Tracks
面向开发者的 AI 工程师助理
26小时
本指南中,我使用了一台4× H100 80GB GPU 虚拟机。Mistral Medium 3.5 是致密的 128B 模型,因此需要多 GPU 配置。SGLang 建议在 H100 或 H200 GPU 上使用 --tp 4 开启张量并行。该模型支持大上下文窗口,但建议先从100,000 个 token 起步,而非直接使用完整的 256K 上下文,以便更容易测试和调试。
我选择了 Hyperbolic,因为它提供完整的 GPU 虚拟机,更便于安装 Docker、配置 NVIDIA 容器运行时,并手动运行 SGLang Docker 镜像。您也可以使用 RunPod 或 Vast.ai 等平台,但其部分实例已绑定自定义 Docker 环境,灵活性较低。
在 Hyperbolic 中,选择H100 PCIe 80GB,选择4 块 GPU,添加约3TB 存储,填入您的SSH 公钥,并为实例命名,例如 MM-35。我之所以选择 H100 PCIe,是因为在本次测试中它是可用的 H100 选项里最便宜的。
点击Start Building 后,机器大约需要 10 分钟启动。准备就绪后,Hyperbolic 会显示下一步所需的 SSH 访问命令。
实例就绪后,在本地终端使用 Hyperbolic 控制台显示的 SSH 命令连接:
ssh ubuntu@XXXXXX为了稍后能在本地机器访问 SGLang API,您也可以转发 30000 端口:
ssh -L 30000:localhost:30000 ubuntu@XXXXXX如果您的 SSH 密钥设置了口令,请按提示输入。登录后,检查所有 GPU 是否可用:
Nvidia-smi您应能看到列出了 4× NVIDIA H100 PCIe 80GB GPU。这表明服务器已准备好进行 Docker 和 SGLang 的设置。
首先,导出您的 Hugging Face 令牌,方便稍后下载 Mistral 模型:
echo 'export HF_TOKEN="your_huggingface_token_here"' >> ~/.bashrc
source ~/.bashrc注意:您可在 Access Tokens 页面获取 Hugging Face 令牌。
创建 Hugging Face 缓存文件夹:
mkdir -p ~/.cache/huggingface现在安装 Docker:
sudo apt update
sudo apt install -y docker.io启动 Docker 并设置为开机自启:
sudo systemctl start docker
sudo systemctl enable docker检查 Docker 是否安装成功:
docker –version您也可以用 Docker 的搜索命令确认可检索 Docker Hub 上的公共镜像:
docker search nvidia/cuda这应会返回可用的 NVIDIA CUDA 镜像。稍后我们将使用其中一个 CUDA 镜像验证 Docker 是否能访问 GPU。
接下来,允许您的用户在不使用 sudo 的情况下运行 Docker 命令:
sudo usermod -aG docker $USER
newgrp docker现在安装并配置 NVIDIA Container Toolkit,以便 Docker 能访问 GPU:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/libnvidia-container/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt update
sudo apt install -y nvidia-container-toolkit
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart docker最后,测试 Docker 能否在容器内识别 GPU:
docker run --rm --gpus all nvidia/cuda:12.4.1-base-ubuntu22.04 nvidia-smi如果容器中打印出了与宿主机一致的 H100 GPU 列表,说明 GPU Docker 环境配置正确。
接下来,拉取为 Mistral Medium 3.5 构建的 SGLang Docker 镜像:
docker pull lmsysorg/sglang:dev-mistral-medium-3.5
所需时间取决于您的网络速度。我的环境大约耗时 10 分钟。镜像下载完成后,Docker 会显示类似如下的成功信息:
Status: Downloaded newer image for lmsysorg/sglang:dev-mistral-medium-3.5现在启动 SGLang 服务器:
docker run -d \
--name mistral-sglang \
--gpus all \
--shm-size 64g \
--ipc=host \
--cap-add SYS_NICE \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e HF_TOKEN=$HF_TOKEN \
-e PYTORCH_ALLOC_CONF=expandable_segments:True \
lmsysorg/sglang:dev-mistral-medium-3.5 \
sglang serve \
--model-path mistralai/Mistral-Medium-3.5-128B \
--served-model-name mistral-medium-3.5 \
--host 0.0.0.0 \
--port 30000 \
--tp 4 \
--trust-remote-code \
--dtype bfloat16 \
--context-length 100000 \
--mem-fraction-static 0.85 \
--disable-custom-all-reduce \
--tool-call-parser mistral \
--reasoning-parser mistral我使用了 --dtype bfloat16,因为后续的 EAGLE 配置也需要 bf16,这样基础运行与试探运行保持一致,避免在测试间切换 dtype。我还从 --context-length 100000 起步,而不是直接使用最大上下文窗口,以便首次运行更易调试。
通过以下命令查看容器日志:
docker logs -f mistral-sglang
首次启动会更慢,因为 SGLang 需要从 Hugging Face 下载模型文件。整个仓库很大,视实例速度不同,可能需要一小时或更久。
当服务器就绪时,日志应显示 Uvicorn 正在监听 30000 端口。
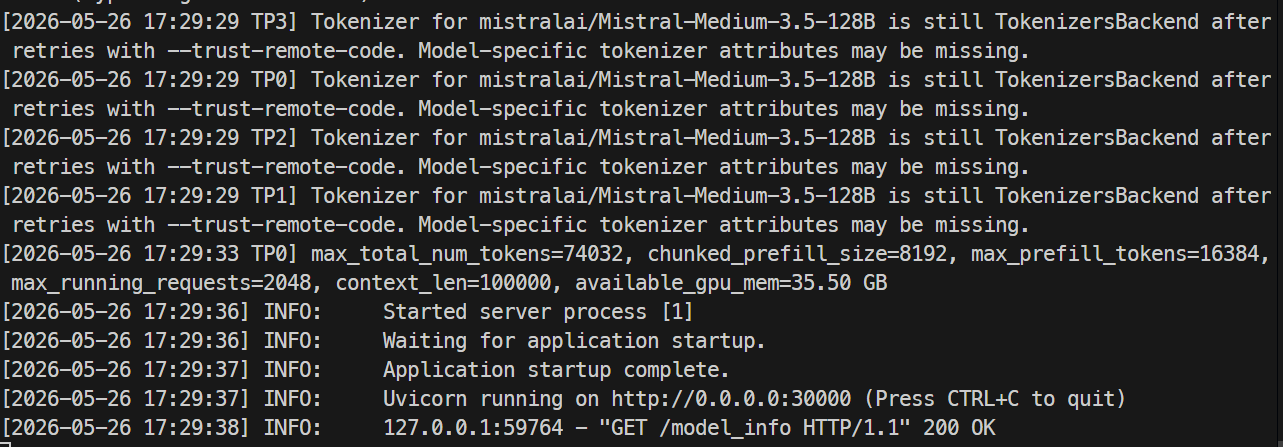
在另一个终端再次 SSH 登录服务器,检查模型端点:
curl http://localhost:30000/v1/models您应能看到 mistral-medium-3.5,其 max_model_len 为 100000。
{"object":"list","data":[{"id":"mistral-medium-3.5","object":"model","created":1779816738,"owned_by":"sglang","root":"mistral-medium-3.5","parent":null,"max_model_len":100000}]}最后,测试一次对话补全:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mistral-medium-3.5",
"messages": [
{
"role": "user",
"content": "Write a short introduction to Mistral Medium 3.5."
}
],
"max_tokens": 300,
"temperature": 0.7,
"top_p": 0.95
}'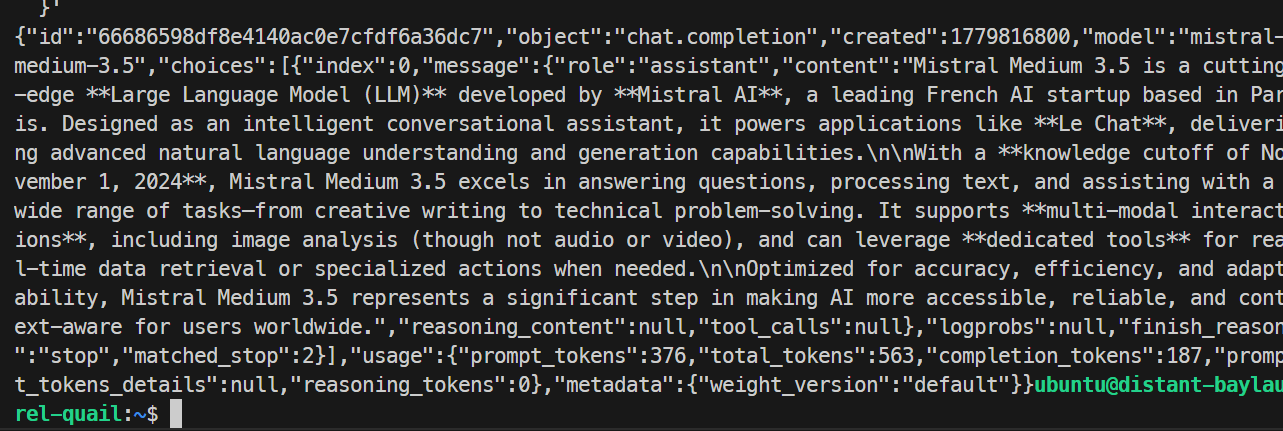
在我的测试中,模型成功响应并顺利完成请求,确认 SGLang 端点工作正常。基础运行的生成速率约为每秒 35.6 个 token。
试探式解码通过使用更小的草拟模型提前预测 token,再由主模型进行校验,从而加速生成。
EAGLE 在此处很有用,因为它为时延敏感型服务而设计,尤其当您在本地运行像 Mistral Medium 3.5 这样的大模型时。它并非总是更快,但很值得测试,因为收益取决于提示长度、输出长度、并发和 GPU 使用率。
首先,移除基础容器:
docker rm -f mistral-sglang然后启动 EAGLE 版本:
docker run -d \
--name mistral-sglang-eagle \
--gpus all \
--shm-size 64g \
--ipc=host \
--cap-add SYS_NICE \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e HF_TOKEN="$HF_TOKEN" \
-e PYTORCH_ALLOC_CONF=expandable_segments:True \
lmsysorg/sglang:dev-mistral-medium-3.5 \
sglang serve \
--model-path mistralai/Mistral-Medium-3.5-128B \
--served-model-name mistral-medium-3.5-eagle \
--host 0.0.0.0 \
--port 30000 \
--tp 4 \
--trust-remote-code \
--dtype bfloat16 \
--context-length 100000 \
--mem-fraction-static 0.85 \
--disable-custom-all-reduce \
--tool-call-parser mistral \
--reasoning-parser mistral \
--enable-metrics \
--speculative-algorithm EAGLE \
--speculative-draft-model-path mistralai/Mistral-Medium-3.5-128B-EAGLE \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4SGLang 推荐以上 EAGLE 配置作为良好的起点:--speculative-num-steps 3、--speculative-eagle-topk 1 和 --speculative-num-draft-tokens 4。首次运行可能更久,因为还需要下载 EAGLE 草拟模型。
加载完成后,您可以用 nvidia-smi 观察 GPU 使用情况;在我的运行中,模型每张 H100 GPU 占用约44GB。
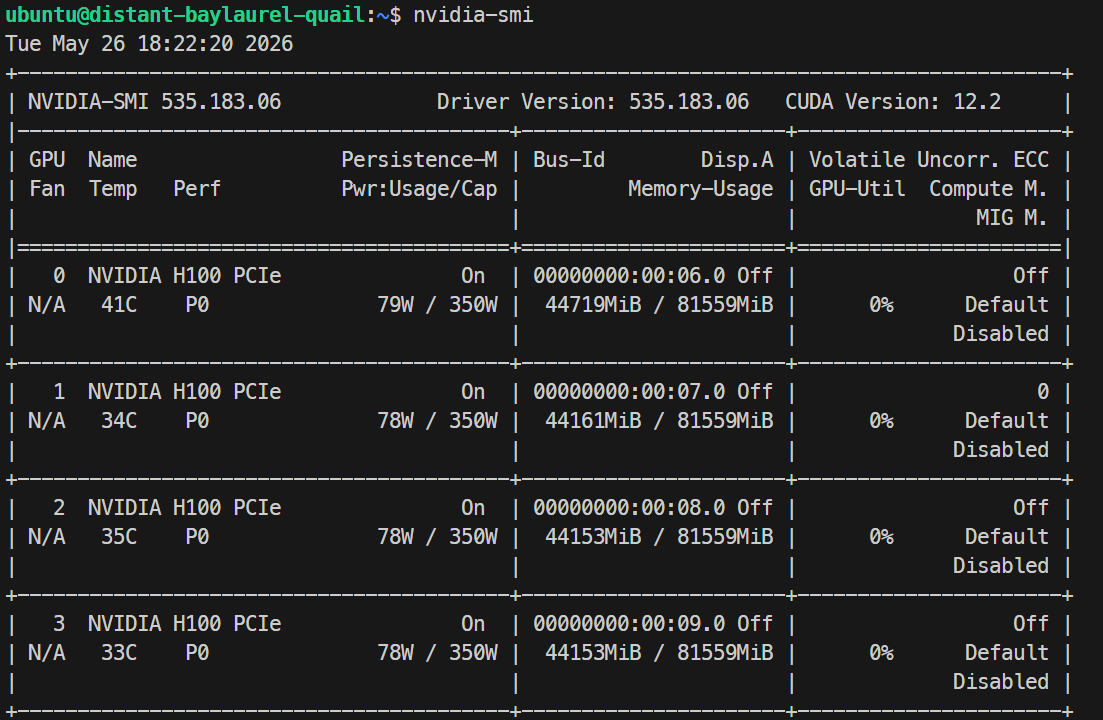
通过以下命令监控日志:
docker logs -f mistral-sglang-eagle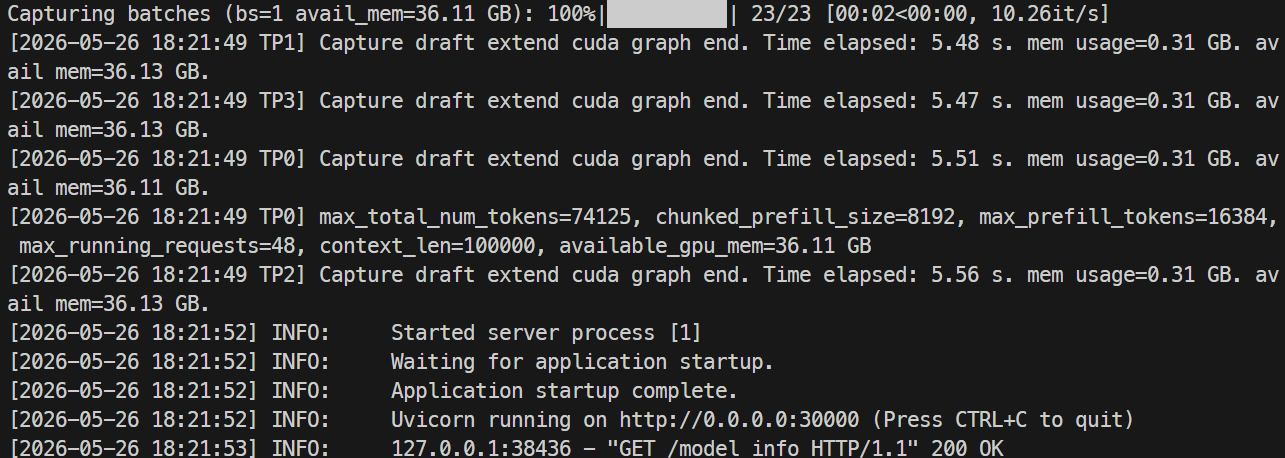
当日志显示 Uvicorn 正在 0.0.0.0:30000 监听时,测试端点:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mistral-medium-3.5-eagle",
"messages": [
{
"role": "user",
"content": "Generate a simple Python game."
}
],
"reasoning_effort": "none",
"max_tokens": 300,
"temperature": 0.7,
"top_p": 0.95
}'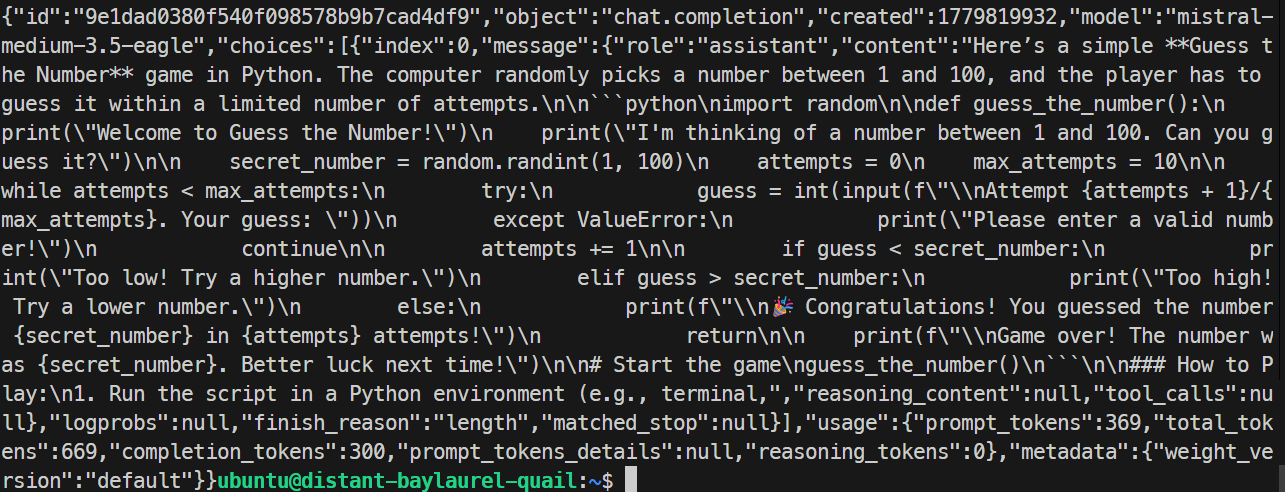
在我的测试中,EAGLE 服务器响应正常并生成了一个简单的 Python 游戏。该次运行约为每秒 32 个 token,略慢于基础运行,因此在这个特定测试中 EAGLE 并未带来提升。
这很正常:试探式解码高度依赖工作负载。评估其效果的最佳方式,是用您自己的提示与并发水平进行测试。
OpenCode 是一款开源 AI 编码代理,能够连接到兼容 OpenAI 的模型端点。由于 SGLang 通过本地兼容 OpenAI 的 API 暴露 Mistral Medium 3.5,我们可以直接在 OpenCode 中使用它。
如果尚未安装 OpenCode,请先安装:
curl -fsSL https://opencode.ai/install | bash然后进入您的项目目录并创建一个 opencode.json 文件。
加入以下配置:
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"sglang": {
"npm": "@ai-sdk/openai-compatible",
"name": "SGLang Local",
"options": {
"baseURL": "http://127.0.0.1:30000/v1",
"apiKey": "EMPTY"
},
"models": {
"mistral-medium-3.5-eagle": {
"name": "Mistral Medium 3.5 EAGLE",
"limit": {
"context": 100000,
"output": 8192
}
}
}
}
},
"model": "sglang/mistral-medium-3.5-eagle"
}现在在同一项目目录启动 OpenCode:
Opencode您应能在 OpenCode 中看到已选择的 Mistral Medium 3.5 EAGLE SGLang Local。也就是说,OpenCode 现已通过转发的 30000 端口与您的本地 SGLang 服务器通信,调用方式与任何兼容 OpenAI 的 API 一致。
在我的测试中,我让 OpenCode 解释项目,它在几秒内读取了代码仓库文件并生成了摘要。
随后,我让它创建一个Badger 2040 模拟器,它先检查了现有项目文件,验证了结构,然后创建了所需的 Python 文件。整个过程大约耗时2 分钟。
之后,我让它在本地测试模拟器。OpenCode 运行了代码并成功打开了模拟器窗口。
字体与真实 Badger 2040 显示屏并不完全一致,但布局、时间显示、日期位置和整体结构几乎完美。

这个结果着实让我惊喜,因为我之前用 Claude Code 和 GPT-5.5 做过同样的任务,它们都遇到了困难,而通过本地 SGLang 配置的 Mistral Medium 3.5 表现得非常出色。
过程中可能会遇到一些坑。下面按情况说明可能出现的问题及解决方法。
首先,您需要有耐心。整个流程我大约花了3 小时。启动 GPU 虚拟机约15 分钟,安装 Docker 与 NVIDIA 容器工具包约10 分钟,拉取 SGLang Docker 镜像约30 分钟,下载并加载 Mistral Medium 3.5 模型权重约1 小时。
启动 EAGLE 配置也会额外耗时,因为需要再次加载模型,且可能下载 EAGLE 草拟模型。若想体验更顺畅,可使用更快的网络、更新的 GPU(如可用的 H200),并为完整的 Hugging Face 缓存预留足够存储。
如果 nvidia-smi 在宿主机可用,但 Docker 无法访问 GPU,可能是 NVIDIA 容器运行时未正确配置。请重新执行 NVIDIA 容器工具包配置并重启 Docker:
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart dockerNVIDIA 文档也推荐通过上述 nvidia-ctk 运行时配置步骤来启用 Docker 的 GPU 访问。
确保已将 Hugging Face 缓存挂载进容器:
-v ~/.cache/huggingface:/root/.cache/huggingface这样 Docker 就能复用已下载的模型文件,避免每次都重新下载。Hugging Face 使用本地缓存来避免重复下载已是最新的文件。
Mistral Medium 3.5 仓库体积很大,首次下载可能耗时很长。如果看起来卡住,请检查网络速度、磁盘空间和 Hugging Face 令牌。同时,务必在运行容器前,在 Hugging Face 上接受必要的模型访问条款。
在日志显示 Uvicorn 已在 30000 端口运行前,服务器都尚未就绪。请用以下命令查看日志:
docker logs -f mistral-sglang若为 EAGLE:
docker logs -f mistral-sglang-eagle还要确认容器正确暴露了端口:
-p 30000:30000这是正常的。试探式解码并不能保证每个请求都有提升。其机制是由草拟模型提出 token、主模型验证,速度收益取决于接受率、提示长度、输出长度、并发度和 GPU 利用率。
如果遇到显存问题,请先降低上下文长度。例如,从 --context-length 100000 开始,而不是一上来就使用最大窗口。如果启动失败,也可略微降低 --mem-fraction-static,但通常降低上下文长度是最简单的第一步。
请确保 SGLang 服务器正在运行,且您的 opencode.json 指向正确的本地端点:
"baseURL": "http://127.0.0.1:30000/v1"如果从本地机器访问服务器,请通过端口转发方式启动 SSH:
ssh -L 30000:localhost:30000 ubuntu@XXXXXX随后在保存了 opencode.json 的同一目录启动 OpenCode。
老实说,这次技术搭建的顺畅程度超出了我的预期。用原生 SGLang Docker 镜像运行 Mistral Medium 3.5 128B 比我想象的容易得多:镜像顺利拉取、模型成功加载、兼容 OpenAI 的端点正常工作、OpenCode 也几乎毫不费力就连上了。
如果您也要尝试,我强烈建议使用 SGLang 的 Docker 镜像,而不是通过 Python 包安装。通过 Python 安装很容易与 CUDA、PyTorch 以及其他依赖发生冲突;Docker 能保持环境干净且隔离。
但这次实验给我最大的感触是成本。我确实不明白 AI 公司如何在推理上实现盈利。即便是较便宜且偏旧的 H100 PCIe 选项,本次配置也接近每小时 10 美元。而这仅是 4 块 GPU 上的一款 128B 模型。若要在 16× H100 上运行更大的万亿参数模型,账单很容易达到每小时 40 美元以上,还没算存储、网络、监控、可用性和工程投入。
对于小公司而言,除非出于隐私、研究或对推理栈的深度掌控等非常强的理由,否则我认为在本地服务这类模型并不划算。推理成本已然很高,运营负担同样不容忽视:您需要保持服务器稳定运行、确保模型不崩溃、监控 GPU 内存、处理容器故障,并维持端点可用。
无服务器并不能真正解决超大模型的问题。冷启动时间实在太长。在本次配置中,从启动 GPU 虚拟机、安装依赖、拉取 Docker 镜像、下载权重到加载模型,总计接近3 小时。
即便您的环境更快,如此规模的模型加载仍然需要很长时间。所以如果每个新请求都要再启动一套 GPU 集群并重新加载模型,就违背了无服务器的初衷。实际生产中,公司需要保持 GPU 集群常温运行,这意味着即便 GPU 空闲也在付费。
这也解释了为何存在非高峰时段的 GPU 定价。服务商希望用户消化闲置的 GPU 产能,因为闲置 GPU 只会烧钱。对用户而言,这可能是更便宜地试验的方法,但也反映出大模型推理在经济性上的艰难。
总体而言,我非常认可在这次搭建中使用 SGLang。基于 Docker 的工作流让 Mistral Medium 3.5 128B 的服务部署比预期简单,OpenCode 的实际测试也令人印象深刻。但这次实验也让我清晰地认识到一点:在本地运行大型开源模型是可行的,但要将其作为真正的产品稳定、经济地运行,则是完全不同层级的挑战。
在 DataCamp 学习 AI!
Tracks
Courses
Courses