
Leerpad
Associate AI Engineer voor ontwikkelaars
26 Hr
Voor deze gids gebruikte ik een 4× H100 80GB GPU-virtuele machine. Mistral Medium 3.5 is een dense 128B-model, dus het heeft een multi-GPU-setup nodig. SGLang raadt aan om het met tensorparallellisme te draaien met --tp 4 op H100- of H200-GPU’s. Het model ondersteunt een groot contextvenster, maar ik raad aan om eerst te beginnen met 100.000 tokens in plaats van de volledige 256K-context om de setup makkelijker te testen en te debuggen.
Ik gebruikte Hyperbolic omdat je daarmee toegang krijgt tot een volledige GPU-VM, wat het makkelijker maakt om Docker te installeren, de NVIDIA-container-runtime te configureren en de SGLang Docker-image handmatig te draaien. Je kunt ook platforms zoals RunPod of Vast.ai gebruiken, maar sommige van hun instanties zijn al gekoppeld aan aangepaste Docker-omgevingen, waardoor je minder controle hebt.
Selecteer in Hyperbolic H100 PCIe 80GB, kies 4 GPU’s, voeg ongeveer 3TB opslag toe, voer je SSH-public key in en geef de instantie een naam zoals MM-35. Ik koos voor H100 PCIe omdat dat voor deze test de goedkoopste beschikbare H100-optie was.
Na te klikken op Start Building kan het ongeveer 10 minuten duren voordat de machine start. Zodra deze klaar is, toont Hyperbolic het SSH-toegangcommando dat je voor de volgende stap nodig hebt.
Zodra de instantie klaar is, maak je vanaf je lokale terminal verbinding met het SSH-commando dat in het Hyperbolic-dashboard wordt weergegeven:
ssh ubuntu@XXXXXXOm later vanaf je lokale machine toegang te krijgen tot de SGLang API, kun je ook poort 30000 forwarden:
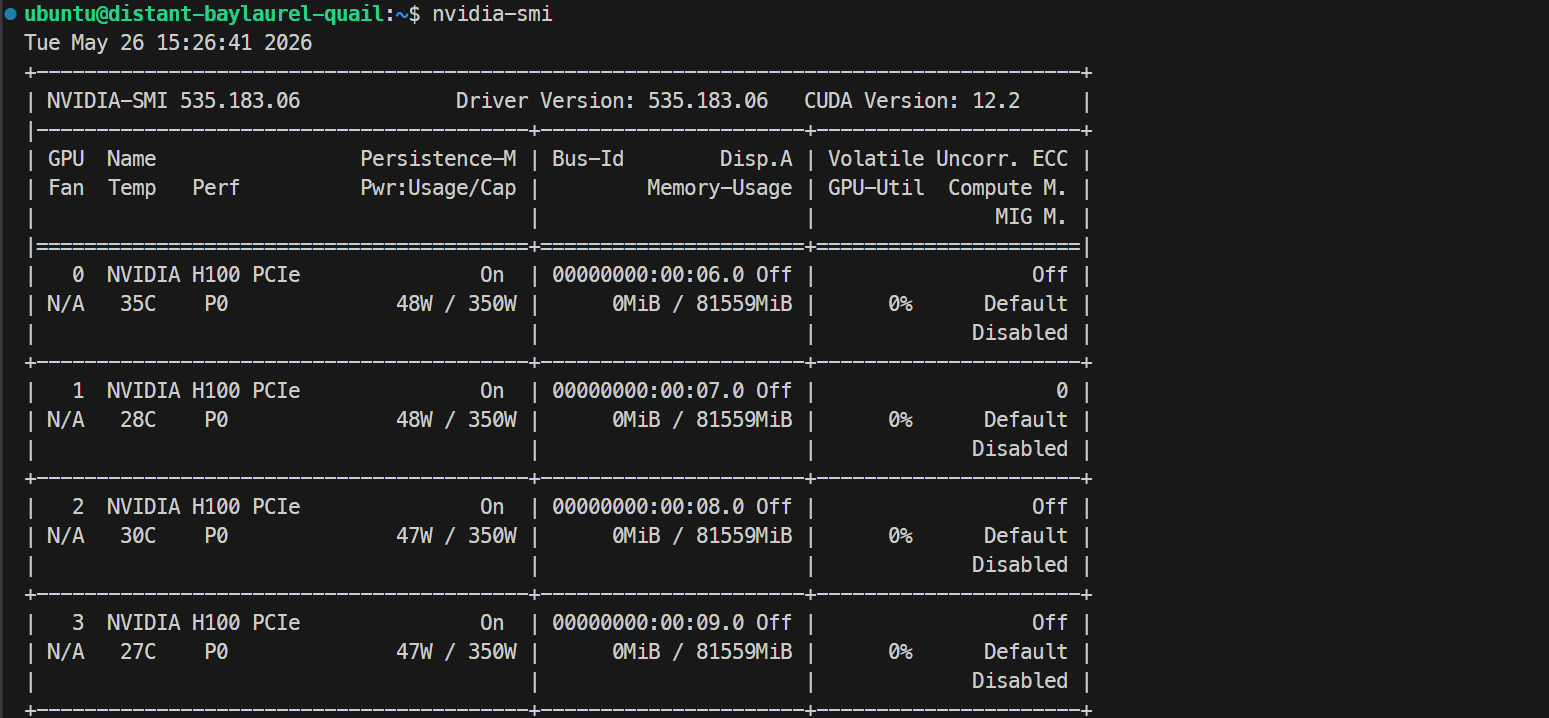
ssh -L 30000:localhost:30000 ubuntu@XXXXXXAls je SSH-sleutel een wachtzin heeft, voer die dan in wanneer daarom wordt gevraagd. Controleer na het inloggen of alle GPU’s beschikbaar zijn:
Nvidia-smiJe zou 4× NVIDIA H100 PCIe 80GB GPU’s moeten zien. Dit bevestigt dat de server klaar is voor de Docker- en SGLang-setup.
Exporteer eerst je Hugging Face-token zodat de server later het Mistral-model kan downloaden:
echo 'export HF_TOKEN="your_huggingface_token_here"' >> ~/.bashrc
source ~/.bashrcOpmerking: je kunt je Hugging Face-token krijgen op de pagina Access Tokens.
Maak de cachemap van Hugging Face aan:
mkdir -p ~/.cache/huggingfaceInstalleer nu Docker:
sudo apt update
sudo apt install -y docker.ioStart Docker en zorg dat het automatisch start na een reboot:
sudo systemctl start docker
sudo systemctl enable dockerControleer of Docker correct is geïnstalleerd:
docker –versionJe kunt ook de Docker-zoekopdracht gebruiken om te bevestigen dat Docker naar publieke images van Docker Hub kan zoeken:
docker search nvidia/cudaDit zou beschikbare NVIDIA CUDA-images moeten retourneren. Later gebruiken we een van deze CUDA-images om te verifiëren dat Docker toegang heeft tot de GPU’s.
Sta vervolgens toe dat je gebruiker Docker-commando’s kan draaien zonder sudo:
sudo usermod -aG docker $USER
newgrp dockerInstalleer en configureer nu de NVIDIA Container Toolkit zodat Docker toegang heeft tot de GPU’s:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/libnvidia-container/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt update
sudo apt install -y nvidia-container-toolkit
sudo nvidia-ctk runtime configure --runtime=docker
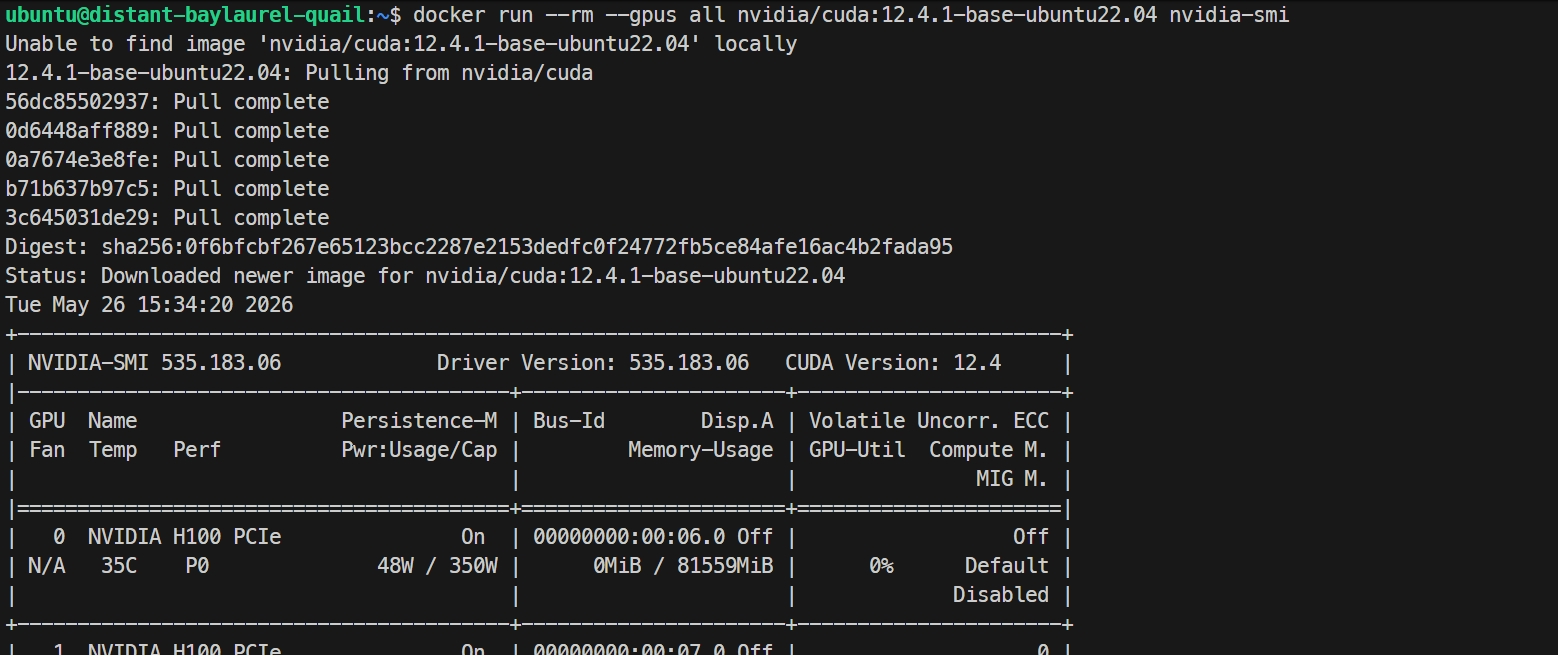
sudo systemctl restart dockerTest tot slot of Docker de GPU’s vanuit een container kan zien:
docker run --rm --gpus all nvidia/cuda:12.4.1-base-ubuntu22.04 nvidia-smiAls dit dezelfde H100-lijst binnen de Docker-container toont, werkt je GPU-Docker-setup correct.
Trek vervolgens de SGLang Docker-image die is gebouwd voor Mistral Medium 3.5:
docker pull lmsysorg/sglang:dev-mistral-medium-3.5
Dit kan even duren, afhankelijk van je internetsnelheid. Bij mij duurde het ongeveer 10 minuten. Zodra de image is gedownload, toont Docker een succesbericht zoals:
Status: Downloaded newer image for lmsysorg/sglang:dev-mistral-medium-3.5Start nu de SGLang-server:
docker run -d \
--name mistral-sglang \
--gpus all \
--shm-size 64g \
--ipc=host \
--cap-add SYS_NICE \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e HF_TOKEN=$HF_TOKEN \
-e PYTORCH_ALLOC_CONF=expandable_segments:True \
lmsysorg/sglang:dev-mistral-medium-3.5 \
sglang serve \
--model-path mistralai/Mistral-Medium-3.5-128B \
--served-model-name mistral-medium-3.5 \
--host 0.0.0.0 \
--port 30000 \
--tp 4 \
--trust-remote-code \
--dtype bfloat16 \
--context-length 100000 \
--mem-fraction-static 0.85 \
--disable-custom-all-reduce \
--tool-call-parser mistral \
--reasoning-parser mistralIk gebruikte --dtype bfloat16 omdat de latere EAGLE-setup ook bf16 vereist, dus door de basisrun en de speculative-run gelijk te houden, voorkom je dat je de dtype tussen tests hoeft te wijzigen. Ik begon ook met --context-length 100000 in plaats van het volledige contextvenster om de eerste run makkelijker te debuggen.
Bekijk de containerlogs met:
docker logs -f mistral-sglang
De eerste start duurt langer omdat SGLang de modelfiles van Hugging Face moet downloaden. De volledige repository is groot, dus dit kan ongeveer een uur of langer duren, afhankelijk van de snelheid van je instantie.
Wanneer de server klaar is, zouden de logs moeten tonen dat Uvicorn draait op poort 30000.
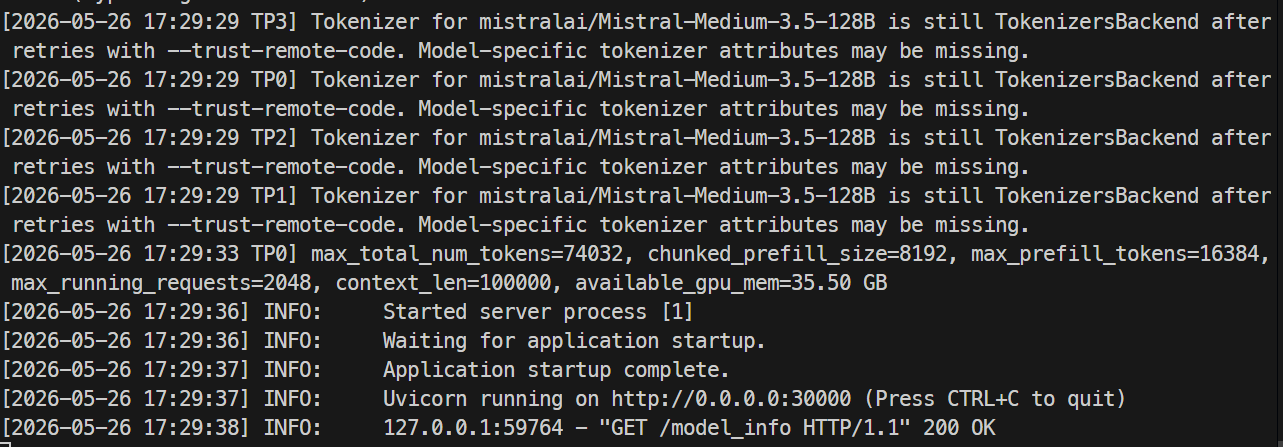
Open in een andere terminal opnieuw een SSH-sessie naar de server en controleer het model-endpoint:
curl http://localhost:30000/v1/modelsJe zou mistral-medium-3.5 moeten zien met een max_model_len van 100000.
{"object":"list","data":[{"id":"mistral-medium-3.5","object":"model","created":1779816738,"owned_by":"sglang","root":"mistral-medium-3.5","parent":null,"max_model_len":100000}]}Test tot slot een chat completion:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mistral-medium-3.5",
"messages": [
{
"role": "user",
"content": "Write a short introduction to Mistral Medium 3.5."
}
],
"max_tokens": 300,
"temperature": 0.7,
"top_p": 0.95
}'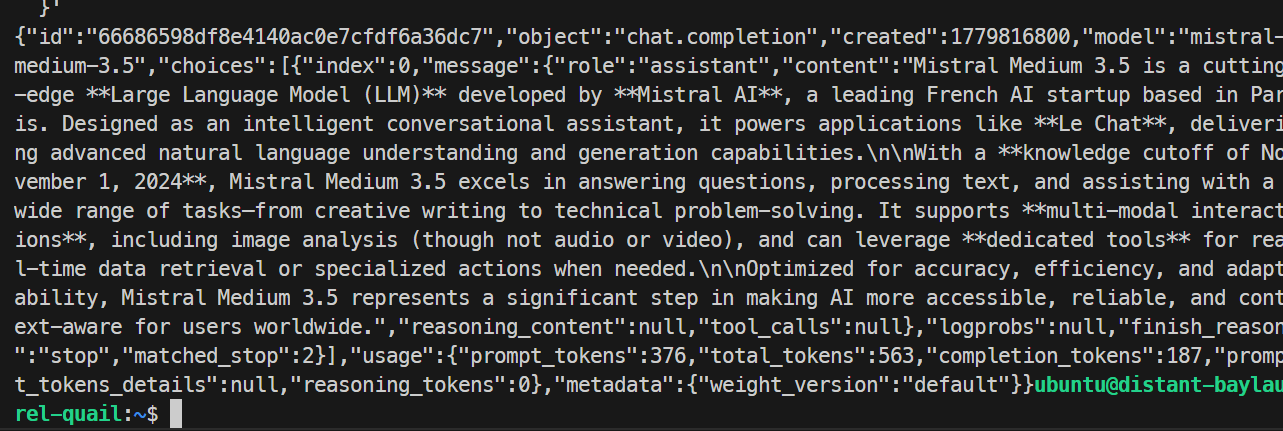
In mijn test reageerde het model succesvol en werd het verzoek netjes afgehandeld, wat bevestigde dat het SGLang-endpoint werkte. De basisrun genereerde ongeveer 35,6 tokens per seconde.
Speculative decoding kan de generatie versnellen door een kleiner draftmodel te gebruiken om tokens vooruit te voorspellen, terwijl het hoofdmodel ze verifieert.
EAGLE is hier nuttig omdat het is ontworpen voor latency-gevoelige serving, vooral wanneer je lokaal een groot model zoals Mistral Medium 3.5 draait. Het is niet altijd sneller, maar het is het testen waard omdat het voordeel afhangt van de promptlengte, outputlengte, concurrentie en GPU-gebruik.
Verwijder eerst de basiscontainer:
docker rm -f mistral-sglangStart daarna de EAGLE-versie:
docker run -d \
--name mistral-sglang-eagle \
--gpus all \
--shm-size 64g \
--ipc=host \
--cap-add SYS_NICE \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e HF_TOKEN="$HF_TOKEN" \
-e PYTORCH_ALLOC_CONF=expandable_segments:True \
lmsysorg/sglang:dev-mistral-medium-3.5 \
sglang serve \
--model-path mistralai/Mistral-Medium-3.5-128B \
--served-model-name mistral-medium-3.5-eagle \
--host 0.0.0.0 \
--port 30000 \
--tp 4 \
--trust-remote-code \
--dtype bfloat16 \
--context-length 100000 \
--mem-fraction-static 0.85 \
--disable-custom-all-reduce \
--tool-call-parser mistral \
--reasoning-parser mistral \
--enable-metrics \
--speculative-algorithm EAGLE \
--speculative-draft-model-path mistralai/Mistral-Medium-3.5-128B-EAGLE \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4SGLang raadt deze EAGLE-setup aan als goed startpunt: --speculative-num-steps 3, --speculative-eagle-topk 1 en --speculative-num-draft-tokens 4. De eerste run kan langer duren omdat ook het EAGLE-draftmodel wordt gedownload.
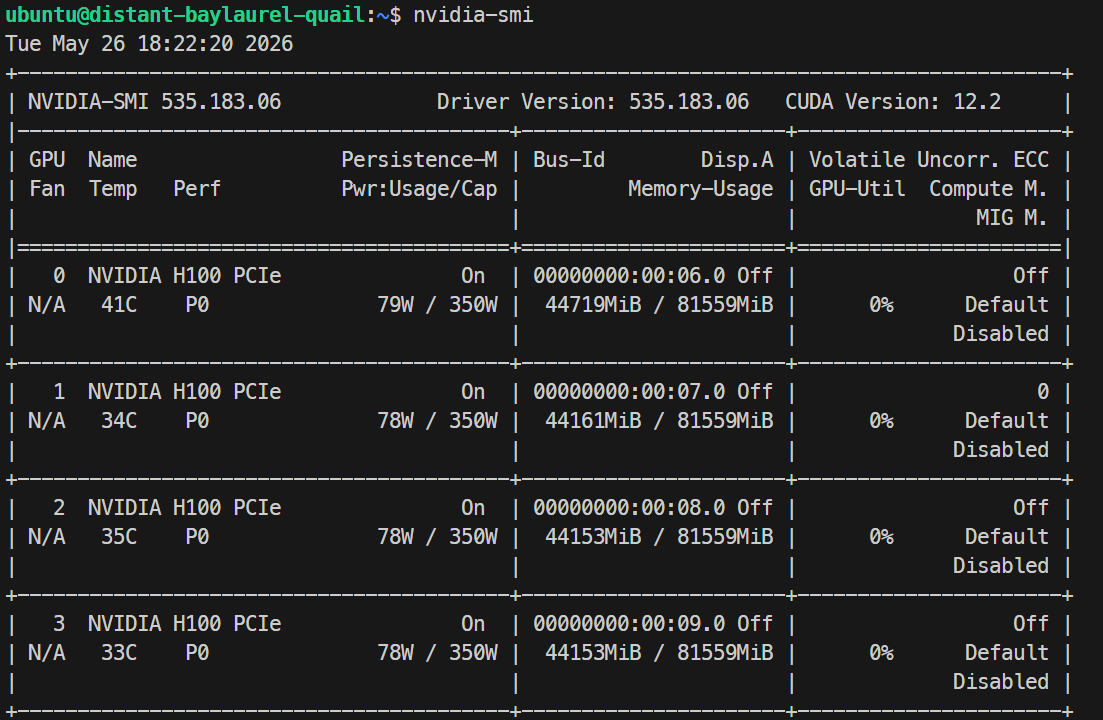
Zodra alles geladen is, kun je het GPU-gebruik controleren met nvidia-smi; in mijn run gebruikte het model ongeveer 44GB per H100-GPU.
Volg de logs met:
docker logs -f mistral-sglang-eagle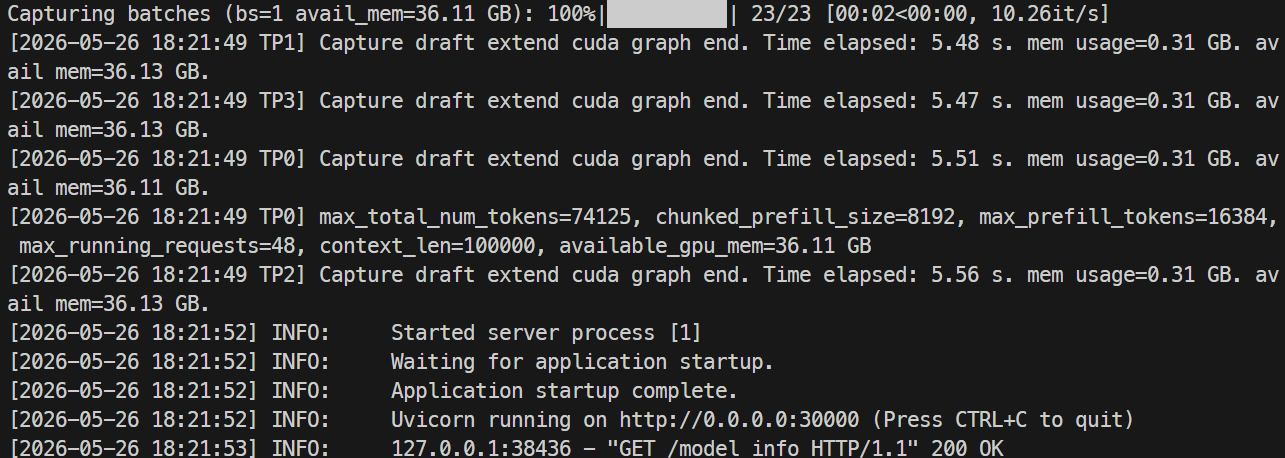
Wanneer de logs tonen dat Uvicorn draait op 0.0.0.0:30000, test dan het endpoint:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mistral-medium-3.5-eagle",
"messages": [
{
"role": "user",
"content": "Generate a simple Python game."
}
],
"reasoning_effort": "none",
"max_tokens": 300,
"temperature": 0.7,
"top_p": 0.95
}'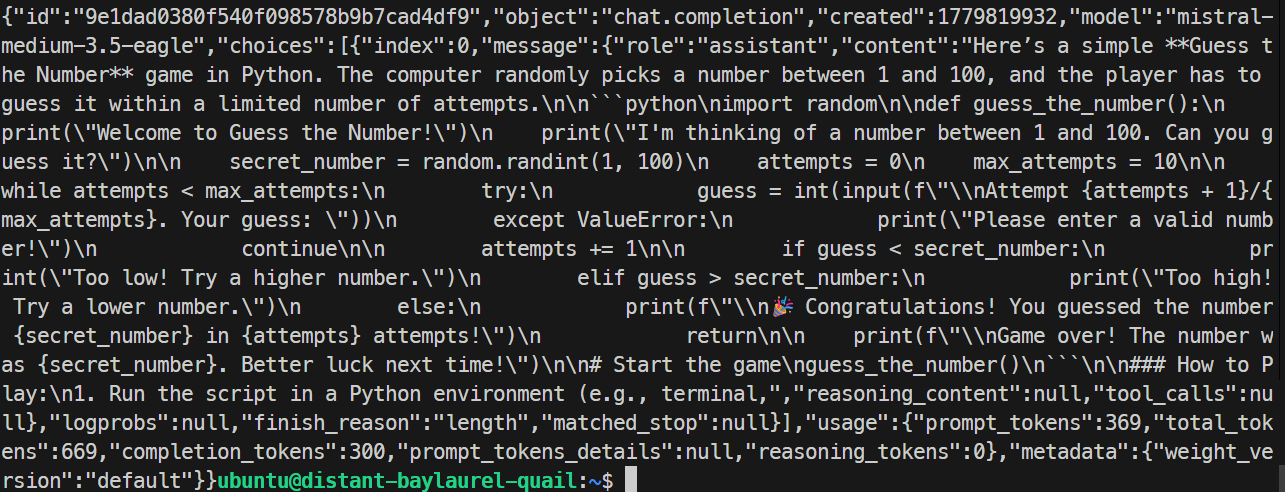
In mijn test reageerde de EAGLE-server correct en genereerde een eenvoudig Python-spel. De run haalde ongeveer 32 tokens per seconde, wat iets langzamer was dan de basisrun, dus EAGLE verbeterde deze specifieke test niet.
Dit is normaal: speculative decoding hangt sterk af van de workload, en de beste manier om dit te beoordelen is om het te testen met je eigen prompts en mate van gelijktijdigheid.
OpenCode is een open-source AI-codingagent die kan verbinden met OpenAI-compatibele modelendpoints. Omdat SGLang Mistral Medium 3.5 via een lokale OpenAI-compatibele API aanbiedt, kunnen we het direct in OpenCode gebruiken.
Installeer OpenCode als je dat nog niet hebt gedaan:
curl -fsSL https://opencode.ai/install | bashGa daarna naar je projectmap en maak een opencode.json-bestand aan.
Voeg de volgende configuratie toe:
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"sglang": {
"npm": "@ai-sdk/openai-compatible",
"name": "SGLang Local",
"options": {
"baseURL": "http://127.0.0.1:30000/v1",
"apiKey": "EMPTY"
},
"models": {
"mistral-medium-3.5-eagle": {
"name": "Mistral Medium 3.5 EAGLE",
"limit": {
"context": 100000,
"output": 8192
}
}
}
}
},
"model": "sglang/mistral-medium-3.5-eagle"
}Start nu OpenCode vanuit dezelfde projectmap:
OpencodeJe zou Mistral Medium 3.5 EAGLE SGLang Local geselecteerd moeten zien in OpenCode. Dit betekent dat OpenCode nu met je lokale SGLang-server praat via de geforwarde 30000-poort, net zoals het elke OpenAI-compatibele API zou aanroepen.
In mijn test vroeg ik OpenCode om het project uit te leggen, en het las de repository-bestanden binnen enkele seconden en genereerde de samenvatting.
Daarna vroeg ik om een Badger 2040-emulator te maken, en het inspecteerde eerst de bestaande projectbestanden, valideerde de structuur en maakte vervolgens het vereiste Python-bestand aan. Het hele proces duurde ongeveer 2 minuten.
Daarna vroeg ik om de emulator lokaal te testen. OpenCode draaide de code en opende het emulatorvenster succesvol.
Het lettertype was niet exact hetzelfde als het echte Badger 2040-display, maar de lay-out, tijdweergave, datumplaatsing en algehele structuur waren bijna perfect.

Ik was oprecht verrast door het resultaat, omdat ik dezelfde taak eerder met Claude Code en GPT-5.5 had geprobeerd en beide hiermee worstelden, terwijl Mistral Medium 3.5 het via de lokale SGLang-setup erg goed deed.
Er zijn een paar valkuilen onderweg. Ik neem je mee langs problemen die je kunt tegenkomen en hoe je ze oplost.
Allereerst: je zult geduld nodig hebben. Deze volledige setup kostte mij bijna 3 uur. Het starten van de GPU-VM duurde ongeveer 15 minuten, het installeren van Docker en de NVIDIA-container-toolkit ongeveer 10 minuten, het pullen van de SGLang Docker-image ongeveer 30 minuten en het downloaden plus laden van de Mistral Medium 3.5-modelgewichten ongeveer 1 uur.
Het starten van de EAGLE-setup kost ook extra tijd omdat het model opnieuw wordt geladen en het EAGLE-draftmodel mogelijk wordt gedownload. Wil je een soepelere ervaring, gebruik dan snellere netwerken, nieuwere GPU’s zoals H200’s indien beschikbaar, en voldoende opslag voor de volledige Hugging Face-cache.
Als nvidia-smi op de host werkt maar Docker geen toegang heeft tot de GPU’s, is de NVIDIA-container-runtime waarschijnlijk niet correct geconfigureerd. Voer de configuratie van de NVIDIA-container-toolkit opnieuw uit en herstart Docker:
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart dockerDe documentatie van NVIDIA raadt deze nvidia-ctk runtimeconfiguratiestap ook aan voor Docker GPU-toegang.
Zorg dat de Hugging Face-cache in de container wordt gemount:
-v ~/.cache/huggingface:/root/.cache/huggingfaceHierdoor kan Docker gedownloade modelfiles hergebruiken in plaats van ze elke keer opnieuw te downloaden. Hugging Face gebruikt een lokale cache om te voorkomen dat bestanden die al up-to-date zijn opnieuw worden gedownload.
De Mistral Medium 3.5-repository is groot, dus de eerste download kan lang duren. Als het vast lijkt te zitten, controleer je internetsnelheid, schijfruimte en Hugging Face-token. Zorg er ook voor dat je eventuele vereiste modeltoegangvoorwaarden op Hugging Face hebt geaccepteerd voordat je de container draait.
De server is pas klaar wanneer de logs tonen dat Uvicorn draait op poort 30000. Bekijk de logs met:
docker logs -f mistral-sglangof voor EAGLE:
docker logs -f mistral-sglang-eagleZorg er ook voor dat de container de poort correct exposeert met:
-p 30000:30000Dat is normaal. Speculative decoding garandeert niet dat elke request sneller wordt. Het werkt door een draftmodel tokens te laten voorstellen en het hoofdmodel ze te laten verifiëren, maar de snelheidswinst hangt af van acceptatiegraad, promptlengte, outputlengte, gelijktijdigheid en GPU-belasting.
Als je geheugenproblemen tegenkomt, verlaag dan eerst de contextlengte. Begin bijvoorbeeld met --context-length 100000 in plaats van meteen het volledige contextvenster te proberen. Je kunt ook --mem-fraction-static iets verlagen als de start faalt, maar de contextlengte verminderen is meestal de makkelijkste eerste stap.
Zorg dat de SGLang-server draait en dat je opencode.json het juiste lokale endpoint gebruikt:
"baseURL": "http://127.0.0.1:30000/v1"Als je vanaf je lokale machine toegang krijgt tot de server, start SSH dan met port forwarding:
ssh -L 30000:localhost:30000 ubuntu@XXXXXXStart vervolgens OpenCode vanuit dezelfde map waar je opencode.json-bestand is opgeslagen.
Ik was eerlijk gezegd verrast hoe soepel de technische setup verliep. Mistral Medium 3.5 128B draaien met de native SGLang Docker-image was veel eenvoudiger dan ik had verwacht. De Docker-image werd correct gepulld, het model werd geladen, het OpenAI-compatibele endpoint werkte en OpenCode maakte zonder veel gedoe verbinding. I
f je dit zelf probeert, zou ik sterk aanraden om de SGLang Docker-image te gebruiken in plaats van alles via Python-packages te installeren. Als je via Python installeert, kan het al snel rommelen met CUDA, PyTorch en andere dependencies. Docker houdt alles schoon en geïsoleerd.
Maar de grootste les uit dit experiment is de kostenkant. Ik weet eerlijk gezegd niet hoe AI-bedrijven geld verdienen aan inferentie. Zelfs met een van de goedkopere en oudere H100 PCIe-opties kwam deze setup nog steeds in de buurt van $10 per uur. En dit is slechts voor een 128B-model op 4 GPU’s. Stel je voor dat je een veel groter model met triljoenen parameters draait op 16× H100’s. Je rekening kan gemakkelijk $40+ per uur bereiken, nog los van opslag, netwerk, monitoring, uptime en engineeringwerk.
Voor kleine bedrijven lijkt het me niet logisch om dit soort modellen lokaal te serven, tenzij er een heel sterke reden is, zoals privacy, onderzoek of diepe controle over de inferentiestack. De inferentiekosten zijn al hoog, maar de operationele last is ook een probleem. Je moet de server draaiende houden, zorgen dat het model niet crasht, het GPU-geheugen monitoren, mislukte containers afhandelen en het endpoint beschikbaar houden.
Serverless lost dit ook niet echt op voor zeer grote modellen. De cold start is gewoon te lang. In deze setup kostte het starten van de GPU-VM, het installeren van dependencies, het pullen van de Docker-image, het downloaden van de gewichten en het laden van het model in totaal bijna 3 uur in totaal.
Zelfs als jouw setup sneller is, kan het laden van een model van dit formaat nog steeds lang duren. Dus als elke nieuwe request een nieuw GPU-cluster moet starten en het model opnieuw moet laden, gaat het doel van serverless verloren. In de praktijk moeten bedrijven warme GPU-clusters draaiende houden, wat betekent dat ze ook betalen wanneer de GPU’s niets doen.
Dit verklaart ook waarom er off-peak GPU-prijzen bestaan. Providers willen dat mensen onbenutte GPU-capaciteit gebruiken, want ongebruikte GPU’s kosten gewoon geld. Voor gebruikers kan dat een goede manier zijn om goedkoper te experimenteren, maar het laat ook zien hoe lastig de economie van inferentie met grote modellen is.
Al met al vond ik SGLang erg prettig voor deze setup. De Docker-gebaseerde workflow maakte het serven van Mistral Medium 3.5 128B veel eenvoudiger dan verwacht, en de OpenCode-test was oprecht indrukwekkend. Maar dit experiment maakte me ook één ding heel duidelijk: grote open modellen lokaal draaien is mogelijk, maar ze betrouwbaar en betaalbaar als echt product draaien is een totaal andere uitdaging.
Leer AI met DataCamp!
Leerpad
Cursus
Cursus
blog
Adel Nehme
15 min
