track
Associate AI Engineer för utvecklare
26 timmar
För den här guiden använde jag en 4× H100 80GB GPU-virtuell maskin. Mistral Medium 3.5 är en tät 128B-modell, så den kräver en uppsättning med flera GPU:er. SGLang rekommenderar att köra den med tensorparallellism med --tp 4 på H100- eller H200-GPU:er. Modellen har stöd för ett stort kontextfönster, men jag rekommenderar att börja med 100 000 tokens i stället för hela 256K-kontexten för att göra det enklare att testa och felsöka.
Jag använde Hyperbolic eftersom det ger tillgång till en fullständig GPU-VM, vilket gör det enklare att installera Docker, konfigurera NVIDIA:s container-runtime och köra SGLangs Docker-avbild manuellt. Du kan också använda plattformar som RunPod eller Vast.ai, men vissa av deras instanser är redan bundna till kundanpassade Docker-miljöer, vilket ger dig mindre kontroll.
I Hyperbolic, välj H100 PCIe 80GB, välj 4 GPU:er, lägg till cirka 3 TB lagring, ange din publika SSH-nyckel och ge instansen ett namn, till exempel MM-35. Jag valde H100 PCIe eftersom det var det billigaste tillgängliga H100-alternativet för detta test.
Efter att du klickat på Start Building kan det ta runt 10 minuter innan maskinen startar. När den är redo visar Hyperbolic SSH-kommandot du behöver för nästa steg.
När instansen är klar ansluter du till den från din lokala terminal med SSH-kommandot som visas i Hyperbolic-instrumentpanelen:
ssh ubuntu@XXXXXXFör att komma åt SGLangs API från din lokala maskin senare kan du också vidarebefordra port 30000:
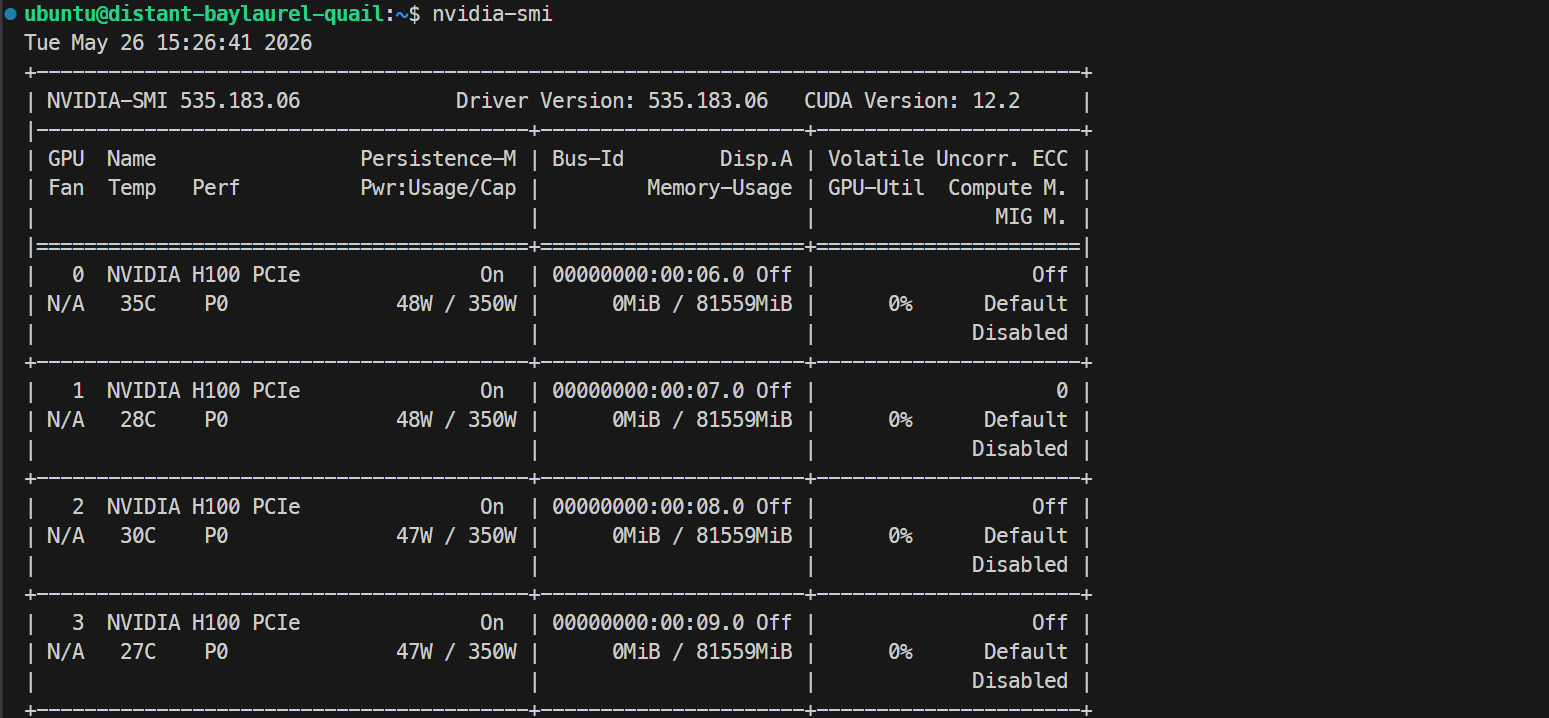
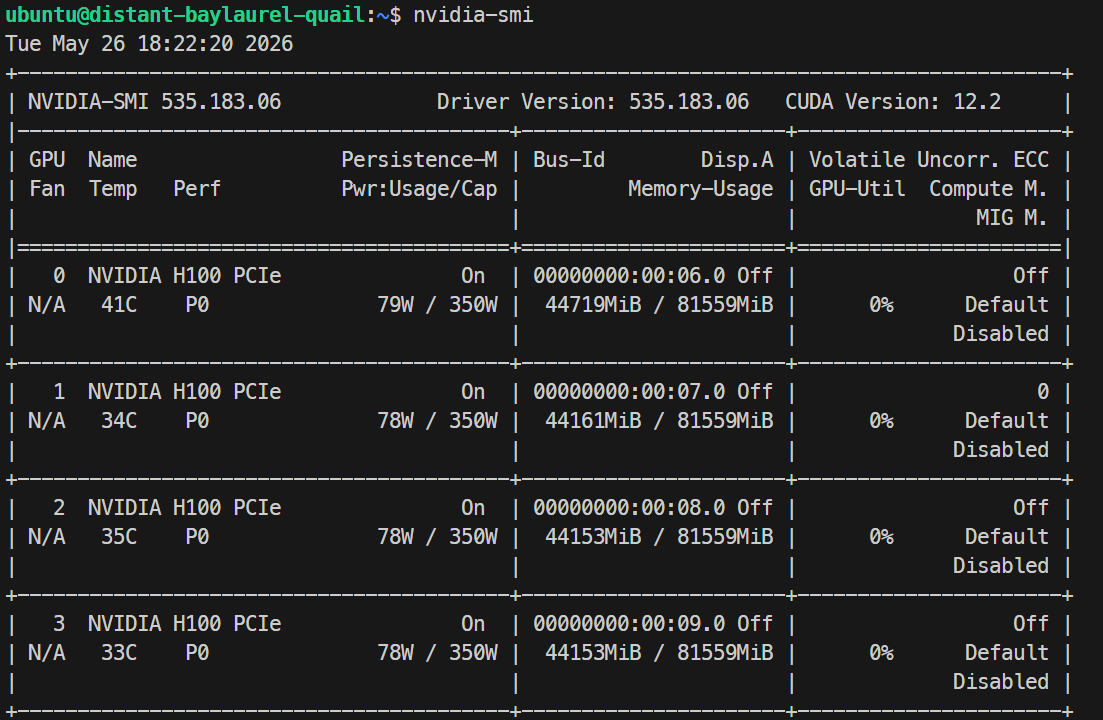
ssh -L 30000:localhost:30000 ubuntu@XXXXXXOm din SSH-nyckel har en lösenfras anger du den när du tillfrågas. Efter inloggning, kontrollera att alla GPU:er är tillgängliga:
Nvidia-smiDu bör se 4× NVIDIA H100 PCIe 80GB GPU:er listade. Det bekräftar att servern är redo för Docker- och SGLang-uppsättningen.
Exportera först din Hugging Face-token så att servern kan ladda ner Mistral-modellen senare:
echo 'export HF_TOKEN="your_huggingface_token_here"' >> ~/.bashrc
source ~/.bashrcObs: Du får din Hugging Face-token från sidan Access Tokens.
Skapa Hugging Face-cachemappen:
mkdir -p ~/.cache/huggingfaceInstallera nu Docker:
sudo apt update
sudo apt install -y docker.ioStarta Docker och aktivera automatisk start efter omstart:
sudo systemctl start docker
sudo systemctl enable dockerKontrollera att Docker installerades korrekt:
docker –versionDu kan också använda Docker-sökning för att bekräfta att Docker kan söka efter publika avbilder från Docker Hub:
docker search nvidia/cudaDetta bör returnera tillgängliga NVIDIA CUDA-avbilder. Senare använder vi en av dessa CUDA-avbilder för att verifiera att Docker kan komma åt GPU:erna.
Tillåt sedan din användare att köra Docker-kommandon utan sudo:
sudo usermod -aG docker $USER
newgrp dockerInstallera och konfigurera nu NVIDIA Container Toolkit så att Docker kan komma åt GPU:erna:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/libnvidia-container/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt update
sudo apt install -y nvidia-container-toolkit
sudo nvidia-ctk runtime configure --runtime=docker
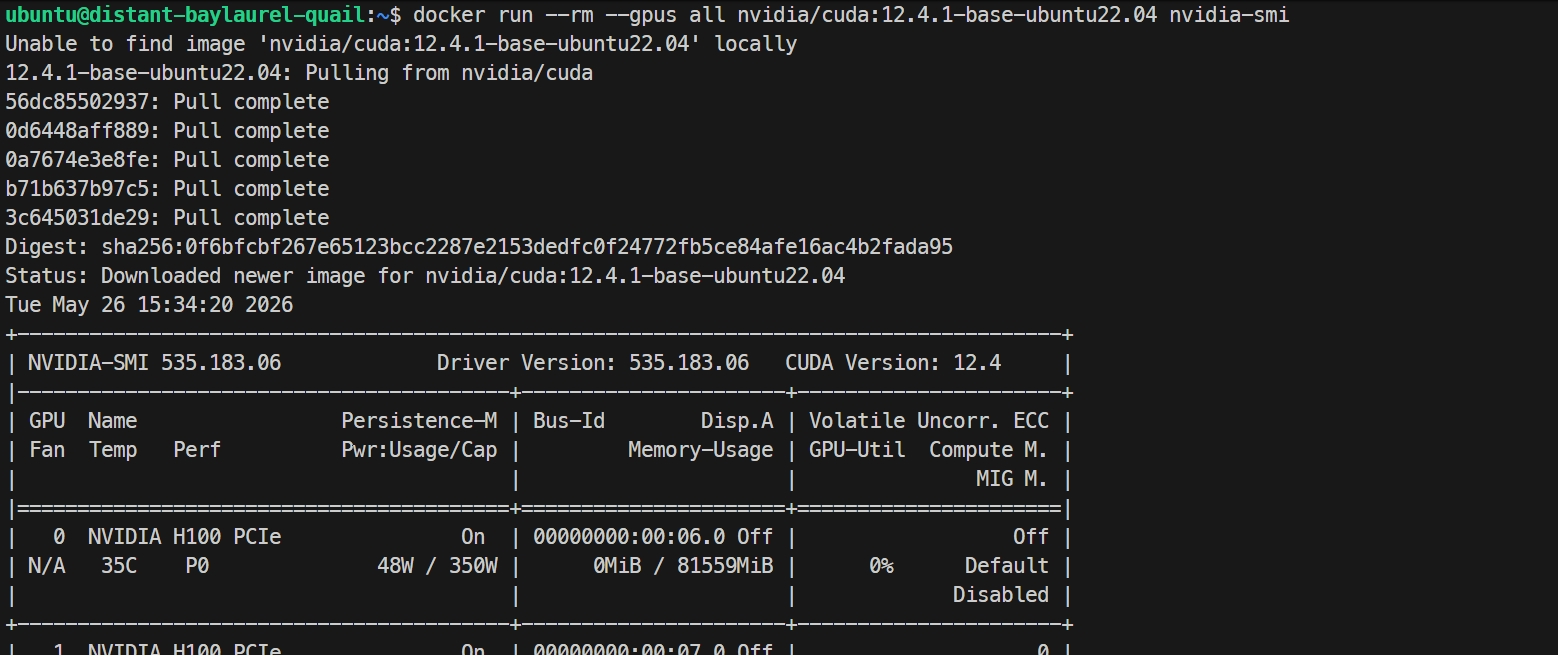
sudo systemctl restart dockerTesta slutligen att Docker kan se GPU:erna inifrån en container:
docker run --rm --gpus all nvidia/cuda:12.4.1-base-ubuntu22.04 nvidia-smiOm detta skriver ut samma H100-GPU-lista inuti Docker-containern fungerar din GPU-Docker-setup korrekt.
Hämta sedan SGLangs Docker-avbild byggd för Mistral Medium 3.5:
docker pull lmsysorg/sglang:dev-mistral-medium-3.5
Detta kan ta en stund beroende på din internethastighet. För mig tog det cirka 10 minuter. När avbilden är nedladdad visar Docker ett meddelande i stil med:
Status: Downloaded newer image for lmsysorg/sglang:dev-mistral-medium-3.5Starta nu SGLang-servern:
docker run -d \
--name mistral-sglang \
--gpus all \
--shm-size 64g \
--ipc=host \
--cap-add SYS_NICE \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e HF_TOKEN=$HF_TOKEN \
-e PYTORCH_ALLOC_CONF=expandable_segments:True \
lmsysorg/sglang:dev-mistral-medium-3.5 \
sglang serve \
--model-path mistralai/Mistral-Medium-3.5-128B \
--served-model-name mistral-medium-3.5 \
--host 0.0.0.0 \
--port 30000 \
--tp 4 \
--trust-remote-code \
--dtype bfloat16 \
--context-length 100000 \
--mem-fraction-static 0.85 \
--disable-custom-all-reduce \
--tool-call-parser mistral \
--reasoning-parser mistralJag använde --dtype bfloat16 eftersom EAGLE-uppsättningen senare också kräver bf16, så att hålla grundkörningen och den spekulativa körningen i linje undviker att behöva ändra dtype mellan testerna. Jag började också med --context-length 100000 i stället för hela kontextfönstret för att göra första körningen enklare att felsöka.
Kontrollera containerloggarna med:
docker logs -f mistral-sglang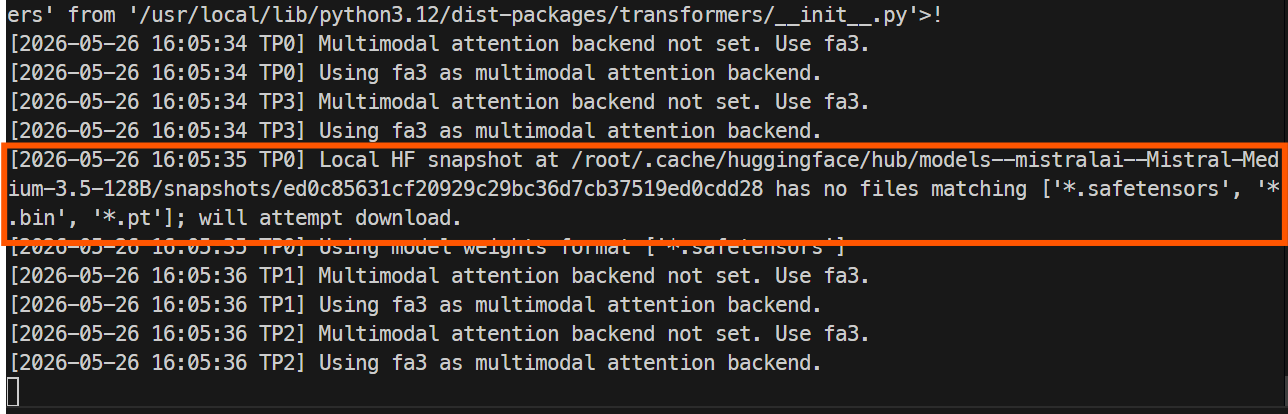
Första starten tar längre tid eftersom SGLang behöver ladda ner modelfilerna från Hugging Face. Hela lagret är stort, så detta kan ta runt en timme eller mer, beroende på instansens hastighet.
När servern är redo ska loggarna visa att Uvicorn kör på port 30000.
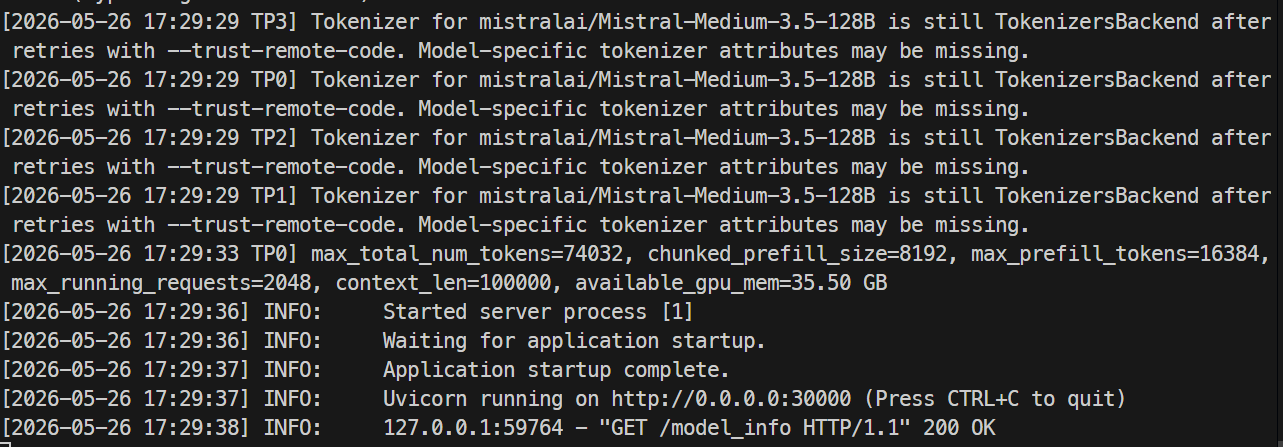
I en annan terminal, SSH:a in på servern igen och kontrollera modellslutpunkten:
curl http://localhost:30000/v1/modelsDu bör se mistral-medium-3.5 listad med ett max_model_len på 100000.
{"object":"list","data":[{"id":"mistral-medium-3.5","object":"model","created":1779816738,"owned_by":"sglang","root":"mistral-medium-3.5","parent":null,"max_model_len":100000}]}Testa slutligen en chattkomplettering:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mistral-medium-3.5",
"messages": [
{
"role": "user",
"content": "Write a short introduction to Mistral Medium 3.5."
}
],
"max_tokens": 300,
"temperature": 0.7,
"top_p": 0.95
}'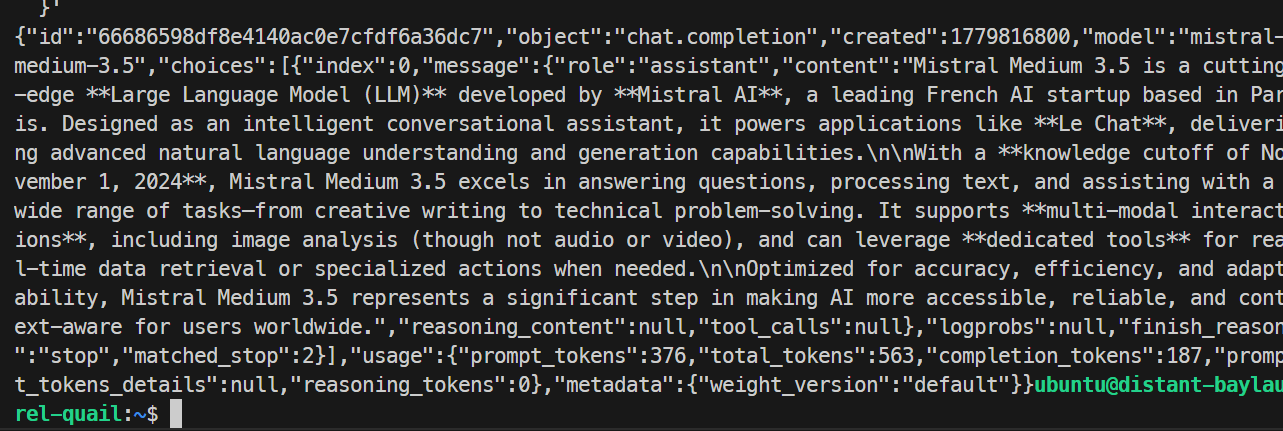
I mitt test svarade modellen utan problem och slutförde förfrågan korrekt, vilket bekräftade att SGLang-slutpunkten fungerade. Grundkörningen genererade omkring 35,6 tokens per sekund.
Spekulativ avkodning kan snabba upp genereringen genom att använda en mindre utkastmodell för att förutsäga token i förväg, medan huvudmodellen verifierar dem.
EAGLE är användbart här eftersom det är utformat för latenskänslig servering, särskilt när du kör en stor modell som Mistral Medium 3.5 lokalt. Det är inte alltid snabbare, men det är värt att testa eftersom nyttan beror på längden på prompt och svar, samtidighet och GPU-användning.
Ta först bort grundcontainern:
docker rm -f mistral-sglangStarta sedan EAGLE-versionen:
docker run -d \
--name mistral-sglang-eagle \
--gpus all \
--shm-size 64g \
--ipc=host \
--cap-add SYS_NICE \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e HF_TOKEN="$HF_TOKEN" \
-e PYTORCH_ALLOC_CONF=expandable_segments:True \
lmsysorg/sglang:dev-mistral-medium-3.5 \
sglang serve \
--model-path mistralai/Mistral-Medium-3.5-128B \
--served-model-name mistral-medium-3.5-eagle \
--host 0.0.0.0 \
--port 30000 \
--tp 4 \
--trust-remote-code \
--dtype bfloat16 \
--context-length 100000 \
--mem-fraction-static 0.85 \
--disable-custom-all-reduce \
--tool-call-parser mistral \
--reasoning-parser mistral \
--enable-metrics \
--speculative-algorithm EAGLE \
--speculative-draft-model-path mistralai/Mistral-Medium-3.5-128B-EAGLE \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4SGLang rekommenderar den här EAGLE-uppsättningen som en bra startpunkt: --speculative-num-steps 3, --speculative-eagle-topk 1 och --speculative-num-draft-tokens 4. Första körningen kan ta längre tid eftersom EAGLE:s utkastmodell också laddas ner.
När den är laddad kan du kontrollera GPU-användningen med nvidia-smi; i min körning använde modellen runt 44 GB per H100-GPU.
Övervaka loggarna med:
docker logs -f mistral-sglang-eagle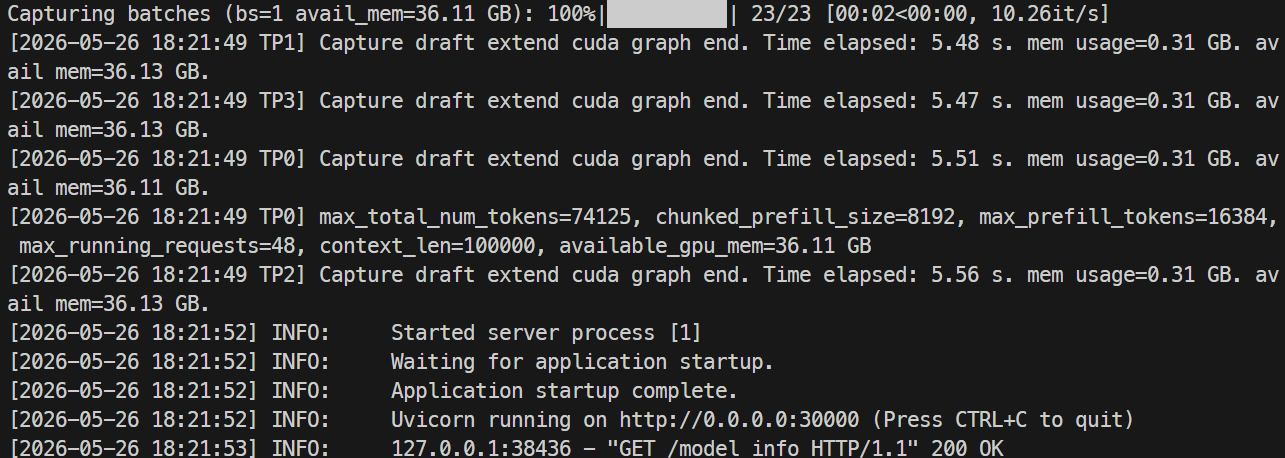
När loggarna visar att Uvicorn kör på 0.0.0.0:30000, testa slutpunkten:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mistral-medium-3.5-eagle",
"messages": [
{
"role": "user",
"content": "Generate a simple Python game."
}
],
"reasoning_effort": "none",
"max_tokens": 300,
"temperature": 0.7,
"top_p": 0.95
}'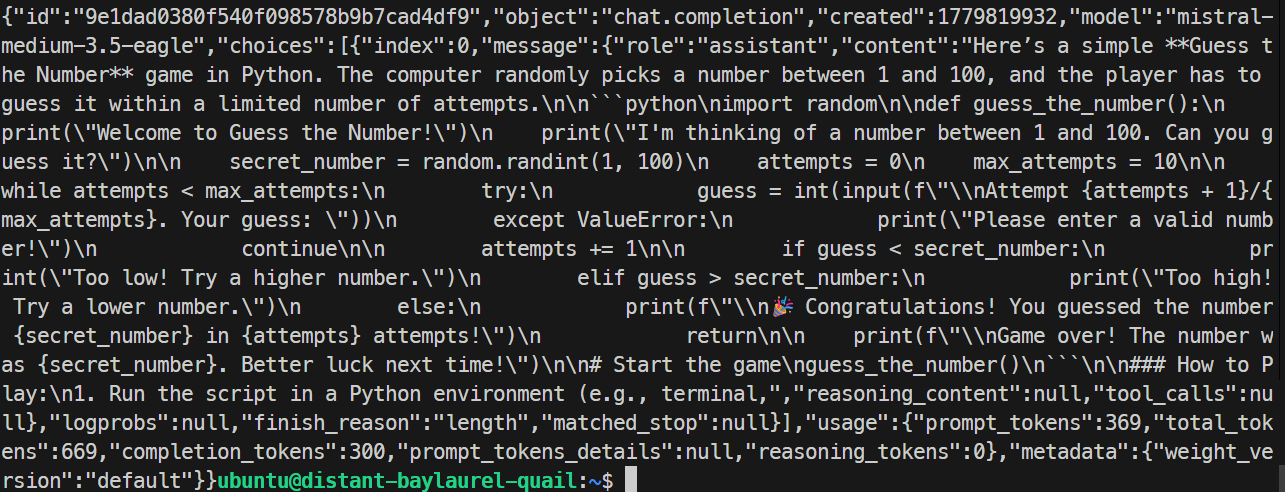
I mitt test svarade EAGLE-servern korrekt och genererade ett enkelt Python-spel. Körningen nådde omkring 32 tokens per sekund, något långsammare än grundkörningen, så EAGLE förbättrade inte just detta test.
Detta är normalt: spekulativ avkodning beror starkt på arbetslasten, och bästa bedömningen får du genom att testa med dina egna promptar och din egen samtidighetsnivå.
OpenCode är en öppen källkod-agent för kodning som kan ansluta till OpenAI-kompatibla modellslutpunkter. Eftersom SGLang exponerar Mistral Medium 3.5 via ett lokalt OpenAI-kompatibelt API kan vi använda det direkt i OpenCode.
Installera OpenCode om du inte redan har gjort det:
curl -fsSL https://opencode.ai/install | bashGå sedan in i din projektkatalog och skapa en opencode.json-fil.
Lägg till följande konfiguration:
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"sglang": {
"npm": "@ai-sdk/openai-compatible",
"name": "SGLang Local",
"options": {
"baseURL": "http://127.0.0.1:30000/v1",
"apiKey": "EMPTY"
},
"models": {
"mistral-medium-3.5-eagle": {
"name": "Mistral Medium 3.5 EAGLE",
"limit": {
"context": 100000,
"output": 8192
}
}
}
}
},
"model": "sglang/mistral-medium-3.5-eagle"
}Starta nu OpenCode från samma projektkatalog:
OpencodeDu bör se Mistral Medium 3.5 EAGLE SGLang Local valt i OpenCode. Det betyder att OpenCode nu pratar med din lokala SGLang-server via den vidarebefordrade 30000-porten, precis som det skulle anropa vilket OpenAI-kompatibelt API som helst.
I mitt test bad jag OpenCode att förklara projektet, och det läste in arkivets filer inom några sekunder och genererade sammanfattningen.
Sedan bad jag den att skapa en Badger 2040-emulator, och den inspekterade först befintliga projektfiler, validerade strukturen och skapade sedan den kräva Python-filen. Hela processen tog omkring 2 minuter.
Därefter bad jag den att testa emulatorn lokalt. OpenCode körde koden och öppnade emulatorfönstret utan problem.
Typsnittet var inte exakt detsamma som den riktiga Badger 2040-skärmen, men layout, tidsvisning, datumplacering och helhetsstruktur var nästan perfekta.

Jag blev genuint överraskad av resultatet eftersom jag hade testat samma uppgift med Claude Code och GPT-5.5 tidigare, och båda hade svårt med den, medan Mistral Medium 3.5 hanterade den riktigt bra via den lokala SGLang-uppsättningen.
Det finns några fallgropar längs vägen. Låt mig gå igenom problem du kan stöta på och hur du löser dem.
Först och främst behöver du ha tålamod. Den fulla installationen tog mig nästan 3 timmar. Att starta GPU-VM:en tog cirka 15 minuter, att installera Docker och NVIDIA:s containerverktyg tog cirka 10 minuter, att hämta SGLangs Docker-avbild tog cirka 30 minuter, och att ladda ner plus ladda Mistral Medium 3.5:s modellvikter tog cirka 1 timme.
Att starta EAGLE-uppsättningen tar också extra tid eftersom modellen laddas igen och EAGLE:s utkastmodell kan behöva laddas ner. Vill du ha en smidigare upplevelse, använd snabbare nätverk, nyare GPU:er som H200 om tillgängliga, och tillräckligt med lagring för hela Hugging Face-cachen.
Om nvidia-smi fungerar på värden men Docker inte kan komma åt GPU:erna, är NVIDIA:s container-runtime troligen inte korrekt konfigurerad. Kör om NVIDIA:s containerverktygskonfiguration och starta om Docker:
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart dockerNVIDIA:s dokumentation rekommenderar också detta nvidia-ctk-steg för runtime-konfiguration för Docker GPU-åtkomst.
Se till att Hugging Face-cachen är monterad i containern:
-v ~/.cache/huggingface:/root/.cache/huggingfaceDetta låter Docker återanvända nedladdade modelfiler i stället för att ladda ner dem igen varje gång. Hugging Face använder en lokal cache för att undvika att ladda ner filer som redan är uppdaterade.
Lagringsplatsen för Mistral Medium 3.5 är stor, så den första nedladdningen kan ta lång tid. Om det verkar ha fastnat, kontrollera din internethastighet, diskutrymme och Hugging Face-token. Se också till att du har accepterat eventuella nödvändiga modellvillkor på Hugging Face innan du kör containern.
Servern är inte redo förrän loggarna visar att Uvicorn kör på port 30000. Kontrollera loggarna med:
docker logs -f mistral-sglangeller för EAGLE:
docker logs -f mistral-sglang-eagleKontrollera också att containern exponerar porten korrekt med:
-p 30000:30000Detta är normalt. Spekulativ avkodning garanterar inte förbättring för varje förfrågan. Den fungerar genom att använda en utkastmodell för att föreslå token och huvudmodellen för att verifiera dem, men hastighetsökningen beror på acceptansgrad, promptlängd, svarets längd, samtidighet och GPU-utnyttjande.
Om du stöter på minnesproblem, minska kontextlängden först. Börja till exempel med --context-length 100000 i stället för att direkt prova hela kontextfönstret. Du kan också sänka --mem-fraction-static något om uppstarten misslyckas, men att minska kontextlängden är oftast det enklaste första steget.
Se till att SGLang-servern körs och att din opencode.json använder rätt lokala slutpunkt:
"baseURL": "http://127.0.0.1:30000/v1"Om du nåt servern från din lokala maskin, starta SSH med portvidarebefordran:
ssh -L 30000:localhost:30000 ubuntu@XXXXXXStarta sedan OpenCode från samma katalog där din opencode.json-fil är sparad.
Jag blev ärligt talat överraskad av hur smidig den tekniska installationen var. Att köra Mistral Medium 3.5 128B med SGLangs egna Docker-avbild var mycket enklare än jag väntat mig. Docker-avbilden hämtades korrekt, modellen laddades, den OpenAI-kompatibla slutpunkten fungerade och OpenCode kopplade upp sig utan större bekymmer. J
ag skulle starkt rekommendera att använda SGLangs Docker-avbild i stället för att installera allt via Python-paket. När du installerar via Python kan det lätt börja strula med CUDA, PyTorch och andra beroenden. Docker håller allt rent och isolerat.
Men det största jag tog med mig från experimentet var kostnaden. Jag vet uppriktigt sagt inte hur AI-företag tjänar pengar på inferens. Även med en av de billigare och äldre H100 PCIe-varianterna låg kostnaden nära $10 per timme. Och detta är bara för en 128B-modell på 4 GPU:er. Föreställ dig att köra en mycket större modell med biljoner parametrar på 16× H100. Din nota kan lätt nå $40+ per timme, innan du ens räknar in lagring, nätverk, övervakning, upptid och ingenjörsarbete.
För små företag tycker jag inte att det är vettigt att serva sådana modeller lokalt om det inte finns en mycket stark anledning, som sekretess, forskning eller djup kontroll över inferensstacken. Inferenskostnaden är redan hög, men den operativa bördan är också ett problem. Du måste hålla servern igång, se till att modellen inte kraschar, övervaka GPU-minnet, hantera containrar som fallerar och hålla slutpunkten tillgänglig.
Serverlöst löser inte heller detta för mycket stora modeller. Kallstarten är helt enkelt för lång. I den här uppsättningen tog det nästan 3 timmar totalt att starta GPU-VM:en, installera beroenden, hämta Docker-avbilden, ladda ner vikterna och ladda modellen.
Även om din uppsättning är snabbare kan det fortfarande ta lång tid att ladda en modell av den här storleken. Om varje ny förfrågan kräver att starta ett nytt GPU-kluster och ladda modellen igen, motverkar det syftet med serverlöst. I praktiken behöver företag hålla varma GPU-kluster igång, vilket innebär att de betalar även när GPU:erna är overksamma.
Detta förklarar också varför GPU-priser utanför högtrafik finns. Leverantörer vill att folk ska använda overksam GPU-kapacitet eftersom outnyttjade GPU:er bara bränner pengar. För användare kan det vara ett sätt att experimentera billigare, men det visar också hur svår ekonomin för inferens av stora modeller är.
Sammantaget gillade jag SGLang skarpt för den här uppsättningen. Det Docker-baserade arbetsflödet gjorde det mycket enklare än väntat att serva Mistral Medium 3.5 128B, och OpenCode-testet var genuint imponerande. Men experimentet gjorde också en sak väldigt tydlig: att köra stora öppna modeller lokalt är möjligt, men att köra dem pålitligt och kostnadseffektivt som en riktig produkt är en helt annan utmaning.
Lär dig AI med DataCamp!
track
course
course