Tracks
開発者向けアソシエイトAIエンジニア
26時間
このガイドでは、H100 80GB×4のGPU仮想マシンを使用しました。Mistral Medium 3.5は高密度の128Bモデルのため、マルチGPU構成が必要です。SGLangはH100またはH200で--tp 4を使ったテンサ並列を推奨しています。モデルは大きなコンテキストウィンドウをサポートしますが、まずは10万トークンから始め、フルの256Kコンテキストは動作確認後に検討することをおすすめします。
今回はHyperbolicを使用しました。フルGPUのVMにアクセスできるため、Dockerのインストール、NVIDIAコンテナランタイムの設定、SGLangのDockerイメージの手動実行が容易だからです。RunPodやVast.aiのようなプラットフォームも利用できますが、インスタンスによってはカスタムDocker環境に結び付けられており、自由度が下がる場合があります。
Hyperbolicでは、H100 PCIe 80GBを選択し、GPUを4枚、ストレージは約3TBを追加、SSH公開鍵を登録し、インスタンス名はMM-35のように付けます。今回はコスト面からH100 PCIeを選びました。
「Start Building」をクリック後、起動まで約10分かかる場合があります。準備が整うと、次のステップで使うSSH接続コマンドが表示されます。
インスタンスが準備できたら、Hyperbolicのダッシュボードに表示されるSSHコマンドを使い、ローカルのターミナルから接続します。
ssh ubuntu@XXXXXX後でローカルマシンからSGLang APIにアクセスするには、30000番ポートをフォワードしておくと便利です。
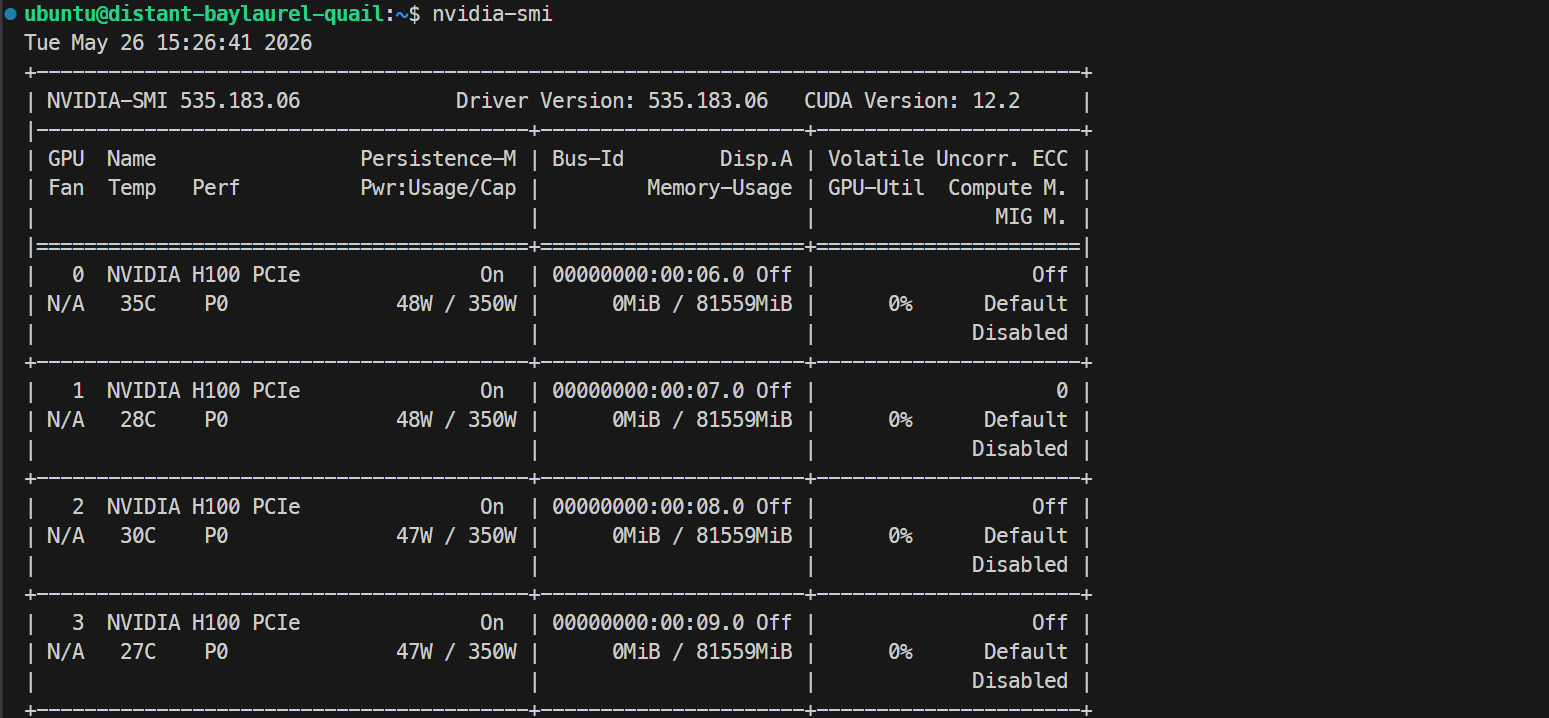
ssh -L 30000:localhost:30000 ubuntu@XXXXXXSSH鍵にパスフレーズを設定している場合は、プロンプトに従って入力します。ログイン後、GPUが認識されているか確認します。
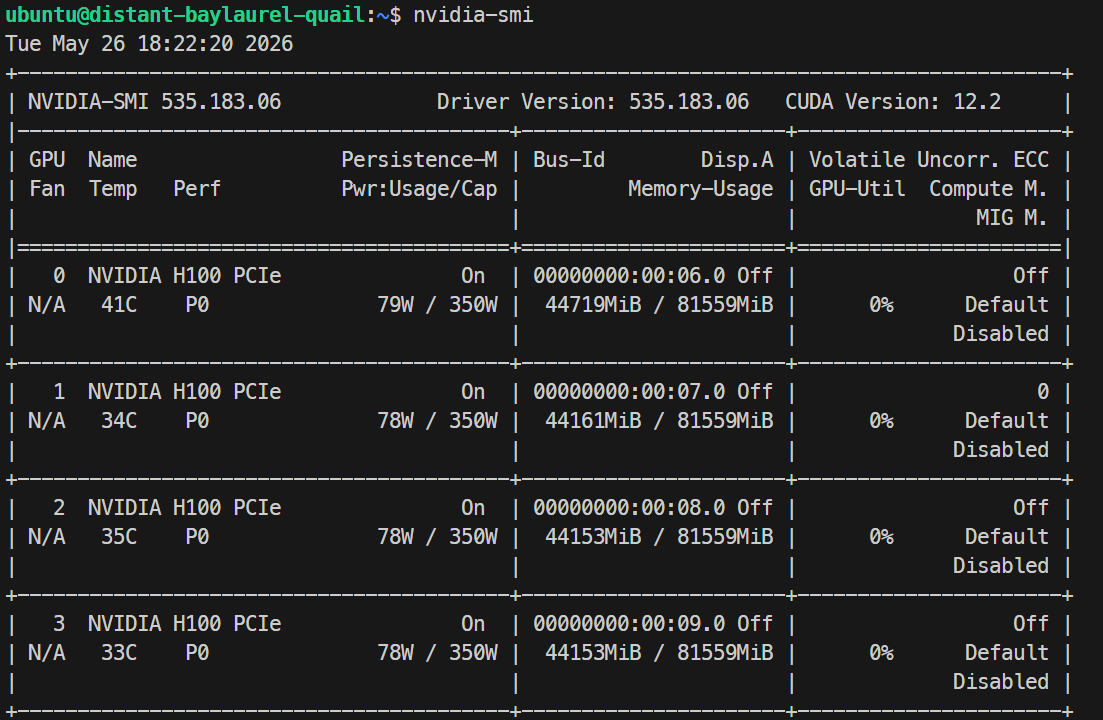
Nvidia-smiNVIDIA H100 PCIe 80GBが4枚表示されるはずです。これでDockerとSGLangのセットアップ準備が整いました。
まず、後でMistralモデルをダウンロードできるよう、Hugging Faceのトークンをエクスポートします。
echo 'export HF_TOKEN="your_huggingface_token_here"' >> ~/.bashrc
source ~/.bashrc注:Hugging FaceのトークンはAccess Tokensページから取得できます。
Hugging Faceのキャッシュフォルダを作成します。
mkdir -p ~/.cache/huggingface次にDockerをインストールします。
sudo apt update
sudo apt install -y docker.ioDockerを起動し、再起動後も自動起動するように設定します。
sudo systemctl start docker
sudo systemctl enable dockerDockerが正しくインストールされたか確認します。
docker –versionまた、Docker Hubの公開イメージを検索できるか、検索コマンドでも確認できます。
docker search nvidia/cudaNVIDIA CUDAのイメージ一覧が返ってくるはずです。後ほど、これらのCUDAイメージの1つを使ってDockerからGPUへアクセスできるか検証します。
次に、sudoなしでDockerコマンドを実行できるようユーザーを設定します。
sudo usermod -aG docker $USER
newgrp docker続いて、DockerからGPUにアクセスできるようNVIDIA Container Toolkitをインストール・設定します。
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/libnvidia-container/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt update
sudo apt install -y nvidia-container-toolkit
sudo nvidia-ctk runtime configure --runtime=docker
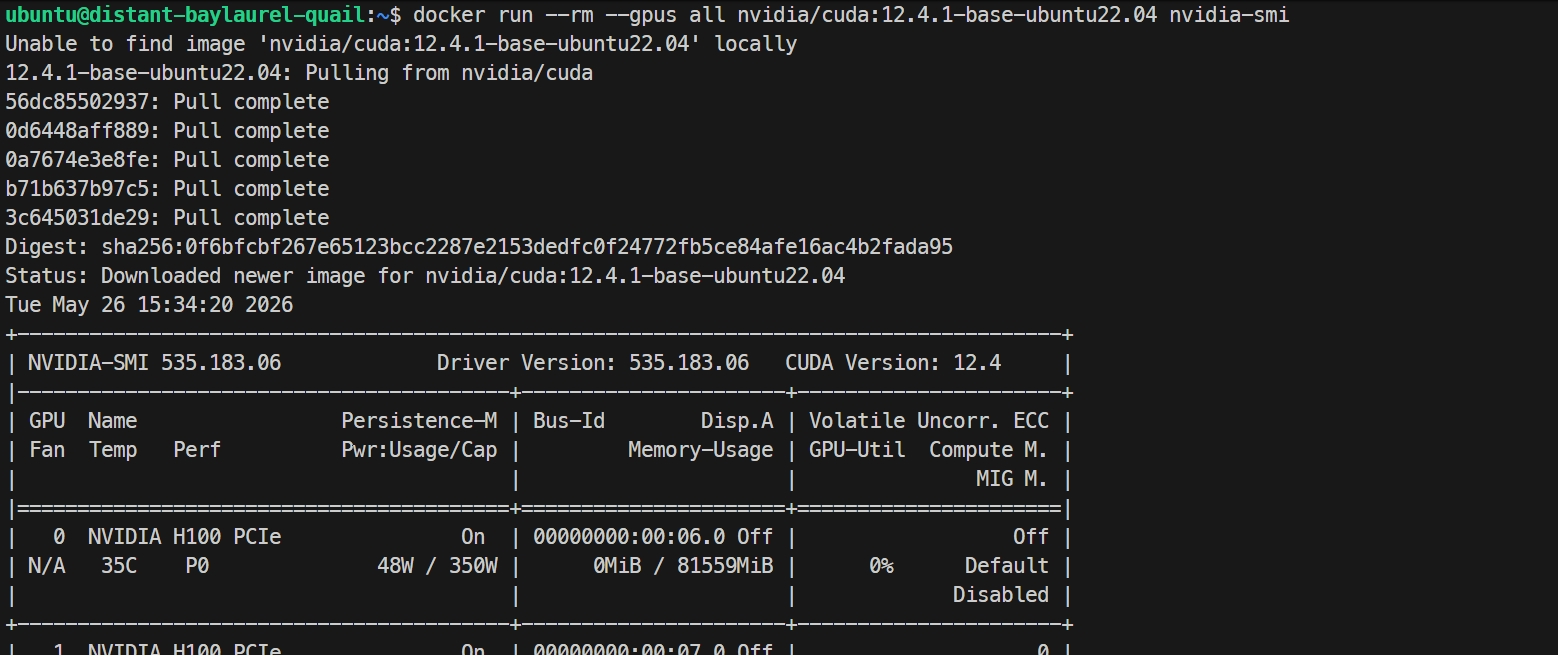
sudo systemctl restart docker最後に、コンテナ内からGPUが見えるかテストします。
docker run --rm --gpus all nvidia/cuda:12.4.1-base-ubuntu22.04 nvidia-smiコンテナ内でも同じH100の一覧が表示されれば、GPU対応のDocker環境は正しく動作しています。
次に、Mistral Medium 3.5向けにビルドされたSGLangのDockerイメージを取得します。
docker pull lmsysorg/sglang:dev-mistral-medium-3.5
回線速度によっては時間がかかります。筆者の環境では約10分でした。ダウンロード完了後、Dockerは次のようなメッセージを表示します。
Status: Downloaded newer image for lmsysorg/sglang:dev-mistral-medium-3.5SGLangサーバーを起動します。
docker run -d \
--name mistral-sglang \
--gpus all \
--shm-size 64g \
--ipc=host \
--cap-add SYS_NICE \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e HF_TOKEN=$HF_TOKEN \
-e PYTORCH_ALLOC_CONF=expandable_segments:True \
lmsysorg/sglang:dev-mistral-medium-3.5 \
sglang serve \
--model-path mistralai/Mistral-Medium-3.5-128B \
--served-model-name mistral-medium-3.5 \
--host 0.0.0.0 \
--port 30000 \
--tp 4 \
--trust-remote-code \
--dtype bfloat16 \
--context-length 100000 \
--mem-fraction-static 0.85 \
--disable-custom-all-reduce \
--tool-call-parser mistral \
--reasoning-parser mistral--dtype bfloat16を選んだのは、後述のEAGLE構成でもbf16が必要であり、ベース実行と推測実行でdtypeを揃えて比較を容易にするためです。また、初回はデバッグしやすいよう--context-length 100000から始めています。
コンテナのログは次で確認します。
docker logs -f mistral-sglang
初回起動時は、SGLangがHugging Faceからモデルファイルをダウンロードするため時間がかかります。リポジトリが大きいため、インスタンスの速度によっては1時間以上かかることがあります。
サーバーの準備が整うと、ログにUvicornが30000番ポートで稼働している旨が表示されます。
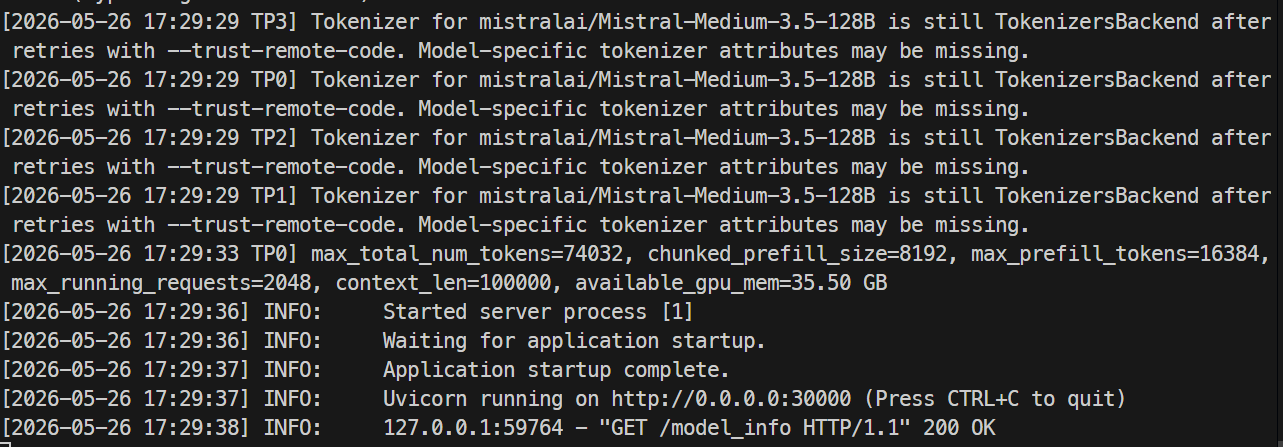
別のターミナルで再度SSH接続し、エンドポイントを確認します。
curl http://localhost:30000/v1/modelsmistral-medium-3.5が、max_model_lenとして100000と共に表示されるはずです。
{"object":"list","data":[{"id":"mistral-medium-3.5","object":"model","created":1779816738,"owned_by":"sglang","root":"mistral-medium-3.5","parent":null,"max_model_len":100000}]}最後に、チャット補完をテストします。
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mistral-medium-3.5",
"messages": [
{
"role": "user",
"content": "Write a short introduction to Mistral Medium 3.5."
}
],
"max_tokens": 300,
"temperature": 0.7,
"top_p": 0.95
}'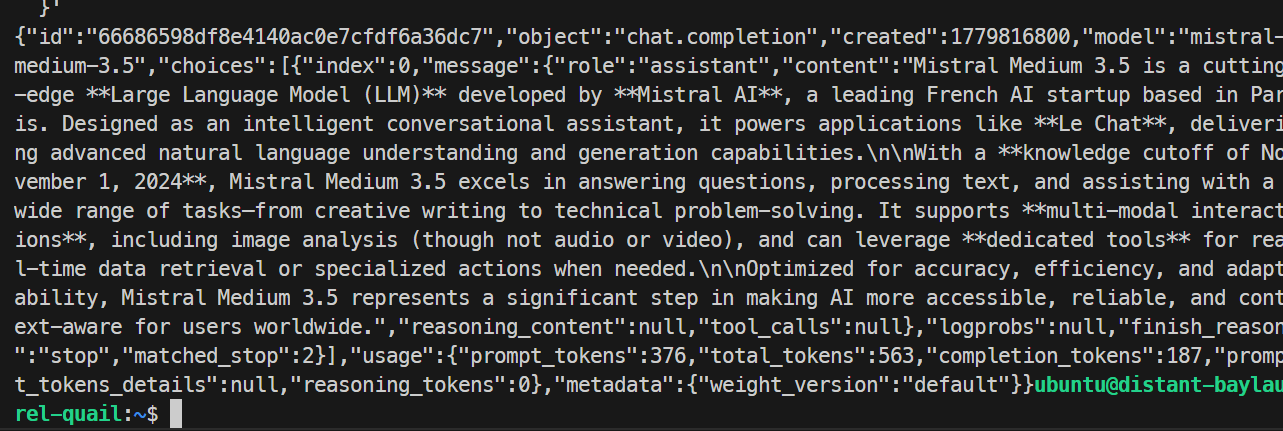
筆者のテストでは、モデルは正常に応答し、要求を問題なく完了しました。SGLangのエンドポイントが機能していることを確認でき、ベース実行では約35.6トークン/秒の生成速度でした。
推測デコーディングは、小型のドラフトモデルで先読みしたトークンを大モデルで検証することで生成を高速化する手法です。
EAGLEはレイテンシに敏感なサービングに役立ちます。特にMistral Medium 3.5のような大規模モデルをローカルで動かす場合に有効です。ただし常に速くなるわけではなく、効果はプロンプト長、出力長、同時実行数、GPU使用率などに大きく依存するため、試してみる価値があります。
まず、ベースのコンテナを削除します。
docker rm -f mistral-sglang次に、EAGLE版を起動します。
docker run -d \
--name mistral-sglang-eagle \
--gpus all \
--shm-size 64g \
--ipc=host \
--cap-add SYS_NICE \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e HF_TOKEN="$HF_TOKEN" \
-e PYTORCH_ALLOC_CONF=expandable_segments:True \
lmsysorg/sglang:dev-mistral-medium-3.5 \
sglang serve \
--model-path mistralai/Mistral-Medium-3.5-128B \
--served-model-name mistral-medium-3.5-eagle \
--host 0.0.0.0 \
--port 30000 \
--tp 4 \
--trust-remote-code \
--dtype bfloat16 \
--context-length 100000 \
--mem-fraction-static 0.85 \
--disable-custom-all-reduce \
--tool-call-parser mistral \
--reasoning-parser mistral \
--enable-metrics \
--speculative-algorithm EAGLE \
--speculative-draft-model-path mistralai/Mistral-Medium-3.5-128B-EAGLE \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4SGLangは、--speculative-num-steps 3、--speculative-eagle-topk 1、--speculative-num-draft-tokens 4というEAGLE構成を出発点として推奨しています。初回はEAGLEのドラフトモデルもダウンロードされるため、起動に時間がかかることがあります。
読み込みが完了したら、nvidia-smiでGPU使用量を確認できます。筆者の環境では、H100あたり約44GBを使用していました。
ログは次のコマンドで監視します。
docker logs -f mistral-sglang-eagle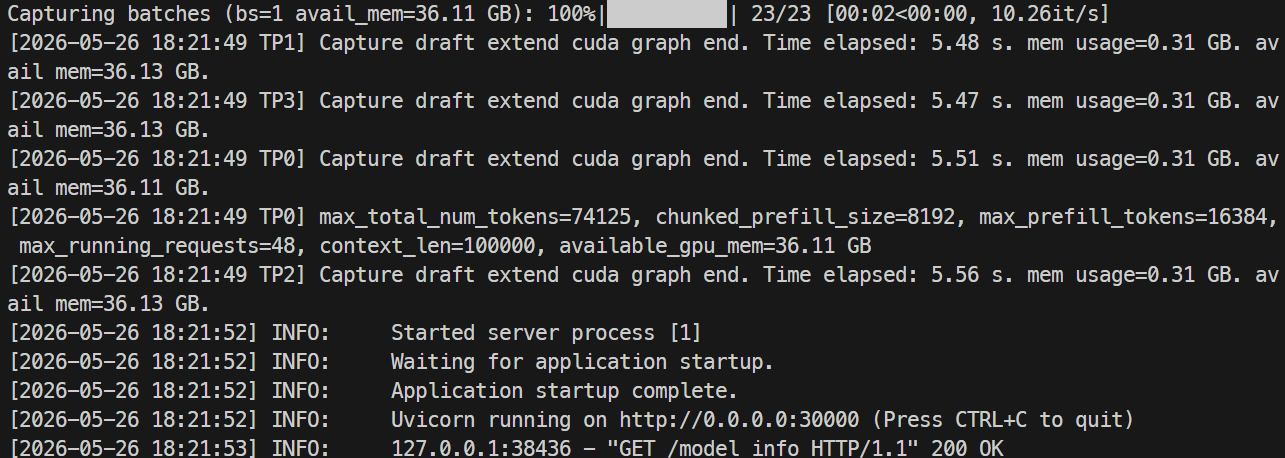
ログに0.0.0.0:30000でUvicornが稼働中と表示されたら、エンドポイントをテストします。
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mistral-medium-3.5-eagle",
"messages": [
{
"role": "user",
"content": "Generate a simple Python game."
}
],
"reasoning_effort": "none",
"max_tokens": 300,
"temperature": 0.7,
"top_p": 0.95
}'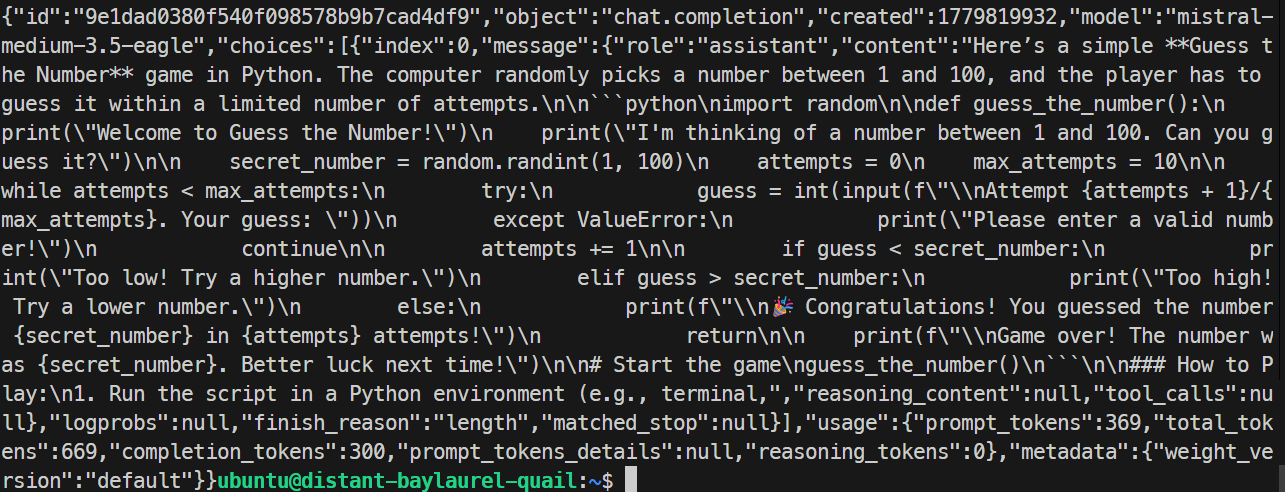
テストでは、EAGLEサーバーは正しく応答し、シンプルなPythonゲームを生成しました。生成速度は約32トークン/秒で、ベース実行よりやや遅く、このケースではEAGLEによる改善は見られませんでした。
これは珍しくありません。推測デコーディングはワークロードに大きく依存します。自分のプロンプトや同時実行レベルで評価するのが最善です。
OpenCodeは、OpenAI互換のモデルエンドポイントに接続できるオープンソースのAIコーディングエージェントです。SGLangはMistral Medium 3.5をローカルのOpenAI互換APIとして公開するため、OpenCodeからそのまま利用できます。
未インストールの場合はOpenCodeをインストールします。
curl -fsSL https://opencode.ai/install | bash次に、プロジェクトディレクトリへ移動し、opencode.jsonファイルを作成します。
以下の設定を追加します。
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"sglang": {
"npm": "@ai-sdk/openai-compatible",
"name": "SGLang Local",
"options": {
"baseURL": "http://127.0.0.1:30000/v1",
"apiKey": "EMPTY"
},
"models": {
"mistral-medium-3.5-eagle": {
"name": "Mistral Medium 3.5 EAGLE",
"limit": {
"context": 100000,
"output": 8192
}
}
}
}
},
"model": "sglang/mistral-medium-3.5-eagle"
}同じプロジェクトディレクトリからOpenCodeを起動します。
OpencodeOpenCode内で、Mistral Medium 3.5 EAGLE(SGLang Local)が選択されているのが確認できるはずです。これは、OpenCodeがフォワードした30000番ポート経由でローカルのSGLangサーバーと通信していることを意味し、OpenAI互換APIと同様に扱えます。
テストでは、プロジェクトの説明を依頼すると、数秒でリポジトリのファイルを読み込み、要約を生成しました。
続いて、Badger 2040エミュレーターの作成を依頼したところ、既存のプロジェクトファイルを調査し、構成を検証したうえで必要なPythonファイルを作成しました。全工程で約2分でした。
その後、ローカルでのエミュレーターのテストも依頼しました。OpenCodeはコードを実行し、エミュレーターのウィンドウを正常に起動しました。
フォントは実機のBadger 2040表示と完全一致ではありませんでしたが、レイアウト、時刻表示、日付の配置、全体の構成はほぼ完璧でした。

正直、この結果には驚きました。同じタスクを以前にClaude CodeやGPT-5.5で試した際は苦戦しましたが、Mistral Medium 3.5はローカルのSGLang構成で非常にうまくこなしました。
いくつか落とし穴があります。起こりうる問題とその解決策を順に説明します。
まず、忍耐強く進めてください。全行程で約3時間要しました。GPU VMの起動に約15分、DockerとNVIDIAコンテナツールキットのインストールに約10分、SGLangのDockerイメージ取得に約30分、Mistral Medium 3.5のモデル重みのダウンロードと読み込みに約1時間かかりました。
EAGLE構成の起動も、再度モデルを読み込み、ドラフトモデルをダウンロードする可能性があるため時間を要します。よりスムーズに進めるには、高速なネットワーク、可能であればH200などの新しいGPU、十分なHugging Faceキャッシュ用ストレージを用意してください。
ホストではnvidia-smiが動くのにDockerからGPUにアクセスできない場合、NVIDIAコンテナランタイムの設定に問題がある可能性が高いです。NVIDIAコンテナツールキットの設定を再実行し、Dockerを再起動してください。
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart dockerNVIDIAのドキュメントでも、DockerでGPUを使う際にはこのnvidia-ctkによるランタイム設定が推奨されています。
コンテナにHugging Faceのキャッシュをマウントしているか確認してください。
-v ~/.cache/huggingface:/root/.cache/huggingfaceこれにより、すでに取得済みのモデルファイルをDockerが再利用し、毎回の再ダウンロードを防げます。Hugging Faceはローカルキャッシュで最新ファイルの再取得を避けます。
Mistral Medium 3.5のリポジトリは大きいため、初回ダウンロードに時間がかかります。進まない場合は回線速度、ディスク容量、Hugging Faceトークンを確認してください。また、コンテナ実行前に必要なモデル利用規約に同意しているかも確認しましょう。
ログにUvicornが30000番ポートで稼働中と表示されるまでサーバーは準備完了ではありません。ログを確認してください。
docker logs -f mistral-sglangEAGLEの場合:
docker logs -f mistral-sglang-eagleまた、ポートが正しく公開されているかも確認します。
-p 30000:30000よくあることです。推測デコーディングはすべてのリクエストで高速化を保証するものではありません。ドラフトモデルが提案しメインモデルが検証する仕組みのため、受理率、プロンプト長、出力長、同時実行数、GPU利用率によって効果が変わります。
メモリに問題が出る場合は、まずコンテキスト長を短くしてください。たとえば、いきなりフルではなく--context-length 100000から始めます。起動に失敗する場合は--mem-fraction-staticを少し下げる方法もありますが、まずはコンテキスト長の削減が手っ取り早いです。
SGLangサーバーが稼働しており、opencode.jsonで正しいローカルエンドポイントを指定しているか確認してください。
"baseURL": "http://127.0.0.1:30000/v1"ローカルマシンからサーバーにアクセスする場合は、ポートフォワーディング付きでSSH接続します。
ssh -L 30000:localhost:30000 ubuntu@XXXXXXその後、opencode.jsonが保存されているディレクトリからOpenCodeを起動してください。
技術的なセットアップは想像以上にスムーズでした。SGLangの公式DockerイメージでMistral Medium 3.5 128Bを動かすのは予想よりずっと簡単で、Dockerイメージの取得、モデルの読み込み、OpenAI互換エンドポイント、OpenCodeとの接続はいずれも問題なく動作しました。
もしご自身で試すなら、Pythonパッケージで一式を入れるよりSGLangのDockerイメージを強く推奨します。Python経由のインストールはCUDAやPyTorchなどの依存関係に影響しやすい一方、Dockerならクリーンで分離された状態を保てます。
ただし、この実験で最も強く感じたのはコスト面です。正直、推論でどう収益化しているのか不思議に思うほどです。今回は比較的安価で古いH100 PCIe構成にもかかわらず、コストは時給10ドル前後でした。これでさえ4GPUの128Bモデルです。仮に兆単位パラメータの巨大モデルをH100×16で動かすと、時給40ドル超に容易に達するでしょう。ストレージ、ネットワーキング、監視、可用性、エンジニアリング工数を考慮する前の話です。
小規模な企業にとって、強い理由(プライバシー、研究、推論スタックの深い制御など)がない限り、このようなモデルをローカル提供するのは得策とは言えません。推論コストが高いだけでなく、運用の負担も大きいからです。サーバーの常時稼働、モデルの安定性確保、GPUメモリ監視、コンテナの障害対応、エンドポイントの可用性維持などが必要になります。
サーバーレスも、非常に大きなモデルに対しては万能ではありません。コールドスタートが長すぎるのです。今回の構成では、GPU VMの起動、依存関係のインストール、Dockerイメージの取得、重みのダウンロード、モデルの読み込みまで、合計で約3時間を要しました。
仮に環境が速くても、これほどの規模のモデルの読み込みはそれなりに時間がかかります。新しいリクエストごとにGPUクラスターを起動してモデルを読み込むようでは、サーバーレスの利点が損なわれます。実務ではGPUクラスターを常時ウォーム状態で維持する必要があり、アイドル時でもコストが発生します。
この事情はオフピークGPU料金が存在する理由の説明にもなります。プロバイダーはアイドルGPUの空き時間を有効活用したいのです。利用者にとっては安価に実験できる利点がある一方で、大規模モデル推論の経済性がどれほど難しいかを物語っています。
総じて、このセットアップにおけるSGLangの使い勝手は非常に良好でした。Docker中心のワークフローにより、Mistral Medium 3.5 128Bの提供は想像以上に容易で、OpenCodeでのテストも実に印象的でした。ただし同時に、ローカルで大規模なオープンモデルを動かすことは可能でも、それを製品として安定かつ低コストで運用するのは全く別次元の課題だという点も明確になりました。
DataCampでAIを学ぼう!
Tracks
Courses
Courses