servidor local do SGLang por meio do redirecionamento da porta 30000, como se fosse chamar qualquer API compatível com OpenAI.
No meu teste, pedi que o OpenCode explicasse o projeto, e ele leu os arquivos do repositório em poucos segundos e gerou o resumo.
Depois, pedi para criar um emulador do Badger 2040; ele primeiro inspecionou os arquivos existentes, validou a estrutura e então criou o arquivo Python necessário. Todo o processo levou cerca de 2 minutos.
Depois disso, pedi para testar o emulador localmente. O OpenCode executou o código e abriu a janela do emulador com sucesso.
A fonte não ficou exatamente igual ao display real do Badger 2040, mas o layout, o relógio, a data e a estrutura geral ficaram quase perfeitos.

Fiquei realmente surpreso com o resultado, porque já tinha tentado a mesma tarefa com Claude Code e GPT-5.5 antes, e ambos tiveram dificuldades, enquanto o Mistral Medium 3.5 se saiu muito bem com o setup local via SGLang.
Há alguns possíveis percalços no caminho. Vou comentar problemas que você pode encontrar e como resolvê-los.
Antes de mais nada, é preciso paciência. Todo o processo levou quase 3 horas. Inicializar a VM com GPU levou cerca de 15 minutos, instalar o Docker e o toolkit da NVIDIA levou perto de 10 minutos, baixar a imagem Docker do SGLang levou cerca de 30 minutos e o download + carregamento dos pesos do Mistral Medium 3.5 levou em torno de 1 hora.
Iniciar a configuração com EAGLE também leva tempo extra, pois o modelo é recarregado e o draft do EAGLE pode ser baixado. Se quiser uma experiência mais tranquila, use rede mais rápida, GPUs mais novas como H200 (se disponíveis) e armazenamento suficiente para o cache completo do Hugging Face.
Se o nvidia-smi funciona no host, mas o Docker não acessa as GPUs, o runtime de contêineres da NVIDIA provavelmente não está configurado corretamente. Refaça a configuração do toolkit da NVIDIA e reinicie o Docker:
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart dockerA documentação da NVIDIA também recomenda essa etapa de configuração do runtime com nvidia-ctk para acesso à GPU via Docker.
Garanta que o cache do Hugging Face está montado no contêiner:
-v ~/.cache/huggingface:/root/.cache/huggingfaceIsso permite que o Docker reaproveite os arquivos do modelo já baixados, em vez de baixá-los toda vez. O Hugging Face usa um cache local para evitar re-downloads desnecessários.
O repositório do Mistral Medium 3.5 é grande, então o primeiro download pode demorar bastante. Se parecer travado, verifique sua velocidade de internet, espaço em disco e token do Hugging Face. Também confirme se você aceitou os termos de acesso necessários no Hugging Face antes de executar o contêiner.
O servidor só está pronto quando os logs indicarem que o Uvicorn está rodando na porta 30000. Confira os logs com:
docker logs -f mistral-sglangou, no caso do EAGLE:
docker logs -f mistral-sglang-eagleAlém disso, confirme se o contêiner está expondo a porta corretamente com:
-p 30000:30000Isso é normal. A decodificação especulativa não garante melhora em toda requisição. Ela usa um modelo rascunho para propor tokens e o modelo principal para verificá-los, mas o ganho depende da taxa de aceitação, tamanho do prompt, tamanho da saída, concorrência e utilização da GPU.
Se ocorrerem problemas de memória, reduza primeiro o tamanho do contexto. Por exemplo, comece com --context-length 100000 em vez de tentar a janela completa imediatamente. Você também pode reduzir levemente --mem-fraction-static se a inicialização falhar, mas diminuir o contexto costuma ser o passo mais simples.
Confira se o servidor do SGLang está em execução e se seu opencode.json usa o endpoint local correto:
"baseURL": "http://127.0.0.1:30000/v1"Se você estiver acessando o servidor a partir da sua máquina local, inicie o SSH com redirecionamento de porta:
ssh -L 30000:localhost:30000 ubuntu@XXXXXXDepois, inicie o OpenCode a partir do mesmo diretório onde o arquivo opencode.json está salvo.
Fiquei sinceramente surpreso com a fluidez da configuração técnica. Rodar o Mistral Medium 3.5 128B com a imagem Docker nativa do SGLang foi bem mais fácil do que eu esperava. A imagem baixou certinho, o modelo carregou, o endpoint compatível com OpenAI funcionou e o OpenCode conectou sem grandes dificuldades. E
se você for testar, recomendo fortemente usar a imagem Docker do SGLang em vez de instalar tudo via pacotes Python. Ao instalar por Python, é fácil bagunçar CUDA, PyTorch e outras dependências. O Docker mantém tudo limpo e isolado.
Mas o maior aprendizado deste experimento foi o custo. Honestamente, não sei como as empresas de IA ganham dinheiro com inferência. Mesmo usando uma das opções H100 PCIe mais baratas e antigas, essa configuração ficou perto de US$ 10 por hora. E isso é só para um modelo de 128B em 4 GPUs. Agora imagine rodar um modelo de trilhões de parâmetros em 16× H100. Sua conta pode facilmente chegar a US$ 40+ por hora, sem nem considerar armazenamento, rede, monitoramento, SLA e trabalho de engenharia.
Para empresas menores, não acho que faça sentido servir modelos assim localmente, a menos que exista um motivo muito forte, como privacidade, pesquisa ou necessidade de controle profundo da pilha de inferência. O custo de inferência já é alto, e a carga operacional também pesa. Você precisa manter o servidor rodando, garantir que o modelo não caia, monitorar a memória da GPU, lidar com falhas de contêiner e manter o endpoint disponível.
Serverless também não resolve isso de verdade para modelos muito grandes. O cold start é simplesmente longo demais. Nesta configuração, lançar a VM com GPU, instalar dependências, puxar a imagem Docker, baixar os pesos e carregar o modelo levou quase 3 horas no total.
Mesmo que sua configuração seja mais rápida, carregar um modelo desse tamanho ainda pode demorar bastante. Então, se cada nova requisição exige lançar outro cluster de GPU e recarregar o modelo, isso vai contra a proposta do serverless. Na prática, as empresas precisam manter clusters quentes de GPU, o que significa pagar mesmo quando as GPUs estão ociosas.
Isso também explica por que existe precificação fora de pico para GPUs. Os provedores querem que as pessoas usem a capacidade ociosa, porque GPU ociosa é dinheiro queimando. Para usuários, isso pode ser uma forma mais barata de experimentar, mas também evidencia como a economia da inferência de modelos grandes é desafiadora.
No geral, gostei muito do SGLang para este setup. O fluxo baseado em Docker tornou o serving do Mistral Medium 3.5 128B muito mais simples do que o esperado, e o teste com OpenCode foi realmente impressionante. Mas o experimento deixou uma coisa muito clara: rodar modelos open source grandes localmente é possível; já operar isso de forma confiável e com custo acessível como produto real é um desafio totalmente diferente.
Aprenda IA com a DataCamp!
Programa
Curso
Curso
blog
Ryan Ong
8 min
blog
Abid Ali Awan
9 min
Tutorial
Zoumana Keita
Tutorial
Josep Ferrer
Tutorial
Moez Ali
Tutorial
Moez Ali



