
programa
Associate AI Engineer para desarrolladores
26 h
Para esta guía utilicé una máquina virtual con 4× H100 80GB. Mistral Medium 3.5 es un modelo denso de 128B, por lo que necesita una configuración multi‑GPU. SGLang recomienda ejecutarlo con paralelismo tensorial usando --tp 4 en GPUs H100 o H200. El modelo admite una ventana de contexto grande, pero te recomiendo empezar con 100.000 tokens en lugar del contexto completo de 256K para facilitar las pruebas y la depuración inicial.
Usé Hyperbolic porque da acceso a una VM con GPU completa, lo que facilita instalar Docker, configurar el runtime de contenedores de NVIDIA y ejecutar manualmente la imagen Docker de SGLang. También puedes usar plataformas como RunPod o Vast.ai, pero algunas de sus instancias ya vienen ligadas a entornos Docker personalizados, lo que te da menos control.
En Hyperbolic, selecciona H100 PCIe 80GB, elige 4 GPUs, añade unos 3 TB de almacenamiento, introduce tu clave pública SSH y ponle un nombre a la instancia, por ejemplo MM-35. Elegí H100 PCIe porque era la opción H100 más barata disponible para esta prueba.
Tras hacer clic en Start Building, la máquina puede tardar unos 10 minutos en iniciarse. Cuando esté lista, Hyperbolic mostrará el comando de acceso SSH que necesitarás en el siguiente paso.
Cuando la instancia esté lista, conéctate desde tu terminal local usando el comando SSH que aparece en el panel de Hyperbolic:
ssh ubuntu@XXXXXXPara acceder más tarde a la API de SGLang desde tu máquina local, también puedes reenviar el puerto 30000:
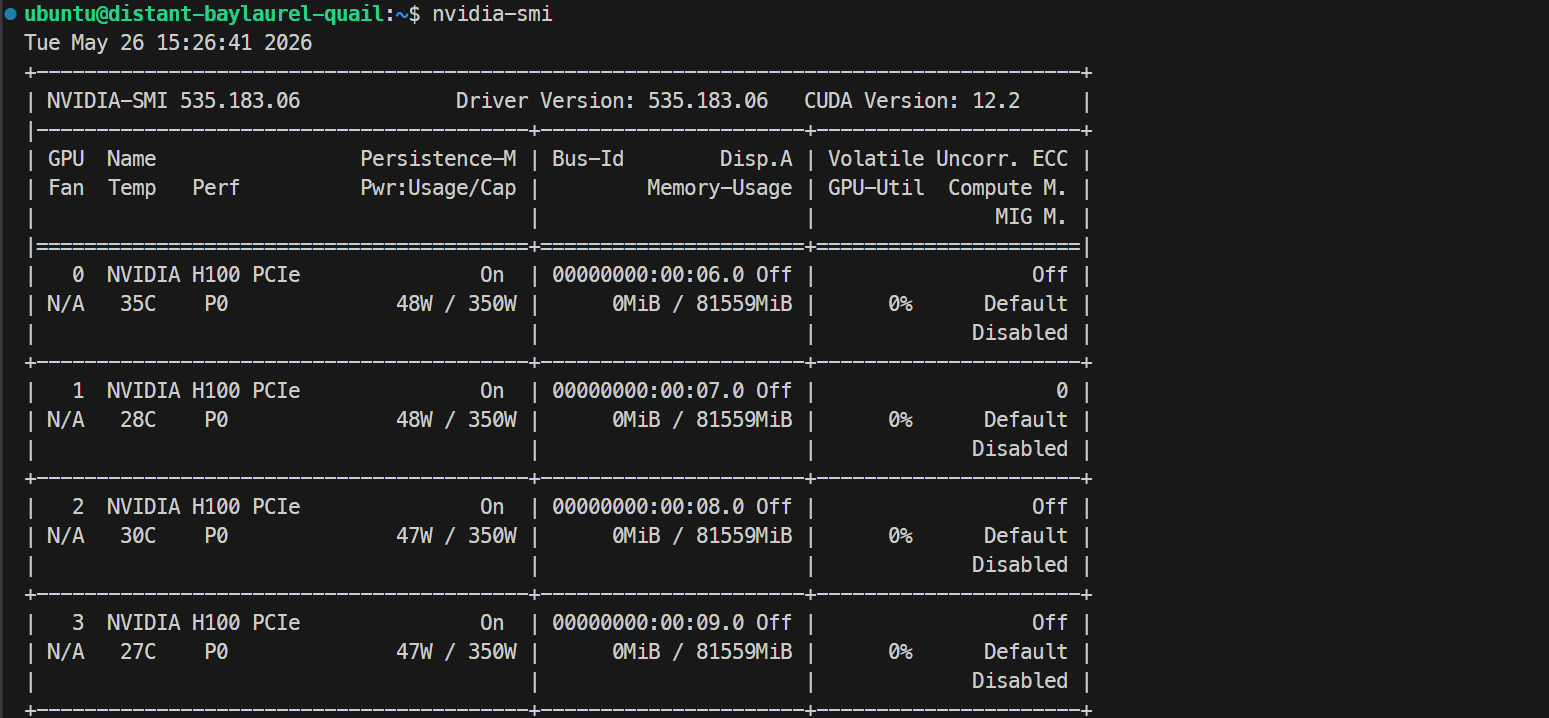
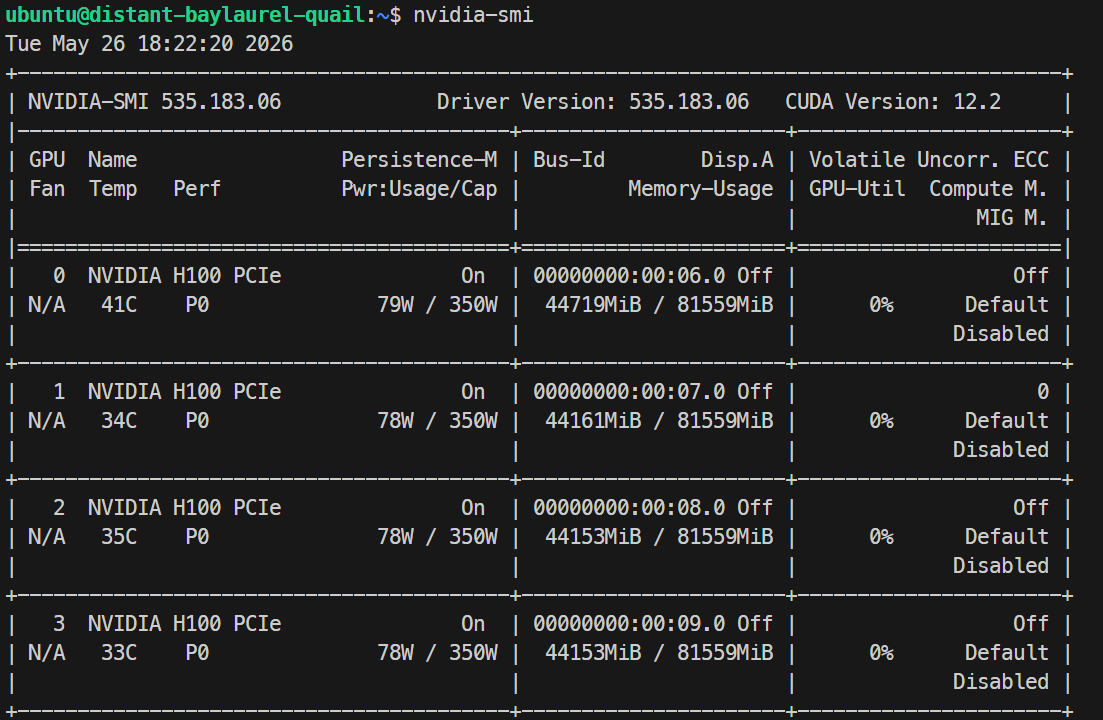
ssh -L 30000:localhost:30000 ubuntu@XXXXXXSi tu clave SSH tiene passphrase, introdúcela cuando se te pida. Después de iniciar sesión, comprueba que todas las GPUs están disponibles:
Nvidia-smiDeberías ver 4× NVIDIA H100 PCIe 80GB listadas. Esto confirma que el servidor está listo para configurar Docker y SGLang.
Primero, exporta tu token de Hugging Face para que el servidor pueda descargar el modelo de Mistral más adelante:
echo 'export HF_TOKEN="your_huggingface_token_here"' >> ~/.bashrc
source ~/.bashrcNota: puedes obtener tu token de Hugging Face en la página de Access Tokens.
Crea la carpeta de caché de Hugging Face:
mkdir -p ~/.cache/huggingfaceAhora instala Docker:
sudo apt update
sudo apt install -y docker.ioInicia Docker y habilita su arranque automático tras reinicio:
sudo systemctl start docker
sudo systemctl enable dockerComprueba que Docker se instaló correctamente:
docker –versionTambién puedes usar el comando de búsqueda de Docker para confirmar que puede encontrar imágenes públicas en Docker Hub:
docker search nvidia/cudaEsto debería devolver imágenes NVIDIA CUDA disponibles. Más adelante usaremos una de estas imágenes para verificar que Docker puede acceder a las GPUs.
A continuación, permite que tu usuario ejecute comandos de Docker sin sudo:
sudo usermod -aG docker $USER
newgrp dockerAhora instala y configura NVIDIA Container Toolkit para que Docker pueda acceder a las GPUs:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/libnvidia-container/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt update
sudo apt install -y nvidia-container-toolkit
sudo nvidia-ctk runtime configure --runtime=docker
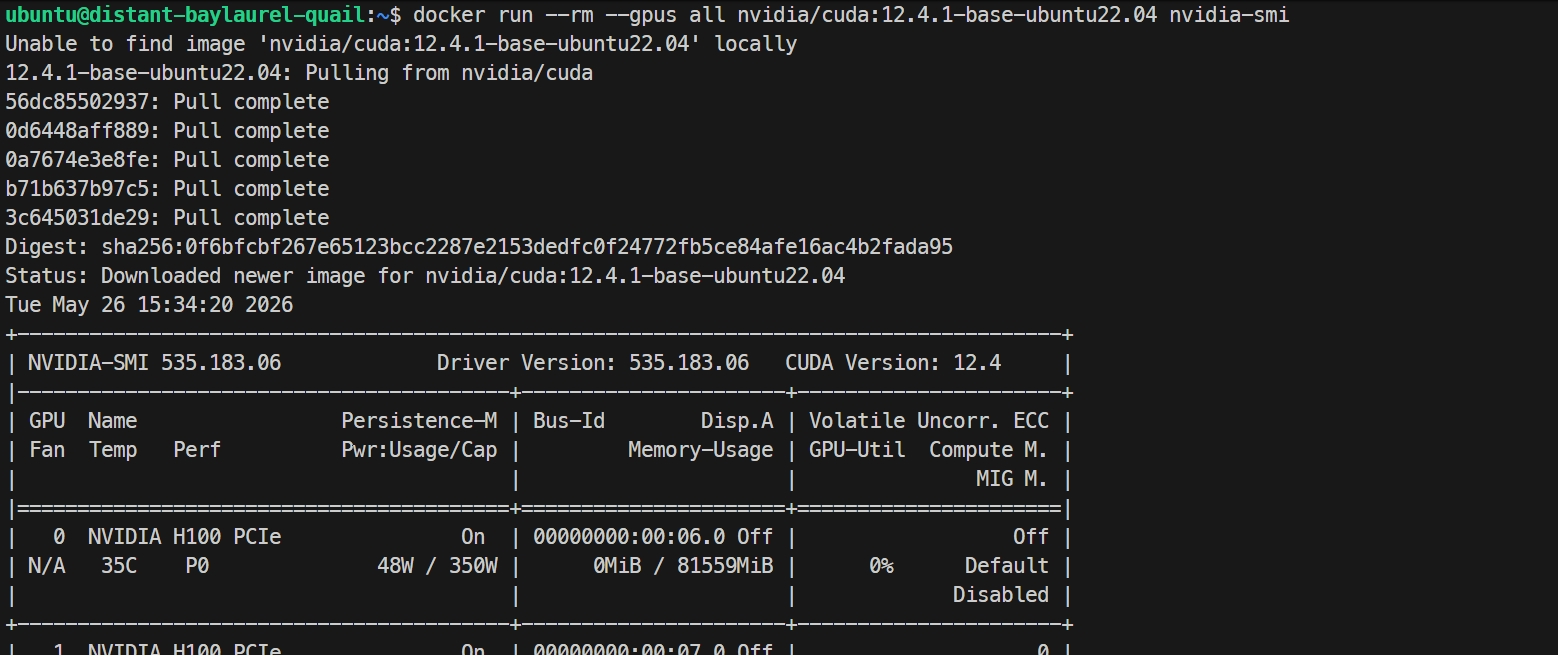
sudo systemctl restart dockerPor último, prueba que Docker ve las GPUs desde dentro de un contenedor:
docker run --rm --gpus all nvidia/cuda:12.4.1-base-ubuntu22.04 nvidia-smiSi imprime la misma lista de GPUs H100 dentro del contenedor, tu configuración de Docker con GPU funciona correctamente.
Ahora, descarga la imagen Docker de SGLang preparada para Mistral Medium 3.5:
docker pull lmsysorg/sglang:dev-mistral-medium-3.5
Esto puede tardar, según tu velocidad de internet. En mi caso, unos 10 minutos. Cuando finalice la descarga, Docker mostrará un mensaje de éxito similar a:
Status: Downloaded newer image for lmsysorg/sglang:dev-mistral-medium-3.5Ahora inicia el servidor de SGLang:
docker run -d \
--name mistral-sglang \
--gpus all \
--shm-size 64g \
--ipc=host \
--cap-add SYS_NICE \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e HF_TOKEN=$HF_TOKEN \
-e PYTORCH_ALLOC_CONF=expandable_segments:True \
lmsysorg/sglang:dev-mistral-medium-3.5 \
sglang serve \
--model-path mistralai/Mistral-Medium-3.5-128B \
--served-model-name mistral-medium-3.5 \
--host 0.0.0.0 \
--port 30000 \
--tp 4 \
--trust-remote-code \
--dtype bfloat16 \
--context-length 100000 \
--mem-fraction-static 0.85 \
--disable-custom-all-reduce \
--tool-call-parser mistral \
--reasoning-parser mistralUsé --dtype bfloat16 porque la configuración posterior con EAGLE también requiere bf16, así que mantener alineada la ejecución base y la especulativa evita cambiar el dtype entre pruebas. También empecé con --context-length 100000 en lugar del contexto completo para facilitar la depuración del primer arranque.
Consulta los logs del contenedor con:
docker logs -f mistral-sglang
El primer arranque tardará más porque SGLang tiene que descargar los archivos del modelo desde Hugging Face. El repositorio completo es grande, así que puede llevar alrededor de una hora o más, según la velocidad de tu instancia.
Cuando el servidor esté listo, los logs deberían indicar que Uvicorn se está ejecutando en el puerto 30000.
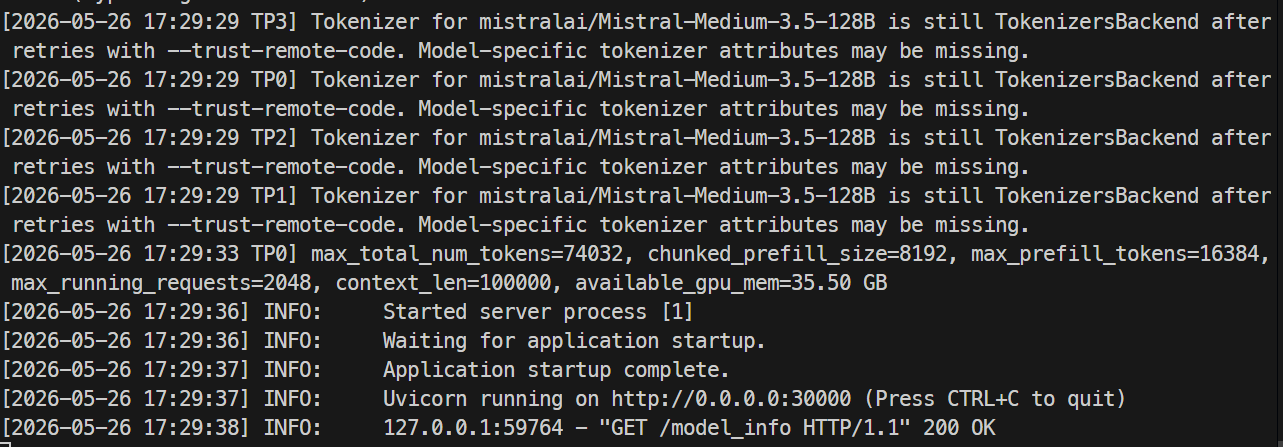
En otra terminal, vuelve a acceder por SSH al servidor y comprueba el endpoint del modelo:
curl http://localhost:30000/v1/modelsDeberías ver mistral-medium-3.5 listado con un max_model_len de 100000.
{"object":"list","data":[{"id":"mistral-medium-3.5","object":"model","created":1779816738,"owned_by":"sglang","root":"mistral-medium-3.5","parent":null,"max_model_len":100000}]}Por último, prueba una completion de chat:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mistral-medium-3.5",
"messages": [
{
"role": "user",
"content": "Write a short introduction to Mistral Medium 3.5."
}
],
"max_tokens": 300,
"temperature": 0.7,
"top_p": 0.95
}'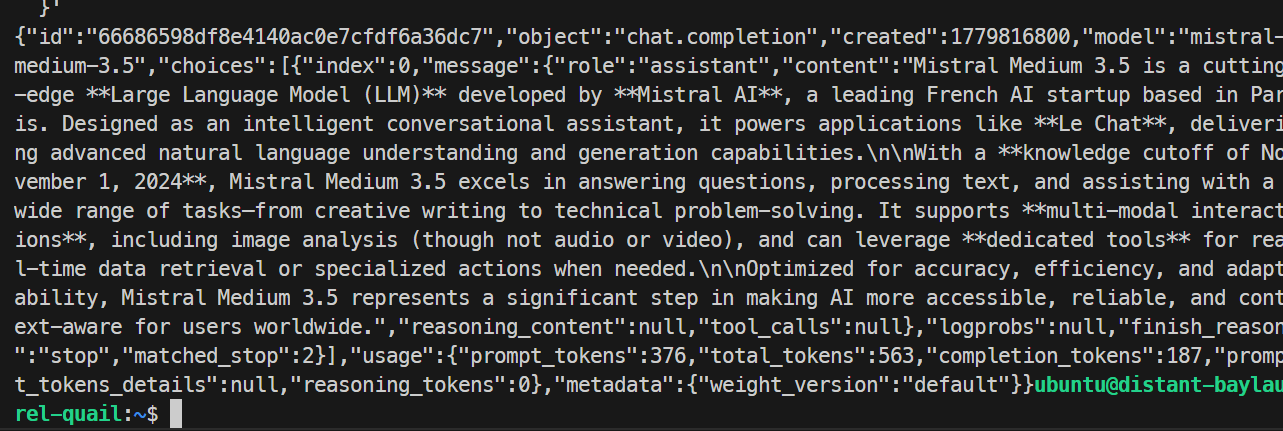
En mi prueba, el modelo respondió correctamente y completó la petición sin problemas, confirmando que el endpoint de SGLang funcionaba. La ejecución básica generó alrededor de 35,6 tokens por segundo.
La decodificación especulativa puede acelerar la generación usando un modelo borrador más pequeño que predice tokens por adelantado, mientras el modelo principal los verifica.
EAGLE es útil aquí porque está pensado para serving sensible a la latencia, especialmente cuando ejecutas en local un modelo grande como Mistral Medium 3.5. No siempre será más rápido, pero merece la pena probarlo porque el beneficio depende de la longitud del prompt, la salida, la concurrencia y el uso de GPU.
Primero, elimina el contenedor base:
docker rm -f mistral-sglangLuego inicia la versión con EAGLE:
docker run -d \
--name mistral-sglang-eagle \
--gpus all \
--shm-size 64g \
--ipc=host \
--cap-add SYS_NICE \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e HF_TOKEN="$HF_TOKEN" \
-e PYTORCH_ALLOC_CONF=expandable_segments:True \
lmsysorg/sglang:dev-mistral-medium-3.5 \
sglang serve \
--model-path mistralai/Mistral-Medium-3.5-128B \
--served-model-name mistral-medium-3.5-eagle \
--host 0.0.0.0 \
--port 30000 \
--tp 4 \
--trust-remote-code \
--dtype bfloat16 \
--context-length 100000 \
--mem-fraction-static 0.85 \
--disable-custom-all-reduce \
--tool-call-parser mistral \
--reasoning-parser mistral \
--enable-metrics \
--speculative-algorithm EAGLE \
--speculative-draft-model-path mistralai/Mistral-Medium-3.5-128B-EAGLE \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4SGLang recomienda esta configuración de EAGLE como buen punto de partida: --speculative-num-steps 3, --speculative-eagle-topk 1 y --speculative-num-draft-tokens 4. La primera ejecución puede tardar más porque también descarga el modelo borrador de EAGLE.
Una vez cargado, puedes comprobar el uso de GPU con nvidia-smi; en mi ejecución, el modelo utilizó alrededor de 44 GB por GPU H100.
Supervisa los logs con:
docker logs -f mistral-sglang-eagle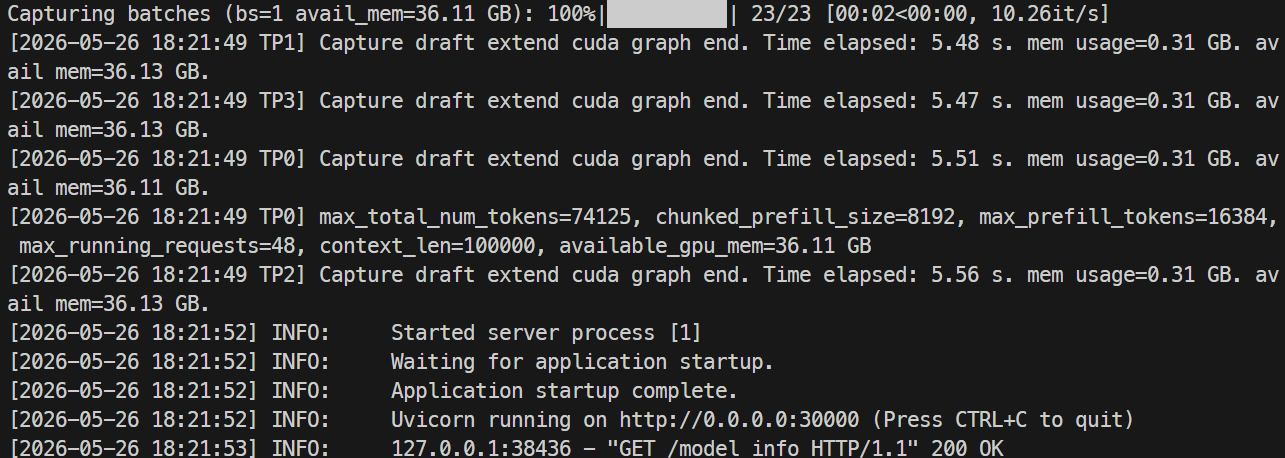
Cuando los logs muestren que Uvicorn se ejecuta en 0.0.0.0:30000, prueba el endpoint:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mistral-medium-3.5-eagle",
"messages": [
{
"role": "user",
"content": "Generate a simple Python game."
}
],
"reasoning_effort": "none",
"max_tokens": 300,
"temperature": 0.7,
"top_p": 0.95
}'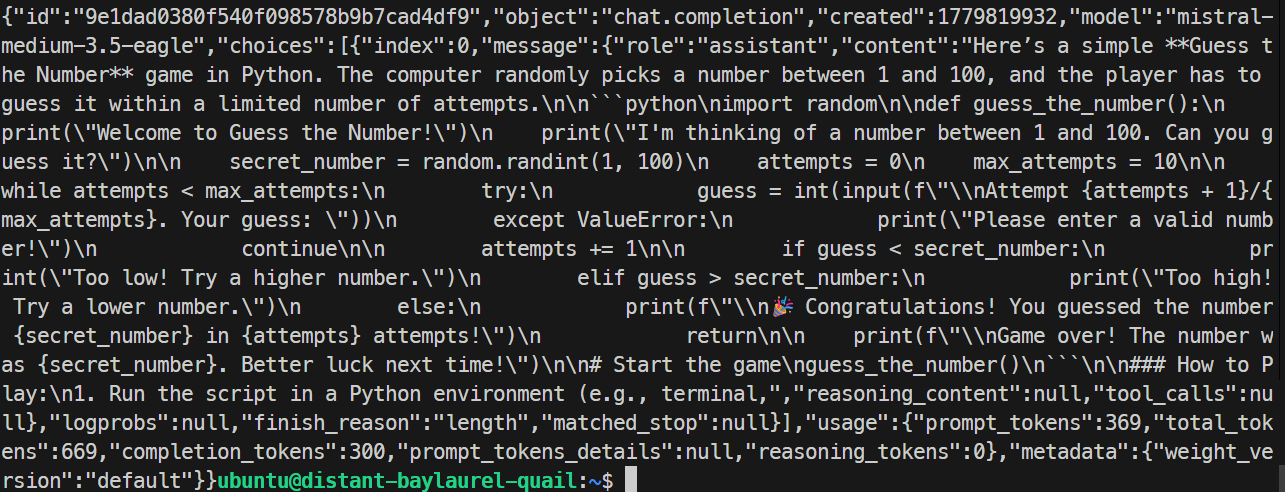
En mi prueba, el servidor con EAGLE respondió correctamente y generó un juego simple en Python. La ejecución alcanzó unos 32 tokens por segundo, ligeramente más lenta que la base, así que EAGLE no mejoró este test concreto.
Esto es normal: la decodificación especulativa depende mucho de la carga; la mejor forma de evaluarla es probarla con tus propios prompts y nivel de concurrencia.
OpenCode es un agente de codificación de IA de código abierto que puede conectarse a endpoints de modelos compatibles con OpenAI. Como SGLang expone Mistral Medium 3.5 mediante una API local compatible con OpenAI, podemos usarlo directamente en OpenCode.
Instala OpenCode si aún no lo has hecho:
curl -fsSL https://opencode.ai/install | bashDespués, ve al directorio de tu proyecto y crea un archivo opencode.json.
Añade la siguiente configuración:
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"sglang": {
"npm": "@ai-sdk/openai-compatible",
"name": "SGLang Local",
"options": {
"baseURL": "http://127.0.0.1:30000/v1",
"apiKey": "EMPTY"
},
"models": {
"mistral-medium-3.5-eagle": {
"name": "Mistral Medium 3.5 EAGLE",
"limit": {
"context": 100000,
"output": 8192
}
}
}
}
},
"model": "sglang/mistral-medium-3.5-eagle"
}Ahora lanza OpenCode desde el mismo directorio del proyecto:
OpencodeDeberías ver seleccionado Mistral Medium 3.5 EAGLE SGLang Local dentro de OpenCode. Esto significa que OpenCode ya está hablando con tu servidor local de SGLang a través del puerto 30000 reenviado, igual que haría con cualquier API compatible con OpenAI.
En mi prueba, pedí a OpenCode que explicara el proyecto, leyó los archivos del repositorio en pocos segundos y generó el resumen.
Luego le pedí crear un emulador Badger 2040; primero inspeccionó los archivos existentes, validó la estructura y después creó el archivo Python necesario. Todo el proceso llevó unos 2 minutos.
Después, le pedí probar el emulador en local. OpenCode ejecutó el código y abrió la ventana del emulador correctamente.
La tipografía no era exactamente la misma que en la pantalla real de Badger 2040, pero la maquetación, la hora, la fecha y la estructura general estaban casi perfectas.

El resultado me sorprendió de verdad porque había intentado la misma tarea con Claude Code y GPT-5.5 antes, y ambos tuvieron dificultades, mientras que Mistral Medium 3.5 lo resolvió muy bien con la configuración local de SGLang.
Hay algunos escollos por el camino. Te explico los problemas que puedes encontrarte y cómo resolverlos.
Para empezar, vas a necesitar paciencia. Toda la configuración me llevó casi 3 horas. Lanzar la VM con GPU tardó unos 15 minutos; instalar Docker y el toolkit de contenedores de NVIDIA, unos 10 minutos; descargar la imagen Docker de SGLang, unos 30 minutos; y descargar y cargar los pesos de Mistral Medium 3.5, alrededor de 1 hora.
Iniciar la configuración con EAGLE también lleva tiempo extra porque vuelve a cargar el modelo y puede descargar el borrador EAGLE. Si quieres una experiencia más fluida, usa redes más rápidas, GPUs más nuevas como H200 si están disponibles y suficiente almacenamiento para toda la caché de Hugging Face.
Si nvidia-smi funciona en el host pero Docker no accede a las GPUs, probablemente el runtime de contenedores de NVIDIA no está bien configurado. Vuelve a ejecutar la configuración del toolkit de NVIDIA y reinicia Docker:
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart dockerLa documentación de NVIDIA también recomienda este paso de configuración de runtime con nvidia-ctk para el acceso a GPU con Docker.
Asegúrate de montar la caché de Hugging Face dentro del contenedor:
-v ~/.cache/huggingface:/root/.cache/huggingfaceEsto permite a Docker reutilizar los archivos del modelo ya descargados en lugar de bajarlos cada vez. Hugging Face usa una caché local para evitar descargas repetidas.
El repositorio de Mistral Medium 3.5 es grande, así que la primera descarga puede tardar bastante. Si parece atascado, revisa tu velocidad de internet, el espacio en disco y tu token de Hugging Face. Asegúrate también de haber aceptado los términos de acceso al modelo en Hugging Face antes de ejecutar el contenedor.
El servidor no está listo hasta que los logs muestran que Uvicorn se ejecuta en el puerto 30000. Revisa los logs con:
docker logs -f mistral-sglango para EAGLE:
docker logs -f mistral-sglang-eagleAdemás, asegúrate de exponer correctamente el puerto con:
-p 30000:30000Es normal. La decodificación especulativa no garantiza mejoras en todas las peticiones. Funciona con un modelo borrador que propone tokens y el modelo principal que los verifica, pero la ganancia depende de la tasa de aceptación, la longitud del prompt y la salida, la concurrencia y la utilización de GPU.
Si te quedas sin memoria, reduce primero la longitud de contexto. Por ejemplo, empieza con --context-length 100000 en lugar de intentar el máximo desde el principio. También puedes bajar ligeramente --mem-fraction-static si el arranque falla, pero reducir el contexto suele ser el primer paso más sencillo.
Asegúrate de que el servidor SGLang está en marcha y de que tu opencode.json usa el endpoint local correcto:
"baseURL": "http://127.0.0.1:30000/v1"Si accedes al servidor desde tu máquina local, inicia SSH con reenvío de puertos:
ssh -L 30000:localhost:30000 ubuntu@XXXXXXDespués lanza OpenCode desde el mismo directorio donde guardaste el archivo opencode.json.
Me sorprendió lo fluida que fue la configuración técnica. Ejecutar Mistral Medium 3.5 128B con la imagen Docker nativa de SGLang fue mucho más fácil de lo que esperaba. La imagen se descargó bien, el modelo cargó, el endpoint compatible con OpenAI funcionó y OpenCode se conectó sin complicaciones.
Si vas a intentarlo, te recomiendo encarecidamente usar la imagen Docker de SGLang en lugar de instalar todo con paquetes de Python. Al instalar vía Python es fácil acabar rompiendo CUDA, PyTorch y otras dependencias. Docker mantiene todo limpio y aislado.
Pero lo más importante que me llevo de este experimento es el coste. Sinceramente no sé cómo las empresas de IA ganan dinero con la inferencia. Incluso con una de las opciones H100 PCIe más baratas y antiguas, esta configuración rondaba los 10 $ por hora. Y esto es solo un modelo de 128B en 4 GPUs. Imagina ejecutar un modelo de billones de parámetros en 16× H100. La factura puede llegar fácilmente a 40 $ o más por hora, sin contar almacenamiento, red, monitorización, disponibilidad y trabajo de ingeniería.
Para empresas pequeñas, no creo que tenga sentido servir modelos así en local salvo que haya una razón de peso, como privacidad, investigación o necesidad de control profundo sobre la pila de inferencia. El coste de inferencia ya es alto y la carga operativa también es un problema: hay que mantener el servidor, evitar caídas del modelo, vigilar la memoria de GPU, manejar contenedores fallidos y mantener el endpoint disponible.
El serverless tampoco resuelve realmente esto para modelos muy grandes: el cold start es demasiado largo. En esta configuración, lanzar la VM con GPU, instalar dependencias, descargar la imagen Docker, bajar los pesos y cargar el modelo llevó casi 3 horas en total.
Aunque tu configuración sea más rápida, cargar un modelo de este tamaño puede seguir llevando mucho. Si cada nueva petición requiere lanzar otro clúster de GPU y volver a cargar el modelo, se pierde el propósito del serverless. En la práctica, las empresas necesitan mantener clústeres de GPU calientes, lo que implica pagar incluso cuando las GPUs están inactivas.
Esto también explica por qué existe la tarificación fuera de pico: los proveedores quieren que se use la capacidad ociosa de GPU porque las GPUs sin uso queman dinero. Para quienes usan estos servicios, puede ser una forma de experimentar más barato, pero también evidencia lo compleja que es la economía de la inferencia con modelos grandes.
En conjunto, SGLang me gustó mucho para esta configuración. El flujo basado en Docker hizo que servir Mistral Medium 3.5 128B fuera mucho más sencillo de lo esperado, y la prueba con OpenCode fue realmente impresionante. Pero este experimento también me dejó algo muy claro: ejecutar modelos abiertos grandes en local es posible, pero hacerlo de forma fiable y asequible como producto real es un reto completamente distinto.
¡Aprende IA con DataCamp!
programa
Curso
Curso
blog
Ryan Ong
8 min
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Dimitri Didmanidze
Tutorial
Moez Ali



