Track
Ассоциированный AI-инженер для разработчиков
26 ч
Для этого руководства я использовал виртуальную машину с 4 × H100 80GB. Mistral Medium 3.5 — плотная модель 128B, поэтому ей требуется конфигурация с несколькими GPU. SGLang рекомендует запускать её с тензорным параллелизмом, используя --tp 4 на GPU H100 или H200. Модель поддерживает большой контекст, но я рекомендую начать со 100 000 токенов вместо полного окна 256K, чтобы упростить тестирование и отладку.
Я выбрал Hyperbolic, потому что он предоставляет доступ к полноценной VM с GPU, что упрощает установку Docker, настройку среды выполнения контейнеров NVIDIA и ручной запуск Docker‑образа SGLang. Можно использовать и платформы вроде RunPod или Vast.ai, но некоторые их инстансы уже привязаны к кастомным Docker‑средам, что даёт меньше контроля.
В Hyperbolic выберите H100 PCIe 80GB, укажите 4 GPU, добавьте около 3 ТБ хранилища, введите ваш SSH‑публичный ключ и дайте инстансу имя, например MM-35. Я выбрал H100 PCIe, потому что это был самый дешёвый доступный вариант H100 для этого теста.
После нажатия Start Building запуск машины может занять около 10 минут. Когда всё будет готово, Hyperbolic покажет команду для доступа по SSH, которая понадобится на следующем шаге.
Когда инстанс готов, подключитесь к нему из локального терминала, используя команду SSH, показанную в панели Hyperbolic:
ssh ubuntu@XXXXXXЧтобы позже получить доступ к API SGLang с локальной машины, можно также пробросить порт 30000:
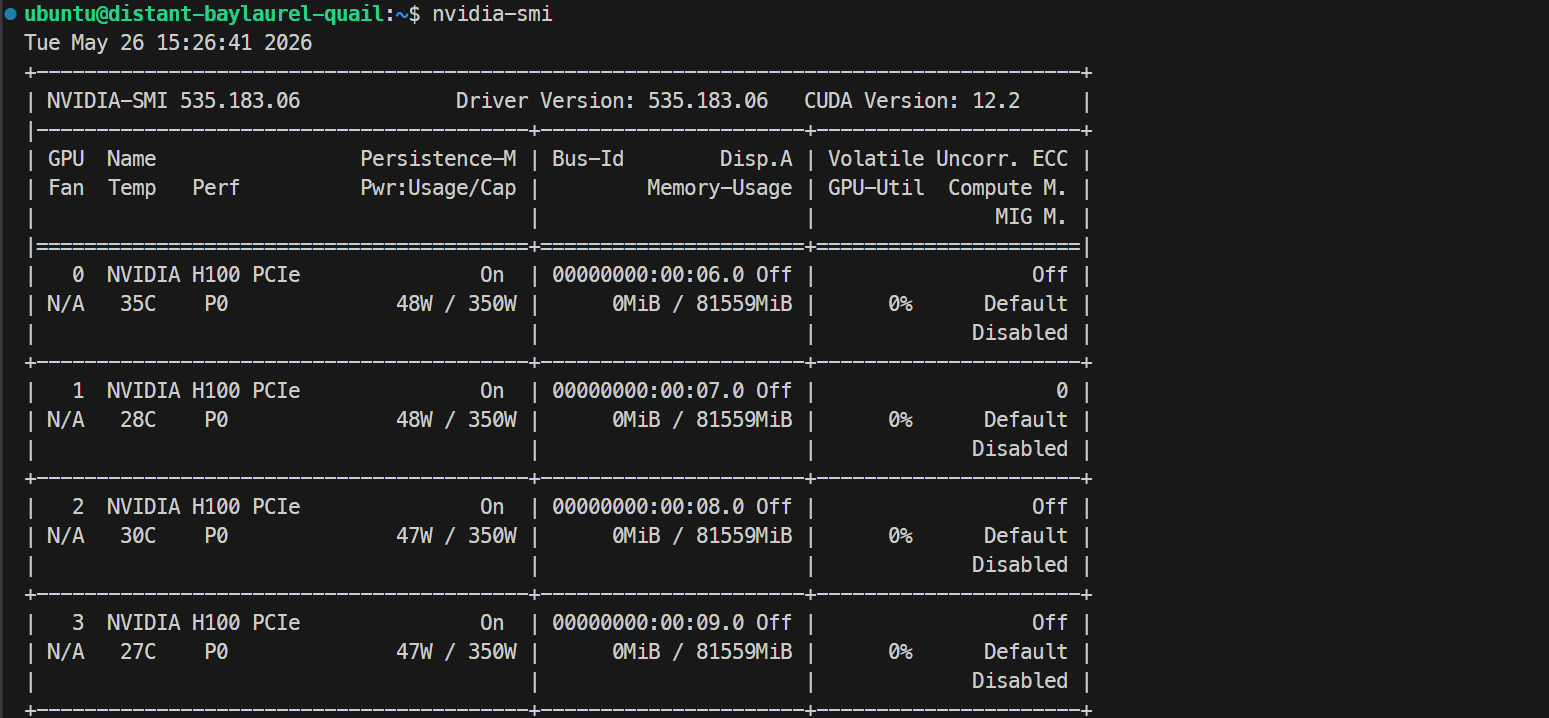
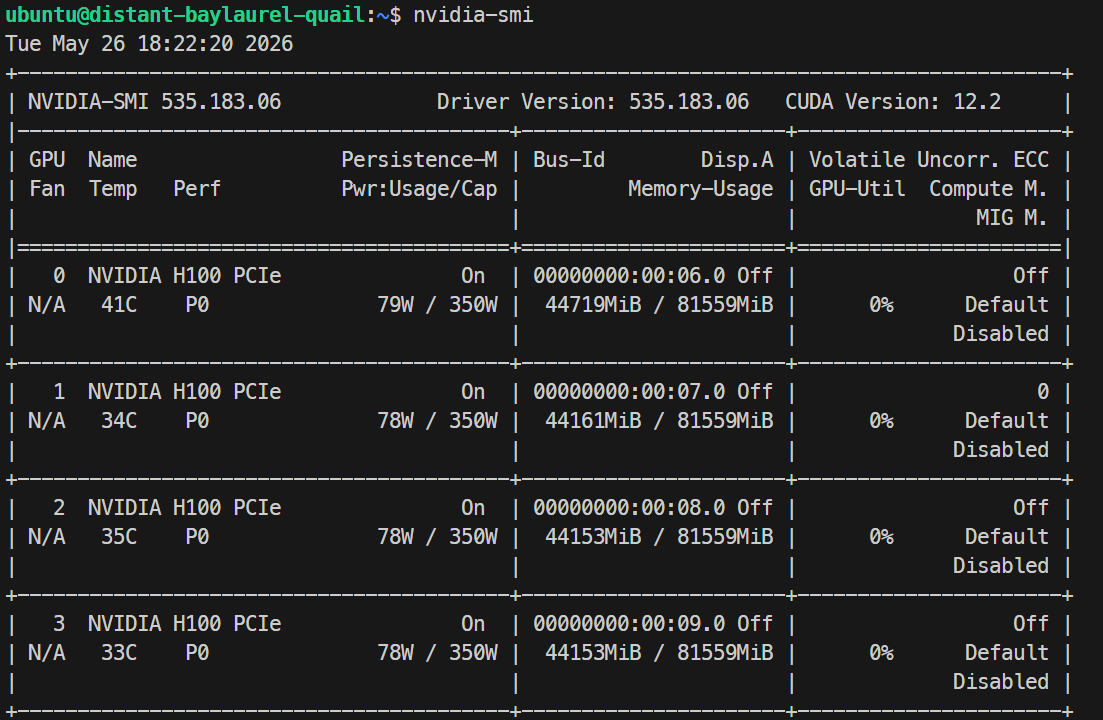
ssh -L 30000:localhost:30000 ubuntu@XXXXXXЕсли у вашего SSH‑ключа есть парольная фраза, введите её по запросу. После входа проверьте, что все GPU доступны:
Nvidia-smiВы должны увидеть 4 × NVIDIA H100 PCIe 80GB. Это подтверждает, что сервер готов к установке Docker и SGLang.
Сначала экспортируйте токен Hugging Face, чтобы сервер позже смог скачать модель Mistral:
echo 'export HF_TOKEN="your_huggingface_token_here"' >> ~/.bashrc
source ~/.bashrcПримечание: получить токен Hugging Face можно на странице Access Tokens.
Создайте папку кэша Hugging Face:
mkdir -p ~/.cache/huggingfaceТеперь установите Docker:
sudo apt update
sudo apt install -y docker.ioЗапустите Docker и включите автозапуск после перезагрузки:
sudo systemctl start docker
sudo systemctl enable dockerПроверьте, что Docker установлен корректно:
docker –versionТакже можно использовать команду поиска Docker, чтобы убедиться, что он находит публичные образы на Docker Hub:
docker search nvidia/cudaДолжны вернуться доступные образы NVIDIA CUDA. Позже мы используем один из этих образов CUDA, чтобы проверить доступ Docker к GPU.
Далее разрешите вашему пользователю выполнять команды Docker без sudo:
sudo usermod -aG docker $USER
newgrp dockerТеперь установите и настройте NVIDIA Container Toolkit, чтобы Docker мог обращаться к GPU:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/libnvidia-container/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt update
sudo apt install -y nvidia-container-toolkit
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart dockerНаконец, проверьте, что Docker видит GPU внутри контейнера:
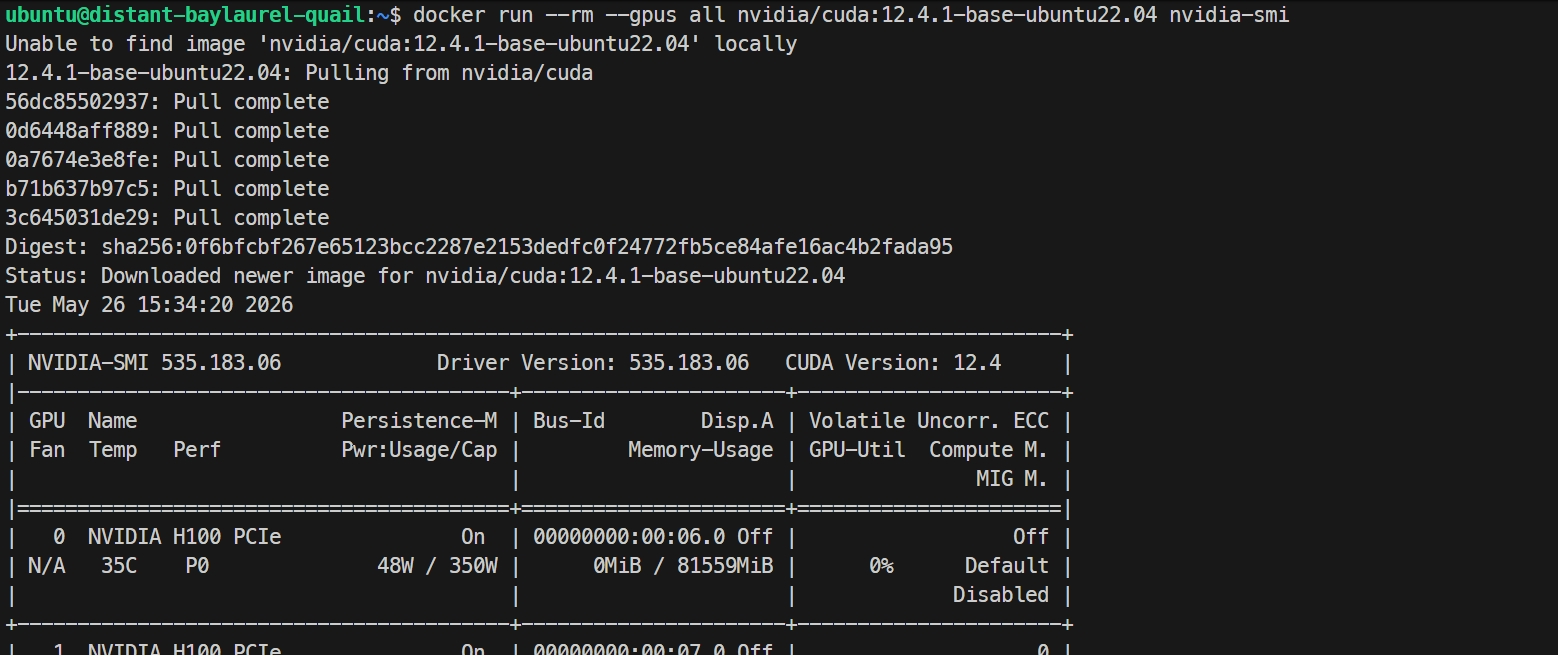
docker run --rm --gpus all nvidia/cuda:12.4.1-base-ubuntu22.04 nvidia-smiЕсли внутри контейнера выводится тот же список H100, значит, конфигурация GPU для Docker работает корректно.
Далее загрузите Docker‑образ SGLang, собранный для Mistral Medium 3.5:
docker pull lmsysorg/sglang:dev-mistral-medium-3.5
Это может занять некоторое время в зависимости от скорости интернета. У меня ушло около 10 минут. После загрузки Docker покажет сообщение об успешной загрузке, например:
Status: Downloaded newer image for lmsysorg/sglang:dev-mistral-medium-3.5Теперь запустите сервер SGLang:
docker run -d \
--name mistral-sglang \
--gpus all \
--shm-size 64g \
--ipc=host \
--cap-add SYS_NICE \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e HF_TOKEN=$HF_TOKEN \
-e PYTORCH_ALLOC_CONF=expandable_segments:True \
lmsysorg/sglang:dev-mistral-medium-3.5 \
sglang serve \
--model-path mistralai/Mistral-Medium-3.5-128B \
--served-model-name mistral-medium-3.5 \
--host 0.0.0.0 \
--port 30000 \
--tp 4 \
--trust-remote-code \
--dtype bfloat16 \
--context-length 100000 \
--mem-fraction-static 0.85 \
--disable-custom-all-reduce \
--tool-call-parser mistral \
--reasoning-parser mistralЯ использовал --dtype bfloat16, потому что последующая настройка EAGLE тоже требует bf16, поэтому выравнивание базового запуска и спекулятивного запуска избавляет от смены типа данных между тестами. Я также начал с --context-length 100000 вместо полного окна, чтобы упростить отладку первого запуска.
Проверьте логи контейнера командой:
docker logs -f mistral-sglang
Первый запуск займёт больше времени, поскольку SGLang должен скачать файлы модели с Hugging Face. Репозиторий большой, поэтому это может занять около часа или больше — зависит от скорости инстанса.
Когда сервер будет готов, в логах появится сообщение о запуске Uvicorn на порту 30000.
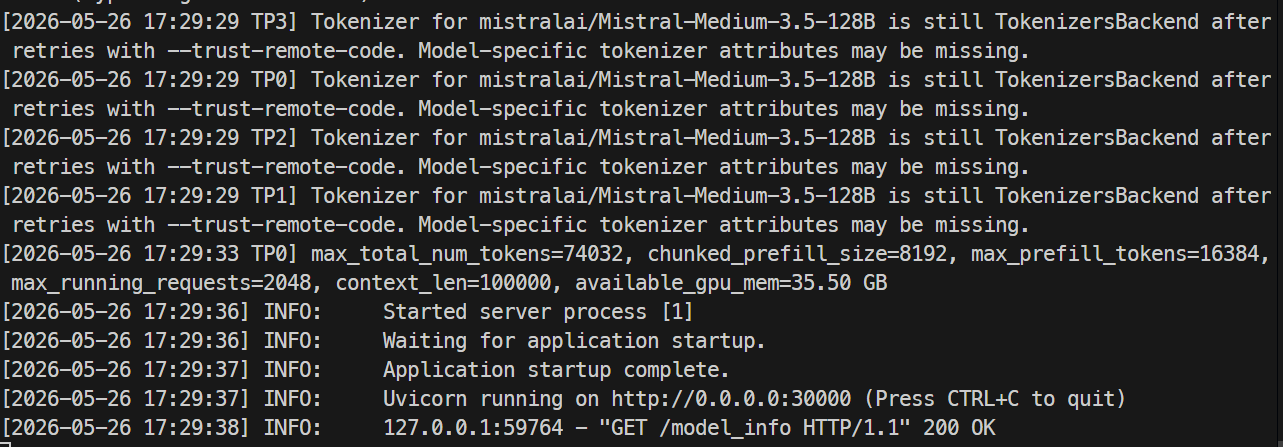
В другом терминале снова подключитесь по SSH к серверу и проверьте конечную точку модели:
curl http://localhost:30000/v1/modelsВы должны увидеть mistral-medium-3.5 с max_model_len равным 100000.
{"object":"list","data":[{"id":"mistral-medium-3.5","object":"model","created":1779816738,"owned_by":"sglang","root":"mistral-medium-3.5","parent":null,"max_model_len":100000}]}Наконец, протестируйте чат‑completion:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mistral-medium-3.5",
"messages": [
{
"role": "user",
"content": "Write a short introduction to Mistral Medium 3.5."
}
],
"max_tokens": 300,
"temperature": 0.7,
"top_p": 0.95
}'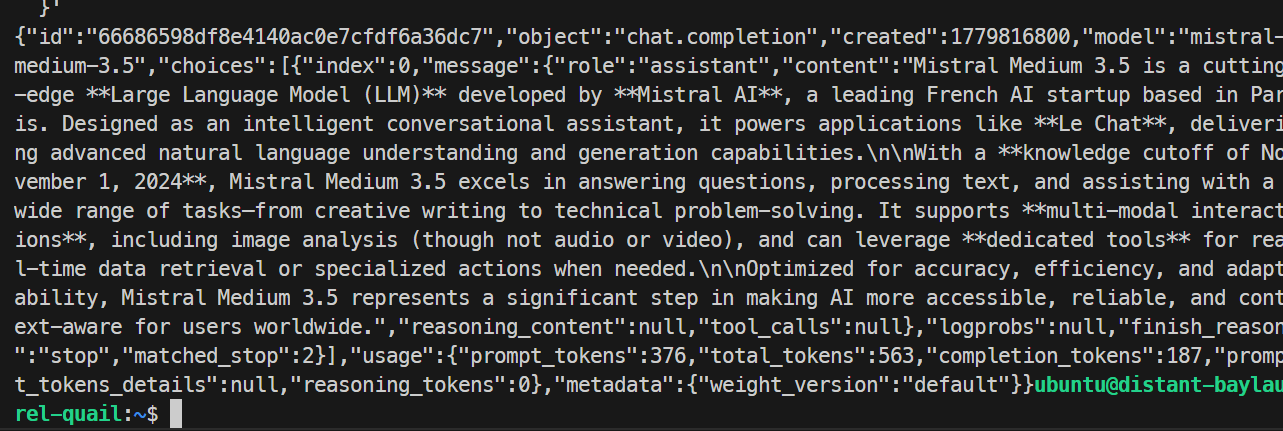
В моём тесте модель успешно ответила и корректно выполнила запрос, подтвердив, что конечная точка SGLang работает. Базовый запуск дал около 35,6 токена в секунду.
Спекулятивное декодирование может ускорить генерацию, используя меньшую черновую модель для предсказания токенов наперёд, пока основная модель их проверяет.
EAGLE полезен здесь, потому что он ориентирован на сервинг с низкой задержкой, особенно при локальном запуске большой модели вроде Mistral Medium 3.5. Он не всегда будет быстрее, но стоит протестировать, так как выгода зависит от длины промпта, длины вывода, параллелизма и загрузки GPU.
Сначала остановите базовый контейнер:
docker rm -f mistral-sglangЗатем запустите версию с EAGLE:
docker run -d \
--name mistral-sglang-eagle \
--gpus all \
--shm-size 64g \
--ipc=host \
--cap-add SYS_NICE \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e HF_TOKEN="$HF_TOKEN" \
-e PYTORCH_ALLOC_CONF=expandable_segments:True \
lmsysorg/sglang:dev-mistral-medium-3.5 \
sglang serve \
--model-path mistralai/Mistral-Medium-3.5-128B \
--served-model-name mistral-medium-3.5-eagle \
--host 0.0.0.0 \
--port 30000 \
--tp 4 \
--trust-remote-code \
--dtype bfloat16 \
--context-length 100000 \
--mem-fraction-static 0.85 \
--disable-custom-all-reduce \
--tool-call-parser mistral \
--reasoning-parser mistral \
--enable-metrics \
--speculative-algorithm EAGLE \
--speculative-draft-model-path mistralai/Mistral-Medium-3.5-128B-EAGLE \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4SGLang рекомендует такую стартовую конфигурацию EAGLE: --speculative-num-steps 3, --speculative-eagle-topk 1 и --speculative-num-draft-tokens 4. Первый запуск может идти дольше, потому что также загружается черновая модель EAGLE.
После загрузки можно проверить использование GPU командой nvidia-smi; в моём запуске модель использовала около 44 ГБ на каждый H100.
Следите за логами:
docker logs -f mistral-sglang-eagle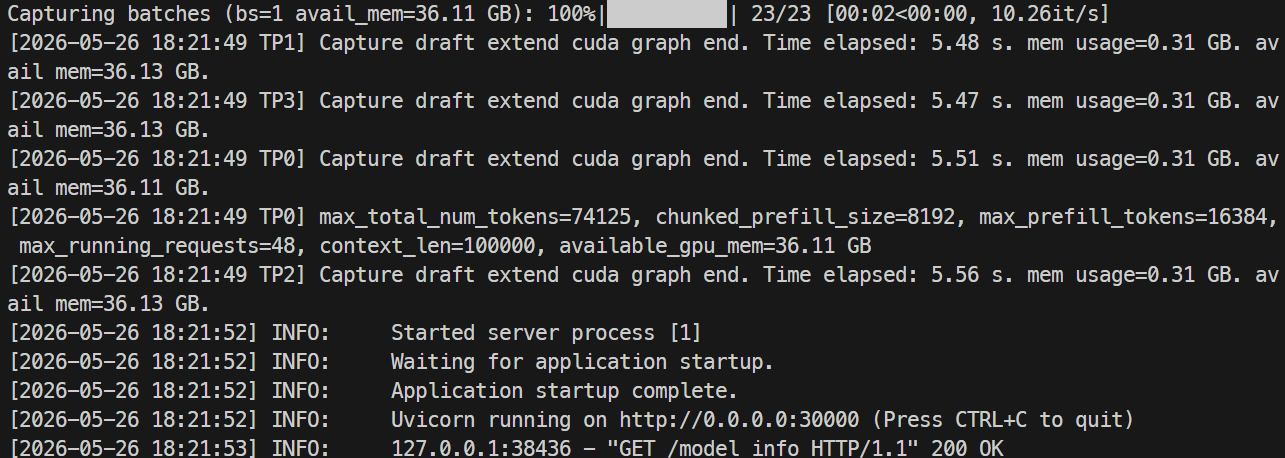
Когда в логах появится, что Uvicorn запущен на 0.0.0.0:30000, протестируйте конечную точку:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mistral-medium-3.5-eagle",
"messages": [
{
"role": "user",
"content": "Generate a simple Python game."
}
],
"reasoning_effort": "none",
"max_tokens": 300,
"temperature": 0.7,
"top_p": 0.95
}'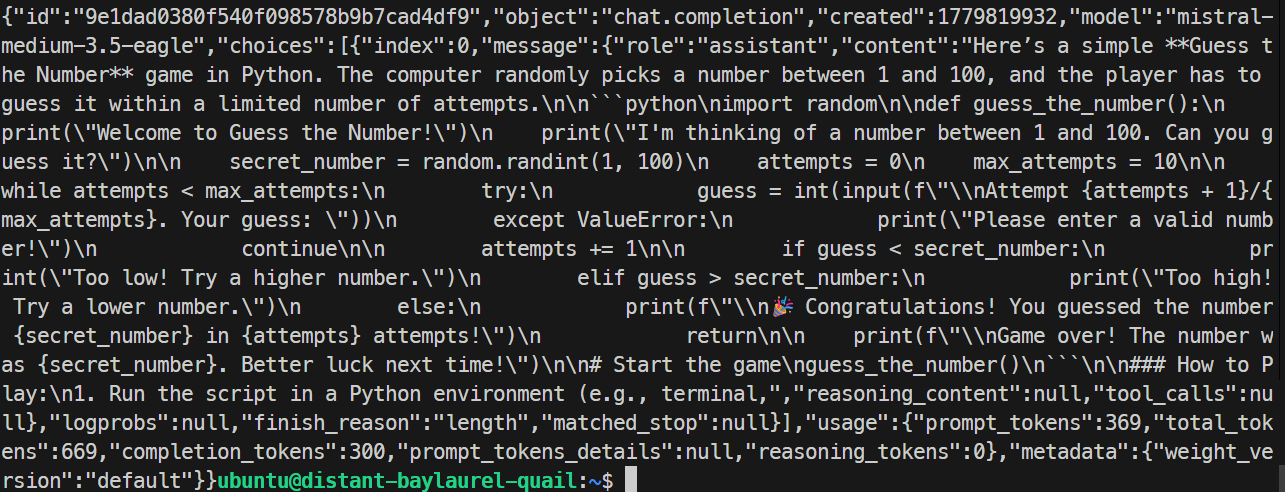
В моём тесте сервер EAGLE корректно ответил и сгенерировал простой Python‑game. Скорость составила около 32 токенов в секунду, что немного медленнее базового прогона, так что в этом конкретном тесте EAGLE ускорения не дал.
Это нормально: спекулятивный декод зависит от нагрузки, и лучший способ оценить его — тестировать на своих промптах и уровне параллелизма.
OpenCode — это открытый ИИ‑кодирующий агент, который может подключаться к конечным точкам моделей, совместимым с OpenAI. Поскольку SGLang предоставляет Mistral Medium 3.5 через локальный совместимый с OpenAI API, мы можем использовать её напрямую в OpenCode.
Установите OpenCode, если вы ещё не сделали этого:
curl -fsSL https://opencode.ai/install | bashЗатем перейдите в директорию проекта и создайте файл opencode.json.
Добавьте следующую конфигурацию:
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"sglang": {
"npm": "@ai-sdk/openai-compatible",
"name": "SGLang Local",
"options": {
"baseURL": "http://127.0.0.1:30000/v1",
"apiKey": "EMPTY"
},
"models": {
"mistral-medium-3.5-eagle": {
"name": "Mistral Medium 3.5 EAGLE",
"limit": {
"context": 100000,
"output": 8192
}
}
}
}
},
"model": "sglang/mistral-medium-3.5-eagle"
}Теперь запустите OpenCode из той же директории проекта:
OpencodeВы должны увидеть, что в OpenCode выбран Mistral Medium 3.5 EAGLE SGLang Local. Это значит, что OpenCode общается с вашим локальным сервером SGLang через проброшенный порт 30000 — так же, как если бы он вызывал любой совместимый с OpenAI API.
В моём тесте я попросил OpenCode объяснить проект: он прочитал файлы репозитория за несколько секунд и сгенерировал сводку.
Затем я попросил создать эмулятор Badger 2040: он сначала изучил существующие файлы проекта, проверил структуру и затем создал нужный Python‑файл. Весь процесс занял около 2 минут.
После этого я попросил протестировать эмулятор локально. OpenCode запустил код и успешно открыл окно эмулятора.
Шрифт был не совсем как на реальном дисплее Badger 2040, но расположение элементов, вывод времени, дата и общая структура были почти идеальными.

Честно говоря, результат меня удивил: я пробовал ту же задачу с Claude Code и GPT‑5.5, и у обоих были трудности, тогда как Mistral Medium 3.5 справилась очень хорошо в локальной конфигурации SGLang.
Есть несколько подводных камней. Кратко опишу возможные проблемы и способы их решения.
Прежде всего, запаситесь терпением. Вся настройка заняла у меня почти 3 часа. Запуск VM с GPU — около 15 минут, установка Docker и NVIDIA Container Toolkit — около 10 минут, загрузка Docker‑образа SGLang — около 30 минут, а скачивание и загрузка весов Mistral Medium 3.5 — около 1 часа.
Запуск настроек EAGLE также требует времени, потому что модель снова загружается и, возможно, скачивается черновая модель EAGLE. Для более плавного опыта используйте более быстрые сети, новые GPU, такие как H200 (если доступны), и достаточно места для полного кэша Hugging Face.
Если nvidia-smi работает на хосте, но Docker не получает доступ к GPU, вероятно, неправильно настроена среда выполнения NVIDIA. Повторно выполните настройку NVIDIA Container Toolkit и перезапустите Docker:
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart dockerДокументация NVIDIA также рекомендует этот шаг конфигурации рантайма nvidia-ctk для доступа Docker к GPU.
Убедитесь, что кэш Hugging Face смонтирован в контейнер:
-v ~/.cache/huggingface:/root/.cache/huggingfaceЭто позволит Docker переиспользовать уже скачанные файлы модели, а не загружать их каждый раз заново. Hugging Face использует локальный кэш, чтобы избегать повторных загрузок актуальных файлов.
Репозиторий Mistral Medium 3.5 большой, поэтому первая загрузка может занять много времени. Если кажется, что процесс завис, проверьте скорость интернета, место на диске и токен Hugging Face. Также убедитесь, что вы приняли необходимые условия доступа к модели на Hugging Face перед запуском контейнера.
Сервер не готов, пока в логах не появится, что Uvicorn запущен на порту 30000. Проверьте логи:
docker logs -f mistral-sglangили для EAGLE:
docker logs -f mistral-sglang-eagleТакже убедитесь, что порт проброшен правильно:
-p 30000:30000Это нормально. Спекулятивное декодирование не гарантирует ускорение для каждого запроса. Оно работает так: черновая модель предлагает токены, а основная их проверяет. Но ускорение зависит от доли принятия, длины промпта, длины вывода, параллелизма и загрузки GPU.
Если сталкиваетесь с нехваткой памяти, сначала уменьшите длину контекста. Например, начните с --context-length 100000 вместо попытки использовать сразу полное окно. Можно также слегка уменьшить --mem-fraction-static, если запуск не удаётся, но чаще всего проще всего сократить контекст.
Убедитесь, что сервер SGLang запущен, а в opencode.json указан правильный локальный эндпоинт:
"baseURL": "http://127.0.0.1:30000/v1"Если вы обращаетесь к серверу со своей локальной машины, запустите SSH с пробросом порта:
ssh -L 30000:localhost:30000 ubuntu@XXXXXXЗатем запустите OpenCode из той же директории, где сохранён ваш файл opencode.json.
Честно говоря, меня поразила гладкость технической части. Запуск Mistral Medium 3.5 128B с использованием нативного Docker‑образа SGLang оказался куда проще, чем я ожидал. Образ загрузился, модель поднялась, совместимая с OpenAI конечная точка работала, а OpenCode подключился без особых проблем. Я
если вы будете повторять эти шаги, настоятельно рекомендую использовать Docker‑образ SGLang вместо установки всего через Python‑пакеты. При установке через Python легко запутать версии CUDA, PyTorch и прочих зависимостей. Docker держит всё чистым и изолированным.
Но главный вывод из эксперимента — стоимость. Честно, я не понимаю, как ИИ‑компании зарабатывают на инференсе. Даже с одним из более дешёвых и старых вариантов H100 PCIe эта конфигурация обходилась примерно в $10 в час. И это всего лишь модель 128B на 4 GPU. А теперь представьте гораздо большую модель на триллион параметров на 16 × H100. Счёт легко достигнет $40+ в час — и это без учёта хранилища, сетей, мониторинга, доступности и инженерных работ.
Для небольших компаний, на мой взгляд, не имеет смысла обслуживать такие модели локально без очень веской причины — приватности, исследований или глубокого контроля над стеком инференса. Стоимость инференса уже высока, но есть и операционные сложности: нужно держать сервер в онлайне, следить, чтобы модель не падала, мониторить память GPU, обрабатывать упавшие контейнеры и поддерживать доступность конечной точки.
Serverless тоже не решает задачу для очень больших моделей. Холодный старт слишком долгий. В этой настройке запуск VM с GPU, установка зависимостей, загрузка образа Docker, скачивание весов и загрузка модели заняли почти 3 часа.
Даже если ваша среда быстрее, загрузка модели такого размера всё равно может занять много времени. Поэтому если каждый новый запрос требует запуска ещё одного GPU‑кластера и повторной загрузки модели, это сводит на нет смысл serverless. На практике компаниям приходится держать «тёплые» GPU‑кластеры, то есть платить даже при простое GPU.
Этим же объясняется наличие цен на GPU вне пиковых часов. Провайдерам важно загружать простаивающие GPU, потому что неиспользуемые GPU — это чистые расходы. Для пользователей это может быть способом экспериментировать дешевле, но одновременно показывает, насколько сложна экономика инференса больших моделей.
В целом, SGLang мне очень понравился для этой задачи. Docker‑ориентированный рабочий процесс сделал сервинг Mistral Medium 3.5 128B гораздо проще ожидаемого, а тест с OpenCode действительно впечатлил. Но этот эксперимент также наглядно показал: запускать большие открытые модели локально — возможно, а вот делать это надёжно и экономично как реальный продукт — совершенно иная задача.
Изучайте ИИ с DataCamp!
Track
Course
Course