
Cursus
Associate AI Engineer pour développeurs
26 h
Pour ce guide, j’ai utilisé une machine virtuelle GPU 4 × H100 80 GB. Mistral Medium 3.5 est un modèle dense 128B, il nécessite donc une configuration multi‑GPU. SGLang recommande de l’exécuter avec du parallélisme tensoriel via --tp 4 sur des GPU H100 ou H200. Le modèle prend en charge une grande fenêtre de contexte, mais je vous conseille de commencer par 100 000 tokens au lieu des 256K complets pour faciliter les tests et le débogage.
J’ai utilisé Hyperbolic car cela donne accès à une VM GPU complète, ce qui simplifie l’installation de Docker, la configuration du runtime conteneur NVIDIA et l’exécution manuelle de l’image Docker SGLang. Vous pouvez aussi utiliser des plateformes comme RunPod ou Vast.ai, mais certaines de leurs instances sont déjà liées à des environnements Docker personnalisés, ce qui vous laisse moins de contrôle.
Dans Hyperbolic, sélectionnez H100 PCIe 80GB, choisissez 4 GPU, ajoutez environ 3 To de stockage, saisissez votre clé publique SSH et donnez un nom à l’instance, par exemple MM-35. J’ai choisi H100 PCIe car c’était l’option H100 la moins chère disponible pour ce test.
Après avoir cliqué sur Start Building, la machine peut mettre environ 10 minutes à démarrer. Une fois prête, Hyperbolic affiche la commande SSH dont vous aurez besoin pour l’étape suivante.
Une fois l’instance prête, connectez‑vous depuis votre terminal local avec la commande SSH indiquée dans le tableau de bord Hyperbolic :
ssh ubuntu@XXXXXXPour accéder plus tard à l’API SGLang depuis votre machine locale, vous pouvez aussi rediriger le port 30000 :
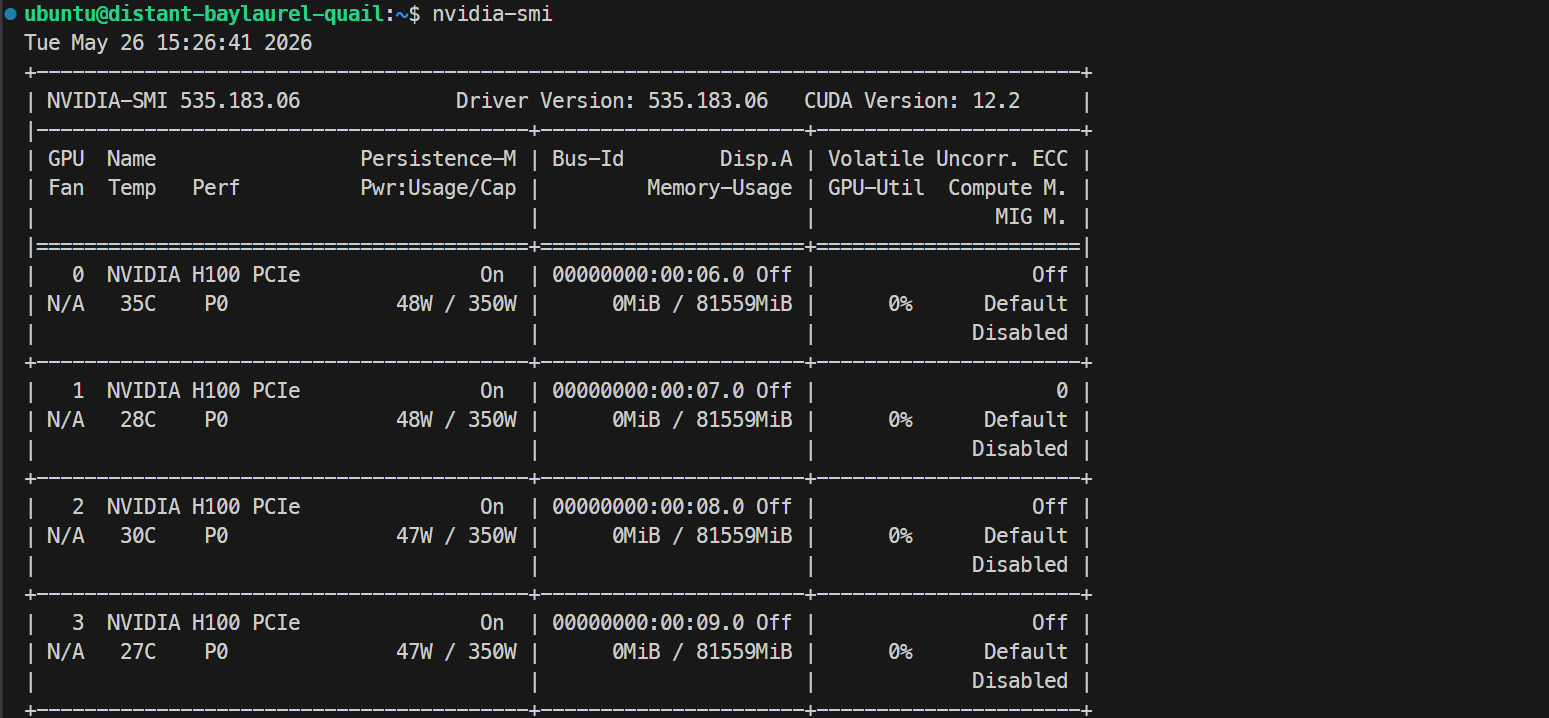
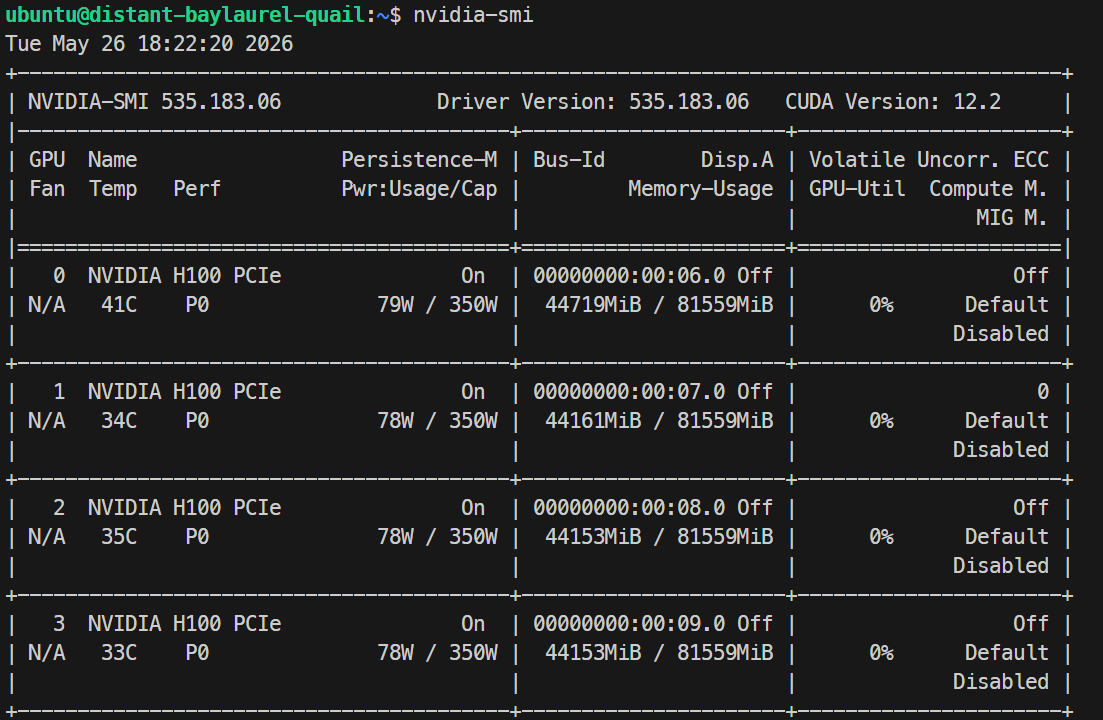
ssh -L 30000:localhost:30000 ubuntu@XXXXXXSi votre clé SSH a une phrase secrète, saisissez‑la quand elle est demandée. Après connexion, vérifiez que tous les GPU sont disponibles :
Nvidia-smiVous devriez voir 4 × NVIDIA H100 PCIe 80GB listés. Cela confirme que le serveur est prêt pour l’installation de Docker et SGLang.
Commencez par exporter votre jeton Hugging Face pour que le serveur puisse télécharger le modèle Mistral ensuite :
echo 'export HF_TOKEN="your_huggingface_token_here"' >> ~/.bashrc
source ~/.bashrcRemarque : vous pouvez récupérer votre jeton Hugging Face sur la page Access Tokens.
Créez le dossier de cache Hugging Face :
mkdir -p ~/.cache/huggingfaceInstallez maintenant Docker :
sudo apt update
sudo apt install -y docker.ioDémarrez Docker et activez son lancement automatique au redémarrage :
sudo systemctl start docker
sudo systemctl enable dockerVérifiez que Docker est correctement installé :
docker –versionVous pouvez aussi utiliser la recherche d’images Docker pour confirmer l’accès à Docker Hub :
docker search nvidia/cudaCela devrait retourner des images NVIDIA CUDA disponibles. Plus tard, nous utiliserons l’une de ces images pour vérifier l’accès GPU depuis Docker.
Ensuite, autorisez votre utilisateur à exécuter Docker sans sudo :
sudo usermod -aG docker $USER
newgrp dockerInstallez et configurez maintenant le NVIDIA Container Toolkit pour que Docker accède aux GPU :
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/libnvidia-container/gpgkey | sudo apt-key add -
curl -s - L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt update
sudo apt install -y nvidia-container-toolkit
sudo nvidia-ctk runtime configure --runtime=docker
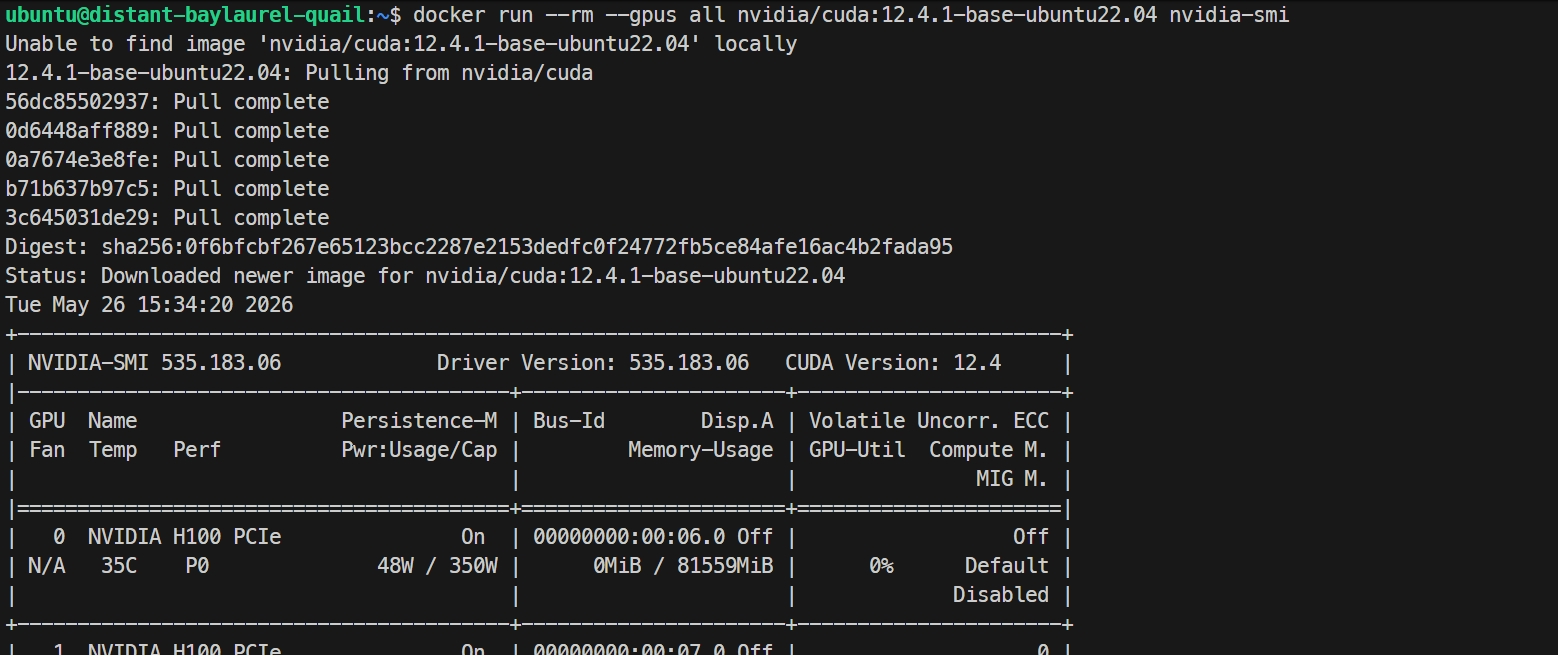
sudo systemctl restart dockerEnfin, testez que Docker voit les GPU depuis un conteneur :
docker run --rm --gpus all nvidia/cuda:12.4.1-base-ubuntu22.04 nvidia-smiSi la même liste de GPU H100 s’affiche dans le conteneur, votre configuration GPU pour Docker fonctionne.
Téléchargez ensuite l’image Docker SGLang conçue pour Mistral Medium 3.5 :
docker pull lmsysorg/sglang:dev-mistral-medium-3.5
Cela peut prendre un certain temps selon votre débit. Dans mon cas, environ 10 minutes. Une fois l’image téléchargée, Docker affiche un message de succès semblable à :
Status: Downloaded newer image for lmsysorg/sglang:dev-mistral-medium-3.5Démarrez maintenant le serveur SGLang :
docker run -d \
--name mistral-sglang \
--gpus all \
--shm-size 64g \
--ipc=host \
--cap-add SYS_NICE \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e HF_TOKEN=$HF_TOKEN \
-e PYTORCH_ALLOC_CONF=expandable_segments:True \
lmsysorg/sglang:dev-mistral-medium-3.5 \
sglang serve \
--model-path mistralai/Mistral-Medium-3.5-128B \
--served-model-name mistral-medium-3.5 \
--host 0.0.0.0 \
--port 30000 \
--tp 4 \
--trust-remote-code \
--dtype bfloat16 \
--context-length 100000 \
--mem-fraction-static 0.85 \
--disable-custom-all-reduce \
--tool-call-parser mistral \
--reasoning-parser mistralJ’ai utilisé --dtype bfloat16 car la configuration EAGLE requiert aussi bf16 : garder le run de base et le run spéculatif alignés évite de changer le dtype entre les tests. J’ai également démarré avec --context-length 100000 au lieu de la fenêtre complète pour faciliter le premier débogage.
Consultez les logs du conteneur avec :
docker logs -f mistral-sglang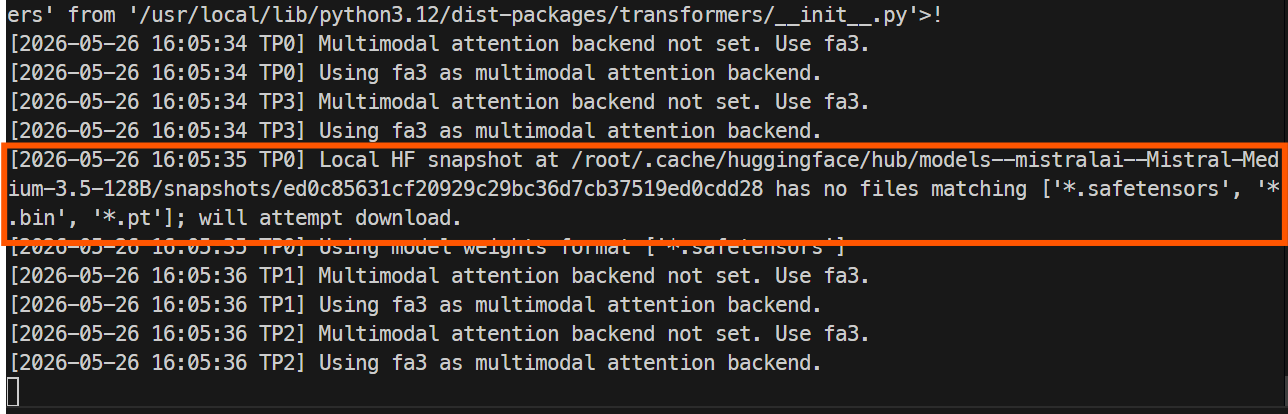
Le premier démarrage est plus long, car SGLang doit télécharger les fichiers du modèle depuis Hugging Face. Le dépôt est volumineux : comptez environ une heure ou plus selon la vitesse de votre instance.
Quand le serveur est prêt, les logs indiquent qu’Uvicorn écoute sur le port 30000.
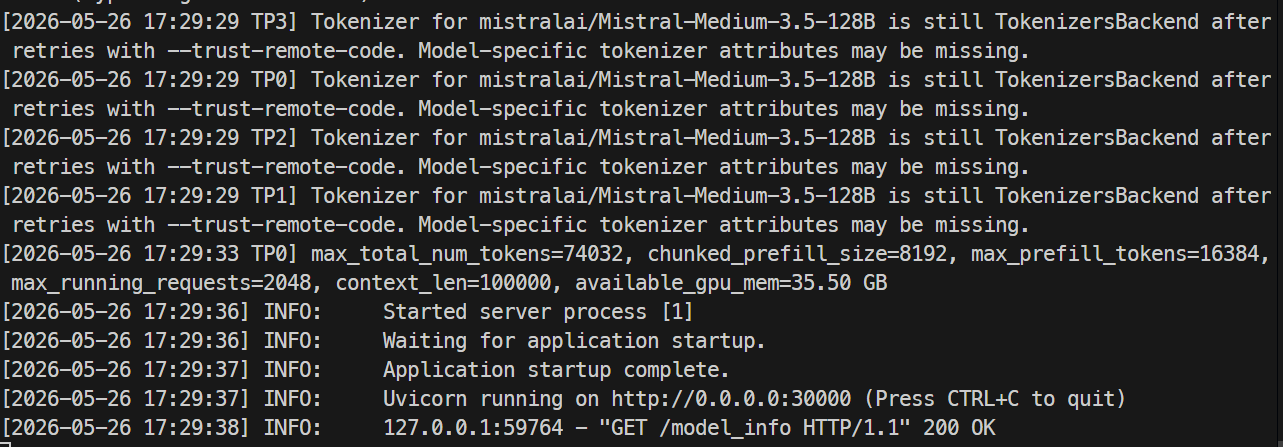
Dans un autre terminal, reconnectez‑vous en SSH au serveur et testez l’endpoint du modèle :
curl http://localhost:30000/v1/modelsVous devriez voir mistral-medium-3.5 listé avec un max_model_len à 100000.
{"object":"list","data":[{"id":"mistral-medium-3.5","object":"model","created":1779816738,"owned_by":"sglang","root":"mistral-medium-3.5","parent":null,"max_model_len":100000}]}Enfin, testez une complétion de chat :
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mistral-medium-3.5",
"messages": [
{
"role": "user",
"content": "Write a short introduction to Mistral Medium 3.5."
}
],
"max_tokens": 300,
"temperature": 0.7,
"top_p": 0.95
}'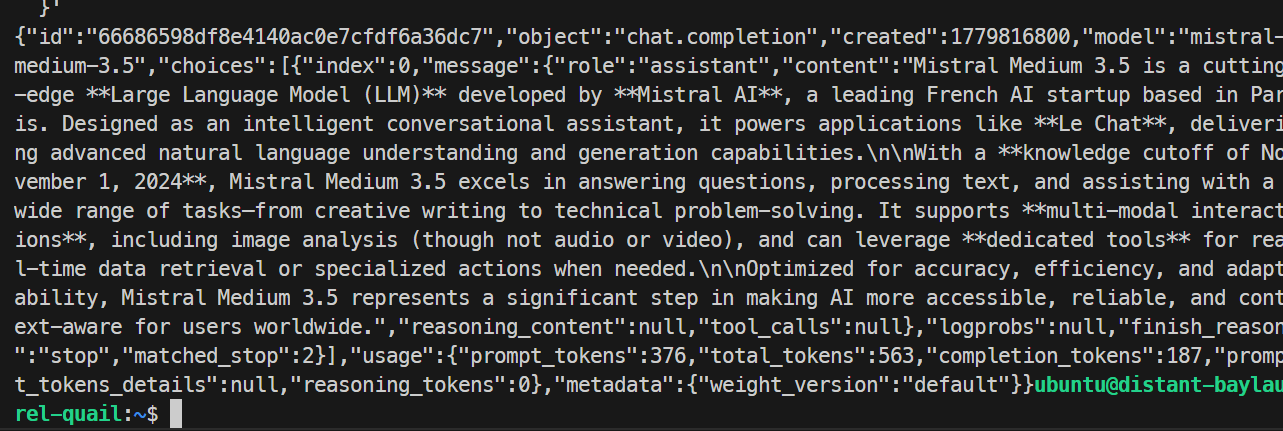
Dans mon test, le modèle a répondu correctement et terminé la requête sans erreur, confirmant que l’endpoint SGLang fonctionnait. L’exécution de base a généré environ 35,6 tokens par seconde.
Le décodage spéculatif peut accélérer la génération en utilisant un petit modèle de brouillon pour prédire des tokens à l’avance, tandis que le modèle principal les vérifie.
EAGLE est utile ici parce qu’il est conçu pour le serving à faible latence, en particulier lorsque vous faites tourner un grand modèle comme Mistral Medium 3.5 en local. Il ne sera pas toujours plus rapide, mais cela vaut la peine d’être testé : le gain dépend de la longueur du prompt, de la longueur de sortie, de la concurrence et de l’utilisation GPU.
Commencez par supprimer le conteneur de base :
docker rm -f mistral-sglangDémarrez ensuite la version EAGLE :
docker run -d \
--name mistral-sglang-eagle \
--gpus all \
--shm-size 64g \
--ipc=host \
--cap-add SYS_NICE \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e HF_TOKEN="$HF_TOKEN" \
-e PYTORCH_ALLOC_CONF=expandable_segments:True \
lmsysorg/sglang:dev-mistral-medium-3.5 \
sglang serve \
--model-path mistralai/Mistral-Medium-3.5-128B \
--served-model-name mistral-medium-3.5-eagle \
--host 0.0.0.0 \
--port 30000 \
--tp 4 \
--trust-remote-code \
--dtype bfloat16 \
--context-length 100000 \
--mem-fraction-static 0.85 \
--disable-custom-all-reduce \
--tool-call-parser mistral \
--reasoning-parser mistral \
--enable-metrics \
--speculative-algorithm EAGLE \
--speculative-draft-model-path mistralai/Mistral-Medium-3.5-128B-EAGLE \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4SGLang recommande cette configuration EAGLE comme bon point de départ : --speculative-num-steps 3, --speculative-eagle-topk 1 et --speculative-num-draft-tokens 4. Le premier lancement peut être plus long car il télécharge aussi le modèle de brouillon EAGLE.
Une fois chargé, vous pouvez vérifier l’usage GPU avec nvidia-smi : lors de mon run, le modèle utilisait environ 44 Go par GPU H100.
Surveillez les logs avec :
docker logs -f mistral-sglang-eagle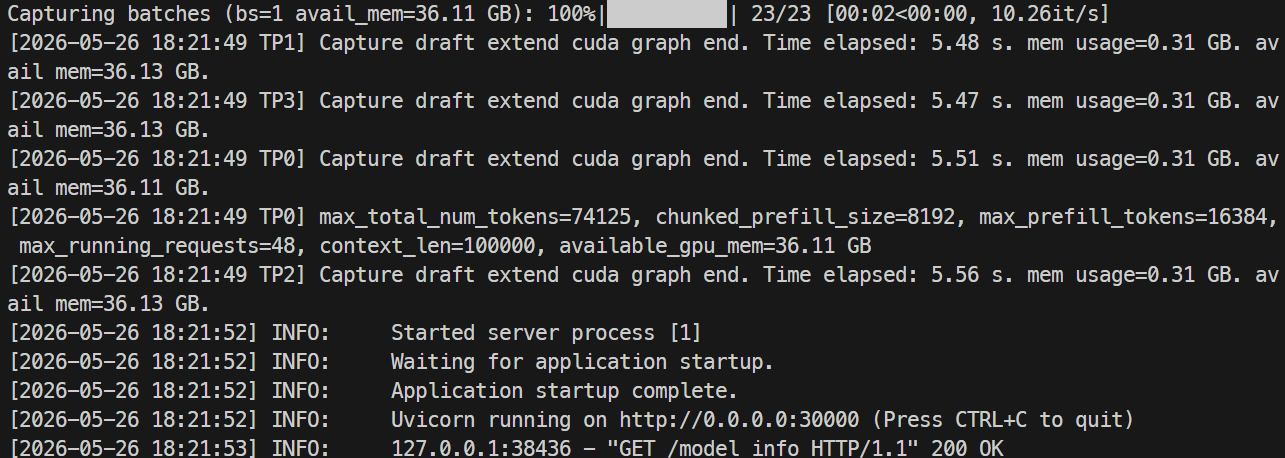
Quand les logs indiquent qu’Uvicorn tourne sur 0.0.0.0:30000, testez l’endpoint :
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mistral-medium-3.5-eagle",
"messages": [
{
"role": "user",
"content": "Generate a simple Python game."
}
],
"reasoning_effort": "none",
"max_tokens": 300,
"temperature": 0.7,
"top_p": 0.95
}'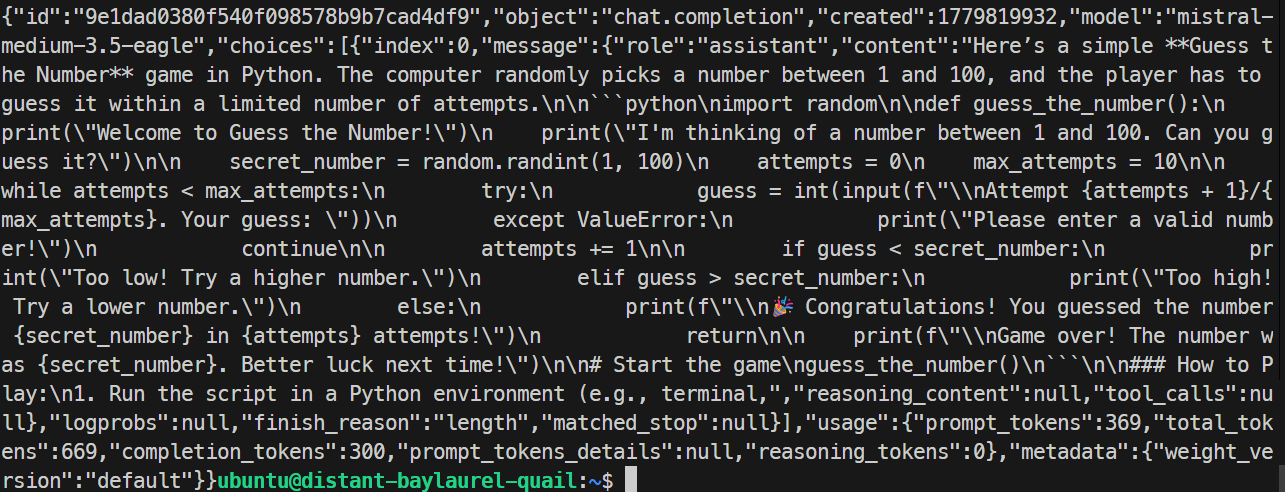
Dans mon test, le serveur EAGLE a répondu correctement et généré un petit jeu Python. Le débit était d’environ 32 tokens par seconde, légèrement inférieur au run de base, donc EAGLE n’a pas amélioré ce test précis.
C’est normal : le décodage spéculatif dépend fortement de la charge. Le meilleur moyen d’évaluer l’intérêt est de le tester avec vos propres prompts et votre niveau de concurrence.
OpenCode est un agent de code open source qui peut se connecter à des endpoints de modèles compatibles OpenAI. Comme SGLang expose Mistral Medium 3.5 via une API locale compatible OpenAI, nous pouvons l’utiliser directement dans OpenCode.
Installez OpenCode si ce n’est pas déjà fait :
curl -fsSL https://opencode.ai/install | bashPlacez‑vous ensuite dans votre répertoire projet et créez un fichier opencode.json.
Ajoutez la configuration suivante :
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"sglang": {
"npm": "@ai-sdk/openai-compatible",
"name": "SGLang Local",
"options": {
"baseURL": "http://127.0.0.1:30000/v1",
"apiKey": "EMPTY"
},
"models": {
"mistral-medium-3.5-eagle": {
"name": "Mistral Medium 3.5 EAGLE",
"limit": {
"context": 100000,
"output": 8192
}
}
}
}
},
"model": "sglang/mistral-medium-3.5-eagle"
}Lancez maintenant OpenCode depuis le même répertoire projet :
OpencodeVous devriez voir Mistral Medium 3.5 EAGLE SGLang Local sélectionné dans OpenCode. Cela signifie qu’OpenCode discute avec votre serveur SGLang local via le port 30000 redirigé, comme il le ferait avec n’importe quelle API compatible OpenAI.
Dans mon test, j’ai demandé à OpenCode d’expliquer le projet. Il a lu les fichiers du dépôt en quelques secondes et généré un résumé.
Ensuite, je lui ai demandé de créer un émulateur Badger 2040. Il a d’abord inspecté les fichiers existants, validé la structure, puis créé le fichier Python requis. L’ensemble a pris environ 2 minutes.
Après cela, je lui ai demandé de tester l’émulateur en local. OpenCode a lancé le code et ouvert la fenêtre de l’émulateur avec succès.
La police n’était pas exactement la même que sur le véritable affichage du Badger 2040, mais la mise en page, l’heure, la date et la structure générale étaient quasiment parfaites.

Le résultat m’a vraiment surpris : j’avais tenté la même tâche avec Claude Code et GPT‑5.5, et les deux avaient peiné, alors que Mistral Medium 3.5 s’en est très bien sorti via la configuration SGLang locale.
Quelques écueils sont possibles. Voici les problèmes que vous pourriez rencontrer et comment les résoudre.
Avant tout, il faut être patient. Cette mise en place complète m’a pris presque 3 heures. Le lancement de la VM GPU : environ 15 minutes, l’installation de Docker et du toolkit NVIDIA : 10 minutes environ, le pull de l’image SGLang : 30 minutes, et le téléchargement puis le chargement des poids du modèle Mistral Medium 3.5 : environ 1 heure.
Le démarrage d’EAGLE prend aussi du temps supplémentaire, car il recharge le modèle et peut télécharger le modèle de brouillon EAGLE. Pour une expérience plus fluide, utilisez un réseau plus rapide, des GPU plus récents comme des H200 si disponibles, et suffisamment de stockage pour tout le cache Hugging Face.
Si nvidia-smi fonctionne sur l’hôte mais que Docker n’accède pas aux GPU, le runtime NVIDIA n’est probablement pas bien configuré. Relancez la configuration du NVIDIA Container Toolkit et redémarrez Docker :
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart dockerLa documentation NVIDIA recommande également cette étape de configuration du runtime nvidia-ctk pour l’accès GPU avec Docker.
Assurez‑vous que le cache Hugging Face est monté dans le conteneur :
-v ~/.cache/huggingface:/root/.cache/huggingfaceCela permet à Docker de réutiliser les fichiers déjà téléchargés au lieu de les retélécharger à chaque lancement. Hugging Face utilise un cache local pour éviter les téléchargements inutiles.
Le dépôt Mistral Medium 3.5 est volumineux, donc le premier téléchargement peut être long. S’il semble bloqué, vérifiez votre débit, l’espace disque et votre jeton Hugging Face. Assurez‑vous aussi d’avoir accepté les conditions d’accès requises sur Hugging Face avant de lancer le conteneur.
Le serveur n’est pas prêt tant que les logs n’indiquent pas qu’Uvicorn écoute sur le port 30000. Vérifiez les logs avec :
docker logs -f mistral-sglangou pour EAGLE :
docker logs -f mistral-sglang-eagleAssurez‑vous aussi que le conteneur expose correctement le port :
-p 30000:30000C’est normal. Le décodage spéculatif n’améliore pas toutes les requêtes. Il fonctionne avec un modèle de brouillon qui propose des tokens et un modèle principal qui les vérifie, mais l’accélération dépend du taux d’acceptation, de la longueur du prompt, de la longueur de sortie, de la concurrence et de l’utilisation GPU.
En cas de problème de mémoire, réduisez d’abord la longueur de contexte. Par exemple, commencez par --context-length 100000 au lieu d’attaquer directement la fenêtre maximale. Vous pouvez aussi baisser légèrement --mem-fraction-static si le démarrage échoue, mais réduire la longueur de contexte est souvent le plus simple.
Assurez‑vous que le serveur SGLang tourne et que votre opencode.json pointe vers le bon endpoint local :
"baseURL": "http://127.0.0.1:30000/v1"Si vous y accédez depuis votre machine locale, lancez la redirection de port via SSH :
ssh -L 30000:localhost:30000 ubuntu@XXXXXXPuis lancez OpenCode depuis le même répertoire que votre fichier opencode.json.
J’ai été honnêtement surpris par la fluidité de la mise en place. Faire tourner Mistral Medium 3.5 128B avec l’image Docker native SGLang a été bien plus simple que prévu. L’image s’est téléchargée correctement, le modèle s’est chargé, l’endpoint compatible OpenAI a fonctionné et OpenCode s’y est connecté sans difficulté majeure. J
e vous recommande vivement d’utiliser l’image Docker SGLang plutôt que d’installer le tout via des packages Python. En passant par Python, on dérègle vite CUDA, PyTorch et autres dépendances. Docker garde le tout propre et isolé.
Mais ce qui m’a le plus marqué, c’est le coût. Je ne sais pas comment les entreprises d’IA gagnent de l’argent avec l’inférence. Même avec une des options H100 PCIe les moins chères et les plus anciennes, cette configuration tournait autour de 10 $ de l’heure. Et ce n’est qu’un modèle 128B sur 4 GPU. Imaginez un modèle bien plus grand, à un trillion de paramètres, sur 16 H100. La facture grimpe facilement à 40 $+ de l’heure, sans même compter le stockage, le réseau, le monitoring, la disponibilité et l’ingénierie.
Pour les petites entreprises, servir ce type de modèle en local n’a pas beaucoup de sens sauf raison impérieuse : confidentialité, recherche ou besoin d’un contrôle fin de la pile d’inférence. Le coût d’inférence est déjà élevé, mais la charge opérationnelle l’est aussi. Il faut garder le serveur en ligne, éviter les crashs, surveiller la mémoire GPU, gérer les conteneurs en échec et maintenir l’endpoint disponible.
Le serverless ne résout pas vraiment ce problème pour les très grands modèles. Le cold start est tout simplement trop long. Dans cette configuration, lancer la VM GPU, installer les dépendances, récupérer l’image Docker, télécharger les poids et charger le modèle a pris presque 3 heures au total.
Même avec une configuration plus rapide, charger un modèle de cette taille peut rester long. Donc si chaque requête implique de lancer un nouveau cluster GPU et de recharger le modèle, cela va à l’encontre du principe du serverless. En pratique, les entreprises doivent garder des clusters GPU « chauds », ce qui signifie payer même quand les GPU sont inactifs.
C’est aussi ce qui explique l’existence de tarifs GPU hors‑pointe. Les fournisseurs veulent que les gens utilisent la capacité GPU inactive, car des GPU inutilisés coûtent de l’argent. Pour les utilisateurs, c’est une bonne manière d’expérimenter à moindre coût, mais cela illustre aussi la difficulté économique de l’inférence sur très grands modèles.
Globalement, j’ai beaucoup apprécié SGLang pour cette configuration. Le flux de travail basé sur Docker a grandement simplifié le serving de Mistral Medium 3.5 128B, et le test avec OpenCode était réellement impressionnant. Mais cette expérience m’a aussi confirmé une chose : faire tourner de grands modèles ouverts en local, c’est possible ; les exécuter de manière fiable et économique en produit réel, c’est un tout autre défi.
Apprenez l’IA avec DataCamp !
Cursus
Cours
Cours
blog
Kurtis Pykes
9 min
blog
Kurtis Pykes
15 min
blog
blog
Zoumana Keita
15 min
Tutoriel
Tutoriel
Moez Ali
