
Lernpfad
Associate AI Engineer für Entwickler
26 Std.
Für diesen Guide habe ich eine VM mit 4× H100 80GB GPUs genutzt. Mistral Medium 3.5 ist ein dichtes 128B-Modell und benötigt daher ein Multi-GPU-Setup. SGLang empfiehlt den Betrieb mit Tensor-Parallelisierung via --tp 4 auf H100- oder H200-GPUs. Das Modell unterstützt ein großes Kontextfenster, aber ich empfehle, zunächst mit 100.000 Tokens statt der vollen 256K zu starten, um das Setup einfacher zu testen und zu debuggen.
Ich habe Hyperbolic verwendet, weil es Zugriff auf eine vollwertige GPU-VM bietet. Dadurch ist es leichter, Docker zu installieren, die NVIDIA-Containerruntime zu konfigurieren und das SGLang-Docker-Image manuell auszuführen. Du kannst auch Plattformen wie RunPod oder Vast.ai nutzen, aber manche ihrer Instanzen sind bereits an benutzerdefinierte Docker-Umgebungen gebunden, was dir weniger Kontrolle gibt.
Wähle in Hyperbolic H100 PCIe 80GB, dann 4 GPUs, füge etwa 3 TB Speicher hinzu, hinterlege deinen SSH-Public-Key und gib der Instanz einen Namen wie MM-35. Ich habe PCIe gewählt, weil es für diesen Test die günstigste H100-Option war.
Nach einem Klick auf Start Building braucht die Maschine etwa 10 Minuten zum Starten. Sobald sie bereit ist, zeigt Hyperbolic den SSH-Befehl für den nächsten Schritt an.
Wenn die Instanz bereit ist, verbindest du dich vom lokalen Terminal aus mit dem im Hyperbolic-Dashboard angezeigten SSH-Befehl:
ssh ubuntu@XXXXXXDamit du später von deinem Rechner auf die SGLang-API zugreifen kannst, kannst du zusätzlich den Port 30000 weiterleiten:
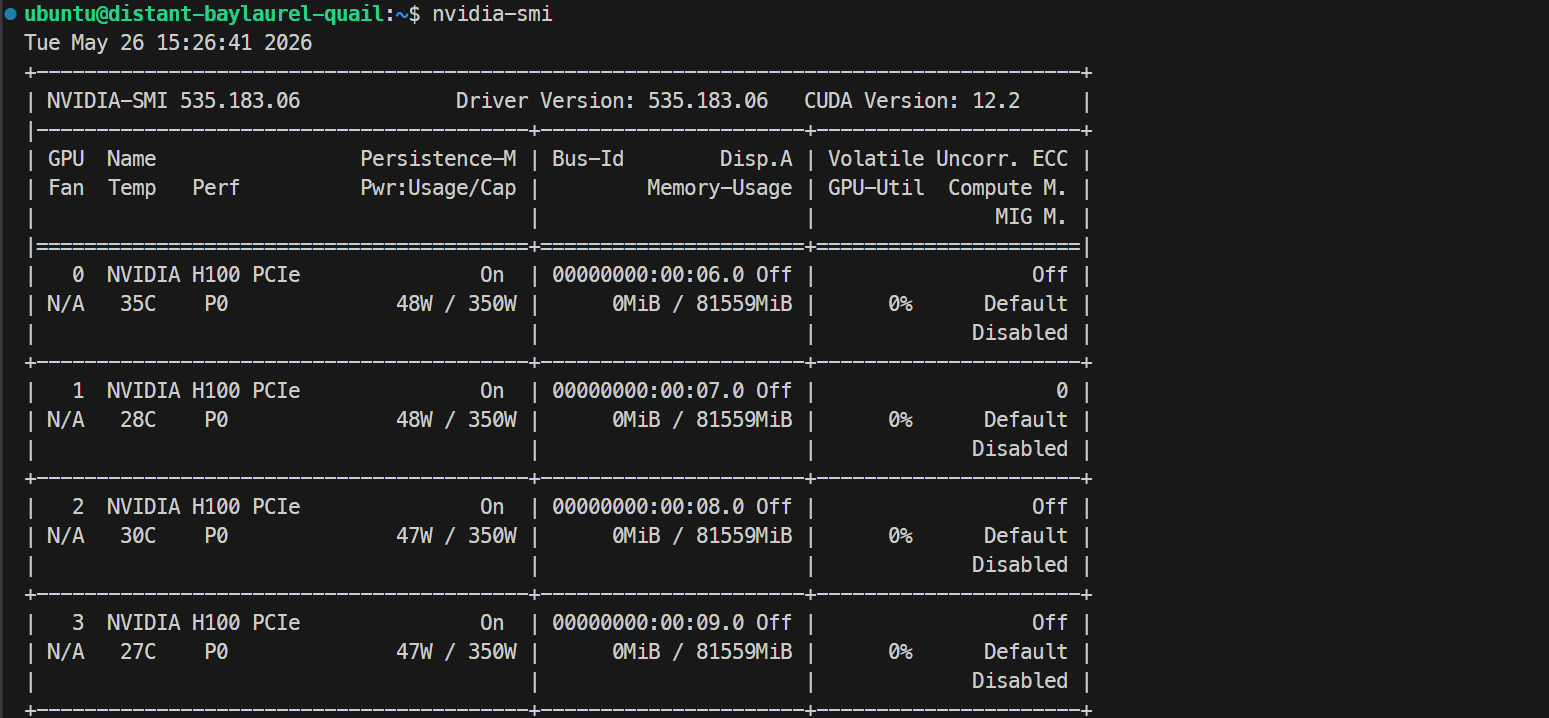
ssh -L 30000:localhost:30000 ubuntu@XXXXXXWenn dein SSH-Schlüssel eine Passphrase hat, gib sie bei Aufforderung ein. Prüfe nach dem Login, ob alle GPUs verfügbar sind:
Nvidia-smiDu solltest 4× NVIDIA H100 PCIe 80GB sehen. Das bestätigt, dass der Server für Docker und SGLang bereit ist.
Exportiere zuerst deinen Hugging-Face-Token, damit der Server später das Mistral-Modell herunterladen kann:
echo 'export HF_TOKEN="your_huggingface_token_here"' >> ~/.bashrc
source ~/.bashrcHinweis: Du findest deinen Hugging-Face-Token auf der Seite Access Tokens.
Erstelle den Hugging-Face-Cache-Ordner:
mkdir -p ~/.cache/huggingfaceInstalliere jetzt Docker:
sudo apt update
sudo apt install -y docker.ioStarte Docker und aktiviere den Autostart nach einem Neustart:
sudo systemctl start docker
sudo systemctl enable dockerPrüfe, ob Docker korrekt installiert wurde:
docker –versionMit dem Docker-Suchbefehl kannst du außerdem prüfen, ob öffentliche Images von Docker Hub gefunden werden:
docker search nvidia/cudaDas sollte verfügbare NVIDIA-CUDA-Images zurückgeben. Später nutzen wir eines davon, um zu verifizieren, dass Docker auf die GPUs zugreifen kann.
Erlaube als Nächstes deinem Nutzer, Docker-Befehle ohne sudo auszuführen:
sudo usermod -aG docker $USER
newgrp dockerInstalliere und konfiguriere nun das NVIDIA Container Toolkit, damit Docker auf die GPUs zugreifen kann:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/libnvidia-container/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt update
sudo apt install -y nvidia-container-toolkit
sudo nvidia-ctk runtime configure --runtime=docker
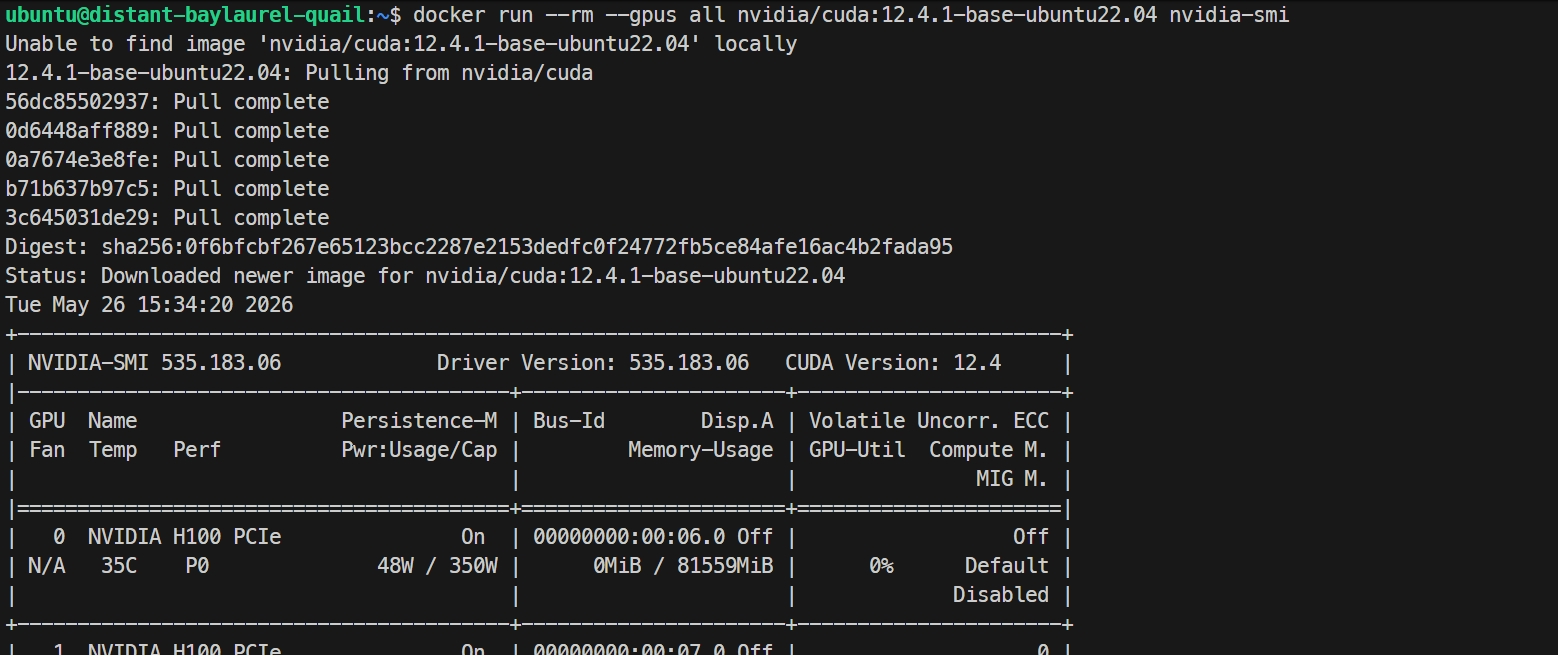
sudo systemctl restart dockerTeste abschließend, ob Docker die GPUs innerhalb eines Containers sieht:
docker run --rm --gpus all nvidia/cuda:12.4.1-base-ubuntu22.04 nvidia-smiWenn hier die gleichen H100-GPUs innerhalb des Containers angezeigt werden, funktioniert dein GPU-Docker-Setup korrekt.
Ziehe als Nächstes das für Mistral Medium 3.5 gebaute SGLang-Docker-Image:
docker pull lmsysorg/sglang:dev-mistral-medium-3.5
Das kann je nach Internetgeschwindigkeit etwas dauern. Bei mir waren es rund 10 Minuten. Nach dem Download zeigt Docker eine Erfolgsmeldung wie:
Status: Downloaded newer image for lmsysorg/sglang:dev-mistral-medium-3.5Starte jetzt den SGLang-Server:
docker run -d \
--name mistral-sglang \
--gpus all \
--shm-size 64g \
--ipc=host \
--cap-add SYS_NICE \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e HF_TOKEN=$HF_TOKEN \
-e PYTORCH_ALLOC_CONF=expandable_segments:True \
lmsysorg/sglang:dev-mistral-medium-3.5 \
sglang serve \
--model-path mistralai/Mistral-Medium-3.5-128B \
--served-model-name mistral-medium-3.5 \
--host 0.0.0.0 \
--port 30000 \
--tp 4 \
--trust-remote-code \
--dtype bfloat16 \
--context-length 100000 \
--mem-fraction-static 0.85 \
--disable-custom-all-reduce \
--tool-call-parser mistral \
--reasoning-parser mistralIch habe --dtype bfloat16 gewählt, weil das spätere EAGLE-Setup ebenfalls bf16 erfordert. So bleiben Basistest und Speculative-Run konsistent. Außerdem starte ich mit --context-length 100000 statt dem vollen Kontextfenster, um die erste Inbetriebnahme leichter debuggen zu können.
Prüfe die Container-Logs mit:
docker logs -f mistral-sglang
Der erste Start dauert länger, da SGLang die Modelldateien von Hugging Face herunterladen muss. Das komplette Repository ist groß und kann – je nach Instanz – etwa eine Stunde oder mehr beanspruchen.
Wenn der Server bereit ist, sollten die Logs anzeigen, dass Uvicorn auf Port 30000 läuft.
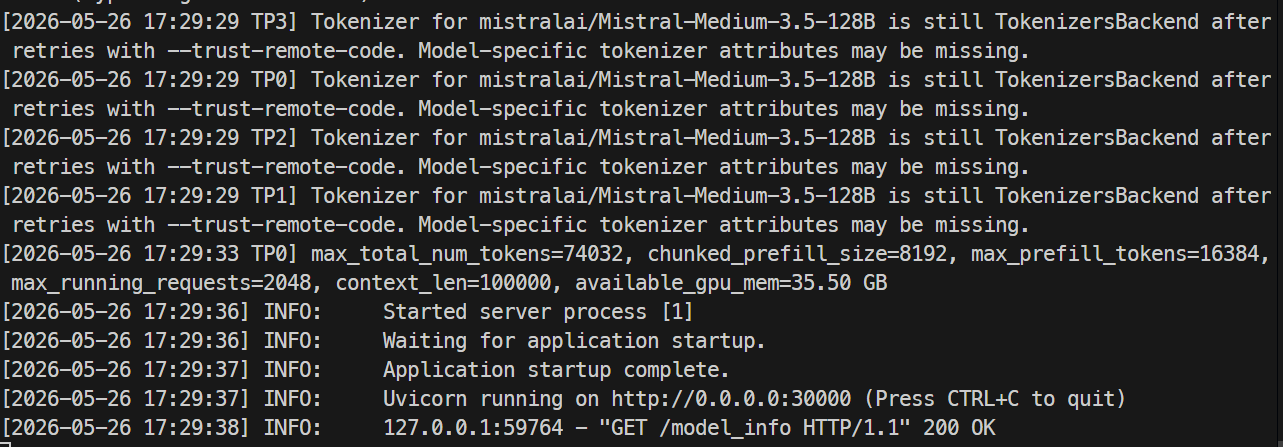
Öffne in einem anderen Terminal erneut eine SSH-Verbindung zum Server und prüfe den Model-Endpoint:
curl http://localhost:30000/v1/modelsDu solltest mistral-medium-3.5 mit einem max_model_len von 100000 sehen.
{"object":"list","data":[{"id":"mistral-medium-3.5","object":"model","created":1779816738,"owned_by":"sglang","root":"mistral-medium-3.5","parent":null,"max_model_len":100000}]}Teste abschließend eine Chat-Completion:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mistral-medium-3.5",
"messages": [
{
"role": "user",
"content": "Write a short introduction to Mistral Medium 3.5."
}
],
"max_tokens": 300,
"temperature": 0.7,
"top_p": 0.95
}'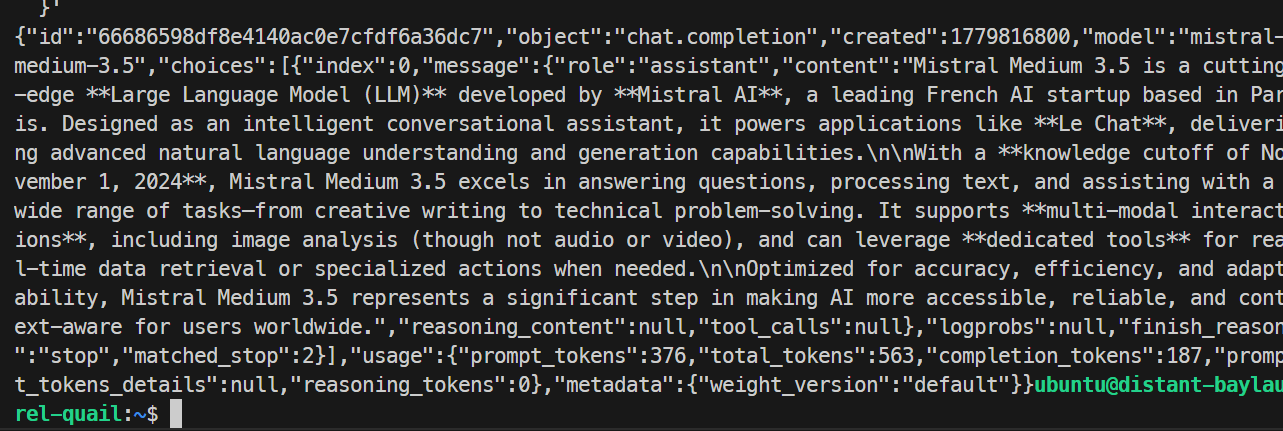
In meinem Test hat das Modell sauber geantwortet und die Anfrage korrekt abgeschlossen – der SGLang-Endpoint funktioniert also. Der Basistest lag bei rund 35,6 Tokens pro Sekunde.
Speculative Decoding kann die Generierung beschleunigen, indem ein kleineres Draft-Modell Tokens vorhersagt, während das Hauptmodell diese verifiziert.
EAGLE ist hier hilfreich, weil es für latenzkritisches Serving ausgelegt ist – besonders, wenn du ein großes Modell wie Mistral Medium 3.5 lokal betreibst. Es ist nicht immer schneller, aber einen Test wert, denn der Nutzen hängt von Prompt-Länge, Output-Länge, Parallelität und GPU-Auslastung ab.
Entferne zuerst den Basis-Container:
docker rm -f mistral-sglangStarte dann die EAGLE-Variante:
docker run -d \
--name mistral-sglang-eagle \
--gpus all \
--shm-size 64g \
--ipc=host \
--cap-add SYS_NICE \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e HF_TOKEN="$HF_TOKEN" \
-e PYTORCH_ALLOC_CONF=expandable_segments:True \
lmsysorg/sglang:dev-mistral-medium-3.5 \
sglang serve \
--model-path mistralai/Mistral-Medium-3.5-128B \
--served-model-name mistral-medium-3.5-eagle \
--host 0.0.0.0 \
--port 30000 \
--tp 4 \
--trust-remote-code \
--dtype bfloat16 \
--context-length 100000 \
--mem-fraction-static 0.85 \
--disable-custom-all-reduce \
--tool-call-parser mistral \
--reasoning-parser mistral \
--enable-metrics \
--speculative-algorithm EAGLE \
--speculative-draft-model-path mistralai/Mistral-Medium-3.5-128B-EAGLE \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4SGLang empfiehlt dieses EAGLE-Setup als guten Startpunkt: --speculative-num-steps 3, --speculative-eagle-topk 1 und --speculative-num-draft-tokens 4. Der erste Start dauert länger, weil auch das EAGLE-Draft-Modell heruntergeladen wird.
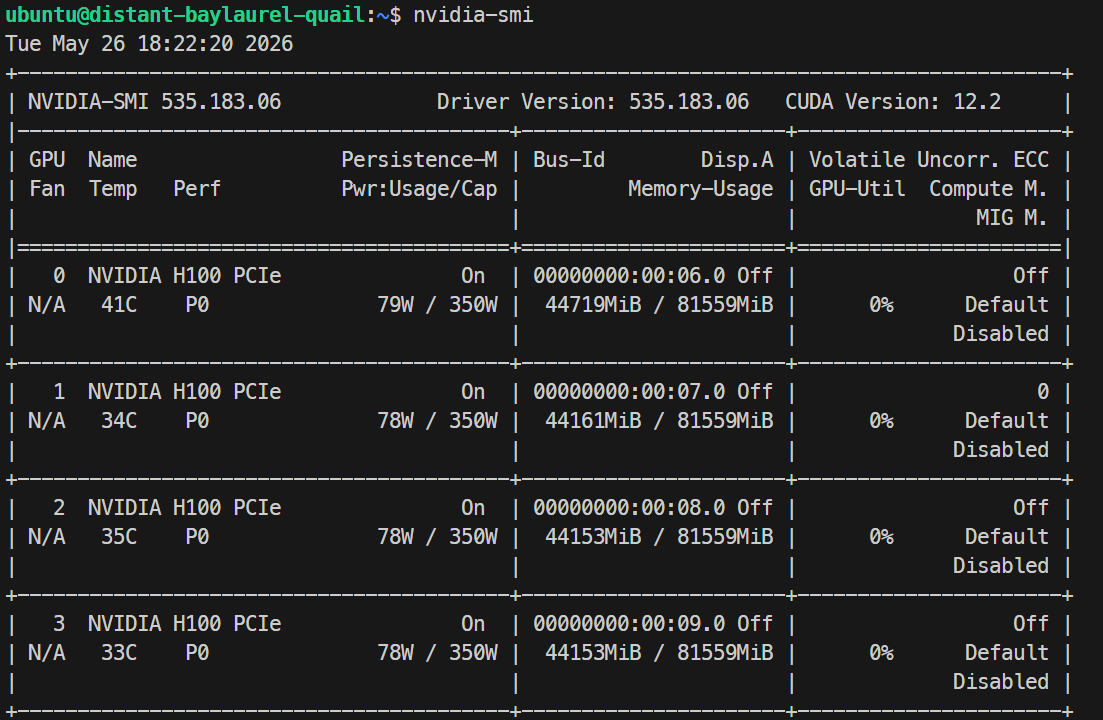
Sobald geladen, kannst du die GPU-Auslastung mit nvidia-smi prüfen; in meinem Lauf belegte das Modell etwa 44 GB pro H100-GPU.
Überwache die Logs mit:
docker logs -f mistral-sglang-eagle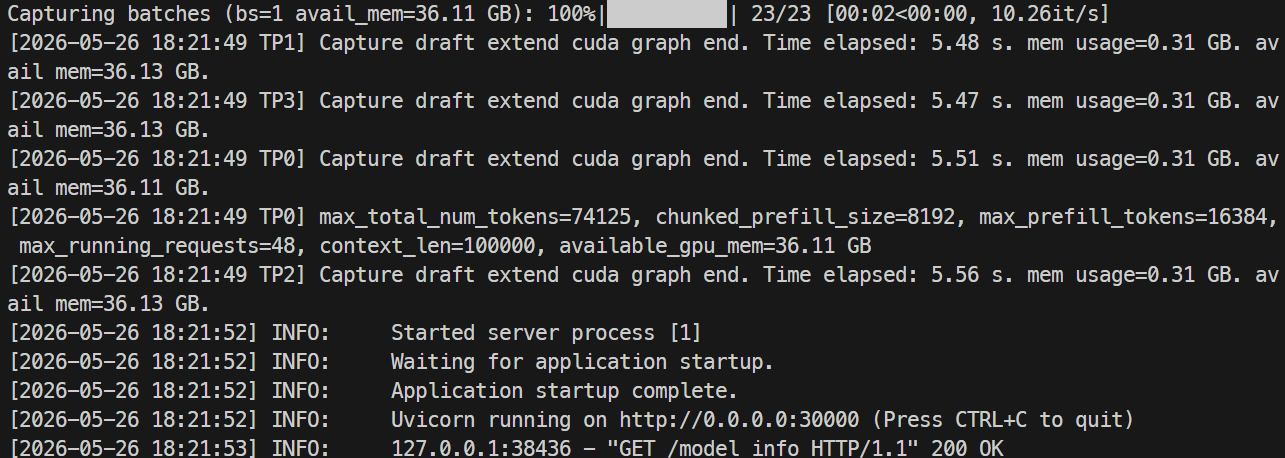
Wenn die Logs anzeigen, dass Uvicorn auf 0.0.0.0:30000 läuft, teste den Endpoint:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mistral-medium-3.5-eagle",
"messages": [
{
"role": "user",
"content": "Generate a simple Python game."
}
],
"reasoning_effort": "none",
"max_tokens": 300,
"temperature": 0.7,
"top_p": 0.95
}'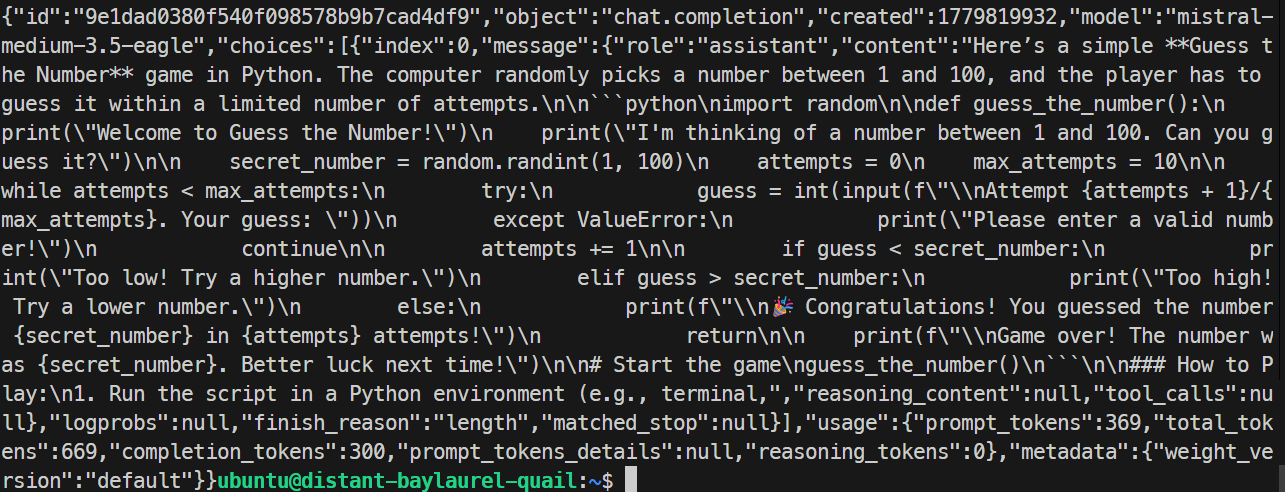
In meinem Test antwortete der EAGLE-Server korrekt und generierte ein einfaches Python-Spiel. Die Laufzeit erreichte etwa 32 Tokens pro Sekunde und war damit leicht langsamer als der Basistest – für diesen konkreten Fall brachte EAGLE also keinen Vorteil.
Das ist normal: Speculative Decoding hängt stark von der Workload ab. Am besten bewertest du es mit deinen eigenen Prompts und deiner gewünschten Parallelität.
OpenCode ist ein Open-Source-AI-Coding-Agent, der sich mit OpenAI-kompatiblen Model-Endpunkten verbinden kann. Da SGLang Mistral Medium 3.5 über eine lokale OpenAI-kompatible API bereitstellt, können wir es direkt in OpenCode nutzen.
Installiere OpenCode, falls noch nicht geschehen:
curl -fsSL https://opencode.ai/install | bashWechsle dann in dein Projektverzeichnis und erstelle eine Datei opencode.json.
Füge die folgende Konfiguration hinzu:
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"sglang": {
"npm": "@ai-sdk/openai-compatible",
"name": "SGLang Local",
"options": {
"baseURL": "http://127.0.0.1:30000/v1",
"apiKey": "EMPTY"
},
"models": {
"mistral-medium-3.5-eagle": {
"name": "Mistral Medium 3.5 EAGLE",
"limit": {
"context": 100000,
"output": 8192
}
}
}
}
},
"model": "sglang/mistral-medium-3.5-eagle"
}Starte nun OpenCode aus demselben Projektverzeichnis:
OpencodeIn OpenCode sollte „Mistral Medium 3.5 EAGLE SGLang Local“ ausgewählt sein. Das bedeutet, OpenCode spricht jetzt über den weitergeleiteten Port 30000 mit deinem lokalen SGLang-Server – so, als würde es jede OpenAI-kompatible API ansprechen.
In meinem Test bat ich OpenCode, das Projekt zu erklären; es las die Repository-Dateien in wenigen Sekunden und erstellte die Zusammenfassung.
Danach ließ ich einen Badger-2040-Emulator erstellen. OpenCode inspizierte zunächst die vorhandenen Projektdateien, validierte die Struktur und erzeugte dann die benötigte Python-Datei. Der gesamte Vorgang dauerte etwa 2 Minuten.
Im Anschluss bat ich, den Emulator lokal zu testen. OpenCode führte den Code aus und öffnete das Emulatorfenster erfolgreich.
Die Schrift entsprach nicht exakt dem realen Badger-2040-Display, aber Layout, Uhrzeit, Datumsposition und Gesamtstruktur waren nahezu perfekt.

Das Ergebnis hat mich ehrlich überrascht, denn ich hatte dieselbe Aufgabe zuvor mit Claude Code und GPT-5.5 ausprobiert – beide taten sich schwer, während Mistral Medium 3.5 das über das lokale SGLang-Setup sehr gut meisterte.
Auf dem Weg lauern ein paar Stolpersteine. Hier sind typische Probleme und wie du sie löst.
Zunächst brauchst du Geduld. Das komplette Setup dauerte bei mir fast 3 Stunden. Das Starten der GPU-VM etwa 15 Minuten, die Installation von Docker und NVIDIA-Toolkit rund 10 Minuten, das Ziehen des SGLang-Images etwa 30 Minuten und Download plus Laden der Mistral-Medium-3.5-Gewichte ungefähr 1 Stunde.
Auch das EAGLE-Setup braucht zusätzliche Zeit, weil das Modell erneut geladen und ggf. das EAGLE-Draft-Modell heruntergeladen wird. Für ein reibungsloseres Erlebnis: schnellere Netzwerke nutzen, neuere GPUs wie H200 (falls verfügbar) und genügend Speicherplatz für den vollständigen Hugging-Face-Cache bereitstellen.
Wenn nvidia-smi auf dem Host funktioniert, Docker aber nicht auf die GPUs zugreifen kann, ist die NVIDIA-Containerruntime vermutlich nicht korrekt konfiguriert. Führe die Konfiguration erneut aus und starte Docker neu:
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart dockerAuch die NVIDIA-Dokumentation empfiehlt diesen nvidia-ctk-Schritt für Docker-GPU-Zugriff.
Stelle sicher, dass der Hugging-Face-Cache in den Container gemountet ist:
-v ~/.cache/huggingface:/root/.cache/huggingfaceSo kann Docker bereits geladene Modelldateien wiederverwenden, statt sie jedes Mal neu zu laden. Hugging Face nutzt einen lokalen Cache, um erneute Downloads aktueller Dateien zu vermeiden.
Das Mistral-Medium-3.5-Repository ist groß, daher kann der erste Download lange dauern. Wenn es festzustecken scheint, prüfe Internetgeschwindigkeit, Speicherplatz und deinen Hugging-Face-Token. Akzeptiere außerdem ggf. erforderliche Nutzungsbedingungen auf Hugging Face, bevor du den Container startest.
Der Server ist erst bereit, wenn die Logs anzeigen, dass Uvicorn auf Port 30000 läuft. Prüfe die Logs mit:
docker logs -f mistral-sglangoder für EAGLE:
docker logs -f mistral-sglang-eagleAchte außerdem darauf, dass der Container den Port korrekt freigibt:
-p 30000:30000Das ist normal. Speculative Decoding garantiert keine Beschleunigung für jede Anfrage. Das Draft-Modell schlägt Tokens vor, das Hauptmodell verifiziert – die Beschleunigung hängt u. a. von Akzeptanzrate, Prompt-Länge, Output-Länge, Parallelität und GPU-Auslastung ab.
Wenn Speicherprobleme auftreten, reduziere zuerst die Kontextlänge. Starte zum Beispiel mit --context-length 100000, statt sofort das volle Kontextfenster zu nutzen. Du kannst auch --mem-fraction-static leicht absenken, wenn der Start fehlschlägt. Am einfachsten ist meist, die Kontextlänge zu reduzieren.
Stelle sicher, dass der SGLang-Server läuft und deine opencode.json den korrekten lokalen Endpoint nutzt:
"baseURL": "http://127.0.0.1:30000/v1"Wenn du vom lokalen Rechner auf den Server zugreifst, starte SSH mit Port-Forwarding:
ssh -L 30000:localhost:30000 ubuntu@XXXXXXStarte anschließend OpenCode in demselben Verzeichnis, in dem deine opencode.json liegt.
Mich hat ehrlich überrascht, wie reibungslos das technische Setup lief. Mistral Medium 3.5 128B mit dem nativen SGLang-Docker-Image zu starten, war deutlich einfacher als erwartet. Das Image ließ sich ziehen, das Modell lud, der OpenAI-kompatible Endpoint lief und OpenCode verband sich ohne große Hürden. I
ch würde dir dringend empfehlen, das SGLang-Docker-Image zu nutzen statt alles über Python-Pakete zu installieren. Bei einer Python-Installation gerät man schnell mit CUDA, PyTorch und anderen Abhängigkeiten in Konflikt. Docker hält alles sauber und isoliert.
Am deutlichsten war für mich aber die Kostenfrage. Ich verstehe ehrlich nicht, wie AI-Unternehmen mit Inferenz Geld verdienen. Selbst mit einer der günstigeren, älteren H100-PCIe-Optionen lag dieses Setup bei fast 10 $ pro Stunde. Und das ist „nur“ ein 128B-Modell auf 4 GPUs. Stell dir vor, du betreibst ein deutlich größeres Modell mit Billionen Parametern auf 16× H100. Die Rechnung landet schnell bei 40 $ und mehr pro Stunde – noch ohne Speicher, Netzwerk, Monitoring, Verfügbarkeit und Engineering-Aufwand einzurechnen.
Für kleine Unternehmen ergibt es aus meiner Sicht kaum Sinn, solche Modelle lokal zu serven – es sei denn, es gibt sehr starke Gründe wie Datenschutz, Forschung oder die Notwendigkeit tiefer Kontrolle über den Inferenz-Stack. Die reinen Inferenzkosten sind schon hoch, und der operative Aufwand kommt noch dazu: Server am Laufen halten, Abstürze vermeiden, GPU-Speicher überwachen, fehlgeschlagene Container handhaben und den Endpoint verfügbar halten.
Serverless löst das für sehr große Modelle ebenfalls kaum. Die Kaltstartzeit ist schlicht zu lang. In diesem Setup hat das Starten der GPU-VM, das Installieren der Abhängigkeiten, das Ziehen des Images, das Herunterladen der Gewichte und das Laden des Modells in Summe fast 3 Stunden gedauert.
Selbst wenn dein Setup schneller ist, braucht das Laden eines Modells dieser Größe immer noch lange. Wenn für jede neue Anfrage erneut ein GPU-Cluster hochgefahren und das Modell geladen werden muss, adelt das die Idee von Serverless ad absurdum. In der Praxis halten Unternehmen GPU-Cluster warm – und zahlen damit, selbst wenn die GPUs nichts zu tun haben.
Das erklärt auch, warum es Off-Peak-GPU-Preise gibt. Anbieter wollen, dass Leerlaufkapazitäten genutzt werden, weil ungenutzte GPUs Geld verbrennen. Für Nutzer ist das eine günstige Möglichkeit zum Experimentieren – zeigt aber zugleich, wie herausfordernd die Ökonomie von Inferenz mit großen Modellen ist.
Unterm Strich hat mir SGLang für dieses Setup sehr gut gefallen. Der Docker-basierte Workflow machte das Serving von Mistral Medium 3.5 128B deutlich einfacher als erwartet, und der OpenCode-Test war wirklich beeindruckend. Gleichzeitig wurde mir klar: Große offene Modelle lokal zu betreiben ist möglich – sie als Produkt zuverlässig und kosteneffizient zu betreiben, ist eine ganz andere Herausforderung.
Lerne KI mit DataCamp!
Lernpfad
Kurs
Kurs