Track
डेवलपर्स के लिए एसोसिएट AI इंजीनियर
26 घंटा
इस गाइड के लिए, मैंने 4× H100 80GB GPU वर्चुअल मशीन का उपयोग किया। Mistral Medium 3.5 एक डेंस 128B मॉडल है, इसलिए इसे मल्टी‑GPU सेटअप चाहिए। SGLang सलाह देता है कि H100 या H200 GPUs पर --tp 4 के साथ टेंसर पैरेललिज़्म का उपयोग करें। मॉडल बड़ा कॉन्टेक्स्ट विंडो सपोर्ट करता है, लेकिन मैं शुरू करने के लिए पहले 100,000 टोकन रखने की सलाह दूँगा/दूँगी, ताकि फुल 256K कॉन्टेक्स्ट की जगह सेटअप को टेस्ट और डिबग करना आसान रहे।
मैंने Hyperbolic का उपयोग किया क्योंकि यह फुल GPU VM देता है, जिससे Docker इंस्टॉल करना, NVIDIA कंटेनर रनटाइम कॉन्फ़िगर करना, और SGLang Docker इमेज को मैन्युअली चलाना आसान हो जाता है। आप RunPod या Vast.ai जैसे प्लेटफ़ॉर्म भी इस्तेमाल कर सकते हैं, लेकिन उनके कुछ इंस्टेंसेज़ पहले से कस्टम Docker वातावरण से बंधे होते हैं, जिससे आपका नियंत्रण कम हो जाता है।
Hyperbolic में, H100 PCIe 80GB चुनें, 4 GPUs सेलेक्ट करें, लगभग 3TB स्टोरेज जोड़ें, अपना SSH पब्लिक की दर्ज करें, और इंस्टेंस को MM-35 जैसा कोई नाम दें। मैंने H100 PCIe इसलिए चुना क्योंकि यह इस टेस्ट के लिए उपलब्ध H100 विकल्पों में सबसे सस्ता था।
Start Building पर क्लिक करने के बाद, मशीन को शुरू होने में लगभग 10 मिनट लग सकते हैं। तैयार होने पर, Hyperbolic आपको अगले चरण के लिए आवश्यक SSH एक्सेस कमांड दिखाएगा।
इंस्टेंस तैयार होने के बाद, Hyperbolic डैशबोर्ड पर दिखाए गए SSH कमांड का उपयोग करके अपने लोकल टर्मिनल से कनेक्ट करें:
ssh ubuntu@XXXXXXबाद में अपनी लोकल मशीन से SGLang API एक्सेस करने के लिए, आप पोर्ट 30000 को फ़ॉरवर्ड भी कर सकते हैं:
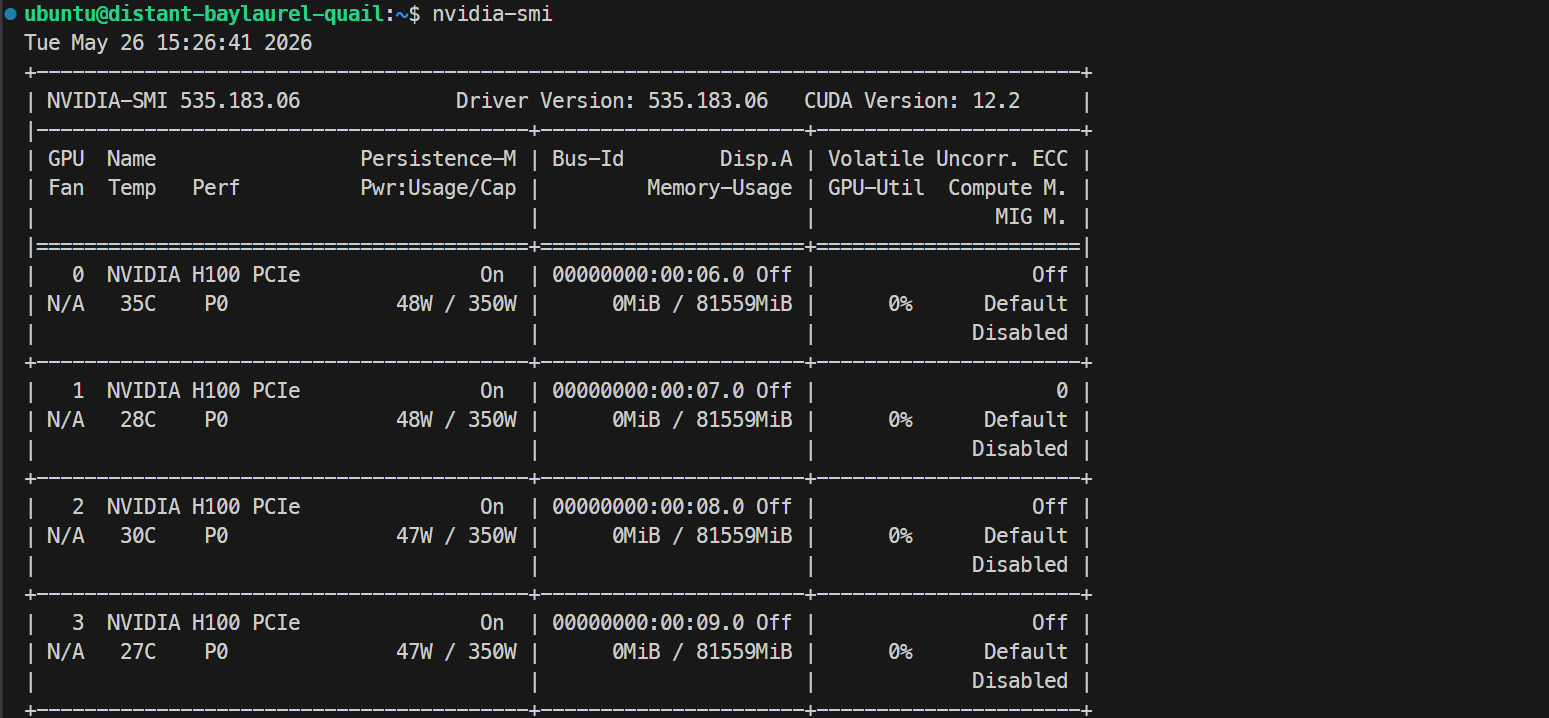
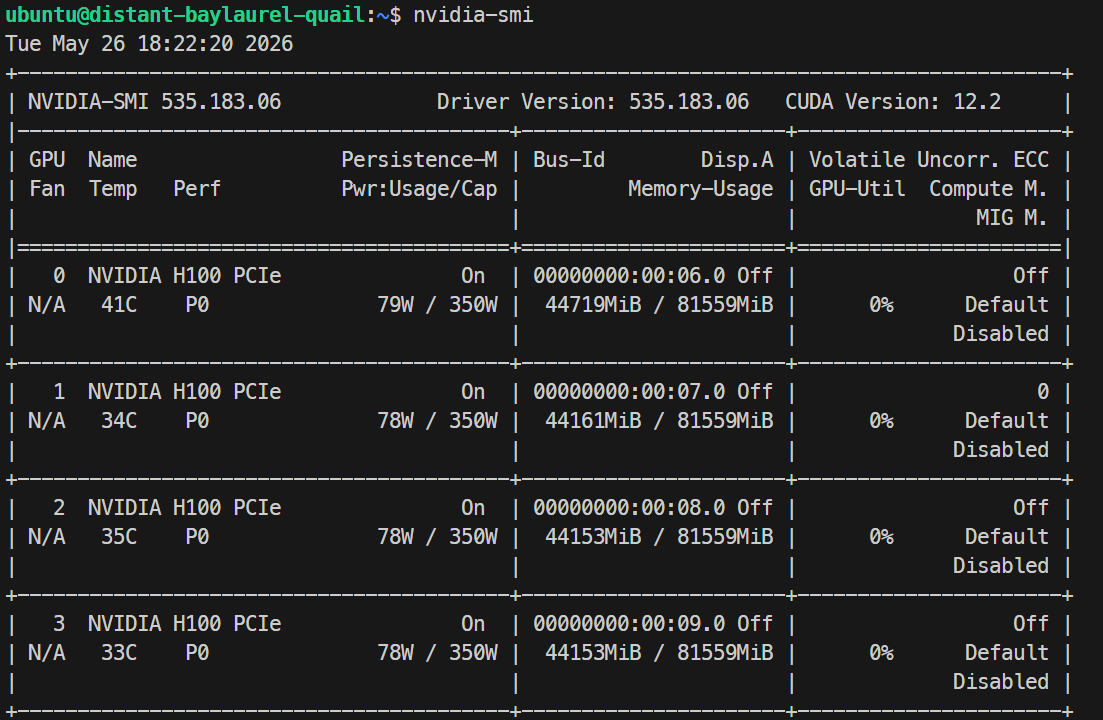
ssh -L 30000:localhost:30000 ubuntu@XXXXXXयदि आपकी SSH की पर पासफ़्रेज़ है, तो संकेत मिलने पर दर्ज करें। लॉगिन के बाद, जाँचें कि सभी GPUs उपलब्ध हैं:
Nvidia-smiआपको 4× NVIDIA H100 PCIe 80GB GPUs लिस्टेड दिखने चाहिए। यह पुष्टि करता है कि सर्वर Docker और SGLang सेटअप के लिए तैयार है।
सबसे पहले, अपना Hugging Face टोकन एक्सपोर्ट करें ताकि सर्वर बाद में Mistral मॉडल डाउनलोड कर सके:
echo 'export HF_TOKEN="your_huggingface_token_here"' >> ~/.bashrc
source ~/.bashrcनोट: आप अपना Hugging Face टोकन Access Tokens पेज से ले सकते हैं।
Hugging Face कैश फ़ोल्डर बनाएं:
mkdir -p ~/.cache/huggingfaceअब Docker इंस्टॉल करें:
sudo apt update
sudo apt install -y docker.ioDocker शुरू करें और रीबूट के बाद ऑटोमैटिकली चलने के लिए सक्षम करें:
sudo systemctl start docker
sudo systemctl enable dockerजाँचें कि Docker सही से इंस्टॉल हुआ है:
docker –versionआप Docker Hub से पब्लिक इमेजेस सर्च करने के लिए Docker सर्च कमांड का उपयोग करके भी पुष्टि कर सकते हैं:
docker search nvidia/cudaइसमें उपलब्ध NVIDIA CUDA इमेजेस वापस आनी चाहिए। आगे चलकर, हम इन्हीं CUDA इमेजेस में से एक का उपयोग करके वेरिफ़ाई करेंगे कि Docker GPUs तक पहुँच सकता है।
अब अपने यूज़र को sudo के बिना Docker कमांड चलाने की अनुमति दें:
sudo usermod -aG docker $USER
newgrp dockerअब NVIDIA Container Toolkit इंस्टॉल और कॉन्फ़िगर करें ताकि Docker GPUs तक पहुँच सके:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/libnvidia-container/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt update
sudo apt install -y nvidia-container-toolkit
sudo nvidia-ctk runtime configure --runtime=docker
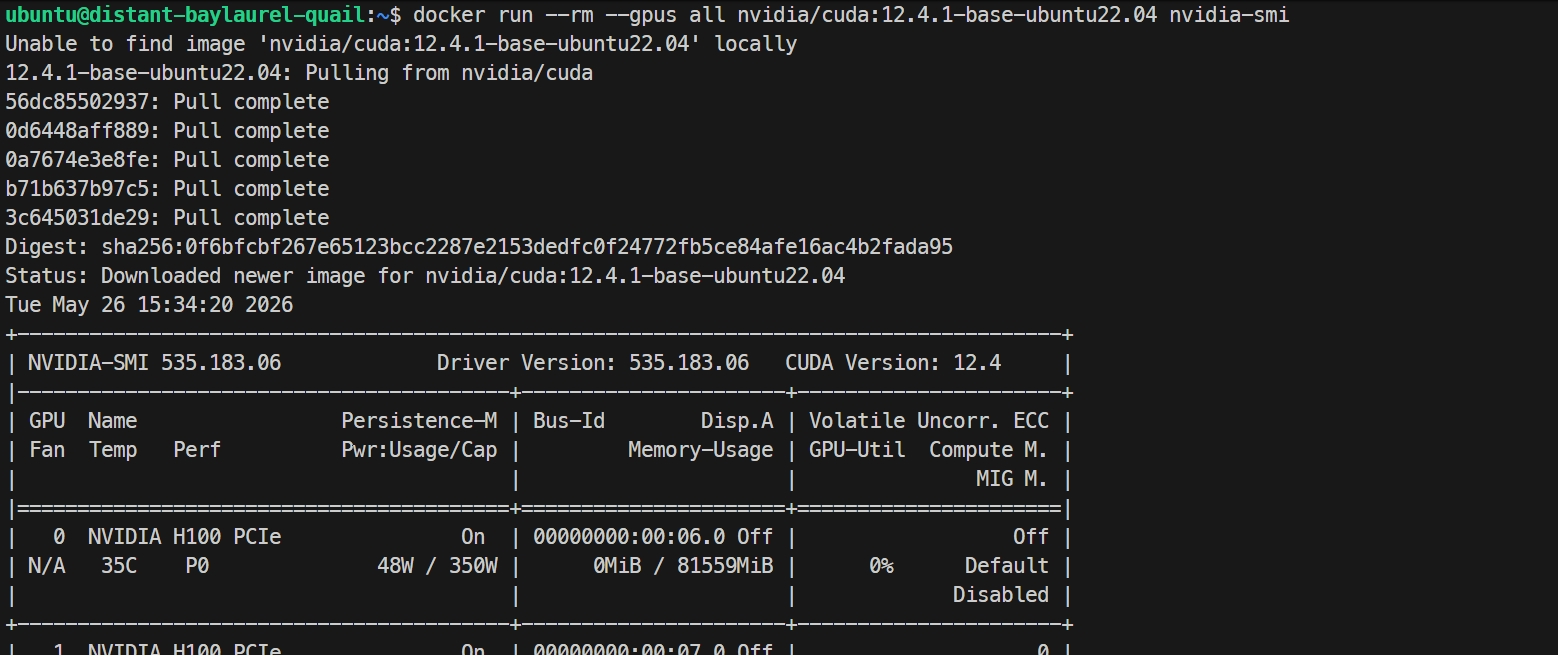
sudo systemctl restart dockerअंत में, टेस्ट करें कि Docker कंटेनर के अंदर से GPUs देख पा रहा है:
docker run --rm --gpus all nvidia/cuda:12.4.1-base-ubuntu22.04 nvidia-smiयदि कंटेनर के अंदर भी वही H100 GPU सूची प्रिंट होती है, तो आपका GPU Docker सेटअप सही से काम कर रहा है।
अब, Mistral Medium 3.5 के लिए बनी SGLang Docker इमेज पुल करें:
docker pull lmsysorg/sglang:dev-mistral-medium-3.5
यह आपके इंटरनेट स्पीड पर निर्भर करते हुए कुछ समय ले सकता है। मेरे मामले में, इसमें लगभग 10 मिनट लगे। इमेज डाउनलोड होने पर, Docker इस तरह का सफलता संदेश दिखाएगा:
Status: Downloaded newer image for lmsysorg/sglang:dev-mistral-medium-3.5अब SGLang सर्वर शुरू करें:
docker run -d \
--name mistral-sglang \
--gpus all \
--shm-size 64g \
--ipc=host \
--cap-add SYS_NICE \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e HF_TOKEN=$HF_TOKEN \
-e PYTORCH_ALLOC_CONF=expandable_segments:True \
lmsysorg/sglang:dev-mistral-medium-3.5 \
sglang serve \
--model-path mistralai/Mistral-Medium-3.5-128B \
--served-model-name mistral-medium-3.5 \
--host 0.0.0.0 \
--port 30000 \
--tp 4 \
--trust-remote-code \
--dtype bfloat16 \
--context-length 100000 \
--mem-fraction-static 0.85 \
--disable-custom-all-reduce \
--tool-call-parser mistral \
--reasoning-parser mistralमैंने --dtype bfloat16 का उपयोग किया क्योंकि बाद का EAGLE सेटअप भी bf16 की आवश्यकता रखता है, तो बेस रन और speculative रन को एक जैसा रखने से टेस्ट के बीच dtype बदलने की ज़रूरत नहीं रहती। मैंने पहले रन में --context-length 100000 भी रखा ताकि फुल कॉन्टेक्स्ट विंडो की बजाय डिबग करना आसान रहे।
कंटेनर लॉग्स इस कमांड से देखें:
docker logs -f mistral-sglang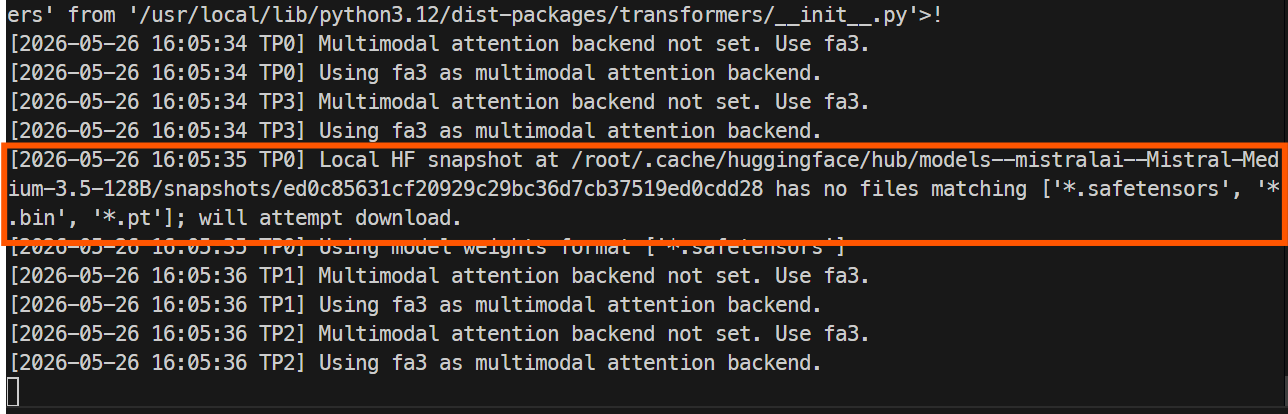
पहला लॉन्च अधिक समय लेगा क्योंकि SGLang को Hugging Face से मॉडल फ़ाइलें डाउनलोड करनी होती हैं। पूरा रेपो बड़ा है, इसलिए यह आपके इंस्टेंस की स्पीड के अनुसार लगभग एक घंटा या उससे अधिक ले सकता है।
जब सर्वर तैयार हो जाएगा, तो लॉग्स दिखाएँगे कि Uvicorn पोर्ट 30000 पर चल रहा है।
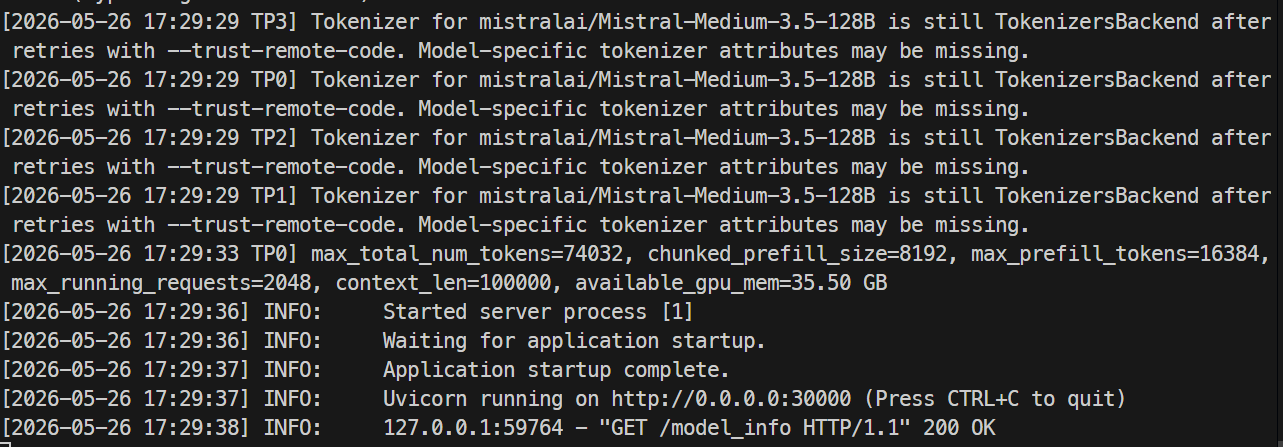
दूसरे टर्मिनल में, फिर से सर्वर में SSH करें और मॉडल एंडपॉइंट जाँचें:
curl http://localhost:30000/v1/modelsआपको mistral-medium-3.5 दिखाई देना चाहिए, जिसके max_model_len की वैल्यू 100000 होगी।
{"object":"list","data":[{"id":"mistral-medium-3.5","object":"model","created":1779816738,"owned_by":"sglang","root":"mistral-medium-3.5","parent":null,"max_model_len":100000}]}अंत में, एक चैट कम्प्लीशन टेस्ट करें:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mistral-medium-3.5",
"messages": [
{
"role": "user",
"content": "Write a short introduction to Mistral Medium 3.5."
}
],
"max_tokens": 300,
"temperature": 0.7,
"top_p": 0.95
}'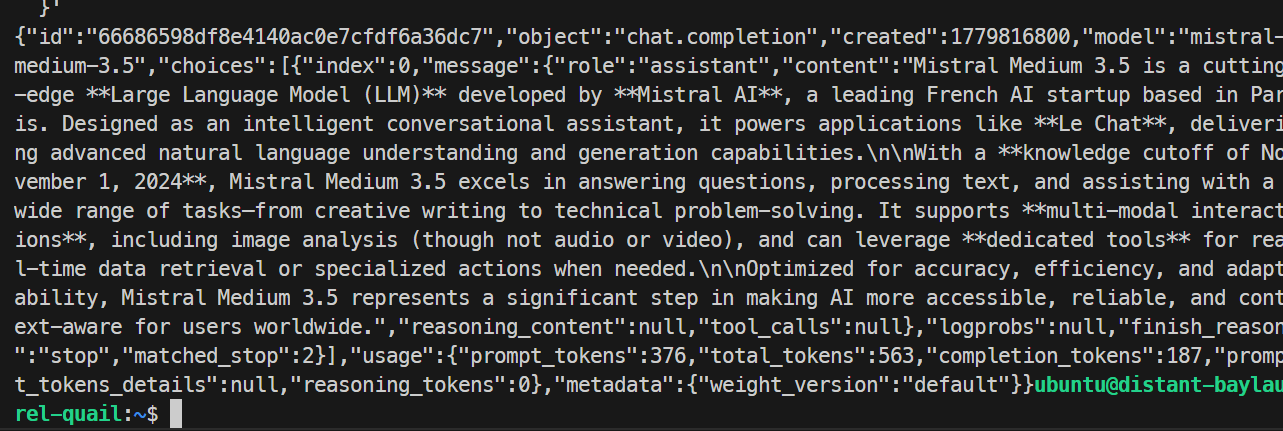
मेरे टेस्ट में, मॉडल ने सफलतापूर्वक जवाब दिया और रिक्वेस्ट को साफ़‑सुथरे तरीके से पूरा किया, जिससे पुष्टि हुई कि SGLang एंडपॉइंट काम कर रहा था। बेस रन ने लगभग 35.6 टोकन प्रति सेकंड जेनरेट किए।
Speculative decoding स्पीड बढ़ा सकता है—एक छोटा ड्राफ्ट मॉडल आगे के टोकन का अनुमान लगाता है और मुख्य मॉडल उन्हें वेरिफ़ाई करता है।
EAGLE यहाँ उपयोगी है क्योंकि इसे लेटेंसी‑सेंसिटिव सर्विंग के लिए डिज़ाइन किया गया है, खासकर तब जब आप Mistral Medium 3.5 जैसे बड़े मॉडल को लोकली चला रहे हों। यह हमेशा तेज़ नहीं होगा, लेकिन टेस्ट करने लायक है क्योंकि लाभ प्रॉम्प्ट की लंबाई, आउटपुट की लंबाई, कंकरेन्सी, और GPU उपयोग पर निर्भर करता है।
सबसे पहले, बेस कंटेनर हटाएँ:
docker rm -f mistral-sglangफिर EAGLE वर्ज़न शुरू करें:
docker run -d \
--name mistral-sglang-eagle \
--gpus all \
--shm-size 64g \
--ipc=host \
--cap-add SYS_NICE \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e HF_TOKEN="$HF_TOKEN" \
-e PYTORCH_ALLOC_CONF=expandable_segments:True \
lmsysorg/sglang:dev-mistral-medium-3.5 \
sglang serve \
--model-path mistralai/Mistral-Medium-3.5-128B \
--served-model-name mistral-medium-3.5-eagle \
--host 0.0.0.0 \
--port 30000 \
--tp 4 \
--trust-remote-code \
--dtype bfloat16 \
--context-length 100000 \
--mem-fraction-static 0.85 \
--disable-custom-all-reduce \
--tool-call-parser mistral \
--reasoning-parser mistral \
--enable-metrics \
--speculative-algorithm EAGLE \
--speculative-draft-model-path mistralai/Mistral-Medium-3.5-128B-EAGLE \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4SGLang इस EAGLE सेटअप की सिफारिश एक अच्छे शुरुआती बिंदु के रूप में करता है: --speculative-num-steps 3, --speculative-eagle-topk 1, और --speculative-num-draft-tokens 4। पहला रन अधिक समय ले सकता है क्योंकि यह EAGLE ड्राफ्ट मॉडल भी डाउनलोड करता है।
लोड होने के बाद, आप nvidia-smi से GPU उपयोग देख सकते हैं; मेरे रन में, मॉडल ने लगभग प्रति H100 GPU 44GB उपयोग किया।
लॉग्स मॉनिटर करें:
docker logs -f mistral-sglang-eagle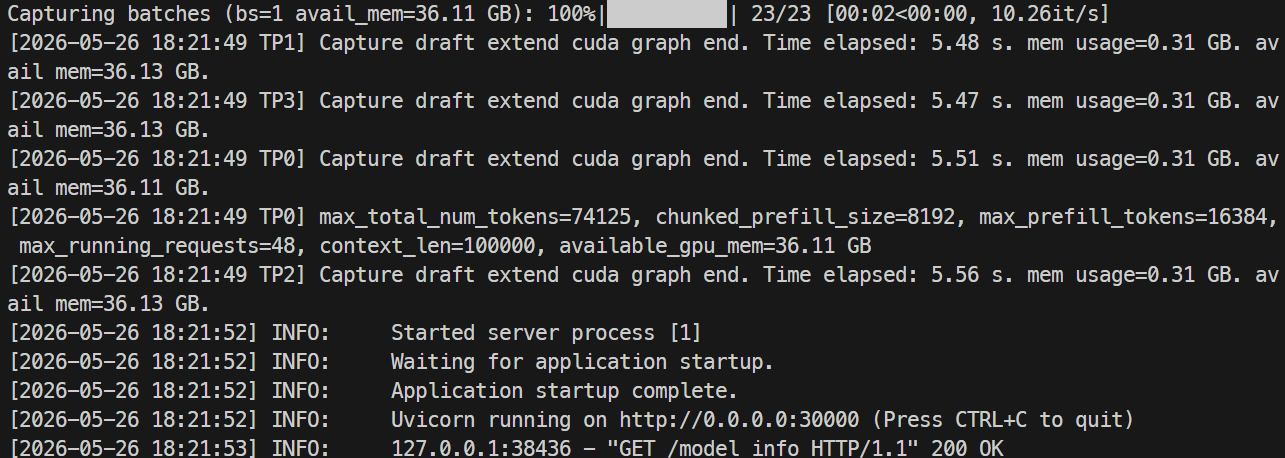
जब लॉग्स दिखाएँ कि Uvicorn 0.0.0.0:30000 पर चल रहा है, तो एंडपॉइंट टेस्ट करें:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mistral-medium-3.5-eagle",
"messages": [
{
"role": "user",
"content": "Generate a simple Python game."
}
],
"reasoning_effort": "none",
"max_tokens": 300,
"temperature": 0.7,
"top_p": 0.95
}'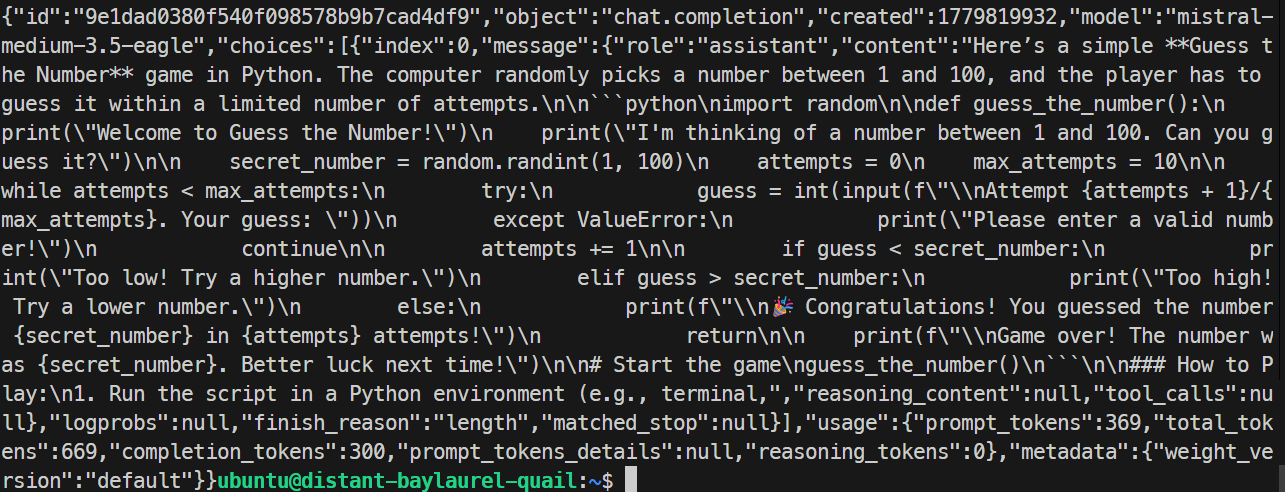
मेरे टेस्ट में, EAGLE सर्वर ने सही जवाब दिया और एक साधारण Python गेम जेनरेट किया। रन ने लगभग 32 टोकन प्रति सेकंड हासिल किए, जो बेस रन से थोड़ा धीमा था, इसलिए इस विशेष टेस्ट में EAGLE ने सुधार नहीं दिया।
यह सामान्य है: speculative decoding काफी हद तक वर्कलोड पर निर्भर करता है, और इसका सही आकलन करने का सबसे अच्छा तरीका है कि आप इसे अपने प्रॉम्प्ट्स और कंकरेन्सी स्तर के साथ टेस्ट करें।
OpenCode एक ओपन‑सोर्स AI कोडिंग एजेंट है जो OpenAI‑अनुकूल मॉडल एंडपॉइंट्स से कनेक्ट हो सकता है। चूँकि SGLang Mistral Medium 3.5 को लोकल OpenAI‑अनुकूल API के जरिए एक्सपोज़ करता है, हम इसे सीधे OpenCode में उपयोग कर सकते हैं।
यदि आपने OpenCode इंस्टॉल नहीं किया है, तो करें:
curl -fsSL https://opencode.ai/install | bashफिर अपने प्रोजेक्ट डायरेक्टरी में जाएँ और एक opencode.json फ़ाइल बनाएँ।
निम्न कॉन्फ़िगरेशन जोड़ें:
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"sglang": {
"npm": "@ai-sdk/openai-compatible",
"name": "SGLang Local",
"options": {
"baseURL": "http://127.0.0.1:30000/v1",
"apiKey": "EMPTY"
},
"models": {
"mistral-medium-3.5-eagle": {
"name": "Mistral Medium 3.5 EAGLE",
"limit": {
"context": 100000,
"output": 8192
}
}
}
}
},
"model": "sglang/mistral-medium-3.5-eagle"
}अब उसी प्रोजेक्ट डायरेक्टरी से OpenCode लॉन्च करें:
Opencodeआपको OpenCode के अंदर Mistral Medium 3.5 EAGLE SGLang Local सेलेक्टेड दिखना चाहिए। इसका मतलब है कि OpenCode अब फ़ॉरवर्ड किए गए 30000 पोर्ट के ज़रिए आपके लोकल SGLang सर्वर से बात कर रहा है, बिल्कुल वैसे ही जैसे वह किसी OpenAI‑अनुकूल API को कॉल करता है।
मेरे टेस्ट में, मैंने OpenCode से प्रोजेक्ट समझाने को कहा, और इसने कुछ सेकंड में रेपो फ़ाइलें पढ़कर सारांश बना दिया।
फिर, मैंने इसे Badger 2040 इम्यूलेटर बनाने को कहा, तो इसने पहले मौजूदा प्रोजेक्ट फ़ाइलों का निरीक्षण किया, संरचना वेरिफ़ाई की, और फिर आवश्यक Python फ़ाइल बना दी। पूरा प्रोसेस लगभग 2 मिनट में पूरा हुआ।
उसके बाद, मैंने इसे लोकली इम्यूलेटर टेस्ट करने को कहा। OpenCode ने कोड चलाया और इम्यूलेटर विंडो सफलतापूर्वक खोली।
फ़ॉन्ट असली Badger 2040 डिस्प्ले जैसा बिल्कुल नहीं था, लेकिन लेआउट, समय प्रदर्शन, तारीख का स्थान, और समग्र संरचना क़रीब‑क़रीब परफ़ेक्ट थे।

नतीजा सच में चौंकाने वाला था क्योंकि मैंने यही टास्क पहले Claude Code और GPT-5.5 से आज़माया था, और दोनों को दिक्कत हुई थी, जबकि Mistral Medium 3.5 ने इसे लोकल SGLang सेटअप के जरिए बहुत अच्छे से हैंडल कर लिया।
रास्ते में कुछ पेंच आ सकते हैं। आइए उन समस्याओं पर चलते हैं जिनका सामना आपको हो सकता है और उनके समाधान।
सबसे पहले, आपको धैर्य रखना होगा। इस पूरे सेटअप में मुझे लगभग 3 घंटे लगे। GPU VM लॉन्च होने में लगभग 15 मिनट, Docker और NVIDIA कंटेनर टूलकिट इंस्टॉल करने में लगभग 10 मिनट, SGLang Docker इमेज पुल करने में लगभग 30 मिनट, और Mistral Medium 3.5 मॉडल वेट्स डाउनलोड व लोड करने में लगभग 1 घंटा लगा।
EAGLE सेटअप शुरू करना भी अतिरिक्त समय लेता है क्योंकि यह मॉडल फिर से लोड करता है और EAGLE ड्राफ्ट मॉडल भी डाउनलोड कर सकता है। यदि आप स्मूथ अनुभव चाहते हैं, तो तेज़ नेटवर्किंग, उपलब्ध होने पर नए GPUs जैसे H200s, और पूरे Hugging Face कैश के लिए पर्याप्त स्टोरेज का उपयोग करें।
यदि nvidia-smi होस्ट पर काम करता है लेकिन Docker GPUs तक नहीं पहुँच पा रहा, तो संभवतः NVIDIA कंटेनर रनटाइम सही से कॉन्फ़िगर नहीं है। NVIDIA कंटेनर टूलकिट कॉन्फ़िगरेशन फिर से चलाएँ और Docker रीस्टार्ट करें:
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart dockerNVIDIA के दस्तावेज़ भी Docker GPU एक्सेस के लिए इस nvidia-ctk रनटाइम कॉन्फ़िगरेशन स्टेप की सिफारिश करते हैं।
सुनिश्चित करें कि Hugging Face कैश कंटेनर में माउंट किया गया है:
-v ~/.cache/huggingface:/root/.cache/huggingfaceइससे Docker पहले से डाउनलोड की गई मॉडल फ़ाइलों को री‑यूज़ कर सकता है, हर बार दोबारा डाउनलोड करने की ज़रूरत नहीं रहेगी। Hugging Face अप‑टू‑डेट फ़ाइलों को दोबारा डाउनलोड करने से बचने के लिए लोकल कैश का उपयोग करता है।
Mistral Medium 3.5 रेपो बड़ा है, इसलिए पहली बार डाउनलोड में लंबा समय लग सकता है। यदि यह अटका दिखे, तो अपना इंटरनेट स्पीड, डिस्क स्पेस, और Hugging Face टोकन जाँचें। साथ ही, कंटेनर चलाने से पहले यह सुनिश्चित करें कि आपने Hugging Face पर आवश्यक मॉडल एक्सेस शर्तें स्वीकार कर ली हैं।
जब तक लॉग्स यह न दिखाएँ कि Uvicorn पोर्ट 30000 पर चल रहा है, सर्वर तैयार नहीं है। लॉग्स इस तरह देखें:
docker logs -f mistral-sglangया EAGLE के लिए:
docker logs -f mistral-sglang-eagleसाथ ही, सुनिश्चित करें कि कंटेनर पोर्ट सही से एक्सपोज़ कर रहा है:
-p 30000:30000यह सामान्य है। Speculative decoding हर रिक्वेस्ट में सुधार की गारंटी नहीं देता। यह ड्राफ्ट मॉडल से टोकन प्रस्तावित कराकर और मुख्य मॉडल से वेरिफ़ाई कराकर काम करता है, पर स्पीड‑अप एक्सेप्टेंस रेट, प्रॉम्प्ट लंबाई, आउटपुट लंबाई, कंकरेन्सी, और GPU उपयोग पर निर्भर करता है।
यदि मेमोरी से जुड़ी समस्याएँ आएँ, तो पहले कॉन्टेक्स्ट लंबाई घटाएँ। उदाहरण के लिए, तुरंत फुल कॉन्टेक्स्ट विंडो आज़माने के बजाय --context-length 100000 से शुरू करें। यदि स्टार्टअप फ़ेल हो, तो आप --mem-fraction-static को थोड़ा कम कर सकते हैं, लेकिन आम तौर पर कॉन्टेक्स्ट लंबाई घटाना सबसे आसान पहला कदम होता है।
सुनिश्चित करें कि SGLang सर्वर चल रहा है और आपका opencode.json सही लोकल एंडपॉइंट का उपयोग कर रहा है:
"baseURL": "http://127.0.0.1:30000/v1"यदि आप सर्वर को अपनी लोकल मशीन से एक्सेस कर रहे हैं, तो पोर्ट फ़ॉरवर्डिंग के साथ SSH शुरू करें:
ssh -L 30000:localhost:30000 ubuntu@XXXXXXफिर उसी डायरेक्टरी से OpenCode लॉन्च करें जहाँ आपका opencode.json सेव है।
ईमानदारी से कहूँ तो तकनीकी सेटअप उम्मीद से ज़्यादा स्मूथ था। नैटिव SGLang Docker इमेज के साथ Mistral Medium 3.5 128B चलाना मेरी अपेक्षा से आसान रहा। Docker इमेज सही से पुल हुई, मॉडल लोड हुआ, OpenAI‑अनुकूल एंडपॉइंट काम किया, और OpenCode बिना ज़्यादा दिक्कत के कनेक्ट हो गया। मैं
यदि आप खुद यह आज़मा रहे हैं, तो मेरी मज़बूत सिफारिश है कि Python पैकेजेस से सब कुछ इंस्टॉल करने के बजाय SGLang Docker इमेज का उपयोग करें। Python से इंस्टॉल करने पर CUDA, PyTorch, और अन्य डिपेंडेंसीज़ के साथ चीज़ें आसानी से उलझ सकती हैं। Docker सब कुछ साफ़ और आइसोलेटेड रखता है।
लेकिन इस प्रयोग से मुझे सबसे बड़ा निष्कर्ष लागत का लगा। सच में समझ नहीं आता कि AI कंपनियाँ इन्फ़्रेंस पर पैसे कैसे कमा रही हैं। अपेक्षाकृत सस्ते और पुराने H100 PCIe विकल्प के साथ भी, यह सेटअप करीब $10 प्रति घंटा था। और यह सिर्फ 4 GPUs पर 128B मॉडल के लिए है। अब कल्पना करें कि 16× H100s पर कहीं बड़ा ट्रिलियन‑पैरामीटर मॉडल चल रहा हो। आपका बिल आसानी से $40+ प्रति घंटा तक पहुँच सकता है—स्टोरेज, नेटवर्किंग, मॉनिटरिंग, अपटाइम, और इंजीनियरिंग कार्य के बारे में सोचे बिना।
छोटी कंपनियों के लिए, मुझे नहीं लगता कि बिना बहुत मज़बूत कारण (जैसे प्राइवेसी, रिसर्च, या इन्फ़्रेंस स्टैक पर गहरा नियंत्रण) के इस तरह लोकली मॉडल सर्व करना समझदारी है। इन्फ़्रेंस लागत पहले से ही ऊँची है, और ऑपरेशनल बोझ भी समस्या है। आपको सर्वर चालू रखना होगा, मॉडल के क्रैश न होने का ध्यान रखना होगा, GPU मेमोरी मॉनिटर करनी होगी, फ़ेल्ड कंटेनर्स संभालने होंगे, और एंडपॉइंट को उपलब्ध रखना होगा।
सर्वरलेस भी बहुत बड़े मॉडलों के लिए सच में समाधान नहीं है। कोल्ड स्टार्ट बहुत लंबा है। इस सेटअप में GPU VM लॉन्च करना, डिपेंडेंसीज़ इंस्टॉल करना, Docker इमेज पुल करना, वेट्स डाउनलोड करना, और मॉडल लोड करना, कुल मिलाकर लगभग 3 घंटे लगा।
भले ही आपका सेटअप तेज़ हो, इस आकार के मॉडल को लोड करने में फिर भी समय लगता है। तो अगर हर नई रिक्वेस्ट के लिए एक और GPU क्लस्टर लॉन्च करना और मॉडल फिर से लोड करना पड़े, तो सर्वरलेस का उद्देश्य ही ख़त्म हो जाता है। व्यवहार में, कंपनियों को वार्म GPU क्लस्टर्स चलाते रहना पड़ता है—यानी GPUs के आइडल होने पर भी क़ीमत चुकानी पड़ती है।
यही वजह है कि ऑफ़‑पीक GPU प्राइसिंग मौजूद है। प्रदाता चाहते हैं कि लोग आइडल GPU क्षमता का उपयोग करें क्योंकि उपयोग न होने वाले GPUs सीधे नुकसान हैं। उपयोगकर्ताओं के लिए, यह सस्ते में प्रयोग करने का अच्छा तरीका हो सकता है, लेकिन यह भी दिखाता है कि बड़े मॉडलों के इन्फ़्रेंस की इकॉनॉमिक्स कितनी कठिन है।
कुल मिलाकर, इस सेटअप के लिए मुझे SGLang बहुत पसंद आया। Docker‑आधारित वर्कफ़्लो ने Mistral Medium 3.5 128B को सर्व करना उम्मीद से कहीं आसान बना दिया, और OpenCode टेस्ट सच में प्रभावशाली था। लेकिन इस प्रयोग ने मेरे लिए एक बात बिल्कुल साफ़ कर दी: बड़े ओपन मॉडल्स को लोकली चलाना संभव है, पर उन्हें एक असली प्रोडक्ट के रूप में भरोसेमंद और किफ़ायती तरीके से चलाना बिलकुल अलग चुनौती है।
DataCamp के साथ AI सीखें!
Track
course
course