
Programma
Ingegnere AI associato per sviluppatori
26 h
Per questa guida ho usato una VM con GPU 4× H100 80GB. Mistral Medium 3.5 è un modello denso da 128B, quindi richiede una configurazione multi-GPU. SGLang consiglia di eseguirlo con il parallelismo di tensori usando --tp 4 su GPU H100 o H200. Il modello supporta una finestra di contesto ampia, ma consiglio di partire da 100.000 token invece dell’intero contesto a 256K per rendere più semplice test e debug iniziali.
Ho usato Hyperbolic perché fornisce accesso a una VM GPU completa, il che semplifica l’installazione di Docker, la configurazione del runtime container NVIDIA e l’esecuzione manuale dell’immagine Docker SGLang. Puoi usare anche piattaforme come RunPod o Vast.ai, ma alcune delle loro istanze sono già vincolate a ambienti Docker personalizzati, dandoti meno controllo.
In Hyperbolic, seleziona H100 PCIe 80GB, scegli 4 GPU, aggiungi circa 3TB di storage, inserisci la tua chiave pubblica SSH e dai un nome all’istanza, ad esempio MM-35. Ho scelto H100 PCIe perché era l’opzione H100 più economica disponibile per questo test.
Dopo aver cliccato su Start Building, la macchina potrebbe impiegare circa 10 minuti ad avviarsi. Quando è pronta, Hyperbolic mostrerà il comando SSH per l’accesso necessario al passo successivo.
Quando l’istanza è pronta, connettiti dal tuo terminale locale usando il comando SSH mostrato nella dashboard di Hyperbolic:
ssh ubuntu@XXXXXXPer accedere in seguito all’API di SGLang dalla tua macchina locale, puoi anche fare il forwarding della porta 30000:
ssh -L 30000:localhost:30000 ubuntu@XXXXXXSe la tua chiave SSH ha una passphrase, inseriscila quando richiesto. Dopo l’accesso, verifica che tutte le GPU siano disponibili:
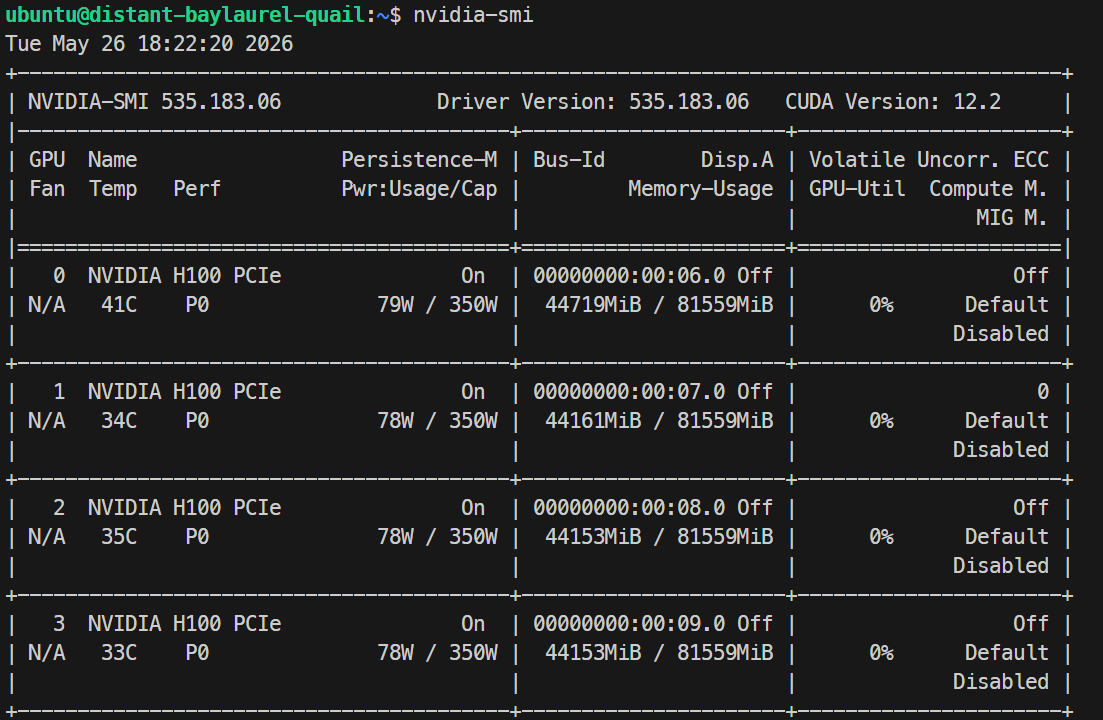
Nvidia-smiDovresti vedere elencate 4× NVIDIA H100 PCIe 80GB. Questo conferma che il server è pronto per la configurazione di Docker e SGLang.
Per prima cosa, esporta il tuo token Hugging Face così il server potrà scaricare il modello Mistral in seguito:
echo 'export HF_TOKEN="your_huggingface_token_here"' >> ~/.bashrc
source ~/.bashrcNota: puoi ottenere il token Hugging Face dalla pagina Access Tokens.
Crea la cartella cache di Hugging Face:
mkdir -p ~/.cache/huggingfaceOra installa Docker:
sudo apt update
sudo apt install -y docker.ioAvvia Docker e abilitalo all’avvio automatico dopo il reboot:
sudo systemctl start docker
sudo systemctl enable dockerVerifica che Docker sia stato installato correttamente:
docker –versionPuoi anche usare il comando di ricerca di Docker per confermare che Docker riesca a cercare immagini pubbliche su Docker Hub:
docker search nvidia/cudaDovrebbe restituire immagini NVIDIA CUDA disponibili. Più avanti useremo una di queste immagini CUDA per verificare che Docker possa accedere alle GPU.
Successivamente, consenti al tuo utente di eseguire comandi Docker senza sudo:
sudo usermod -aG docker $USER
newgrp dockerOra installa e configura l’NVIDIA Container Toolkit affinché Docker possa accedere alle GPU:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/libnvidia-container/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt update
sudo apt install -y nvidia-container-toolkit
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart dockerInfine, testa che Docker veda le GPU dall’interno di un container:
docker run --rm --gpus all nvidia/cuda:12.4.1-base-ubuntu22.04 nvidia-smiSe stampa lo stesso elenco di GPU H100 all’interno del container Docker, la tua configurazione GPU con Docker è corretta.
Ora scarica l’immagine Docker di SGLang costruita per Mistral Medium 3.5:
docker pull lmsysorg/sglang:dev-mistral-medium-3.5
Potrebbe richiedere un po’ di tempo, a seconda della velocità della tua connessione. Nel mio caso, circa 10 minuti. Una volta scaricata l’immagine, Docker mostrerà un messaggio di successo simile a:
Status: Downloaded newer image for lmsysorg/sglang:dev-mistral-medium-3.5Ora avvia il server SGLang:
docker run -d \
--name mistral-sglang \
--gpus all \
--shm-size 64g \
--ipc=host \
--cap-add SYS_NICE \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e HF_TOKEN=$HF_TOKEN \
-e PYTORCH_ALLOC_CONF=expandable_segments:True \
lmsysorg/sglang:dev-mistral-medium-3.5 \
sglang serve \
--model-path mistralai/Mistral-Medium-3.5-128B \
--served-model-name mistral-medium-3.5 \
--host 0.0.0.0 \
--port 30000 \
--tp 4 \
--trust-remote-code \
--dtype bfloat16 \
--context-length 100000 \
--mem-fraction-static 0.85 \
--disable-custom-all-reduce \
--tool-call-parser mistral \
--reasoning-parser mistralHo usato --dtype bfloat16 perché anche la configurazione EAGLE richiede bf16; mantenere allineata l’esecuzione base e quella speculativa evita di cambiare il dtype tra i test. Ho anche iniziato con --context-length 100000 invece della finestra completa, per semplificare il debug del primo avvio.
Controlla i log del container con:
docker logs -f mistral-sglang
Il primo avvio richiederà più tempo perché SGLang deve scaricare i file del modello da Hugging Face. Il repository completo è grande, quindi può richiedere circa un’ora o più, a seconda della velocità dell’istanza.
Quando il server è pronto, i log dovrebbero mostrare Uvicorn in esecuzione sulla porta 30000.
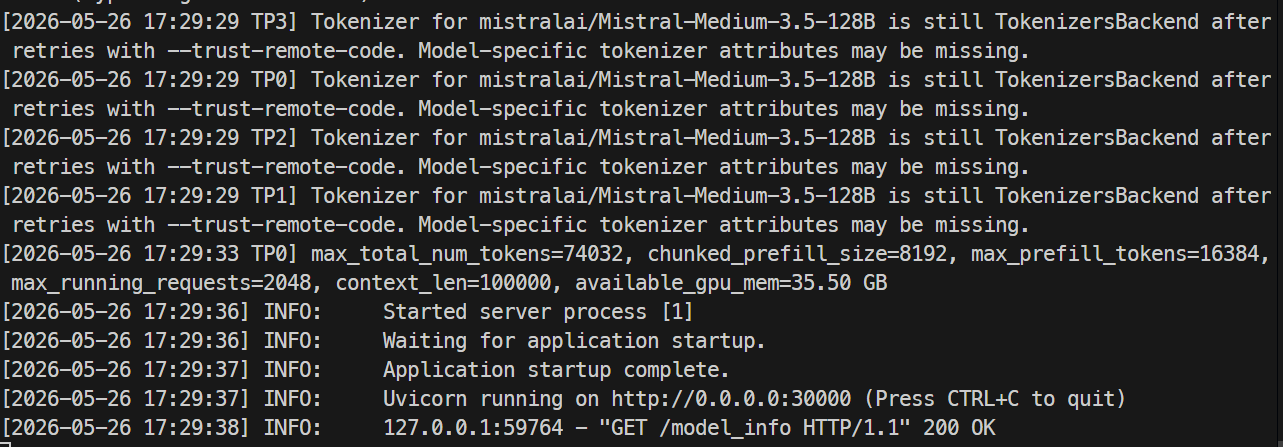
In un altro terminale, ricollegati via SSH al server e verifica l’endpoint del modello:
curl http://localhost:30000/v1/modelsDovresti vedere mistral-medium-3.5 elencato con un max_model_len di 100000.
{"object":"list","data":[{"id":"mistral-medium-3.5","object":"model","created":1779816738,"owned_by":"sglang","root":"mistral-medium-3.5","parent":null,"max_model_len":100000}]}Infine, testa una chat completion:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mistral-medium-3.5",
"messages": [
{
"role": "user",
"content": "Write a short introduction to Mistral Medium 3.5."
}
],
"max_tokens": 300,
"temperature": 0.7,
"top_p": 0.95
}'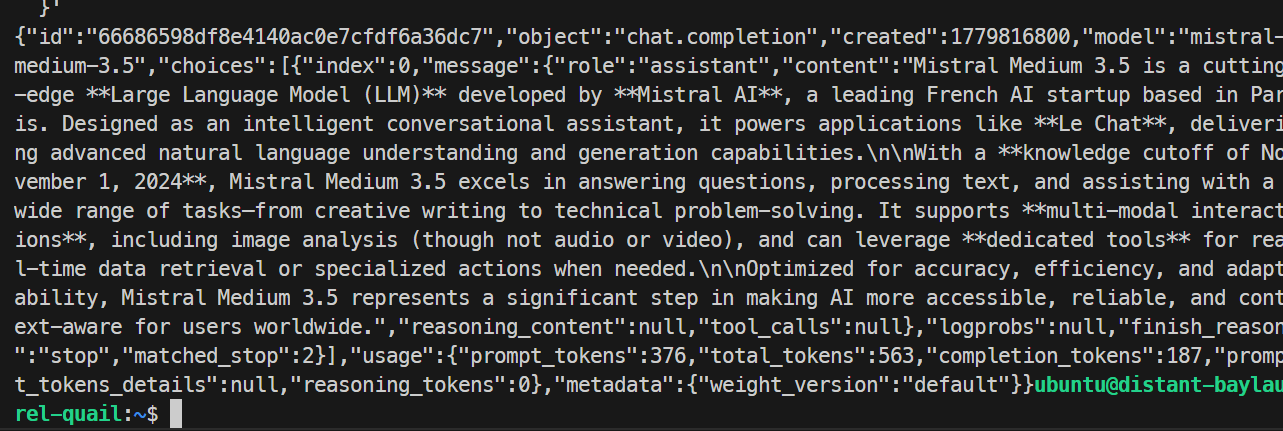
Nel mio test, il modello ha risposto correttamente e completato la richiesta senza problemi, confermando il corretto funzionamento dell’endpoint SGLang. L’esecuzione base ha generato circa 35,6 token al secondo.
Il decoding speculativo può velocizzare la generazione usando un modello di bozza più piccolo per prevedere in anticipo i token, mentre il modello principale li verifica.
EAGLE è utile qui perché è progettato per il serving sensibile alla latenza, soprattutto quando esegui in locale un modello grande come Mistral Medium 3.5. Non sarà sempre più veloce, ma vale la pena testarlo perché il beneficio dipende dalla lunghezza del prompt, dalla lunghezza dell’output, dalla concorrenza e dall’uso delle GPU.
Per prima cosa, rimuovi il container base:
docker rm -f mistral-sglangPoi avvia la versione EAGLE:
docker run -d \
--name mistral-sglang-eagle \
--gpus all \
--shm-size 64g \
--ipc=host \
--cap-add SYS_NICE \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e HF_TOKEN="$HF_TOKEN" \
-e PYTORCH_ALLOC_CONF=expandable_segments:True \
lmsysorg/sglang:dev-mistral-medium-3.5 \
sglang serve \
--model-path mistralai/Mistral-Medium-3.5-128B \
--served-model-name mistral-medium-3.5-eagle \
--host 0.0.0.0 \
--port 30000 \
--tp 4 \
--trust-remote-code \
--dtype bfloat16 \
--context-length 100000 \
--mem-fraction-static 0.85 \
--disable-custom-all-reduce \
--tool-call-parser mistral \
--reasoning-parser mistral \
--enable-metrics \
--speculative-algorithm EAGLE \
--speculative-draft-model-path mistralai/Mistral-Medium-3.5-128B-EAGLE \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4SGLang consiglia questa configurazione EAGLE come buon punto di partenza: --speculative-num-steps 3, --speculative-eagle-topk 1 e --speculative-num-draft-tokens 4. La prima esecuzione può richiedere più tempo perché scarica anche il modello di bozza EAGLE.
Una volta caricato, puoi controllare l’uso della GPU con nvidia-smi; nella mia esecuzione, il modello ha usato circa 44GB per GPU H100.
Monitora i log con:
docker logs -f mistral-sglang-eagle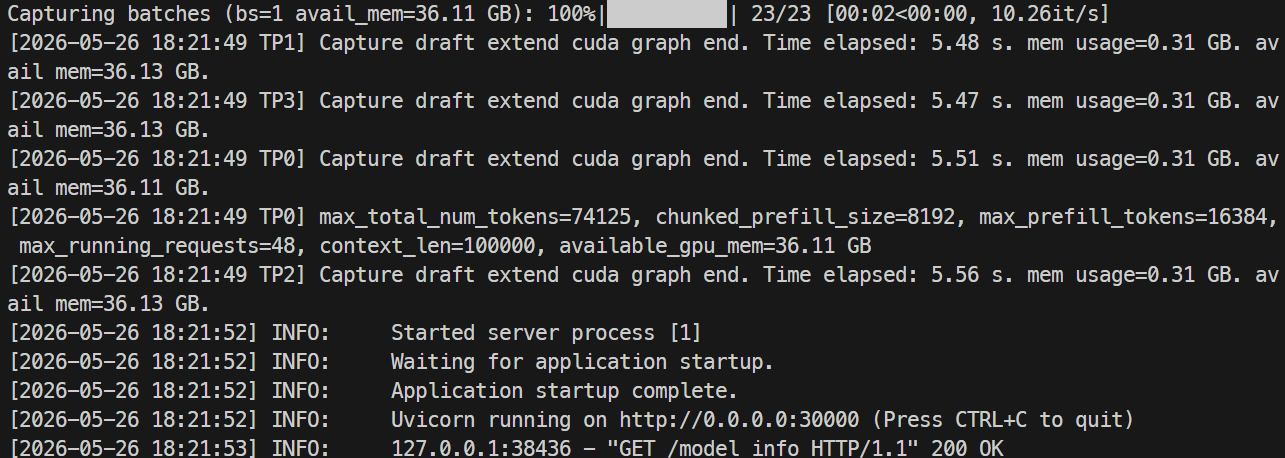
Quando i log mostrano Uvicorn in esecuzione su 0.0.0.0:30000, testa l’endpoint:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mistral-medium-3.5-eagle",
"messages": [
{
"role": "user",
"content": "Generate a simple Python game."
}
],
"reasoning_effort": "none",
"max_tokens": 300,
"temperature": 0.7,
"top_p": 0.95
}'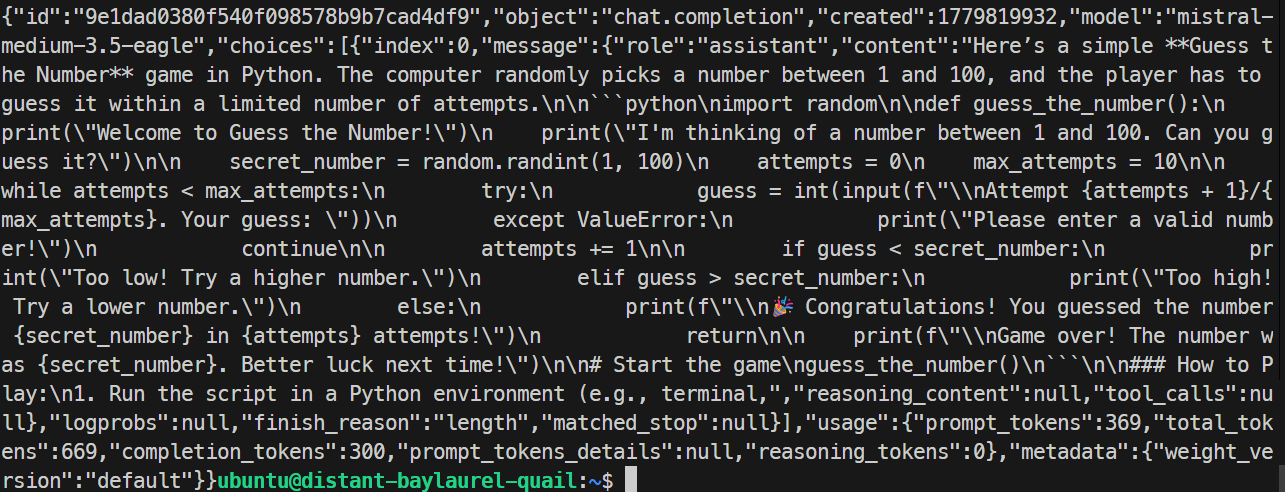
Nel mio test, il server EAGLE ha risposto correttamente e generato un semplice gioco in Python. L’esecuzione ha raggiunto circa 32 token al secondo, leggermente più lenta della base, quindi EAGLE non ha migliorato questo test specifico.
È normale: il decoding speculativo dipende molto dal carico, e il modo migliore per valutarlo è provarlo con i tuoi prompt e il tuo livello di concorrenza.
OpenCode è un coding agent open source che può connettersi a endpoint di modelli compatibili con OpenAI. Poiché SGLang espone Mistral Medium 3.5 tramite un’API locale compatibile con OpenAI, possiamo usarlo direttamente in OpenCode.
Installa OpenCode se non l’hai già fatto:
curl -fsSL https://opencode.ai/install | bashPoi spostati nella directory del tuo progetto e crea un file opencode.json.
Aggiungi la seguente configurazione:
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"sglang": {
"npm": "@ai-sdk/openai-compatible",
"name": "SGLang Local",
"options": {
"baseURL": "http://127.0.0.1:30000/v1",
"apiKey": "EMPTY"
},
"models": {
"mistral-medium-3.5-eagle": {
"name": "Mistral Medium 3.5 EAGLE",
"limit": {
"context": 100000,
"output": 8192
}
}
}
}
},
"model": "sglang/mistral-medium-3.5-eagle"
}Ora avvia OpenCode dalla stessa directory del progetto:
OpencodeDovresti vedere selezionato Mistral Medium 3.5 EAGLE SGLang Local dentro OpenCode. Questo significa che OpenCode sta ora comunicando con il tuo server SGLang locale tramite la porta 30000 inoltrata, proprio come farebbe con una qualsiasi API compatibile con OpenAI.
Nel mio test ho chiesto a OpenCode di spiegare il progetto: ha letto i file del repository in pochi secondi e generato il riepilogo.
Poi gli ho chiesto di creare un emulatore Badger 2040: prima ha ispezionato i file esistenti del progetto, validato la struttura e quindi creato il file Python richiesto. L’intero processo ha impiegato circa 2 minuti.
Dopodiché, gli ho chiesto di testare l’emulatore in locale. OpenCode ha eseguito il codice e aperto con successo la finestra dell’emulatore.
Il font non era esattamente lo stesso del display reale del Badger 2040, ma layout, orario, posizione della data e struttura generale erano quasi perfetti.

Sono rimasto sinceramente sorpreso dal risultato perché avevo provato lo stesso compito con Claude Code e GPT-5.5 in precedenza, e entrambi avevano avuto difficoltà, mentre Mistral Medium 3.5 lo ha gestito molto bene tramite la configurazione locale con SGLang.
Ci sono alcune insidie lungo il percorso. Ti guido attraverso i problemi che potresti incontrare e come risolverli.
Per prima cosa, serve pazienza. Questa configurazione completa mi ha portato quasi 3 ore. L’avvio della VM GPU circa 15 minuti, l’installazione di Docker e dell’NVIDIA container toolkit circa 10 minuti, il pull dell’immagine Docker SGLang circa 30 minuti e il download più il caricamento dei pesi del modello Mistral Medium 3.5 circa 1 ora.
L’avvio della configurazione EAGLE richiede tempo extra perché ricarica il modello e può scaricare il modello di bozza EAGLE. Se vuoi un’esperienza più fluida, usa una rete più veloce, GPU più recenti come le H200 se disponibili e storage sufficiente per l’intera cache di Hugging Face.
Se nvidia-smi funziona sull’host ma Docker non riesce ad accedere alle GPU, probabilmente il runtime NVIDIA container non è configurato correttamente. Riesegui la configurazione dell’NVIDIA container toolkit e riavvia Docker:
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart dockerLa documentazione NVIDIA raccomanda anche questo passaggio di configurazione del runtime nvidia-ctk per l’accesso GPU in Docker.
Assicurati che la cache di Hugging Face sia montata nel container:
-v ~/.cache/huggingface:/root/.cache/huggingfaceQuesto consente a Docker di riutilizzare i file del modello già scaricati, invece di riscaricarli ogni volta. Hugging Face usa una cache locale per evitare di riscaricare file aggiornati.
Il repository di Mistral Medium 3.5 è grande, quindi il primo download può richiedere molto. Se sembra bloccato, controlla velocità di rete, spazio su disco e token Hugging Face. Inoltre, assicurati di aver accettato gli eventuali termini di accesso al modello su Hugging Face prima di avviare il container.
Il server non è pronto finché i log non mostrano Uvicorn in esecuzione sulla porta 30000. Controlla i log con:
docker logs -f mistral-sglangoppure per EAGLE:
docker logs -f mistral-sglang-eagleInoltre, assicurati che il container esponga correttamente la porta con:
-p 30000:30000È normale. Il decoding speculativo non garantisce un miglioramento per ogni richiesta. Funziona usando un modello di bozza per proporre token e il modello principale per verificarli, ma la velocità dipende dal tasso di accettazione, dalla lunghezza del prompt e dell’output, dalla concorrenza e dall’utilizzo della GPU.
Se incontri problemi di memoria, riduci prima la lunghezza del contesto. Ad esempio, parti con --context-length 100000 invece di provare subito la finestra completa. Puoi anche abbassare leggermente --mem-fraction-static se l’avvio fallisce, ma ridurre la lunghezza del contesto è di solito il passo più semplice.
Assicurati che il server SGLang sia in esecuzione e che il tuo opencode.json usi il giusto endpoint locale:
"baseURL": "http://127.0.0.1:30000/v1"Se accedi al server dalla tua macchina locale, avvia SSH con il port forwarding:
ssh -L 30000:localhost:30000 ubuntu@XXXXXXPoi avvia OpenCode dalla stessa directory in cui è salvato il file opencode.json.
Sono rimasto onestamente sorpreso da quanto sia stato fluido l’aspetto tecnico. Eseguire Mistral Medium 3.5 128B con l’immagine Docker nativa di SGLang è stato molto più semplice del previsto. L’immagine Docker è stata scaricata correttamente, il modello si è caricato, l’endpoint compatibile con OpenAI ha funzionato e OpenCode si è collegato senza troppi problemi. I
n se stai provando anche tu, ti consiglierei vivamente di usare l’immagine Docker di SGLang invece di installare tutto tramite pacchetti Python. Con l’installazione via Python è facile creare conflitti con CUDA, PyTorch e altre dipendenze. Docker mantiene tutto pulito e isolato.
Ma la cosa principale che ho ricavato da questo esperimento è il costo. Onestamente non so come le aziende di AI guadagnino con l’inferenza. Anche con una delle opzioni H100 PCIe più economiche e datate, questa configurazione è costata quasi $10 all’ora. E questo solo per un modello da 128B su 4 GPU. Ora immagina di eseguire un modello da trilioni di parametri su 16× H100. Il conto può arrivare facilmente a $40+ all’ora, senza nemmeno considerare storage, rete, monitoraggio, uptime e lavoro di engineering.
Per le piccole aziende, non credo abbia senso servire localmente modelli di questo tipo a meno che non ci sia una ragione molto forte, come privacy, ricerca o necessità di un controllo profondo dello stack di inferenza. Il costo di inferenza è già elevato, ma anche il carico operativo è un problema. Devi mantenere il server attivo, assicurarti che il modello non vada in crash, monitorare la memoria GPU, gestire i container falliti e mantenere l’endpoint disponibile.
Nemmeno il serverless risolve davvero per i modelli molto grandi. Il cold start è semplicemente troppo lungo. In questa configurazione, l’avvio della VM GPU, l’installazione delle dipendenze, il pull dell’immagine Docker, il download dei pesi e il caricamento del modello hanno richiesto in totale quasi 3 ore.
Anche se la tua configurazione fosse più veloce, caricare un modello di queste dimensioni può comunque richiedere molto. Quindi, se ogni nuova richiesta richiede di lanciare un altro cluster GPU e ricaricare il modello, si vanifica lo scopo del serverless. In pratica, le aziende devono mantenere cluster GPU "caldi", il che significa pagare anche quando le GPU sono in idle.
Questo spiega anche perché esistono prezzi GPU fuori picco. I provider vogliono che le persone usino la capacità GPU inattiva, perché le GPU inutilizzate bruciano denaro. Per gli utenti può essere un buon modo per sperimentare a costi minori, ma mostra anche quanto sia complicata l’economia dell’inferenza di modelli molto grandi.
Nel complesso, SGLang mi è piaciuto molto per questa configurazione. Il workflow basato su Docker ha reso il serving di Mistral Medium 3.5 128B molto più semplice del previsto e il test con OpenCode è stato davvero convincente. Ma questo esperimento mi ha anche chiarito una cosa: eseguire in locale grandi modelli open è possibile, ma gestirli in modo affidabile e a costi sostenibili come prodotto reale è tutta un’altra sfida.
Impara l'AI con DataCamp!
Programma
Corso
Corso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min

