
Tracks
Kỹ sư Trợ lý Trí tuệ Nhân tạo (AI) cho Lập trình viên
26 giờ
Trong hướng dẫn này, tôi đã dùng một máy ảo GPU 4× H100 80GB. Mistral Medium 3.5 là model dày đặc 128B, nên cần thiết lập đa GPU. SGLang khuyến nghị chạy với song song tensor dùng --tp 4 trên GPU H100 hoặc H200. Model hỗ trợ cửa sổ ngữ cảnh lớn, nhưng tôi khuyên nên bắt đầu với 100.000 token trước thay vì toàn bộ ngữ cảnh 256K để dễ kiểm thử và gỡ lỗi hơn.
Tôi đã dùng Hyperbolic vì nó cho quyền truy cập toàn bộ máy ảo GPU, giúp dễ cài Docker, cấu hình NVIDIA container runtime, và chạy image Docker SGLang thủ công. Bạn cũng có thể dùng các nền tảng như RunPod hoặc Vast.ai, nhưng một số phiên bản của họ đã gắn với môi trường Docker tùy chỉnh, khiến bạn ít kiểm soát hơn.
Trong Hyperbolic, chọn H100 PCIe 80GB, chọn 4 GPU, thêm khoảng 3TB lưu trữ, nhập khóa công khai SSH của bạn, và đặt tên cho phiên bản, ví dụ MM-35. Tôi chọn H100 PCIe vì đây là tùy chọn H100 rẻ nhất có sẵn cho thử nghiệm này.
Sau khi nhấp Start Building, máy có thể mất khoảng 10 phút để khởi động. Khi sẵn sàng, Hyperbolic sẽ hiển thị lệnh truy cập SSH bạn cần cho bước tiếp theo.
Khi phiên bản sẵn sàng, kết nối đến đó từ terminal cục bộ của bạn bằng lệnh SSH hiển thị trong bảng điều khiển Hyperbolic:
ssh ubuntu@XXXXXXĐể truy cập API SGLang từ máy cục bộ sau này, bạn cũng có thể chuyển tiếp cổng 30000:
ssh -L 30000:localhost:30000 ubuntu@XXXXXXNếu khóa SSH của bạn có mật khẩu, hãy nhập khi được nhắc. Sau khi đăng nhập, kiểm tra rằng tất cả GPU khả dụng:
Nvidia-smiBạn sẽ thấy 4× NVIDIA H100 PCIe 80GB được liệt kê. Điều này xác nhận máy chủ đã sẵn sàng cho thiết lập Docker và SGLang.
Đầu tiên, export token Hugging Face của bạn để máy chủ có thể tải model Mistral sau này:
echo 'export HF_TOKEN="your_huggingface_token_here"' >> ~/.bashrc
source ~/.bashrcLưu ý: Bạn có thể lấy token Hugging Face từ trang Access Tokens.
Tạo thư mục cache của Hugging Face:
mkdir -p ~/.cache/huggingfaceBây giờ cài Docker:
sudo apt update
sudo apt install -y docker.ioKhởi động Docker và bật tự động chạy sau khi khởi động lại:
sudo systemctl start docker
sudo systemctl enable dockerKiểm tra Docker đã cài đúng chưa:
docker –versionBạn cũng có thể dùng lệnh tìm kiếm của Docker để xác nhận Docker có thể tìm image công khai từ Docker Hub:
docker search nvidia/cudaLệnh này sẽ trả về các image NVIDIA CUDA khả dụng. Sau đó, chúng ta sẽ dùng một trong các image CUDA này để xác minh Docker có thể truy cập GPU.
Tiếp theo, cho phép người dùng của bạn chạy lệnh Docker không cần sudo:
sudo usermod -aG docker $USER
newgrp dockerGiờ hãy cài và cấu hình NVIDIA Container Toolkit để Docker có thể truy cập GPU:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/libnvidia-container/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt update
sudo apt install -y nvidia-container-toolkit
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart dockerCuối cùng, kiểm tra Docker có thể thấy GPU từ trong container:
docker run --rm --gpus all nvidia/cuda:12.4.1-base-ubuntu22.04 nvidia-smiNếu lệnh này in ra cùng danh sách GPU H100 bên trong container Docker, thiết lập Docker GPU của bạn hoạt động đúng.
Tiếp theo, kéo image Docker SGLang được xây cho Mistral Medium 3.5:
docker pull lmsysorg/sglang:dev-mistral-medium-3.5
Bước này có thể mất thời gian tùy tốc độ mạng. Trường hợp của tôi mất khoảng 10 phút. Khi image tải xong, Docker sẽ hiển thị thông báo thành công tương tự:
Status: Downloaded newer image for lmsysorg/sglang:dev-mistral-medium-3.5Bây giờ khởi động máy chủ SGLang:
docker run -d \
--name mistral-sglang \
--gpus all \
--shm-size 64g \
--ipc=host \
--cap-add SYS_NICE \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e HF_TOKEN=$HF_TOKEN \
-e PYTORCH_ALLOC_CONF=expandable_segments:True \
lmsysorg/sglang:dev-mistral-medium-3.5 \
sglang serve \
--model-path mistralai/Mistral-Medium-3.5-128B \
--served-model-name mistral-medium-3.5 \
--host 0.0.0.0 \
--port 30000 \
--tp 4 \
--trust-remote-code \
--dtype bfloat16 \
--context-length 100000 \
--mem-fraction-static 0.85 \
--disable-custom-all-reduce \
--tool-call-parser mistral \
--reasoning-parser mistralTôi dùng --dtype bfloat16 vì thiết lập EAGLE sau đó cũng yêu cầu bf16, nên giữ lần chạy cơ bản và lần chạy speculative đồng bộ giúp tránh phải đổi dtype giữa các bài kiểm thử. Tôi cũng bắt đầu với --context-length 100000 thay vì cửa sổ ngữ cảnh đầy đủ để lần chạy đầu dễ gỡ lỗi hơn.
Kiểm tra log của container bằng:
docker logs -f mistral-sglang
Lần khởi động đầu sẽ lâu hơn vì SGLang cần tải các tệp model từ Hugging Face. Kho lưu trữ đầy đủ rất lớn, nên có thể mất khoảng một giờ hoặc hơn, tùy tốc độ của phiên bản máy.
Khi máy chủ sẵn sàng, log sẽ hiển thị Uvicorn đang chạy trên cổng 30000.
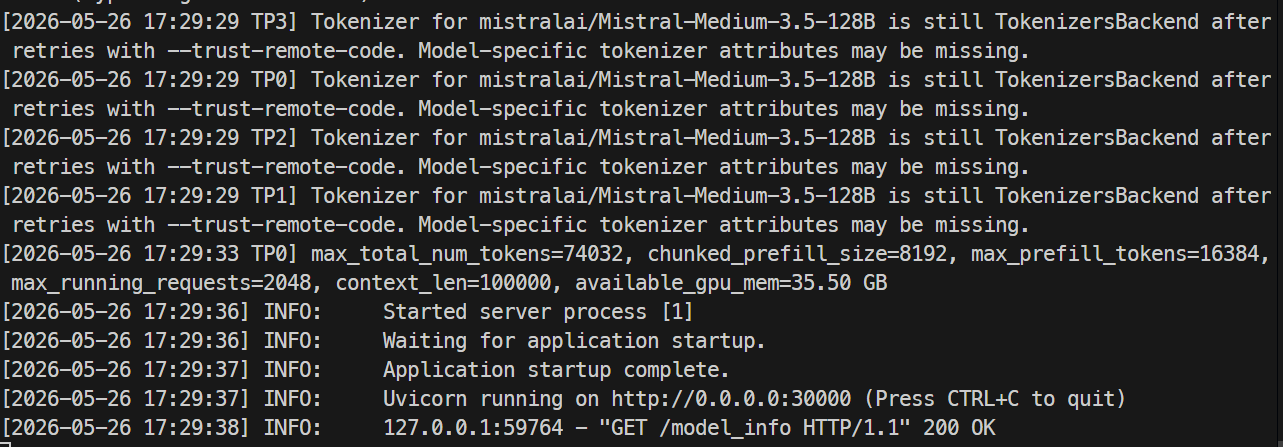
Trong một terminal khác, SSH vào máy chủ lần nữa và kiểm tra endpoint của model:
curl http://localhost:30000/v1/modelsBạn sẽ thấy mistral-medium-3.5 được liệt kê với max_model_len là 100000.
{"object":"list","data":[{"id":"mistral-medium-3.5","object":"model","created":1779816738,"owned_by":"sglang","root":"mistral-medium-3.5","parent":null,"max_model_len":100000}]}Cuối cùng, kiểm thử một chat completion:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mistral-medium-3.5",
"messages": [
{
"role": "user",
"content": "Write a short introduction to Mistral Medium 3.5."
}
],
"max_tokens": 300,
"temperature": 0.7,
"top_p": 0.95
}'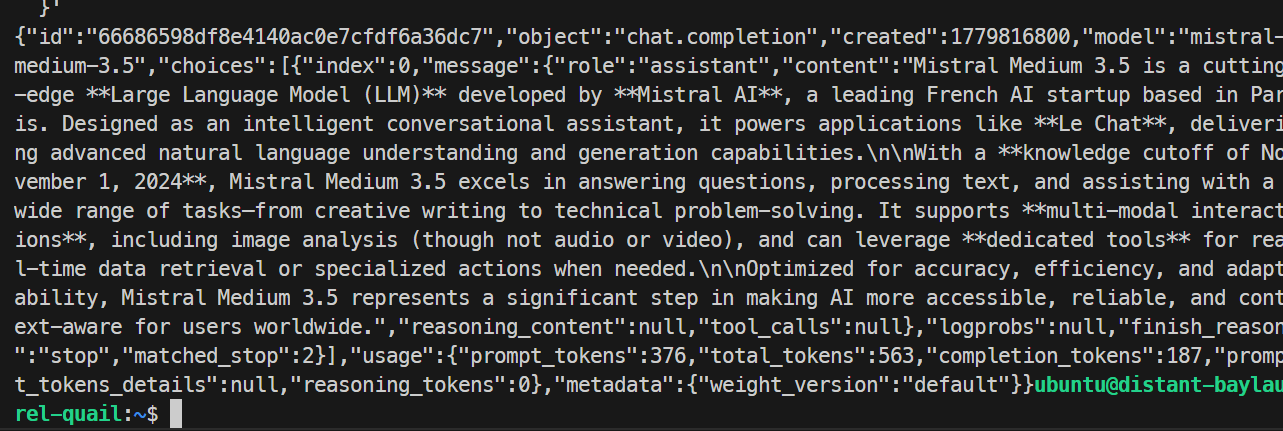
Trong thử nghiệm của tôi, model phản hồi thành công và hoàn tất yêu cầu gọn gàng, xác nhận endpoint SGLang hoạt động. Lần chạy cơ bản tạo khoảng 35,6 token mỗi giây.
Speculative decoding có thể tăng tốc sinh bằng cách dùng một model nháp nhỏ hơn để dự đoán trước token, trong khi model chính xác minh chúng.
EAGLE hữu ích ở đây vì nó được thiết kế cho phục vụ nhạy cảm độ trễ, đặc biệt khi bạn chạy một model lớn như Mistral Medium 3.5 cục bộ. Nó sẽ không phải lúc nào cũng nhanh hơn, nhưng đáng để thử vì lợi ích phụ thuộc vào độ dài prompt, độ dài đầu ra, mức độ song song và mức sử dụng GPU.
Trước tiên, gỡ container cơ bản:
docker rm -f mistral-sglangSau đó khởi động phiên bản EAGLE:
docker run -d \
--name mistral-sglang-eagle \
--gpus all \
--shm-size 64g \
--ipc=host \
--cap-add SYS_NICE \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e HF_TOKEN="$HF_TOKEN" \
-e PYTORCH_ALLOC_CONF=expandable_segments:True \
lmsysorg/sglang:dev-mistral-medium-3.5 \
sglang serve \
--model-path mistralai/Mistral-Medium-3.5-128B \
--served-model-name mistral-medium-3.5-eagle \
--host 0.0.0.0 \
--port 30000 \
--tp 4 \
--trust-remote-code \
--dtype bfloat16 \
--context-length 100000 \
--mem-fraction-static 0.85 \
--disable-custom-all-reduce \
--tool-call-parser mistral \
--reasoning-parser mistral \
--enable-metrics \
--speculative-algorithm EAGLE \
--speculative-draft-model-path mistralai/Mistral-Medium-3.5-128B-EAGLE \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4SGLang khuyến nghị thiết lập EAGLE này như một điểm khởi đầu tốt: --speculative-num-steps 3, --speculative-eagle-topk 1, và --speculative-num-draft-tokens 4. Lần chạy đầu có thể lâu hơn vì nó cũng tải model nháp EAGLE.
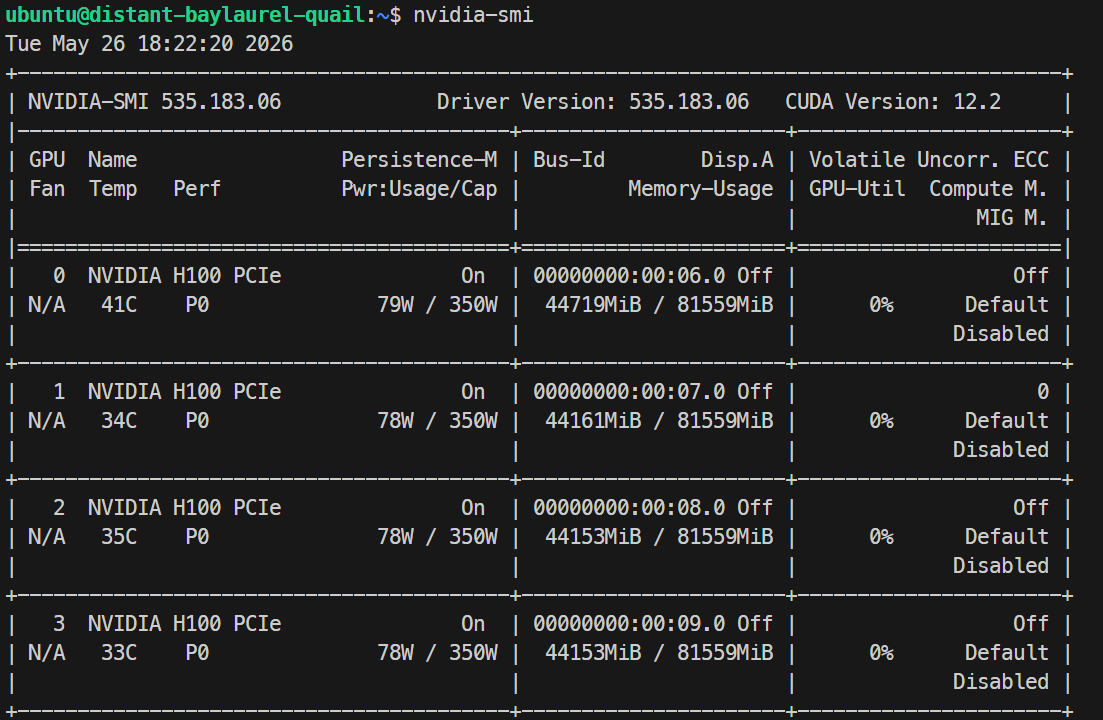
Khi đã tải, bạn có thể kiểm tra mức dùng GPU bằng nvidia-smi; trong lần chạy của tôi, model dùng khoảng 44GB trên mỗi GPU H100.
Theo dõi log bằng:
docker logs -f mistral-sglang-eagle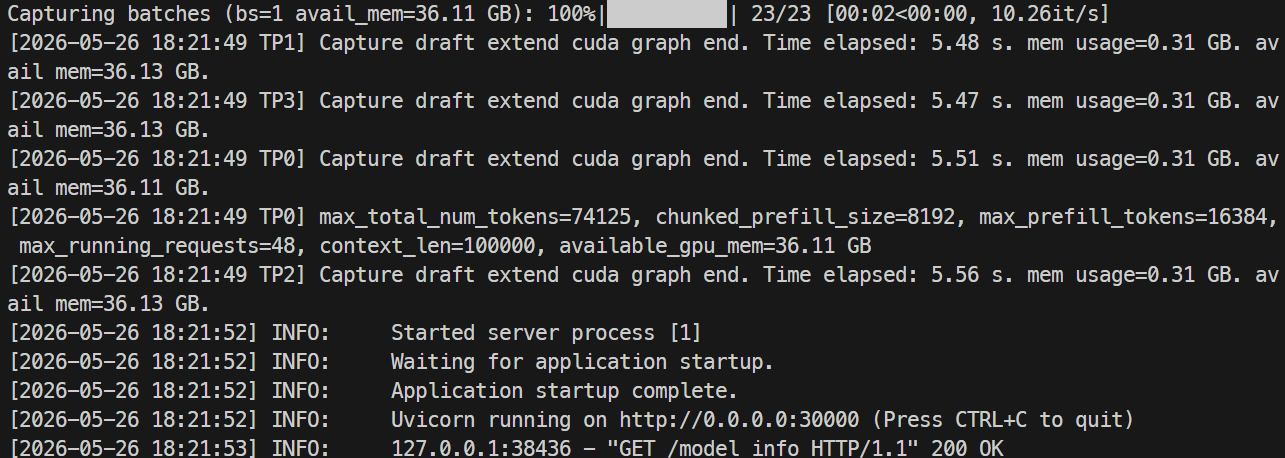
Khi log hiển thị Uvicorn đang chạy trên 0.0.0.0:30000, hãy kiểm thử endpoint:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mistral-medium-3.5-eagle",
"messages": [
{
"role": "user",
"content": "Generate a simple Python game."
}
],
"reasoning_effort": "none",
"max_tokens": 300,
"temperature": 0.7,
"top_p": 0.95
}'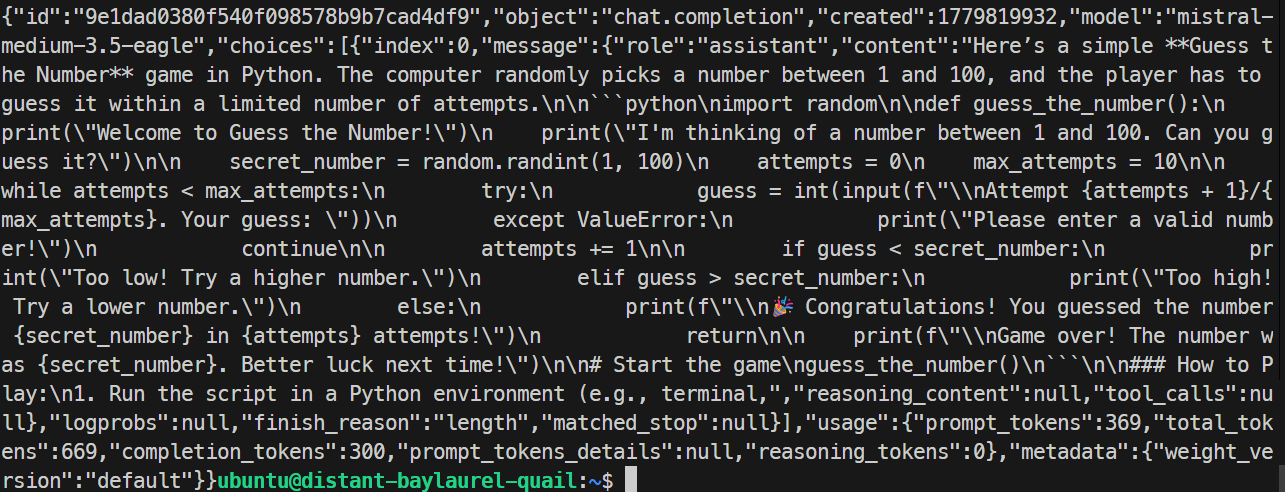
Trong thử nghiệm của tôi, máy chủ EAGLE phản hồi chính xác và tạo ra một trò chơi Python đơn giản. Lần chạy đạt khoảng 32 token mỗi giây, hơi chậm hơn lần chạy cơ bản, nên EAGLE không cải thiện bài test cụ thể này.
Điều này là bình thường: speculative decoding phụ thuộc rất nhiều vào khối lượng công việc, và cách đánh giá tốt nhất là thử với chính prompt và mức độ song song của bạn.
OpenCode là một tác tử lập trình AI mã nguồn mở có thể kết nối đến các endpoint model tương thích OpenAI. Vì SGLang cung cấp Mistral Medium 3.5 qua API tương thích OpenAI cục bộ, chúng ta có thể dùng trực tiếp trong OpenCode.
Cài OpenCode nếu bạn chưa cài:
curl -fsSL https://opencode.ai/install | bashSau đó chuyển vào thư mục dự án của bạn và tạo tệp opencode.json.
Thêm cấu hình sau:
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"sglang": {
"npm": "@ai-sdk/openai-compatible",
"name": "SGLang Local",
"options": {
"baseURL": "http://127.0.0.1:30000/v1",
"apiKey": "EMPTY"
},
"models": {
"mistral-medium-3.5-eagle": {
"name": "Mistral Medium 3.5 EAGLE",
"limit": {
"context": 100000,
"output": 8192
}
}
}
}
},
"model": "sglang/mistral-medium-3.5-eagle"
}Giờ khởi động OpenCode từ cùng thư mục dự án:
OpencodeBạn sẽ thấy Mistral Medium 3.5 EAGLE SGLang Local được chọn trong OpenCode. Điều này có nghĩa OpenCode đang giao tiếp với máy chủ SGLang cục bộ của bạn qua cổng 30000 đã chuyển tiếp, tương tự như gọi bất kỳ API tương thích OpenAI nào.
Trong thử nghiệm của tôi, tôi yêu cầu OpenCode giải thích dự án, và nó đã đọc các tệp trong kho trong vài giây và sinh bản tóm tắt.
Sau đó, tôi yêu cầu tạo một trình giả lập Badger 2040, và trước tiên nó kiểm tra các tệp dự án hiện có, xác thực cấu trúc, rồi tạo tệp Python cần thiết. Toàn bộ quá trình mất khoảng 2 phút.
Sau đó, tôi yêu cầu kiểm thử trình giả lập cục bộ. OpenCode đã chạy mã và mở cửa sổ trình giả lập thành công.
Phông chữ không hoàn toàn giống màn hình Badger 2040 thật, nhưng bố cục, hiển thị thời gian, vị trí ngày tháng và cấu trúc tổng thể gần như hoàn hảo.

Tôi thực sự bất ngờ với kết quả vì trước đó tôi đã thử tác vụ tương tự với Claude Code và GPT-5.5, cả hai đều gặp khó khăn, trong khi Mistral Medium 3.5 xử lý rất tốt qua thiết lập SGLang cục bộ.
Có vài điểm dễ mắc lỗi trong quá trình. Hãy cùng điểm qua những vấn đề bạn có thể gặp và cách giải quyết.
Trước hết, bạn sẽ cần kiên nhẫn. Toàn bộ thiết lập này mất của tôi gần 3 giờ. Khởi chạy máy ảo GPU mất khoảng 15 phút, cài Docker và NVIDIA container toolkit khoảng 10 phút, kéo image Docker SGLang khoảng 30 phút, và tải cùng nạp trọng số model Mistral Medium 3.5 khoảng 1 giờ.
Bắt đầu thiết lập EAGLE cũng tốn thêm thời gian vì nó nạp model lại và có thể tải model nháp EAGLE. Nếu muốn trải nghiệm mượt hơn, hãy dùng mạng nhanh hơn, GPU mới hơn như H200 nếu có, và đủ dung lượng cho toàn bộ cache của Hugging Face.
Nếu nvidia-smi hoạt động trên máy chủ host nhưng Docker không truy cập được GPU, có thể NVIDIA container runtime chưa được cấu hình đúng. Chạy lại cấu hình NVIDIA container toolkit và khởi động lại Docker:
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart dockerTài liệu của NVIDIA cũng khuyến nghị bước cấu hình runtime nvidia-ctk này cho truy cập GPU trong Docker.
Hãy đảm bảo cache Hugging Face được mount vào container:
-v ~/.cache/huggingface:/root/.cache/huggingfaceĐiều này cho phép Docker tái sử dụng các tệp model đã tải thay vì tải lại mỗi lần. Hugging Face dùng cache cục bộ để tránh tải lại các tệp đã cập nhật.
Kho Mistral Medium 3.5 rất lớn, nên lần tải đầu có thể mất lâu. Nếu có vẻ bị treo, hãy kiểm tra tốc độ mạng, dung lượng đĩa và token Hugging Face. Đồng thời, đảm bảo bạn đã chấp nhận các điều khoản truy cập model bắt buộc trên Hugging Face trước khi chạy container.
Máy chủ chưa sẵn sàng cho đến khi log hiển thị Uvicorn đang chạy trên cổng 30000. Kiểm tra log bằng:
docker logs -f mistral-sglanghoặc với EAGLE:
docker logs -f mistral-sglang-eagleNgoài ra, đảm bảo container đã mở cổng đúng với:
-p 30000:30000Điều này bình thường. Speculative decoding không đảm bảo cải thiện mọi yêu cầu. Nó hoạt động bằng cách dùng model nháp đề xuất token và model chính xác minh, nhưng mức tăng tốc phụ thuộc vào tỷ lệ chấp nhận, độ dài prompt, độ dài đầu ra, mức độ song song và sử dụng GPU.
Nếu gặp vấn đề bộ nhớ, hãy giảm độ dài ngữ cảnh trước. Ví dụ, bắt đầu với --context-length 100000 thay vì thử ngay cửa sổ ngữ cảnh đầy đủ. Bạn cũng có thể giảm nhẹ --mem-fraction-static nếu khởi động thất bại, nhưng giảm độ dài ngữ cảnh thường là bước đầu dễ nhất.
Hãy đảm bảo máy chủ SGLang đang chạy và opencode.json của bạn dùng đúng endpoint cục bộ:
"baseURL": "http://127.0.0.1:30000/v1"Nếu bạn truy cập máy chủ từ máy cục bộ, hãy khởi động SSH với chuyển tiếp cổng:
ssh -L 30000:localhost:30000 ubuntu@XXXXXXSau đó khởi chạy OpenCode từ cùng thư mục nơi lưu tệp opencode.json.
Tôi thật sự ngạc nhiên về độ trơn tru của thiết lập kỹ thuật. Chạy Mistral Medium 3.5 128B với image Docker gốc của SGLang dễ hơn tôi mong đợi. Image Docker được kéo chính xác, model nạp thành công, endpoint tương thích OpenAI hoạt động và OpenCode kết nối mà không gặp nhiều trục trặc. T
ôi khuyên bạn, nếu tự thử, hãy dùng image Docker của SGLang thay vì cài mọi thứ bằng gói Python. Khi cài qua Python, rất dễ phát sinh xung đột với CUDA, PyTorch và các phụ thuộc khác. Docker giữ mọi thứ sạch và tách biệt.
Nhưng điều đáng chú ý nhất tôi rút ra là chi phí. Thành thật mà nói, tôi không biết các công ty AI kiếm tiền từ suy luận bằng cách nào. Ngay cả với một trong những tùy chọn H100 PCIe cũ và rẻ hơn, thiết lập này vẫn vào khoảng $10 mỗi giờ. Và đây chỉ là một model 128B trên 4 GPU. Hãy tưởng tượng chạy một model nghìn tỷ tham số lớn hơn nhiều trên 16× H100. Hóa đơn dễ dàng chạm $40+ mỗi giờ, trước khi tính đến lưu trữ, mạng, giám sát, uptime và công việc kỹ thuật.
Với các công ty nhỏ, tôi không nghĩ việc phục vụ các model như thế này cục bộ là hợp lý trừ khi có lý do rất mạnh như quyền riêng tư, nghiên cứu, hoặc cần kiểm soát sâu ngăn xếp suy luận. Chi phí suy luận đã cao, nhưng gánh nặng vận hành cũng là vấn đề. Bạn cần giữ máy chủ luôn chạy, đảm bảo model không sập, giám sát bộ nhớ GPU, xử lý container lỗi và duy trì endpoint sẵn sàng.
Serverless cũng không thực sự giải quyết được điều này cho các model rất lớn. Thời gian khởi chạy lạnh đơn giản là quá dài. Với thiết lập này, khởi chạy máy ảo GPU, cài phụ thuộc, kéo image Docker, tải trọng số và nạp model mất gần 3 giờ tất cả.
Ngay cả khi thiết lập của bạn nhanh hơn, việc nạp một model cỡ này vẫn mất nhiều thời gian. Vì vậy nếu mỗi yêu cầu mới đòi hỏi khởi chạy một cụm GPU khác và nạp lại model, điều đó đi ngược mục đích của serverless. Trên thực tế, các công ty cần giữ cụm GPU ở trạng thái warm, đồng nghĩa vẫn phải trả tiền ngay cả khi GPU nhàn rỗi.
Điều này cũng giải thích vì sao có mức giá GPU ngoài giờ cao điểm. Nhà cung cấp muốn người dùng tận dụng công suất GPU nhàn rỗi vì GPU không được dùng chỉ đốt tiền. Với người dùng, đó có thể là cách thử nghiệm rẻ hơn, nhưng cũng cho thấy bài toán kinh tế của suy luận model lớn khó khăn thế nào.
Tổng thể, tôi rất thích SGLang cho thiết lập này. Quy trình dựa trên Docker khiến việc phục vụ Mistral Medium 3.5 128B dễ hơn nhiều so với kỳ vọng, và bài test với OpenCode thực sự ấn tượng. Nhưng thử nghiệm này cũng làm tôi thấy rõ một điều: chạy các model mở lớn cục bộ là khả thi, nhưng vận hành chúng một cách ổn định và hợp chi phí như một sản phẩm thực sự là một thách thức hoàn toàn khác.
Học AI cùng DataCamp!
Tracks
Courses
Courses
blogs
Matt Crabtree
10 phút